性能测试-jmeter13-性能资源指标监控
课程:B站大学
记录软件测试-性能测试学习历程、掌握前端性能测试、后端性能测试、服务端性能测试的你才是一个专业的软件测试工程师
性能测试-jmeter性能指标监控
- Jmeter常见图表
- Jmeter性能资源指标监控
- 步骤 1:安装 PerfMon Metrics Collector 插件
- 步骤 2:在目标服务器安装 ServerAgent
- 下载 ServerAgent
- 启动 ServerAgent
- 步骤 3:在 JMeter 中配置 PerfMon 监控
- PerfMon Metrics Collector 监控指标说明表
- 典型监控方案组合:
- ==主流常用的搭建监控体系==
- 并发数的计算
- 普通计算方法
- 二八原则计算方法
- 按照业务数据进行计算
- 一、明确测试目标与关键业务场景
- 二、确定核心性能指标及目标阈值
- 性能测试核心指标及说明
- 1. 响应时间
- 2. 吞吐量
- 3. 并发用户数
- 4. 错误率
- 5. 资源利用率
- 三、基于业务数据的性能指标计算
- 实践是检验真理的唯一标准
Jmeter常见图表
在jmeter-plugins中有很多插件jar可以进行安装,部分插件包在github上有开源的jar集合
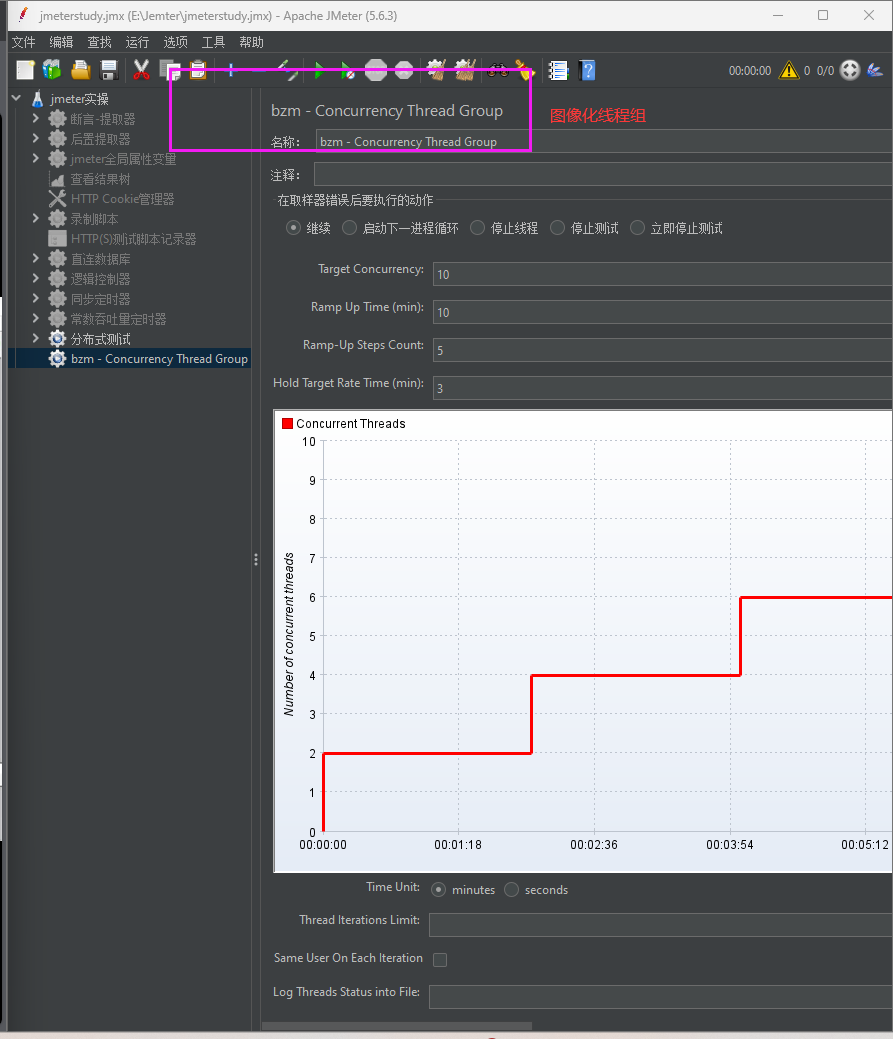
Jmeter性能资源指标监控
JMeter PerfMon Metrics Collector(服务器性能监控插件) 监控服务器资源(CPU、内存、磁盘、网络等)
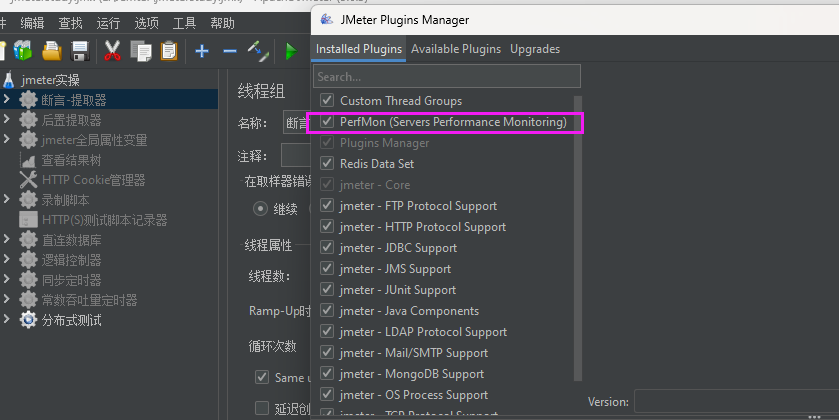
步骤 1:安装 PerfMon Metrics Collector 插件
步骤 2:在目标服务器安装 ServerAgent
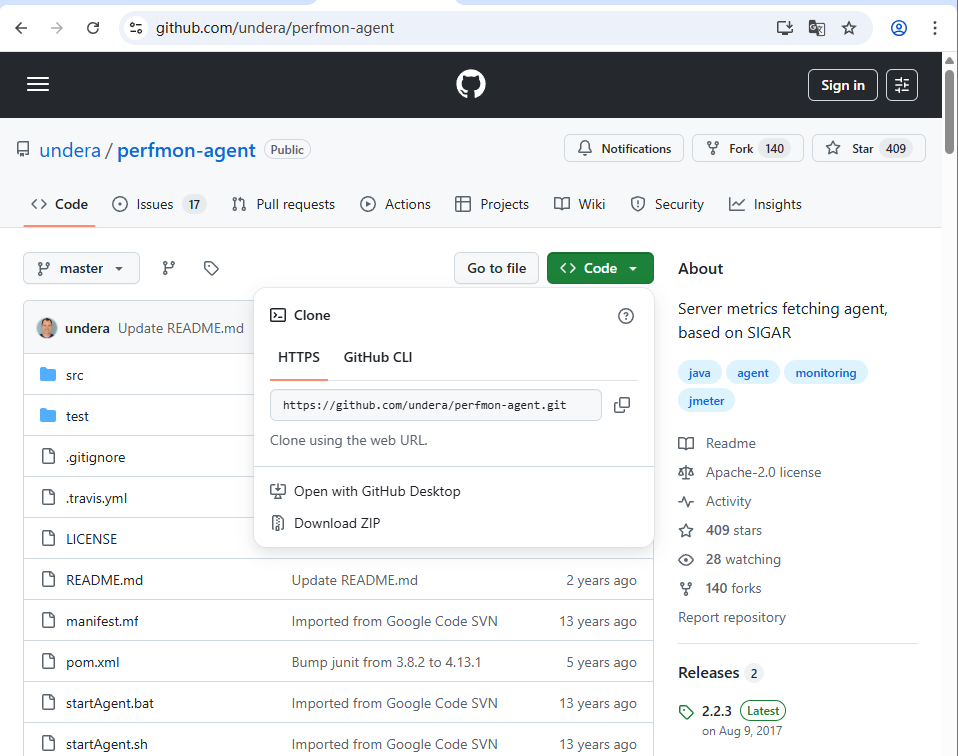
下载 ServerAgent
从官方地址下载:ServerAgent - GitHub(选择最新版,如 ServerAgent-2.2.3.zip)。
解压到目标服务器的任意目录(如 /opt/serveragent或 C:\serveragent)。
https://github.com/undera/perfmon-agent
启动 ServerAgent
linux服务器进入解压目录,执行以下命令启动(默认端口 4444):
./startAgent.sh
若需指定端口(如 4444):
./startAgent.sh --tcp-port 4444 --udp-port 4444
windows同理
Windows 服务器:
双击解压目录下的 startAgent.bat文件启动(默认端口 4444)。
若需指定端口:
修改 startAgent.bat中的 PORT参数(如 set PORT=5555),然后运行。
3. 验证 ServerAgent 是否运行
在服务器上执行 netstat -tulnp | grep 4444(Linux)或 netstat -ano | findstr 4444(Windows),确认端口 4444处于监听状态。
若无法连接,检查防火墙是否放行该端口(如开放 TCP 4444)。
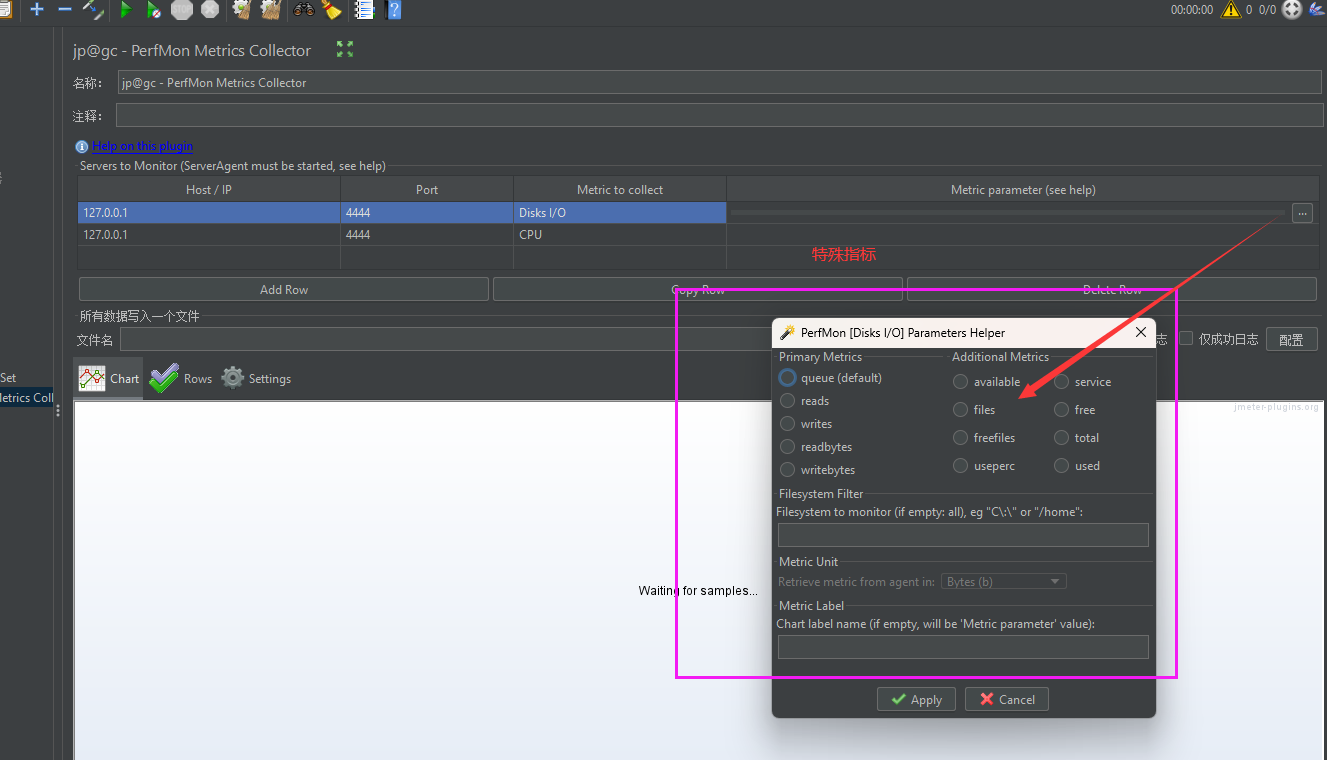
步骤 3:在 JMeter 中配置 PerfMon 监控
### 1. 添加 PerfMon Metrics Collector 监听器
- 打开 JMeter,创建或打开一个测试计划(Test Plan)。
- 右键点击 Test Plan → Add→ Threads (Users)→ Thread
Group(添加线程组,模拟用户请求)。 - 右键点击 Thread Group → Add→ Listener→ jp@gc - PerfMon Metrics Collector(即 PerfMon 监控监听器)。
### 2. 配置监控的服务器和指标
在 PerfMon Metrics Collector 监听器界面,点击 Add Row 按钮(添加要监控的服务器)。
填写以下信息:
- Server IP / Host Name:目标服务器的 IP 地址或主机名(如 192.168.1.100)。
- Port:ServerAgent 的端口(默认 4444,若修改过则填写自定义端口,如 5555)。
- Metric to collect:选择要监控的资源类型(从下拉菜单选择,常用选项见下文)。
- Alias:自定义别名(如 Server_CPU、Server_Mem,便于结果识别
常用监控指标(Metric to collect):
PerfMon Metrics Collector 监控指标说明表
| 指标名称 | 监控内容 | 单位/格式 | 详细说明 |
|---|---|---|---|
cpu | CPU 使用率 | 百分比 (%) | 服务器整体 CPU 资源占用比例(0%-100%),反映计算负载压力。 |
memory | 内存使用量 | MB 或 GB(取决于服务器配置) | 物理内存的已用量(非剩余量),用于分析内存瓶颈(如频繁 GC 或 OOM 风险)。 |
diskio | 磁盘 I/O 性能 | 读写速率(KB/s / MB/s) | 磁盘的读写速度(每秒传输的数据量),高值可能表示磁盘 I/O 瓶颈。 |
network | 网络流量 | 发送/接收速率(KB/s / MB/s) | 网络接口的实时上传(发送)和下载(接收)速度,用于评估网络带宽占用情况。 |
swap | 交换分区使用量 | MB 或 GB | 虚拟内存(磁盘交换空间)的已用量,过高表明物理内存不足,可能影响性能。 |
tcp | TCP 连接数 | 当前活跃连接数(整数) | 服务器当前建立的 TCP 连接总数(包括客户端与服务端),反映网络交互负载。 |
不错目前这个技术以及落后了,现在又开源更加完善的服务端监控系统比如:
Prometheus + Grafana(云原生/容器化环境首选)
- Prometheus 负责采集指标(通过 Exporter 如 node_exporter采集服务器基础资源),Grafana负责可视化展示(配置丰富的仪表盘)。
- 适合大规模分布式环境,支持告警规则(Alertmanager)。
Zabbix(传统企业级监控) - 老牌综合监控工具,支持服务器、网络设备、数据库等,提供阈值告警和历史数据存储。
典型监控方案组合:
- 服务器基础资源:用 Prometheus + Grafana(node_exporter) 实时监控
CPU/内存/磁盘/网络。 - 应用性能:用 Spring Boot Actuator + Micrometer + Prometheus 监控 JVM和业务指标,或直接通过 JMeter 的 PerfMon Metrics Collector 监控服务器资源。
- 数据库/中间件:用 Prometheus + Exporter(如 MySQL Exporter、Redis
Exporter) 监控慢查询、连接池状态。 - 分布式追踪:用 SkyWalking/Jaeger 分析微服务调用链耗时。
- 日志:用 ELK 收集错误日志,快速定位异常。
主流常用的搭建监控体系
nginx+docker+influxdb(Prometheus )+grafana+jmeter+shell+git+jenkis搭建服务端性能测试监控体系以及服务端cpu核心监控
并发数的计算
业务需求;
- PV:(Page View)即页面访问量,每打开一次页面PV计数+1,刷新页面也是。PV只统计页面访问次数。
- UV(Unique Visitor),唯一访问用户数,用来衡量真实访问网站的用户数量。
- 一般用UV统计用户活跃数,用PV统计用户访问页面的频率。
普通计算方法
计算公式: TPS= 总请求数 / 总时间
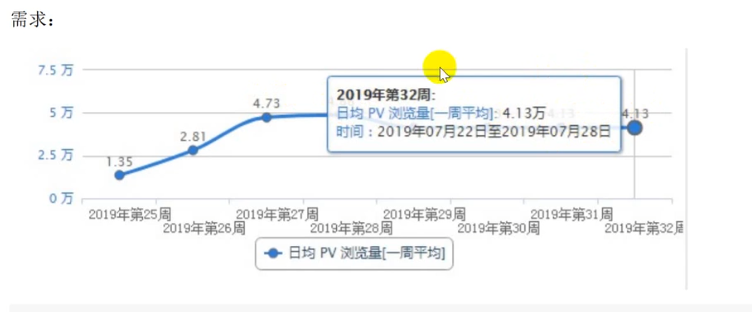
按照需求所示,在2019年第32周,有4.13万的浏览量,那么总请求数,我们可以认为估算为4.13万(1次浏览量都至少对应1个请求
总请求数 = 4.13 万请求数 = 41300 请求数
总时间:由于不知道每个请求的具体时间,我们按照普通方法,我们可以按照一周的时间进行计算
总时间 = 1天 = 1 * 24 小时 = 24 * 3600 秒
套入公式可得:
这个公式会被平均,故指标不准确(用二八原则,最好还是先业务基准测试得到基准指标,然后逐步加压)
TPS = 41300请求数/24 * 3600秒 = 0.48请求数/秒
结论: 按照普通计算方法,我们在测试环境对相同的系统进行性能测试时,每秒能够发送0.48请求就可以满足线上的需要。
当然具体还是需要看场景的。看是哪个页面又哪个接口组成。
软件应用的本质:前端页面,后端接口,服务端部署
二八原则计算方法
二八原则是指80%的请求在20%的时间内完成。
计算公式:TPS = 总请求数 × 80% / (总时间 × 20%)
按照公式进行计算:
TPS = 41300 × 0.8请求数 / (24×3600×0.2秒) = 1.91 请求数/秒
结论:按照二八原则计算,在测试环境我们的TPS只要能达到1.91请求数每秒就能满足线上需要。二八原则的估算结果会比平均指标更加准确一些
按照业务数据进行计算
一、明确测试目标与关键业务场景
- 目标:确定要验证的系统性能问题,如支撑并发用户数、高峰业务请求量下的响应时间和错误率等。
- 场景:梳理高频、核心、对性能敏感的业务操作,如电商的商品详情页加载、订单支付,金融的账户查询、转账交易等。
二、确定核心性能指标及目标阈值
性能测试核心指标及说明
1. 响应时间
| 具体指标 | 说明 | 业务关联示例 |
|---|---|---|
| 平均响应时间、P90/P95/P99 | 用户从发起请求到收到完整响应的时间 | 订单支付响应时间 ≤ 1s |
2. 吞吐量
| 具体指标 | 说明 | 业务关联示例 |
|---|---|---|
| TPS(每秒事务数)、QPS(每秒查询数) | 系统每秒成功处理的业务请求数量 | 支付接口需支持 1000 TPS |
3. 并发用户数
| 具体指标 | 说明 | 业务关联示例 |
|---|---|---|
| 活跃用户数(VU)、绝对并发数 | 同时发起请求的用户数量或模拟持续操作的用户数 | 电商大促时 10 万用户同时浏览商品 |
4. 错误率
| 具体指标 | 说明 | 业务关联示例 |
|---|---|---|
| HTTP 4xx/5xx 错误比例 | 请求失败的比例 | 错误率需 < 1% |
5. 资源利用率
| 具体指标 | 说明 | 业务关联示例 |
|---|---|---|
| CPU、内存、磁盘 I/O、网络带宽 | 服务器硬件资源的消耗情况 | CPU 使用率 ≤ 70% |
三、基于业务数据的性能指标计算
- 吞吐量:TPS= 总测试时间(秒)/总业务请求数,根据业务需求确定目标 TPS,如每日 100 万次查询,日平均 QPS 约为
86400/1,000,000 ≈11.57。 - 并发用户数:并发用户数(VU)=活跃用户比例×总注册用户数,如日活用户 10 万,10% 活跃则 VU 为
100,000×10%=10,000;绝对并发数根据同时操作用户数确定。 - 响应时间:参考行业标准,如 ≤ 1s 流畅,1 - 3s 可接受,> 3s 易流失。
- 错误率:错误率= 总请求数/失败请求数(4xx/5xx) ×100%,业务要求错误率 < 1%。