深入大模型-2-大模型微调之Windows10安装大语言模型Unsloth微调环境
文章目录
- 1 什么是LLM微调
- 2 windows安装微调环境
- 2.1 windows安装WSL
- 2.2 准备安装环境
- 2.2.1 Anaconda(linux)
- 2.2.2 ollama(linux)
- 2.2.3 unsloth(linux)
- 2.2.4 CUDA简介
- 3 查找适配的版本
- 3.1 GTX1050显卡
- 3.2 支持的CUDA版本
- 3.3 支持的PyTorch版本
- 3.4 安装方式
- 3.5 总结
- 4 执行安装
- 4.1 创建Conda虚拟环境
- 4.2 安装Unsloth(使用清华镜像源)
- 4.3 卸载CPU版本的PyTorch
- 4.4 安装GPU版本的PyTorch
- 4.5 解决xformers版本冲突问题
- 4.6 验证安装
- 4.7 安装jupyterlab(linux)
- 5 参考附录
基于显卡GTX1050,驱动的版本,CUDA的版本,查找适配的pytorch版本。Unsloth、PyTorch及xformers等库之间存在版本依赖,需谨慎选择。注意一定要先安装Unsloth,然后再安装pytorch和调整xformers。
1 什么是LLM微调
微调是拿一个已经预训练好的LLM(比如GPT或Llama),它已经很懂得通用语言了,然后针对你的特定任务“调校”一下。给它喂一些你领域的例子,它就会调整自己的知识,专门为这个领域发光发热。
1、微调原理
从一个懂得英语(或其他语言)的base model开始,给它一堆“输入”(比如一个问题)和“输出”(比如完美答案)的配对,模型会调整内部weights来匹配这些例子。
2、微调与prompting的区别
Prompting就像临时给指令(比如“写得像莎士比亚”),而微调是永久改变模型,让它表现更稳定。
3、微调与parameter tuning的区别
Parameter tuning是调整像“temperature”(输出多有创意)这样的设置,就像调车上的收音机。微调则是给引擎升级,让它能跑越野。
4、假设想让LLM从乱糟糟的邮件里提取信息
(1)微调前:
Prompt: "从’嗨,我是 John。订个披萨。“中提取名字和订单。”
输出:可能很随机,比如"Name: John, Food: Pizza"或者只是个总结。
(2)微调后:
用100封邮件例子训练。
现在它总会输出JSON格式:{“name”: “John”, “order”: “pizza”}。
2 windows安装微调环境
2.1 windows安装WSL
Windows Subsystem for Linux
(1)启用WSL
勾选三个选项:Hyper-V,适用于Linux的windows子系统,虚拟机平台。
(2)安装ubuntu22.04
microsoft store搜索下载ubuntu。
双击Ubuntu 22.04.5 LTS Installer.exe
设置初始root密码:sudo passwd。
安装网络查询工具:sudo apt install net-tools。
(3)wsl升级到wsl2
(4)WSL(C盘迁移到D盘)
把WSL从C盘迁移到D盘,彻底解决“C盘飘红”的问题。
将你的Ubuntu-22.04从C盘迁移到D盘,释放C盘空间,并让未来的使用不再占用C盘。
2.2 准备安装环境
部署没有GPU显卡也可以,但是训练一定要有GPU显卡。
训练大模型一定是linux系统.
2.2.1 Anaconda(linux)
Anaconda下载地址
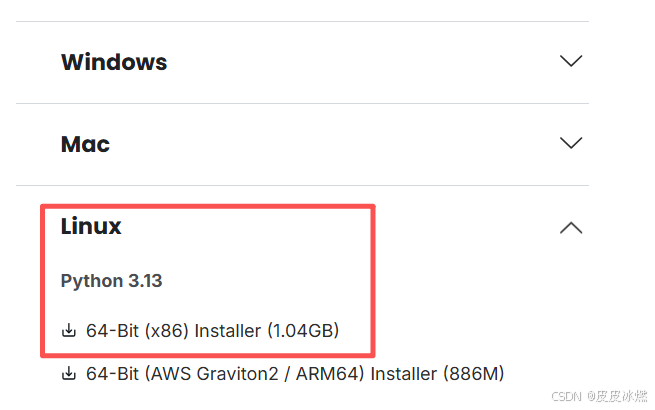
在windows中将下载好的安装包放到目录中。
默认安装路径固定,若用户想修改安装路径,需自行留意安装过程中的提示,部分用户可能因疏忽而直接采用默认路径,导致后期因磁盘空间分配不合理等问题产生困扰。
(1)执行安装
./Anaconda3-2025.06-0-Linux-x86_64.sh
记得一定不要修改安装位置/home/zb/anaconda3
(2)配置环境变量
编辑文件/home/zb/.bashrc
添加export PATH=$PATH:/home/zb/anaconda3/bin
生效source /home/zb/.bashrc

2.2.2 ollama(linux)
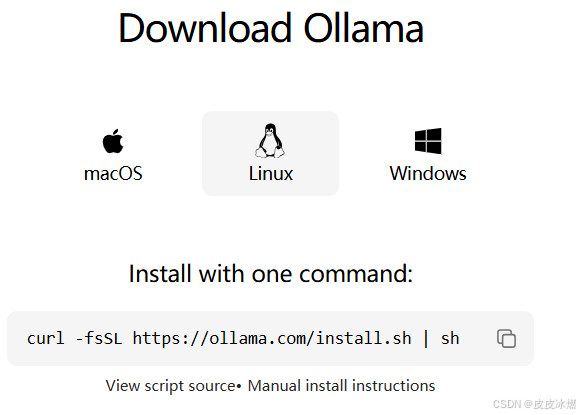
ollama官网
本地服务器部署Ollama(自定义安装位置)以及open-webui前端
curl -fsSL https://ollama.com/install.sh | sh
2.2.3 unsloth(linux)
unsloth的GitHub地址
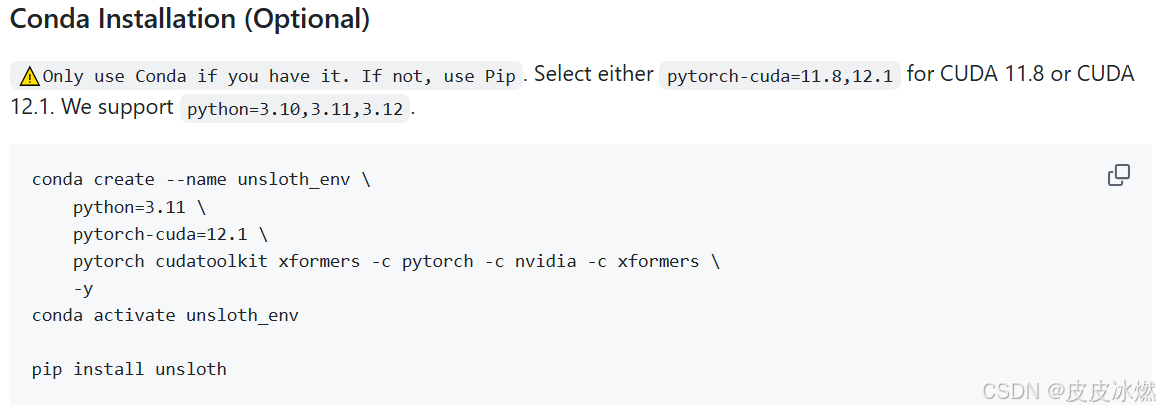
查看一下unsloth对版本的要求。
CUDA 11.8和CUDA 12.1指的是NVIDIA CUDA Toolkit的不同版本号。
2.2.4 CUDA简介
CUDA (Compute Unified Device Architecture))是NVIDIA开发的一个并行计算平台和编程模型。
它允许开发者使用NVIDIA的GPU(图形处理器)来执行复杂的计算任务,而不仅仅是处理图形。这在深度学习、科学计算、高性能计算(HPC)等领域至关重要。
(1)深度学习框架(如 PyTorch, TensorFlow)和加速库(如cuDNN)会为不同的CUDA 版本发布对应的编译版本。
(2)你安装的PyTorch版本必须与你系统上安装的CUDA Toolkit版本兼容。
例如:pytorch-cuda=12.1,这意味着你安装的是专门为CUDA 12.1编译和优化的PyTorch版本。如果你的系统只有CUDA 11.8,这个版本的PyTorch可能无法正常工作或无法利用GPU。
3 查找适配的版本
系统中安装了GTX1050显卡,其驱动版本为537.13,支持的CUDA版本为12.2,所以只要安装的pytorch-cuda的版本小于等于12.2就可以使用这个显卡。
3.1 GTX1050显卡
对于GTX 1050这款显卡,其支持的CUDA和PyTorch版本主要取决于它的计算能力 (Compute Capability)。
GTX 1050的计算能力为 6.1。
确保你的 NVIDIA 显卡驱动版本足够新,能够支持你选择的CUDA版本。
你可以通过nvidia-smi命令查看驱动支持的最高CUDA版本。
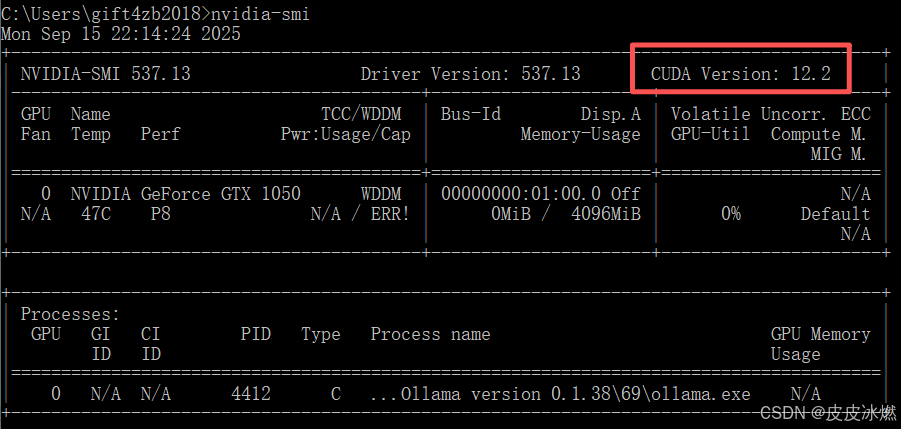
为CUDA 12.1编译的程序通常可以在安装了CUDA 12.2运行时的系统上正常运行。因此,安装pytorch-cuda=12.1的环境,在系统CUDA驱动支持的前提下,也可以在CUDA 12.2的环境中工作。
3.2 支持的CUDA版本
GTX 1050可以支持非常广泛的CUDA版本。
NVIDIA通常会向后兼容旧架构的显卡。
(1)最高支持的CUDA版本:理论上,最新的CUDA版本(如CUDA 12.x)仍然可以安装在GTX 1050上,并能正常工作。驱动程序会处理兼容性问题。
(2)推荐使用的CUDA版本:
对于深度学习开发,建议使用一个稳定且被主流框架广泛支持的版本。
像CUDA 11.8或CUDA 11.7是非常好的选择。它们足够新,能支持大多数现代 PyTorch/TensorFlow 版本,同时与Pascal架构(如GTX 1050)的兼容性经过了充分验证。
避免使用过老的版本(如CUDA 9.0, 10.0),因为它们可能不支持你想要安装的较新PyTorch版本。
3.3 支持的PyTorch版本
PyTorch官方发布的预编译包(通过pip或conda安装)通常会指定所支持的CUDA版本。
1、关键点:你需要安装一个其编译的CUDA版本 ≤ 你的系统实际安装的CUDA版本的PyTorch包。
例如,你可以用cu118(底层CUDA版本11.8)的PyTorch包运行在CUDA 12.1(实际安装的版本)的系统上,但反之则不行。
GTX 1050支持的PyTorch版本范围:非常广。从较早的PyTorch 1.0+到最新的 PyTorch 2.0+系列,只要选择了正确的CUDA版本后端(主要是cu118或更早的 cu117, cu116, cu113, cu111, cu102等),都可以在GTX 1050上运行。
2、强烈推荐的配置组合:
PyTorch 2.0+ / 2.1+ / 2.2+ / 2.3+ … + CUDA 11.8
(1)稳定性与性能:PyTorch 2.0+ 引入了torch.compile,能显著提升模型训练/推理速度。
(2)长期支持:这些是当前和未来的主流版本,拥有更好的文档、社区支持和第三方库兼容性。
(3)CUDA兼容性:CUDA 11.8是一个非常成熟和稳定的版本,完美支持 Compute Capability 6.1。
3.4 安装方式
(1)确认驱动:首先确保你的NVIDIA 显卡驱动是最新的或至少是较新的版本(450+系列以上通常没问题)。
(2)选择安装方式:最简单的方法是使用pip或conda安装PyTorch的预编译包,它会捆绑所需的CUDA工具包(不需要单独安装完整CUDA Toolkit)。
3.5 总结
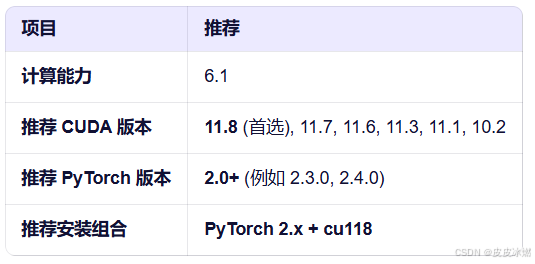
尽管GTX 1050是一款入门级且较老的显卡,但它完全可以支持进行深度学习开发。为了获得最佳体验,强烈建议安装PyTorch 2.0+版本并搭配CUDA 11.8 后端。避免追求使用最新的CUDA 12.x,因为这可能会导致与某些旧版 PyTorch包的兼容性问题,而对GTX 1050本身的性能提升微乎其微。
但CUDA12.X对Windows Subsystem for Linux (WSL) 有更好集成。
系统中安装了GTX1050显卡,其驱动版本为537.13,支持的CUDA版本为12.2,所以只要安装的pytorch-cuda的版本小于等于12.2就可以使用这个显卡。

4 执行安装
版本兼容性: Unsloth、PyTorch及xformers等库之间存在版本依赖,需谨慎选择。
4.1 创建Conda虚拟环境
conda create -n unsloth_gtx1050py310 python=3.10 -y
conda activate unsloth_gtx1050py310
4.2 安装Unsloth(使用清华镜像源)
接下来,使用清华镜像源安装Unsloth。
此步骤会自动安装Unsloth及其依赖,其中通常包含一个CPU版本的PyTorch。
pip install unsloth -i https://pypi.tuna.tsinghua.edu.cn/simple
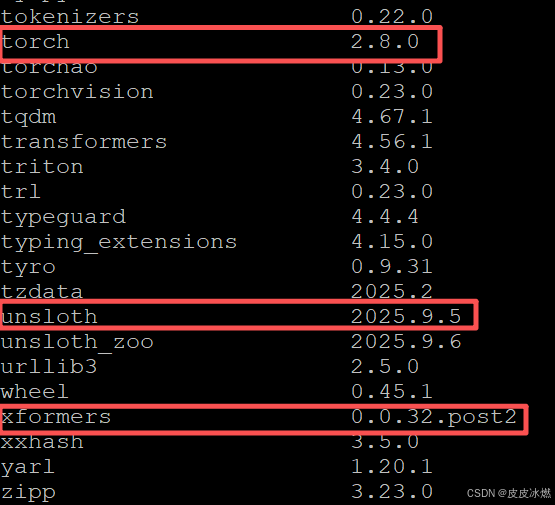
安装完成后,日志会列出所有已安装的包。
请留意此时安装的torch和xformers的版本。
例如,日志中可能显示torch-2.8.0和xformers-0.0.32.post2。
4.3 卸载CPU版本的PyTorch
pip uninstall torch torchvision torchaudio -y
4.4 安装GPU版本的PyTorch
(1)Unsloth兼容性: 检查你安装的Unsloth版本对PyTorch的最低版本要求 (例如,unsloth-2025.5.9 可能需要 torch>=2.4.0)。
(2)xformers 兼容性: 与Unsloth一同安装的xformers版本 (例如 xformers-0.0.32.post2) 通常与当时一同安装的PyTorch CPU版本 (例如 torch-2.8.0) 兼容。
(3)CUDA 版本: 确保选择与你的NVIDIA驱动和本地CUDA Toolkit版本匹配的PyTorch (例如 cu118 对应 CUDA 11.8)。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
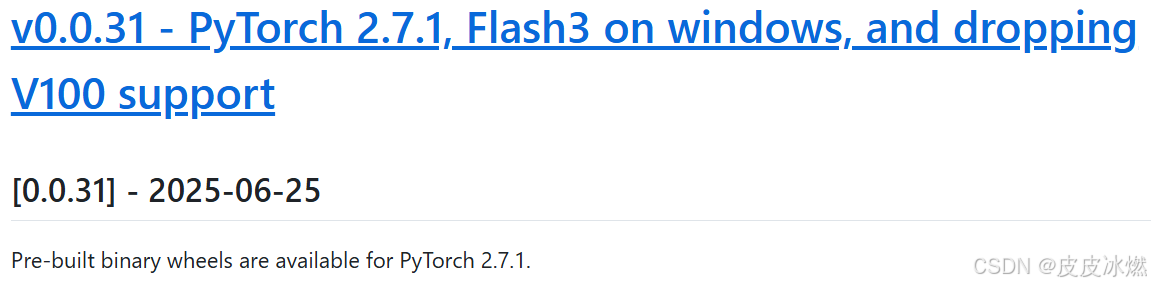
4.5 解决xformers版本冲突问题
xformers的Github地址
为了解决这个问题,需要查看xformers的GitHub地址。
# 1. 卸载现有不兼容版本
pip uninstall xformers -y
# 2. 安装与 CUDA 11.8 兼容的版本(使用预编译 wheel)
pip install xformers==0.0.31 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip cache purge# 会删除所有缓存的包文件,释放空间
4.6 验证安装
import torch
print(torch.__version__)
print(torch.cuda.is_available()) # 应该返回 True
print(torch.cuda.get_device_name(0)) # 应该显示 'GeForce GTX 1050'
4.7 安装jupyterlab(linux)
(1)安装JupyterLab
pip install jupyterlab -i https://pypi.tuna.tsinghua.edu.cn/simple
(2)运行
jupyter lab
(3)后台运行
nohup jupyter lab --no-browser --port=8888 &
(4)关闭
ps -aux | grep jupyter
kill -9 PID
5 参考附录
参考Anaconda下载地址
参考ollama官网
参考unsloth的GitHub地址
参考unsloth 部署教学 2.0
参考深度学习-79-大语言模型LLM之基于python与ollama启用的模型交互API介绍
参考ollama的GitHub地址
参考本地部署交互式计算平台 JupyterLab 并实现外部访问( Linux 版本)