论文笔记:How Can Recommender Systems Benefit from Large Language Models: A Survey
文献核心观点
这篇综述系统性地探讨了大语言模型(Large Language Models, LLMs)如何赋能推荐系统(Recommender Systems, RS),并提出了一个四象限分类框架来组织现有研究。
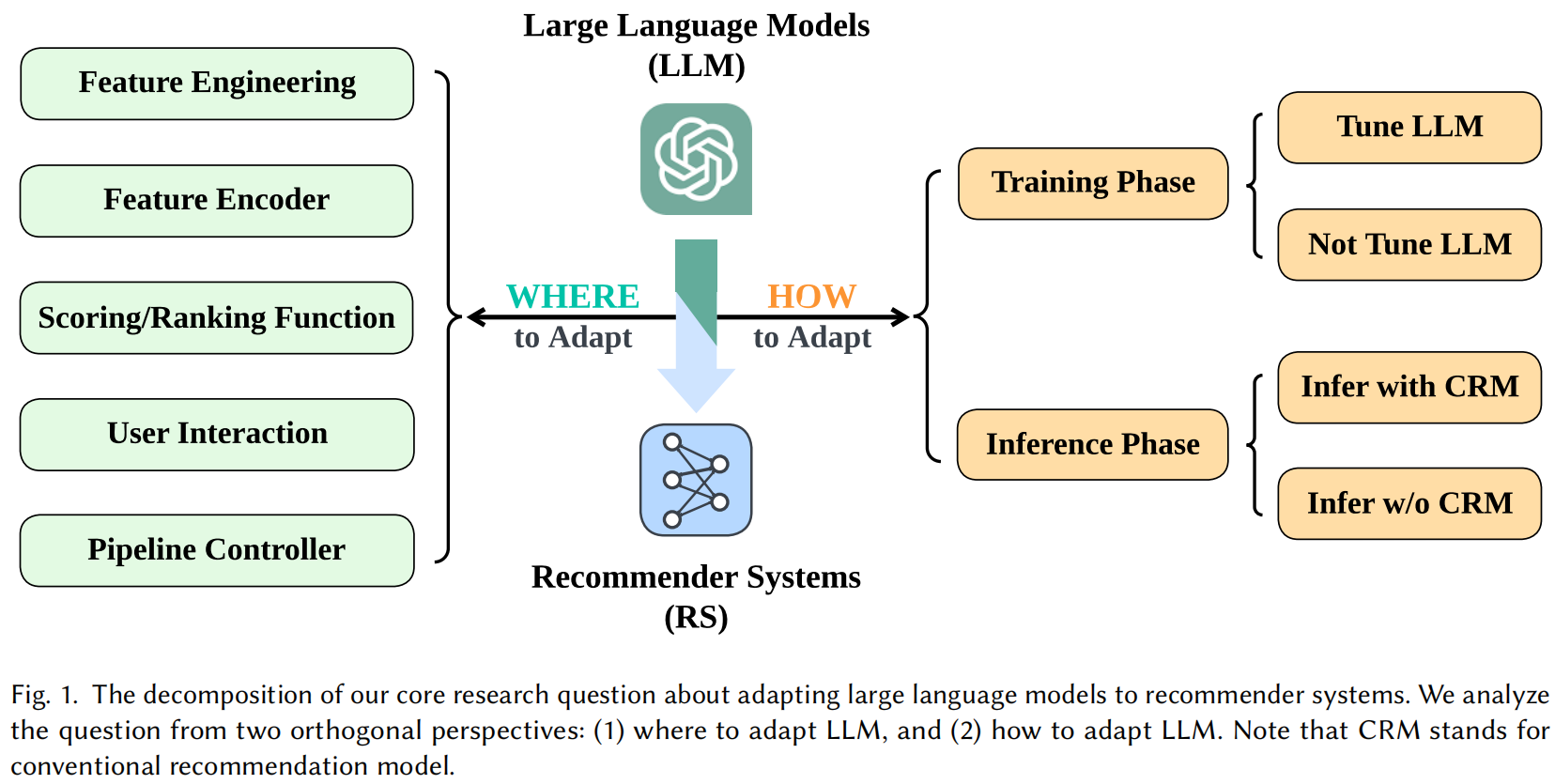
其核心观点是:
大语言模型可以通过四种主要范式(象限)融入推荐系统:直接作为推荐器、作为推荐器的增强模块、利用LLM生成的数据进行训练、以及作为推荐过程的控制器。每种范式在模型规模、任务形式和性能表现上各有特点。
一、核心框架:四象限分类法
文献的核心贡献是提出了一个二维四象限图(Figure 4),横轴为 “是否在推荐任务上微调”,纵轴为 “是否使用LLM生成的中间结果”。
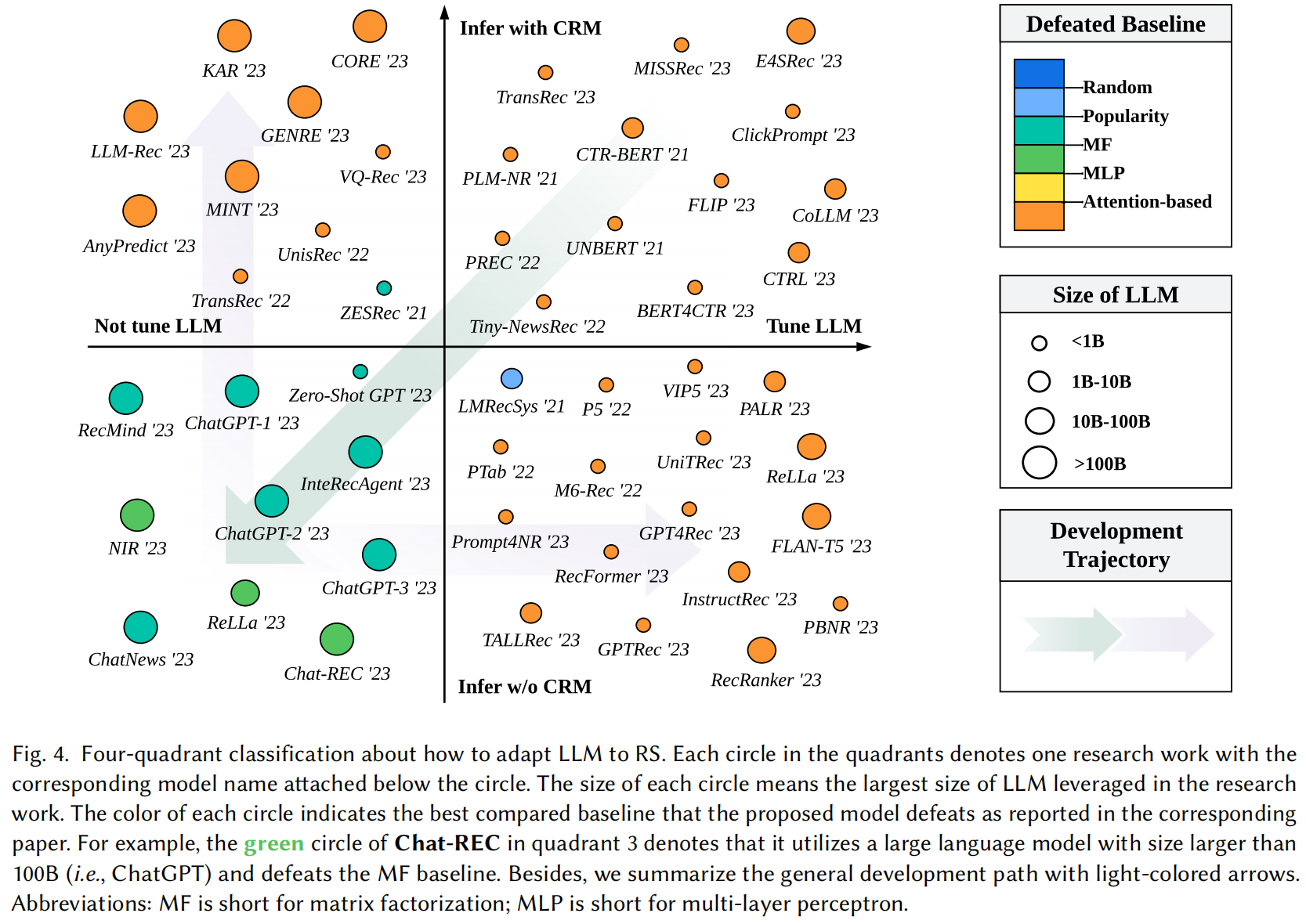
四个象限及其含义:
| 象限 | 是否微调 | 是否使用LLM中间结果 | 核心思想 |
|---|---|---|---|
| Q1 | 是 | 是 | LLM作为增强模块:LLM生成用户画像、物品描述、上下文等中间信息,输入给传统推荐模型。 |
| Q2 | 是 | 否 | LLM生成数据用于训练:用LLM生成合成数据(如用户评论、交互理由)来扩充训练集,提升传统模型性能。 |
| Q3 | 否 | 是 | LLM作为控制器:LLM不直接推荐,而是调度、组合或解释传统推荐模型的结果。 |
| Q4 | 否 | 否 | LLM直接作为推荐器:零样本/少样本推荐,直接用LLM(如ChatGPT)预测用户偏好。 |
下面我们通过具体实例来说明每个象限的观点。
二、各象限观点解析与实例说明
象限 Q4:LLM 直接作为推荐器(Zero-shot / Few-shot Recommendation)
观点:利用LLM强大的语言理解和生成能力,无需微调即可进行推荐,尤其适用于冷启动场景。
实例说明:
- 模型:
Chat-REC(文献中提及,利用ChatGPT) - 场景:用户说:“我想看一部类似《星际穿越》的科幻电影,最好有时间旅行和哲学思考。”
- 过程:
- 将用户查询和候选电影列表(含标题、简介)构造为自然语言提示(Prompt)。
- 输入给ChatGPT:“基于以下电影简介,哪部最符合用户‘喜欢《星际穿越》风格’的偏好?”
- ChatGPT分析语义相似性,输出推荐结果,如《盗梦空间》。
- 优势:无需训练数据,可解释性强。
- 挑战:计算成本高,可能产生幻觉(hallucination),难以处理大规模候选集。
✅ 文献支持:图4中
Chat-REC位于Q4,使用>100B的LLM(如ChatGPT),击败了MF等传统基线。
象限 Q1:LLM 作为推荐器的增强模块(LLM as Enhancer)
观点:LLM不直接推荐,而是为传统推荐模型提供高质量的语义特征,如用户画像、物品嵌入、上下文表示。
实例说明:
- 模型:
ZESRec(Zero-shot Explainable Recommendation) - 场景:电商平台需要为新上架商品推荐。
- 过程:
- 用LLM分析商品标题和描述,生成“风格:复古”、“材质:棉麻”、“适用场景:通勤”等结构化标签。
- 将这些标签作为物品的语义特征,输入给矩阵分解(MF)或深度模型进行推荐。
- 推荐结果可附带解释:“推荐此商品,因其‘复古风格’与您历史偏好一致。”
- 优势:结合了LLM的语义理解与传统模型的高效推荐能力。
- 挑战:LLM生成的特征可能有噪声,需后处理。
✅ 文献支持:
ZESRec位于Q1,利用LLM生成中间表示,提升传统模型性能。
象限 Q2:利用LLM生成的数据进行训练(LLM as Data Generator)
观点:用LLM生成高质量的合成数据(如用户评论、交互理由、负样本),用于增强传统推荐模型的训练。
实例说明:
- 模型:
MINT(可能指某项利用LLM生成训练数据的工作) - 场景:音乐推荐系统缺乏用户对歌曲的详细反馈。
- 过程:
- 用LLM生成合成用户评论:“这首歌旋律优美,但节奏偏慢,适合下午茶时间。”
- 将这些评论作为辅助信息,训练一个能理解用户情感偏好的推荐模型。
- 模型在真实数据上训练时,能更好地区分“旋律”和“节奏”等细粒度偏好。
- 优势:缓解数据稀疏问题,提升模型泛化能力。
- 挑战:生成数据的质量和真实性难以保证,可能导致模型学到错误模式。
✅ 文献支持:Q2象限强调“LLM生成数据用于训练”,如生成用户行为理由来辅助学习。
象限 Q3:LLM 作为推荐过程的控制器(LLM as Controller)
观点:LLM不生成特征也不直接推荐,而是作为“大脑”调度多个推荐模块,实现复杂决策。
实例说明:
- 模型:
InteRecAgent(Integrated Recommendation Agent) - 场景:智能助手需为用户规划周末活动(电影、餐厅、景点)。
- 过程:
- LLM接收用户请求:“周末想放松,看个电影吃顿好的。”
- LLM调用多个子系统:
- 调用电影推荐API获取候选。
- 调用餐厅推荐API获取附近餐厅。
- 判断时间是否冲突,推荐“先看电影后吃饭”的组合。
- 最终输出一个连贯的行程建议,并解释理由。
- 优势:实现多任务协同、可解释决策、个性化服务。
- 挑战:系统复杂,延迟高,需精确的API设计。
✅ 文献支持:
InteRecAgent位于Q3,LLM作为控制器协调多个推荐组件。
三、总结:本文的核心贡献与价值
| 贡献维度 | 具体内容 |
|---|---|
| 统一框架 | 提出四象限分类法,系统梳理LLM与RS的融合路径,避免研究碎片化。 |
| 技术洞察 | 揭示了LLM在推荐中的角色演变:从“工具”到“核心”再到“大脑”。 |
| 发展轨迹 | 图中箭头暗示研究趋势:从Q4(直接推荐)向Q1/Q3(增强与控制)演进,追求效率与可控性。 |
| 挑战指明 | 强调幻觉、成本、评估难题,为未来研究指明方向。 |
四、未来方向
- 高效微调(如LoRA、Adapter)降低LLM应用成本。
- 多模态LLM:结合图像、音频的LLM用于视频、电商推荐。
- 可信赖推荐:减少幻觉,提升推荐的公平性与可解释性。
- LLM-native RS:设计专为推荐任务优化的轻量级LLM。
结语
这篇综述不仅是对LLM+RS领域的“全景图”,更提出了一个范式级的分类框架。它揭示了LLM正从“辅助工具”转变为推荐系统的“认知核心”。未来,随着LLM能力的提升和成本的降低,我们或将看到以LLM为中心的智能推荐代理(Intelligent Recommendation Agent),真正实现个性化、可解释、多轮交互的推荐体验。