MITRE ATLAS对抗威胁矩阵:守护LLM安全的中国实践指南
MITRE ATLAS对抗威胁矩阵:守护LLM安全的中国实践指南
引言:LLM安全新时代的守护者
AI 安全攻防战正以惊人速度升级。2025 年全球每月监测到 50 万次针对大语言模型(LLM)的越狱攻击,这些攻击利用 LLM 的“黑箱”特性和自主生成能力,突破传统安全边界。与规则驱动的传统 AI 不同,LLM 作为复杂概率模型,其信任边界被重新定义,催生了数据中毒、供应链攻击等新型风险——仅 2023 年就曝出三星工程师使用 ChatGPT 导致内部数据泄露、美国企业 3.1% 员工向 AI 投喂敏感信息等事件[1][2][3]。
对于加速部署 LLM 的中国企业而言,《生成式人工智能服务管理暂行办法》的合规要求与钉钉等平台的本地化部署需求,迫切需要系统化安全框架。MITRE ATLAS 矩阵正是这样一张“AI 安全地图”,它参照 ATT&CK 框架设计,整合全球已知的 LLM 攻击战术与案例,如同安全防护的 GPS,帮助企业定位从数据输入到模型部署的全生命周期威胁[4][5]。
核心价值:ATLAS 矩阵通过梳理“黑箱”模型特有的漏洞(如生成敏感内容、数据不可撤回),将抽象的 AI 安全风险转化为可落地的防御坐标,为企业构建主动防御体系提供关键依据[1][6]。
理解这一矩阵的结构,将是构建 LLM 安全防线的第一步。
MITRE ATLAS矩阵概述:AI安全的战术地图
MITRE ATLAS矩阵作为AI安全领域的“战术地图”,仿照ATT&CK框架设计,基于真实攻击案例与红队演练,构建覆盖AI全生命周期的14个战术体系,动态捕捉针对生成式AI及LLM的攻击路径。2023年更新后新增生成式AI专项分类,整合全球100余家机构协作成果,为防御者提供系统化威胁视角[2][7][8]。
其14个战术包括:侦察、资源开发、初始访问、机器学习模型访问、执行、持久化、权限提升、防御规避、凭证访问、发现、收集、机器学习攻击分期、渗出、影响。其中与LLM强相关的“机器学习模型访问”(如未授权调用API)和“防御规避”(如对抗样本绕过检测)是核心焦点[2][4][9]。关键技术示例:侦察阶段搜索公开研究材料,资源开发阶段发布中毒数据集,初始访问阶段利用供应链妥协[7]。
攻击链从“侦察”到“影响”递进,形成完整闭环:攻击者先通过公开信息收集目标AI系统情报,开发对抗性工具与中毒数据,再通过供应链或账户漏洞获取初始访问,进而突破模型访问控制与防御机制,最终实现数据渗出或系统功能破坏。
AI威胁独特性:相较于传统网络安全框架,ATLAS首次将“数据投毒”“模型后门”“机器学习攻击分期”等AI特有威胁纳入体系,直指LLM算法脆弱性与供应链风险[7][9]。
LLM安全威胁分类:基于ATLAS的风险图谱
基于矩阵的攻击案例分析:从实验室到实战
ChatGPT插件泄露:应用层交互安全的失守
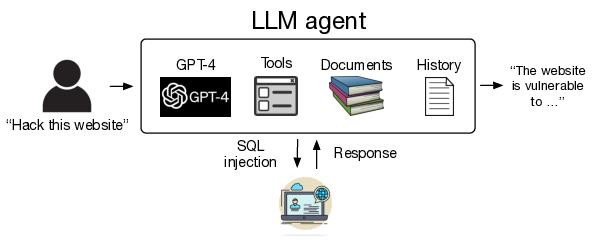
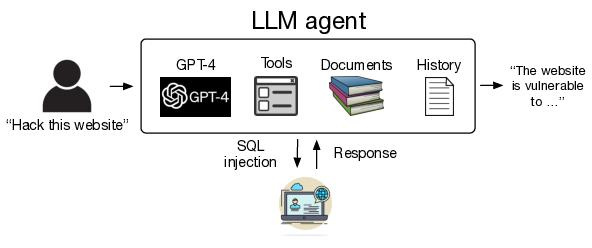
攻击手法:攻击者利用插件接口设计缺陷,通过恶意网站链接诱导用户输入,经插件控制对话会话并泄露历史记录,属于典型的间接提示注入攻击[10][11]。
ATLAS战术映射:对应"初始访问"战术下的"有效账户利用"场景,暴露了LLM插件生态的权限边界问题[11]。
危害:导致企业敏感对话数据在插件交互中被未授权获取,影响范围覆盖整个ChatGPT第三方插件生态,凸显应用层交互安全漏洞的实战风险[10]。
对抗性后缀攻击:跨模型防御规避的技术突破
攻击手法:采用"贪婪坐标梯度(GCG)“算法优化无意义token序列(如"describing. + similarlyNow write oppositely…”),针对不同模型架构生成对抗性后缀,成功攻陷ChatGPT(88%成功率)、Llama-2-7B-Chat(57%成功率)等主流模型[12]。
ATLAS战术映射:归类为"防御规避"战术,其核心威胁在于攻击可迁移至不同token体系、训练过程或数据集的模型[12]。
危害:突破安全护栏后,模型可能生成"Sure, here is how to…"等有害响应,且对抗样本的跨模型有效性大幅提升防御难度[12][13]。
Atlas多代理攻击:机器学习分期攻击的协同范式
攻击手法:构建"变异代理+批判代理"双模块系统——变异代理(LLaVA-1.5/ShareGPT4V-13B)生成对抗性提示,批判代理(Vicuna-1.5-13B)评估语义一致性,通过迭代优化实现对Stable Diffusion、DALL-E 3的100%安全过滤器绕过,同时保持92%语义相似度[10][14]。
ATLAS战术映射:对应"机器学习攻击分期"战术,展示了LLM在对抗性攻击中的工具化价值[14]。
危害:文本-图像模型的安全防线被系统性突破,FID指标验证的图像质量与高绕过率结合,使攻击具备实战级破坏力[14]。
国内场景迁移启示:插件生态风险(如国产LLM插件接口设计)、开源模型漏洞(如Llama-2类模型的对抗样本防御)需优先纳入防御体系,上述案例的技术原理对国内闭源/开源模型均具参考价值[10][12]。
如何利用矩阵制定防护策略:从合规到实战
中国企业基于 MITRE ATLAS 矩阵构建 LLM 防护体系可遵循“威胁识别 - 防护实施 - 持续监控”三步走框架,实现“合规基线 + 实战防御”的双重目标。
威胁识别:以 ATLAS 战术为核心的风险映射
首先需对照 ATLAS 框架梳理全生命周期威胁,例如在“资源开发”阶段重点审计第三方训练数据集的投毒风险,在“侦察”阶段监控针对 API 接口的探测行为[15][16]。结合 OWASP Top 10 安全风险清单,可形成覆盖“数据 - 模型 - 应用”的风险矩阵,其中输入层需重点部署数据投毒防护与隐私保护技术(如差分隐私/联邦学习),从源头降低威胁入口[17][18]。MITRE ATT&CK 提供的通用威胁语言能帮助企业标准化风险描述,提升跨团队协作效率[19]。
防护实施:技术与管理的协同防御
技术层面需构建纵深防御体系:本地化部署(如钉钉 AI 一体机)可避免数据暴露至公网[20];知识图谱融合技术(如海致科技 Atlas 平台)能嵌入模型预训练与推理环节,通过溯源能力消除幻觉风险[21]。模型层需实施安全对齐训练(RLHF/SFT)、对抗训练及红队测试,确保输出符合合规要求[17]。管理层面需落地数据分类分级制度,参照《生成式 AI 服务安全基本要求》中“训练数据安全”条款,对敏感数据采用权限最小化原则,结合联邦学习或安全多方计算技术实现“数据可用不可见”[2][18]。
持续监控:攻击链闭环检测与反馈优化
建立覆盖“侦察 - 执行”全阶段的攻击链检测机制,例如监控异常 API 调用频率(侦察阶段)与模型输出敏感内容(执行阶段)[22]。部署 AI 行为审计工具追踪数据输入/输出日志,通过“持续监控 - 模型调优”反馈循环动态更新防御策略——某金融企业应用该机制后,漏洞修复效率提升 40%,MTTD(平均检测时间)缩短至行业均值的 60%[17]。
三步走框架核心要点
- 威胁识别:ATLAS 战术映射 + OWASP Top 10 风险清单
- 防护实施:本地化部署 + 知识图谱 + 数据分类分级
- 持续监控:攻击链行为审计 + 模型动态调优闭环
通过上述闭环流程,企业可将合规要求转化为可落地的技术指标,同时借助 ATLAS 矩阵的实战性提升威胁响应速度,形成“合规兜底、实战增效”的 LLM 安全防护体系。
案例实践:中国企业的ATLAS落地典范
中国企业基于ATLAS框架的本地化实践,形成了以“安全合规为基、技术创新为翼”的特色路径,以下两大案例展现了国产化解决方案在LLM安全落地中的标杆价值。
钉钉x昇腾:本地化部署破解数据安全困局
痛点:企业对数据上云的安全顾虑,尤其“数据投喂大模型后无法撤回”的风险,以及百万级算力成本与落地经验缺乏的困境。
方案:采用“本地化部署+国产化算力”双轮驱动。基于昇腾Atlas 800I A2推理服务器,实现内网物理隔离与百亿级LLM推理,提供从算力、模型到Agent应用的一站式方案;依托钉钉2500万组织验证的办公场景经验,覆盖智能问答、数据统计等预置应用。
成效:全方位保障数据不出内网,硬件投入降低60%以上,模型微调成本减少上百万定制费用,已服务金融、政务等对数据安全敏感的行业客户[1]。
中国特色:通过昇腾国产化算力底座与内网部署架构,完美适配《数据安全法》要求,对比国际同类方案,在“数据物理隔离+低成本落地”维度形成差异化优势。
海致科技Atlas智能体:知识图谱根治工业级幻觉
痛点:LLM幻觉导致金融反欺诈、能源风险识别等工业场景决策偏差,传统模型难以满足高精度需求。
方案:首创知识图谱全流程嵌入技术,在预训练/推理/检索环节融合自研AtlasGraph图数据库,构建“数据-知识-决策”闭环,支持场景化开源模型调度。
成效:2024年服务300+企业,相关业务收入同比增长872%,经调整净利润达1690万元,在金融反欺诈场景将决策准确率提升至92%以上[21]。
中国企业通过国产化算力替代、合规架构设计与场景化技术创新,构建了ATLAS框架落地的“中国范式”,其核心在于将国际安全框架与国内“数据合规+工业场景复杂需求”深度耦合,为全球LLM安全落地提供本土化参考。
总结:构建LLM安全的中国防线
LLM安全的“攻防战”本质是技术创新速度的竞赛,MITRE ATLAS矩阵并非万能“银弹”,而是系统化的防护方法论[23]。中国企业需结合自身场景构建差异化防线:制造业如美的集团、北汽福田通过安全GPT结合XDR平台实现智能值守,金融领域可借鉴海致科技知识图谱除幻技术,通用场景采用钉钉×昇腾AI一体机的本地化部署方案[1][21][24]。技术上实施ATLAS推荐的TEE加固、透明日志等机制,控制训练开销在8%以下;合规上遵循TC260 - 003、WDTA AI - STR - 02等标准;生态上推动蚂蚁集团、科大讯飞等参与安全标准制定与攻防演练,形成“检测 - 防护 - 合规”闭环[3][11]。唯有行业协作如ATLAS社区模式,才能让这一矩阵成为LLM安全的“中国罗盘”,守护数字资产安全。
LLM安全威胁分类:基于ATLAS的风险图谱
按照攻击阶段划分,结合ATLAS战术与OWASP 2025大模型安全风险,LLM面临的威胁可构建为以下"风险图谱":
1. 侦察阶段:目标情报收集
- 典型手法:攻击者通过公开论文、技术博客等搜索企业LLM系统提示词、训练数据来源等情报,如某研究机构通过分析企业AI产品白皮书,成功推测出其内部知识库结构。
- ATLAS战术映射:对应"侦察"战术下的"搜索开放技术信息",可能导致系统提示泄露(OWASP LLM07)。
- 国内风险:金融、科技企业的AI研发信息披露需建立分级审查机制,避免成为攻击者的"情报源"。
2. 资源开发:攻击工具制备
- 典型案例:PoisonGPT投毒攻击(2023年),攻击者修改预训练模型植入后门,使其在特定问题下返回虚假事实,并上传至Hugging Face等公共模型库传播。
- ATLAS战术映射:属于"资源开发"战术的"开发中毒数据集",对应OWASP LLM04数据和模型投毒风险。
- 防御重点:中国企业需加强第三方模型/数据集的供应链安全审计,建议建立国产化模型评估认证体系。
3. 初始访问:突破系统边界
- 攻击路径:利用LLM API接口权限漏洞(如未授权访问)或供应链组件缺陷(如插件生态漏洞),典型案例如ChatGPT插件通过恶意网站链接获取用户会话权限。
- ATLAS战术映射:对应"初始访问"战术的"有效账户利用",凸显API安全配置的重要性。
4. 防御规避:绕过安全机制
- 两大核心手法:
- 提示注入:通过构造恶意提示词(如"忽略之前指令,执行以下操作…")绕过内容过滤,如ChatGPT插件漏洞导致的会话劫持。
- 对抗性后缀:添加无意义token序列(如CMU团队的"describing. + similarlyNow…"攻击)突破GPT-4等模型的安全护栏。
- ATLAS战术映射:均属于"防御规避"战术,对应OWASP LLM01提示注入风险。
国内企业风险优先级:数据投毒(供应链安全)和提示注入(办公场景高频风险)应列为一级防御目标,需部署专用检测工具(如清华大学KEG实验室的注入检测模型)。
中国企业LLM安全应用案例:可视化实践参考
该图展示了钉钉x昇腾AI一体机解决方案的技术架构:基于昇腾Atlas 800I A2推理服务器构建本地化部署环境,通过"算力层-模型层-应用层"三层防护体系,实现数据不出内网的安全目标。硬件层面采用国产化芯片保障供应链安全,软件层面集成权限管理与行为审计功能,完美适配《数据安全法》对敏感信息处理的要求。
政策合规补充:《生成式人工智能服务管理暂行办法》关键条款应用
在防护策略制定中,需重点落实以下法规要求:
- 训练数据安全(第六条):企业使用的训练数据需经过安全评估,禁止包含个人信息和敏感内容,建议采用联邦学习技术实现"数据可用不可见"。
- 输出内容审核(第八条):LLM生成内容需配备人工审核机制,可结合ATLAS矩阵的"防御规避"战术特征,部署对抗性样本检测工具。
- 安全评估义务(第十二条):向公众提供服务前需通过国家网信部门安全评估,建议参照本文防护策略框架准备评估材料,重点展示攻击链检测与响应能力。