AI热点周报(09.14~09.20):Gemini集成到Chrome、Claude 强化记忆、Qwen3-Next快速落地,AI走向集成化,工程化?
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、开场与 TL;DR(3分钟看完要点)
- 二、重点事件解读(把复杂概念讲清楚)
- 1. Qwen3-Next:我选择“激活”少参数
- 2. Gemini 入 Chrome:浏览器变身“AI 操作台”
- 3. Anthropic 的记忆与可用性事件:连续性 vs 可控性
- 三、案例分析:把“论文/公告”变成“工程/产品能用的事例”
- 案例 A — 把 `Qwen3-Next-80B-A3B` 用到客服多轮理解(简化流程)
- 案例 B — 在浏览器中用 Gemini 自动化信息整理(产品原型)
- 四、总结
- 参考(部分权威来源)
很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI知识图谱》,内容持续更新中…
大家好,我是流苏👋,今天我们一起了解一下本周的一些AI热点。
- 如果你想看简单版,下面笔者整理了3分钟速览版,请看下方
一、开场与 TL;DR(3分钟看完要点)
欢迎来到本周的 AI 大模型周报。本周(2025-09-14 至 09-20)中美两边的两类动作最值得关注:
- Google 把 Gemini 深度集成到 Chrome(先在美版桌面放开),把大模型能力直接带入浏览器,可跨标签页读取与执行多步任务——这是消费端体验向“系统级 AI 助手”迈出的重要一步。(blog.google)
- Anthropic(Claude)为 Team/Enterprise 推出“记忆”功能,并向全体用户提供“隐身(Incognito)”模式,同时本周也有若干短时服务中断与事后回溯说明。企业用户要权衡“连续性”与“隐私/合规”。(Anthropic)
- 阿里 Qwen3-Next 的工程适配进入实操期:官方发布
Qwen3-Next-80B-A3B变体并对外提供说明,生态(HuggingFace/ModelScope、SDK/推理示例)逐步出现,说明从“论文/宣发”往“工程可跑”迈进。(qwen.ai) - 国内图像模型也有动作:腾讯 HunyuanImage-2.1 开源与推理优化、字节 Seedream 4.0 在图像生成/编辑速度与质量上继续迭代。(GitHub)
- 学术与工程层面,“为什么模型会幻觉(hallucinate)” 的研究继续被重视,建议从训练/评估激励层面做调整以减少“自信的错误”。(arXiv)
| 模型 / 事件 | 团队 | 时间 | 主要更新点(简要) | 参考 |
|---|---|---|---|---|
| Qwen3-Next-80B-A3B | 阿里 Qwen / 通义 | 9月中旬 | 80B 总参数,稀疏激活仅 ~3B/step,面向长上下文与低成本推理,已在 HuggingFace/ModelScope 放出资料与示例。 | (qwen.ai) |
| HunyuanImage-2.1 | 腾讯混元 | 9/8—9/18(发布/更新) | 开源推理代码、FP8 量化、2K 输出在 24GB 显存可跑的优化与 workflow(ComfyUI 等示例)。 | (GitHub) |
| Seedream 4.0 | 字节跳动(Seedream) | 9月初至中旬 | 图像生成/编辑体验与多图一致性提升、速度与批处理能力优化。 | (Flux AI) |
| Gemini → Chrome(集成) | 9/18 起公布/推送 | 把 Gemini 嵌入 Chrome,支持跨标签页理解、摘要、任务自动化(多步 agent),首批先在美版桌面上线。 | (blog.google) | |
| Claude Memory / Incognito | Anthropic | 9/11 起 rolling | 为 Team/Enterprise 推出持久记忆(可管理/关闭),对所有用户上线 Incognito(不记入记忆);同时有短时服务中断记录与后续技术说明。 | (Anthropic) |
| 幻觉研究 | OpenAI / 学术圈 | 9月初论文与解读 | 指出训练/评估机制会“奖励猜测”,导致模型更倾向于给出确定性(甚至错误)答案,建议调整评估逻辑。 | (arXiv) |
小注:上表中时间与细节以各方官方博文与主流媒体报道为准(参考列表见文末)。
二、重点事件解读(把复杂概念讲清楚)
1. Qwen3-Next:我选择“激活”少参数
核心要点:Qwen3-Next 系列(例如 Qwen3-Next-80B-A3B)表述为“总体参数规模大(80B)但稀疏激活时只用 ~3B”。通俗地说,这像把一个大型工具箱按需只打开一小格来用:训练或推理时并不总把所有参数都唤醒,从而大幅降低计算与成本,同时保留大模型的能力边界。

类比到工程上,这类稀疏 MoE / 门控注意力思想就是把“性能”与“成本”做更优的折中。(qwen.ai)
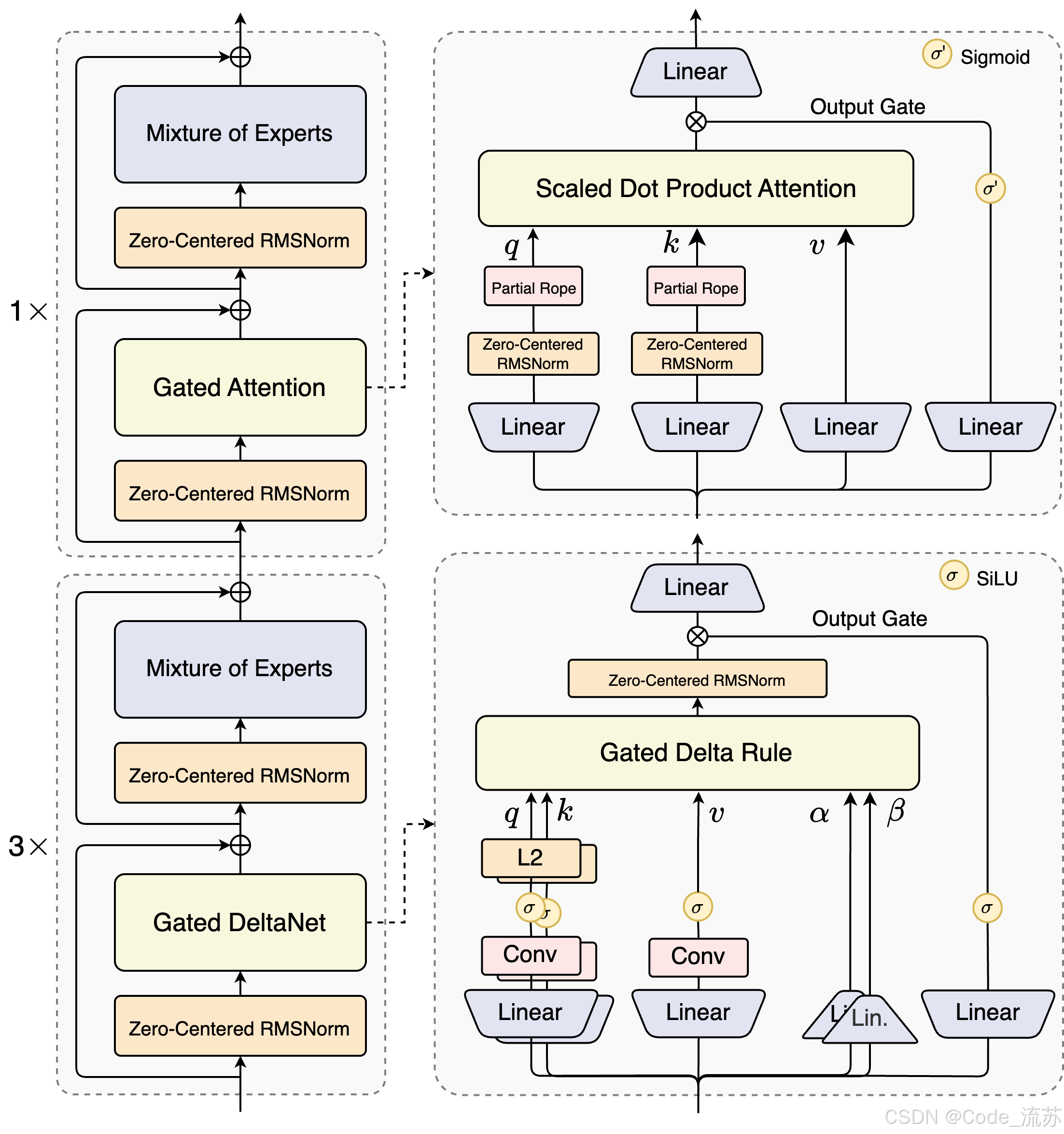
为什么工程师要关心:
- 成本/部署选择:稀疏激活意味着在相同预算下可支持更长上下文或更高并发。
- 兼容性问题:实际落地需要看推理框架(如
vLLM、NVIDIA runtime、ModelScope 插件)是否支持稀疏调度与量化优化。(reworked.co)
2. Gemini 入 Chrome:浏览器变身“AI 操作台”
发生了什么:Google 将 Gemini 深度植入 Chrome,用户可以在浏览器内请求摘要、跨页搜索、甚至让 AI 帮忙执行“多步任务”例如根据邮件自动下单或变更日程。

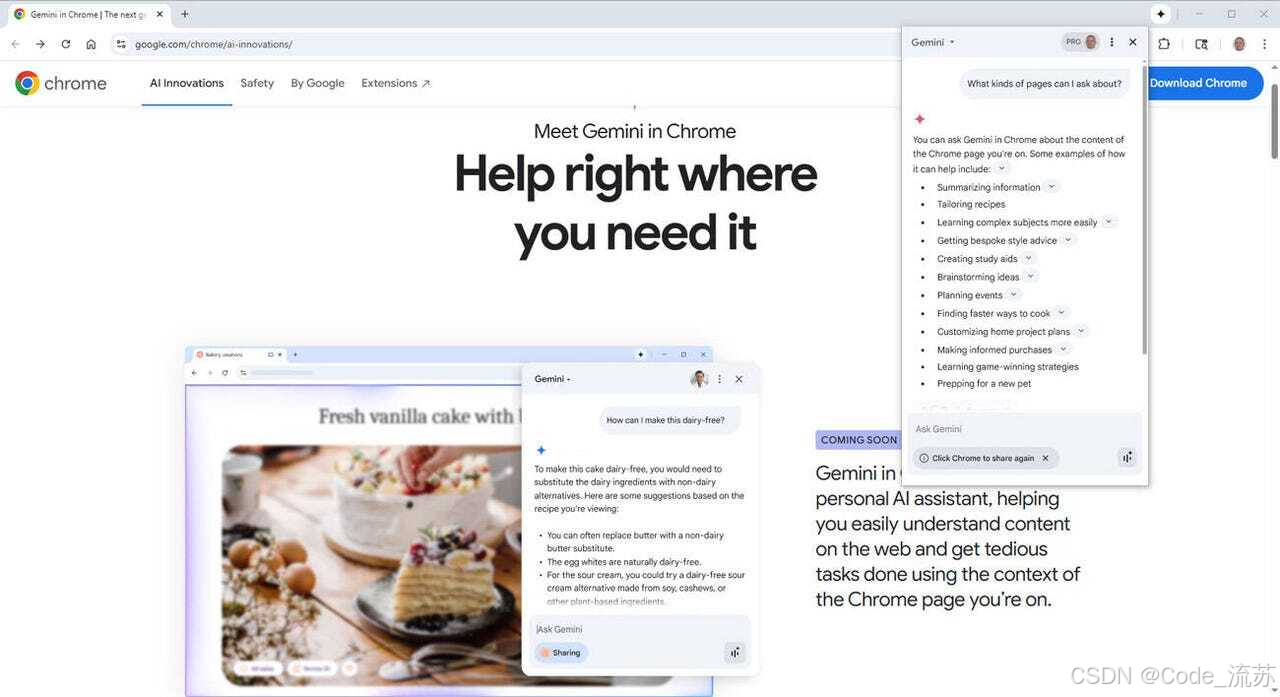
把模型放入浏览器,体验从“打开一个聊天窗口问问题”变为“浏览器直接辅助决策和操作”。(blog.google)
风险与挑战:
- 权限与隐私管理:浏览器读取标签页/历史的能力需要细粒度授权与审计。
- 安全边界:自动化执行(下单、修改日历)需有明确的回退与人为确认点。
3. Anthropic 的记忆与可用性事件:连续性 vs 可控性
Anthropic 上周五发布,本周陆续将把“记忆(Memory)”功能推给付费团队,使 Claude 能长期记住团队偏好或项目上下文;同时给全体用户提供“Incognito”私密选项。别忘了:本周也发生了短时服务中断并有技术性事后报告,提醒企业在用第三方大模型时要做容灾与降级方案。(Anthropic)

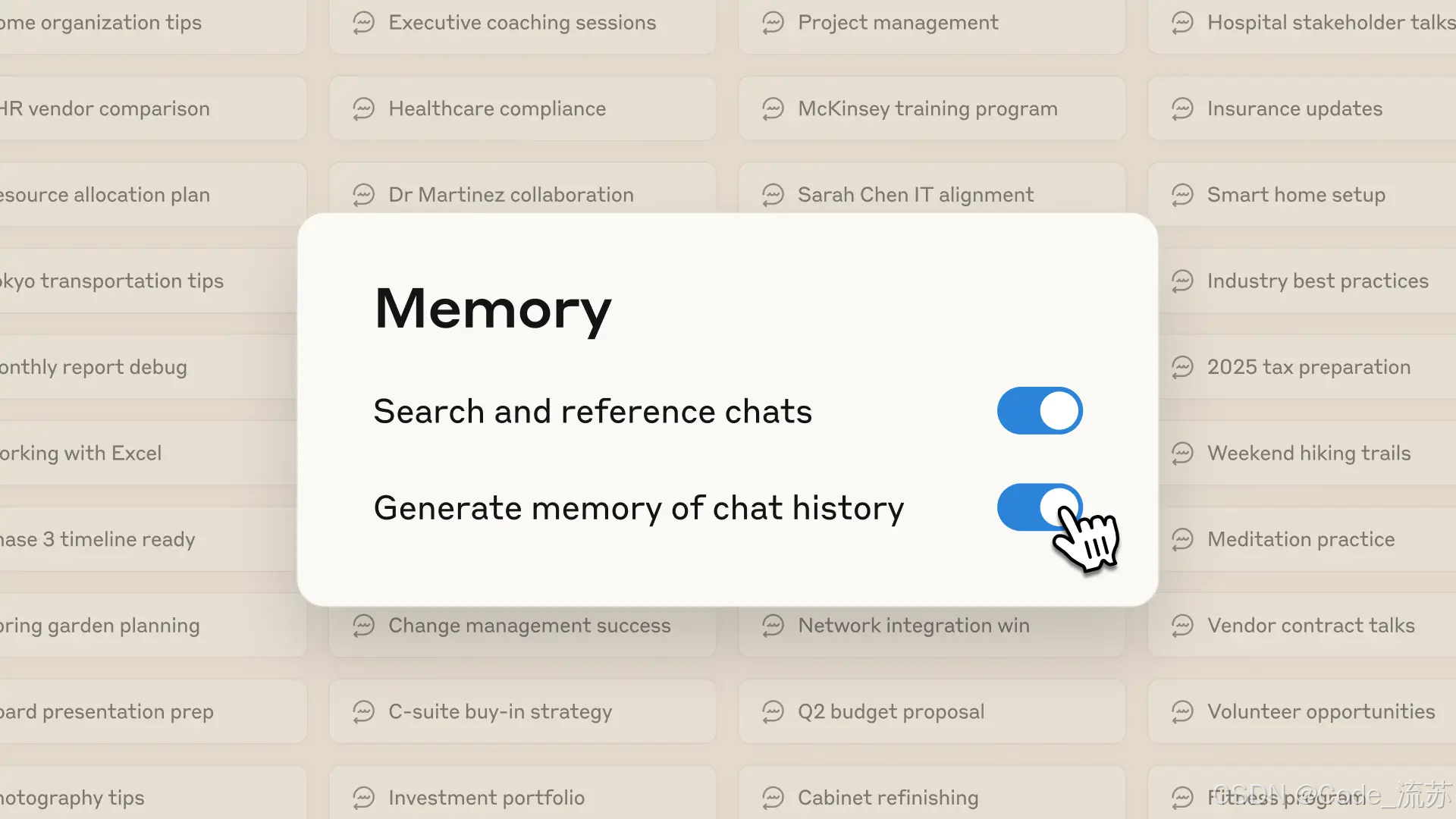
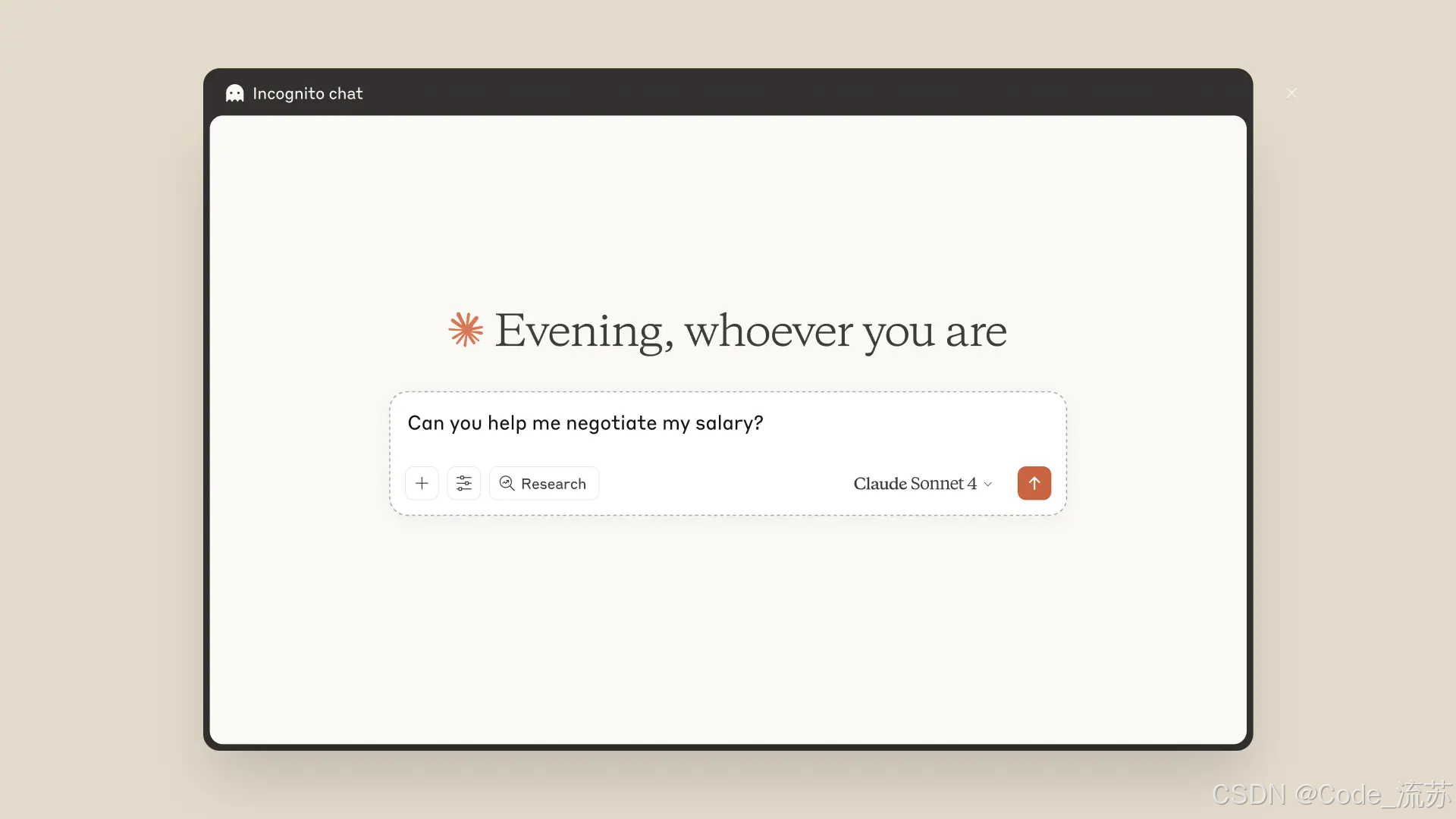
三、案例分析:把“论文/公告”变成“工程/产品能用的事例”
案例 A — 把 Qwen3-Next-80B-A3B 用到客服多轮理解(简化流程)
场景:一个电商平台需要在用户历史对话 + 50K token 的产品/物流上下文里完成一段复杂的退换流程判断。
做法建议:
- 在本地做小样本评测,比较
Qwen3-Next的 长上下文吞吐 与其他基线模型(记录 latency/throughput)。 - 用稀疏激活时的成本模型(spot GPU 定价)估算每千万 token 的推理成本。
- 把核心知识放在 RAG(检索增强生成)层,避免把所有事实都丢给模型“记住”,以减少幻觉。
为何可行:Qwen3-Next 的设计目标就是在长上下文场景里用更少资源完成更高效的推理。(qwen.ai)
案例 B — 在浏览器中用 Gemini 自动化信息整理(产品原型)
场景:内容运营想要在周报中收集 10 个热门网页的要点并生成摘要。
产品思路:Chrome 插件调用本地/云端 Gemini,自动打开 10 个标签页抓取内容、去重、按主题聚类并输出一份可编辑草稿(用户最后确认后发送邮件)。注意点:权限提示、操作回退、数据留存策略。(blog.google)
四、总结
本周可用一句话概括为 “从能力展示走向工程落地”。
Google 把 Gemini 推到浏览器端、Anthropic 推出记忆与隐身以支持团队/个人不同诉求、阿里 Qwen3-Next 在生态中开始跑通实例,国内图像模型(腾讯/字节)也在性能/易用性上快速迭代。
但同时 幻觉、可用性与合规 依旧是阻碍大规模产品化的三大问题。
参考(部分权威来源)
- Qwen 官方博客:Qwen3-Next 发布说明。(qwen.ai)
- Alibaba / Qwen 官方 X 帖子(模型简介)。(X (formerly Twitter))
- Google Chrome 新 AI 功能公告(官方博客)。(blog.google)
- Reuters / Wired 关于 Gemini 入 Chrome 的报道。(Reuters)
- Anthropic 官方公告:Claude memory。(Anthropic)
- Anthropic 事故回顾与状态页。(Anthropic)
- OpenAI / arXiv:Why Language Models Hallucinate(研究与解读)。(arXiv)
- 腾讯 HunyuanImage-2.1(GitHub / HuggingFace space)。(GitHub)
- Seedream 4.0(产品说明与 demo)。(Flux AI)
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)