Science Robotics最新研究:腿足机器人控制的革新性进展
导读
想象一下,如果机器人能像人类一样在复杂的地形中自由穿行——跨越岩石、跳跃障碍、走过陡坡,这将为它们的应用带来无限可能。从灾后救援到环境勘探,腿足机器人已经展现出其无可比拟的优势。但是,现实中,这种高难度的运动却并不像我们想象的那么简单。
特别是在那些没有稳定支撑点的地形上,机器人如何精准地规划每一步、保持平稳的行进,仍然是一个亟待解决的难题。现有的技术虽然在某些环境下表现不错,但通常要么缺乏足够的精度,要么无法应对环境的不确定性。为了让机器人能够在不确定的复杂环境中稳定、高效地行走,我们需要一种全新的方法。
本文提出了一种创新的控制框架,通过结合强化学习和多头注意力机制(MHA),让机器人能够在不同的地形上做出精准的步伐规划,同时也具备了强大的鲁棒性和适应性。

那么,这项技术是如何实现这些突破的呢?本文的创新之处在于引入了基于多头注意力的地图编码方法。通过将机器人本体觉感知数据与外部地形数据结合,利用MHA模块,机器人能够根据当前的状态和环境,精确预测未来的支撑点。这一方法的最大亮点在于,它不仅仅依赖于传统的感知数据,还能根据机器人实时的运动状态动态调整对地形的关注,从而提高了机器人对复杂地形的适应性。
通过这种创新的控制框架,本文展示了如何解决腿足机器人在复杂地形中面临的精准性与鲁棒性的双重挑战。接下来,我们将详细解读这一方法的实现过程,首先介绍如何通过CNN与MHA的结合来精确预测支撑点,随后分析强化学习如何帮助机器人在复杂环境中进行自我调整。最后,我们还将探讨实验部分,展示该方法在实际应用中的表现,以及其在不同地形上的实际效果

▲图1|该控制器使得足腿式机器人能够在各种具有挑战性的地形上动态行走。高度可解释的逐点地图编码显示了更高的注意力权重,红色越浓表示下一个脚步点的位置

研究框架与控制策略
本文的核心创新是提出了一种结合多头注意力机制(MHA)和强化学习的腿足机器人控制框架,旨在解决机器人在复杂地形中精准导航的问题。为什么要使用这种方法呢?传统的控制方法——无论是基于模型的还是学习型的,都有各自的优缺点。基于模型的方法虽然能提供精确的控制,但往往缺乏应对动态环境变化的灵活性;而基于学习的方法则在应对不确定性方面有优势,但在精确控制和泛化能力上有所欠缺。为了弥补这些不足,本文提出的控制框架,通过注意力机制结合强化学习,不仅能预测精确的支撑点,还能适应不同地形的变化。
框架的核心部分是一个由CNN和MHA组成的双层网络结构。CNN负责从机器人所看到的地形中提取局部特征,而MHA模块则通过“关注”最关键的特征来帮助机器人做出精准的运动决策。MHA是一种能使模型动态聚焦关键输入数据的技术,使得机器人能够根据当前的本体觉感知数据,调整对不同地形的关注度,进而有效预测未来的支撑点。这种动态关注的能力,使得机器人在面对不同类型地形时,能够更灵活地调整步伐,保证行走的稳定性和精度。
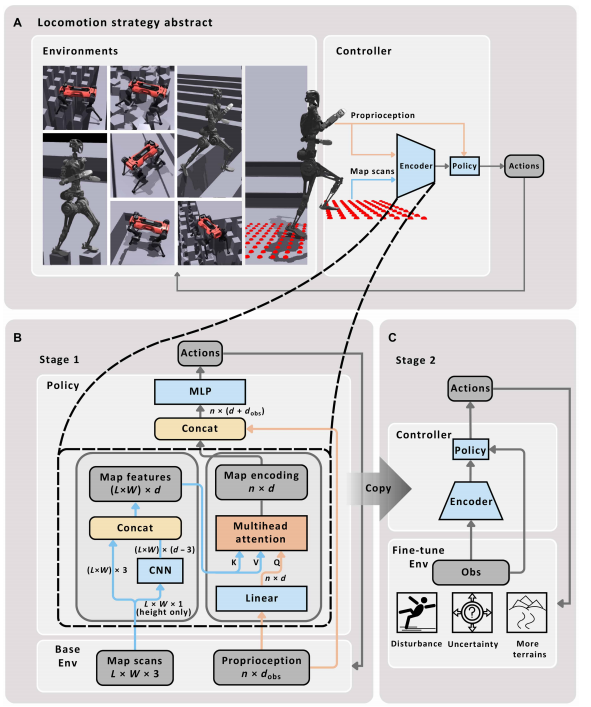
▲图2|全文方法总览
多头注意力机制(MHA)
说到MHA,我们不妨先简单解释一下它是什么。MHA是一种深度学习技术,能够在输入信息中找到最重要的部分,并通过多个“头”来处理这些信息。每个头都能从不同的角度来看待数据,然后把这些信息整合起来,形成更为丰富的表征。在腿足机器人控制中,MHA的作用就是让机器人能够“专注”于那些最重要的地形特征,从而提高导航的精确度。
例如,假设机器人在一个崎岖的地形中行走,MHA可以根据当前的状态(如机器人的速度、角度等),动态调整对地形的关注点。它会将更多的注意力集中在那些适合机器人行走的支撑点上,而对其他不重要的区域则给予较少的关注。这个过程完全是通过机器人的本体觉感知数据来引导的,从而确保机器人能够在复杂地形中稳定地行走。

▲图3|注意力可视化。该方法通过将每个扫描的注意力权重与高度扫描进行可视化,其中更强的红色表示更高的注意力。该图表示对第一阶段控制器在单一基础地形上的注意力权重,涵盖前进、侧向和转向速度指令。
CNN与MHA的结合
为了让MHA能够真正发挥作用,论文首先通过卷积神经网络(CNN)提取地形的局部特征。这些局部特征包括地面各个点的高度值(z值),是机器人在行走过程中非常重要的参考信息。CNN通过两层卷积操作,提取每个地形点周围的局部特征,然后将这些特征传递给MHA模块。MHA模块利用这些局部特征,结合机器人当前的本体觉感知数据,生成最终的地图编码。
简单来说,CNN负责从地形图中“扫描”出有用的信息,而MHA则帮助机器人在这些信息中找出最重要的部分,像是一个指挥官,告诉机器人下一步应该把注意力集中在哪里。这样的结合使得机器人不仅能够处理静态的地形数据,还能根据自己的状态灵活调整,适应不同的环境。
两阶段训练流程
本文还设计了一个两阶段的训练流程,来帮助机器人更好地应对不同的地形挑战。在第一阶段,机器人在理想的环境下进行训练,获得精准的感知数据并学习基本的运动技能。这一阶段的训练目标是让机器人熟悉如何在简单地形中行走,比如平坦的地面或简单的坡度。

▲图4|在训练过程中机器人的地形从简单的平地,楼梯逐步过渡到有挑战性的梅花桩,碎石路下坡等
而到了第二阶段,训练变得更具挑战性。此时,机器人开始面对更加复杂的地形,其中包括感知噪声和不确定性的扰动,模拟了真实世界中的各种环境变化。这一阶段的目的是让机器人不仅能够应对理想的环境,还能在面对传感器误差、环境变化等实际问题时,依然能够稳定、高效地行走。
通过这样的两阶段训练,机器人学会了如何在理想环境中精确行走,并且具备了在复杂、真实环境下应对不确定性的能力。训练过程中,机器人逐渐适应了从理想环境到现实环境的过渡,确保了控制器的强大泛化能力。
强化学习与奖励机制
为了引导机器人进行有效的学习,本文设计了一个复杂的奖励机制。强化学习中,奖励信号是训练的关键,它决定了机器人会朝着哪个方向优化自己的行为。具体来说,本文的奖励分为三大类:任务奖励、正则化奖励和风格奖励。
● 任务奖励:主要确保机器人能够完成预定的任务,比如准确跟随命令保持运动,并避免在复杂地形上失败。
● 正则化奖励:用于避免机器人的运动过于激烈,避免出现过度扭矩或关节过度伸展等情况。
● 风格奖励:鼓励机器人做出更自然的动作,避免脚步滑动、倾斜等不自然的步态。
这些奖励的设计不仅帮助机器人在训练中形成合适的运动习惯,还让机器人在实际应用中能够做出更平滑、自然的动作。
训练环境与数据增强
为了确保控制器在复杂环境中具有强大的鲁棒性,论文采用了广泛的领域随机化技术。通过向感知数据中加入噪声,模拟真实环境中的不确定性,训练中的扰动和不完美感知得以反映在实际训练中。这不仅增强了机器人的适应能力,也确保了训练结果的现实意义。

在实验中,作者测试了所提出的控制器在GR-1和ANYmal-D两款机器人上的表现。通过模拟和真实环境中的广泛测试,验证了该方法在不同地形下的适应性和精准度,尤其是在训练阶段未曾遇见的全新地形上。
训练与测试:广泛的地形适应能力
实验首先展示了控制器在GR-1机器人上的表现,尽管该控制器仅在基础地形上训练,但它在未见过的地形上也展现了优秀的泛化能力。
● 实验结果:
○ 训练地形:包括栅格石、托盘、梁等(如下图A)。
○ 测试地形:包括五边形石、单柱石、狭窄托盘、连续间隙等(如下图B所示)。
○ 控制器成功适应了这些新地形,验证了其在训练外地形上的广泛适应性。
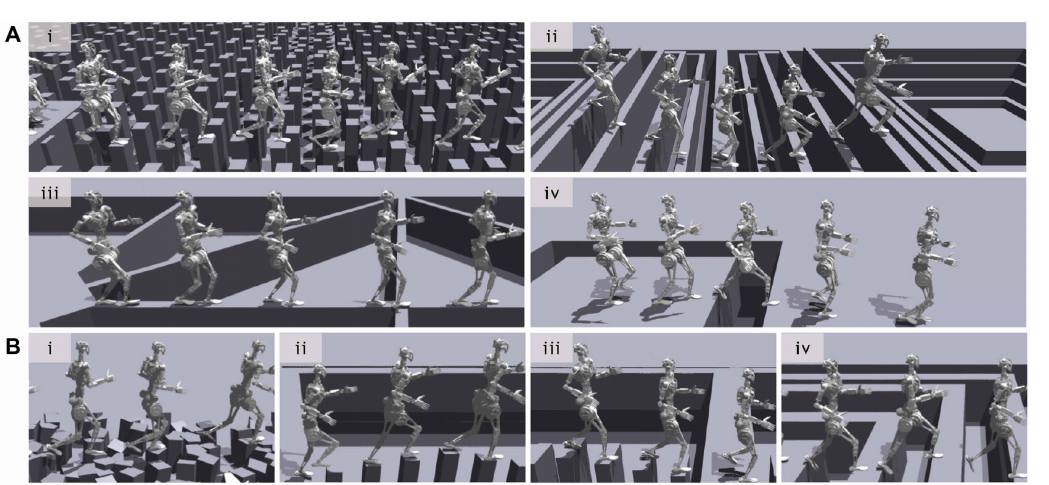
▲图5|机器人多地形行走适应力实验图示
同样,ANYmal-D控制器也表现出了类似的泛化能力。尽管其运动学与GR-1不同,训练时的地形选择有所调整,但它在面对新地形时依然表现优秀。
● 实验结果:
○ 训练地形:基础地形(如下图E所示)。
○ 测试地形:如下图D所示的未知地形。
○ 该控制器能够有效适应新地形,展示了所提方法的跨机器人适应能力。
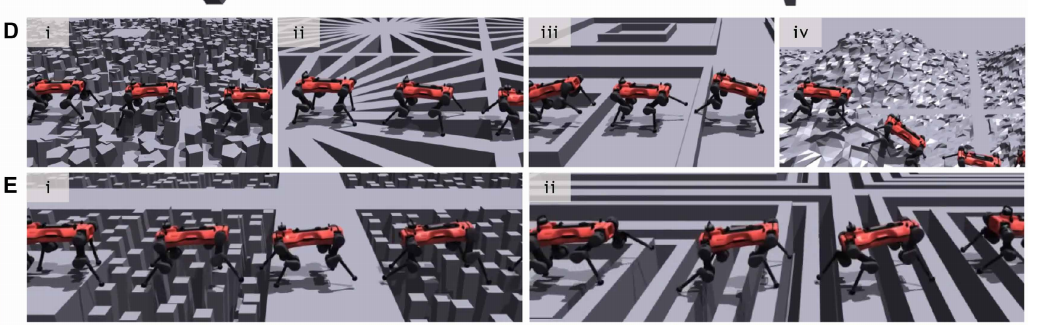
▲图6|ANYmal-D在不同地形行走可视化
强化现实世界的适应性:扰动与不确定性的考验
为了进一步提高控制器的精确性与现实世界适应性,作者在第二阶段对控制器进行了微调,加入了更多复杂的地形和扰动因素,模拟了现实环境中的不确定性。
● 实验结果:
○ 实验环境:挑战性的障碍跑酷赛道,包含干扰和不确定性。
○ 结果:GR-1和ANYmal-D在这些复杂地形上表现出100%的成功率,证明了该控制器在现实环境中的稳定性和适应能力。

▲图7|通过对控制器的微调,加入更多地形和扰动,最终机器人能够在真实世界中健步如飞的应对各种有挑战性的地形
敏捷性与恢复反应:全身协调带来的灵活性
控制器在真实机器人上的敏捷性和恢复能力也得到了验证。通过全身运动控制,ANYmal-D和GR-1能够有效使用膝关节和手臂提高灵活性,在不稳定地形中快速恢复。
● 实验结果:
○ 敏捷性:GR-1和ANYmal-D能够在不同地形上实现敏捷的运动,使用膝关节和手臂提升灵活性(如下图A和图C所示)。
○ 恢复能力:在滑倒或支撑不稳定时,机器人能够主动进行恢复,保持行进稳定(如下图B和图E所示)。
这些自我恢复行为是传统基于模型的控制方法难以实现的,因为它们通常依赖于固定的接触状态机和人工规则。通过强化学习,控制器能够自主学习并执行复杂的恢复动作,从而提升机器人在复杂地形中的稳定性。

▲图8|通过全身协调实现的灵活性和恢复反射。(A) ANYmal-D使用膝盖爬上大岩石,同时旋转躯干。(B) ANYmal-D通过膝部支撑从不稳定的碎石中恢复,克服了因滑动而导致的脚部陷入问题。(C) GR-1通过一排19厘米宽的不平整踏脚石,利用自然摆臂帮助灵活运动。(D) GR-1在一个不稳定的19厘米宽平衡梁上稳定自身。(E) GR-1在通过一排不平整踏脚石时发生滑动,并迅速通过向前踏步做出反应。(F) GR-1在穿越一排不平整踏脚石时由于左侧偏向速度指令导致遇到不合适的落脚点。由于右脚落地后左脚没有足够的空间着陆,GR-1在空中交换了支撑脚,成功用右脚踩到下一个石块形
控制精度与速度追踪:不同速度下的灵活应对
机器人不仅能够精确预测支撑点,还能灵活地跟踪不同速度命令,在复杂地形上表现出高度的适应性。
● 实验结果:
○ ANYmal-D:成功应对了稀疏地形中可移动支撑物,展示了全方位的运动适应能力(如下图A所示)。
○ GR-1:能够在不平整的步伐、摇晃的平衡梁等地形上调整步态和动作,展现出其多样化的运动能力(如下图B和下图C所示)。
这种速度适应能力极大地扩展了机器人在复杂环境和狭小空间中的操作范围。

▲图9|多功能的速度跟踪。本文提出的学习型控制器在ANYmal-D和GR-1上展示了多功能的速度跟踪能力。(A) ANYmal-D在碎石上操控,克服了具有可移动支撑的稀疏地形,展示了全向的灵活性。(B) 当速度指令从0.7 m/s变为1.5 m/s时,GR-1在不稳定的平衡梁上加速,迈出了更长的步伐。(C) 在1.5 m/s的前进速度指令下,GR-1每踩一个踏脚石迈出一步。(D) 在0.7 m/s的前进速度指令下,GR-1每个踏脚石上踩两步
模拟与对比:与其他方法的比较
为了验证所提方法的优势,作者与DTC(Deep Tracking Control)和基线RL控制器进行了对比,重点评估了它们在稀疏地形上的表现。通过速度追踪性能、成功率和失败率的比较,结果表明,所提方法在多个地形中表现出了更低的追踪误差和更高的成功率。
● 实验结果:
○ 速度追踪误差:所提方法在大多数地形中表现出明显更低的追踪误差,尤其是在速度较高时(如图6A(i)所示)。
○ 成功率:所提方法在训练地形上的成功率比DTC和基线RL高出26.5%和77.3%(如图6A(ii)所示)。
○ 泛化能力:所提方法在未见过的地形上成功执行任务,而基线RL则在这些地形上失败(如图6A(iii)所示)。
这些结果表明,所提方法不仅在已知地形上表现出色,还能有效应对新地形,具有更强的泛化能力。
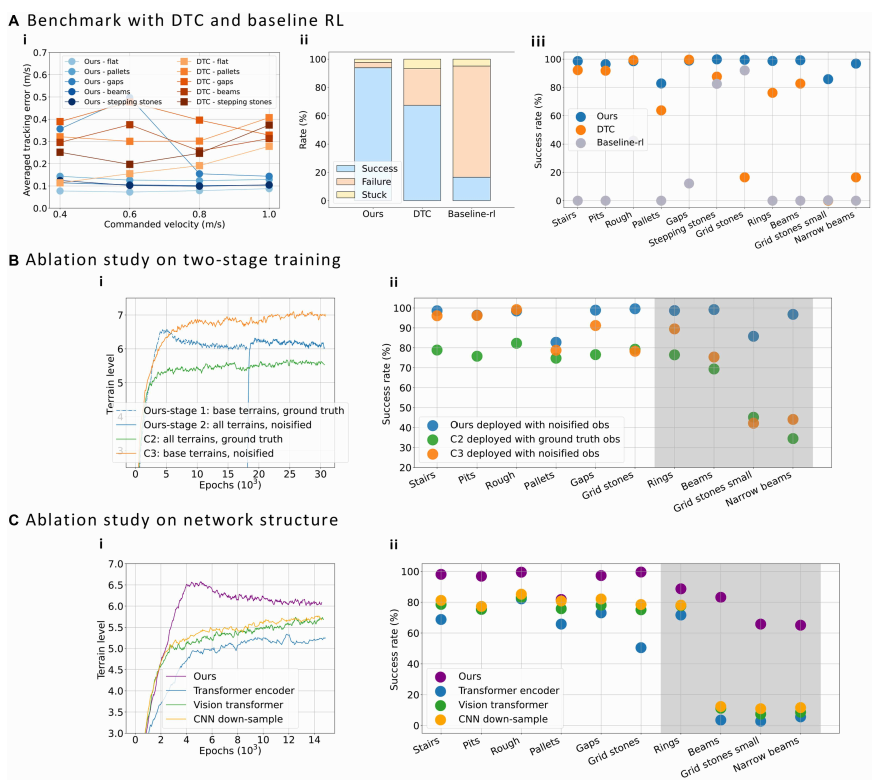
▲图10|基于仿真的评估。该方法仅在ANYmal-D上进行评估,并与其他方法进行了基准对比。(A) 与DTC和baseline-rl的基准对比。(i) 该方法在不同前进速度指令下,在选定地形上显示了总体较低的速度跟踪误差。(ii) 该方法在所有训练地形的组合上表现出显著更高的成功率,且卡住和失败率更低(“成功”指机器人能够在完整的实验过程中走出地形边界,“失败”指发生了不良接触,“卡住”则表示其他情况)。(iii) 该方法在各个地形上展示了更高的总体成功率。(B) 两阶段训练的消融研究。(i) 针对提出的两阶段训练(该方案)、从零开始在所有地形(基础+微调地形)上使用真实观测(C2)以及从零开始在基础地形上进行感知漂移和噪声训练(C3)的地形级训练曲线。该方案显示了最佳的收敛行为。(ii) 该方法在各个地形上显示出更高的总体成功率,其中白色背景表示基础地形,灰色背景表示微调地形。(C) 网络结构的消融研究。(i) 在基础地形上的不同方法的地形级训练曲线。该方案显示了最佳的收敛行为。(ii) 该方法在各个地形上展示了更高的总体成功率
训练过程与架构选择:双阶段训练的优势
消融实验进一步验证了双阶段训练的有效性。通过比较三种不同的训练方式,结果显示,采用双阶段训练的控制器能够更快收敛,并在现实环境中表现更好。
● 实验结果:
○ 训练表现:采用双阶段训练的控制器在训练中显示出更好的收敛性,能够在最难地形上达到更高的成功率(如上图B(i)所示)。
○ 部署表现:经过微调后的控制器在部署过程中展现了更高的成功率和更好的稳定性(如上图B(ii)所示)。
这些实验结果表明,分阶段引入复杂地形和扰动的训练策略能够显著提升控制器的泛化能力和现实适应性

这项研究带来了腿足机器人控制的一大突破。通过结合强化学习和多头注意力机制(MHA),研究人员让机器人不仅能够精准预测在崎岖地形中的支撑点,还能在充满不确定性的环境中保持稳定、高效的运动。无论是GR-1还是ANYmal-D机器人,都在实验和实际环境中表现出色,成功应对了未曾见过的复杂地形。
更酷的是,这项技术给机器人带来了新的“智慧”。通过不断学习和适应,机器人能够在各种复杂地形上实现精准的运动控制,开辟了更多实际应用的可能性。未来,无论是在灾后救援还是探索未知领域,机器人都能更加灵活地融入到我们的生活和工作中,成为我们的得力助手。
附paper链接:https://www.science.org/doi/10.1126/scirobotics.adv3604#M1