使用云端GPU训练Lerobot
#AutoDL #GPU #租显卡
-
租用AutoDL服务器
登陆https://www.autodl.com/,注册登陆后,选择左上方的“算力市场”,找到合适的GPU算力服务器,如选择“A100-PCIE-40G”
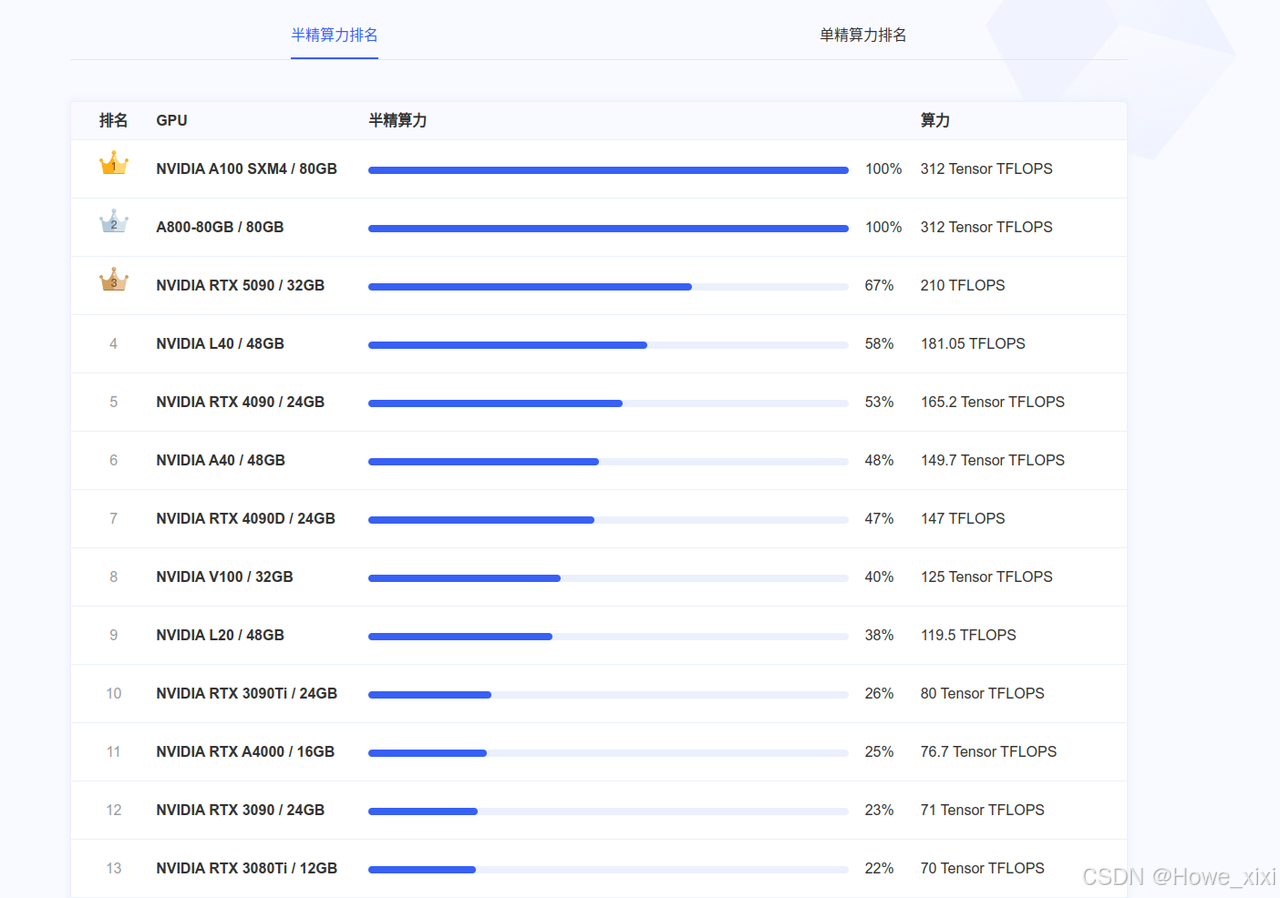
官网也提供了算力排行榜
然后根据实际需求选择是否需要扩容,服务器免费提供50G,后期也可动态添加扩容
镜像部分,我选择了基础镜像-Miniconda的22.04的版本,创建之后如下图,然后点击JupyterLab进入界面
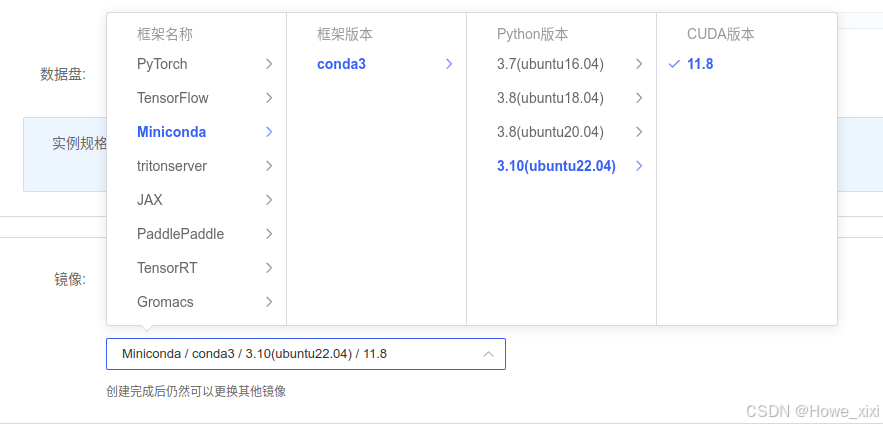
镜像部分,我选择了基础镜像-Miniconda的22.04的版本,创建之后如下图,然后点击JupyterLab进入界面


点击终端启动后,我们开始部署lerobot的环境。
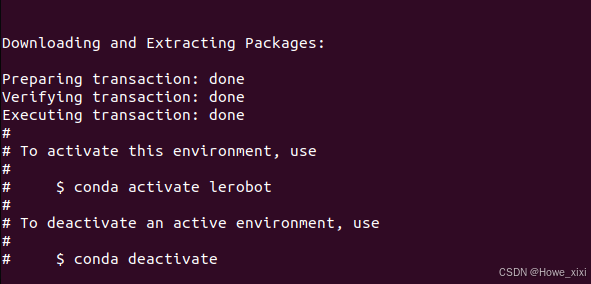
创建并激活一个新的 conda 环境用于 LeRobot,整体流程与在实体机上相同:
conda create -y -n lerobot python=3.10 && conda activate lerobotConda 主要用于区分python环境以及环境中使用的库版本,如上为创建了一个python版本为3.10的环境
-
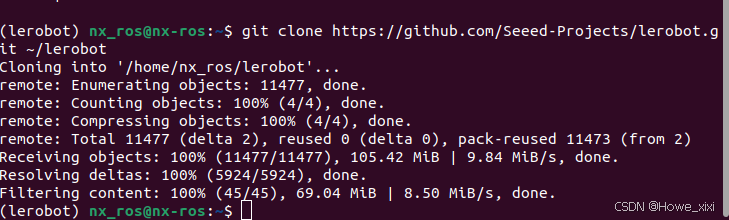
克隆 LeRobot 仓库
git clone https://github.com/Seeed-Projects/lerobot.git ~/lerobot
 看到在用户名前有LeRobot标志,说明当前的环境为LeRobot。
看到在用户名前有LeRobot标志,说明当前的环境为LeRobot。
-
使用 miniconda 时,在环境中安装 ffmpeg
conda install ffmpeg -c conda-forge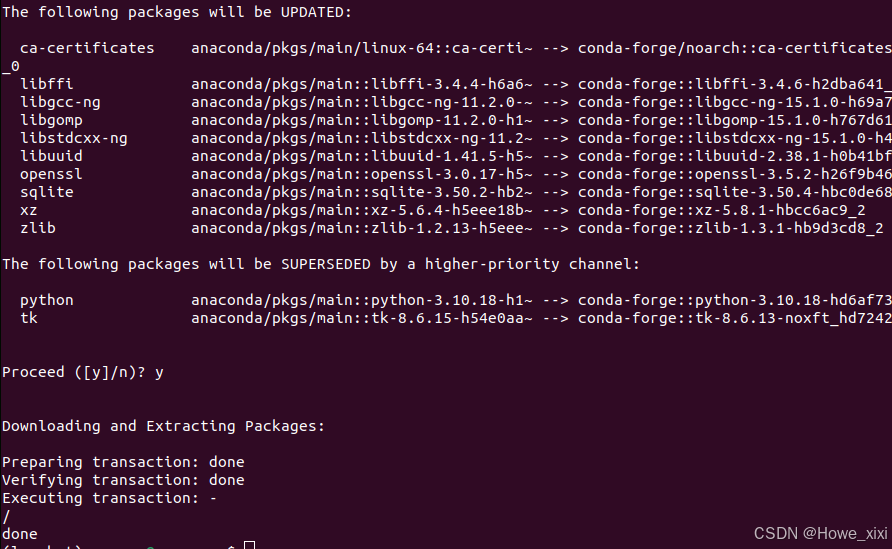
-
安装带有 feetech 电机依赖的 LeRobot
cd ~/lerobot && pip install -e ".[feetech]"-
使用filezilla传输文件
filezilla使用ssh进行连接,可直接拖拽文件进行传输,在本地终端使用以下命令进行下载
sudo apt install filezilla下载成功后运行filezilla即可启动
点击左上角File-Site Manager-后,点击下方的New site创建新的连接
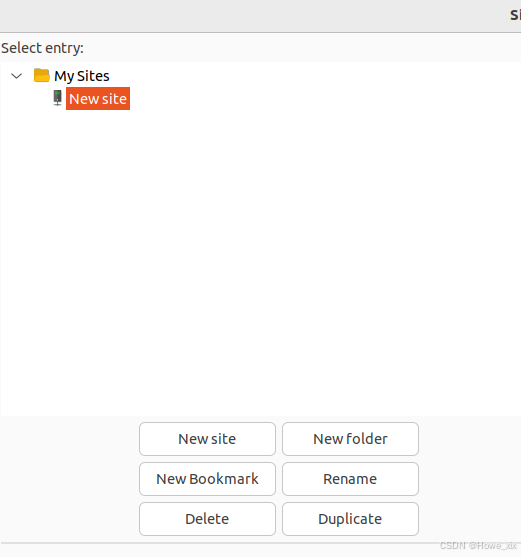
选择Protocol部分为SFTP,HOST和Port部分由AutoDL获取
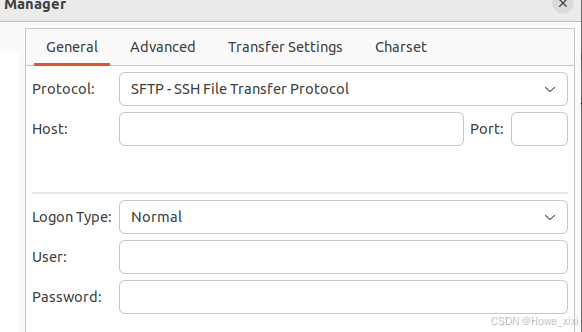
回到AutoDL页面,查看服务器ip,复制登陆指令,其格式如ssh -p 45082 root@regxxxxx.autodl.pro,root@regxxxxx.autodl.pro即为HOST,45082即为Port
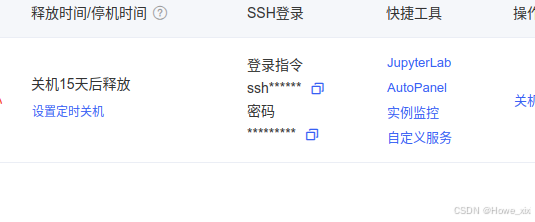
User名为root,密码同样根据网络提示获取。
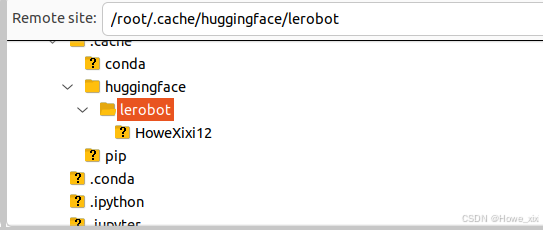
将本地机器的数据集.cache/huggingface/lerobot-放置在云端相同的路径中中,注意路径位置。
-
训练模型
python -m src.lerobot.scripts.train --dataset.repo_id HoweXixi12/Pick_Sugar01 --policy.type act --output_dir outputs/train/Pick_Sugar01 --job_name act_Aura_test --policy.device cuda --wandb.enable false --policy.push_to_hub false --steps 300000 -
数据集指定:我们通过
--dataset.repo_id=${HF_USER}/Pick_Sugar01参数提供了数据集,这通常会检查。 -
训练步数:我们通过
--steps=300000修改训练步数,算法默认为800000,根据自己的任务难易程度,观察训练时候的loss来进行调整。 -
策略类型:我们使用
policy.type=act提供了策略,同样可以更换[act,diffusion,pi0,pi0fast,pi0fast,sac,smolvla]等策略,这将从configuration_act.py加载配置。重要的是,这个策略会自动适应机器人(例如laptop和phone)的电机状态、电机动作和摄像头数量,这些信息已保存在您的数据集中。 -
设备选择:我们提供了
policy.device=cuda,因为我们正在 Nvidia GPU 上进行训练,但您可以使用policy.device=mps在 Apple Silicon 上进行训练。 -
可视化工具:我们提供了
wandb.enable=true来使用 Weights and Biases 可视化训练图表。这是可选的,但如果使用它,请确保已通过运行wandb login登录。 -
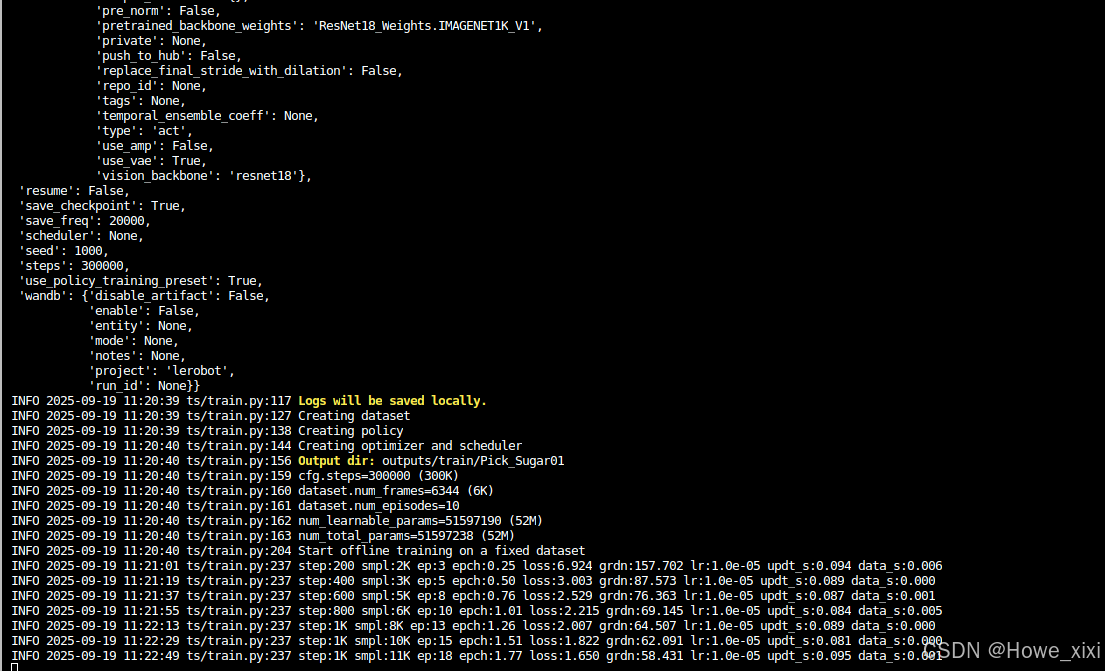
如果使用本地的显卡,我训练2K步就要6,7个小时了,使用AutoDL的显卡,训练20K,直接压缩到1-2小时,起飞~~
训练完,使用filezilla将output中的预训练模型下载会本地设备即可。