无事随笔——mp踩坑
好久没更新博客了,今天也是闲来无事随便写点,也是在工作上遇到的坑吧。
先说背景吧——最近在使用拦截器给项目做全局sql changelog的时候,发现调用MyBatis-Plus saveBatch()的时候,无法在拦截器里获取到对应新增实体类的主键ID(主键ID并没有回填到实体类中),于是我便去翻看mp的源码,不看不知道,一开始才发现有好多坑。
先说结论:MyBatis-Plus 默认自带的 saveBatch() 方法,是“伪批量新增”,它在实现上并不是真正意义上的 SQL 批量插入,而是将多条记录拆分成多个单条 INSERT 语句,在同一个 SqlSession 中循环执行,并通过 flushStatements() 分批提交。
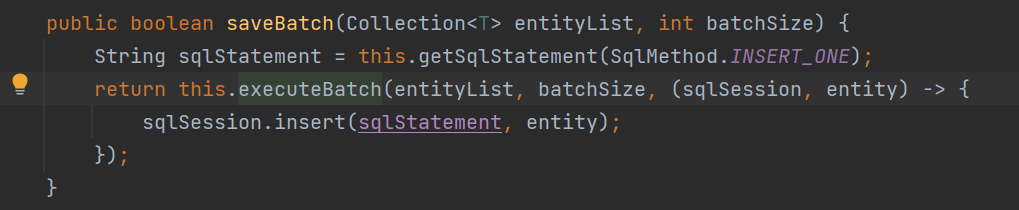
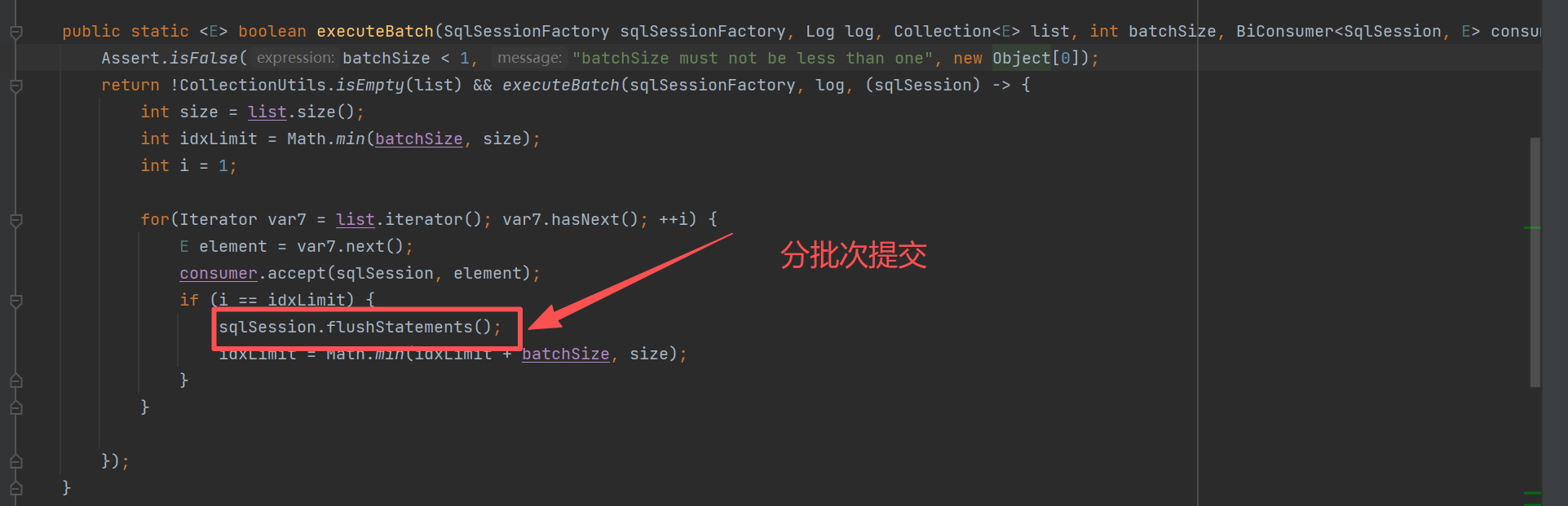
那其实很多小白可能就会问,这个真批量和伪批量 有啥区别呀?
1、 执行sql的形式
伪批量实际执行的 SQL:
INSERT INTO user(name, age) VALUES ('张三', 20);
INSERT INTO user(name, age) VALUES ('李四', 22);
INSERT INTO user(name, age) VALUES ('王五', 24);
真批量实际执行的 SQL:
INSERT INTO user(name, age) VALUES ('张三', 20), ('李四', 22), ('王五', 24);
在大批量插入的时候伪批量的sql执行效率要远远低于真批量的sql执行效率
但是虽然伪批量本质就是for循环,但是它确实比你自己写的 手动 for 循环 + 单条 insert() 要快
先说原因:
1、它把 N 条 SQL 的执行 放到了 同一个 SqlSession 的批处理里
2、它按批次 flush,减少了网络往返和 Statement 编译次数
举个例子:
for (User u : list) {// 每执行一次就会创建一条PreparedStatementuserMapper.insert(u);
}
- 每条 insert 都会走一次:SqlSession → JDBC → 网络 → SQL解析 → 写 redo/undo → 返回
- 默认 ExecutorType.SIMPLE,一条 SQL 就创建一个新的 PreparedStatement
这个就会导致性能极低,而saveBatch()复用了Statement,并且将网络之间的往返和SQL解析次数降低为 list.size()/batchSize,并将事务提交降低为一次
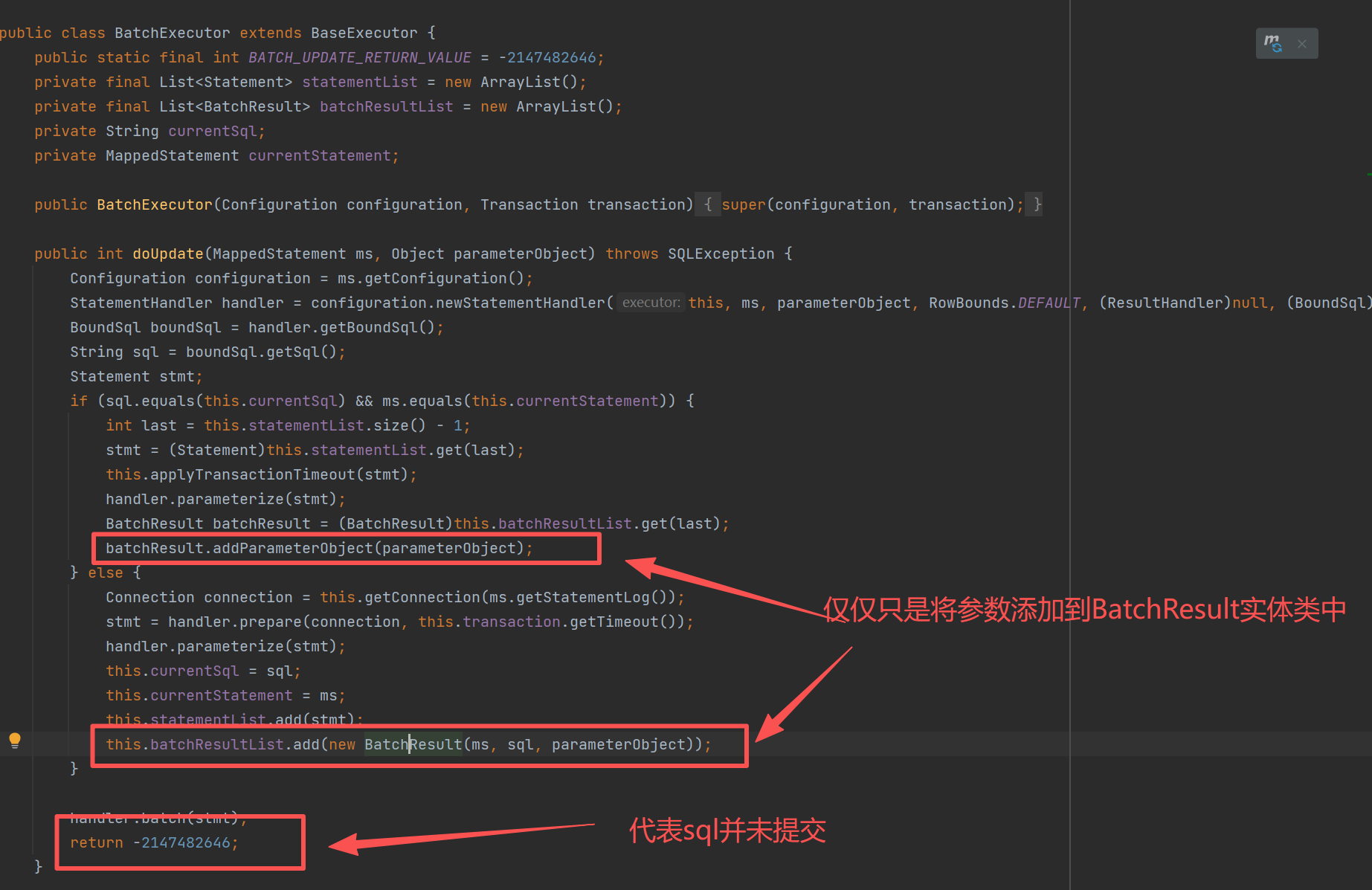
解析到这里,我也就明白了为什么我在拦截器中无法获取到主键ID,就是因为此时的sql只是暂存并未提交,于是我也就只能放弃了在拦截器中获取主键ID的想法,转而采用集成TransactionSynchronization 接口的形式来获取