✅ Python微博舆情分析系统 Flask+SnowNLP情感分析 词云可视化 爬虫大数据 爬虫+机器学习+可视化
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:Python语言、Flask框架、MySQL数据库、requests网络爬虫技术、scikit-learn机器学习、snownlp情感分析、词云、舆情分析
功能:微博数据爬取→情感倾向判定→热词/词云/IP地域→可视化大屏→CSV/MySQL导出
研究背景:社交媒体已成为舆情主阵地,快速感知网民情绪对品牌、政务、金融风控价值巨大;Python+爬虫+ML可低成本构建舆情洞察原型。
研究意义:将“爬虫-清洗-NLP-可视化”完整链路封装成Flask Web系统,为舆情监测、市场营销、毕业设计提供一键复用的开源方案。
2、项目界面
(1)系统首页-数据概况
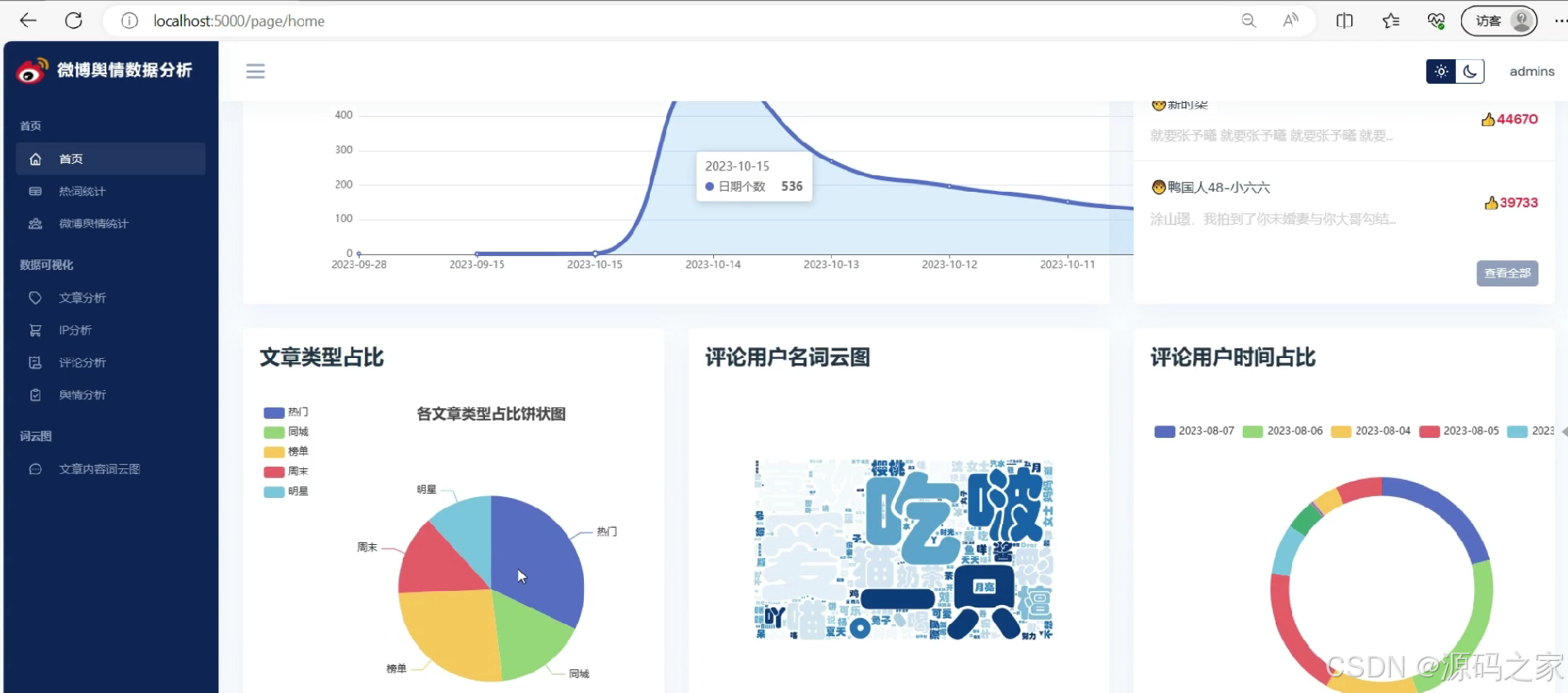
(2)微博舆情统计分析
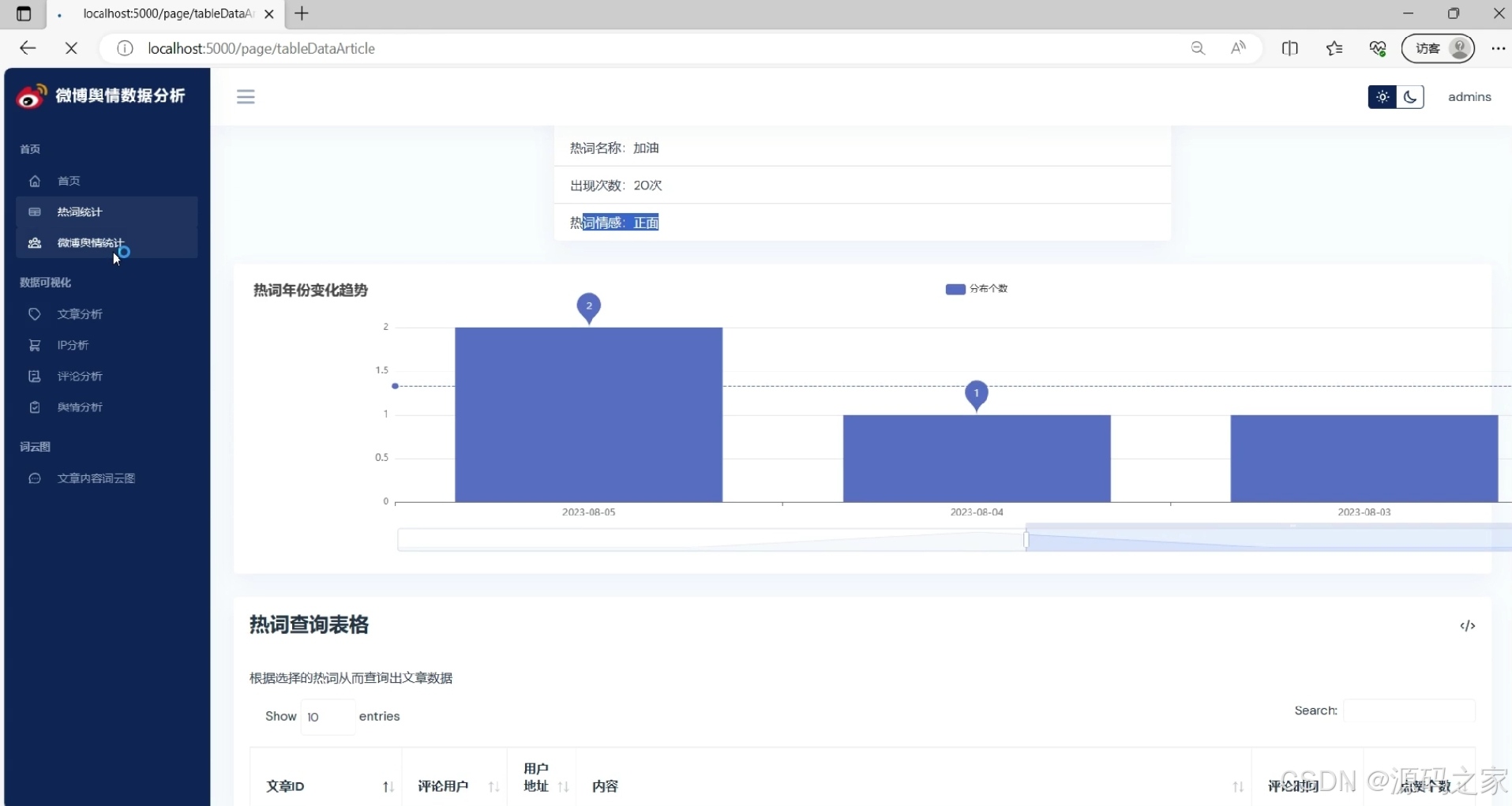
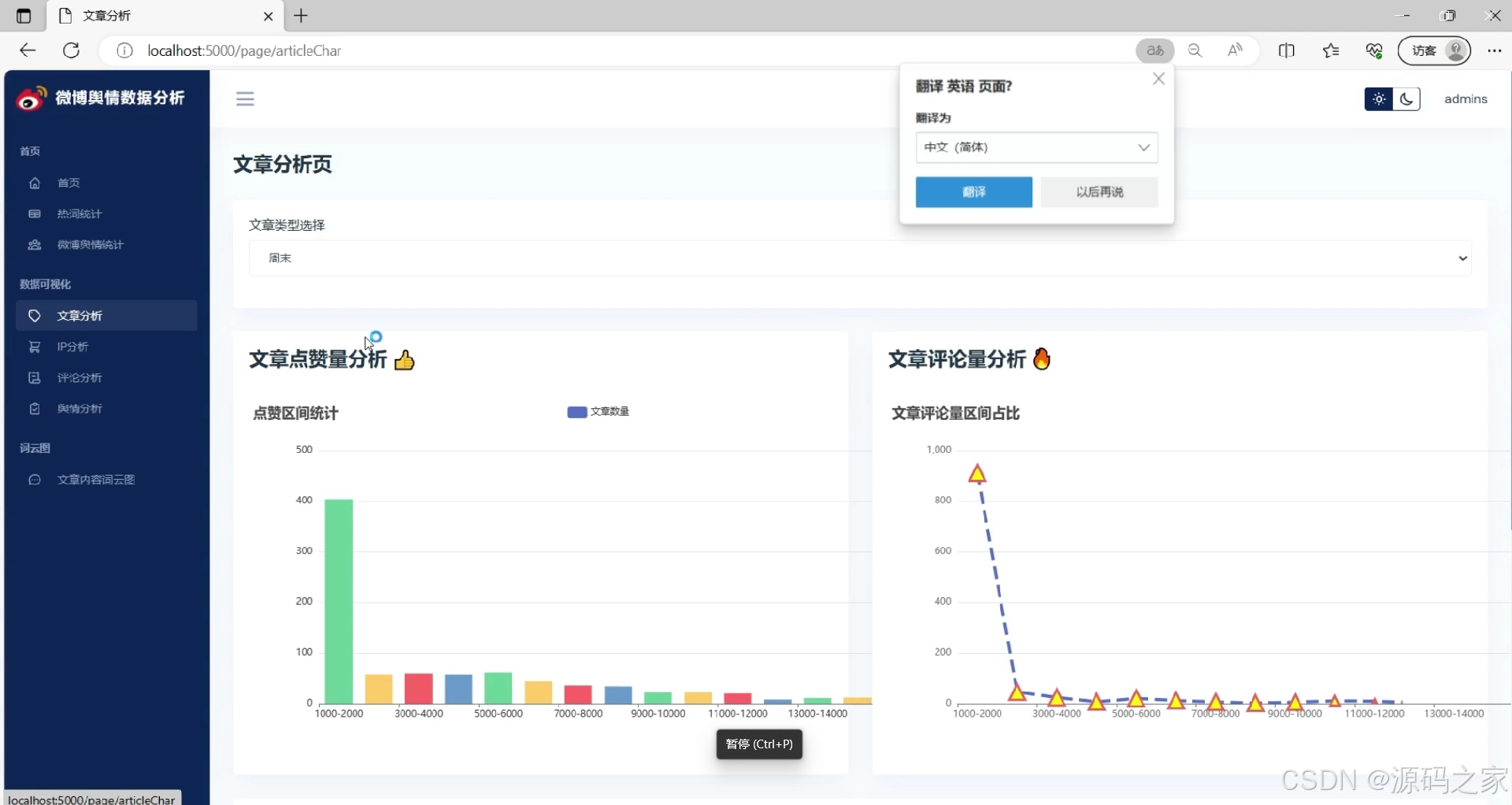
(3)舆情文章分析
(4)IP地址分析
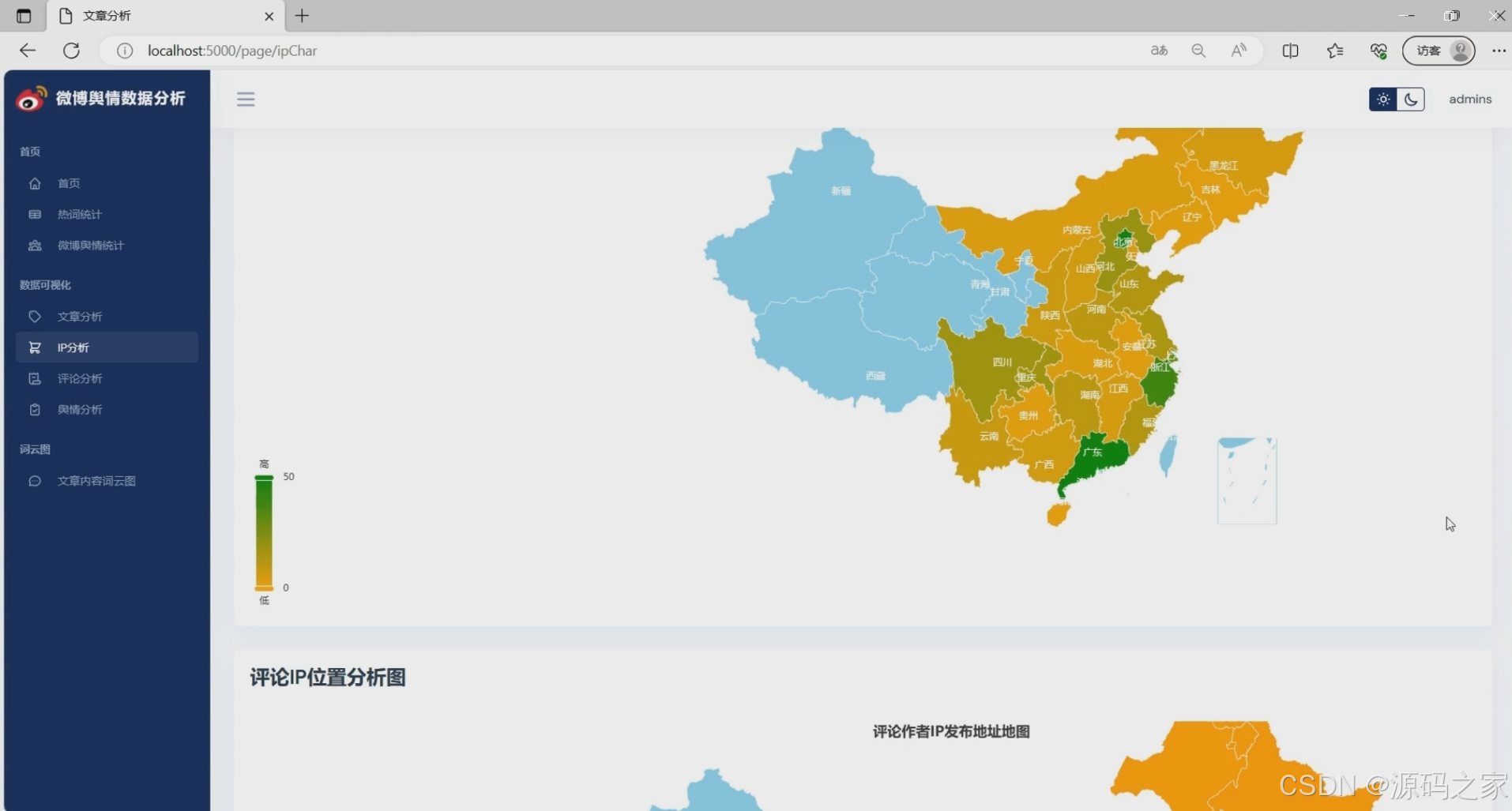
(5)舆情数据
(6)舆情评论分析
(7)舆情分析
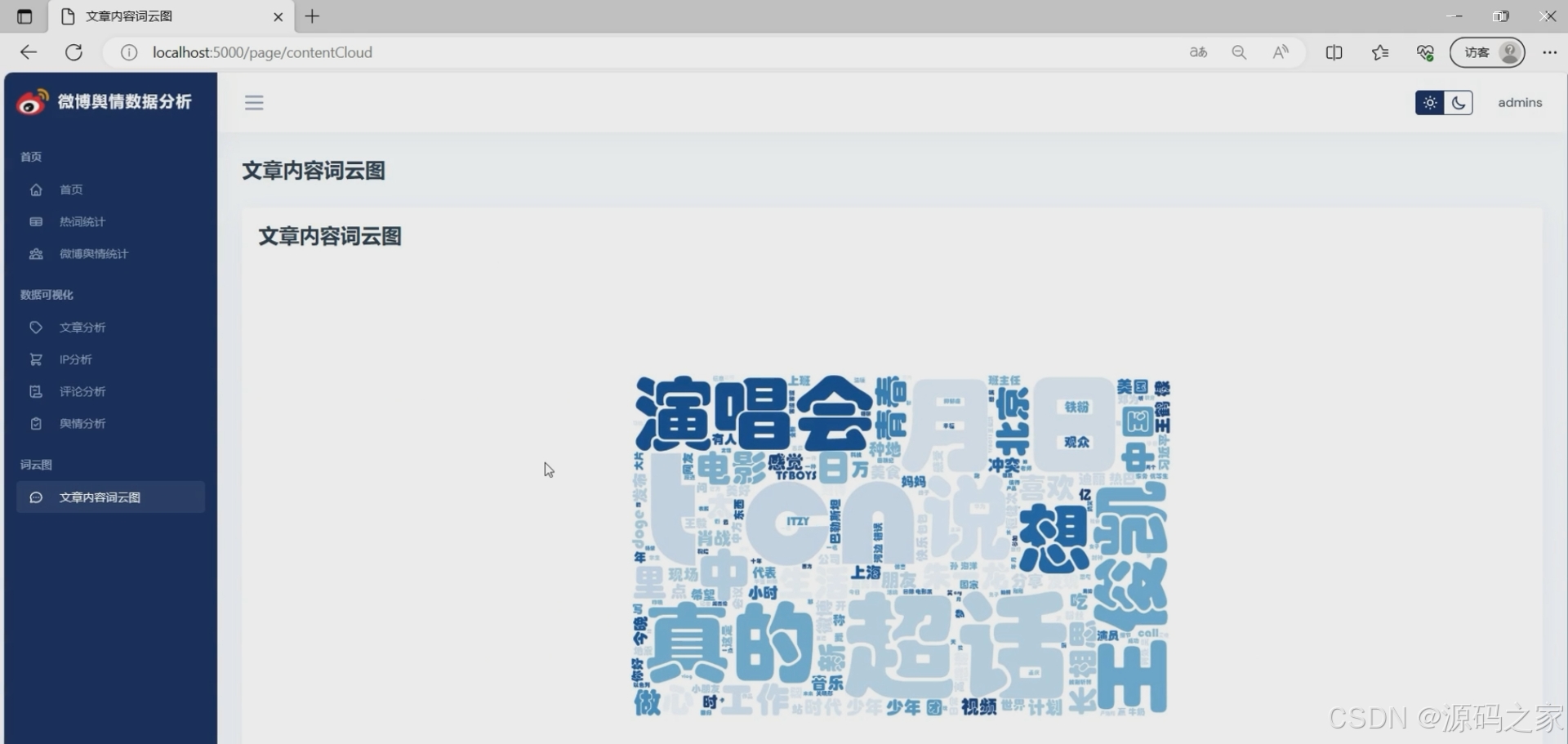
(8)文章内容词云分析
3、项目说明
-
开发工具
本项目在PyCharm IDE下使用Python 3.8完成,借助其强大的调试、虚拟环境与Git集成,显著提高开发效率。 -
数据获取
通过requests+Session池模拟登录微博,采用随机UA、IP代理与重试机制绕过反爬,定时抓取微博正文、发布时间、用户昵称、IP归属地、点赞/评论/转发量等字段;数据经过去重、清洗后使用PyMySQL+SQLAlchemy写入MySQL,同时生成CSV备份,确保后续分析任务数据完整且更新及时。 -
微博热词统计
① 热点年份变化趋势:按年聚合高频关键词,折线图展示话题迁移轨迹,可观察社会焦点从“娱乐明星”向“社会事件”再向“科技前沿”的演变。
② 热词情感分析:调用SnowNLP计算每条微博的positive/negative概率,堆叠面积图呈现情感比例随时间波动,帮助捕捉突发事件引发的舆论反转。
③ 热词频率分析:使用Counter+Jieba分词,剔除停用词后生成Top30词频柱状图,支持交互式下钻查看具体微博列表。 -
微博文章分析
① 类型占比:按“原创/转发/长文”打标签,饼图展示分布,洞察平台内容生态。
② 评论量&转发量:箱线图呈现区间分布,辅助评估话题互动深度。
③ 词云:TF-IDF提取关键词,蒙版轮廓采用微博logo,增强品牌识别度。
④ 基本信息统计:折线图展示阅读量、发布时间24h分布,为内容运营提供数据依据。 -
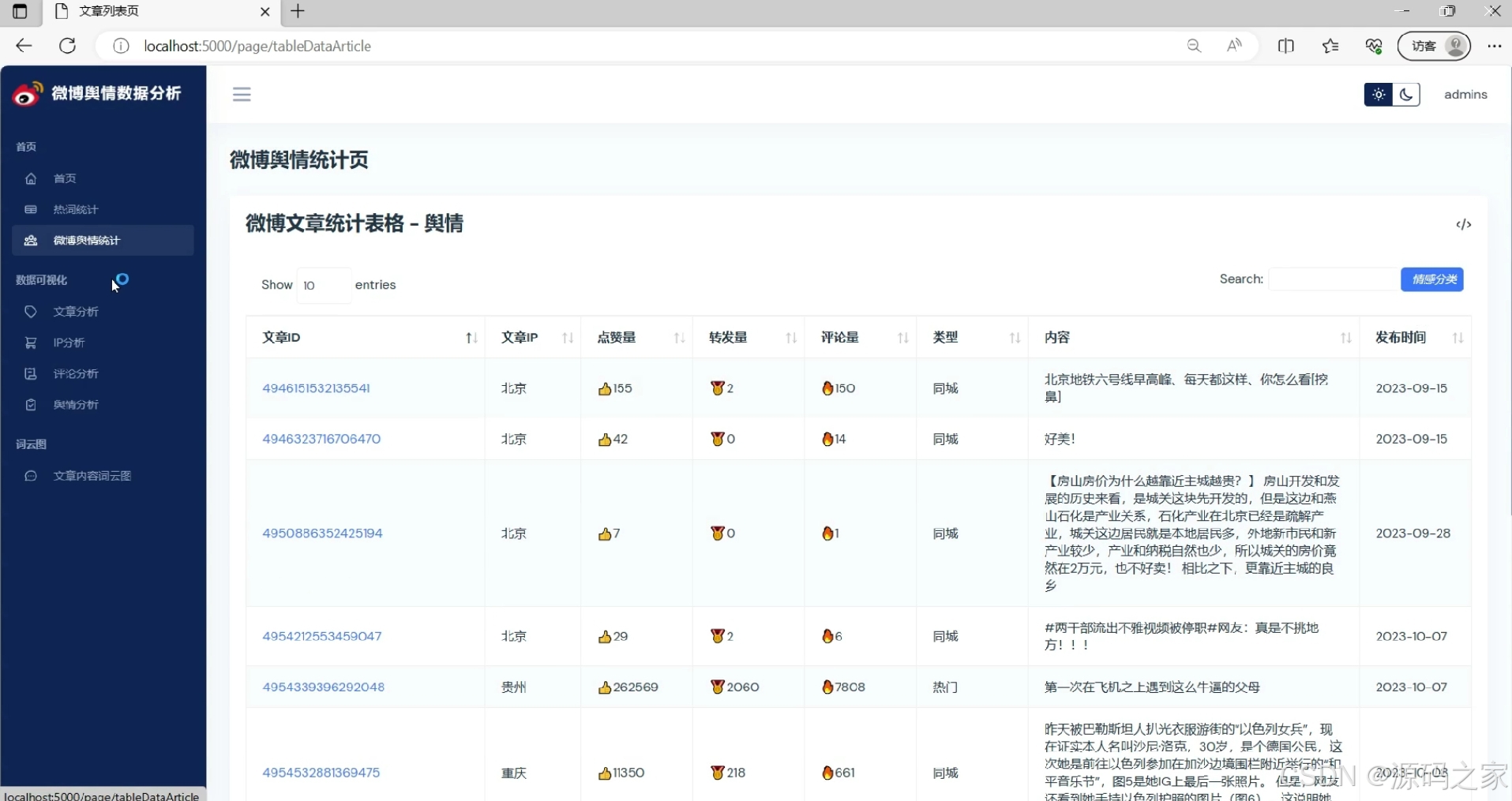
微博评论分析
① 性别占比:爬取用户资料页性别字段,玫瑰图展示男女比例,可辅助判断话题受众偏向。
② 评论词云:单独对评论分词,高频词以心形蒙版呈现,直观反映网友情绪焦点。
③ 点赞排行:柱状图展示高赞评论,点击条目可跳转原文,快速定位“金句”或“爆点”。 -
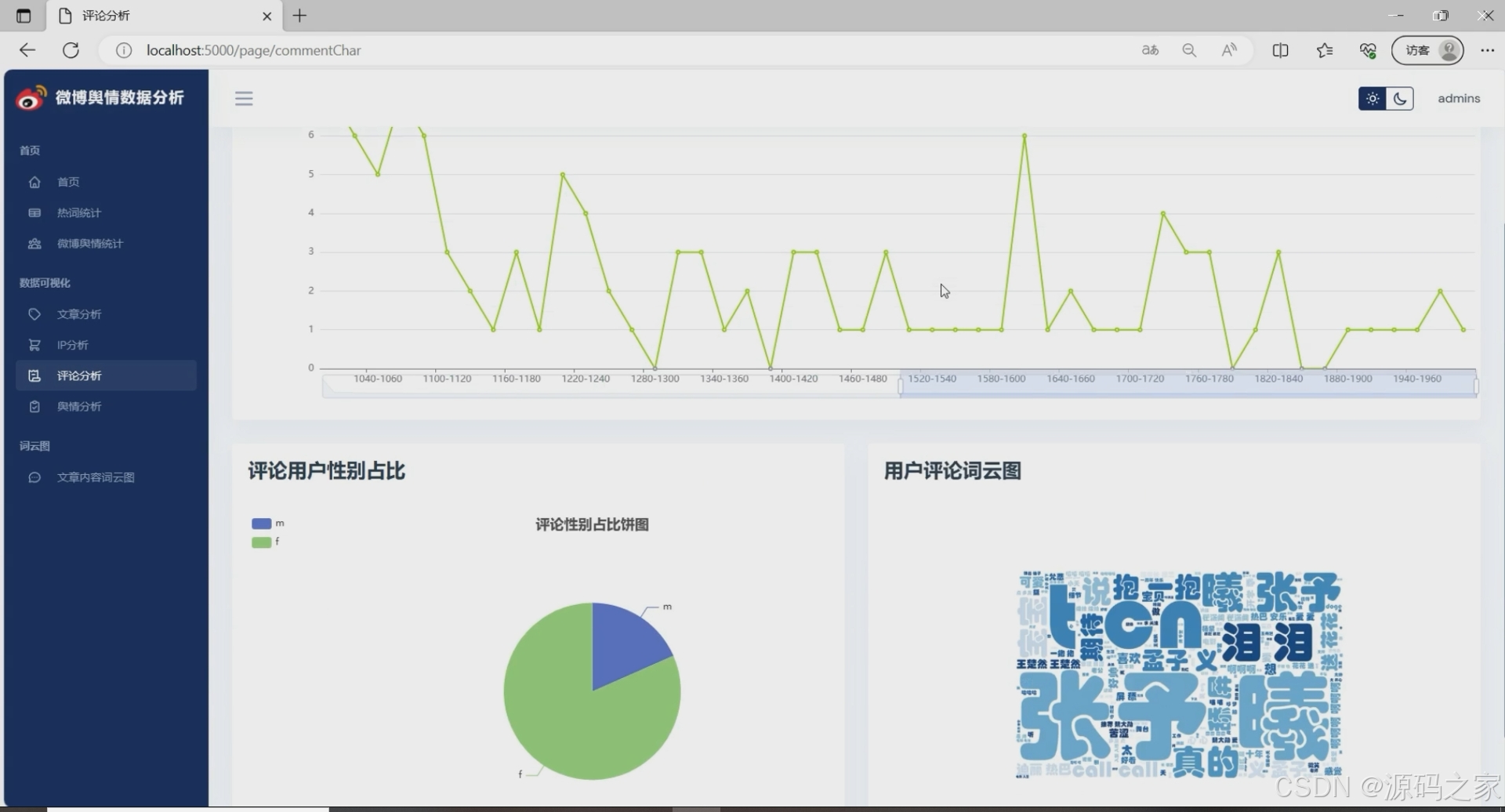
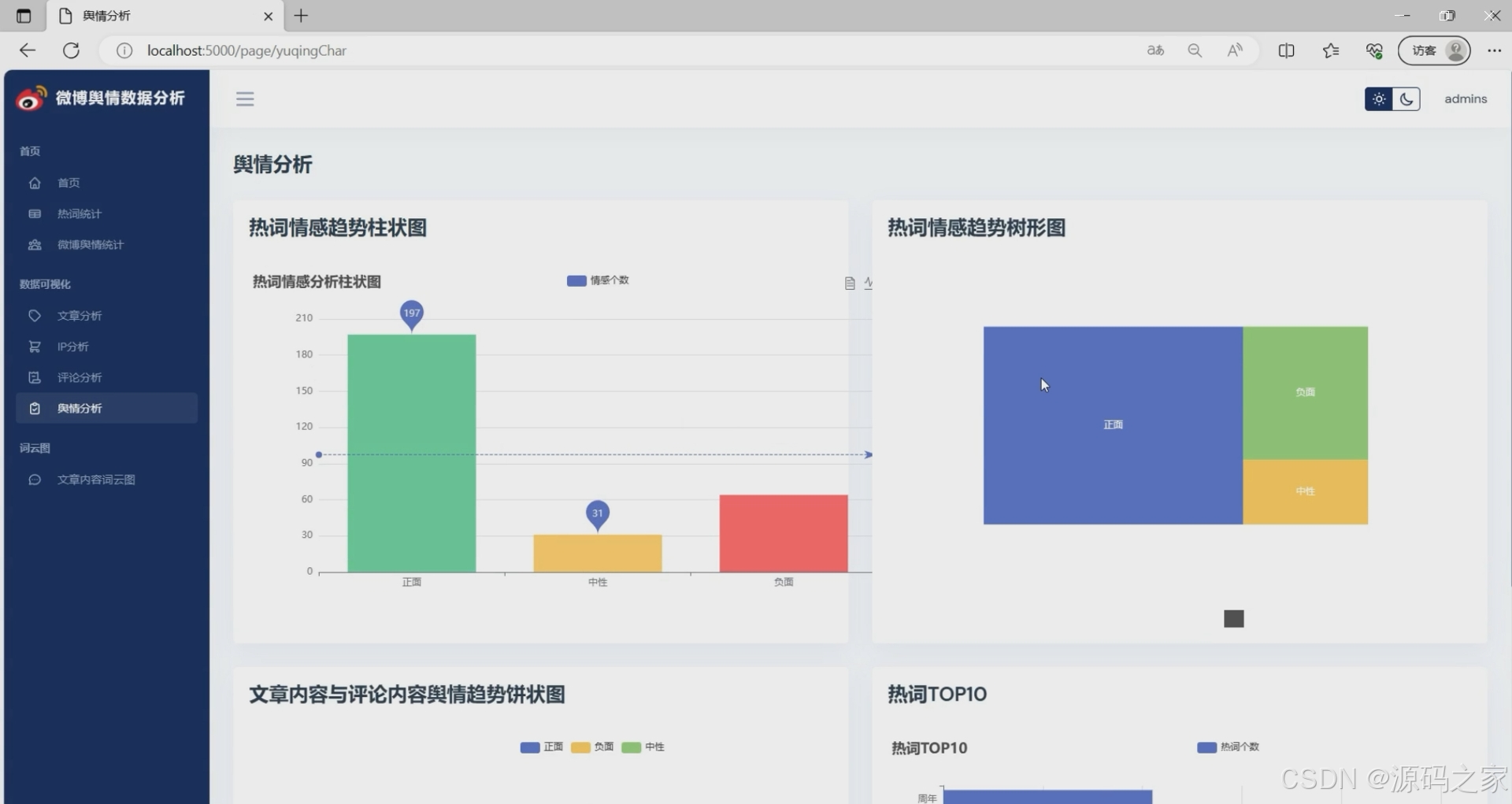
微博舆情分析
① 热词情感趋势:以周为粒度,绘制positive/negative曲线,叠加微博发布量柱状图,一眼看出“量增情降”或“量降情升”的异常周。
② 舆情走势:融合文章与评论情感,采用7日滑动平均,预测未来3天情绪走向(线性回归),为品牌方或政务部门提供决策参考。
系统采用Flask+MySQL架构,前端使用Bootstrap+ECharts,所有图表支持一键导出PNG/CSV;后台管理可配置爬虫频率、敏感词过滤、用户权限;整个工程代码开源、环境一键复现,是舆情监控、市场营销、毕业设计的理想模板。
4、核心代码
from utils import getPublicData
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image # 图片处理
import numpy as np
from snownlp import SnowNLPdef getTypeList():typeList = list(set([x[8] for x in getPublicData.getAllData()]))return typeListdef getArticleCharOneData(defaultType):articleList = getPublicData.getAllData()xData = []rangeNum = 1000for item in range(1,15):xData.append(str(rangeNum * item)+ '-' + str(rangeNum*(item+1)))yData = [0 for x in range(len(xData))]for article in articleList:if article[8] != defaultType:for item in range(14):if int(article[1]) < rangeNum*(item+2):yData[item] += 1breakreturn xData,yDatadef getArticleCharTwoData(defaultType):articleList = getPublicData.getAllData()xData = []rangeNum = 1000for item in range(1,15):xData.append(str(rangeNum * item)+ '-' + str(rangeNum*(item+1)))yData = [0 for x in range(len(xData))]for article in articleList:if article[8] != defaultType:for item in range(14):if int(article[2]) < rangeNum*(item+2):yData[item] += 1breakreturn xData,yDatadef getArticleCharThreeData(defaultType):articleList = getPublicData.getAllData()xData = []rangeNum = 50for item in range(1, 30):xData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))yData = [0 for x in range(len(xData))]for article in articleList:if article[8] != defaultType:for item in range(29):if int(article[2]) < rangeNum * (item + 2):yData[item] += 1breakreturn xData, yDatadef getGeoCharDataTwo():cityList = getPublicData.cityListcommentList = getPublicData.getAllCommentsData()cityDic = {}for comment in commentList:if comment[3] == '无': continuefor j in cityList:if j['province'].find(comment[3]) != -1:if cityDic.get(j['province'], -1) == -1:cityDic[j['province']] = 1else:cityDic[j['province']] += 1cityDicList = []for key, value in cityDic.items():cityDicList.append({'name': key,'value': value})return cityDicListdef getGeoCharDataOne():cityList = getPublicData.cityListarticleList = getPublicData.getAllData()cityDic = {}for article in articleList:if article[4] == '无':continuefor j in cityList:if j['province'].find(article[4]) != -1:if cityDic.get(j['province'],-1) == -1:cityDic[j['province']] = 1else:cityDic[j['province']] += 1cityDicList = []for key, value in cityDic.items():cityDicList.append({'name': key,'value': value})return cityDicListdef getCommetCharDataOne():commentList = getPublicData.getAllCommentsData()xData = []rangeNum = 20for item in range(1, 100):xData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))yData = [0 for x in range(len(xData))]for comment in commentList:for item in range(99):if int(comment[2]) < rangeNum * (item + 2):yData[item] += 1breakreturn xData, yDatadef getCommetCharDataTwo():commentList = getPublicData.getAllCommentsData()genderDic = {}for i in commentList:if genderDic.get(i[6],-1) == -1:genderDic[i[6]] = 1else:genderDic[i[6]] += 1resultData = [{'name':x[0],'value':x[1]} for x in genderDic.items()]return resultDatadef stopwordslist():stopwords = [line.strip() for line in open('./model/stopWords.txt',encoding='UTF-8').readlines()]return stopwordsdef getContentCloud():text = ''stopwords = stopwordslist()articleList = getPublicData.getAllData()for article in articleList:text += article[5]cut = jieba.cut(text)newCut = []for word in cut:if word not in stopwords: newCut.append(word)string = ' '.join(newCut)img = Image.open('./static/content.jpg') # 打开遮罩图片img_arr = np.array(img) # 将图片转化为列表wc = WordCloud(width=1000, height=600,background_color='white',colormap='Blues',font_path='STHUPO.TTF',mask=img_arr,)wc.generate_from_text(string)# 绘制图片fig = plt.figure(1)plt.imshow(wc)plt.axis('off') # 不显示坐标轴# 显示生成的词语图片# plt.show()# 输入词语图片到文件plt.savefig('./static/contentCloud.jpg', dpi=500)def getCommentContentCloud():text = ''stopwords = stopwordslist()commentsList = getPublicData.getAllCommentsData()for comment in commentsList:text += comment[4]cut = jieba.cut(text)newCut = []for word in cut:if word not in stopwords:newCut.append(word)string = ' '.join(newCut)img = Image.open('./static/comment.jpg') # 打开遮罩图片img_arr = np.array(img) # 将图片转化为列表wc = WordCloud(width=1000, height=600,background_color='white',colormap='Blues',font_path='STHUPO.TTF',mask=img_arr,)wc.generate_from_text(string)# 绘制图片fig = plt.figure(1)plt.imshow(wc)plt.axis('off') # 不显示坐标轴# 显示生成的词语图片# plt.show()# 输入词语图片到文件plt.savefig('./static/commentCloud.jpg', dpi=500)def getYuQingCharDataOne():hotWordList = getPublicData.getAllCiPingTotal()xData = ['正面', '中性', '负面']yData = [0,0,0]for hotWord in hotWordList:emotionValue = SnowNLP(hotWord[0]).sentimentsif emotionValue > 0.5:yData[0] +=1elif emotionValue == 0.5:yData[1] += 1elif emotionValue < 0.5:yData[2] += 1bieData = [{'name': '正面','value': yData[0]}, {'name': '中性','value': yData[1]}, {'name': '负面','value': yData[2]}]return xData,yData,bieDatadef getYuQingCharDataTwo():bieData1 = [{'name':'正面','value':0},{'name':'中性','value':0},{'name':'负面','value':0}]bieData2 = [{'name': '正面','value': 0}, {'name': '中性','value': 0}, {'name': '负面','value': 0}]commentList = getPublicData.getAllCommentsData()articleList = getPublicData.getAllData()for comment in commentList:emotionValue = SnowNLP(comment[4]).sentimentsif emotionValue > 0.5:bieData1[0]['value'] += 1elif emotionValue == 0.5:bieData1[1]['value'] += 1elif emotionValue < 0.5:bieData1[2]['value'] += 1for article in articleList:emotionValue = SnowNLP(article[5]).sentimentsif emotionValue > 0.5:bieData2[0]['value'] += 1elif emotionValue == 0.5:bieData2[1]['value'] += 1elif emotionValue < 0.5:bieData2[2]['value'] += 1return bieData1,bieData2def getYuQingCharDataThree():hotWordList = getPublicData.getAllCiPingTotal()return [x[0] for x in hotWordList],[int(x[1]) for x in hotWordList]🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻