Windows 本地 UV 环境部署 Index-TTS2 实战:基于 EPGF 架构的完整指南(支持 DeepSpeed + FP16)
🎯 《Windows 本地部署 Index-TTS2 实战:基于 EPGF 架构的完整指南(支持 DeepSpeed + FP16)》
关键词:
Index-TTS2TTS部署uvEPGFDeepSpeedHF-MirrorGradioWinError 10054
标签:#TTS #语音合成 #Python #EPGF #CSDN #AI部署
【EPGF 白皮书】路径治理驱动的多版本 Python 架构—— Windows 环境治理与 AI 教学开发体系
📌 前言

Index-TTS2 是一个高质量的端到端中文语音合成系统,采用 GPT+CFM+BigVGAN 架构。本地部署常因 依赖混乱、模型下载失败、Gradio 自检中断 等问题卡住。
本文基于 EPGF(Engineering Python Governance Framework) 治理理念,结合 uv、huggingface_hub[cli]、modelscope、HF-Mirror 等现代工具,带你完成一套 可控、可迁移、可复现 的部署流程。
本文后续会简单对比 IndexTTS 与 IndexTTS2 的关键差异。
✅ 所有步骤在 Windows 11 验证过
✅ 支持 DeepSpeed 加速与 FP16 推理
✅ 完全遵循 IndexTTS2 官方pyproject.toml与 README 的推荐
🏗️ 一、EPGF 治理视角(要点)
EPGF 强调 过程化治理:路径治理 → 环境隔离 → 依赖锁定 → 工具治理 → 运行闭环。本文的所有步骤都围绕这条闭环展开,确保工程化可控。
在 EPGF 架构下的 Python 环境变量设置建议——Anaconda 路径精简后暴露 python 及工具到环境变量的配置记录 [三]
- 📂 示例:在 EPGF 架构下,用于创建项目 uv 环境的工具路径
- uv.exe 路径示例为
D:/A/envs/Scripts/uv.exe
- uv.exe 路径示例为
D:\A\envs\
│─ py310\
│ └─ Scripts/
│ ├─ uv.exe ← 本级工具链
│─ py311\
│ └─ Scripts/
└─ …命令行操作示意:
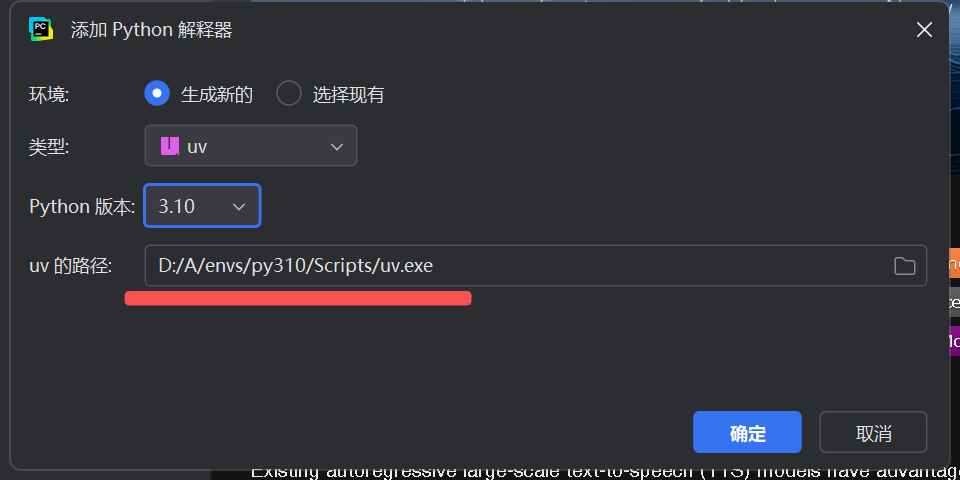
uv venv --seed .venv- 📂 示例:在 EPGF 架构下,在 PyCharm 中用于创建项目 uv 环境的演示
- uv.exe 路径示例为
D:/A/envs/Scripts/uv.exe
- uv.exe 路径示例为
🧱 二、Environment:多级隔离与工具自包含(EPGF 核心)
0) 克隆项目与下载 LFS 资源
git lfs install
git clone https://github.com/index-tts/index-tts.git
cd index-tts # 进入项目文件夹
如果原先已经部署了 index-tts1 的,建议克隆到 index-tts2 文件夹中,以便区分。
1) 激活 Conda 基础环境(固定 Python 版本)
conda activate py310
2) 使用 uv 创建虚拟环境并预置基础构建工具(推荐)
uv venv 为何没有 pip?—— 揭秘现代 Python 工具链的“动态治理”挑战与 EPGF 的应对之道
# 使用父级 Conda 环境中的 uv.exe 创建项目本地的名为 .venv 的UV环境
uv venv --seed .venv# .venv 创建成功后,立即退出 Conda 父级环境,避免父级 Conda 环境污染
conda deactivate# 激活位于项目本地的 uv 虚拟环境
.venv\Scripts\activate# 管理大文件资源下载
git lfs pull
git lfs pull是 Git Large File Storage (LFS) 提供的一个命令,主要作用是拉取当前分支中所有被 Git LFS 跟踪的大文件的实际内容。具体来说,当使用 Git LFS 管理大文件时,Git 仓库中存储的并非大文件本身,而是指向这些大文件的 "指针文件"(包含文件哈希等信息)。而
git lfs pull命令会根据这些指针文件,从 LFS 存储服务器(通常与 Git 仓库关联)下载对应的实际大文件内容到本地,确保本地工作区拥有完整的文件数据。使用场景包括:
- 刚克隆仓库后,指针文件已存在但实际大文件未下载时
- 切换分支后,新分支包含未在本地缓存的 LFS 跟踪文件时
- 远程仓库的 LFS 文件有更新,需要获取最新版本时
该命令确保了在使用 Git LFS 时,既能保持 Git 仓库体积小巧,又能在需要时获取完整的大文件内容。
说明与兼容性注意:
--seed会在新 venv 中自动安装pip,setuptools,wheel,避免后来出现“venv 中没有 pip 的问题”。如果在后续执行
uv pip install或uv sync时出现Failed to hardlink警告,可通过添加--link-mode=copy参数或设置setx UV_LINK_MODE copy环境变量解决,或者忽略即可。
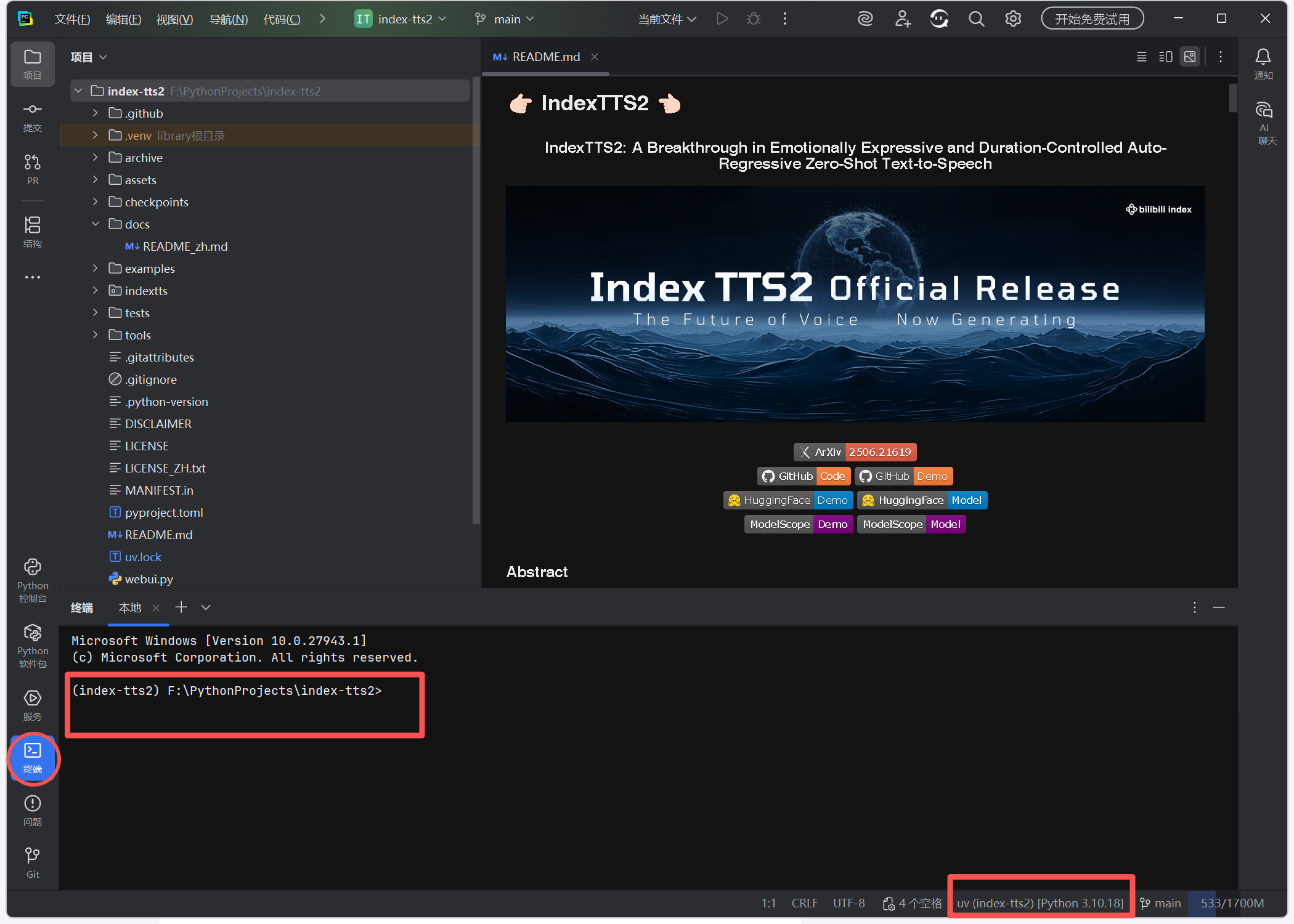
3) 将 uv 本地化安装到 .venv(保证工具自包含)
uv pip install uv -i https://mirrors.aliyun.com/pypi/simple/
where uv
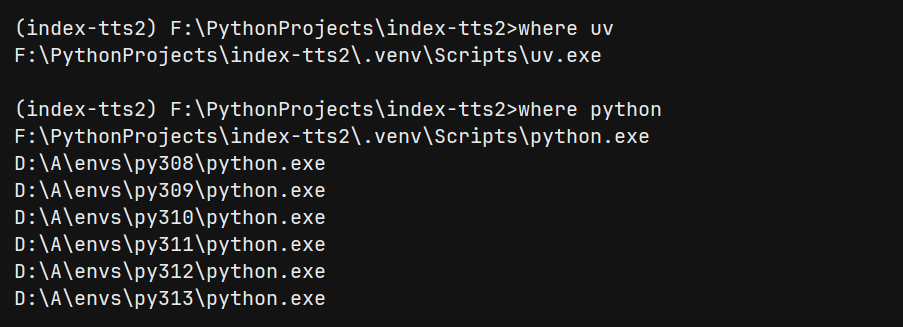
确保
where uv第一条指向当前.venv,否则后续uv sync/uv run可能不在本地环境执行。
如果在续执行
uv pip install或uv sync时出现Failed to hardlink警告,可通过添加--link-mode=copy参数或设置setx UV_LINK_MODE copy环境变量解决,或者忽略即可。
4) (可选)设置国内镜像加速
setx UV_PYPI_INDEX_URL https://mirrors.aliyun.com/pypi/simple/
5) 升级基础构建工具
uv pip install --upgrade pip setuptools wheel
如果在续执行
uv pip install或uv sync时出现Failed to hardlink警告,可通过添加--link-mode=copy参数或设置setx UV_LINK_MODE copy环境变量解决,或者忽略即可。
📦 三、Package:依赖同步、Deepspeed 处理与模型下载
1) 注释 Deepspeed(Windows 特殊处理)
在 pyproject.toml 文件中找到 [project.optional-dependencies] 下的 deepspeed 段,将整段用 # 注释掉或临时删除。
例如:
注释掉第 71、72、73 行(该项依赖在 Windows 系统上,暂无法通过 pypi 或 uv 直装,后边将通过手动下载补齐该依赖项)
# deepspeed = [
# "deepspeed==0.17.1",
# ]
这样可以避免 Windows 下编译失败,待后续手动安装 wheel 后再恢复此条目(可选)。
2) 同步依赖
uv sync --all-extras --default-index "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"
⚠️ 注意:
uv sync会依据pyproject.toml中的tool.uv.sources自动处理 PyTorch/CUDA 源,无须手动安装 torch(除非你要改 CUDA 版本)。(提示:
Failed to hardlink警告可能在此步骤或uv pip install执行过程中出现,可通过添加--link-mode=copy参数或设置setx UV_LINK_MODE copy环境变量解决。)
3) 手动安装 DeepSpeed(Windows)
https://www.piwheels.org/project/deepspeed/
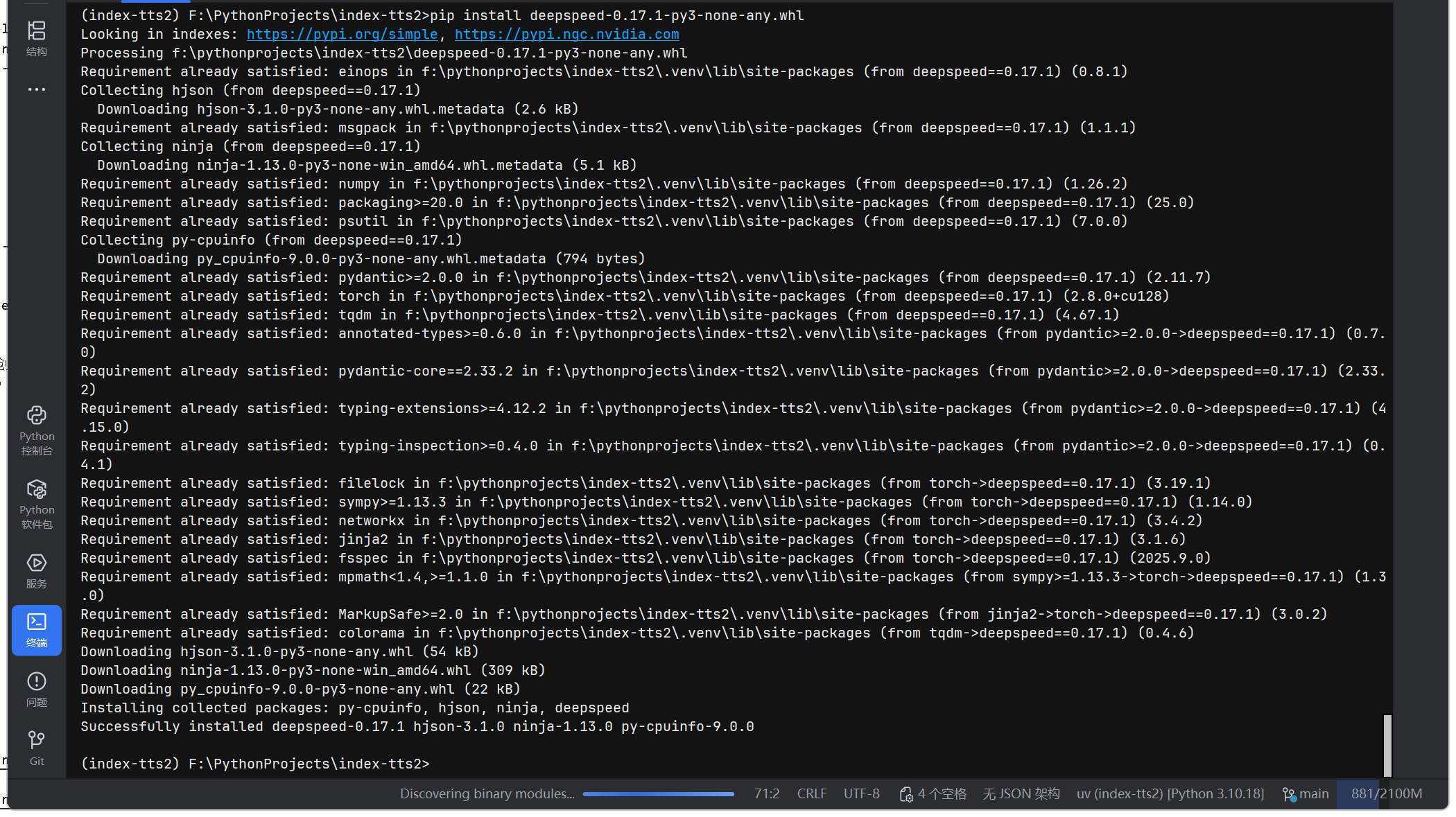
从 piwheels 下载对应 .whl 文件,放到项目目录执行:
uv pip install deepspeed-0.17.1-py3-none-any.whl
或
pip install deepspeed-0.17.1-py3-none-any.whl
4) 下载模型
方式 A — HuggingFace CLI
uv tool install "huggingface_hub[cli]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
方式 B — ModelScope
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
⚠️ 额外提示:首次运行还会下载小模型,建议预先设置环境变量以加速下载:
set HF_ENDPOINT=https://hf-mirror.com
🖥️ 四、环境诊断:检查 GPU 可用性
uv run tools/gpu_check.py
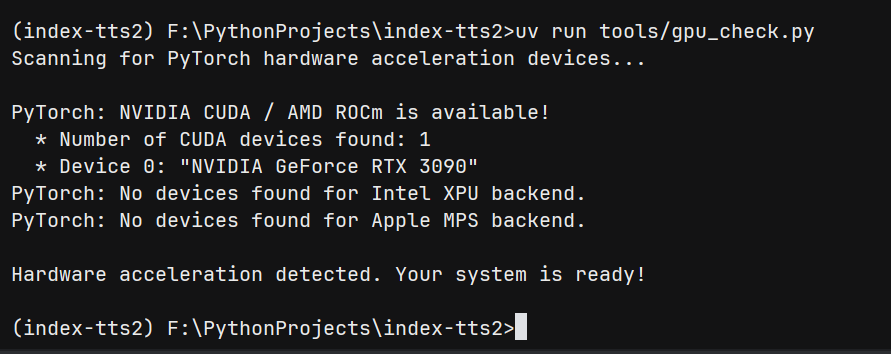
输出应包括 CUDA 是否可用、GPU 名称与显存大小。
上图中这段内容是在检查系统中 PyTorch 可用的硬件加速设备。
首先,“Scanning for PyTorch hardware acceleration devices...” 表示正在扫描 PyTorch 硬件加速设备。
然后,“PyTorch: NVIDIA CUDA / AMD ROCm is available!” 说明 PyTorch 支持的 NVIDIA CUDA 或 AMD ROCm 是可用的。
- “Number of CUDA devices found: 1” 表示找到 1 个 CUDA 设备。
- “Device 0: "NVIDIA GeForce RTX 3090"” 指出第 0 号设备是 “NVIDIA GeForce RTX 3090” 显卡。
接着,“PyTorch: No devices found for Intel XPU backend.” 和 “PyTorch: No devices found for Apple MPS backend.” 分别表示没有找到支持 Intel XPU 后端和 Apple MPS 后端的设备。
最后,“Hardware acceleration detected. Your system is ready!” 说明检测到了硬件加速,系统已准备好,意味着可以利用 NVIDIA GeForce RTX 3090 显卡通过 CUDA 来为 PyTorch 相关的计算(比如深度学习模型训练、推理等)提供硬件加速,提升计算性能。
🚀 五、Flow:启动 WebUI 与推理调优
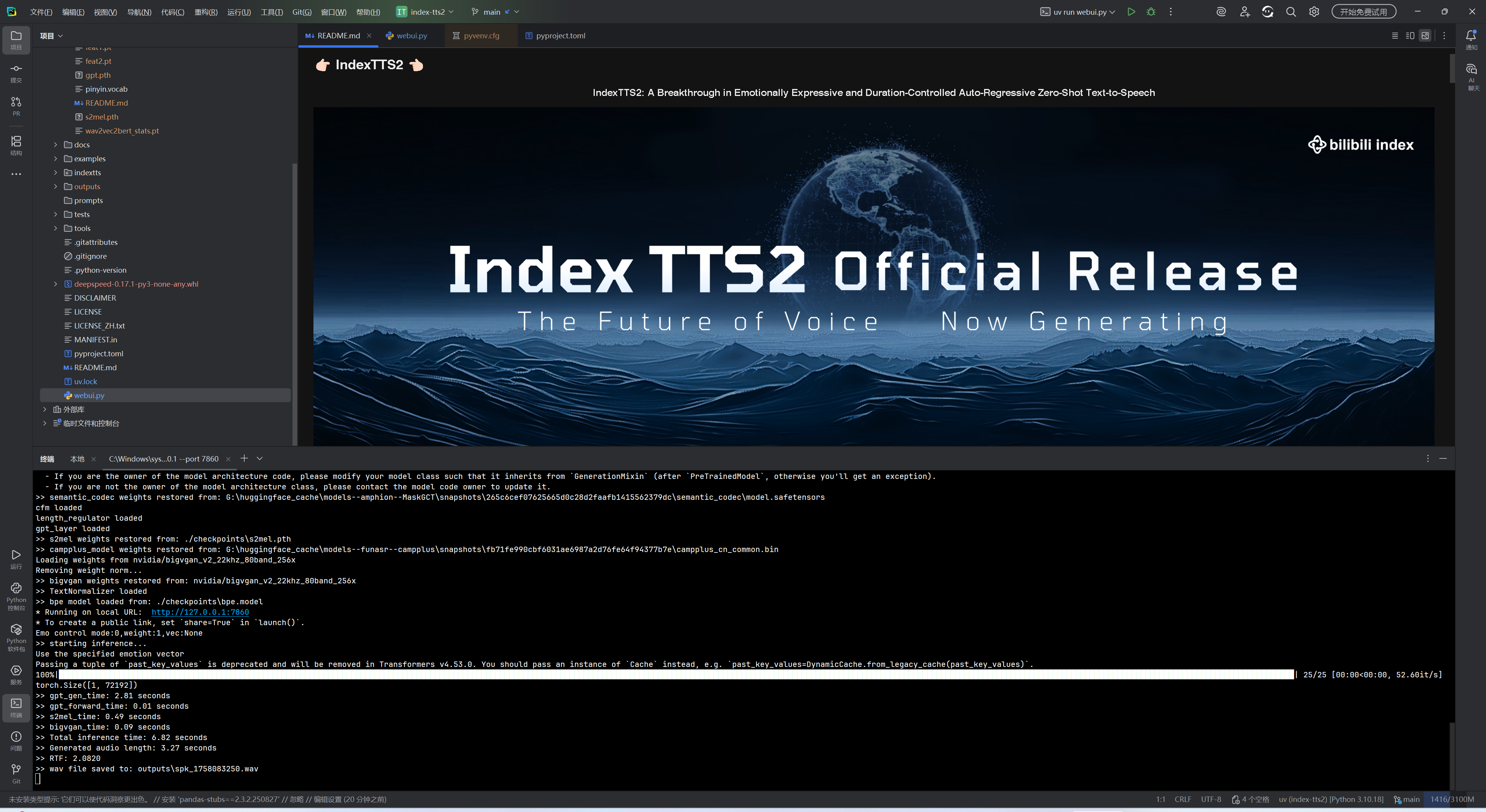
uv run webui.py
uv run webui.py --fp16
uv run webui.py --deepspeed
uv run webui.py -h
建议对比测试开启/关闭 DeepSpeed 的性能差异。
🔄 六、IndexTTS 与 IndexTTS2 的关键差异
-
依赖管理:由
requirements.txt→pyproject.toml + uv -
中文文本处理:Windows 用
wetext取代WeTextProcessing -
加速库:移除了
triton简化构建 -
CUDA:通过
tool.uv.sources自动解析安装 -
DeepSpeed 与 FP16:依赖可选化,Windows 需手动安装 wheel
-
Python 虚拟环境管理:几乎完全依赖 uv 管理
❌ 七、常见问题与排查
| 问题 | 原因 | 解决 |
|---|---|---|
pip 不存在 | venv 未使用 --seed | uv venv --seed .venv 重新创建 |
Failed to hardlink | 不同磁盘 | --link-mode=copy 或 setx UV_LINK_MODE copy |
uv sync 覆盖手动包 | 锁文件冲突 | 先 uv lock --upgrade 再 sync |
| 模型下载慢 | 网络问题 | 设置 HF_ENDPOINT 或预下载 |
| WinError 10054 | 代理中断 | 清理 HTTP_PROXY 或检查防火墙 |
✅ 八、EPGF 治理亮点
-
路径可控:工具与依赖本地化
-
环境可复现:uv.lock + pyproject.toml
-
结构可迁移:.venv 可直接打包
-
运行可治理:镜像加速 + 预下载 + 本地 uv
文档更新时间: 2025-09-19