非连续性内存分配:分页

一、帧(Frame)的核心定义
物理内存的分割单位
- 物理内存被划分为 大小相等的固定区块,称为帧(Frame)。
- 帧大小:每帧包含
2^S字节(S为帧内偏移的位数)。
示例:若S=12,则每帧大小为 4KB(2^12=4096字节)。
帧的数量
- 物理内存中帧的总数为
2^F(F为帧号的位数)。
示例:若F=20,则最多支持 1,048,576 个帧(1M帧)。
- 物理内存中帧的总数为
二、物理地址的二元组结构:(f, o)
物理地址由两个关键部分组成:
- 帧号(f)
- 作用:标识目标帧在物理内存中的位置(如第
f帧)。 - 位数:
F位 → 可寻址2^F个帧。
- 作用:标识目标帧在物理内存中的位置(如第
- 帧内偏移(o)
- 作用:定位帧内的具体字节位置。
- 位数:
S位 → 每帧包含2^S字节。
物理地址计算公式
物理地址=(2S×f)+o物理地址=(2S×f)+o
- 计算逻辑:
2^S × f:帧的起始物理地址(帧号f对应的内存基址)。+ o:在帧内进一步偏移o字节。
✅ 二进制实现:
物理地址的高F位存储帧号(f),低S位存储偏移(o),硬件可直接拼接计算地址(无需乘法运算)。
通过一个例子来更好的解释
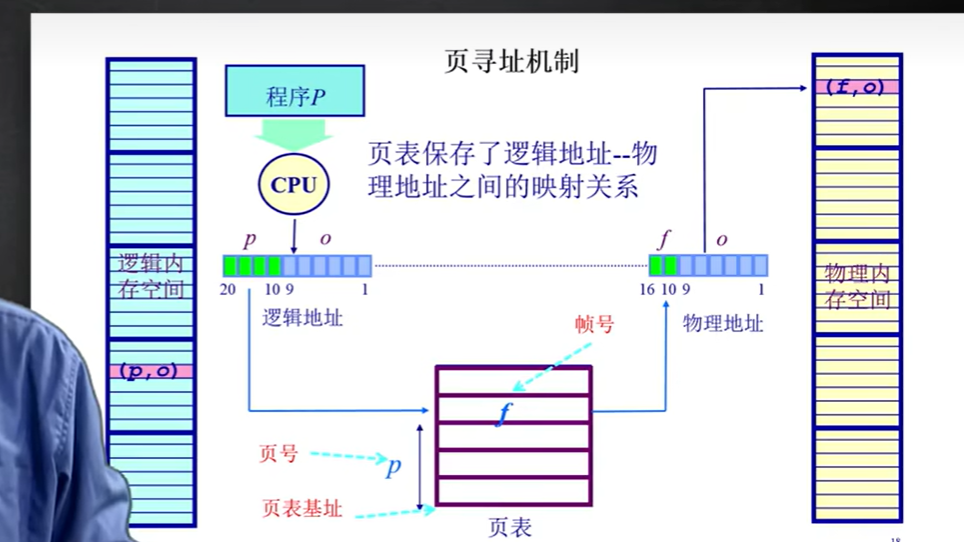
程序将页号与偏移量提交给cpu,cpu通过页号找到页表项,该页表项存储了对应的帧号,cpu此时就得到了帧号、偏移量,通过2S次方*f+o,得到物理地址
页表结构
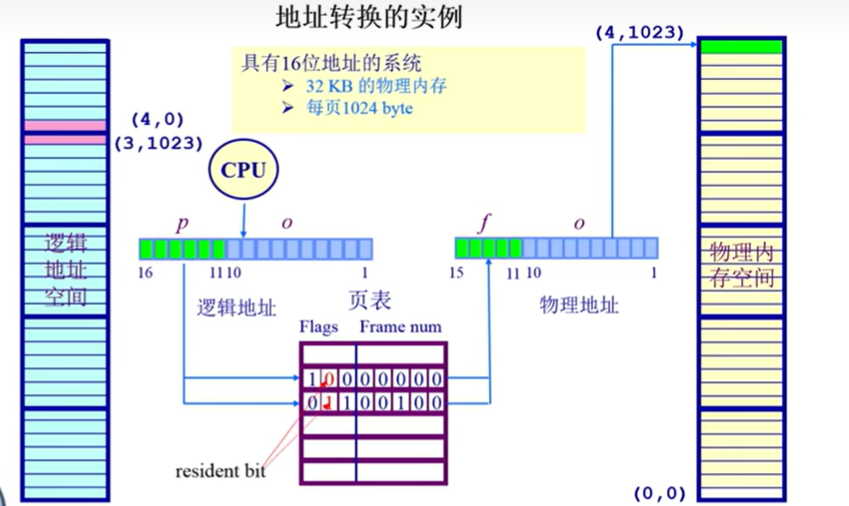
逻辑地址到物理地址的转换依赖页表(Page Table),这是操作系统维护的关键数据结构,用于记录**逻辑页(Logical Page)与物理帧(Physical Frame)**的映射关系。
具体步骤如下(结合例子中的参数:16位逻辑地址、1024字节/页、32KB物理内存):
1. 逻辑地址的结构拆分
逻辑地址(Logical Address)必然拆分为两部分: 逻辑地址=(逻辑页号 p,页内偏移量 o)逻辑地址=(逻辑页号p,页内偏移量o) 拆分规则由页大小决定:
- 页大小=1024字节(210210),因此页内偏移量o占10位(范围0~1023);
- 逻辑地址总位数=16位,因此逻辑页号p占6位(16−10=616−10=6,范围0~63)。
例如,例子中的逻辑地址**(4, 1023)**:
- p=4p=4:逻辑页号(第4个逻辑页);
- o=1023o=1023:页内偏移量(该页的最后一个字节)。
2. 页表查询:逻辑页→物理帧
每个进程都有自己的页表,页表中的每一项(Page Table Entry, PTE)对应一个逻辑页号p,记录了:
- 驻留位(Resident Bit):指示该逻辑页是否已加载到物理内存(1=在内存,0=不在);
- 物理帧号(Frame Number, f):若驻留位为1,记录该逻辑页对应的物理帧编号(即物理内存中的块编号)。
例如,例子中的逻辑页p=4,假设页表中对应的PTE的驻留位为1,物理帧号f=4(即该逻辑页加载到了物理内存的第4个帧)。
3. 物理地址的组合
物理地址(Physical Address)由物理帧号f和帧内偏移量o组合而成: 物理地址=(物理帧号 f,帧内偏移量 o)物理地址=(物理帧号f,帧内偏移量o) 其中:
- 物理帧号f:来自页表查询的结果(例子中f=4);
- 帧内偏移量o:直接复用逻辑地址的页内偏移量(例子中o=1023,与逻辑地址相同)。
因此,例子中的物理地址为: (物理帧号 4,帧内偏移量 1023)(物理帧号4,帧内偏移量1023)
4. 数值验证(可选)
物理地址的数值计算遵循公式: 物理地址数值=物理帧号×页大小+帧内偏移量物理地址数值=物理帧号×页大小+帧内偏移量 代入例子中的数值: 4×1024+1023=4096+1023=51194×1024+1023=4096+1023=5119 这与逻辑地址的数值(4×1024+1023=51194×1024+1023=5119)相同吗?不——逻辑地址的数值是逻辑页号×页大小+偏移量,但逻辑地址是“虚拟”的,物理地址是“实际”的。两者的数值可能不同,但偏移量o的数值一定相同(因为页大小=帧大小)。
页表结构可能出现的问题
页表膨胀(Page Table Bloat):内存占用过大
分页机制中,每个进程都需要维护自己的页表,而页表的大小取决于逻辑地址空间大小和页大小。
- 逻辑地址空间越大(如32位→64位),或页大小越小(如4KB→1KB),页表项(PTE)的数量就越多。 例如:32位逻辑地址空间,4KB页大小(212212字节),则逻辑页号位数为32−12=2032−12=20位,页表项数量为220=1,048,576220=1,048,576(约100万)。若每个页表项占4字节,则单个进程的页表大小为100万×4字节=4MB100万×4字节=4MB。
- 对于多进程系统(如同时运行100个进程),页表总占用内存可能达到100×4MB=400MB100×4MB=400MB,这会消耗大量物理内存。
通过TLB解决问题
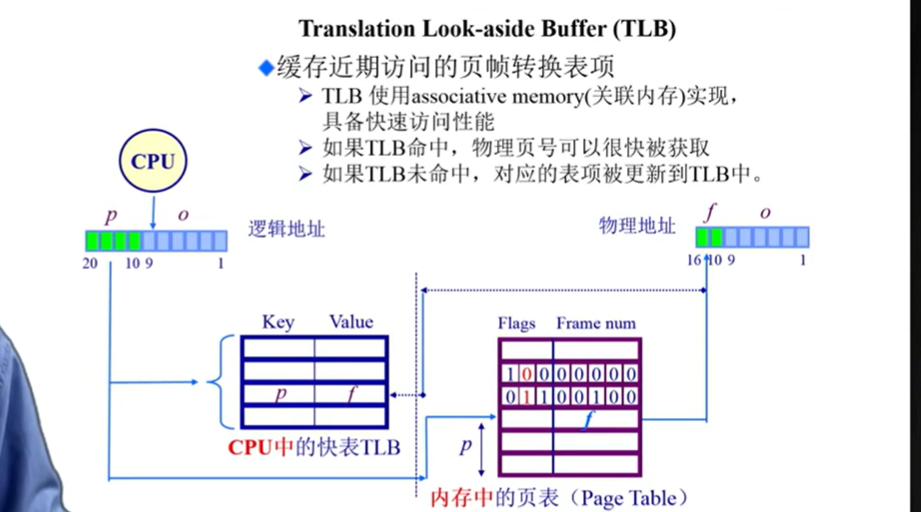
一、TLB的核心作用:加速地址转换
在分页机制中,逻辑地址→物理地址的转换需要查页表(页表位于内存中)。而内存访问速度远慢于CPU(例如,CPU缓存访问时间约1ns,内存访问约100ns),若每次转换都查页表,会导致CPU等待时间过长,严重降低性能。
TLB的出现就是为了缓存高频访问的页表项:
- 当CPU需要转换逻辑地址时,首先查TLB(CPU内部,访问时间≈1ns);
- 若TLB中存在该逻辑页号(TLB命中,TLB Hit),直接获取物理帧号,无需访问内存;
- 若TLB中不存在(TLB未命中,TLB Miss),才会访问内存中的页表,获取物理帧号,并将该映射存入TLB(替换旧项)。
二、TLB的结构与特点
TLB的结构由**关联内存(Associative Memory)**实现,这是其能快速查找的关键:
- 关联内存:又称“内容可寻址内存(CAM)”,允许按“键(Key)”并行查找(而非按地址顺序查找)。例如,TLB中的“键”是逻辑页号(p),“值”是物理帧号(f)+ 标志位(Flags);
- 并行查找:关联内存可同时检查所有TLB项的“键”,若匹配则立即返回对应的“值”,查找时间与TLB容量无关(通常≈1ns);
- 容量小:由于关联内存的成本高、功耗大,TLB容量通常很小(例如,桌面CPU的TLB容量为64~512项,服务器CPU为1024~4096项)。
三、TLB的工作流程(结合图理解)
图中展示了16位物理地址(假设)的转换过程,逻辑地址拆分,TLB与页表的交互:
1. 逻辑地址拆分
CPU生成逻辑地址,拆分为逻辑页号(p)和页内偏移(o):
- 例如,图中逻辑地址的p占10位(用于查TLB/页表),o占9位(用于定位帧内字节)。
2. TLB查找(第一步)
将逻辑页号p作为键(Key),查询TLB:
- 若命中(TLB Hit):从TLB中获取对应的物理帧号(f)和标志位(Flags,如驻留位、修改位);
- 若未命中(TLB Miss):进入“页表查询”流程(第二步)。
3. 页表查询(第二步,仅当TLB Miss时)
用逻辑页号p作为索引,访问内存中的页表(Page Table):
- 页表中的每一项(PTE)包含物理帧号(f)和标志位(Flags);
- 获取f和Flags后,将p→f的映射存入TLB(替换旧项,使用替换策略如LRU)。
4. 物理地址组合
无论通过TLB还是页表获取f,最终都将物理帧号(f)与页内偏移(o)组合,生成物理地址:
- 例如,图中物理地址的f占7位(16-9=7),o占9位,组合后得到16位物理地址。
四、TLB的关键特性
容量小,命中率依赖局部性 TLB容量小(如64项),但进程的内存访问具有局部性(时间局部性:最近访问的页可能再次访问;空间局部性:最近访问的页的相邻页可能被访问),因此TLB命中率通常很高(例如,桌面系统命中率≈90%~95%)。
替换策略 当TLB满时,需要替换旧项,常用策略:
- LRU(最近最少使用):替换最久未被访问的项(效果最好,但实现复杂);
- FIFO(先进先出):替换最早进入的项(实现简单,但可能导致“Belady异常”);
- 随机替换:随机替换一项(实现最简单,适用于局部性好的场景)。
上下文切换与TLB刷新 当进程切换时,旧进程的TLB项对新进程无效,因此需要刷新TLB(清空或标记为无效)。为了减少刷新开销,现代CPU采用地址空间标识符(ASID):
- ASID是进程的唯一标识,TLB项中添加ASID字段;
- 进程切换时,无需刷新TLB,只需检查ASID是否匹配(匹配则有效,不匹配则无效)。
在单级页表中,每个逻辑页号对应一个页表项(PTE),无论该页是否被使用,都需要为其分配页表项。例如:
- 32位逻辑地址,页大小=4KB(212212字节),则逻辑页号占32−12=2032−12=20位,单级页表项数量= 220=1,048,576220=1,048,576(约100万项);
- 若每个页表项占4字节,单级页表大小= 100万×4=4MB100万×4=4MB。
对于多进程系统(如100个进程),单级页表总内存占用= 100×4MB=400MB100×4MB=400MB,这会严重挤压用户进程的可用内存。
多级页表的核心目标:仅加载进程实际使用的页表项,减少页表的内存占用。
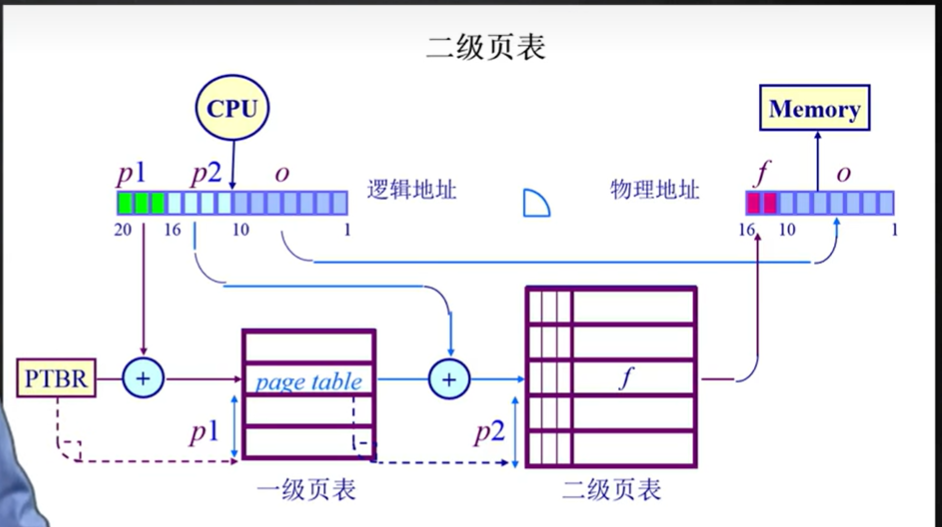
二级页表的结构
二级页表是最典型的多级页表结构,其核心思想是将逻辑页号拆分为“多级索引”,每级索引对应一级页表,仅当需要时才加载下一级页表。
1. 逻辑地址的拆分
二级页表中,逻辑地址必然拆分为三级: 逻辑地址=一级页号 (p1)+二级页号 (p2)+页内偏移 (o)逻辑地址=一级页号(p1)+二级页号(p2)+页内偏移(o) 拆分规则由页大小和页表大小决定:
- 页内偏移(o):位数=页大小的二进制位数(如页大小=1024字节→o=10o=10位);
- 二级页号(p2):位数=二级页表的大小(如二级页表有64项→p2=6p2=6位);
- 一级页号(p1):位数=总逻辑地址位数 - p2p2 - oo(如20位逻辑地址→p1=20−6−10=4p1=20−6−10=4位)。
二级页表的地址转换流程(核心)
二级页表的地址转换是分级索引的过程,具体步骤如下(结合图):
1. 逻辑地址拆分
CPU生成逻辑地址,将其拆分为一级页号(p1)、二级页号(p2)和页内偏移(o)。 例如,图中逻辑地址的p1=4位(高位)、p2=6位(中间)、o=10位(低位)。
2. 查一级页表(获取二级页表基地址)
- 一级页表的基地址:存储在PTBR中(操作系统初始化时设置);
- 一级页表项地址:PTBR+p1×页表项大小PTBR+p1×页表项大小(如页表项大小=4字节→PTBR+p1×4PTBR+p1×4);
- 取出二级页表基地址:访问一级页表项,获取该p1对应的二级页表在物理内存中的起始地址。
3. 查二级页表(获取物理帧号)
- 二级页表项地址:二级页表基地址+p2×页表项大小二级页表基地址+p2×页表项大小(如二级页表基地址+p2×4二级页表基地址+p2×4);
- 取出物理帧号(f):访问二级页表项,获取该p2对应的物理帧号(即逻辑页对应的物理内存块编号)。
基于页寄存器的方案
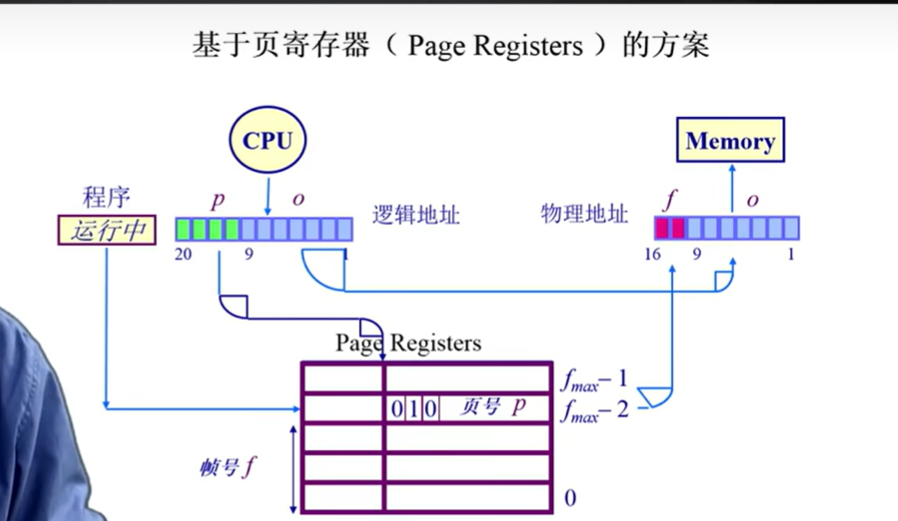
页寄存器方案的核心是按物理帧号索引(每个帧对应一个寄存器),每个寄存器存储:
- 驻留位(Residence Bit):帧是否被占用;
- 占用页号(Occupier):占用该帧的逻辑页号(p);
- 保护位(Protection Bits):访问权限。
这种结构的优势是:
- 页寄存器总大小=物理帧数量×每个寄存器大小,仅与物理内存大小相关(如16MB物理内存、4KB页大小→4096个帧,每个寄存器8字节→总大小32KB),与逻辑地址空间无关(即使逻辑地址空间是1GB,页寄存器大小仍为32KB);
- 内存占用极小(如32KB/16MB≈0.2%)。
但弊端也源于此:地址转换需要“页号→帧号”的正向映射(逻辑地址→物理地址),而页寄存器存储的是“帧号→页号”的反向映射(帧→页),因此正向查找需遍历所有帧寄存器,效率极低(如4096个帧需遍历4096次)。

- 物理帧数量:16MB物理内存,页大小4KB,共有16 MB/4 KB=409616 MB/4 KB=4096个物理帧;
- 每个帧的状态信息:每个页寄存器用8字节存储上述状态信息(驻留位、占用页号、保护位),40964096个帧需要4096×8=32768 bytes=32 KB4096×8=32768 bytes=32 KB;
- 管理逻辑:通过这32KB的页寄存器,操作系统可以跟踪所有4096个物理帧的状态(是否被占用、被哪个页占用、访问权限),从而实现逻辑页到物理帧的映射(即地址转换)。

解决“页号→帧号”正向查找的核心方案
针对正向查找的效率问题,核心思路是:在反向页表(页寄存器)之上,建立正向索引结构,缓存高频的“页号→帧号”映射,减少遍历次数。具体方案包括:
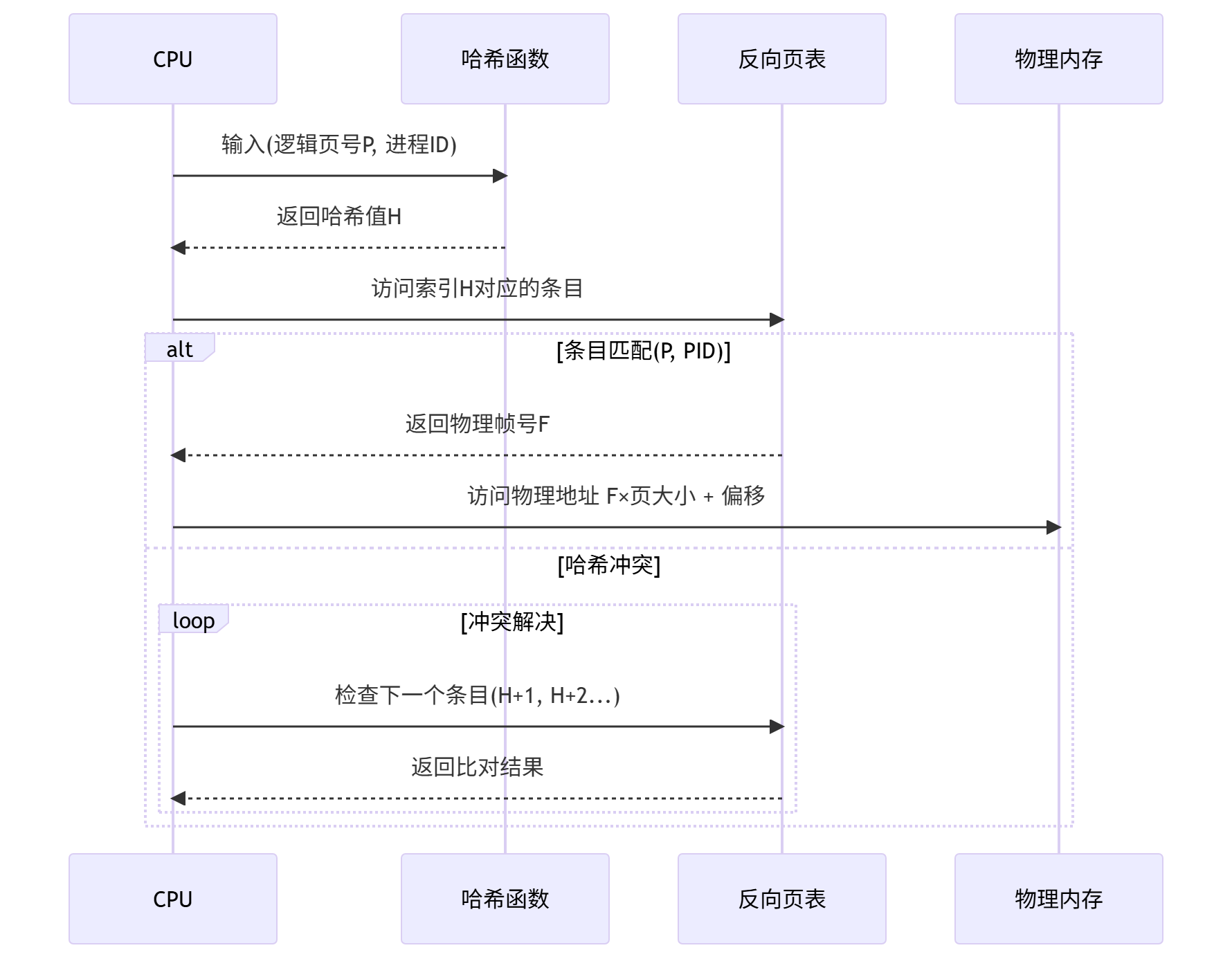
1. 方案一:使用哈希表(Hash Table)建立正向索引
原理:
- 维护一个哈希表(Hash Table),键是逻辑页号(p),值是对应的物理帧号(f);
- 当需要转换逻辑地址(p, o)时,先查哈希表:
- 若命中(哈希表中存在p→f映射),直接获取f,无需遍历页寄存器;
- 若未命中(哈希表中无p→f映射),遍历页寄存器(所有帧),找到“Occupier=p”的帧号f,然后将p→f映射存入哈希表(替换旧条目,用LRU等策略),下次再查该p时直接命中。
优势:
- 哈希表的平均查找时间为O(1)(理想情况),大幅提升正向查找效率;
- 利用进程的局部性(时间局部性:最近访问的页可能再次访问;空间局部性:最近访问的页的相邻页可能被访问),哈希表命中率极高(如桌面系统命中率≈90%~95%)。
反向页表的主要目的是减少内存消耗。帧号为索引,页号为内容。实际查找的时候还是用页号去查帧号,是用哈希函数查的。大概意思是哈希之后得到值,再用这个值去反向页表里查索引,是用时间换空间的方法
事实上反向页表也不是放在寄存器中的(太小了) 这里也是放在内存中的哈希表也是 又到了老生常谈的问题 做哈希计算时也需要去内存中取数,这又需要多次访问内存,内存的开销还是很大,所以还是可以通过缓存来解决
示例:
- 进程访问页号p=100,哈希表中存在100→f=200的映射,直接获取f=200;
- 若p=100未命中,遍历4096个页寄存器,找到“Occupier=100”的帧号f=200,将100→200存入哈希表,下次访问p=100时直接命中。
2. 方案二:使用TLB(转换检测缓冲区)缓存高频映射
原理:
- TLB(Translation Lookaside Buffer)是CPU内部的高速缓存(关联内存),用于缓存高频的“页号→帧号”映射(p→f);
- 当需要转换逻辑地址时,优先查TLB(CPU内部,访问时间≈1ns):
- 若命中(TLB中存在p→f映射),直接获取f,无需访问哈希表或页寄存器;
- 若未命中(TLB中无p→f映射),查哈希表(内存中,访问时间≈100ns);
- 若哈希表也未命中,遍历页寄存器(内存中,访问时间≈100ns×4096次→约400ms,但因局部性,这种情况极少发生)。
优势:
- TLB的访问速度极快(远快于内存中的哈希表或页寄存器),能覆盖进程的局部性访问(如循环访问的页、连续的页);
- 结合哈希表和TLB的多级缓存,可将正向查找的平均延迟降至极低(如TLB命中率90%→平均延迟=0.9×1ns + 0.1×(100ns+1ns)=11ns)。
3. 方案三:遍历反向页表( fallback )
原理:
- 当哈希表和TLB都未命中时(极端情况,如进程首次访问某个页),遍历所有页寄存器(按帧号顺序),查找“Occupier=p”的帧号f;
- 找到后,将p→f映射存入哈希表和TLB,以便后续访问快速命中。
注意:
- 遍历反向页表的时间开销极大(如4096个帧需遍历4096次,每次内存访问100ns→约400ms),但因进程的局部性(时间局部性:最近访问的页会再次访问;空间局部性:最近访问的页的相邻页会被访问),这种情况发生概率极低(如<1%),不会影响系统整体性能。