AAAI2025 | 视觉语言模型 | 西电等提出少样本语言驱动多模态分类模型DiffCLIP
论文信息
**题目:**DiffCLIP: Few-shot Language-driven Multimodal Classifier
**出版:**AAAI
**日期:**2024-12-10
第一作者:Jiaqing Zhang
通讯作者: Yunsong Li
**单位:**Xidian University, Shanghai AI Laboratory
原文链接:https://arxiv.org/abs/2412.07119
一、总结
1.1 概述
Purpose: Summarize your contributions
Style:
-What is the problem
Contrastive Language-Image Pretraining(CLIP)等视觉语言模型在分析带有语言信息的自然图像方面表现出色。然而,由于用于训练的图像-文本对数量有限,这些模型在应用于遥感等专业领域时往往会遇到挑战。
-What is the work
为了解决这个问题,我们引入了 DiffCLIP,这是一个新颖的框架,它对 CLIP 进行了扩展,能有效地传递全面的语言驱动语义信息,从而对高维多模态遥感图像进行准确分类。
-Features of the work
DiffCLIP 是一种利用未标记图像进行预训练的few-shot学习方法。它采用无监督掩模扩散学习,无需标签即可捕捉不同模态的分布。
模态共享图像编码器将多模态数据映射到一个统一的子空间中,提取具有跨模态一致参数的共享特征。well-trained图像编码器通过将视觉表征与来自 CLIP 的类标签文本信息进行对齐,进一步增强了学习效果。
-Advantages of the work
通过整合这些方法,DiffCLIP 只需使用最少的图像-文本对,就能显著提高 CLIP 的性能。
-Results
我们在广泛使用的高维多模态数据集上对 DiffCLIP 进行了评估,证明了它在处理few-shot annotated classification tasks时的有效性。与 CLIP 相比,DiffCLIP 在三个遥感数据集上的总体准确率提高了 10.65%,同时只使用了 2 张图像-文本对。
1.2 创新点
- 为高维多模态图像分类框架提供了一种少样本训练范例,探索了 CLIP 在特定少样本学习领域的潜力。
- 设计了一种无监督掩码扩散过程,以提取多种模态的共享特征,从而为将 CLIP 引入少样本学习的专业领域提供了一种稳健的视觉图像编码器。
- 提出了一个语言驱动框架,引入类标签文本信息,以加强多模态视觉图像编码器的语义信息提取,从而促进不同模态视觉表征的一致学习。
1.3 核心思想
DiffCLIP 引入掩膜操作和扩散无监督学习对视觉编码器进行预训练,然后利用文本特征驱动少样本分类,以解决将CLIP应用于遥感高维多模态数据领域时训练样本有限和迁移困难的问题。
二、研究目标
- 现存模型只关注在视觉图像维度的潜在语义空间内寻求一致性,缺乏基于视觉语言视图的联合探索
⟹\Longrightarrow⟹ 整合视觉语言跨模态特征
- CLIP等视觉语言模型遥感领域高维特征的多样性和复杂性,大规模高维图像数据集的专业可用性要求限制了高维图像的监督学习
⟹\Longrightarrow⟹ 在标注样本较少的情况下将CLIP 引入高维多模态图像分类
- 利用无监督学习知识来处理 CLIP 少量训练的问题尚未得到充分探索
⟹\Longrightarrow⟹ 提出DiffCLIP,为高维多模态遥感图像分类提供少样本训练范例的新方法
三、研究的背景以及问题陈述
3.1 Introduction
不同传感器在同一地理区域拍摄的遥感图像往往提供互补的地面特征。多模态遥感数据的联合分类利用这些互补资源的整合来提高分类的准确性。这种方法已被广泛应用于各个领域,包括城市规划、自然资源管理和环境监测等。
典型的高维遥感图像–高光谱成像(HSI)提供了丰富的高维光谱信息,可根据反射率值进行物质识别,从而为遥感图像分类提供新的多维模态信息。
**高维多模态联合表征学习的关键是如何有效利用高维光谱信息来整合和学习不同模态的特征,从而更好地理解和表征跨模态特征。**虽然每种模态都有独特的特征,但它们在语义空间中往往共享共同的信息。
然而,现存模型只关注在视觉图像维度的潜在语义空间内寻求一致性,缺乏基于视觉语言视图的联合探索。
最近,CLIP取得了显著成就,为语义分割、物体检测和三维点云理解等许多后续任务奠定了基础。CLIP 模型的最新进展主要集中在扩大模型规模和数据量、结合自监督、提高预训练效率和少样本适应等方面。
然而,当这些模型应用于遥感图像等特定领域,尤其是高维数据时,往往会遇到困难。这是因为这些模型是在自然图像上训练的,可能无法完全捕捉特定领域的多样性和复杂性。为了解决这个问题,大多数研究都集中在为每个领域构建大规模的预训练数据集,并进行额外的微调阶段,以适应医疗、电子商务和遥感领域的下游任务。
然而,大规模高维图像数据集的专业可用性要求限制了高维图像的监督学习。因此,一个自然而然的问题出现了:我们能否避免收集和标注数据的成本,在标注样本较少的情况下将 CLIP 引入高维多模态图像分类?
遗憾的是,利用无监督学习知识来处理 CLIP 少量训练的问题尚未得到充分探索。
为了克服这一问题,本文提出了 DiffCLIP,一种为高维多模态遥感图像分类提供少样本训练范例的新方法。
首先采用掩膜扩散无监督学习法来捕捉各种视觉图像模态的分布,而无需依赖标签。为了提高模型提取语义信息的能力,引入了掩膜操作和扩散过程。这种操作有助于稀疏表示输入数据,减少多模态遥感数据中冗余信息的干扰,并加快训练速度。通过利用具有共享参数的视觉图像编码器,将多模态数据映射到一个共享子空间,并通过两个特定模态解码器进行掩码还原。这将重建输入的视觉图像模态,以捕捉不同模态的特定属性。整个编码和解码过程被集成到一个去噪扩散模型中,该模型具有很强的隐式学习能力,有助于应对巨大模态差距造成的重建困难。
语言驱动的少样本分类是一种文本特征驱动的监督学习过程,训练有素的视觉图像编码器使 CLIP 能够有效利用少样本标签文本信息进行监督。不同模态的语义信息与文本编码器获得的类标签文本信息保持一致,从而促进了不同模态视觉表征的一致性学习。与离散标签值相比,它提供了更全面的语义信息表征。利用语言驱动方法有助于模型捕捉复杂数据分布中丰富的内在语义细节,从而提高分类性能。
在几个下游任务上的广泛实验证明了所提出的 DiffCLIP 的有效性。具体来说,在Houston数据集上,DiffCLIP 使用未标记的patch样本作为无监督掩码扩散预训练数据集,并利用转换器作为图像文本编码器,在 2-shot分类任务中取得了 52.15% 的总体准确率,比直接使用 ViT-B-14 进行预训练的基线 CLIP 高出 16.32%。
3.2 Related work
Vision-language pre-training (VLP)尽管对大量自然图像样本进行了训练,但 VLM 在捕捉遥感等专业领域的多样性和复杂性方面表现出了困难,阻碍了在这些领域的直接应用。这些领域的数据通常稀缺,可访问性有限,并且需要专家注释,因此获取图像文本对进行 VLM 训练具有挑战性。
少样本学习旨在使模型能够在未见类别中利用有限的标注样本有效地学习和适应新任务。然而,目前的少样本方法主要集中于单模态任务,缺乏对多模态应用的讨论。CLIP 通过在大量图像-文本对上进行预训练,展示了令人印象深刻的少拍分类能力。尽管 CLIP 很有效,但它们对特定领域的适应性,尤其是在数据有限的情况下,如少样本遥感任务,仍未得到充分研究。
四、模型详解
4.1 概述
所提出的 DiffCLIP 是一种少样本学习方法,旨在通过使用掩膜扩散对图像编码器进行无监督训练来学习不同模态的共享特征,然后在文本语义监督的指导下匹配图像特征的表示。该方法可解决高维多模态少样本遥感图像分类问题。
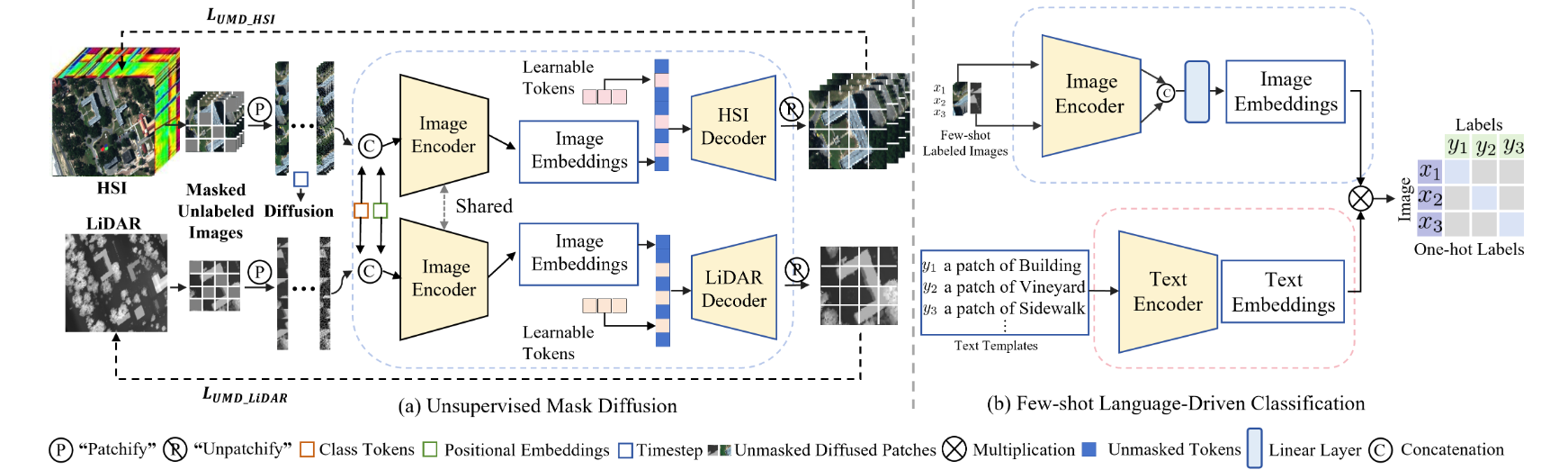
DiffCLIP 框架包括两个主要阶段:
a) 无监督掩码扩散:模态共享图像编码器捕捉两种模态的一致特征,而两种特定模态解码器整合语义提示和独特特征;
b) 少样本学习: DiffCLIP 对模态共享编码器进行了微调,并采用语言方法来传达全面的语义信息。这种方法有助于捕捉复杂数据分布中固有的丰富语义信息。
无监督学习阶段包括两个部分:正向掩膜扩散和反向去噪恢复。为了降低扩散模型的训练成本,采用的策略是只对训练数据集的一个子集进行采样,并应用正向掩膜扩散。在反向去噪修复中,采用共享图像编码器来学习多模态共享特征。此外,还设计了两个特定模态解码器,以捕捉不同模态的特定属性。
少样本学习阶段是一个语言驱动的监督学习过程,与离散标签值相比,它能提供更全面的语义信息表征。这种更丰富的语义背景有助于模型捕捉复杂数据分布中存在的细微差别,从而提高分类性能。此外,为了简洁起见,在大多数情况下,我们只介绍单模态输入的公式,因为它们通常适用于两种模态。
五、实验方法
5.1 数据集
Houston, Trento , MUUFL and MRNet dataset.
5.2 实验环境
NVIDIA GeForce RTX A100 GPU.
在无监督学习和少样本学习的优化过程中,Adam优化器的初始学习率为 1e-4,权重衰减为 1e-5。
使用了两个schedulers:用于无监督学习的cosine scheduler和用于少样本学习的step scheduler。
无监督学习为 100 个epochs,少样本学习为 150 个epochs。
为确保在比较实验中获得最佳性能,无监督学习的批次大小设置为 256,少样本学习的批次大小设置为 64,所有数据集的参数设置保持一致。
5.3 实验结果

六、结论
提出的 DiffCLIP 为高维多模态少样本遥感图像分类引入了一种新模式,解决了该领域训练样本有限所带来的挑战。
DiffCLIP 利用无监督掩模扩散预训练将多模态数据转换为共享子空间,用于学习多模态共享特征。它通过特定模态解码器保持特定模态特征,并能在少量训练样本的情况下有效运行。这种方法为少样本学习提供了稳健的图像特征编码器,同时还降低了计算成本。DiffCLIP 的一个重要方面是利用语言驱动方法来传达全面的语义信息。这有助于模型捕捉复杂数据分布中丰富的内在语义细节。通过将文本特征与视觉特征相结合,DiffCLIP 促进了多模态信息的融合,从而提高了分类性能。在基准数据集上取得的结果证明了所提出方法的有效性和稳健性。
论文信息
**题目:**DiffCLIP: Few-shot Language-driven Multimodal Classifier
**出版:**AAAI
**日期:**2024-12-10
第一作者:Jiaqing Zhang
通讯作者: Yunsong Li
**单位:**Xidian University, Shanghai AI Laboratory
原文链接:https://arxiv.org/abs/2412.07119
一、总结
1.1 概述
Purpose: Summarize your contributions
Style:
-What is the problem
Contrastive Language-Image Pretraining(CLIP)等视觉语言模型在分析带有语言信息的自然图像方面表现出色。然而,由于用于训练的图像-文本对数量有限,这些模型在应用于遥感等专业领域时往往会遇到挑战。
-What is the work
为了解决这个问题,我们引入了 DiffCLIP,这是一个新颖的框架,它对 CLIP 进行了扩展,能有效地传递全面的语言驱动语义信息,从而对高维多模态遥感图像进行准确分类。
-Features of the work
DiffCLIP 是一种利用未标记图像进行预训练的few-shot学习方法。它采用无监督掩模扩散学习,无需标签即可捕捉不同模态的分布。
模态共享图像编码器将多模态数据映射到一个统一的子空间中,提取具有跨模态一致参数的共享特征。well-trained图像编码器通过将视觉表征与来自 CLIP 的类标签文本信息进行对齐,进一步增强了学习效果。
-Advantages of the work
通过整合这些方法,DiffCLIP 只需使用最少的图像-文本对,就能显著提高 CLIP 的性能。
-Results
我们在广泛使用的高维多模态数据集上对 DiffCLIP 进行了评估,证明了它在处理few-shot annotated classification tasks时的有效性。与 CLIP 相比,DiffCLIP 在三个遥感数据集上的总体准确率提高了 10.65%,同时只使用了 2 张图像-文本对。
1.2 创新点
- 为高维多模态图像分类框架提供了一种少样本训练范例,探索了 CLIP 在特定少样本学习领域的潜力。
- 设计了一种无监督掩码扩散过程,以提取多种模态的共享特征,从而为将 CLIP 引入少样本学习的专业领域提供了一种稳健的视觉图像编码器。
- 提出了一个语言驱动框架,引入类标签文本信息,以加强多模态视觉图像编码器的语义信息提取,从而促进不同模态视觉表征的一致学习。
1.3 核心思想
DiffCLIP 引入掩膜操作和扩散无监督学习对视觉编码器进行预训练,然后利用文本特征驱动少样本分类,以解决将CLIP应用于遥感高维多模态数据领域时训练样本有限和迁移困难的问题。
二、研究目标
- 现存模型只关注在视觉图像维度的潜在语义空间内寻求一致性,缺乏基于视觉语言视图的联合探索
⟹\Longrightarrow⟹ 整合视觉语言跨模态特征
- CLIP等视觉语言模型遥感领域高维特征的多样性和复杂性,大规模高维图像数据集的专业可用性要求限制了高维图像的监督学习
⟹\Longrightarrow⟹ 在标注样本较少的情况下将CLIP 引入高维多模态图像分类
- 利用无监督学习知识来处理 CLIP 少量训练的问题尚未得到充分探索
⟹\Longrightarrow⟹ 提出DiffCLIP,为高维多模态遥感图像分类提供少样本训练范例的新方法
三、研究的背景以及问题陈述
3.1 Introduction
不同传感器在同一地理区域拍摄的遥感图像往往提供互补的地面特征。多模态遥感数据的联合分类利用这些互补资源的整合来提高分类的准确性。这种方法已被广泛应用于各个领域,包括城市规划、自然资源管理和环境监测等。
典型的高维遥感图像–高光谱成像(HSI)提供了丰富的高维光谱信息,可根据反射率值进行物质识别,从而为遥感图像分类提供新的多维模态信息。
**高维多模态联合表征学习的关键是如何有效利用高维光谱信息来整合和学习不同模态的特征,从而更好地理解和表征跨模态特征。**虽然每种模态都有独特的特征,但它们在语义空间中往往共享共同的信息。
然而,现存模型只关注在视觉图像维度的潜在语义空间内寻求一致性,缺乏基于视觉语言视图的联合探索。
最近,CLIP取得了显著成就,为语义分割、物体检测和三维点云理解等许多后续任务奠定了基础。CLIP 模型的最新进展主要集中在扩大模型规模和数据量、结合自监督、提高预训练效率和少样本适应等方面。
然而,当这些模型应用于遥感图像等特定领域,尤其是高维数据时,往往会遇到困难。这是因为这些模型是在自然图像上训练的,可能无法完全捕捉特定领域的多样性和复杂性。为了解决这个问题,大多数研究都集中在为每个领域构建大规模的预训练数据集,并进行额外的微调阶段,以适应医疗、电子商务和遥感领域的下游任务。
然而,大规模高维图像数据集的专业可用性要求限制了高维图像的监督学习。因此,一个自然而然的问题出现了:我们能否避免收集和标注数据的成本,在标注样本较少的情况下将 CLIP 引入高维多模态图像分类?
遗憾的是,利用无监督学习知识来处理 CLIP 少量训练的问题尚未得到充分探索。
为了克服这一问题,本文提出了 DiffCLIP,一种为高维多模态遥感图像分类提供少样本训练范例的新方法。
首先采用掩膜扩散无监督学习法来捕捉各种视觉图像模态的分布,而无需依赖标签。为了提高模型提取语义信息的能力,引入了掩膜操作和扩散过程。这种操作有助于稀疏表示输入数据,减少多模态遥感数据中冗余信息的干扰,并加快训练速度。通过利用具有共享参数的视觉图像编码器,将多模态数据映射到一个共享子空间,并通过两个特定模态解码器进行掩码还原。这将重建输入的视觉图像模态,以捕捉不同模态的特定属性。整个编码和解码过程被集成到一个去噪扩散模型中,该模型具有很强的隐式学习能力,有助于应对巨大模态差距造成的重建困难。
语言驱动的少样本分类是一种文本特征驱动的监督学习过程,训练有素的视觉图像编码器使 CLIP 能够有效利用少样本标签文本信息进行监督。不同模态的语义信息与文本编码器获得的类标签文本信息保持一致,从而促进了不同模态视觉表征的一致性学习。与离散标签值相比,它提供了更全面的语义信息表征。利用语言驱动方法有助于模型捕捉复杂数据分布中丰富的内在语义细节,从而提高分类性能。
在几个下游任务上的广泛实验证明了所提出的 DiffCLIP 的有效性。具体来说,在Houston数据集上,DiffCLIP 使用未标记的patch样本作为无监督掩码扩散预训练数据集,并利用转换器作为图像文本编码器,在 2-shot分类任务中取得了 52.15% 的总体准确率,比直接使用 ViT-B-14 进行预训练的基线 CLIP 高出 16.32%。
3.2 Related work
Vision-language pre-training (VLP)尽管对大量自然图像样本进行了训练,但 VLM 在捕捉遥感等专业领域的多样性和复杂性方面表现出了困难,阻碍了在这些领域的直接应用。这些领域的数据通常稀缺,可访问性有限,并且需要专家注释,因此获取图像文本对进行 VLM 训练具有挑战性。
少样本学习旨在使模型能够在未见类别中利用有限的标注样本有效地学习和适应新任务。然而,目前的少样本方法主要集中于单模态任务,缺乏对多模态应用的讨论。CLIP 通过在大量图像-文本对上进行预训练,展示了令人印象深刻的少拍分类能力。尽管 CLIP 很有效,但它们对特定领域的适应性,尤其是在数据有限的情况下,如少样本遥感任务,仍未得到充分研究。
四、模型详解
4.1 概述
所提出的 DiffCLIP 是一种少样本学习方法,旨在通过使用掩膜扩散对图像编码器进行无监督训练来学习不同模态的共享特征,然后在文本语义监督的指导下匹配图像特征的表示。该方法可解决高维多模态少样本遥感图像分类问题。
DiffCLIP 框架包括两个主要阶段:
a) 无监督掩码扩散:模态共享图像编码器捕捉两种模态的一致特征,而两种特定模态解码器整合语义提示和独特特征;
b) 少样本学习: DiffCLIP 对模态共享编码器进行了微调,并采用语言方法来传达全面的语义信息。这种方法有助于捕捉复杂数据分布中固有的丰富语义信息。
无监督学习阶段包括两个部分:正向掩膜扩散和反向去噪恢复。为了降低扩散模型的训练成本,采用的策略是只对训练数据集的一个子集进行采样,并应用正向掩膜扩散。在反向去噪修复中,采用共享图像编码器来学习多模态共享特征。此外,还设计了两个特定模态解码器,以捕捉不同模态的特定属性。
少样本学习阶段是一个语言驱动的监督学习过程,与离散标签值相比,它能提供更全面的语义信息表征。这种更丰富的语义背景有助于模型捕捉复杂数据分布中存在的细微差别,从而提高分类性能。此外,为了简洁起见,在大多数情况下,我们只介绍单模态输入的公式,因为它们通常适用于两种模态。
五、实验方法
5.1 数据集
Houston, Trento , MUUFL and MRNet dataset.
5.2 实验环境
NVIDIA GeForce RTX A100 GPU.
在无监督学习和少样本学习的优化过程中,Adam优化器的初始学习率为 1e-4,权重衰减为 1e-5。
使用了两个schedulers:用于无监督学习的cosine scheduler和用于少样本学习的step scheduler。
无监督学习为 100 个epochs,少样本学习为 150 个epochs。
为确保在比较实验中获得最佳性能,无监督学习的批次大小设置为 256,少样本学习的批次大小设置为 64,所有数据集的参数设置保持一致。
5.3 实验结果
六、结论
提出的 DiffCLIP 为高维多模态少样本遥感图像分类引入了一种新模式,解决了该领域训练样本有限所带来的挑战。
DiffCLIP 利用无监督掩模扩散预训练将多模态数据转换为共享子空间,用于学习多模态共享特征。它通过特定模态解码器保持特定模态特征,并能在少量训练样本的情况下有效运行。这种方法为少样本学习提供了稳健的图像特征编码器,同时还降低了计算成本。DiffCLIP 的一个重要方面是利用语言驱动方法来传达全面的语义信息。这有助于模型捕捉复杂数据分布中丰富的内在语义细节。通过将文本特征与视觉特征相结合,DiffCLIP 促进了多模态信息的融合,从而提高了分类性能。在基准数据集上取得的结果证明了所提出方法的有效性和稳健性。