用 JMeter 打通“异步入队 + 网关限流”的高并发压测实践
目标:在不打穿下游的前提下,验证入口链路的高并发承载能力,并形成可复制的压测脚本。
一、为什么要先压“入队链路”?
很多系统的重任务(报表、地图/视频处理、机器人调度等)都会走 “请求→入消息队列→异步消费” 的模式。
上线前必须回答三个问题:
峰值请求能不能稳稳接住?
网关限流能不能把洪峰挡在外面?
队列是否按预期累积,不触发级联雪崩?
本实践选择 Dry-Run + 禁用消费者 的“用法 A”:
请求只入队,不真正执行耗时任务;
既能压出真实入口 QPS,又不会把下游打穿;
观测面(SkyWalking/RabbitMQ/JMeter)一样齐全。
二、压测目标与环境
目标:100 QPS × 3 分钟(可 50→100→200 QPS 梯度爬坡)
接口:
POST /external/gs/async/_mqSmoke(创建“烟囱任务”,仅入队)网关策略:必须带
X-Dry-Run:true,否则 403;命中限流返回 429观测:SkyWalking(
ruoyi-gateway、ruoyi-robot),RabbitMQ 控制台,JMeter 报表结果判定:JMeter Error%≈0;SW SuccessRate≈100%、Apdex 高;RabbitMQ Ready 累积
三、脚本结构(可直接照抄)
3.1 Test Plan 变量(User Defined Variables)
BASE_SCHEME=http
BASE_HOST=localhost
BASE_PORT=8080 # 或直连 9300
SUBMIT_PATH=/xxxxxx/_mqSmoke
POLL_PATH=/xxxxxxx
AUTH_HEADER=
POLL_INTERVAL_MS=1200
MAX_POLLS=20
提示:A 策略通常不启用轮询;只压入队链路。
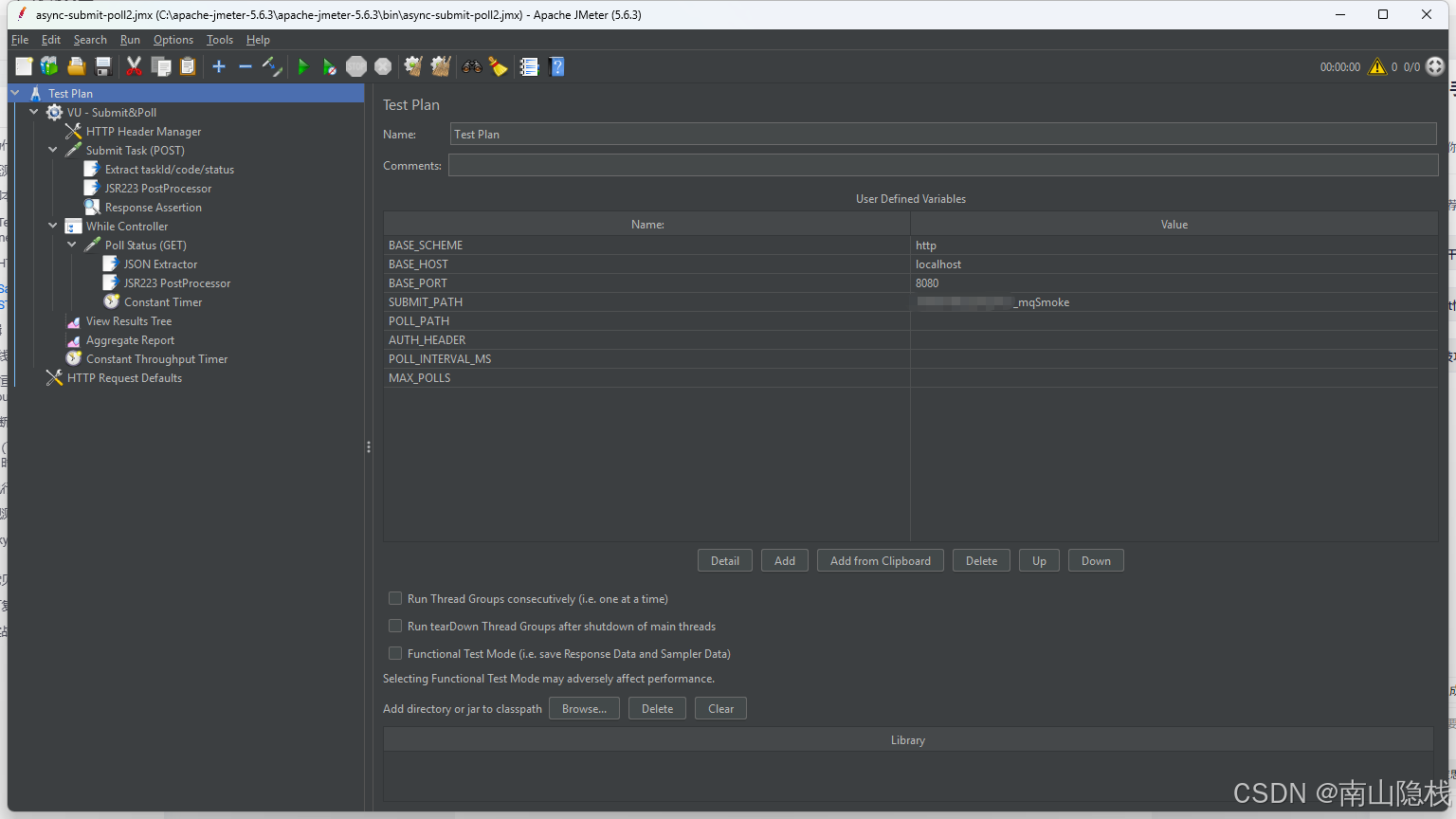
3.2 HTTP Header Manager
Content-Type: application/jsonX-Request-Id: ${__UUID()}Authorization: ${AUTH_HEADER}(如需)X-Dry-Run: true← 关键
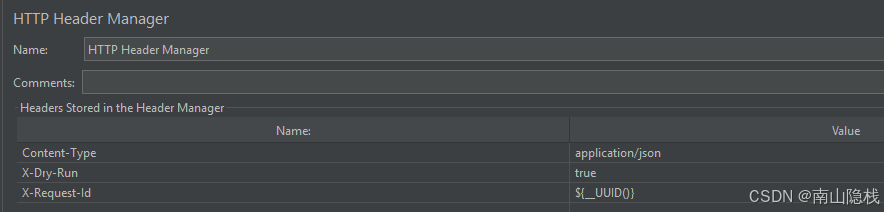
3.3 Sampler:Submit Task (POST)
Path:
${SUBMIT_PATH}Body:
{"xxxxx":"dummy","taskName":"mq-smoke"}
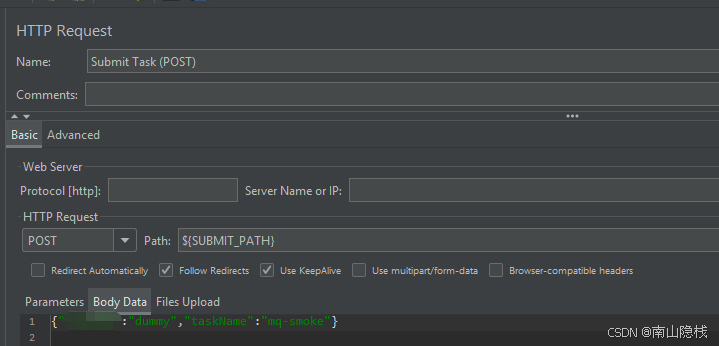
3.4 线程组(Thread Group)
调试:Threads=5, Ramp-up=10s, Loop Count=1
正式:Threads=50, Ramp-up=60s,勾选 Specify Thread lifetime → Duration=180s
3.5 恒定吞吐定时器(Constant Throughput Timer)
Target throughput (samples per minute) = 6000(≈100 QPS)Calculate Throughput based on = this thread group only
小公式:目标 QPS × 60 = 每分钟样本数。比如 100 QPS ⇒ 6000 samples/min。

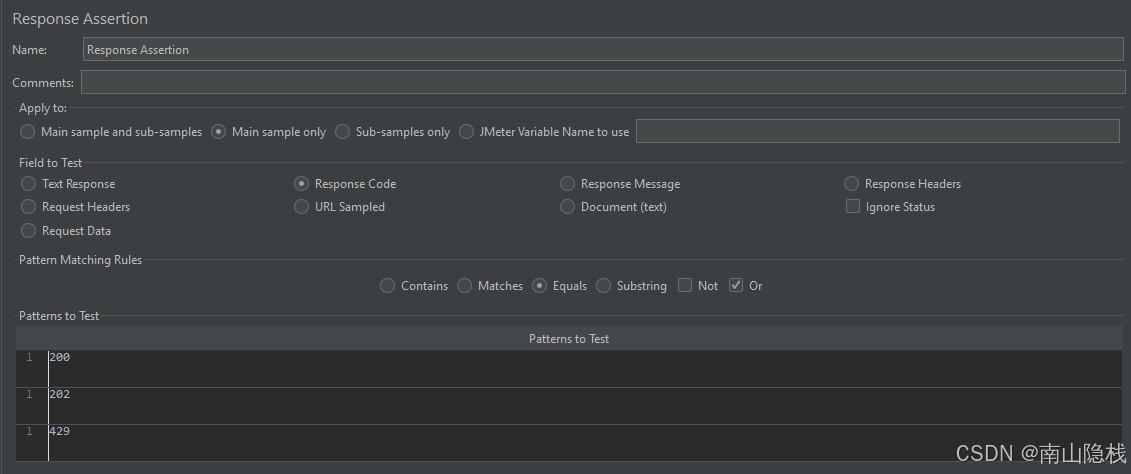
3.6 断言与 429 处理
Response Assertion:Response Code 允许
200 / 202 / 429JSR223 PostProcessor 将 429 记为成功:
if (prev.getResponseCode() == '429') { prev.setSuccessful(true) }
3.7(可选)轮询逻辑(非 Dry-Run 时用)
JSON Extractor:
变量:xxxx
JsonPath:
xxxxxxx
While Controller 条件:
${__groovy((vars.get('done')!='true') && ((vars.get('polls') as int ?: 0) < (${MAX_POLLS} as int)))}
轮询定时器:Constant Timer → ${POLL_INTERVAL_MS}
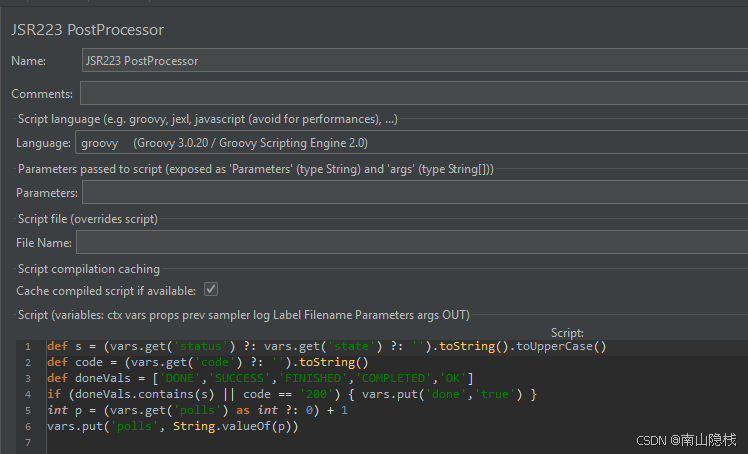
JSR223 PostProcessor:
def s = (vars.get('status') ?: vars.get('state') ?: '').toString().toUpperCase()
def code = (vars.get('code') ?: '').toString()
def doneVals = ['DONE','SUCCESS','FINISHED','COMPLETED','OK']
if (doneVals.contains(s) || code == '200') { vars.put('done','true') }
int p = (vars.get('polls') as int ?: 0) + 1
vars.put('polls', String.valueOf(p))
四、执行步骤
预热(1 分钟 / 5 线程)
JMeter View Results Tree 绿灯;
SW“服务列表/端点负载”出现。
正式压测(100 QPS × 3 分钟)
打开 Aggregate Report;
同时观看Skywalking
RabbitMQ 队列
robot.tempTask.q,Ready 累积曲线。
非 GUI 推荐(更稳)
jmeter -n -t async-submit-poll.jmx -l result.jtl -e -o html
五、观测与判读
JMeter
关注
#Samples / Average / P95 / P99 / Error% / Throughput。示例(多轮实测):Error%=0,P95≈6ms,P99≈9–10ms,Throughput≈41–100/sec(视目标而定)。

SkyWalking
关注 Service Load(calls/min)、Success Rate、Apdex、P95/P99。
示例:
ruoyi-gatewayLoad ≈ 2300–2900/min,Success 100%,Apdex≈0.83–0.94;ruoyi-robotLoad ≈ 2800–4700/min,Success 100%,Apdex≈1.0。

RabbitMQ
A 策略下消费者禁用,Ready 持续累积是预期;Unacked≈0。
六、SkyWalking“防自杀”设置(很关键)
压测期间,观测系统太“勤奋”也会被打爆,建议:
Java Agent(
agent.config增量)sample_n_per_3_secs=10 trace.ignore_path=/external/gs/async/_mqSmoke采样降低到“每 3 秒 ~10 条”,并忽略高频压测路径。

2.OAP Server 内存(Windows 示例)
set SW_OAP_OPTIONS=-Xms512m -Xmx1024m -XX:+UseG1GC
bin\oapService.bat stop
bin\oapService.bat start
3.UI 时间范围
只看“今天”,避免渲染大量历史数据变卡。
七、常见问题与排错清单
Q1:另一台机器跑出来 Success 只有 50%,Apdex 0.3~0.4?
A:一般是本机资源/网络/观测开销导致:
JMeter 用 GUI 跑 + 开很多监听器,CPU 飙高;
网络丢包/代理/防火墙;
没有把 429 记为成功;
SW 采样太高/OAP 内存太小;
网关策略不一致(是否强制 Dry-Run?是否命中限流?)。
Q2:SW 过 2 分钟就“白屏/转圈”?
降采样(见上),忽略高频路径;
给 OAP 多点内存;
缩短 UI 时间窗口。
Q3:JMeter 吞吐达不到配置的 QPS?
Threads 不够、Ramp-up 太短、Timer 作用域不对;
脚本夹了多余“思考时间”;
机器顶不住:CPU/内存/网络/磁盘。
Q4:网关 403?
确认头
X-Dry-Run: true;未带头被路由策略拦截是对的。
Q5:换一台电脑,为什么 SkyWalking 上看到的成功率、Apdex、负载和上一台不一样?
现象:同一套后端与脚本,不同压测机跑出来的 SW 成功率/Apdex/Load 有明显差异,甚至一台高、一台低。
根因分类 & 快速排查:
压测端(JMeter)差异
GUI 监听器过多、开着 View Results Tree/Graphs,CPU 抢占高 → 真实吞吐达不到配置值。
机器性能/电源模式不同(省电/节能模式、CPU 频率被限)。
Java/JMeter 版本/JVM 参数不同,GC/HTTP 堆栈差异。
脚本细节不一致:线程数、Ramp-up、Constant Throughput Timer 的“作用域”不是 this thread group only,或 429 未被标记为成功(JMeter 与 SW 统计口径不一致)。
建议:非 GUI 模式运行
jmeter -n ...;只保留 Aggregate Report;固定 Java 版本;核对 .jmx 差异;把 429 设为成功。
网络路径差异
一台走 公司代理/本机代理/VPN、一台直连;DNS 解析落到不同网关实例;丢包/抖动导致重传与超时。
建议:两机都
tracert/ping网关;禁用代理/VPN;固定目标 IP;同时抓一小段tcpdump/Wireshark看重传/RTT。
SkyWalking 观测口径差异
时间窗口不同(另一台选了更大范围或不是“今天”);筛选条件(实例/端点)不同。
采样率不同:另一台机器或另一环境的
sample_n_per_3_secs/sampleRate不一致;或者没有trace.ignore_path,导致 UI/存储压力大,指标被稀释或 UI 卡顿。OAP 内存不足/存储后端压力大 → 指标迟到/掉点。
建议:两边统一时间范围(Today + 同步 NTP),清空所有筛选;统一 Agent 配置(采样 + 忽略压测路径),OAP 增内存(例如
-Xms512m -Xmx1024m);必要时只看压测时段 2–5 分钟窗口。
网关/服务端策略差异
限流/熔断/鉴权配置在不同实例不一致;请求头(如
X-Dry-Run:true/Authorization)在一台机器未携带导致 403/429 比例变化。建议:抓包或开启网关 access log 校验请求头;对比实例配置;将压测流量固定到同一实例(临时关闭负载均衡或用权重/灰度)。
时钟偏差与统计口径
压测机与 SW/OAP 时钟不同步,导致“每分钟调用数(Load)”按窗口聚合时分桶不齐。
建议:所有机器启用 NTP;SW UI 选择近实时小窗口(例如最近 5 分钟)。
一键对齐清单(两台压测机都做):
用 非 GUI 模式跑,Aggregate Report 保存到文件;
检查
.jmx完全一致(线程/Timer 作用域/断言/429 处理);固定 Java 版本,关闭省电模式;
统一 Agent 配置:
sample_n_per_3_secs=10、trace.ignore_path=/external/gs/async/_mqSmoke;OAP:
-Xms512m -Xmx1024m -XX:+UseG1GC,UI 只看“今天/最近 5 分钟”;关闭代理/VPN,固定网关实例或检查负载均衡;
所有节点开启 NTP 对时。
结论:压测端供给能力 + 网络路径 + 观测采样/窗口 是造成 SW 指标差异的三大源头。把三者对齐后,两台机器的曲线会非常接近。
八、可复用产物
async-submit-poll.jmx:线程组 + 恒定吞吐 + Header + POST +(可选)轮询/断言/JSR223网关路由与限流规则:
/external/gs/async/**+ 强制X-Dry-Run:true+ 统一 429SW 配置片段:
sample_n_per_3_secs、trace.ignore_path、OAP JVM 参数
九、实战结论
在“Dry-Run + 禁消费”的保护模式下,入口链路稳定撑住 100 QPS×3min:
JMeter Error%=0,P95/P99 低;
网关/业务 Success≈100%、Apdex 高;
RabbitMQ Ready 按预期累积,无 Unacked 积压。