更符合人类偏好的具身导航!HALO:面向机器人导航的人类偏好对齐离线奖励学习
作者:Gershom Seneviratne, Jianyu An, Sahire Ellahy, Kasun Weerakoon, Mohamed Bashir Elnoor, Jonathan Deepak Kannan, Amogha Thalihalla Sunil, Dinesh Manocha
单位:马里兰大学
论文标题:HALO: Human Preference Aligned Offline Reward Learning for Robot Navigation
论文链接:https://arxiv.org/pdf/2508.01539v1
项目主页:https://gamma.umd.edu/researchdirections/crowdmultiagent/halo/
主要贡献
提出了离线奖励学习算法 HALO,通过人类偏好对机器人导航进行奖励建模,无需手工设计奖励函数。
设计了基于 Plackett-Luce 损失的偏好驱动奖励学习框架,能够利用人类对导航动作的二元可行性反馈来训练奖励模型,并将其应用于离线策略学习和基于模型预测控制(MPC)的规划器中,展示了在多样化室内外环境中的泛化能力。
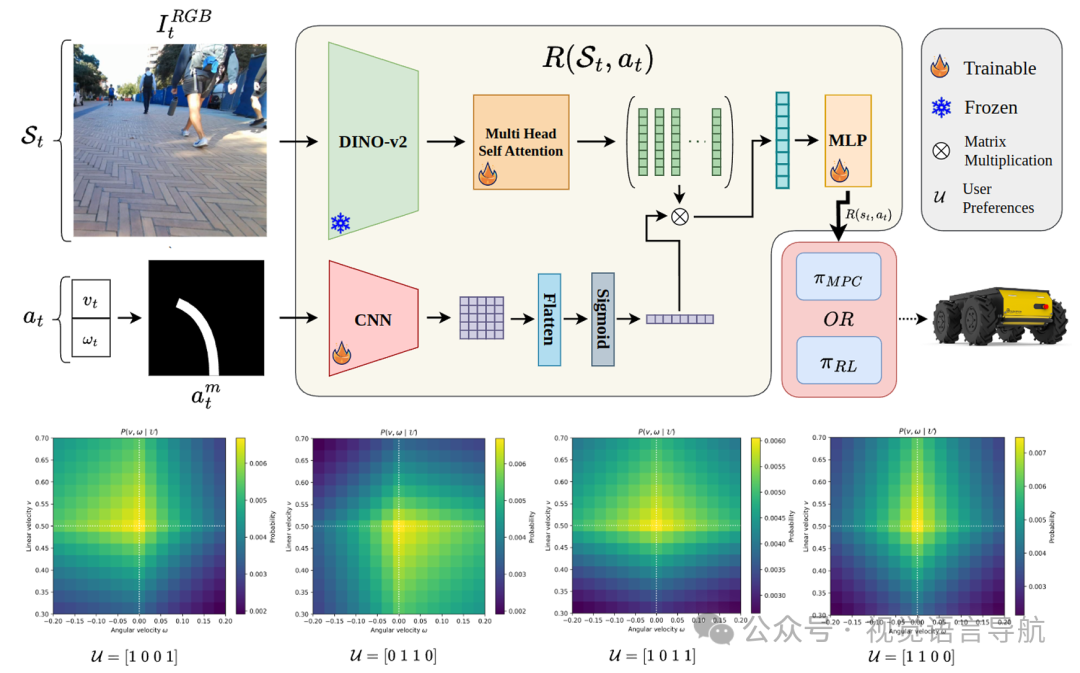
提出了动作条件下的视觉特征聚合机制,通过基于同胚变换生成的轨迹掩码来识别图像中与轨迹相关的空间区域,使模型能够基于预期轨迹聚合高度相关的图像信息。
在 Clearpath Husky 机器人平台上进行了广泛的现实世界评估,证明了 HALO 在多种未见环境中都能有效泛化,并且在成功率、归一化轨迹长度和与专家轨迹的 Fréchet 距离等指标上优于现有的基于视觉的导航方法。
研究背景
自主导航是移动机器人在复杂现实环境中运行的基本能力。传统系统通常依赖激光雷达或立体相机等深度传感器来估计几何形状和避障,但这些传感器成本高、功耗大、硬件复杂,限制了其在机器人平台上的可扩展性。相比之下,RGB 相机是一种低成本且易于部署的感知方式,但仅基于 RGB 输入构建可靠的导航系统具有挑战性,尤其是在动态光照、路径模糊或地形不规则的情况下,难以直接从原始视觉观测中推断出可导航性和障碍物的相关性。
强化学习(RL)在导航方面展现出了巨大潜力,允许机器人通过与环境的直接交互(在线 RL)来学习并根据经验数据进行适应。然而,许多在线 RL 方法在模拟环境中训练时存在从模拟到现实(sim-to-real)的转移差距,导致在现实世界环境中泛化能力不足。为了解决这一问题,近期的研究利用大规模导航数据集进行离线 RL 训练,使机器人能够直接从现实世界观测中学习,无需在线交互。
尽管如此,无论是在线还是离线 RL 方法,通常都依赖于手工设计的奖励函数,这需要大量的领域专业知识来识别关键组成部分并将其数学形式化,且奖励函数必须经过精心调整,往往需要多轮现实世界的训练和测试,这是一个成本高且资源密集型的过程。此外,许多基于 RL 的导航算法还依赖于激光雷达或深度相机在奖励计算过程中估计障碍物距离,这进一步增加了传感器成本和部署难度,限制了其可扩展性。
背景知识
马尔可夫决策过程
机器人导航可以建模为一个马尔可夫决策过程(MDP),其由连续状态空间 、动作空间 、转移函数 、奖励函数 和折扣因子 组成。
表示所有可能的环境配置。
是机器人可用的动作集合。
定义了在状态 下执行动作 后到达状态 的概率。
为在状态 下执行动作 的即时奖励。
平衡了即时奖励与未来奖励的重要性,影响长期导航行为。
策略 将每个状态映射到动作上的概率分布。最优策略 是最大化期望累积奖励的策略,用于指导有效的机器人导航。
离线强化学习
离线强化学习(Offline RL)允许从固定数据集中学习策略,无需进一步与环境交互,适用于探索成本高或不安全的场景。
Offline RL 面临的主要挑战包括数据分布与学习策略之间的不匹配(分布偏移)、Q 值对未见状态的过估计(外推误差)以及价值估计不准确性的传播(引导误差)。
如保守 Q 学习(Conservative Q-Learning, CQL)和隐式 Q 学习(Implicit Q-Learning)等算法,旨在解决上述挑战。
Plackett-Luce 模型用于偏好建模
Plackett-Luce 模型是一种用于偏好建模的概率框架。给定一组动作 和相应的分数 ,观察到特定排序 的概率定义为:
该模型将分数转换为排名概率分布,通过指数化分数并逐步归一化,能够捕捉排名中所有候选动作的相对重要性。
HALO 方法
数据集
使用 Socially Compliant Navigation Dataset (SCAND) 进行离线训练,包含在室内和室外环境中,由人类操作员通过遥控方式操作轮式或腿式机器人在德克萨斯大学奥斯汀分校校园内导航的演示数据。
从 139 个场景中手动标注了 25 个场景(约 107,000 帧)的人类偏好分数。
额外收集了 116 个场景(约 33,000 帧),其中约 100 个是会导致碰撞或不安全行为的短截断轨迹,作为负样本以引导奖励模型学习更安全的行为。
奖励学习问题的表述
将人类对齐的导航建模为 MDP,专注于从离线数据中学习一个奖励函数 ,该函数能够根据人类的导航偏好来评估动作的质量。
动作空间 由连续的控制命令组成,表示线速度和角速度对 。
状态空间 由机器人的 egocentric RGB 相机观测 组成。
奖励模型与目标无关,仅基于 egocentric 视觉输入来量化动作的质量。
基于人类反馈的偏好分数
人类反馈:通过收集人类对五个基于机器人 egocentric 视图和专家动作的导航查询的二元响应来捕捉人类直觉,这些查询包括“机器人能否左转”“能否右转”“能否加速”“能否减速”以及“机器人是否处于危险或表现次优”。
动作偏好分数:根据用户反馈生成离散的、动态可行的动作集,并为每个动作分配基于其与参考动作接近程度的概率分数,使用可分离的 Boltzmann 分布来计算:其中,温度值 和 根据用户偏好 适应性选择,以确保偏好方向获得足够的概率质量。
最终偏好分数:通过一个标量因子 调整,以反映用户对场景的期望可取性:最终偏好分数为:
基于 Plackett-Luce 损失的偏好数据奖励模型学习
Plackett-Luce 损失:使用 Plackett-Luce 模型来学习奖励函数,通过最小化 Plackett-Luce 排名概率的负对数似然,确保学习到的奖励函数与人类偏好一致:该损失函数能够将分数转换为排名概率分布,通过指数化分数并逐步归一化,避免了成对比较方法所需的大量比较,从而得到更稳定的损失景观和高效的优化。
奖励模型架构
图像特征提取:使用 DINOv2 提取输入图像的 patch 级嵌入,输出 个空间 patch 嵌入,每个嵌入的维度为 。这些嵌入进一步通过 层 Transformer 层进行细化。
动作条件下的视觉特征聚合:给定一个动作 ,通过同胚变换将机器人在该动作下会遵循的路径投影到图像平面上,生成二值轨迹掩码 。该掩码通过一个轻量级 CNN 处理后得到空间相关性图 ,用于调制 DINOv2 的 patch 嵌入,使模型能够强调与给定动作相关的图像区域。
最终奖励预测:聚合后的特征表示通过一个简单的 MLP 头直接映射为标量奖励值。
训练和离线导航策略
训练:在训练过程中,为了提高奖励学习的稳定性和泛化能力,加入了两个正则化策略:焦点式惩罚和多样性正则化。焦点式惩罚通过加权均方误差(MSE)来惩罚较大的奖励误差,多样性正则化通过惩罚奖励差异过小的动作对来鼓励模型为不相似的动作分配更不同的奖励。
应用:训练好的奖励模型可以用于监督目标条件下的离线策略,或者作为经典导航算法(如动态窗口方法 DWA 或模型预测控制 MPC)的额外成本项。
结果与分析
实施与比较
实验平台:在 Clearpath Husky 机器人平台上进行现实世界实验,该机器人配备了 Realsense d435i 相机和搭载 Intel i7 处理器及 NVIDIA RTX 3060 GPU 的笔记本电脑。
对比方法:将 HALO 奖励模型与手工设计的奖励(HER)模型进行比较,同时设计了基于 HER 的 IQL 策略和行为克隆(BC)策略,并与经典方法 DWA 和学习型视觉动作方法 VANP 进行对比。
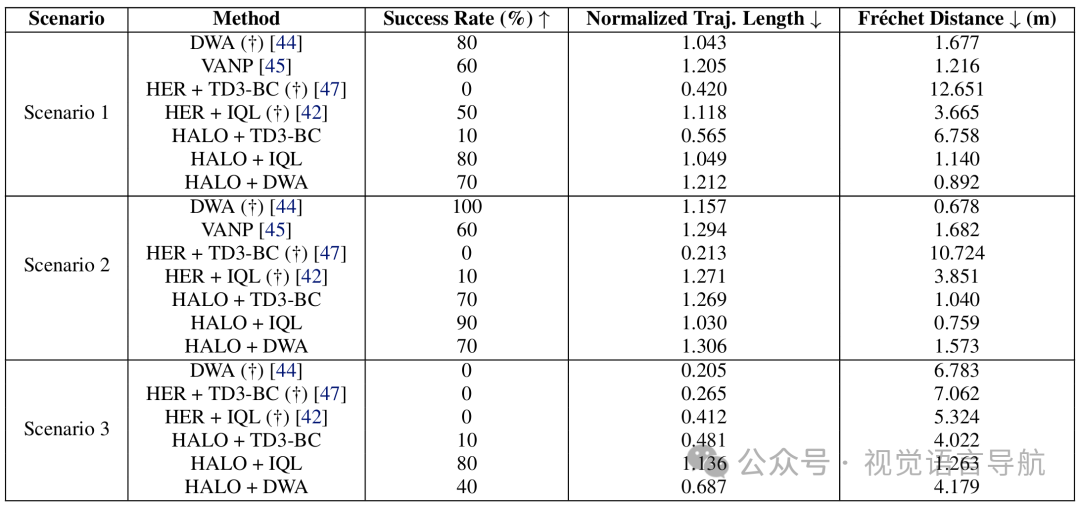
评估指标
成功率:机器人在没有碰撞的情况下到达目标的次数比例。
归一化轨迹长度:执行轨迹长度与专家轨迹长度的比率,越低越好。
Fréchet 距离:机器人轨迹与专家轨迹之间的最大距离,越低越好。
讨论
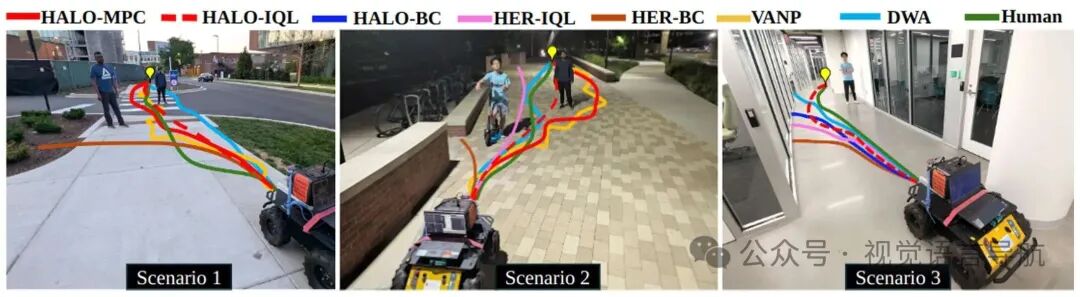
实验结果:
在三种不同的现实世界导航场景(户外、低光照、室内)中,HALO 基策略在成功率和 Fréchet 距离方面均优于基线方法,展现出更好的安全性和与人类偏好对齐的轨迹生成能力,且无需依赖激光雷达或手工设计的奖励。
在场景 1 中,HALO + DWA 方法能够产生更平滑、更符合社交规范的轨迹,其 Fréchet 距离和成功率均优于仅依赖激光雷达感知的 DWA 规划器,而 HALO + IQL 方法也展现出社交合规性,成功率与 DWA 方法相当,但不依赖激光雷达。
在场景 2 中,HALO + DWA 方法在保持社交规范方面表现出色,通过在行人周围保持较大的缓冲半径来实现,即使这意味着需要在经过行人后调整航向以重新朝向目标。HALO + IQL 和 HALO + BC 策略虽然成功率较高,但在社交合规性方面表现稍差,倾向于采取更直接的路径,更接近行人。
在场景 3 中,基于激光雷达的方法如 DWA 在室内环境中遇到玻璃墙时会失败,而 HALO 基策略能够成功识别玻璃墙和行人,并有效地导航穿过走廊以到达目标。
结论:HALO 作为一种新颖的离线奖励学习算法,能够通过人类偏好将机器人导航与人类直觉对齐,无需手工设计奖励函数,且在多种现实世界环境中展现出优越的性能,具有良好的泛化能力。
结论与未来工作
结论:
HALO 作为一种新颖的离线奖励学习算法,能够通过人类偏好将机器人导航与人类直觉对齐,无需手工设计奖励函数,且在多种现实世界环境中展现出优越的性能,具有良好的泛化能力。
该方法在成功率、轨迹安全性和与专家轨迹的 Fréchet 距离等指标上均优于现有的基于视觉的导航方法,证明了其在不同机器人平台和环境中的有效性。
然而,该方法也存在一些局限性,如在训练和测试过程中缺乏可解释性,模型性能可能不稳定,且对光照条件较为敏感。此外,由于该方法基于视觉的奖励模型具有有限的视野范围,机器人可能会出现物体永久性的现象,即在障碍物离开视野后,机器人可能会再次转向障碍物,导致碰撞。
未来工作:
未来的工作可以关注提高模型的可解释性和稳定性,进一步优化在不同光照条件下的性能,并探索如何解决机器人对自身尺寸缺乏意识以及视野有限导致的问题,以进一步提升 HALO 在复杂环境中的导航性能和安全性。
