《RocketMQ 2025 实战指南:从消息丢失 / 重复消费 / 顺序消费到事务消息,一篇搞定生产级问题(附完整代码)》
目录
场景
如何避免消息丢失
生产者发送到broker:
broker对数据进行持久化的过程
消费者拿到消息之后消费的过程
如何保障消息顺序消费
如何避免重复消费
常见解决方案:
方案1:利用消息的唯一标识(比如 Key / 业务 ID)做去重
方案2:利用数据库唯一约束 / 去重表
方案3:业务状态机 / 幂等操作设计
如何处理消息重放
如何实现延迟队列
实现自定义延时时间的方案:
1. 数据库 + 定时任务扫描
2. Redis Sorted Set(ZSet) + 定时任务
3. 时间轮算法 (Hashed Timing Wheel)
负载均衡
生产者负载均衡
1. 默认负载均衡策略
2. 自定义队列选择策略
消费者负载均衡
1. 消费者负载均衡策略
2. 重平衡(Rebalance)过程
Broker 负载均衡
1. Topic 队列分布
2. 读写分离
事务消息
进阶
消息积压
产生积压的原因:
1. 消费速度 < 生产速度(最常见原因)
2. 消费者出现故障或停止
3. 消费者未能正确ACK(确认)
4. Topic 的队列数(MessageQueue)太少
5. 突发流量 / 流量洪峰
处理消息积压
1. 短期应急:快速消费积压消息
(1)增加消费者实例(横向扩容)
(2)提高单消费者消费能力
(3)临时跳过非关键消息(视业务而定)
2. 中长期优化:架构与配置优化
(1)增加 Topic 的 MessageQueue 数量
(2)优化消费者组负载均衡
(3)控制生产速率(限流 / 降级)
3. 监控与告警:提前发现积压
持久化
持久化机制
1. CommitLog(提交日志)—— 所有消息的最终存储地
2. ConsumeQueue(消费队列)—— 消费的逻辑视图 / 索引
二者关系(图示理解):
刷盘策略
1. 异步刷盘(ASYNC_FLUSH,默认)
2. 同步刷盘(SYNC_FLUSH)
消息过滤
长轮询机制
1. 传统轮询(Short Polling / 轮询)是什么?
2. 长轮询(Long Polling)是什么?
那它是如何实现说当一个请求进来之后,把请求hold起来的呢?
1. PullRequest 的数据结构
2. 挂起请求:将 PullRequest 放入一个 “待处理队列”
类名:org.apache.rocketmq.broker.longpolling.PullRequestHoldManager
3. 如何挂起请求(不立即返回)?
伪代码逻辑(简化):
4. 何时唤醒被挂起的请求?
场景 1:有新消息写入到某个 MessageQueue
唤醒操作:
5. 超时处理:如果一直没新消息怎么办?
6. Netty 非阻塞模型 + 异步调度
自己编写类似的异步响应代码
消息消费模式之推/拉模式
拉模式(Pull Consumer)详解
什么是拉模式?
拉模式的特点
底层实现原理(拉模式)
推模式(Push Consumer)详解
你可能一直以为:Push 模式是服务端主动把消息推过来,对吧?
推模式的特点
底层实现原理(推模式)
为什么 RocketMQ 不做真正的“服务端推送”?
原因主要包括:
重试队列
死信队列
广播机制/集群机制
集群机制
定义
特点:
应用场景:
示例:
广播模式
定义:
特点:
应用场景:
示例:
批量消息
场景
如何避免消息丢失
首先就是要分析一下rocketmq在那些地方会出现消息丢失

主要有几个缓解可能会出现消息丢失
- 生产者发送到broker
- broker对数据进行持久化的过程
- 消费者拿到消息之后消费的过程
生产者发送到broker:
生产者发送到broker的过程中,可能会出现网络波动或是服务宕机或是突然 触发Full GC
解决的这个问题的方法需要通过代码控制加配置调整,核心思路就是“自动重试+最终一致”
核心配置:
retryTimesWhenSendFailed:设置同步发送模式下的重试次数(默认值为 2)。retryTimesWhenSendAsyncFailed:设置异步发送模式下的重试次数(默认值为 2)。retryAnotherBrokerWhenNotStoreOK:当发送结果未明确成功时(如返回未知状态),是否尝试发送到其他 Broker(默认为 false)。在集群环境下,开启此配置能进一步提升容错能力。设置了之后,当你send() 的时候,它的工作流程就是:
- 尝试发送消息。
- 如果失败(抛出异常或返回非成功状态),它会等待一小段时间(可退避)。
- 换一个路由地址(比如另一个 Broker 地址)再次尝试发送。
- 重复步骤 2 和 3,直到达到你设置的重试次数上限。
这个过程对你的业务代码是透明的,你不需要在代码中写 for 循环来重试。
代码控制:
配置了重试并不代表消息就 100% 发出去了。如果重试了所有次数后仍然失败,客户端会抛出异常。
你必须在你自己的业务代码中捕获这个异常并进行处理。
try {Message msg = new Message("TopicTest", "TagA", "Hello RocketMQ".getBytes(RemotingHelper.DEFAULT_CHARSET));// 此send方法调用会触发内部的重试机制SendResult sendResult = producer.send(msg);// 【关键】检查发送结果状态if (sendResult.getSendStatus() == SendStatus.SEND_OK) {System.out.println("消息发送成功!MsgId: " + sendResult.getMsgId());} else {// 通常不会进入这里,除非得到明确的状态如FLUSH_DISK_TIMEOUT等log.warn("消息发送状态异常: {}", sendResult.getSendStatus());// 这里可以加入你的降级处理逻辑,例如存入数据库、写入本地文件等saveToDBForRetry(msg);}
} catch (MQClientException e) {// 通常是客户端配置错误、找不到Topic等错误,重试也无用log.error("客户端异常,消息发送失败", e);// 需要人工介入排查
} catch (RemotingException e) {// 网络异常,可能已经触发了内部重试,但最终还是失败了log.error("网络异常,消息发送失败,已重试{}次", producer.getRetryTimesWhenSendFailed(), e);// 加入你的降级处理逻辑saveToDBForRetry(msg);
} catch (MQBrokerException e) {// Broker返回的错误,例如:无权写入、Topic不存在等log.error("Broker处理异常,错误代码: {}", e.getResponseCode(), e);// 需要根据错误码判断是否重试,或者人工介入
} catch (InterruptedException e) {log.error("发送被中断", e);// 恢复中断状态Thread.currentThread().interrupt();
} catch (Exception e) {// 其他未知异常log.error("未知异常,消息发送失败", e);// 加入你的降级处理逻辑saveToDBForRetry(msg);
}
// 发送消息的代码片段
Message msg = new Message("ORDER_TOPIC", "PAY_TAG", orderId, orderInfoJson.getBytes());// 附带业务ID,便于后续追踪和补偿
String businessId = "ORDER_" + orderId;
msg.putUserProperty("biz_id", businessId);producer.send(msg, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {// 1. 发送成功:理想情况,记录日志即可log.info("消息发送成功! MsgId: {}, BizId: {}", sendResult.getMsgId(), businessId);// 可选:如果之前有补偿记录,可以在这里将其删除// compensationService.deleteCompensationRecord(businessId);}@Overridepublic void onException(Throwable e) {// 2. 【核心】最终发送失败:所有重试后仍失败,必须在此处进行降级处理log.error("消息最终发送失败,进入降级流程。业务ID: {}, 错误信息: {}", businessId, e.getMessage(), e);// 降级方案:以下三种根据业务可靠性要求选择一种或多种// 方案一(最低保障):记录错误日志并触发告警(如钉钉、短信、邮件),通知人工介入处理。alertService.sendAlert("消息发送失败告警", "业务ID: " + businessId, e);// 方案二(推荐:高可靠性):将消息持久化到“补偿表”try {// 将消息的核心内容、业务ID、目标Topic、创建时间等存入数据库MessageFailoverRecord record = new MessageFailoverRecord();record.setBizId(businessId);record.setTopic(msg.getTopic());record.setTags(msg.getTags());record.setBody(new String(msg.getBody()));record.setRetryCount(0);record.setStatus("TO_BE_RETRY");messageFailoverService.saveRecord(record); // 存入数据库log.info("消息已降级存入数据库等待补偿, BizId: {}", businessId);} catch (Exception dbException) {// 如果连落库都失败了,这是最坏的情况,必须用最高级别告警log.error("消息落库也失败了!消息可能彻底丢失!BizId: {}", businessId, dbException);alertService.sendUrgentAlert("消息落库失败", "业务ID: " + businessId);}// 方案三(简易版):如果不想引入数据库,可以写入本地文件(可靠性稍差)// localFileWriter.writeFailedMessage(businessId, msg);}
});@Component
public class AsyncMessageCompensationTask {@Scheduled(fixedDelay = 60000) // 每60秒执行一次public void retryFailedMessages() {// 1. 从数据库查询状态为“TO_BE_RETRY”且重试次数小于阈值的记录List<MessageFailoverRecord> toRetryList = messageFailoverService.getToRetryRecords(5); // 最多重试5次for (MessageFailoverRecord record : toRetryList) {try {// 2. 将数据库记录重建为RocketMQ的Message对象Message retryMsg = new Message(record.getTopic(), record.getTags(), record.getBody().getBytes());// 3. 使用同步发送进行重试!补偿任务追求可靠性,应该用同步。SendResult result = producer.send(retryMsg);// 4. 如果发送成功,删除或更新数据库中的记录状态为“COMPENSATED_SUCCESS”messageFailoverService.updateStatus(record.getId(), "COMPENSATED_SUCCESS");log.info("补偿消息发送成功, BizId: {}", record.getBizId());} catch (Exception e) {// 5. 如果补偿发送也失败,更新记录的重试次数+1messageFailoverService.increaseRetryCount(record.getId());log.error("补偿消息发送失败, BizId: {}, 重试次数: {}", record.getBizId(), record.getRetryCount() + 1, e);}}}
}最后的建议就是如果是一些要求强可靠性的话,尽量使用同步发送,会比较可靠和好处理一点
broker对数据进行持久化的过程
主要会有以下两个环节会出现问题
- Broker 节点宕机(内存丢失):Broker 接收到消息后,默认会先写入内存的 PageCache(操作系统的页面缓存),然后由后台线程异步地刷写到磁盘。如果在这个过程中 Broker 突然宕机或断电,内存中尚未刷盘的消息就会全部丢失。
- 磁盘损坏(单点故障):即使消息已经成功写入磁盘,如果该 Broker 节点的磁盘发生物理损坏,且消息没有在其他地方留有备份(副本),那么消息也会永久丢失。
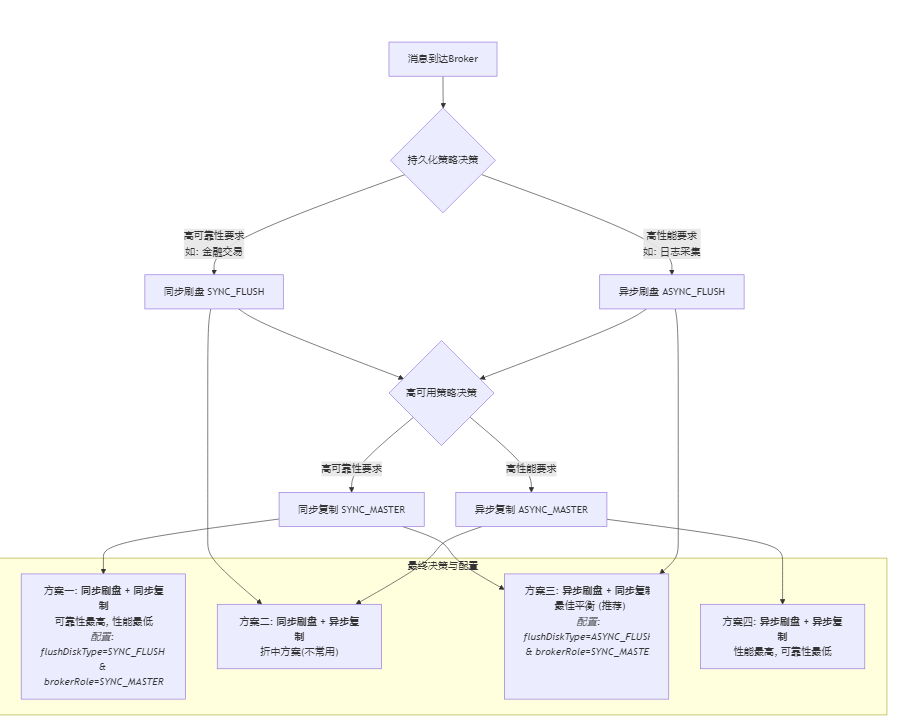
解决broker进行数据存储的过程中出现的错误问题,主要通过配置来进行解决,这两个问题最好的解决方法其实都是搭建可靠的集群环境,然后再调整对应的配置,才能减少数据丢失的可能
两个配置就是刷盘策略和复制策略
刷盘就是把数据同步到磁盘中,有同步和异步两种;复制就是把数据从主节点复制到从节点,也是有同步和异步两种
刷盘策略(FlushDiskType)
- 异步刷盘 (ASYNC_FLUSH):
工作机制:Broker 将消息写入 PageCache 后就立即向生产者返回成功响应。刷盘操作由后台线程定期(如每秒一次)批量完成。
优点:性能极高,吞吐量大。
缺点:有丢失消息的风险。如果 Broker 宕机,上次刷盘之后写入 PageCache 的消息都会丢失。
配置:在 broker.conf 文件中设置 flushDiskType = ASYNC_FLUSH (此为默认值)。
- 同步刷盘 (SYNC_FLUSH):
工作机制:Broker 会等待消息真正被写入磁盘后,才向生产者返回成功响应。
优点:可靠性极高。只要返回成功,消息就一定落在磁盘上了,即使宕机也不会丢失。
缺点:性能较差,延迟更高,因为每次写入都要等待磁盘 I/O。
配置:在 broker.conf 文件中设置 flushDiskType = SYNC_FLUSH。
简单比喻:
异步刷盘:就像你在 Word 里写文档,写的内容会先缓存在内存中,Word 会定时帮你点一下保存。
同步刷盘:就像你每敲一个字,就手动按一次 Ctrl + S 保存,确保每个字都立刻存到硬盘上。
复制策略 (BrokerRole)
此配置决定了 Master Broker 如何将消息复制到 Slave Broker,用于防止单点磁盘损坏,保证高可用。
- 异步复制 (ASYNC_MASTER):
工作机制:Master 收到消息并持久化后,就立即向生产者返回成功,然后再异步地将消息复制给 Slave。
优点:性能好,延迟低。
缺点:如果消息还没复制到 Slave,Master 就磁盘损坏了,消息会丢失。
配置:brokerRole = ASYNC_MASTER
- 同步复制 (SYNC_MASTER):
工作机制:Master 会等待至少一个 Slave 成功复制并持久化消息后,才向生产者返回成功。
优点:高可用。只要 Master/Slave 不同时宕机,消息就不会丢。即使 Master 磁盘损坏,Slave 上还有完整的数据。
缺点:延迟会稍高一些,因为它要等待网络 Round-Trip Time (RTT)。
配置:brokerRole = SYNC_MASTER
简单比喻:
异步复制:就像你给同事发邮件,点击“发送”后就认为成功了,不管对方什么时候收到。
同步复制:就像你发邮件后,必须等到对方的“已读回执”,才认为发送成功。
常见的使用场景及选择
| 场景 | 推荐配置组合 | 说明 |
| 金融交易、资金扣减 | 同步刷盘 (SYNC_FLUSH) + | 最可靠的配置。消息在返回成功前,已在多个节点的磁盘上留存。性能最低。 |
| 绝大多数业务场景 | 异步刷盘 (ASYNC_FLUSH) + | 最佳平衡点。即使单个 Master 节点磁盘损坏,消息在 Slave 上也有备份(因为复制是同步的)。利用异步刷盘保证高性能。这是生产环境最常用的配置。 |
| 日志采集、 metrics 数据 | 异步刷盘 (ASYNC_FLUSH) + | 性能最高,但存在消息丢失风险。适用于可容忍少量数据丢失的场景。 |
消费者拿到消息之后消费的过程
消费者在进行消息消费的时候也是会出现消息丢失的问题的,最常见的就是拿到消息之后就发送了消费确认,结果消息还没开始消费就挂了
从Consumer角度分析,如何保证消息被成功消费?
- Consumer保证消息成功消费的关键在于确认的时机,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。因为消息队列维护了消费的位置,逻辑执行失败了,没有确认,再去队列拉取消息,就还是之前的一条。
主要的问题就出在确认的时机
解决的思路:
- 不要使用自动ACK,而是手动ACK
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {for (MessageExt msg : msgs) {try {// 1. 解析消息String messageBody = new String(msg.getBody(), StandardCharsets.UTF_8);// 2. 执行核心业务逻辑(这里是可能出错的地方)boolean businessResult = processBusiness(messageBody);if (!businessResult) {// 2.1 如果业务逻辑执行失败(如扣款失败),主动要求重试log.error("业务处理失败,请求重试。msgId: {}", msg.getMsgId());return ConsumeConcurrentlyStatus.RECONSUME_LATER;}// 2.2 业务成功,继续处理下一条消息log.info("业务处理成功。msgId: {}", msg.getMsgId());} catch (Exception e) {// 3. 【关键】捕获所有异常,防止异常抛出导致没有返回任何状态log.error("处理消息发生未知异常,请求重试。msgId: {}", msg.getMsgId(), e);return ConsumeConcurrentlyStatus.RECONSUME_LATER;}}// 4. 只有这批消息全部处理成功,才返回SUCCESSreturn ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});在执行完所有的业务逻辑之后才进行ACK确认,并且执行过程中出现错误也要返回对应的标识
- 保证消费逻辑的幂等性
private boolean processBusiness(String messageBody) {// 解析出业务的唯一标识,比如订单IDString orderId = parseOrderId(messageBody);// 1. 在执行业务前,先查询是否已经处理过(快,但非绝对可靠)// if (orderService.isOrderProcessed(orderId)) {// return true; // 已处理过,直接返回成功// }// 2. 【推荐】直接执行业务SQL,利用数据库唯一键约束防止重复try {// 例如:INSERT INTO orders (order_id, status, ...) VALUES (?, ?, ...);// 其中order_id是唯一索引orderService.createOrder(orderId, ...);return true;} catch (DuplicateKeyException e) {// 如果捕获到唯一键冲突异常,说明是重复消息,直接视为成功log.warn("订单已存在,可能是重复消息,orderId: {}", orderId);return true;}
}消息丢失不只是出现在消息进行消费之前,也可能是在消费之后,去发送ACK的时候,消息丢失了,导致broker接收不到ACK确认,误以为消费失败,导致重复消费的问题,所以我们的业务代码里面也要做好幂等判断
常见的就是借助一些中间件进行判断,不是绝对可靠,但是性能好;如果是要求极高的可靠性的话,可以使用数据库的唯一索引来判断,但是也要搭配上其他的方案
- 监控与告警
这点应该更多的是运维老哥来处理的。
监控消息的堆积情况和重试次数。如果发现某个Topic的消息不断重试却始终无法成功消费(重试次数 reconsumeTimes 很高),说明消费逻辑可能出了严重Bug,需要立即告警并人工介入处理。
RocketMQ默认会重试16次,如果16次都失败,消息会被投递到一条叫做%DLQ%<consumerGroup>的死信队列(Dead-Letter Queue) 中。你需要监控死信队列,它里面都是需要紧急处理的“疑难杂症”消息。
- 优化我们的消费处理代码的逻辑
有时候消息其实并没有丢失,而是“迟到”了,可能就是我们的消费逻辑中包含了比较多很重的操作,导致超时了,broker误以为是消息丢失了,或是执行失败了,又重新进行投递,这个时候靠前面第二点的保证消费幂等性就没什么用了,因为你可能会出现多次执行的结果都是超时,但是每一次来都发现已经执行过了
解决的方式:优化消费的代码;一些比较重的操作如果允许的情况下用异步任务后台去跑(这个看业务允不允许)
如何保障消息顺序消费
顺序消费就是让消息按照一定的顺序进行消费,而不是交错的消费(消费顺序和胜场顺序一致)
常见的场景就是订单系统,生成订单,用户付款,订单发货,这几个步骤是需要顺序性的
顺序消费要分成是局部顺序性还是全局顺序性,但是其实原理都是一样的
保证顺序性需要从发送端和消费端一起来控制,发送端需要把这些需要保证顺序性的消息发送到同一个MessageQueue中,然后消费端需要顺序的去读取这个队列中的消息(不能并发读取)
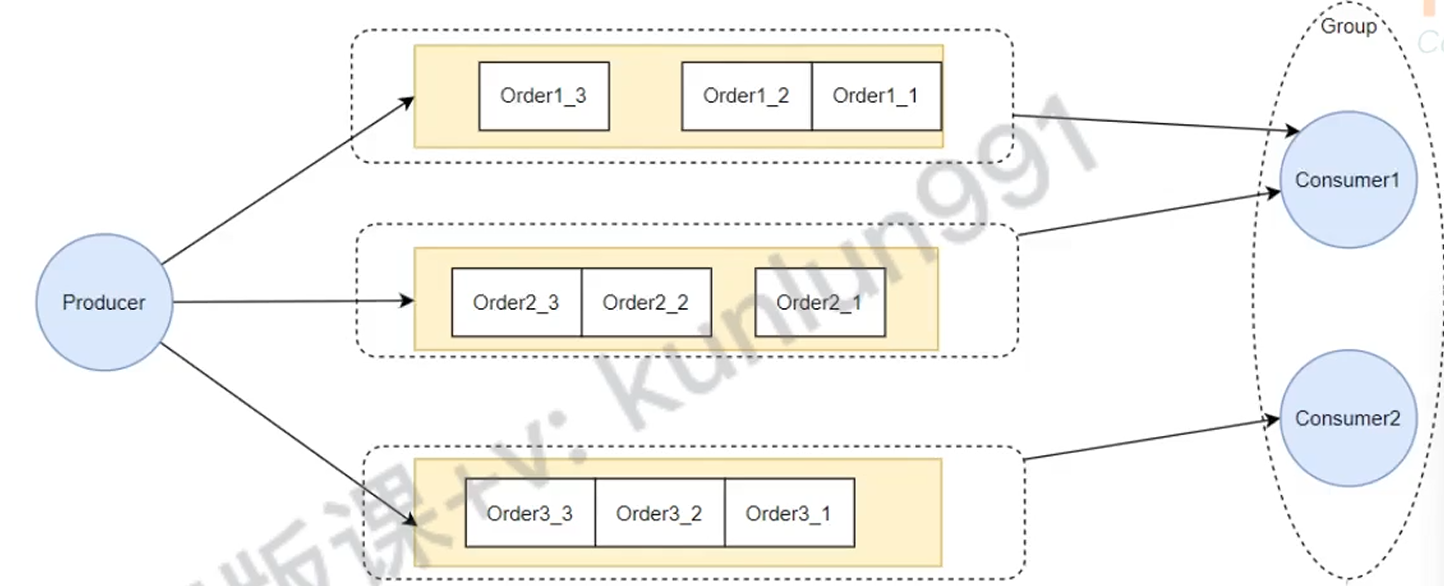
发送端:
Message message = new Message();
message.setBody("123".getBytes());
message.setTopic("123");
SendResult sendResult = producer.send(message, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {String orderId = (String) arg; // 例如订单IDint index = Math.abs(orderId.hashCode()) % mqs.size();return mqs.get(index);}
}, orderId); // orderId 就是用来决定队列的业务 key将只要是同一个订单的消息都发送到同一个队列中
并且存储的顺序和发送到broker的先后顺序一致,对于必需保证强一致的场景,就要做到每一条消息发送之前判断上一条消息是否发送成功并且要避免网络抖动的问题,否则会出现消息非顺序存储问题
发送端也要处理因为网络抖动导致的发送顺序错乱问题,解决的方案就是同步发送+发送失败内部重试
结论:同一订单的消息发送到同一个队列中并且按照执行的先后顺序进行存储,否则无法保证
消费端
consumer.registerMessageListener(new MessageListenerOrderly() {@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {for (MessageExt msg : msgs) {System.out.printf("收到顺序消息: %s \n", new String(msg.getBody()));}return ConsumeOrderlyStatus.SUCCESS; // 处理成功// 如果返回 SUSPEND_CURRENT_QUEUE_A_MOMENT,会稍后重试当前队列}
});消费端需要保证只有顺序的去读取同一个消息队列就行了,因为存储的时候已经保证了顺序性
注意:对于同一个队列必须是单线程去读取,这样才能保证顺序性,如果是对于不同的队列的话就不一定能保证顺序性(局部有序性)
如果是springboot整合的话
// 生产者
public void sendMessage(String topic,String msg){String hashingKey = "order-123"; // 用于保证相同订单进入同一个队列Message message = new Message();message.setBody(msg.getBytes());SendResult result = rocketMQTemplate.syncSendOrderly(topic, message, hashingKey);
}// 消费者
@RocketMQMessageListener(topic = "order-topic", // 监听的主题consumerGroup = "order-consumer-group", // 消费者组consumeMode = ConsumeMode.ORDERLY // 顺序消费模式
)
public class OrderMessageConsumer implements RocketMQListener<String> {@Overridepublic void onMessage(String message) {// 顺序处理每一条消息(RocketMQ 保证同一个 Queue 的消息是 FIFO)System.out.println("【顺序消费】收到消息: " + message);// TODO 你的业务逻辑,比如更新订单状态// 注意:不要抛出异常,否则会阻塞该队列的后续消息}
}上面的这些分析都是针对局部有序性或是相对有序,也是比较常见的,如果要保证全局有序的话,就是所有的消息都只发送到同一个队列中(不能有多个),并且只能有一个线程来顺序的读取这个队列,但是这样子就浪费了性能以及分布式的优势
并且在实际的业务中基本都是局部有序比较多,要尽量让生产者把消息打到多个队列上,避免数据热点竞争
原理:
- 队列锁定机制
当使用 MessageListenerOrderly 时,RocketMQ 会为每个消息队列加锁:
- 每个 MessageQueue 在同一时刻只能被一个消费线程处理
- Broker 会维护消费偏移量,确保消息按顺序投递
2. 失败处理策略
顺序消息的失败处理与普通消息不同:
- 不能返回 RECONSUME_LATER:这会导致消息进入重试队列,破坏顺序性
- 应该返回 SUSPEND_CURRENT_QUEUE_A_MOMENT:暂停当前队列的消费,稍后重试同一批消息
3. 消费幂等性
由于顺序消息在失败时会重复投递同一批消息,消费者必须实现幂等处理:
- 记录已处理的消息ID或业务ID
- 使用数据库唯一约束防止重复处理
- 使用Redis等分布式缓存记录处理状态
// 幂等消费示例
private boolean processMessageIdempotent(MessageExt msg) {String messageId = msg.getMsgId();String businessKey = msg.getKeys(); // 发送时设置的业务键// 使用Redis判断是否已处理String processedKey = "processed:" + businessKey;if (redis.exists(processedKey)) {return true; // 已经处理过,直接返回成功}// 处理业务逻辑processBusiness(msg);// 标记为已处理,设置过期时间防止无限增长redis.setex(processedKey, 24 * 3600, "1");return true;
}总结一下:所谓的顺序消费其实就是生产者把需要保证顺序性的消息发送同一个队列中(原生API自己手动处理,springboot整合的话用人家提供的,传入hashkey),然后消费者只能用一个线程去读取这一个队列
如何避免重复消费
为什么会出现重复,常见的原因就是:
- Rebalance(再平衡):这是最常见的原因。
-
- 当消费者集群中某个实例宕机或新实例加入时,会触发Rebalance,重新分配队列。分配过程中,部分已处理但未提交偏移量(Offset)的消息会被重新投递给新的消费者实例。
- 消费者处理失败后重试:
-
- 消费者处理消息成功,但在发送ACK确认给Broker之前宕机了。
- Broker未收到ACK,会认为消息处理失败,会在稍后重新投递。
- 生产者重试:
-
- 生产者发送消息后未收到Broker响应,触发重试机制,可能导致Broker收到重复的消息(例如第一条消息网络延迟,重发的第二条先到)。RocketMQ 4.3+版本的消息ID去重机制可以解决Broker层面的重复,但客户端仍需做业务幂等。
解决这个问题的关键最好就是直接在业务上做幂等性处理
幂等性是指:无论同一条消息被消费一次还是多次,其对系统状态造成的影响结果是相同的。
常见解决方案:
方案1:利用消息的唯一标识(比如 Key / 业务 ID)做去重
每条消息都有一个唯一标识,比如:RocketMQ 的 messageKey(你可以在发送消息时通过 message.setKey("order_123")设置)或者你自己业务中的 唯一业务 ID,比如:订单ID、支付流水号、用户ID + 操作类型
处理过程:
- 消费者在处理消息前,先检查这个 唯一标识是否已经被处理过;
- 如果已经处理过,则 直接忽略这条消息(认为是重复的);
- 如果没处理过,则执行业务逻辑,并 记录该标识已处理。
可以通过 redis或是本地缓存之类的来进行实现,在进行处理前先通过查询本地缓存或是redis中是否存在处理过标识了
String msgKey = message.getKeys(); // 或者你的业务唯一ID,比如订单ID
String redisKey = "msg:processed:" + msgKey;// 尝试设置一个标志,表示这个消息已经处理过,过期时间根据业务设定,比如 24 小时
Boolean isFirstProcess = redis.setIfAbsent(redisKey, "1", Duration.ofHours(24));if (isFirstProcess != null && isFirstProcess) {// ✅ 第一次处理,执行业务逻辑processBusiness(message);
} else {// ❌ 已经处理过了,认为是重复消息,直接跳过log.warn("消息已经被处理过,忽略重复消费,msgKey = {}", msgKey);
}优点:简单高效,适用于大部分业务场景,特别是有唯一业务标识的情况;基本适合所有的场景
缺点:需要维护一个 “已处理消息”的存储,比如 Redis,有一定成本;
方案2:利用数据库唯一约束 / 去重表
如果是数据操作本身就会写入到数据库的话,可以通过数据库建立唯一索引或是主键之类的来进行去重
如果是不用写入到数据库的话也可以单独开一张去重表,同样是存储已经处理了的那些消息,并且通过唯一约束,这样子只有先去写入到数据库成功的那些消息才能正常的进行处理,如果写入失败的话也是不行的
实现过程:
在消息中携带上唯一的处理标识,然后在消费者端消费之前先进行写入数据库操作
String msgKey = message.getKeys(); // 唯一业务ID
try {// 尝试插入一条记录,表示这个消息已经处理deduplicationMapper.insertIfNotExists(msgKey, new Date());// 唯一索引未冲突,说明是第一次处理 → 执行业务逻辑processBusiness(message);
} catch (DuplicateKeyException e) {// 唯一约束冲突,说明这条消息已经处理过了 → 忽略log.warn("重复消息,已忽略,msgKey = {}", msgKey);
}优点:不依赖外部缓存,利用数据库自身特性,适合强一致性业务;基本适合所有的场景
缺点:频繁的插入可能对数据库有压力,需合理设计表结构和索引;
方案3:业务状态机 / 幂等操作设计
你的业务逻辑本身是 具有状态、且操作是天然幂等的;
比如:订单状态只能从 “待支付” → “已支付”,不能重复支付;
比如:给用户加积分,但每次操作前先检查当前状态是否已满足,避免重复执行;
实现的方式:
在进行操作之前先检查一下状态,满足特定的状态才能进行对应的操作
Order order = orderService.getById(orderId);
if ("PENDING".equals(order.getStatus())) {// 当前是待支付,可以支付orderService.pay(orderId);
} else {// 已经支付过了,是重复消息,直接忽略log.info("订单已支付,忽略重复消息,orderId = {}", orderId);
}优点:不需要额外存储,逻辑内聚,适合状态明确的业务;
缺点:需要对业务状态有清晰的建模,不适合所有场景;
如何处理消息重放
消息重放(Message Replay)是指有意或无意地重新消费已经处理过的消息。
- 主动重放:
-
- 数据修复:发现历史数据有问题,需要重新处理
- 功能迭代:新功能需要基于旧消息重新计算
- 测试与调试:重现生产环境问题
- 被动重放:
-
- 消费者重置偏移量:消费者组重置消费位点到历史位置
- 故障恢复:系统故障后需要重新处理消息
想要实现消息重放的话可以通过以下几个方式实现
- 通过命令重置消费偏移量
mqadmin resetOffsetByTime -n <nameserver> -g <consumerGroup> -t <topic> -s <timestamp>- 通过控制台重放,一般都是有提供这样的功能的
- 也可以通过代码的方式实现
// 编程方式重放示例
public void replayMessages(String consumerGroup, String topic, long startOffset, long endOffset) {try {// 获取MQ客户端实例DefaultMQAdminExt adminExt = new DefaultMQAdminExt();adminExt.start();// 重置消费偏移量adminExt.resetOffsetByOffsetTime(consumerGroup, topic, startOffset);// 监控重放进度monitorReplayProgress(consumerGroup, topic, startOffset, endOffset);adminExt.shutdown();} catch (Exception e) {log.error("消息重放失败", e);throw new ReplayException("重放操作失败", e);}
}其实还是要分情况的,如果是主动的话就不用管,如果是被动的话就是要上面提到的消息重复消费的解决方案一样,通过业务幂等来进行处理
如何实现延迟队列
延迟消息就是发送之后不会马上投递给消费者进行消费,而是等待我们设置的时间到了之后才会投递给消费者消费
发送端:
public class DelayedMessageProducer {public static void main(String[] args) throws Exception {// 初始化生产者DefaultMQProducer producer = new DefaultMQProducer("DelayedProducerGroup");producer.setNamesrvAddr("localhost:9876");producer.start();// 创建消息Message msg = new Message("TestTopic", "TagA", "Hello Delayed Message".getBytes(StandardCharsets.UTF_8));// 设置延迟级别为3,即10秒后消费msg.setDelayTimeLevel(3);// 发送消息SendResult sendResult = producer.send(msg);System.out.println("发送时间: " + new Date());System.out.println("发送结果: " + sendResult);producer.shutdown();}
}消费端不需要干嘛,和原来的是一样的
原理:
延时消息并不是 RocketMQ 通过一个“定时器”或者“线程 sleep”来实现的
Broker收到延时消息了,会先发送到特殊的内部Topic(SCHEDULE_TOPIC_XXXX)中【消息本身是有延时时间的】,然后通过一个定时任务不断轮询这些队列(后台定时调度机制),到期后,把消息取出后投递到目标Topic的队列中,然后消费者就可以正常消费这些消息。

那如果是我们自己来实现这样一个延时任务,应该如何来做的?其实自己实现一个还是很有必要的,因为现在rocketmq开源版本的延时时间其实是固定的,只有18个等级可以选,但是要是我们的项目需要用到特殊的时间,就只能自己定制了。
实现自定义延时时间的方案:
1. 数据库 + 定时任务扫描
// 1. 创建延迟消息表
CREATE TABLE delayed_messages (id BIGINT AUTO_INCREMENT PRIMARY KEY,topic VARCHAR(255) NOT NULL,tags VARCHAR(255),body TEXT NOT NULL,execute_time DATETIME NOT NULL, -- 计划执行时间status TINYINT DEFAULT 0, -- 0:待处理, 1:已处理created_time DATETIME DEFAULT CURRENT_TIMESTAMP
);// 2. 发送延迟消息时,存入数据库
public void sendDelayedMessage(String topic, String tags, String body, long delayMillis) {DelayedMessage message = new DelayedMessage();message.setTopic(topic);message.setTags(tags);message.setBody(body);message.setExecuteTime(new Date(System.currentTimeMillis() + delayMillis));message.setStatus(0);delayedMessageRepository.save(message);
}// 3. 定时任务扫描数据库
@Scheduled(fixedRate = 5000) // 每5秒执行一次
public void processDelayedMessages() {List<DelayedMessage> messages = delayedMessageRepository.findByExecuteTimeBeforeAndStatus(new Date(), 0);for (DelayedMessage message : messages) {try {// 发送到 RocketMQMessage msg = new Message(message.getTopic(), message.getTags(), message.getBody().getBytes());producer.send(msg);// 更新状态为已处理message.setStatus(1);delayedMessageRepository.save(message);} catch (Exception e) {log.error("处理延迟消息失败: {}", message.getId(), e);}}
}然后你查询数据库的sql语句就不用说一定要找刚好到执行时间的,而是通过预先获取的操作,只要离执行时间在6秒以内(自己调整)的就都获取出来进行发送,并没有那么精确的
2. Redis Sorted Set(ZSet) + 定时任务
// 1. 发送延迟消息时,存入 Redis Sorted Set
public void sendDelayedMessage(String topic, String tags, String body, long delayMillis) {long executeTime = System.currentTimeMillis() + delayMillis;String messageId = UUID.randomUUID().toString();// 将消息内容序列化存储Map<String, String> messageData = new HashMap<>();messageData.put("topic", topic);messageData.put("tags", tags);messageData.put("body", body);messageData.put("messageId", messageId);// 使用执行时间作为分数redisTemplate.opsForZSet().add("delayed:messages", JSON.toJSONString(messageData), executeTime);
}// 2. 定时任务扫描 Redis
@Scheduled(fixedRate = 1000) // 每秒执行一次
public void processDelayedMessages() {long now = System.currentTimeMillis();// 获取所有到期的消息Set<String> messages = redisTemplate.opsForZSet().rangeByScore("delayed:messages", 0, now);for (String messageStr : messages) {try {Map<String, String> messageData = JSON.parseObject(messageStr, Map.class);// 发送到 RocketMQMessage msg = new Message(messageData.get("topic"), messageData.get("tags"), messageData.get("body").getBytes());producer.send(msg);// 从 Redis 中移除redisTemplate.opsForZSet().remove("delayed:messages", messageStr);} catch (Exception e) {log.error("处理延迟消息失败: {}", messageStr, e);}}
}3. 时间轮算法 (Hashed Timing Wheel)
// 简化版时间轮实现
public class TimingWheel {private final long tickDuration; // 每个槽位的时间间隔private final int wheelSize; // 槽位数量private final AtomicLong currentTime; // 当前时间private final List<Queue<DelayedTask>> buckets; // 时间槽public TimingWheel(long tickDuration, int wheelSize) {this.tickDuration = tickDuration;this.wheelSize = wheelSize;this.currentTime = new AtomicLong(System.currentTimeMillis());this.buckets = new ArrayList<>(wheelSize);for (int i = 0; i < wheelSize; i++) {buckets.add(new LinkedList<>());}// 启动工作线程new Thread(this::advanceClock).start();}public void addTask(DelayedTask task, long delay) {long executeTime = System.currentTimeMillis() + delay;long relativeTime = executeTime - currentTime.get();// 计算槽位int bucketIndex = (int) (relativeTime / tickDuration) % wheelSize;buckets.get(bucketIndex).add(task);}private void advanceClock() {while (true) {try {Thread.sleep(tickDuration);long now = System.currentTimeMillis();currentTime.set(now);// 处理当前槽位的任务int currentBucket = (int) ((now / tickDuration) % wheelSize);Queue<DelayedTask> bucket = buckets.get(currentBucket);while (!bucket.isEmpty()) {DelayedTask task = bucket.poll();if (task != null) {// 执行任务task.execute();}}} catch (InterruptedException e) {Thread.currentThread().interrupt();break;}}}
}对比
| 方案 | 优点 | 缺点 | 适用场景 |
| RocketMQ 原生 | 简单、可靠、无需额外组件 | 延迟级别固定、不够灵活 | 固定的延迟需求 |
| 数据库 + 定时任务 | 灵活、可持久化、支持任意延迟 | 性能较低、数据库压力大 | 延迟精度要求不高、消息量不大 |
| Redis Sorted Set | 性能较高、灵活 | 需要维护 Redis、可能丢失消息 | 中等消息量、对性能有一定要求 |
| 时间轮算法 | 性能极高、精度高 | 实现复杂、内存消耗大 | 高并发、低延迟要求的场景 |
负载均衡
RocketMQ 的负载均衡主要体现在以下几个方面:
- 生产者负载均衡:决定消息发送到哪个 Broker 的哪个队列
- 消费者负载均衡:决定哪个消费者实例消费哪个队列的消息
- Broker 负载均衡:Topic 的队列在不同 Broker 上的分布
生产者负载均衡
生产者发送消息时,需要决定将消息发送到哪个 MessageQueue(消息队列)。
1. 默认负载均衡策略
RocketMQ 生产者默认使用轮询(Round-Robin)方式选择队列:
public class ProducerLoadBalance {public static void main(String[] args) throws Exception {DefaultMQProducer producer = new DefaultMQProducer("ProducerGroup");producer.start();for (int i = 0; i < 10; i++) {Message msg = new Message("TestTopic", "TagA", ("Message " + i).getBytes());// 默认使用轮询方式选择队列SendResult result = producer.send(msg);System.out.println("发送到队列: " + result.getMessageQueue().getQueueId());}producer.shutdown();}
}2. 自定义队列选择策略
可以通过实现 MessageQueueSelector 接口来自定义队列选择策略:
public class CustomQueueSelector {// 1. 根据业务ID哈希选择队列(保证相同业务的消息进入同一队列)public static void sendWithBusinessHash() throws Exception {DefaultMQProducer producer = new DefaultMQProducer("ProducerGroup");producer.start();// 模拟10个订单,每个订单有3个状态for (int orderId = 1; orderId <= 10; orderId++) {for (int status = 1; status <= 3; status++) {Message msg = new Message("OrderTopic", "TagA", ("Order_" + orderId + "_Status_" + status).getBytes());SendResult result = producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {Integer id = (Integer) arg;int index = id % mqs.size(); // 相同订单选择同一队列return mqs.get(index);}}, orderId); // 传入订单ID作为选择依据System.out.println("订单 " + orderId + " 发送到队列: " + result.getMessageQueue().getQueueId());}}producer.shutdown();}// 2. 其他自定义策略public static class MyMessageQueueSelector implements MessageQueueSelector {private AtomicInteger counter = new AtomicInteger(0);@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {// 随机选择// int index = ThreadLocalRandom.current().nextInt(mqs.size());// 最少使用选择// int index = getLeastUsedQueueIndex(mqs);// 加权轮询int index = counter.getAndIncrement() % mqs.size();return mqs.get(index);}}
}消费者负载均衡
消费者负载均衡是 RocketMQ 的核心机制,通过 RebalanceService 来实现。
1. 消费者负载均衡策略
RocketMQ 提供两种消费模式,对应不同的负载均衡策略:
public class ConsumerLoadBalance {// 1. 集群模式(默认):负载均衡,每个消息只被一个消费者消费public static void clusterMode() throws Exception {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("ConsumerGroup");consumer.setNamesrvAddr("localhost:9876");consumer.subscribe("TestTopic", "*");// 集群模式 - 负载均衡consumer.setMessageModel(MessageModel.CLUSTERING);consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {// 处理消息return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});consumer.start();}// 2. 广播模式:每个消费者都消费所有消息public static void broadcastMode() throws Exception {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("ConsumerGroup");consumer.setNamesrvAddr("localhost:9876");consumer.subscribe("TestTopic", "*");// 广播模式 - 所有消费者都消费所有消息consumer.setMessageModel(MessageModel.BROADCASTING);consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {// 处理消息return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});consumer.start();}
}2. 重平衡(Rebalance)过程
重平衡是消费者负载均衡的核心机制,触发条件包括:
- 消费者启动或停止
- 网络异常导致消费者与 Broker 断开连接
- 定时任务(默认20秒一次)
// 重平衡过程
public void doRebalance() {// 1. 获取Topic的所有消息队列Set<MessageQueue> allQueues = mQClientFactory.getTopicAllQueues(topic);// 2. 获取当前消费者组的所有消费者IDList<String> allConsumerIds = mQClientFactory.findConsumerIdList(consumerGroup, topic);// 3. 对队列和消费者进行排序(保证所有消费者计算结果一致)Collections.sort(allQueues);Collections.sort(allConsumerIds);// 4. 平均分配策略int index = allConsumerIds.indexOf(currentConsumerId);int mod = allQueues.size() % allConsumerIds.size();int averageSize = allQueues.size() / allConsumerIds.size();int startIndex = (index < mod) ? index * (averageSize + 1) : index * averageSize + mod;int range = (index < mod) ? (averageSize + 1) : averageSize;// 5. 分配得到的队列List<MessageQueue> assignedQueues = allQueues.subList(startIndex, startIndex + range);// 6. 更新本地分配的队列updateProcessQueueTable(assignedQueues);
}Broker 负载均衡
1. Topic 队列分布
在创建 Topic 时,可以指定队列在多个 Broker 上的分布:
# 创建Topic,8个队列,2个副本
mqadmin updateTopic -n localhost:9876 -t TestTopic -b broker-a:4 -b broker-b:4这样就将 8 个队列平均分配到了两个 Broker 上。
2. 读写分离
RocketMQ 支持读写分离,从节点只负责读操作,减轻主节点压力:
public class ReadBalance {public static void main(String[] args) throws Exception {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("ConsumerGroup");consumer.setNamesrvAddr("localhost:9876");consumer.subscribe("TestTopic", "*");// 设置从Broker读取策略consumer.setUnitMode(true); // 单元化模式consumer.setUnitName("UnitA");consumer.setReadFromWhichBroker(ReadFromWhichBroker.READ_FROM_SLAVE);consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {// 处理消息return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});consumer.start();}
}事务消息
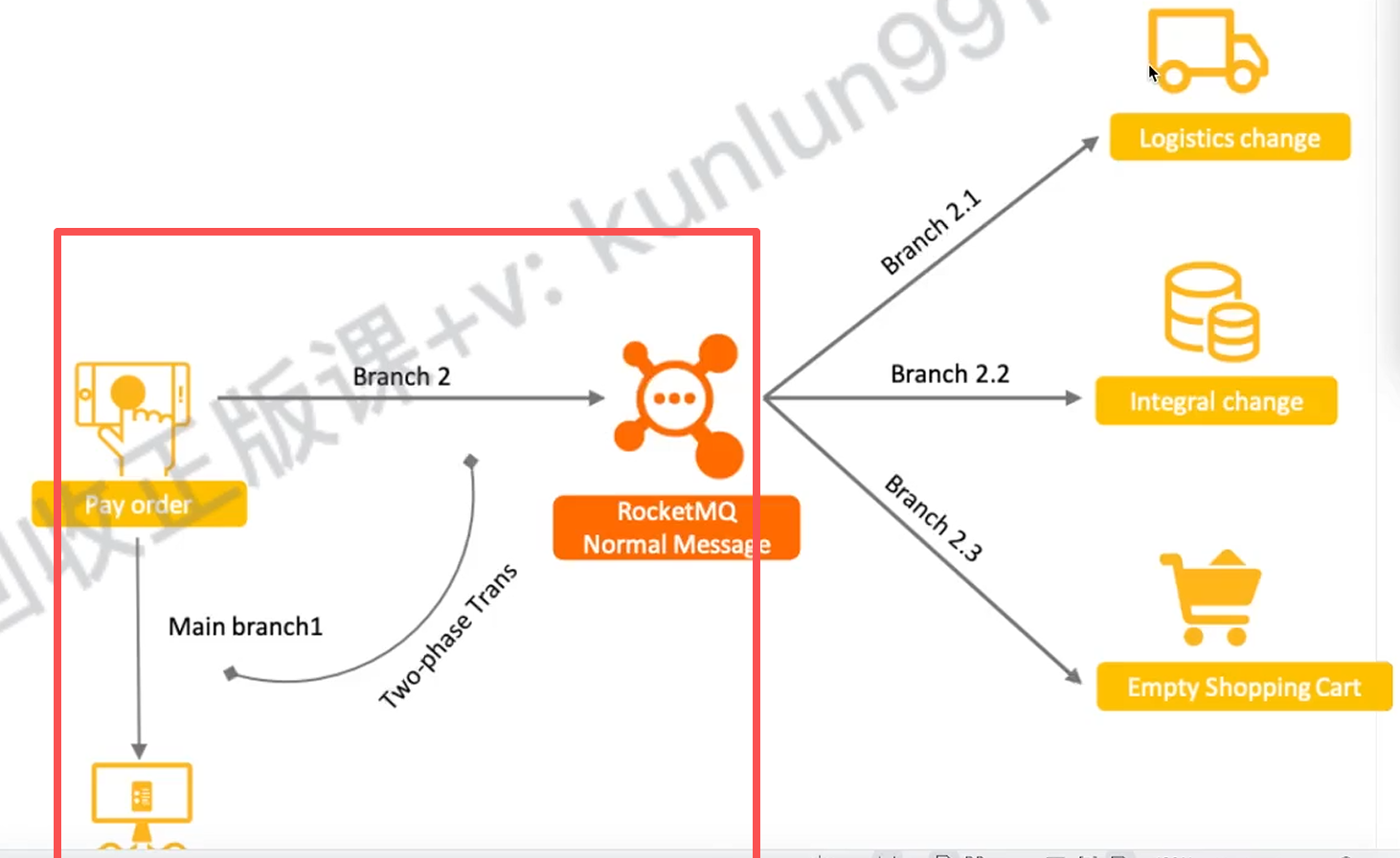
但是RocketMQ 和传统的分布式事务不太一样,它只能保证一半,就是图中圈起来的那一半,它只能说保证发送端部分和本地业务消息的原子性
比如上面的图就是只能保证发送端和数据落库以及其他的业务代码(状态变更)之类的原子性,但是不能保证右边那些消费端的业务也和左边的业务保持原子性,但是我们可以手动控制,在消费端可以通过确认机制,因为消费端如果能消费到消息的话就说明发送端的业务逻辑是完整的(不完整不会发送消息到broker),那么消费端通过确认机制保证自己这一端也消费执行成功就行,不成功就重试
具体代码
TransactionMQProducer producer = new TransactionMQProducer("ProducerGroupName");
producer.setNamesrvAddr("192.168.116.134:9876");
producer.setTransactionListener(new TransactionListener() {// 执行本地的事务操作(数据落库或是其他的业务代码之类的)@Overridepublic LocalTransactionState executeLocalTransaction(Message message, Object o) {try {String orderId = message.getKeys();boolean success = orderService.createOrder(orderId, ...); // 你的业务方法if (success) {return LocalTransactionState.COMMIT_MESSAGE; // 本地事务成功,提交消息} else {return LocalTransactionState.ROLLBACK_MESSAGE; // 本地事务失败,回滚消息}} catch (Exception e) {e.printStackTrace();return LocalTransactionState.ROLLBACK_MESSAGE;}}// broker回查,这里如果涉及到落库操作的话需要查询数据库的状态@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt messageExt) {String orderId = messageExt.getKeys();boolean isCommitted = orderService.isOrderCommitted(orderId); // 查数据库if (isCommitted) {return LocalTransactionState.COMMIT_MESSAGE;} else {return LocalTransactionState.ROLLBACK_MESSAGE;}}
});producer.start();Message msg = new Message("OrderTopic", // Topic"OrderTag", // Tag(可选)"Order001", // Key / 业务ID,可用于回查和查找"这是订单消息内容".getBytes() // 消息体
);
producer.sendMessageInTransaction(msg, null);
用这个方式发送消息的话,记得把回查标志写入到key中
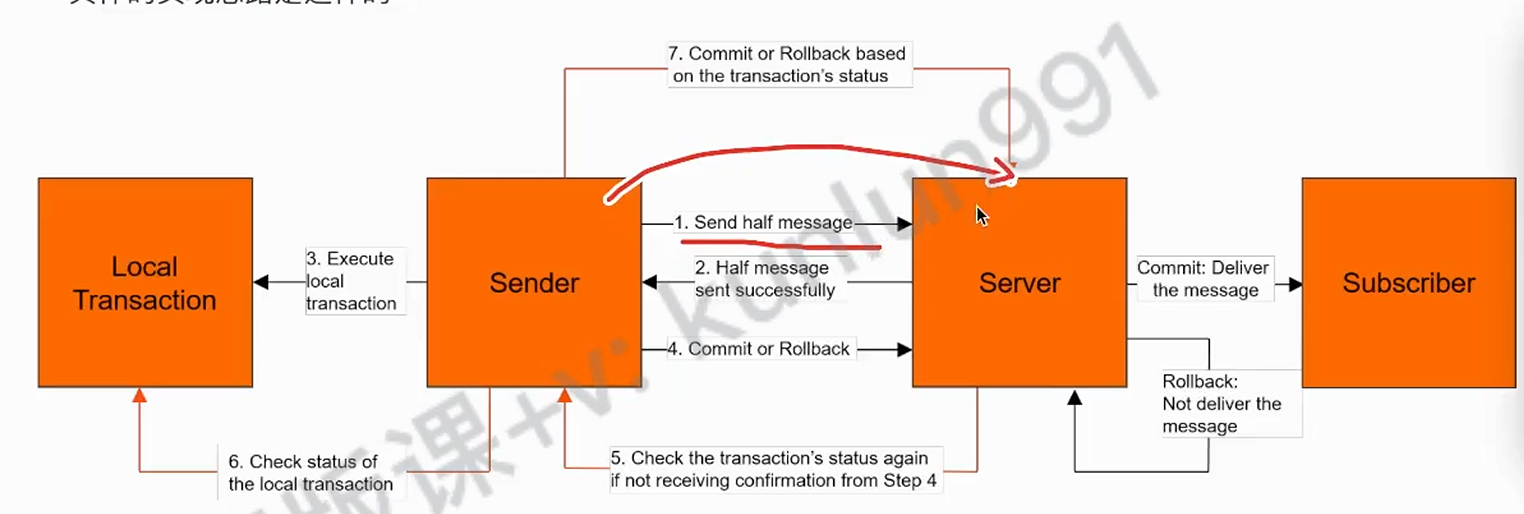
总体的执行流程:
- 发送端先发送一个半消息到broker确认以下服务是否是正常可访问状态
- 如果是可访问就会去执行本地事务方法,并根据执行结果提交 commit 或是 rollback 到服务端
- 服务端接收到之后就会判断,如果是commit就会把消息投递到topic让消费端消费,如果是rollback就会直接把消息丢失掉
- 然后前面发送端如果很久没有发送 commit 或是 rollback 到服务端,broker就会认为状态时 unknown,这个时候就会发送检查状态请求到发送端
- 发送端接收到检查请求之后就会执行一下检查方法进行检查状态,然后再根据状态发送对应的commit 或是 rollback 到服务端
- 要是检查了之后还是没有发送commit 或是 rollback 到服务端,broker会等待一段时间后,再次发送检查请求,直到超过时间上限
如果是在SpringBoot集成的话
首先就是去注册一个事务监听器
@Component
@RocketMQTransactionListener
public class MyTransactionListenerImpl implements RocketMQLocalTransactionListener {// 模拟本地事务执行(比如数据库操作)@Overridepublic RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {String body = new String((byte[]) msg.getPayload());String txId = (String) msg.getHeaders().get("TX-ID");log.info("执行本地事务,事务ID = {}, 消息内容 = {}", txId, body);// 模拟业务操作,比如:// - 创建订单// - 扣减库存// - 保存支付记录boolean success = mockBusinessOperation(txId);if (success) {log.info("本地事务执行成功,事务ID = {}", txId);return RocketMQLocalTransactionState.COMMIT; // 提交事务,消息会投递给消费者} else {log.warn("本地事务执行失败,事务ID = {}", txId);return RocketMQLocalTransactionState.ROLLBACK; // 回滚事务,消息会被丢弃}} catch (Exception e) {log.error("本地事务异常,事务回滚,msg = {}", msg, e);return RocketMQLocalTransactionState.ROLLBACK;}}// RocketMQ 会定期调用此方法,检查本地事务状态(如果没及时返回 COMMIT/ROLLBACK)@Overridepublic RocketMQLocalTransactionState checkLocalTransaction(Message msg) {String txId = (String) msg.getHeaders().get("TX-ID");log.info("事务回查,事务ID = {}", txId);// TODO 你可以根据 TX-ID 去数据库查询该事务最终状态是成功还是失败// 这里简单模拟:假设最终都成功了(实际你应该查 DB 或状态表)return RocketMQLocalTransactionState.COMMIT;}// 模拟业务操作是否成功private boolean mockBusinessOperation(String txId) {// 模拟:90% 成功率return Math.random() > 0.1;}
}就是实现RocketMQLocalTransactionListener接口下的两个方法
重点要注意的就是两个注解必须加上否则就不能实现自动调用了
public class SpringProducer {@Resourceprivate RocketMQTemplate rocketMQTemplate;public void sendMessage(String orderId){// 1. 定义 destination(topic:tag),消费者会监听这个地址String destination = "order-topic:tx"; // ✅ 与消费者监听的 destination 保持一致// 2. 构建消息内容String messageContent = "【事务消息】创建订单,订单ID = " + orderId;Message<String> message = MessageBuilder.withPayload(messageContent).build();// 3. 发送事务消息rocketMQTemplate.sendMessageInTransaction(destination, message, null);}
}半消息:
半消息就是不会立马被投递到topic下的消息,而是被broker进行持久化存储(因为是发送到系统内置的topic,而不是我们订阅的那个topic),这里的半消息其实就是我们的业务消息,只不过不会立马投递,而是等到接收到commit才会进行投递
broker没接收到commit 或是 rollback ,那么要等待多久才会进行回查?回查多少次?
通过以下两个参数来决定
# 事务超时时间(毫秒):超过这个时间没收到 commit/rollback,就回查
transactionTimeout=60000# 事务消息最大回查次数:超过此次数后,broker 默认回滚(丢弃消息)
transactionCheckMax=15进阶
消息积压
消息积压(消息堆积 / Backlog)指的是:生产者已经将消息发送到了 Broker(消息队列),但消费者还没有及时消费这些消息,导致消息在 Broker 的队列中“等待消费”的状态。
通俗点来讲就是生产得很快,但是消费得很慢
当broker的消息超过存储的上限之后,broker不会直接丢弃新消息,也不会覆盖原有的旧消息,而是直接拒绝新消息的写入请求,并返回一个错误,让发送者可以感知到
产生积压的原因:
1. 消费速度 < 生产速度(最常见原因)
- 消费者处理能力不足(比如消费逻辑慢、DB 写入慢、外部接口调用慢)。
- 消费者实例数量太少,并发消费能力跟不上。
2. 消费者出现故障或停止
- 消费者进程宕机、线程阻塞、消费逻辑抛出未捕获异常、消费服务下线等,都会导致消费停滞。
- 消费者虽然没挂,但卡在某个逻辑(死循环、锁等待、慢查询等)。
3. 消费者未能正确ACK(确认)
- 如果消费端没有正确返回消费成功(或异常未处理导致不断重试),消息会一直处于未完成状态,无法被移除,造成“假积压”。
4. Topic 的队列数(MessageQueue)太少
- 如果一个 Topic 只有少量 Queue(比如 4 个),即使你启动了多个消费者,也难以充分利用并行能力,导致消费吞吐上不去。
5. 突发流量 / 流量洪峰
- 比如大促、秒杀活动时,流量可能是平时的几十倍,消费能力没及时扩容,就会瞬间积压。
处理消息积压
处理 RocketMQ 消息积压的核心思路是:提升消费能力,或者减缓生产速度,让消费追上生产。
解决方案可以分为以下几类:
1. 短期应急:快速消费积压消息
(1)增加消费者实例(横向扩容)
- 启动更多的 消费者进程 / 线程 / 容器(如 Docker、K8s Pod)
- RocketMQ 会自动将这些消费者分配到不同的 MessageQueue 上,提高总体的消费并发能力。
这是最快速有效的办法之一!
(2)提高单消费者消费能力
- 优化消费逻辑:减少慢查询、优化外部 HTTP/RPC 调用、使用批量处理、异步非阻塞等。
- 避免在消费线程中做耗时操作(如同步写 DB、同步调用第三方接口)。
- 考虑使用 多线程消费(但要注意消息顺序性等问题)。
(3)临时跳过非关键消息(视业务而定)
- 如果积压的是某些 非核心、可延迟处理 的消息,可以考虑暂时降级处理,优先保证核心链路。
2. 中长期优化:架构与配置优化
(1)增加 Topic 的 MessageQueue 数量
- Queue 是并行消费的基本单位,如果你的 Topic 只有 4 个 Queue,即使你起了 10 个消费者,也最多只有 4 个在真正工作。
- 建议根据消费者数量和并发需求,将 Topic 的 Queue 数量设置为 16、32、64 等,以便更好地利用多消费者并行能力。
注意:Queue 数量 只能在创建 Topic 时指定,后期修改非常麻烦,需谨慎规划!
(2)优化消费者组负载均衡
- 确保消费者组中的消费者数量 ≤ Topic 的 Queue 数量,否则会有消费者分配不到队列,浪费资源。
- 使用合理的分配策略(如平均分配)。
(3)控制生产速率(限流 / 降级)
- 如果积压是因为 突发流量 / 生产过快,可以在生产端做 限流、熔断、降级,避免 Broker 和消费者被压垮。
- 比如大促期间,可以对非核心服务进行流量控制。
3. 监控与告警:提前发现积压
- 设置 RocketMQ 消费延迟告警,比如当某个 Consumer Group 的平均积压超过 N 条时触发告警。
- 通过 Grafana + Prometheus + RocketMQ Exporter 实现可视化与自动化监控。
- 定期巡检关键 Topic 的消费情况,尤其是在大促、活动前。
持久化
持久化就是消息真正写入到磁盘保存起来的过程
持久化机制
1. CommitLog(提交日志)—— 所有消息的最终存储地
核心特点:
- 所有生产者发送的消息,不管属于哪个 Topic、哪个 Queue,都会顺序写入同一个或多个 CommitLog 文件中(顺序 I/O,性能极高)。
- 消息是 二进制格式,包含消息体、Topic、QueueId、生产时间、offset 等元信息。
- 默认是同步或异步地刷盘到磁盘,确保消息落盘持久化。
CommitLog 是 RocketMQ 持久化的核心,所有消息最终都存在这里,是物理存储的最底层。
2. ConsumeQueue(消费队列)—— 消费的逻辑视图 / 索引
核心特点:
- 每个 MessageQueue(即 Queue,分区) 对应一个 ConsumeQueue。
- ConsumeQueue 是一个 轻量级的索引文件,记录了该 Queue 中的每条消息在 CommitLog 中的 物理偏移位置(offset)、消息大小、tag hash 等信息。
- 消费者 不直接读 CommitLog,而是通过 ConsumeQueue 快速定位到 CommitLog 中的消息位置,再读取消息内容。
ConsumeQueue 是逻辑队列,相当于给每个 Queue 建立了一个“消息目录”,让消费变得高效、并行。
二者关系(图示理解):
生产者 ---> 消息 ---> [Broker]+------------------+| CommitLog | <--- 所有消息顺序存储(物理存储)+------------------+|+------------------------+------------------------+| | |
+--------------+ +------------------+ +------------------+
| ConsumeQueue | --> 指向 CommitLog 中的 | --> 消费者从 CommitLog 按索引读取消息
| (Queue 0) | | 消息位置(offset) | |
+--------------+ +------------------+ || | || | |Queue 0 Queue 1 Queue 2 ...刷盘策略
RocketMQ 提供了 两种刷盘方式,决定了消息多久被真正写入磁盘,也就是 “消息多久才算安全落盘”。
1. 异步刷盘(ASYNC_FLUSH,默认)
- 消息先写入 PageCache(内存缓冲区),然后由操作系统异步刷盘。
- 性能非常高,吞吐量大。
- 但如果 Broker 异常崩溃,PageCache 中尚未刷盘的消息可能会丢失。
适用于:对性能要求高、允许极少消息丢失的场景(如日志、指标等非核心业务)
2. 同步刷盘(SYNC_FLUSH)
- 每条消息写入后,Broker 会等待该消息真正刷盘到磁盘后,才返回成功给生产者。
- 性能较低,吞吐量下降,但可靠性极高。
- 即使 Broker 崩溃,已返回成功的消息也一定已经落盘,不会丢失。
适用于:金融、支付、订单等对消息可靠性要求极高的业务场景
# 刷盘方式:ASYNC_FLUSH(异步,默认) 或 SYNC_FLUSH(同步)
flushDiskType=ASYNC_FLUSH除了配置刷盘策略之外,数据在broker上保留多长时间同样重要
# 消息保留时间,默认 48 小时
fileReservedTime=48消息过滤
RocketMQ 提供了 两种主要的消息过滤方式:
第一种就是通过tag订阅:
发送者在进行发送的时候还携带了tag,消费者订阅的时候订阅具体的tag,这样子就能实现消息过滤
// 发送者
Message message = new Message();
message.setBody("123".getBytes());
message.setTopic("123");
message.setTags("TagA");
producer.send(message);// 消费者
consumer.setNamesrvAddr("192.168.116.134:9876");
consumer.subscribe("123", "TagA");
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {for (Message msg : msgs) {System.out.println("Received message: " + new String(msg.getBody()));}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});这种方式的实现原理就是消息都发送到broker,然后消费者订阅的时候,broker会根据这个订阅的tag在broker内部做一层筛选,这样子的好处就是网络的传输性能比较好,但是缺点就是broker的压力比较大(RocketMQ是优先保证网络性能)
还有另外一种方式就是broker不做筛选,让消费端自己进行筛选,好处是broker压力小,坏处是网络传输性能比较差(RocketMQ并不是选择这一种)
正是因为筛选的时候broker压力比较大,所以不建议搞太复杂的订阅规则(tag)
第二种就是就是通过sql进行筛选
consumer.subscribe("123", MessageSelector.bySql("msgTag LIKE 'Tag%'"));其实就是在消费端进行编写上对应的sql,然后broker就会根据这个sql进行筛选,一般式用来实现一些比较复杂的过滤
但是要注意的就是,默认情况下这个sql是不支持的,只有将参数 enablePropertyFilter 开启才能生效
长轮询机制
1. 传统轮询(Short Polling / 轮询)是什么?
在传统的 HTTP 或 RPC 请求中,客户端定期向服务端发起请求,询问是否有新数据,比如每隔几秒就问一次:“有新消息吗?”
- 优点:实现简单
- 缺点:
-
- 实时性差:如果服务端有新数据,客户端也必须等待轮询间隔
- 无效请求多:大多数时候可能没有新消息,浪费网络与计算资源
- 延迟高:消息的到达和客户端的感知之间存在明显的时间间隔
2. 长轮询(Long Polling)是什么?
长轮询是对传统轮询的一种优化。
当客户端发起请求询问“有没有新消息”时:
- 如果服务端 当前没有新消息,不会立即返回空响应,
- 而是 将请求“挂起”(hold住)一段时间(比如 30s),等待新消息的到来;
- 一旦服务端 有新消息到达,或者超时时间到了,就会 立即返回响应给客户端;
- 客户端收到响应后,再发起下一次请求。
核心思想:不是轮着问,而是问完等,有结果立刻回。
那它是如何实现说当一个请求进来之后,把请求hold起来的呢?
1. PullRequest 的数据结构
当消费者发起一次拉取请求时,Broker 会将该请求封装成一个 PullRequest 对象,并 暂不立即处理(或立即返回空),而是将它放入一个 专门的队列中进行挂起,等待被再次唤醒。
🔹 核心类:org.apache.rocketmq.broker.processor.PullMessageProcessor
🔹 关键数据结构:PullRequest
一个 PullRequest通常包括以下信息:
- 消费者组(Consumer Group)
- 消息队列(MessageQueue)
- 当前的拉取偏移量(offset)
- 拉取请求的上下文信息
- 请求的来源 Channel(Netty 连接)
- 超时时间 / 等待时间
- 请求状态等
2. 挂起请求:将 PullRequest 放入一个 “待处理队列”
当 Broker 发现 当前队列没有消息可以返回给消费者 时,它不会立即响应 "没有数据",而是:
将该 PullRequest 对象保存到一个专门的数据结构中(通常是 Map 或 Queue),并关联到对应的 MessageQueue 上,然后 等待新消息的到来。
🔹 关键实现类:PullRequestHoldManager
这是实现长轮询 “Hold 住请求” 的核心管理类!
类名:org.apache.rocketmq.broker.longpolling.PullRequestHoldManager
它的主要职责是:
- 维护一个映射关系:MessageQueue -> 该队列上所有被挂起的 PullRequest 列表
- 当 有新消息到达某个 MessageQueue 时,PullRequestHoldManager 会找到该队列上所有被挂起的请求,并 逐个唤醒它们,触发消息拉取逻辑
- 它内部一般使用 ConcurrentHashMap 来存 Queue -> PullRequest 列表
简化逻辑:
Map<MessageQueue, List<PullRequest>> holdRequestMap = new ConcurrentHashMap<>();3. 如何挂起请求(不立即返回)?
在 PullMessageProcessor(处理拉取请求的入口处理器)中,Broker 会做如下判断:
伪代码逻辑(简化):
if (队列当前没有新消息) {// 不立即返回空!// 而是将这个 PullRequest 挂起(hold)pullRequestHoldManager.suspendPullRequest(queue, pullRequest);// 注意:这里不会立即写回响应,而是等待被唤醒
} else {// 如果有消息,立即返回消息给消费者sendBackMessages(response, messages);
}这里的关键是:Broker 收到拉取请求后,发现没数据,不会立即响应,而是 hold 住该请求,等待新消息!
然后存储被挂起的请求的存储结构其实就是一个ArrayList
public class ManyPullRequest {// todo hold住的请求对象真正存储的结构其实是一个ArrayListprivate final ArrayList<PullRequest> pullRequestList = new ArrayList<>();// todo 添加被hold住的请求的方法public synchronized void addPullRequest(final PullRequest pullRequest) {this.pullRequestList.add(pullRequest);}
}4. 何时唤醒被挂起的请求?
RocketMQ 会在以下时机 触发对挂起请求的唤醒:
场景 1:有新消息写入到某个 MessageQueue
- 当生产者发送了一条新消息,Broker 将消息写入 CommitLog
- 然后会构建对应的 ConsumeQueue 索引
- 紧接着,RocketMQ 会检测到该队列有新数据到达
- 此时,会通知
PullRequestHoldManager:“队列 xxx 有新消息啦,快看看有没有挂起的请求,有的话就唤醒它们!”
唤醒操作:
- Broker 从
PullRequestHoldManager中找出该 MessageQueue 上所有挂起的PullRequest - 然后 重新将这些请求交给 PullMessageProcessor 或调度线程,再次尝试拉取消息
- 此时,因为队列中已经有新数据,所以 可以立即返回消息给消费者
🔹 关键类:
org.apache.rocketmq.broker.processor.SendMessageProcessor(处理消息写入)- 写入消息后,会触发队列的更新事件,进而通知
PullRequestHoldManager
5. 超时处理:如果一直没新消息怎么办?
每个 PullRequest通常都会有一个 超时时间(比如默认 15 秒)。
- 如果在挂起期间,一直没有新消息到达,且超时时间到了
- Broker 会 自动将该请求结束挂起状态,构造一个空响应(没有消息)并返回给消费者
- 消费者收到空响应后,一般会 稍后再次发起拉取请求
这种机制避免了请求永久挂起,同时保证了消费者最终能得到响应(哪怕是空的)
6. Netty 非阻塞模型 + 异步调度
RocketMQ 的网络通信基于 Netty,是一个 NIO / 异步非阻塞 的通信框架。
- 当 Broker 挂起一个 PullRequest 时,并不会阻塞 Netty 的 IO 线程
- 相关的请求会被封装、挂起、并由 Broker 的业务线程池异步处理
- 当新消息到达并唤醒请求时,也是通过业务线程异步构造响应,再通过 Netty Channel 写回给客户端
整个过程是 异步的、非阻塞的、基于事件驱动 的,这也是 RocketMQ 高并发的基石之一
自己编写类似的异步响应代码
可能到这里还是有些人比较模糊,就是传统的开发过程中,请求进来之后不是就去查数据,查到就返回,没查到就返回null吗,但是这种其实是属于同步返回,但是rocketmq使用的是异步返回,主要是借助到了netty框架的长轮询
那么接下来就给出实例的代码,让大家也能在自己的项目中使用这种机制来提高吞吐量,提高性能
挂起请求的存储结构
@Component
public class DeferredResultHolder {// key 可以是 userId / requestId / token 等,这里简单用 Stringprivate final ConcurrentHashMap<String, DeferredResult<String>> deferredResultMap = new ConcurrentHashMap<>();public void saveDeferredResult(String key, DeferredResult<String> deferredResult) {deferredResultMap.put(key, deferredResult);}public DeferredResult<String> getDeferredResult(String key) {return deferredResultMap.get(key);}public void removeDeferredResult(String key) {deferredResultMap.remove(key);}// 模拟:有新数据到达时,触发某个请求的返回public void onDataArrived(String key, String data) {DeferredResult<String> deferredResult = deferredResultMap.get(key);if (deferredResult != null) {deferredResult.setResult("你的数据已到达: " + data); // 唤醒请求,返回数据removeDeferredResult(key); // 清理}}// 模拟:超时或主动清理public void onTimeoutOrCleanup(String key) {DeferredResult<String> deferredResult = deferredResultMap.get(key);if (deferredResult != null) {deferredResult.setResult("请求超时或无数据,稍后再试");removeDeferredResult(key);}}
}首先就是挂起之后的情况需要一个地方进行存储,然后一般是有很短的超时时间,所以直接基于内存存储就行,这里使用Map结构,也可以像RocketMq那样用List结构,把数据都封装到实体类中
控制器部分的逻辑
@RestController
@RequestMapping("/api")
public class AsyncController {@Autowiredprivate DeferredResultHolder deferredResultHolder;/*** 模拟:客户端请求拉取数据,但服务端暂时没有数据,挂起请求*/@GetMapping("/fetch-data")public DeferredResult<String> fetchData() throws InterruptedException {// 为该请求生成一个唯一 key(可以用 sessionId / requestId 等)String requestId = UUID.randomUUID().toString();// 创建一个 DeferredResult,设置超时时间(比如 30 秒)DeferredResult<String> deferredResult = new DeferredResult<>(30_000L); // 30秒超时// 设置超时回调(可选)deferredResult.onTimeout(() -> {deferredResult.setResult("请求超时,没有等到数据,请稍后重试");deferredResultHolder.removeDeferredResult(requestId);});// 设置完成回调(可选,比如异常处理)deferredResult.onError((ex) -> {deferredResult.setResult("请求出错: " + ex.getMessage());deferredResultHolder.removeDeferredResult(requestId);});// 将 deferredResult 挂起,存入管理器,等待被唤醒deferredResultHolder.saveDeferredResult(requestId, deferredResult);System.out.println("请求已挂起,requestId = " + requestId + ",等待数据...");// 模拟:你也可以在这里返回一个 requestId 给客户端,用于轮询或回调// 但 DeferredResult 已经实现了异步非阻塞返回,无需轮询// 注意:我们不立即 return 数据,而是 defer 返回return deferredResult;}/*** 模拟:另一个接口,用于触发“数据到达”,唤醒挂起的请求* (比如另一个服务/线程/定时任务调用此方法,表示数据来了!)*/@PostMapping("/trigger-data/{requestId}")public String triggerData(@PathVariable String requestId, @RequestParam String data) {System.out.println(" 模拟数据到达,触发 requestId = " + requestId + ",数据:" + data);deferredResultHolder.onDataArrived(requestId, data);return "已触发数据返回 for requestId: " + requestId;}/*** 模拟超时或主动清理某个挂起的请求*/@PostMapping("/timeout/{requestId}")public String forceTimeout(@PathVariable String requestId) {deferredResultHolder.onTimeoutOrCleanup(requestId);return "已强制处理超时请求: " + requestId;}
}访问效果:
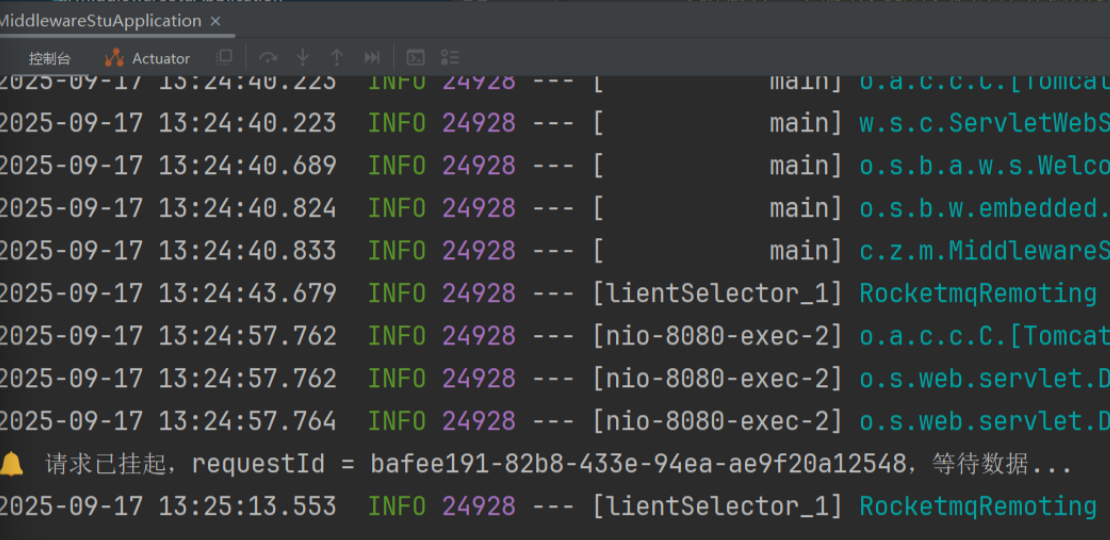

它首先会尝试去获取数据,但是发现一直没有数据,所以等到超时时间一到就返回一个超时信息给到请求方
不过RocketMQ里面不是像我们这样子通过原生的这个类进行返回,而是通过channel.writeAndFlush(response).addListener进行写回
消息消费模式之推/拉模式
拉模式(Pull Consumer)详解
什么是拉模式?
- 消费者主动向 Broker 发起拉取消息的请求(PullMessageRequest)
- 消费者自己决定:
-
- 什么时候拉
- 拉多少条
- 从哪个队列、哪个 offset 开始拉
- Broker 收到请求后:
-
- 如果有消息 → 返回消息
- 如果没有消息:
-
-
- 可以立即返回空
- 或者,如果消费者设置了 挂起(长轮询),就挂起该请求,等有消息了再返回
-
拉模式的特点
| 特点 | 说明 |
| 控制权在消费者 | 消费者决定何时拉取、拉多少、从哪拉 |
| 灵活、精准 | 适合对消费速率、批量、延迟等要求高的场景 |
| 实时性可控 | 消费者可以立即拉,也可以等待 |
| 实现简单直接 | 服务端逻辑相对简单,只负责存储和返回 |
底层实现原理(拉模式)
- 消费者调用 Pull API(如 Java SDK 中的
consumer.pull()或自动拉取循环) - 构造一个 PullMessageRequest,指定:
-
- Topic
- QueueId
- QueueOffset(从哪里开始拉)
- MaxMsgNums(最多拉几条)
- SysFlag(是否挂起、是否提交 offset 等)
- 通过 Netty 长连接 将请求发送给 Broker
- Broker 收到请求后,调用
PullMessageProcessor处理:
-
- 定位到对应的 CommitLog 和 ConsumeQueue
- 根据 QueueOffset 找到真正的消息物理位置
- 读取消息,进行过滤(如 TAG / SQL92)
- 构造响应,返回给消费者
- 消费者收到响应后:
-
- 处理消息
- 提交消费进度(offset)
- 再决定下一次什么时候拉
如果没有消息,且设置了挂起标志(长轮询),Broker 会挂起该请求,等新消息到达后再唤醒并返回,这就是 长轮询(Long Polling),属于拉模式的优化。
推模式(Push Consumer)详解
你可能一直以为:Push 模式是服务端主动把消息推过来,对吧?
但真相是:
RocketMQ 的 Push 模式,并不是服务端真的主动推送消息,而是:
消费者在启动时,通过 SDK 内部封装了一个“不断轮询拉取”的机制,看起来像是服务端在推送,实际上还是消费者在不断地发起拉取请求(Pull),只不过这个过程对用户透明。
推模式的特点
| 特点 | 说明 |
| 使用简单 | 消费者只要订阅 Topic,然后实现消息监听器( |
| 体验像推送 | 消息到达后,消费者几乎能实时处理,像服务端推送过来一样 |
| 控制权仍归消费者 SDK | 实际上是 SDK 在后台不断调用 Pull API,进行长轮询或高频拉取 |
| 适合大多数业务场景 | 对开发者友好,无需关心拉取细节 |
底层实现原理(推模式)
- 消费者调用
consumer.subscribe()+consumer.registerMessageListener() - 启动一个 消费者主线程(或线程池),内部会:
-
- 不断地对订阅的 Topic 和 Queue 进行 消息拉取(调用 Pull API)
- 通常采用 长轮询(挂起请求) 的方式减少无效请求
- 如果有消息:
-
- Broker 返回消息
- SDK 将消息交给用户实现的
MessageListener#consumeMessage()方法处理
- 如果没有消息:
-
- 可能立即再拉
- 或者挂起请求(Long Polling),等待新消息到达后再唤醒,返回消息
关键点:Push 模式是 SDK 帮你封装了“循环/长轮询拉取”的逻辑,让你感觉像是服务端在推送,但其实还是 Pull。
为什么 RocketMQ 不做真正的“服务端推送”?
这是一个非常好的深层问题!
原因主要包括:
| 原因 | 说明 |
| 解耦与扩展性 | 消息存储在 Broker,消费者可能随时上线/下线,服务端很难维护每个客户端的连接状态并主动推送 |
| 网络模型限制 | 真正的推送需要维持大量长连接并跟踪每个消费者的状态,复杂度高,易出错 |
| 消费者处理能力差异 | 不同消费者处理速度不同,服务端推送难以适应所有消费者的节奏 |
| 拉取更可控、更灵活 | 消费者可以根据自身情况决定何时拉、拉多少,避免服务端压力过大或消费者过载 |
| RocketMQ 的设计哲学 | 保持 Broker 简单,将消费逻辑尽量交给消费者控制,适合大规模分布式架构 |
重试队列
消费者在消费某条消息时,如果处理失败(比如抛异常、业务逻辑失败、返回消费状态为失败等),那么 RocketMQ 不会直接丢弃这条消息,也不会无限重试当前队列,而是会把这条消息 转移到一个专门的 “重试队列” 中,然后在 一定延迟之后,再次投递给消费者进行重试消费。
重试队列其实就是一个特殊的一个topic,并且重试队列是以消费者组为维度的,也就是说一个消费者组就会有一个自己的topic(不同消费者组之间的隔离开的)【类似于%RETRY%<ConsumerGroupName>】
然后进入到重试队列之后并不会立马就进行重试,而是有自己的延迟重试策略
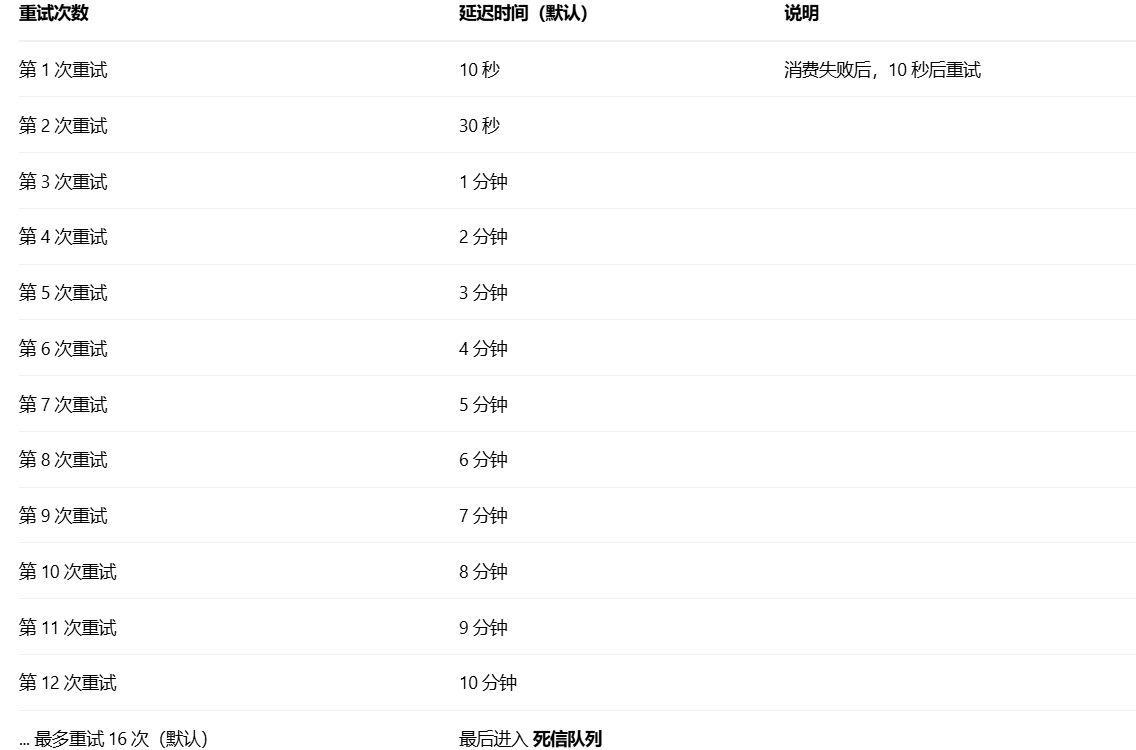
这个最大重试次数是由我们直接通过参数来确定的,如果是默认的情况下的话就是15次重试之后就会进入到死信队列中
重试队列的原理就是和延迟队列一样的原理,通过定时任务不断的去进行扫描,发送到了发送的时间就投递到对应的 topic
死信队列
死信队列(DLQ)是 RocketMQ 用来存放那些 “多次消费失败、已经被重试多次但仍然无法被正常消费” 的消息的 “特殊队列”。
换句话说:
当一条消息被消费者多次消费但一直失败(比如业务逻辑错误、数据问题、异常未捕获等),并且已经达到了最大重试次数(默认是 16 次),那么 RocketMQ 就会认为这条消息 “无法被正常消费”,并且不再继续重试,而是会把这条消息 转移到一个特殊的队列中,这个队列就是:死信队列(Dead Letter Queue, DLQ)。
死信队列就是防止消息因持续消费失败而被无限重试或丢失,同时为这些 “问题消息” 提供一个 “最后存放点”,便于后续排查、告警、人工干预等。
死信队列本身就是一个特殊的topic,消息进入死信队列之后就只能进行手动的处理了
广播机制/集群机制
这两种模式在推拉模式下都是有的
集群机制
定义
在集群模式下,同一条消息只会被同一个 Consumer Group(消费组)内的某一个消费者实例消费一次。也就是说,消息在消费组内是负载均衡的。
特点:
一条消息只被消费组中的一个消费者处理;
适用于需要保证消息只处理一次的场景,比如订单处理、支付等;
具有负载均衡能力,多个消费者共同分担消息压力;
消费者扩容或缩容时,RocketMQ 会自动重新分配队列;
应用场景:
消息需要被业务系统处理且只需处理一次;
多个消费者共同消费,提高吞吐量,但每个消息只处理一次;
示例:
假设有一个 Topic 下有 4 个 Message Queue(消息队列),消费组中有 2 个消费者:
消息队列 Q1, Q2, Q3, Q4
消费者 C1 和 C2
在集群模式下,RocketMQ 会将这 4 个队列分配给 C1 和 C2(比如 C1 拿到 Q1/Q2,C2 拿到 Q3/Q4),每条消息只会被其中一个消费者消费。
广播模式
定义:
在广播模式下,同一个 Consumer Group 中的每一个消费者都会收到该 Topic 下的所有消息,即每条消息会被所有消费者都消费一次。
特点:
每个消费者都会接收到所有的消息;
不支持负载均衡,消息是全量分发的;
常用于广播通知、配置更新等场景;
消费者之间相互独立,不进行队列分配协调;
应用场景:
配置信息的实时推送与更新,所有服务都要获取最新配置;
消息广播,比如系统公告、日志监控信息需要被所有节点接收;
需要每个消费者都处理一遍消息的业务逻辑;
示例:
还是上面那个例子,Topic 有 4 个队列,消费组中有 2 个消费者:
在广播模式下,C1 和 C2 都会收到所有的消息(即所有队列的消息都会被两个消费者都消费);
相当于消息被全量分发到了组内的每一个消费者;
开启的方式:直接在消费者这里开启就行了
consumer.setMessageModel(MessageModel.BROADCASTING); // 广播
consumer.setMessageModel(MessageModel.CLUSTERING); // 集群其实背后的转变就是原本如果是集群模式的话,offset是由broker端来维护的,但是现在因为是广播模式,就只能由客户端来进行维护了
但是会存在offset丢失问题:
比如生产者发送了1~10号消息。消费者当消费到第6个时宕机了。当他重启时,Broker端已经把第10个消息都推送完成了。如果消费者端维护好了自己的Offset,那么他就可以在服务重启时,重新向Broker申请6号到10号的消息。但是,如果消费者端的Offset丢失了,消费者服务依然可以正常运行,但是6到10号消息就无法再申请了。后续这个消费者就只能获取10号以后的消息。
当然如果是广播模式下,我们是允许它丢失的,因为用了这个模式基本就没法保证消息的完整性了
批量消息
就是能一次性将多条消息一起塞到一个集合中进行发送
Message message = new Message();message.setBody("123".getBytes());message.setTopic("123");ArrayList<Message> messages = new ArrayList<>();for (int i = 0; i < 10; i++) {Message msg = new Message("BatchTopic", // Topic"BatchTag", // Tag(可选)"Key-" + i, // Key(可选)("这是第 " + i + " 条批量消息").getBytes(StandardCharsets.UTF_8));messages.add(msg);}producer.send(messages);但是这种虽然减少了网络来回的IO开销,但是单次消息过大也造成了大量的性能开销,而且如果出现发送失败的成本是比较大的
解决的方法就是将过大的集合进行拆分成一个一个批次进行发送,然后还可以进行压缩(或序列化)发送,也会比较节省资源
Message message = new Message();
message.setBody("123".getBytes());
message.setTopic("123");
ArrayList<Message> messages = new ArrayList<>();
for (int i = 0; i < 10; i++) {Message msg = new Message("BatchTopic", // Topic"BatchTag", // Tag(可选)"Key-" + i, // Key(可选)("这是第 " + i + " 条批量消息").getBytes(StandardCharsets.UTF_8));messages.add(msg);
}
int batchSize = 100; // 没批100条
for (int i = 0; i < messages.size(); i += batchSize) {int end = Math.min(i + batchSize, messages.size());List<Message> batch = messages.subList(i, end);SendResult result = producer.send(batch);System.out.println("发送了一批,数量:" + batch.size());
}