SQL Server到Hive:批处理ETL性能提升30%的实战经验
在企业数字化转型进程中,将 SQL Server 的业务数据同步至 Hive 数据仓库,是构建大数据分析平台的关键一步。然而,当数据量突破千万级门槛,传统同步方式往往陷入效率低下、稳定性差的困境。本文将分享使用ETLCLoud工具实现千万级数据量下SQL Server到Hive高效同步的实战经验。
1.配置数据源
来到平台首页进入数据源管理模块。
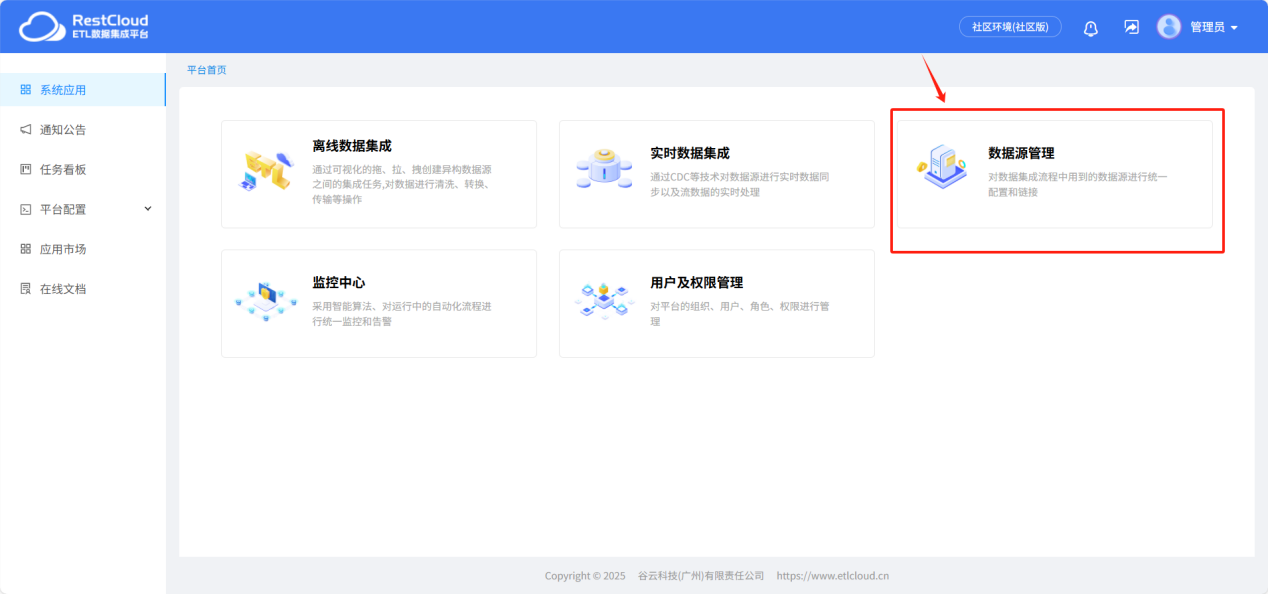
在新建数据源中选择SQLserver数据源模板
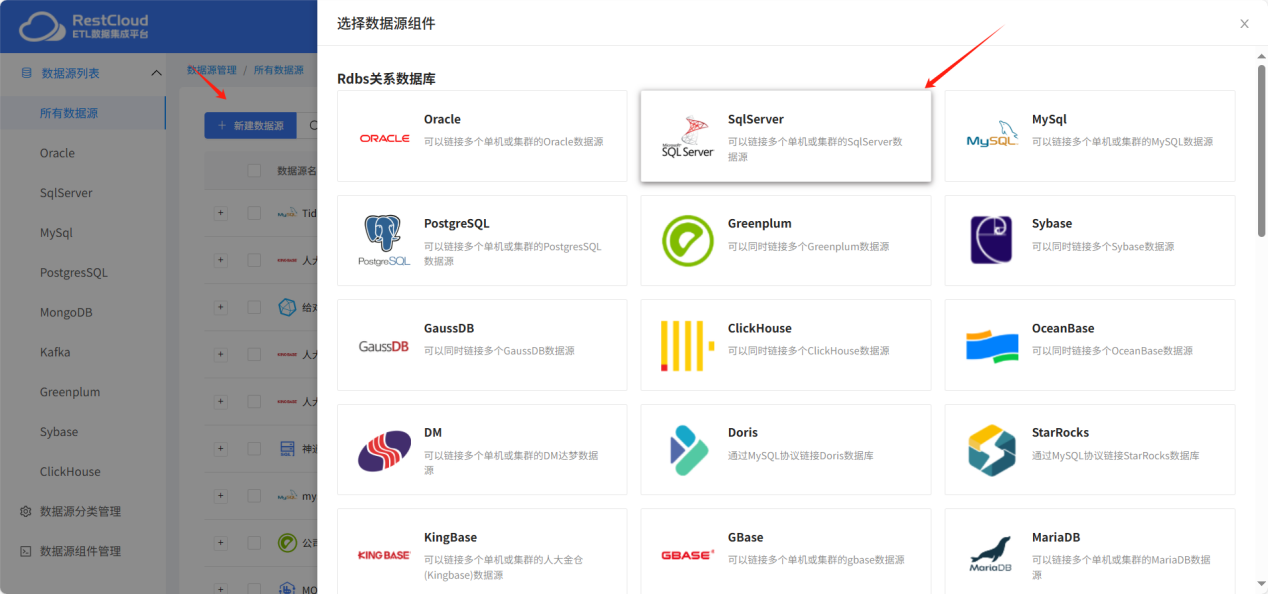
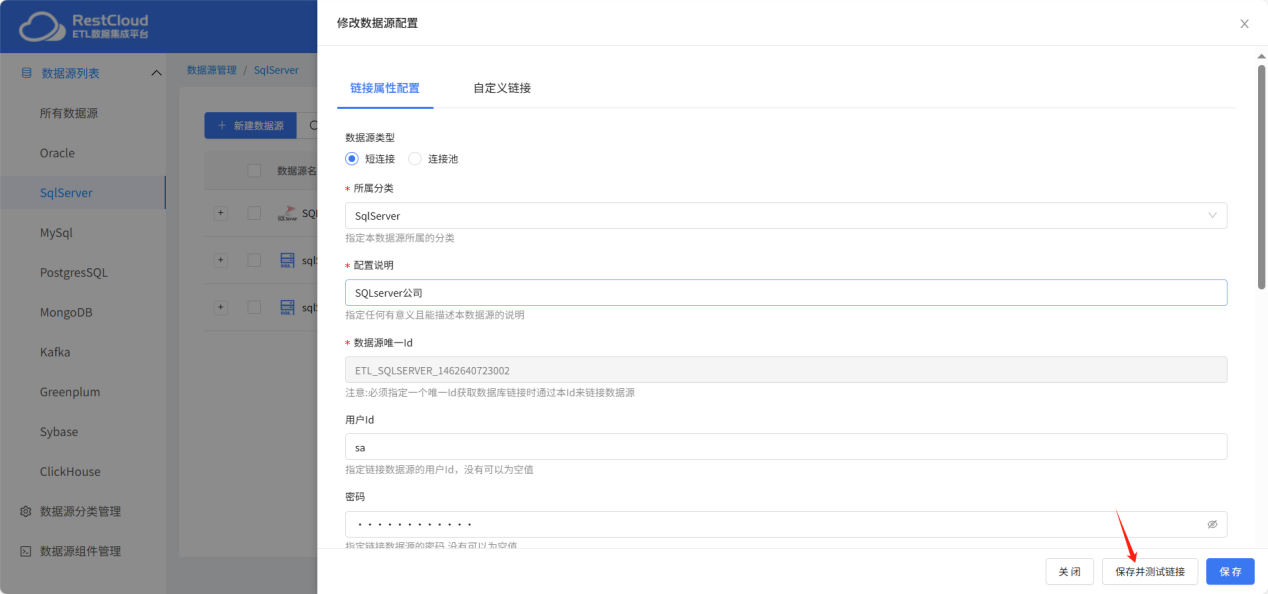
根据实际情况配置连接,注意url的配置。
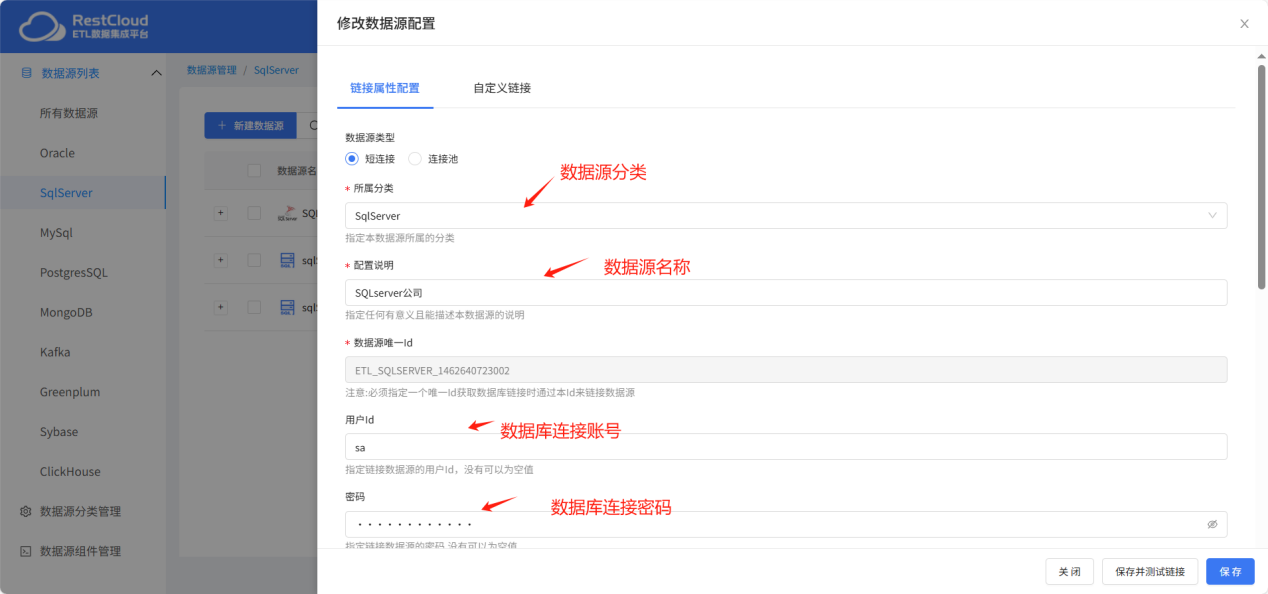
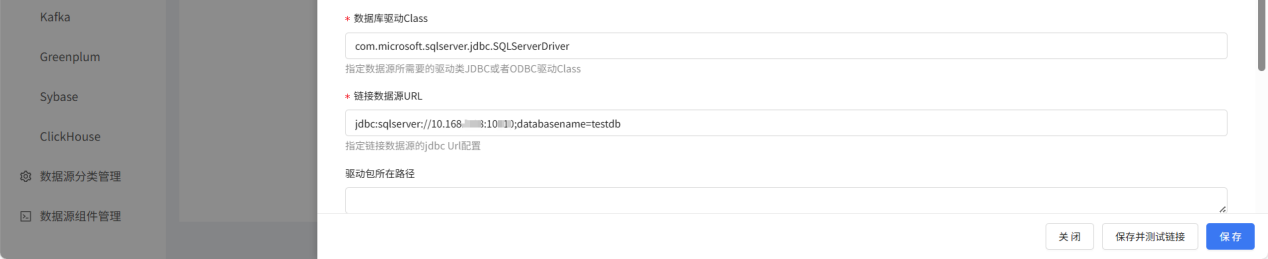
配置完成后点击保存并测试提示链接成功即可。
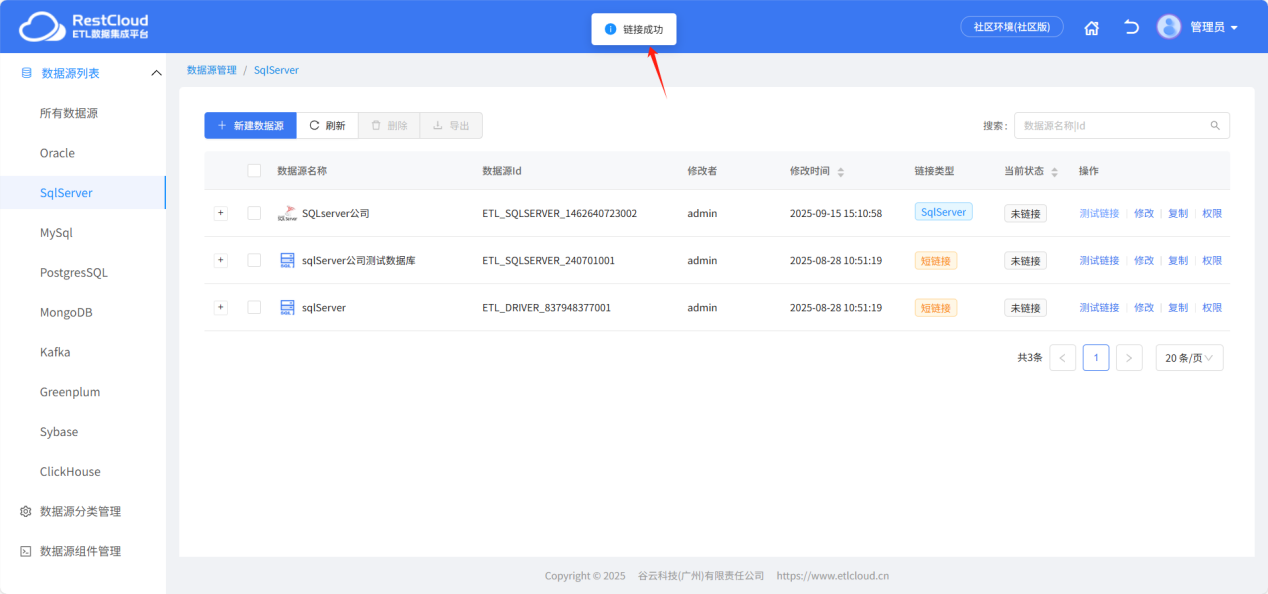
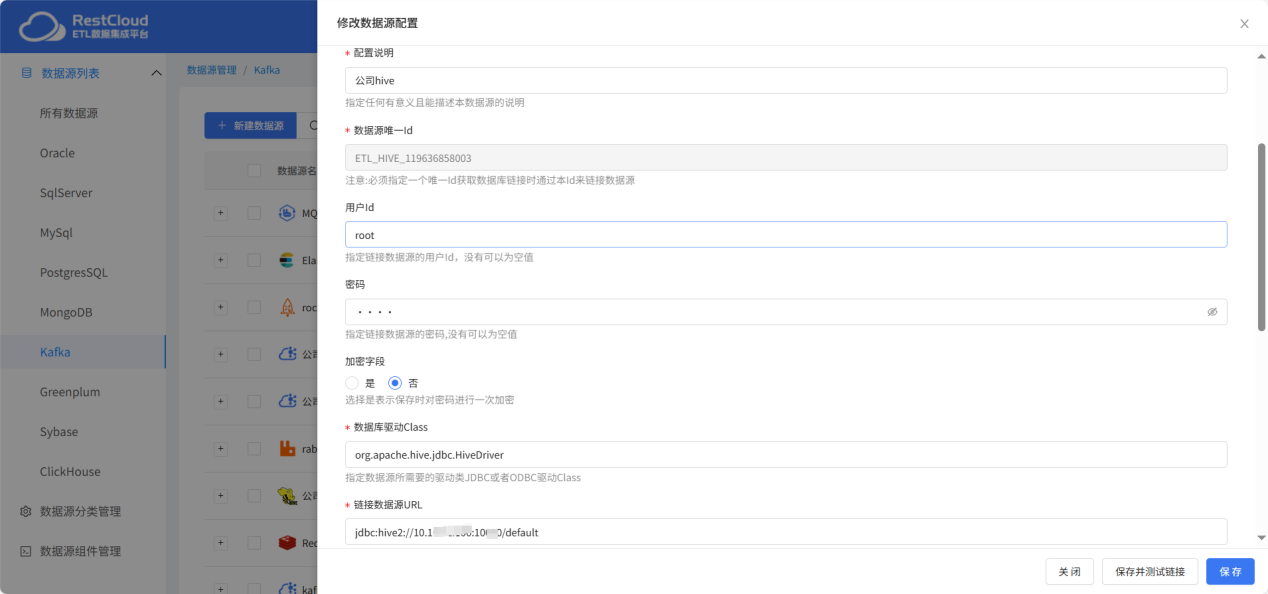
用同样的步骤再次配置一个目标端hive数据源的链接。
现在SQLserver里有一张数据量是一千万的表。
2.同步流程设计
ETLCloud无需用户编写复杂代码,即可实现高效、安全的分页查询和并发同步。其流程设计如下:
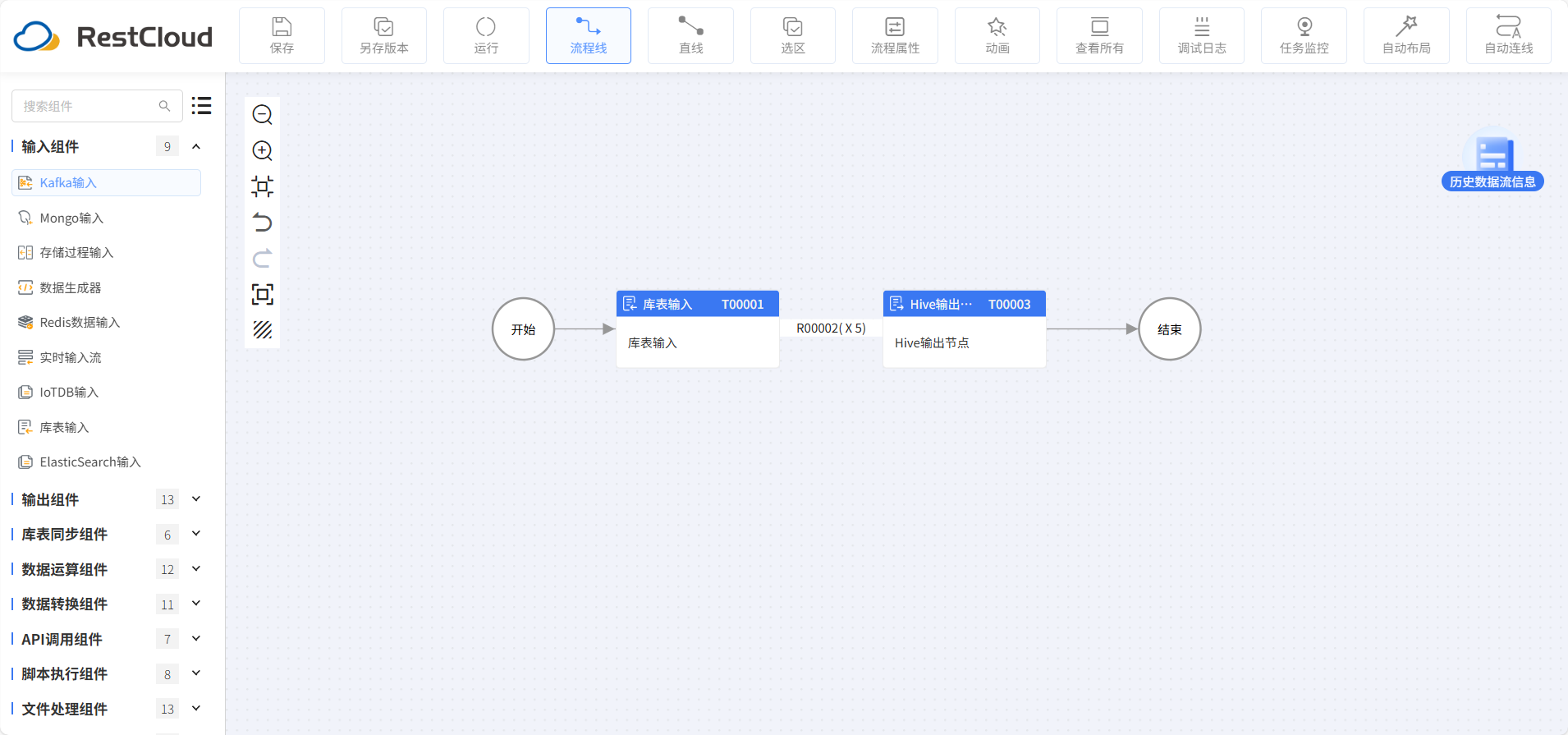
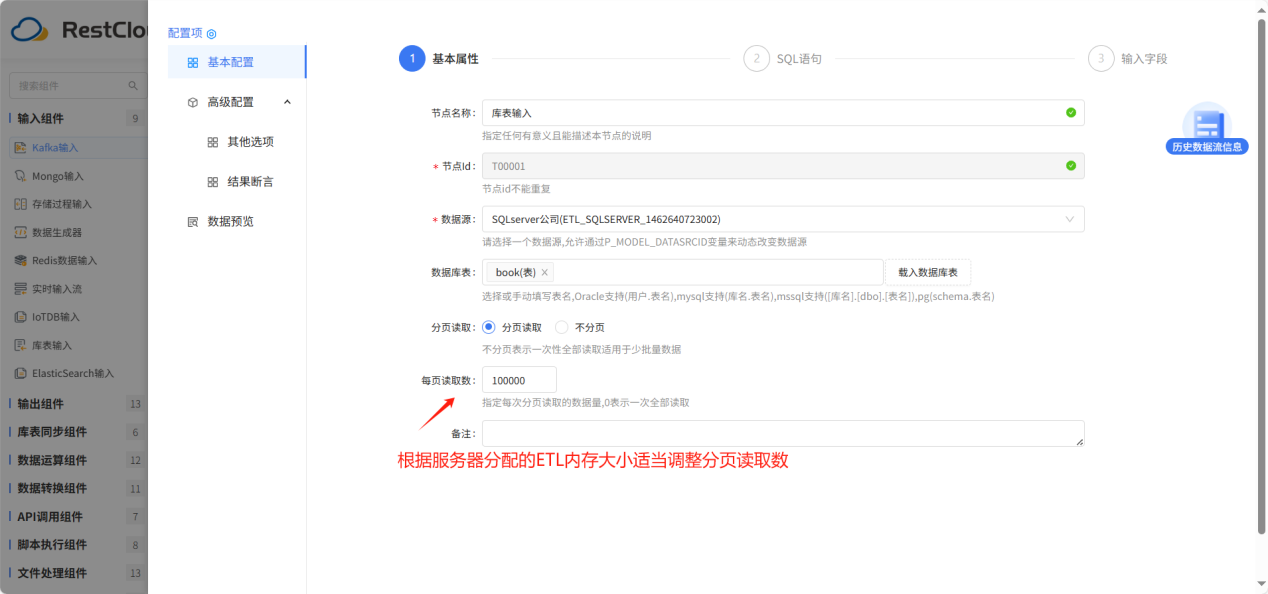
库表输入配置
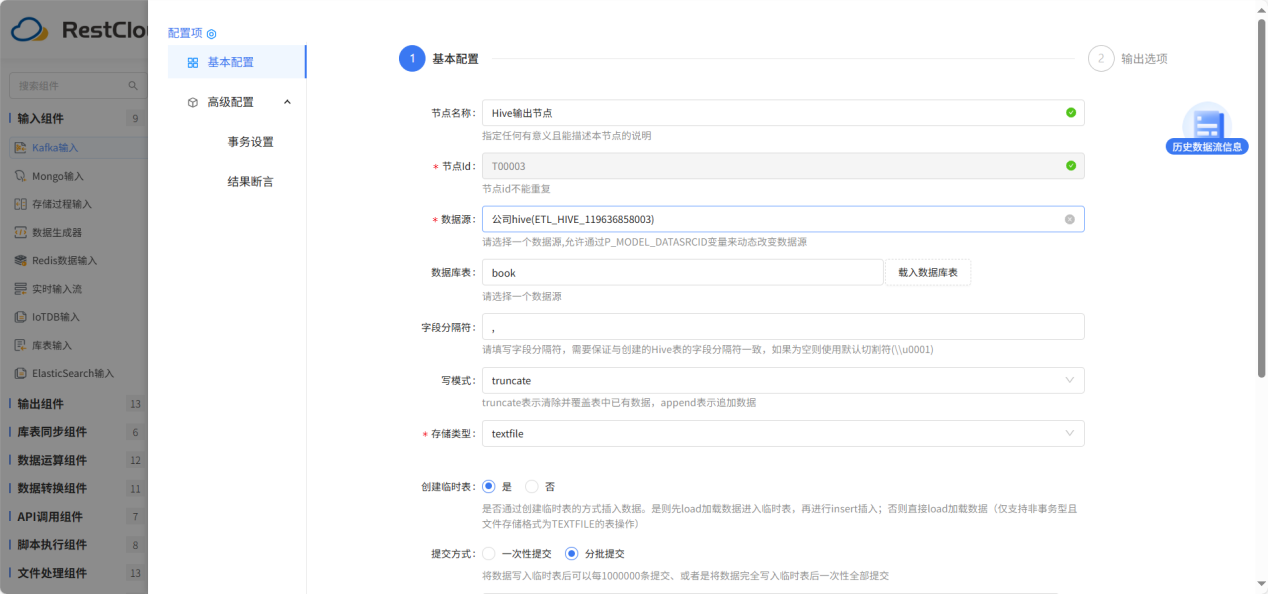
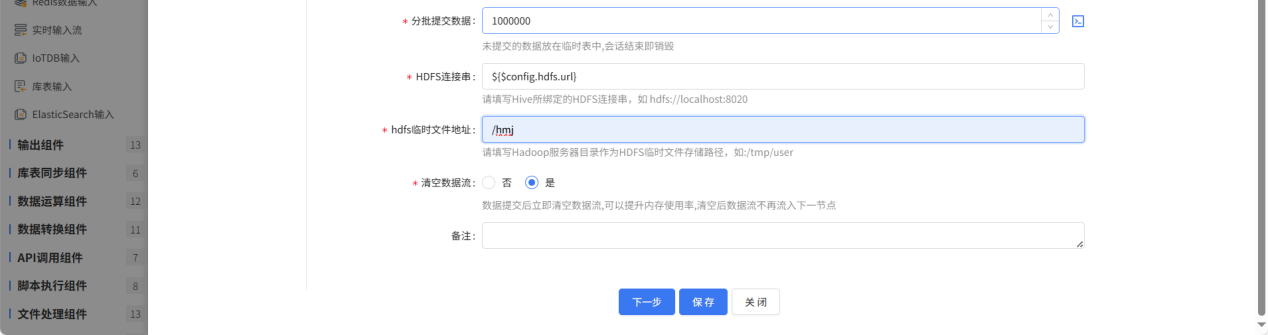
Hive输出配置
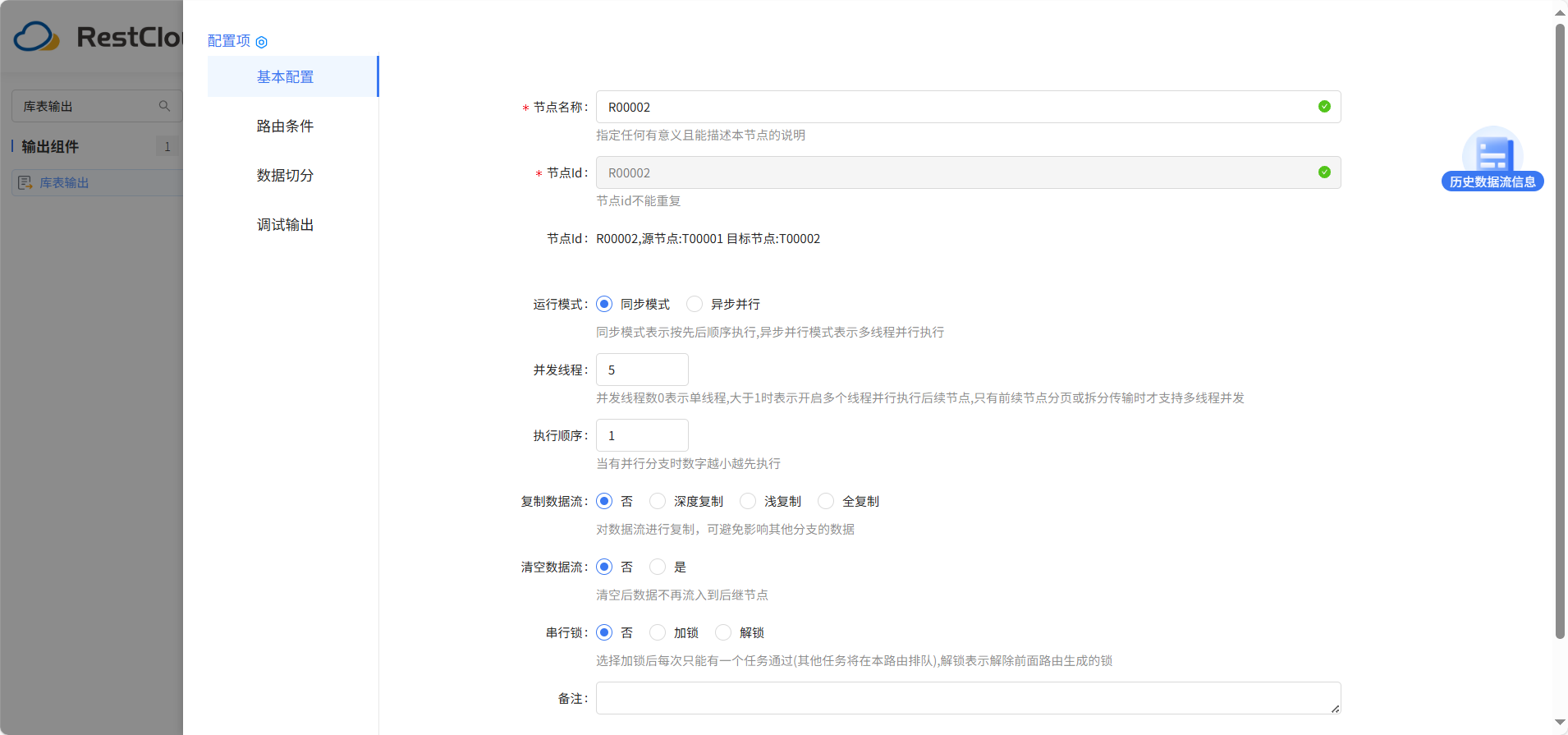
路由线设置并发数
3.运行结果
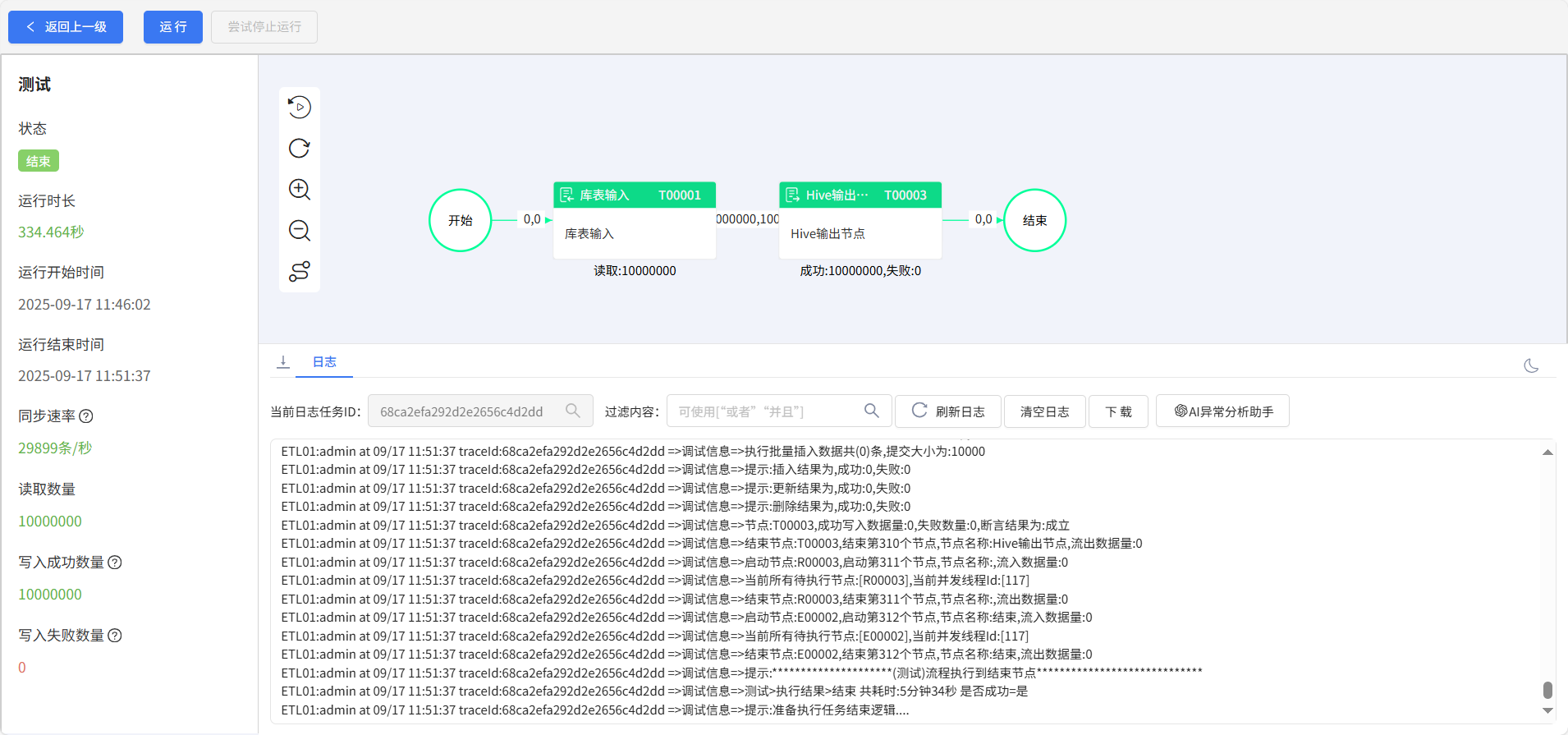
总结:
ETLCloud作为一款数据集成工具,通过其可视化开发、强大转换能力、多目标支持和企业级可靠性,将流式ETL的复杂技术细节封装起来,让数据工程师和分析师能够更专注于业务逻辑本身,而非底层实现,极大地加速了企业从数据到实时洞察的进程,是构建现代实时数据架构的理想选择。