Mysql-主从复制与读写分离
文章目录
- Mysql 主从复制、读写分离
- 一、前言
- 二、主从复制原理
- 2.1 MySQL的复制类型
- 2.2 MySQL主从复制的核心流程:两日志、三线程
- 2.3 主从复制延迟:原因与优化方案
- 2.3.1 延迟核心原因
- 2.3.2 优化方案
- 2.4 MySQL 四种同步方式
- 三、主从复制实验
- 3.1、MySQL手工编译安装
- 3.2、主从服务器时间同步
- 3.2.1 master服务器配置
- 3.2.2 两台SLAVE服务器配置
- 3.3、配置主从同步
- 3.3.1 master服务器修改配置文件
- 3.3.2 从服务器配置
- 3.4、测试数据同步
- 四、MySQL 读写分离
- 4.1、核心概念
- 4.2、为什么要读写分离?
- 4.3、适用场景
- 4.4、主从复制与读写分离
- 4.5、企业 使用MySQL 读写分离场景
- 4.5.1 基于程序代码内部实现
- 4.5.2 基于中间代理层实现
- 五、读写分离实验
- 5.1 MyCat 实现 MySQL 主从读写分离
- 六、总结
Mysql 主从复制、读写分离
一、前言
在企业级应用中,随着业务增长,单台 MySQL 数据库在安全性(单点故障风险)、高可用性(故障后服务中断)和高并发(读写请求拥堵)方面逐渐无法满足需求。此时,通过 “主从复制” 实现数据多节点同步,再结合 “读写分离” 分担请求压力,成为解决上述问题的核心方案 —— 主从复制保障数据一致性与高可用,读写分离提升并发处理能力,二者相辅相成,构成企业级 MySQL 架构的基础。
二、主从复制原理
MySQL 主从复制是指将主库(Master)的增量数据变更同步到一台或多台从库(Slave)的过程,核心依赖 “两日志、三线程” 机制,支持多种复制类型与同步策略。
2.1 MySQL的复制类型
| 复制类型 | 核心逻辑 | 优点 | 缺点 |
|---|---|---|---|
| 基于语句(STATEMENT) | 同步主库执行的完整 SQL 语句,不记录具体数据变更(MySQL 默认复制类型) | 1. 二进制日志体积小,节省磁盘空间 2. 日志可直接审计,便于追溯执行过的 SQL | 1. 含非确定性函数(如 NOW()、RAND())时,可能导致主从数据不一致2. 不支持部分特殊 SQL(如 LOAD DATA INFILE 特定场景) |
| 基于行(ROW) | 不记录 SQL 语句,直接同步数据行的变更结果(如某行数据的新增/修改/删除详情) | 1. 完全规避函数一致性问题,主从数据绝对一致 2. 支持所有数据变更场景,兼容性强 | 1. 高并发/大数据量变更时,日志体积显著增大(如批量更新 10 万行,需记录 10 万行的变更) 2. 日志可读性差,无法直接通过日志追溯 SQL 操作 |
| 混合类型(MIXED) | 自动判断 SQL 类型:简单语句(如单表更新)用 STATEMENT,复杂语句(含函数/特殊操作)用 ROW | 1. 兼顾 STATEMENT 的日志体积优势与 ROW 的一致性优势 2. 无需人工干预,适配大多数业务场景 | 1. 特殊复杂场景(如自定义函数嵌套)仍需手动指定复制类型 2. 日志格式不统一,审计时需区分两种日志类型 |
2.2 MySQL主从复制的核心流程:两日志、三线程
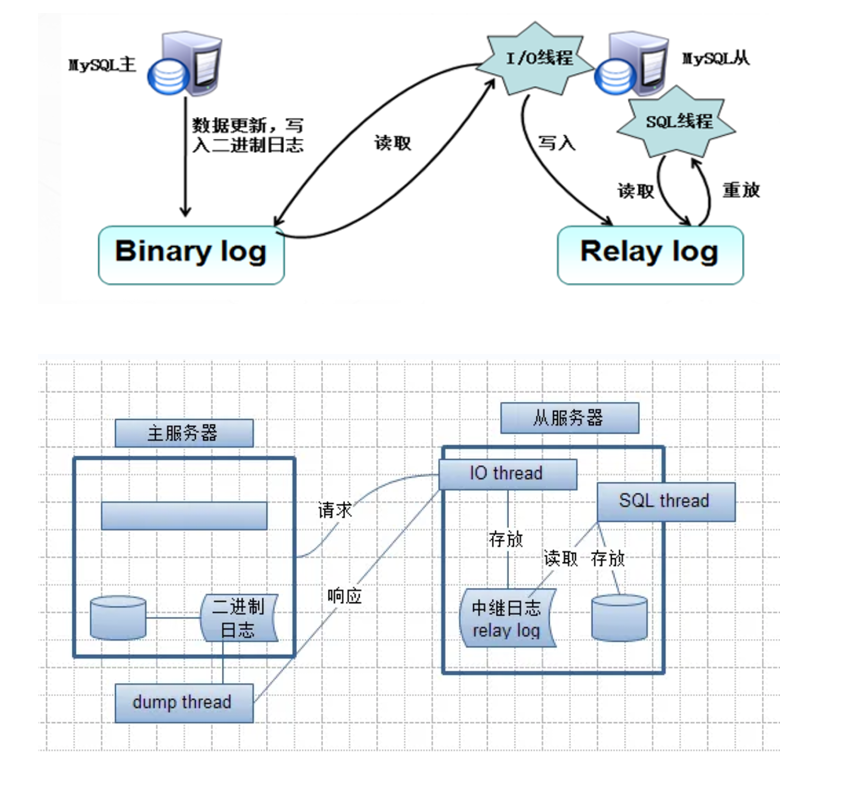
主从复制的本质是 “主库记录变更→从库拉取变更→从库重放变更”,具体通过** 2 个日志文件**和 3 个工作线程实现,流程如下:
1. 核心组件
两日志:
主库:二进制日志(Binary Log):记录主库所有数据变更(INSERT/UPDATE/DELETE 等),是复制的 “数据源”。
从库:中继日志(Relay Log):暂存从主库拉取的 Binary Log 内容,避免直接操作主库日志,降低耦合。
三线程:
主库:Binlog Dump 线程:响应从库 IO 线程的请求,读取主库 Binary Log 并发送给从库。
从库:IO 线程:连接主库,拉取 Binary Log 内容,写入本地 Relay Log。
从库:SQL 线程:读取 Relay Log 内容,重放 SQL 语句以同步主库数据。
2. 完整流程
- 主库执行事务并提交前,将数据变更写入 Binary Log,随后通知存储引擎完成事务提交。
- 从库 IO 线程主动连接主库,请求同步 Binary Log;主库 Binlog Dump 线程读取 Binary Log 中的事件(若已同步完成则睡眠等待新事件),并发送给从库。
- 从库 IO 线程将接收的事件写入本地 Relay Log。
- 从库 SQL 线程读取 Relay Log 中的事件,按顺序重放 SQL 语句,使从库数据与主库一致。
⚠️关键限制:从库 SQL 线程是串行执行的,主库的并行更新无法在从库并行重放,这是导致 “主从延迟” 的核心原因之一。
2.3 主从复制延迟:原因与优化方案
2.3.1 延迟核心原因
1. 主库高并发:大量事务堆积,Binary Log 生成速度超过从库同步速度。
2. 网络延迟:主从跨机房 / 带宽不足,导致 IO 线程拉取日志缓慢。
3.硬件差异:主库用高性能 CPU/SSD,从库用低配硬件,IO 或计算能力不足。
4.异步复制特性:默认异步复制下,主库无需等待从库同步,天然存在延迟。
2.3.2 优化方案
- 硬件层面:从库使用与主库相当的硬件(如 SSD 磁盘、高主频 CPU、大内存),避免跨机房部署。
- 参数优化:从库增大 innodb_buffer_pool_size,减少磁盘 IO(让更多操作在内存完成)。
- 复制策略优化:采用 “并行复制”(MySQL 5.6+ 支持)提升从库 SQL 线程执行效率;采用 “半同步 / 增强半同步复制” 降低延迟风险。
2.4 MySQL 四种同步方式
MySQL 提供了四种数据同步策略,核心差异在于主库等待从库确认的时机与范围,直接影响数据安全性、性能及一致性,具体如下:
| 同步方式 | 核心逻辑 | 关键特点 | 数据安全性 | 性能影响 | 适用场景 |
|---|---|---|---|---|---|
| 异步复制(Async Replication) | 主库执行事务并写入 Binary Log 后,立即返回“成功”,无需等待从库任何响应。 | 1. MySQL 默认同步方式 2. 主从完全异步,主库性能不受从库影响 3. 极端情况(主库宕机)可能丢失未同步的事务 | 低 | 最优 | 非核心业务(如日志、统计),优先追求高并发 |
| 同步复制(Sync Replication) | 主库需等待所有从库完全执行事务并返回成功后,才返回“成功”给客户端。 | 1. 数据零丢失,强一致性 2. 主库性能严重依赖从库数量与性能(从库越多/越慢,主库阻塞越久) | 最高 | 最差 | 核心金融场景(如转账),不允许任何数据丢失 |
| 半同步复制(Semi-Sync Replication) | 主库写入 Binary Log 后,等待至少 1 个从库将日志写入本地 Relay Log 并返回 ACK(确认),再返回“成功”。 | 1. MySQL 5.5 引入,需主从安装 semisync 插件2. 等待超时(默认 10 秒)自动降级为异步复制 3. 等待点为“主库事务提交后”(可能引发主从切换时的数据不一致) | 中 | 中 | 常规核心业务(如订单),兼顾安全与性能 |
| 增强半同步复制(Lossless Semi-Sync Replication) | 主库写入 Binary Log 后,先等待从库 ACK,再执行事务提交(等待点提前)。 | 1. MySQL 5.7 引入,默认配置(rpl_semi_sync_master_wait_point=AFTER_SYNC)2. 解决半同步的“主从切换数据不一致”问题(提交前等待,外界看不到未同步的事务) | 中高 | 中 | 对一致性要求更高的核心业务(如支付) |
总结:选择同步方式需权衡“数据安全性”与“性能损耗”——非核心业务用异步追求性能,金融级业务用同步保障安全,多数场景可采用增强半同步平衡二者。实际部署中,需结合业务对数据一致性的容忍度、并发量及硬件成本综合决策。
三、主从复制实验
基于 CentOS 7.6 环境搭建 “1 主 2 从” MySQL 5.7 主从架构,核心步骤包括 “时间同步→主库配置→从库配置→同步测试”。
整个实验的环境 以及服务器信息
- 环境部署:CentOS 7.9
- 虚拟机服务环境:
- Master服务器:192.168.100.129,部署 mysql 5.7
- Slave1服务器:192.168.100.140,部署 mysql 5.7
- Slave2服务器:192.168.100.150,部署 mysql 5.7
- MyCat服务器:192.168.100.200(预备机器),部署 jdk-8u191-linux + MyCat中间件
3.1、MySQL手工编译安装
详情请看数据库安装
3.2、主从服务器时间同步
主从节点时间必须一致,否则会导致 Binary Log 时间戳异常,同步失败。以 Master 为时间源,Slave 定期同步。
3.2.1 master服务器配置
① 安装ntp、修改配置文件
[root@master ~]# systemctl stop firewalld.service
[root@master ~]# setenforce 0
[root@master ~]# yum -y install ntpdate ntp #安装ntp软件
[root@master ~]# ntpdate ntp.aliyun.com #时间同步
[root@master ~]# vim /etc/ntp.conf #编辑配置文件
fudge 127.127.1.0 stratum 10
#设置本机的时间层级为10级,0级表示时间层级为0级,是向其他服务器提供时间同步源的意思,不要设置为0级server 127.127.1.0 #设置本机为时间同步源
② 开启NTP服务
[root@master ~]# systemctl start ntpd && systemctl enable ntpd
3.2.2 两台SLAVE服务器配置
① 安装ntp、ntpdate服务
[root@localhost ~]# yum install ntp ntpdate -y
② 关闭防火墙、增强性安全功能
[root@slave1 ~]# systemctl stop firewalld.service
[root@slave1 ~]# setenforce 0
③ 时间同步master服务器
[root@localhost ~]# ntpdate 192.168.100.129
④ 布置周期性任务
crontable -e
*/10 * * * * /usr/sbin/ntpdate 192.168.100.129
3.3、配置主从同步
3.3.1 master服务器修改配置文件
[root@master ~]# vim /etc/my.cnf
#在mysqld模块下修改一下内容
#开启二进制日志文件(之后生成的日志名为master-bin)
log_bin=master-bin
#开启从服务器日志同步
log_slave_updates=true
#主服务器id为1(不可重复)
server_id = 1重启服务
[root@master ~]# systemctl restart mysqld配置规则
[root@master ~]# mysql -uroot -p123mysql> GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.100.%' IDENTIFIED BY '123';
#在主库上创建一个名为myslave、密码为123的专用账号,授予其主从复制必需的REPLICATION SLAVE权限,允许192.168.100.网段的从库通过该账号连接主库并同步数据。#刷新权限表
mysql> flush privileges;查看master数据库状态
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000001 | 604 | | | |
+-------------------+----------+--------------+------------------+-------------------+#以上可见产生了master-bin.000001日志文件,定位为604
#从服务器需要定位到此处进行复制
3.3.2 从服务器配置
[root@slave1 ~]# vim /etc/my.cnf
#开启二进制日志文件
log-bin=slave-bin#设置server id为22,slave2 为23
server_id = 2 #另一台可以设为3#从主服务器上同步日志文件记录到本地
relay-log=relay-log-bin#定义relay-log的位置和名称(index索引)
relay-log-index=slave-relay-bin.index开启从服务器功能
[root@slave1 ~]# mysql -uroot -p123456mysql> change master to master_host='192.168.100.129',master_user='myslave',master_password='123',master_log_file='master-bin.000001',master_log_pos=604;
#指定主库 IP(192.168.100.129)、用于复制的专用账号(myslave/123),并明确从主库的二进制日志文件(master-bin.000001)的第 604 字节位置开始同步数据,以此初始化从库与主库的复制关联,为后续启动 IO 线程(拉取主库日志)和 SQL 线程(执行日志)提供准确的连接信息和同步起点。mysql> start slave;
#在从库执行,用于启动从库的两个核心复制线程:IO 线程(连接主库并拉取二进制日志到本地中继日志)和 SQL 线程(读取中继日志并执行其中的 SQL 语句以同步数据),从而正式开始主从数据同步过程。查看从服务器状态
mysql> show slave status\G;
*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.100.129Master_User: myslaveMaster_Port: 3306Connect_Retry: 60Master_Log_File: master-bin.000001Read_Master_Log_Pos: 604Relay_Log_File: relay-log-bin.000002Relay_Log_Pos: 284Relay_Master_Log_File: master-bin.000001Slave_IO_Running: YesSlave_SQL_Running: YesReplicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0Last_Error: Skip_Counter: 0Exec_Master_Log_Pos: 412Relay_Log_Space: 455Until_Condition: NoneUntil_Log_File: Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error: Last_SQL_Errno: 0Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 11Master_UUID: c59043ec-5ad8-11ea-b895-000c29fe085bMaster_Info_File: /home/mysql/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update itMaster_Retry_Count: 86400Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0
#一下字段可以查看对应错误,针对纠错。Last_IO_Errno: 0Last_IO_Error: Last_SQL_Errno: 0Last_SQL_Error:
#这两个值为yes一般就代表成功。 Slave_IO_Running: YesSlave_SQL_Running: Yes1.若slave重新配置,必须
stop slave #关闭上一次的slave。
reset slave #清除缓存。2.若主机不正当的操作(例如删除从机不存在的表)导致从机出现报错,可以
SET GLOBAL sql_slave_skip_counter = 1; #表示跳过一个错误事件。
不然容易是从机I/O进程关闭。同理、开启另一台从服务器同步
3.4、测试数据同步
1.在主服务器上创建一个数据库
mysql> create database work;mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| work |
+--------------------+2.在两台从服务器上直接查看数据库列表
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| work |
+--------------------+以上,主从同步复制配置完成
四、MySQL 读写分离
主从复制解决了数据一致性问题,但所有请求仍可能集中在主库,需通过 “读写分离” 将读请求分流到从库,进一步提升并发能力。
4.1、核心概念
读写分离是指:主库仅处理写请求(INSERT/UPDATE/DELETE/DDL),从库仅处理读请求(SELECT),通过主从复制同步写操作产生的数据变更,实现 “写主读从” 的架构。
4.2、为什么要读写分离?
- 写操作耗时:写请求(如批量插入、复杂更新)需锁表 / 事务,耗时较长(例:写 1 万条数据需 3 分钟)。
- 读操作频繁:多数业务中读请求占比远超写请求(如电商商品页查询、新闻浏览),读操作耗时短(例:读 1 万条数据需 5 秒)。
- 分流压力:若读写请求都走主库,主库易成为瓶颈;将读请求分流到从库,可显著降低主库负载。
4.3、适用场景
- 读请求占比高(如读:写 = 10:1 以上)的业务,如博客、电商、新闻系统。
- 单库并发量超过 1000 QPS,且读请求成为瓶颈的场景。
- 对数据一致性要求不是 “实时”(允许毫秒级延迟)的业务。。
4.4、主从复制与读写分离
- 基础与上层:主从复制是读写分离的前提 —— 若无主从复制,从库数据无法与主库同步,读请求会获取旧数据。
- 协同目标:主从复制保障 “数据一致性”,读写分离保障 “高并发”,二者结合实现 “高可用 + 高并发” 的企业级架构。
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
4.5、企业 使用MySQL 读写分离场景
4.5.1 基于程序代码内部实现
- 核心逻辑:在应用程序代码中直接判断 SQL 操作类型——写操作(INSERT/UPDATE/DELETE/DDL)路由到主库,读操作(SELECT)路由到从库(可通过轮询、随机或权重算法选择从库)。
- 优点:
- 无额外中间件开销,性能损耗低;
- 路由逻辑可自定义,灵活适配业务场景(如特定读请求强制走主库);
- 无需依赖第三方工具,部署简单。
- 缺点:
- 代码侵入性强,需开发人员在代码中嵌入路由逻辑,增加维护成本;
- 多语言应用(如 Java+Python)需重复实现路由逻辑,一致性难保证;
- 架构调整(如增减从库)需修改代码并重新部署,运维灵活性差。
- 适用场景:单一语言开发的中小型应用,读请求占比稳定且业务逻辑简单(如内部管理系统)。
4.5.2 基于中间代理层实现
- 核心逻辑:在客户端与数据库之间部署独立的代理服务(如 MyCat、Atlas),代理层统一接收所有数据库请求,通过解析 SQL 判断操作类型,自动将写请求转发到主库、读请求分发到从库,应用程序无需感知底层数据库架构。
- 主流代理工具对比:
| 代理工具 | 开发方 | 支持事务 | 支持存储过程 | 核心优势 | 主要局限 |
|---|---|---|---|---|---|
| MySQL-Proxy | MySQL 官方 | 有限支持 | 有限支持 | 轻量、开源,与 MySQL 兼容性好 | 需自定义 Lua 脚本实现路由,学习成本高,高并发下性能一般 |
| Atlas | 奇虎 360 | 支持 | 支持 | 高并发承载能力强(日均数十亿请求),稳定可靠 | 文档较少,二次开发难度大,社区活跃度一般 |
| Amoeba | 阿里(陈思儒) | 不支持 | 不支持 | 配置简单、易用性高,适合入门 | 不支持事务和存储过程,不适合复杂业务场景 |
| MyCat | 开源社区 | 支持 | 支持 | 功能全面(读写分离+分库分表),文档丰富,社区活跃 | 高并发场景需优化配置(如连接池、线程数),资源占用略高 |
- 优点:
- 对应用透明,无需修改代码,开发与运维职责分离;
- 架构调整(如增减从库、切换主从)可在代理层完成,灵活性高;
- 支持多语言应用,统一路由规则,降低跨语言维护成本。
- 缺点:
- 引入代理层增加系统复杂度,需单独维护代理服务;
- 代理层可能成为新瓶颈(需合理配置资源);
- 部分代理工具对复杂 SQL(如存储过程、子查询)支持有限。
- 适用场景:多语言开发的大型应用(如电商平台、微服务架构),读请求量大且需频繁调整数据库拓扑的场景。
五、读写分离实验
整个实验的环境 以及服务器信息
- 环境部署:CentOS 7.6(注:原文“cetus7.6”为笔误,修正为CentOS 7.6)
- 虚拟机服务环境:
- Master服务器:192.168.100.129,部署 mysql 5.7
- Slave1服务器:192.168.100.140,部署 mysql 5.7
- Slave2服务器:192.168.100.150,部署 mysql 5.7
- MyCat服务器:192.168.100.200,部署 jdk-8u191-linux + MyCat中间件
注意:先完成主从复制的配置,再来配置mycat更为合适。
5.1 MyCat 实现 MySQL 主从读写分离
详情请跳转读写分离
六、总结
MySQL 主从复制与读写分离是企业级数据库架构的基石:
- 1.主从复制通过 “两日志、三线程” 实现数据同步,提供数据冗余与高可用,支持异步、同步、半同步等多种策略,平衡性能与安全性。
- 2.读写分离基于主从复制,将读请求分流到从库,解决主库并发瓶颈,实现方式分为 “程序内” 和 “中间代理层”,需根据业务规模选择。
- 3.实际生产中,需结合监控工具(如 Prometheus+Grafana)监控主从延迟、代理层健康状态,同时做好故障切换预案(如 MHA 实现主库自动切换),确保架构稳定运行。