Scrapy进阶:POST请求模拟登录实战与管道的使用
模拟登录,发送POST请求
scrapy.Request发送post请求
我们知道可以通过scrapy.Request()指定method、body参数来发送post请求;但是通常使用scrapy.FormRequest()来发送post请求
发送post请求
注意:scrapy.FormRequest()能够发送表单和ajax请求
思路分析
-
找到post的url地址:点击登录按钮进行抓包,然后定位url地址
-
找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
-
否登录成功:通过请求个人主页,观察是否包含用户名
项目演示
网址:https://gitee.com/
需求:
-
获取到登录后个人中心页的用户名(要求使用POST请求)
步骤:
-
进入网页
-
有账号则点击登录/没有账号则先注册再进行登录操作
-
打开开发者工具,刷新页面
-
点击保留日志,由于我们登录后页面会自动跳转,如果没有保留日志就没有办法分析登录的文件
下图为登录页的数据包login,可以先点击预览看看大概是什么内容,这里发现就是登录页面的源文件
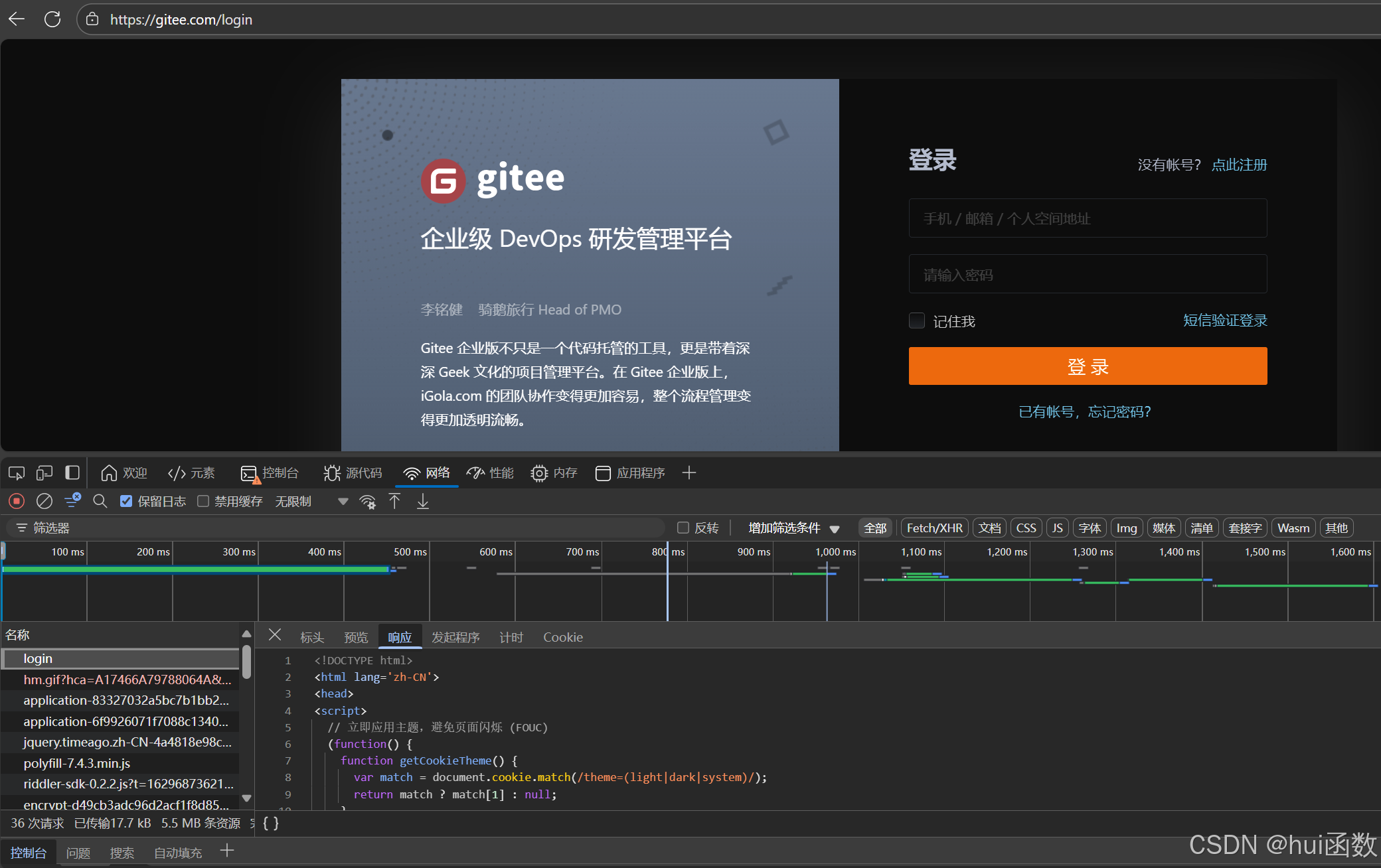
-
输入对应的用户名和密码,点击登录
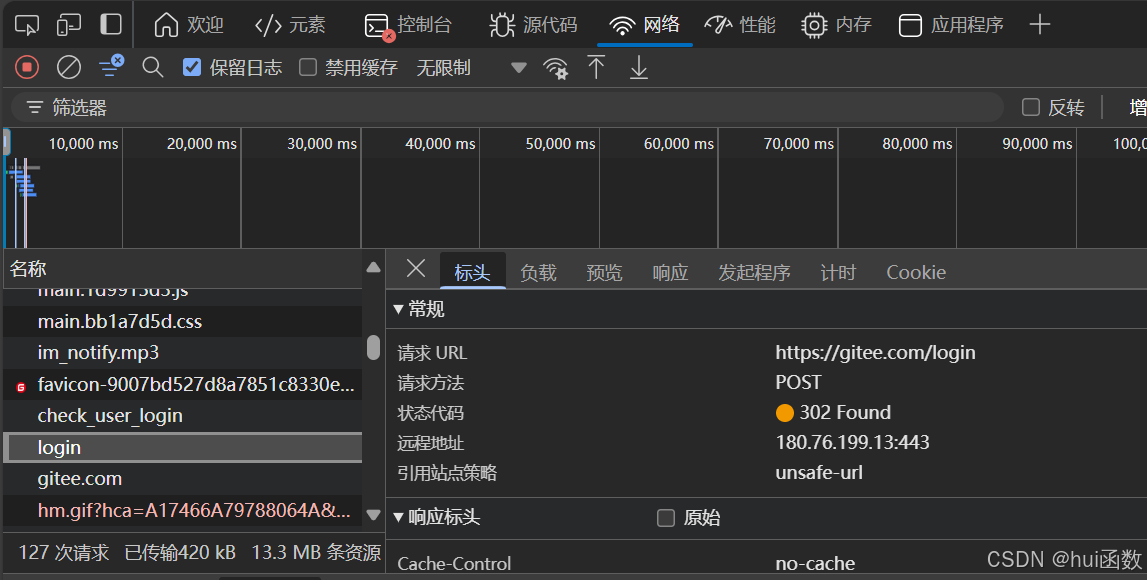
这里由于我们的请求文件比较多,那么我们可以思考一下,我们的表单请求是POST请求,而且进行了页面的重定向,那么我们可按照状态码进行找到我们点击登录这个按钮时发送的请求包,这里发现我们的请求也是在login页面进行处理的,并且有爬虫经验的同学抓包肯定不会去什么css,图片,还有什么媒体文件进行查找,js有部分可能,js逆向的时候要用到
-
分析登录文件

由于是post请求,所以这里我们清楚的明白要点击载荷来看看我们请求的时候带过去的参数,参数如上图所示,可以看出第一个表示登录类型,我们是使用密码登录,而非手机号的验证码进行登录的,第二个参数应该是utf-8来进行编码,第三个参数就是一个token,第四个参数为空,第五个参数是我们登录的用户名,由于这里是我的手机号,所以这里就进行打码了,第六个参数是我们登录密码进行加密后的情况,第七个和第八个我们无需了解,所以这里我们仅仅只需要明白token是怎么生产的就可以了
-
明白token怎么获取的
首先我们先用复制token,然后进行全局搜索发现无法搜索到,那么我们现在又去复制authenticity_token这个键,看看是不是通过js生产的,但是还是无法搜索到数据包,那么我们这里只能去login的GET请求的数据包里面搜索看看是否有这个参数,这里我们发现确实有

但是我们这里我们的token并不是这个,这个是人家来迷惑我们的,其实真正的token在表单里面

那么我们现在弄清楚了请求的所有参数,接下来就是创建scrapy文件,爬虫文件,然后写爬虫文件,启动爬虫,总之就是结合上篇文件的开发流程来处理
代码
import scrapy
class GiteeSpider(scrapy.Spider):name = "gitee"allowed_domains = ["gitee.com"]start_urls = ["https://gitee.com/login"]
def parse(self, response):token = response.xpath('//*[@id="new_user"]/input[@name="authenticity_token"]/@value').extract_first()# print('我是token',token)data = {"encrypt_key": "password","utf8": "✓","authenticity_token": token,"redirect_to_url": "/","user[login]": "…………","encrypt_data[user[password]]": "ItGlVjZhGtSjgM4vwNxQE + ZSFLjnqF0B + A1UhTXXS00N6cgq / JyQmHl1FqTNgQEhVfi39W8v7S / u7wcmqZk2gqQzQ177jbIA1SyvjuYDaxeI + PEADfIzIvQGSKyZb5oQAk96AL8 + GOqeKIKaIA9aYzQlXxgsPdHzS3GWdW1g =","user[remember_me]": "0","user[remember_me]": "1"}yield scrapy.FormRequest(url='https://gitee.com/login',callback=self.after_login,formdata=data)
def after_login(self,response):yield scrapy.Request(url='https://gitee.com/zhang-shunhui',callback=self.check_login)
def check_login(self,response):title = response.xpath('/html/head/title/text()').extract_first()print('获取到title值:',title)scrapy管道的使用
学习目标:
-
掌握 scrapy管道(pipelines.py)的使用
1. pipeline中常用的方法:
-
process_item(self,item,spider):
-
管道类中必须有的函数
-
实现对item数据的处理
-
必须return item
-
-
open_spider(self, spider): 在爬虫开启的时候仅执行一次
-
close_spider(self, spider): 在爬虫关闭的时候仅执行一次
2. 管道文件的修改
import json
from itemadapter import ItemAdapter
class DoubantopPipeline:# 爬虫启动时,创建文件def open_spider(self, spider):self.file = open('results.json', 'w', encoding='utf-8')self.file.write('[\n') # 写入json数组的开始符号
def process_item(self, item, spider):# 将item转换为字典item_dict = dict(item)# 格式为JSONline = json.dumps(item_dict, ensure_ascii=False, indent=4)
# 添加逗号分隔符(添加的时候保证不是第一行)if hasattr(self, 'first_item') and not self.first_item:self.file.write(', \n' + line)else:self.first_item = Falseself.file.write(line)return item
# 爬虫关闭时触发的函数def close_spider(self, spider):self.file.write('\n]') # 写入json数组的结束符号self.file.close()3. 开启管道
在settings.py设置开启pipeline
......
ITEM_PIPELINES = {'myspider.pipelines.DoubantopPipeline': 300, # 300表示权重
}
......
思考:在settings中能够开启多个管道,为什么需要开启多个?
-
不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
-
不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
-
同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
4. pipeline使用注意点
-
使用之前需要在settings中开启
-
pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
-
有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
-
pipeline中process_item的方法必须有,否则item没有办法接受和处理
-
process_item方法接受item和spider,其中spider表示当前传递item过来的spider
-
open_spider(spider) :能够在爬虫开启的时候执行一次
-
close_spider(spider) :能够在爬虫关闭的时候执行一次
-
上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
小结
-
管道能够实现数据的清洗和保存,能够定义多个管道实现不同的功能,其中有个三个方法
-
process_item(self,item,spider):实现对item数据的处理
-
open_spider(self, spider): 在爬虫开启的时候仅执行一次
-
close_spider(self, spider): 在爬虫关闭的时候仅执行一次
-