wend看源码-Open_Deep_Research(LangChain)
前言
在AI 超速发展的今天, AI 早已渗入学界论文分析、企业市场研判等场景,“深度研究” 成了学术与产业的刚需。传统研究靠人工翻文献、拼数据,不仅耗时费力,还难保证结论的系统性与准确性 —— 这时,带自动化能力的深度研究代理工具,就成了破局关键。
在这类工具里,LangChain 团队推出的 Open Deep Research 很 “接地气”:它是款轻量框架,开源属性拉满,代码没冗余模块,核心逻辑一眼能看懂,还曾在权威的 Deep Research Bench 排行榜拿下第 6 名。对于想摸清 “深度研究代理” 底层逻辑的学习者来说,它不用你在大型项目的冗余代码里 “找重点”,还能接触到真实工业场景的技术思路,堪称 deep research 领域的优质 “入门标本”。
本文就以这款框架为核心,手把手拆解其源码结构、核心功能与设计思路,帮开发者掌握用 LangGraph 快速搭建工业级 Deep Research 框架的方法,为后续实践铺路。
-
排行榜地址: Deep Research Bench 排行榜
-
项目源码:https://github.com/langchain-ai/open_deep_research
源码核心模块简介
LangChain-Open Deep Research 的源码核心分为两大模块,功能定位与适用场景各有侧重,具体如下:
-
legacy:历史实现模块(参考价值导向):该模块存储深度研究(Deep Research)的两种早期实现方案,虽非当前框架的核心依赖,但通过与最新实现对比,能帮助开发者理解技术演进思路,具备较高参考意义。其下两个核心子模块功能明确:
-
graph.py:基于图结构的工作流实现。以图节点串联研究步骤,支持通过人机交互细化报告框架(如调整章节顺序、补充研究重点),采用「串行生成章节」的逻辑,优先保证研究内容的准确性与流程可控性,适合对结果精度要求高的场景。
-
multi_agent.py:多代理协作架构实现。设计「监督者代理 + 研究者代理」的分层模式 —— 监督者负责拆解研究任务、分配分工,多个研究者代理并行执行检索与分析,依托并行处理大幅提升生成效率,更适配快速探索性研究(如初步调研、主题扫盲)。
-
-
open_deep_research:当前核心实现模块(实战导向):作为框架的主流功能载体,该模块集成深度研究的全流程逻辑,也是本文后续技术拆解与实战探讨的核心对象。其核心文件分工清晰:
-
deep_researcher.py:主逻辑入口,承载从「接收用户需求」到「生成最终报告」的完整流程(含需求澄清、研究执行、信息整合);
-
configuration.py:配置管理中心,支持自定义模型选型(如 OpenAI/Gemini)、搜索工具对接(如 Tavily)、参数阈值(如检索次数、报告长度);
-
state.py:状态定义文件,规范研究过程中数据流转的格式(如用户需求、检索结果、章节草稿)与状态更新逻辑,保障流程稳定性。
-
Deep_Research核心流程
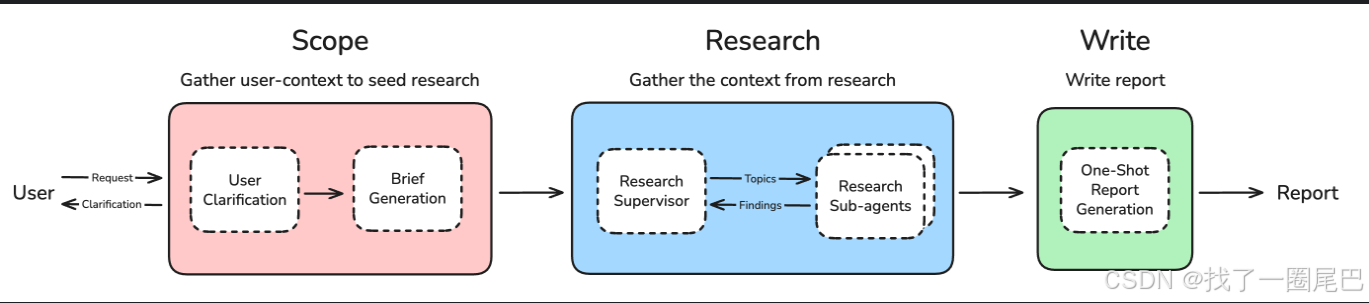
该图来源于项目源码中的README.md,非常清晰的介绍了langchain-open_deep_research 的核心工作步骤,共分为三部分。
-
Scope-范围定义:收集和明确用户研究需求,为后续研究工作奠定精确的方向和范围。
-
User Clarification(用户澄清):分析用户输入的研究请求,评估信息完整性。评估标准包括:
-
研究主题是否明确
-
是否存在缩写词或专业术语需要解释
-
研究范围和深度要求是否清晰
-
是否已在消息历史中询问过澄清问题
-
-
Brief Generation(简报生成):基于澄清后的需求,生成 “研究简报”—— 相当于为后续研究划定范围、明确核心问题。
-
-
Research-研究执行:通过研究监督者和多个子代理的协作,并行收集和处理研究所需的全面信息。
-
Research Supervisor(研究监督者):扮演 “统筹者” 角色,将大研究主题拆解为具体 Topics(子主题);采用 StateGraph 子图架构,独立管理研究任务分配。
-
Research Sub-agents(研究子代理):多个子代理分工 / 并行开展研究,再把获取的 Findings(研究发现) 反馈给 “监督者”,形成 “分配任务→执行研究→反馈结果” 的闭环。
-
-
Write-报告攥写:整合所有研究成果,生成结构化、全面的最终研究报告。
-
One-Shot Report Generation(一次性报告生成):整合 “Scope 阶段的需求定义” 和 “Research 阶段的多代理研究成果”,一次性生成完整的 Report(研究报告)。
-
核心节点详解
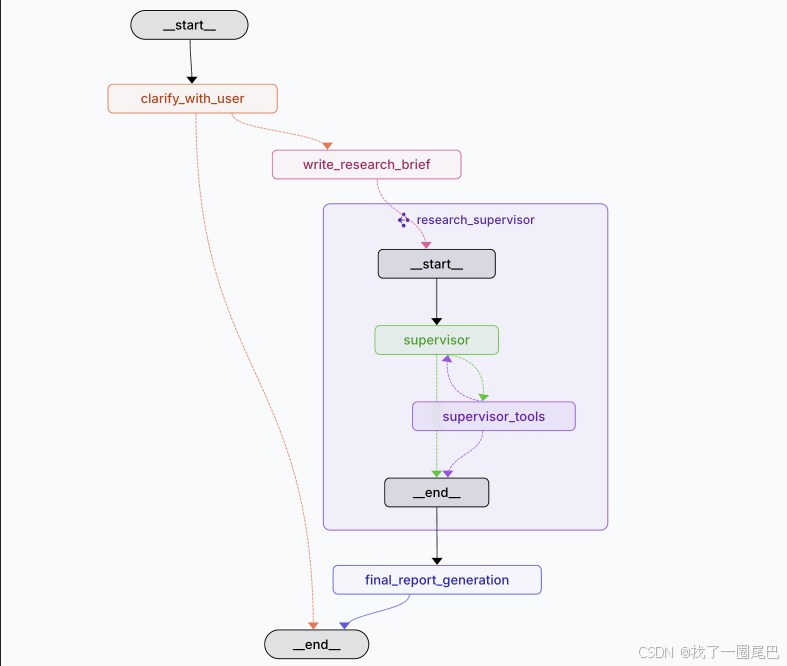
结合 LangGraph 生成的节点图,我们可从技术实现层面进一步熟悉和明确langchain-open_deep_research 的核心工作节点,包括:
clarify_with_user(用户澄清节点)
-
节点核心功能:需求澄清的 “触发 - 反馈” 入口。clarify_with_user节点的核心职责是:当系统识别到用户初始研究需求存在模糊性(如主题范围未明确、关键条件缺失)时,自动生成澄清问题(如 “是否需要聚焦某领域的最新研究成果?”),并通过人机交互获取用户补充信息,为后续研究流程锚定准确方向。
-
技术实现差异-终止工作流 vs Interrupt 函数:这一节点的设计亮点,需结合 legacy 模块graph.py的human_feedback节点对比理解:
-
旧实现(graph.py的human_feedback):采用interrupt(中断)函数实现交互逻辑 —— 当需要用户反馈时,仅暂停当前工作流的执行(不终止流程上下文),待用户提供输入后,流程可从暂停节点直接恢复,无需重启整体链路。
-
新实现(clarify_with_user):采用 “工作流完全终止” 的技术方案 —— 当触发澄清需求时,系统会直接终止当前正在执行的研究工作流,同时将生成的澄清问题返回给用户;待用户补充回复后,需重新初始化并启动完整的研究工作流,新流程会自动加载用户的最新反馈信息,确保需求理解的准确性。
-
-
技术设计的核心考量:该节点采用 “终止 - 重启” 模式,而非interrupt中断模式,本质是为了简化流程状态管理:无需在中断期间维护复杂的上下文缓存(如已执行的检索结果、临时章节草稿),通过 “重启时重新加载全量信息” 的方式,降低多轮交互中的状态同步复杂度,更适配核心模块open_deep_research的轻量化流程设计。
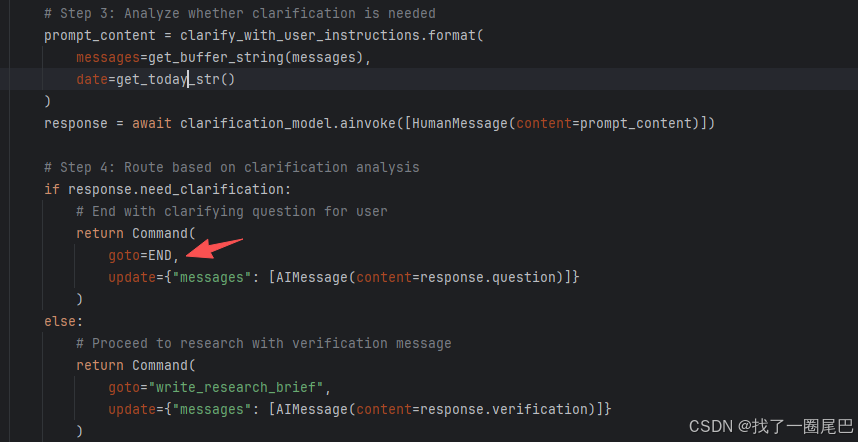
具体流程
-
配置检查与快速跳转: 检查系统配置中是否启用了用户澄清功能
-
澄清模型准备与配置:为后续的澄清需求判断准备专用的结构化输出模型
-
执行澄清需求分析:使用 LLM 智能分析用户消息,判断是否需要澄清
-
基于分析结果的路由决策:根据澄清分析结果决定下一步工作流走向
write_research_brief(生成研究简报节点)
负责将用户的自然语言需求转换为结构化的研究指导文档,并为后续的多代理研究阶段做好准备。
具体流程
1. 研究模型配置与准备:为结构化研究简报生成配置专用模型,包括模型配置参数以及结构化输出配置。
# 模型配置参数
research_model_config = {"model": configurable.research_model, # 使用研究专用模型"max_tokens": configurable.research_model_max_tokens, # Token限制"api_key": get_api_key_for_model(configurable.research_model, config), # API密钥"tags": ["langsmith:nostream"] # LangSmith标记
}# 结构化输出配置
research_model = (configurable_model.with_structured_output(ResearchQuestion) # 绑定ResearchQuestion数据结构.with_retry(stop_after_attempt=configurable.max_structured_output_retries) # 重试机制.with_config(research_model_config) # 应用配置
)2. 用户消息转换与研究简报生成:将用户的对话历史转换为详细的研究指导文档
# 提示词构建
prompt_content = transform_messages_into_research_topic_prompt.format(messages=get_buffer_string(state.get("messages", [])), # 用户消息历史date=get_today_str() # 当前日期上下文
)# 生成结构化研究简报
response = await research_model.ainvoke([HumanMessage(content=prompt_content)])3. 监督者初始化与上下文设置:为研究监督者准备完整的工作环境和指导框架,包括监督者系统提示词构建以及状态更新机制。
supervisor_system_prompt = lead_researcher_prompt.format(date=get_today_str(), # 时间上下文max_concurrent_research_units=configurable.max_concurrent_research_units, # 并发限制max_researcher_iterations=configurable.max_researcher_iterations # 迭代限制
)return Command(goto="research_supervisor", update={"research_brief": response.research_brief, # 存储研究简报"supervisor_messages": {"type": "override", # 覆盖式更新"value": [SystemMessage(content=supervisor_system_prompt), # 系统指令HumanMessage(content=response.research_brief) # 研究任务]}}
)supervisor_subgraph(研究监督子图)
作为 open_deep_research 模块中 “研究执行阶段” 的核心控制单元,supervisor_subgraph(研究监督子图)承担着 “统筹研究全流程、协调工具与子代理” 的关键职责 —— 它上承 clarify_with_user 节点输出的明确研究需求(研究简报),下接报告生成阶段,通过 supervisor(监督者节点)与 supervisor_tools(监督者工具集)的循环调用,实现 “策略规划 - 任务执行 - 结果评估” 的闭环管理,是保障研究深度与效率的核心中枢。
一、核心构成:“决策中枢 + 工具集” 的双节点架构
supervisor_subgraph 仅包含两个核心节点,但职责分工明确、形成强耦合的循环调用关系:
-
supervisor 节点:“决策中枢”,负责全流程的逻辑控制 —— 接收研究简报后,制定研究策略、判断工具调用需求、评估执行结果,并决定是否进入下一轮循环或终止研究;
-
supervisor_tools 节点:“执行工具集”,是 supervisor 决策的 “落地载体”,包含三大专用工具,仅负责执行具体操作(如委派任务、发送结束信号),不参与决策逻辑,确保 “决策 - 执行” 解耦。
两者的交互逻辑为:supervisor 根据当前研究状态发起工具调用请求 → supervisor_tools 执行对应工具并返回结果 → supervisor 基于结果重新评估,决定是否再次调用工具(循环)或触发研究结束。
二、全流程拆解:从 “研究简报” 到 “完成判断” 的六步闭环
结合技术链路与工具调用逻辑,supervisor_subgraph 的运行流程可拆解为六个关键环节,且每个环节均对应明确的节点 / 工具动作:
| 流程阶段 | 核心目标 | 节点 / 工具联动逻辑 |
| 1. 接收研究简报 | 获取明确需求 | supervisor 接收 clarify_with_user 节点输出的 “研究简报”(含主题、范围、要求),作为研究起点 |
| 2. 策略思考 | 制定研究方案 | supervisor 调用 supervisor_tools 中的 think_tool,完成研究策略规划(如 “先检索近 3 年文献,再分析产业案例”),并记录思考过程,为后续决策留痕 |
| 3. 任务分解与并行执行 | 落地研究策略 | supervisor 基于 think_tool 的规划,调用 ConductResearch 工具 —— 自动创建专门的 “研究子代理”,并向多个子代理分配不同子主题(如 A 代理负责 “技术进展”,B 代理负责 “应用案例”),支持多任务并行执行,大幅提升效率 |
| 4. 等待结果 | 收集子代理输出 | ConductResearch 工具监控所有子代理的执行状态,待所有并行任务完成后,将整合后的 “研究发现”(含数据、引用、分析结论)反馈给 supervisor |
| 5. 结果评估 | 判断是否需继续研究 | supervisor 再次调用 think_tool,基于 “研究发现” 反思:现有信息是否足够支撑结论?是否存在信息缺口?若需补充,则规划下一轮研究动作(如 “补充检索某企业白皮书”) |
| 6. 完成判断 | 决定研究终止或继续 | supervisor 评估后,若判定信息足够,则调用 ResearchComplete 工具(发送研究结束信号);若需补充,则回到 “任务分解” 阶段,开启下一轮循环 |
三、supervisor_tools 三大核心工具:各司其职的 “执行单元”
1. ConductResearch:研究任务委派工具(“执行者”)
-
核心作用:连接 supervisor 与 “研究子代理” 的桥梁,是实现 “并行研究” 的关键;
-
核心能力:① 自动创建临时 “研究子代理”(无需手动定义);② 向子代理传递具体任务参数(研究主题、检索范围、输出格式);③ 支持同时委派多个子任务(如 3 个主题并行检索),并统一收集结果;
-
技术价值:通过 “子代理实例化 + 并行执行”,避免 supervisor 直接处理底层检索逻辑,提升研究效率。
2. ResearchComplete:研究完成信号工具(“终结者”)
-
核心作用:标记研究阶段正式结束,触发流程向 “报告生成阶段” 转换;
-
核心特性:① 纯信号工具,无需传入任何参数(仅需 supervisor 发起调用);② 调用后会向整个框架发送 “研究完成” 状态码,supervisor 接收后终止循环,不再发起工具调用;
-
技术价值:作为 “阶段切换开关”,明确划分 “研究执行” 与 “报告生成” 的边界,避免流程混淆。
3. think_tool:战略思考工具(“规划者”)
-
核心作用:为 supervisor 提供 “策略规划与反思载体”,确保研究方向不偏离、不遗漏;
-
核心能力:① 记录 supervisor 的思考过程(如 “当前缺少用户调研数据,需补充检索”),形成可追溯的 “研究日志”;② 基于历史研究结果,迭代优化策略(如 “上一轮检索无近 1 年数据,本轮需调整检索关键词”);
-
技术价值:通过 “思考留痕 + 策略迭代”,避免 supervisor 陷入 “盲目调用工具” 的误区,保障研究的系统性。
四、迭代控制与退出机制:避免无限循环,保障资源可控
为平衡研究深度与资源消耗,supervisor_subgraph 设计了 “思考 - 行动 - 评估” 的迭代循环机制,并明确三大退出条件,确保流程可控:
1. 迭代循环逻辑(思考 - 行动 - 评估):循环核心为 “工具调用 - 结果反馈 - 策略调整” 的闭环:
think_tool(思考:制定策略)→ ConductResearch(行动:执行任务)→ think_tool(评估:反思结果)→ 若需补充,重复上述步骤;若满足退出条件,调用 ResearchComplete 终止。
2. 三大退出条件(防止无限循环)
if exceeded_allowed_iterations or no_tool_calls or research_complete_tool_call:return Command(goto=END,update={"notes": get_notes_from_tool_calls(supervisor_messages), # 提取所有研究笔记"research_brief": state.get("research_brief", "") # 保持研究简报})-
条件 1:超出迭代限制:框架预设最大迭代次数(如 5 轮),若 supervisor 发起的工具调用次数达到上限,即使仍有信息缺口,也自动终止循环,避免占用过多计算资源;
-
条件 2:无工具调用需求:supervisor 调用 think_tool 后,判断当前信息已足够支撑结论,无需再调用 ConductResearch,则自然终止循环;
-
条件 3:触发研究完成信号:supervisor 主动调用 ResearchComplete 工具,发送结束信号,流程正常终止,进入报告生成阶段。
五、核心价值:以 “轻量架构” 实现 “高效统筹”
supervisor_subgraph 虽仅含 2 个节点、3 个工具,却通过 “决策 - 执行解耦”“并行任务支持”“迭代评估机制”,解决了深度研究中的三大核心问题:
-
避免 “方向失控”:think_tool 的策略规划与反思,确保研究不偏离主题;
-
提升研究效率:ConductResearch 的并行执行,大幅缩短多主题研究耗时;
-
保障资源可控:明确的退出条件,防止流程陷入无限循环。
它是 open_deep_research 模块 “轻量化设计” 与 “工业级功能” 平衡的典型体现。
final_report_generation(生成最终报告)
这是整个深度研究系统的收官之作,负责将所有研究成果整合成一份结构化、全面的最终研究报告,同时清理系统状态为下次研究做准备。
具体流程
-
1. 研究成果提取与状态清理准备:收集所有研究发现并准备状态重置
-
2. 报告生成模型配置:为最终报告生成配置专用的高质量模型
-
设计考量:
-
专用模型: 使用单独的 final_report_model,通常是较高质量的模型
-
更大token限制: 报告生成通常需要更大的上下文窗口
-
稳定输出: 禁用流式以确保完整报告的一次性生成
-
-
-
智能重试与Token限制处理:处理大规模研究成果的token限制问题,确保报告成功生成
-
渐进式裁剪策略
-
if is_token_limit_exceeded(e, configurable.final_report_model):current_retry += 1if current_retry == 1:# 首次重试:确定初始裁剪限制model_token_limit = get_model_token_limit(configurable.final_report_model)findings_token_limit = model_token_limit * 4 # 4x token作为字符近似else:# 后续重试:逐步减少10%findings_token_limit = int(findings_token_limit * 0.9)# 裁剪发现内容并重试findings = findings[:findings_token_limit]-
结果返回与状态管理:返回最终报告并清理系统状态
-
概要流程图:
研究成果聚合 → 模型配置 → 报告生成尝试 → Token限制检查 → 智能裁剪 → 重试生成
↓ ↓ ↓ ↓ ↓ ↓
所有notes 专用模型 完整提示 异常捕获 渐进裁剪 成功/失败
↓ ↓ ↓ ↓ ↓ ↓
findings 高质量输出 最终报告 容错处理 内容适配 状态清理
关键组件详解
MCP 工具调用处理
在 Open Deep Research 的 deep_researcher 中,MCP(Model Context Protocol)工具调用的处理围绕配置加载、工具集成和权限控制展开,旨在扩展研究代理对本地 / 外部数据源的访问能力。以下是具体处理逻辑:
MCP 配置定义
MCP 工具的核心配置由 MCPConfig 类(位于 src/open_deep_research/configuration.py)管理,包含关键参数:
-
url:MCP 服务器的访问地址; -
tools:指定允许使用的 MCP 工具列表(如文件读取、数据库查询等); -
auth_required:标记该 MCP 服务器是否需要身份验证。
这些配置可通过 .env 文件或运行时参数动态调整,支持灵活适配不同的 MCP 服务。
MCP 工具的加载与初始化
工具加载逻辑主要由 load_mcp_tools 函数(位于 src/open_deep_research/utils.py)实现,步骤如下:
-
认证处理:若 MCP 服务器要求认证,通过
fetch_tokens获取访问令牌,并生成认证头(Authorization: Bearer <token>); -
配置验证:检查 MCP 服务器 URL、工具列表及认证信息是否完整,不完整则返回空工具列表;
-
服务器连接:通过
MultiServerMCPClient连接 MCP 服务器,获取可用工具列表; -
工具过滤与包装:
-
过滤掉与现有工具(如搜索工具)名称冲突的 MCP 工具;
-
仅保留配置中
tools字段指定的工具; -
对工具进行认证包装(
wrap_mcp_authenticate_tool),确保调用时携带认证信息。
-
工具调用权限与范围
-
权限控制:仅研究代理(Researcher Agent)可访问 MCP 工具,监督者代理(Supervisor Agent)无此权限(参考
legacy.md),确保工具使用的针对性; -
使用场景:MCP 工具可与传统 web 搜索工具(如 Tavily)结合使用,或通过设置
search_api: "none"单独使用,适用于访问本地文档、数据库、API 或文件系统等场景。
调用流程示例(以文件系统访问为例)
-
配置 MCP 服务器:通过
mcp_server_config指定文件系统服务器的启动命令(如npx @modelcontextprotocol/server-filesystem)和目标目录; -
工具调用指令:通过
mcp_prompt定义工具使用步骤(如先调用list_allowed_directories获取允许访问的目录,再调用read_file读取文件); -
研究代理执行:研究代理根据配置加载
list_allowed_directories、read_file等 MCP 工具,按指令顺序调用,将本地文件内容整合到研究报告中(参考legacy.md中的文件系统服务器示例)。
关键特性
-
灵活性:支持单独使用 MCP 工具或与 web 搜索结合,适配不同数据源需求;
-
安全性:通过认证令牌和工具名称过滤,避免未授权访问和工具冲突;
-
可定制性:通过
mcp_prompt自定义工具使用逻辑,通过mcp_tools_to_include精确控制工具范围。
综上,MCP 工具调用的处理通过配置驱动、权限隔离和灵活集成,使 deep_researcher 能够突破 web 搜索的限制,接入本地或私有数据源,增强研究的全面性和针对性。
compress_research 压缩研究结果处理
这是研究子代理工作流的最后一个节点,负责将研究者在整个研究过程中收集的原始工具输出、AI消息和搜索结果转换为结构化、去重、保真的研究摘要。
处理流程
-
1. 压缩模型配置:为压缩任务配置专用的综合模型
-
2. 消息准备与模式切换:将研究消息从探索模式切换到压缩总结模式
以上所有信息都是关于人工智能研究员进行的研究。请清理这些发现。
不要总结信息。我希望以更清晰的格式返回原始信息。
确保所有相关信息都被保留下来——你可以逐字重写调查结果。
-
3. 智能压缩处理与重试机制:执行压缩任务,同时处理token限制等异常情况
synthesis_attempts = 0
max_attempts = 3while synthesis_attempts < max_attempts:try:# 构建系统提示compression_prompt = compress_research_system_prompt.format(date=get_today_str())messages = [SystemMessage(content=compression_prompt)] + researcher_messages# 执行压缩response = await synthesizer_model.ainvoke(messages)# 成功处理...except Exception as e:# 错误处理逻辑...-
4. 智能容错与内容管理:包括token 限制处理,提取所有工具和AI消息内容
-
5. 结果返回与状态管理
压缩策略
-
去重合并: "三个来源都表示X" → 避免重复
-
格式规范: 统一引用编号和来源列表
-
结构清晰: 查询列表 → 发现 → 来源
-
保真要求: 重要信息逐字保留
在整体架构中的价值
-
质量提升: 将原始输出转换为高质量结构化报告
-
信息完整: 确保研究发现在传递过程中不丢失
-
格式标准: 为最终报告生成提供规范化输入
-
效率优化: 去重和整理减少后续处理负担
参考文献
https://github.com/langchain-ai/open_deep_research