【CVPR 2016】基于高效亚像素卷积神经网络的实时单幅图像与视频超分辨率
文章目录
- 一、论文信息
- 二、论文概要
- 三、实验动机
- 四、创新之处
- 五、实验分析
- 六、核心代码
- 源代码
- 注释版本
- 七、实验总结
- 参考引用
一、论文信息
- 论文题目:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
- 中文题目:基于高效亚像素卷积神经网络的实时单幅图像与视频超分辨率
- 论文链接:点击跳转
- 代码链接:点击跳转
- 作者:Wenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, Zehan Wang 史文哲、何塞·卡巴列罗、费伦茨·胡萨尔、约翰内斯·托茨、安德鲁·P·艾特肯、罗布·比肖普、丹尼尔·鲁克特、泽汉·王
- 单位:Twitter
- 核心速览:本文提出了一种基于亚像素卷积的高效卷积神经网络(ESPCN)来进行实时超分辨率,能够有效提升图像和视频的分辨率,并显著提高速度。
二、论文概要
该论文提出了一种新的深度学习方法,通过高效的**子像素卷积神经网络(ESPCN)**进行单图像和视频的实时超分辨率。该方法通过在低分辨率空间中提取特征,并引入子像素卷积层来进行高效的超分辨率重建,从而显著降低计算复杂度,同时提升重建精度。通过使用公开的基准数据集进行测试,ESPCN在图像和视频的超分辨率重建中取得了显著优于现有方法的性能,同时在速度上也有极大提升。
三、实验动机
传统的超分辨率方法通常在高分辨率(HR)空间中进行操作,这会增加计算复杂度。特别是在处理视频时,传统方法往往会使用插值来增大低分辨率(LR)图像的尺寸,这种方法不仅计算量大,而且可能带来冗余信息。本文提出通过子像素卷积层将LR图像直接映射到HR图像,这种方法不仅降低了计算复杂度,还能获得更高的图像质量。
四、创新之处
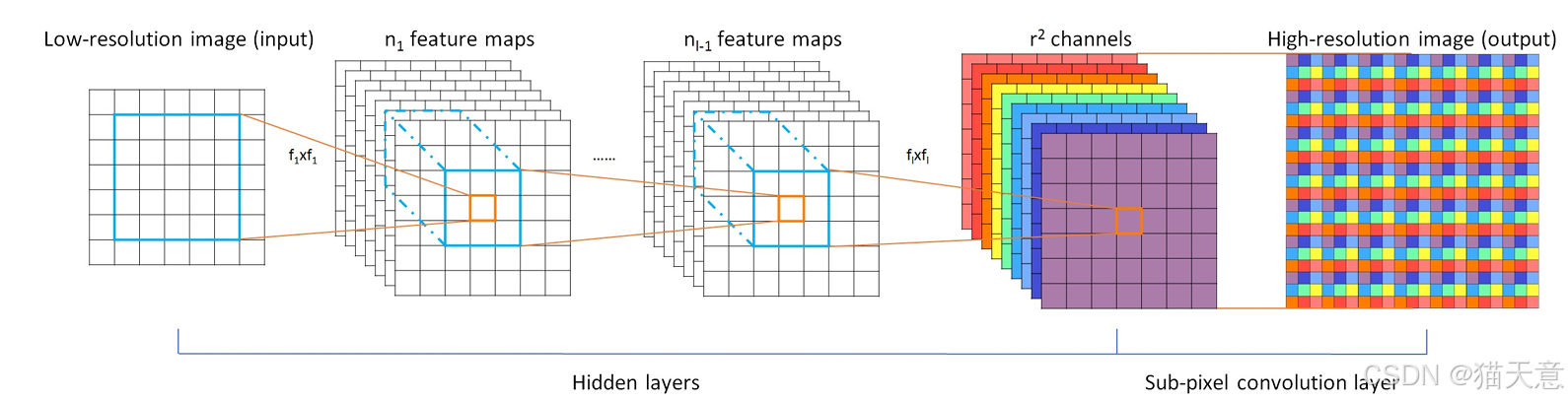
-
引入子像素卷积层:通过在网络中引入子像素卷积层,避免了传统插值方法带来的信息冗余,提升了超分辨率的精度和效率。
-
特征提取在低分辨率空间进行:与现有方法不同,ESPCN直接在低分辨率空间中进行特征提取,避免了在HR空间进行卷积计算的高昂代价。
-
性能提升和速度加快:ESPCN相较于传统方法(如SRCNN)在PSNR值上有显著提升,并且速度上提高了近10倍。
五、实验分析
-
在多个基准数据集上,ESPCN显著超越了SRCNN等方法,尤其在视频超分辨率任务中,表现出了极高的速度和精度。
-
实验结果显示,ESPCN在图像超分辨率任务上较传统方法提高了约0.15dB,在视频超分辨率任务上提高了0.39dB。
-
该方法在计算时间上比现有方法快了一个数量级,尤其适用于实时超分辨率应用。
六、核心代码
源代码
注释版本
七、实验总结
实验表明,提出的ESPCN方法在多个数据集上都表现出了较传统方法更优的性能。该方法不仅提升了图像和视频的重建质量,而且极大地提高了计算速度。ESPCN的实时性使其成为视频超分辨率领域中的重要突破。
参考引用
[超分][CVPR2016]ESPCN
超分论文解读:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
PyTorch学习笔记(10)——上采样和PixelShuffle
【论文阅读】什么是PixelShuffle?为什么它是图像生成任务中更优的上采样方法?