携程线下面试总结
1.kfaka如何避免重复消费
2.kafka是否支持延迟消息
3.分布式id的解决方案
4.g1垃圾回收器的region大小如何设置,过大或过小分别有什么影响
5.线程池递归的任务提交会有什么问题
6.为什么缓存穿透不能直接把请求打到数据库上
7.若是监听binlog 的更新 怎么监听
回答
1.Kafka要避免重复消费,主要在消费者和生产者两边
生产者这边:开启幂等性+生产者事务
kafak幂等性实现:生产者id+消息id(单分区递增) broker端会对每个生产者的消息id有个预期,发现当前消息的id<自己的预期时,会判断是生产者重复发送,不会再写入,只是返回成功
生产者事务主要是解决多分区的重复消费问题,消费者发送的消息可能被分配到不同的分区,需要开启事务来避免多分区消息的重复问题
消费者这边:1.最简单粗暴的,把消费过的消息id存到redis里,每次消费前先检查redis
2.手动提交offset 确保消费确实消费了再提交offset
3.开启消费者事务,有异常全部回滚 不要消费
2.kafka是否支持延迟消息
kafka本身是不支持延迟消息的,但是我们可以用一些扩展的方法帮助他实现
1)消息生产者不直接发送消息给Broker 而是设计一个定时任务,时间到了再发送,缺点是性能较弱不支持高并发
2)设置一些延迟topic 然后搞一个中间层 专门做转发,可以设置多个topic分别代表不同的延迟时间,中间层监听这些topic,有消息后等待特定延迟时间 ,然后再转发消息到真正的topic 并提交
核心在与消费者的无感知延迟,即延迟消息的处理要在生产者这边或者加一个中间层
对于方案1:需要生产者这边开启定时任务,没有多线程和缓冲
但是方案2利用了kafak天然的分区特性,可以设定专门的中间层消费者组,一个消费者对应一个分区,专人做专事,kafka可以做消息和消费者的分配 所以提高了吞吐量
3.分布式id的解决方案
1)用uuid 简单 且不会重复
但是:不递增:导致b+树要频繁的插入分裂
长度过长:要占16字节
2)用雪花算法:时间戳(41bit)+机器ID(10bit)+自增序列号(12bit) 还有1bit没有 总共64bit 8字节

缺点:依赖时钟 如果出现时钟回拨 可能导致重复id 理论上可以记录上一次发号的时间,若是当前比上一次晚则拒绝发号 或者尝试同步时间戳
3)用Redis 的原子操作发号 incr
可以批量获取 节省性能 一次性获取多段id 存在本地用来发号
4)分表环境下 不同的表的id可以设置不同的step 比如表一1 3 5 7 表二 2 4 6 8 缺点就是无法扩展
4.kafka的region 大小如何设置
一般来说,G1会把堆内存分成大小相等的region块 一般不要自己设置 容易出现过大或过小的问题
过大:G1回收器的特点或者说优势就在于把内存分成了很多region,进行gc时比如minor gc时不用做全堆的回收,可以根据设置的stw时间回收一些价值比较高的region,若是region太大,那就相当于缩小了这个优势,甚至说在stw时间内都回收不了一个region,那最后可能导致fullgc,对Region的回收价值的判断也会很麻烦
过小:一个region没存多少数据就满了、对于稍微大点的数据就要转成巨生代存储,横跨好几个region,增加了分配对象的开销,且寻找可以存放对象的reigon的开销也加大
G1垃圾回收器常用的参数
-XX:+UseG1GC 使用g1垃圾回收器
-Xms 初始堆大小 -Xmx 最大堆大小 一般设置为系统总内存的70%左右
-XX:MetaspcetSize -XX:MaxMetaspaceSize 元空间的初时与最大内存 不设置则无上限
-XX:MaxGCPauseMillis: 最大暂停时间 默认200 设置过小会有退化成fullgc的奉献
-XX:G1HeapRegionSize:指定Region大小 必须是2次幂 最大32MB 不设置默认等分2048份
5.线程池递归的任务提交会有什么问题
若是二者并无什么依赖关系还好
若是二者有依赖关系 如下图所示 会有类似死锁的现象
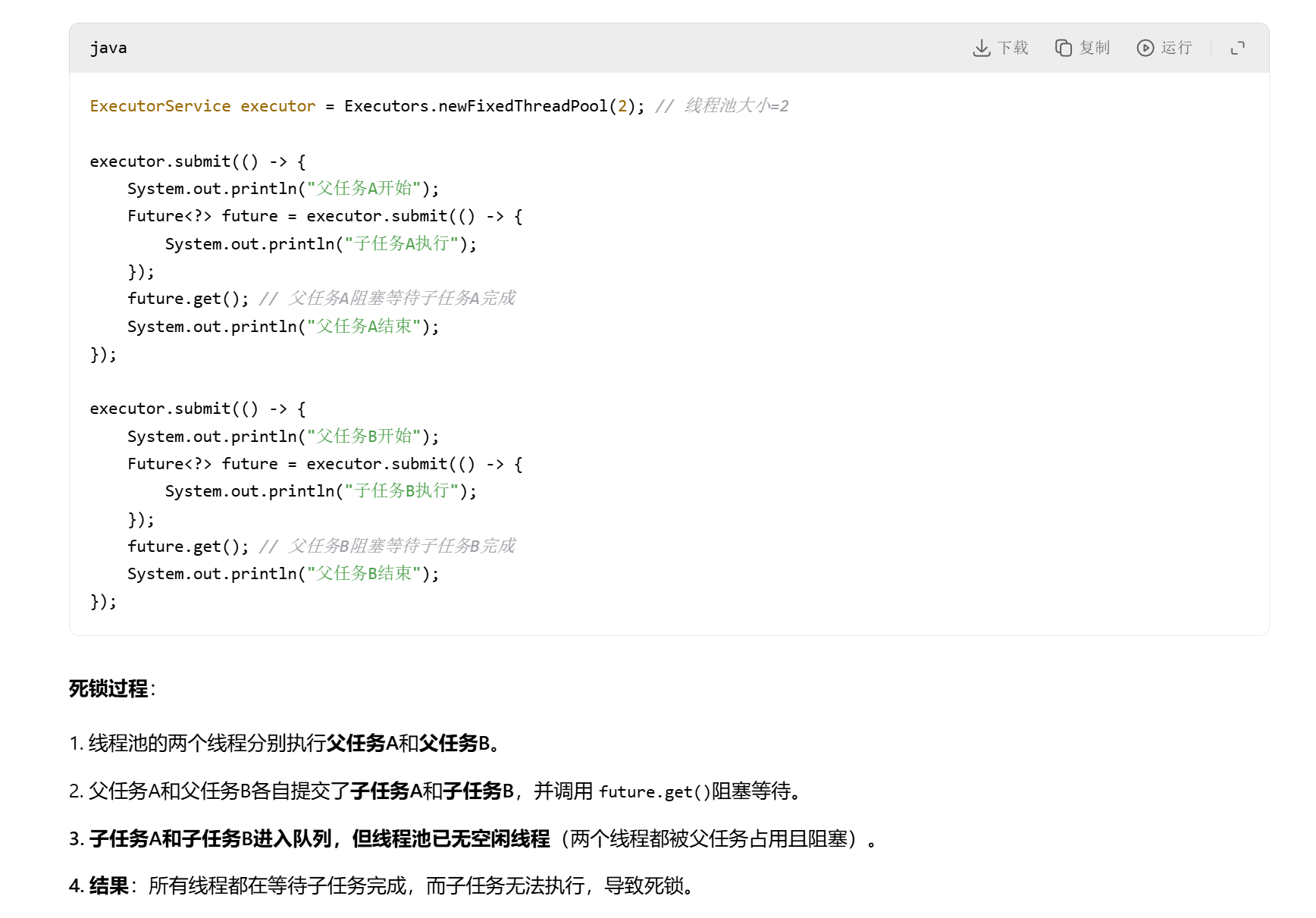
且若是存在递归调用 会指数级的提交任务,造成任务队列爆炸(若使用无界队列会oom)
所以要是有递归关系的任务可以用ForkJoinPoll 用了工作窃取算法 极大缓解了死锁问题
6.为什么缓存穿透不能直接把请求打到数据库上
1)数据库的最大连接数存在限制,无效的连接会消耗这个连接数让真正的请求无法拿到连接
2)cpu和io瓶颈:数据库要从磁盘中读数据、会有很大的io压力、且若是涉及到join group或一些复杂的操作会加大cpu负担
3)BufferPoll大小存在上限:无效数据页的加载会把真正要用bufferpool顶下去,造成我们要查询的数据又得重新从磁盘加载
7.若是监听binlog 的更新 怎么监听
第三方插件(cannal)的底层是对主从复制协议的应用,即伪装成mysql的从库,让主库用一个tcp长连接不断把事件流推送过来(当主库的日志通过两阶段提交真正落盘后),再分析数据的变化
binlog的日志形式分为:
1.row:记录实际数据的变更,即前后镜像,安全但存储空间占用大
2.statement:保留原始的sql语句,占用空间小,但一些动态函数(如时间函数)可能会造成主从不一致
3.mixed:引擎自动判断是否是动态函数