【ICCV 2025】UniConvNet:扩展有效感受野并保持对任何规模的卷积神经网络的渐近高斯分布
文章目录
- 一、论文信息
- 二、论文概要
- 三、实验动机
- 四、创新之处
- 五、实验分析
- 六、核心代码
- 源代码
- 注释版本
- 七、实验总结
一、论文信息
- 论文题目:UniConvNet: Expanding Effective Receptive Field while Maintaining Asymptotically Gaussian Distribution for ConvNets of Any Scale
- 中文题目:UniConvNet:扩展有效感受野并保持对任何规模的卷积神经网络的渐近高斯分布
- 论文链接:点击跳转
- 代码链接:点击跳转
- 作者:Yuhao Wang (王宇昊)、Wei Xi (席伟)
- 单位:Xi’an Jiaotong University (西安交通大学)
- 核心速览:UniConvNet是一种新型卷积神经网络,通过创新的三层感受野聚合器(RFA)和层操作器(LO)来有效扩展感受野(ERF),同时保持渐近高斯分布(AGD)。该模型在多个视觉任务中表现优异,尤其在轻量级和大规模模型上都能提供卓越的准确性和计算效率。UniConvNet在ImageNet-1K上达到了84.2%的Top-1准确率,显著超越了现有的卷积网络和视觉变换器。
二、论文概要
ERF(effective receptive field)
AGD(asymptotically Gaussian distribution)
RFA(Receptive Field Aggregator)
LO(Layer Operator)
本论文提出了一种新型的卷积神经网络架构 UniConvNet,旨在解决当前卷积网络中,如何在增加感受野(ERF)的同时,保持其渐近高斯分布(AGD)的问题。论文中提出的 三层感受野聚合器(RFA),通过合理组合小核卷积(如 7×7, 9×9, 11×11 等),能够有效扩展 ERF,保持其AGD。实验结果表明,UniConvNet在ImageNet-1K、COCO2017、ADE20K等多个视觉任务上,均表现出了比现有的卷积神经网络(CNNs)和视觉变换器(ViTs)更为出色的性能。
三、实验动机
- 传统的卷积神经网络在提升感受野的同时,通常会引入巨大的参数和计算复杂度,而采用过大的卷积核则可能破坏感受野的渐近高斯分布(AGD)。
- 因此,研究的目标是提出一种方法,在扩展感受野的同时,避免AGD的破坏,达到较低的计算成本和较高的准确率。
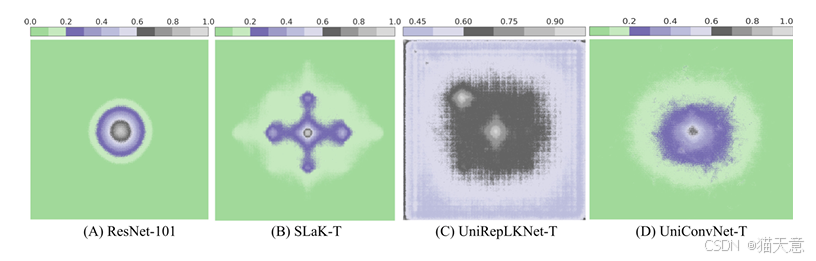
在经典的卷积神经网络 (如 ResNet) 里,如果你不断叠加标准的小卷积核(比如 3×3),从数学上可以证明:
-
当卷积层数足够多时,有效感受野 (Effective Receptive Field, ERF) 的分布会逐渐趋近于 二维高斯分布。
-
也就是说,一个像素对输出的影响不是“硬边界”,而是随距离衰减,且呈现高斯形状的概率分布。
这种 近似高斯的 ERF 分布 很重要,因为:
-
它保证了感受野范围内的像素贡献 平滑衰减,符合自然图像的统计特性。
-
有利于 稳定训练,避免梯度集中在少数位置。
-
提高模型对局部扰动的鲁棒性。
为什么大卷积核方法会破坏 AGD?
-
最近几年许多工作(如 RepLKNet、SLaK)提出使用 超大卷积核(31×31、51×51 等)来直接扩大感受野。
-
这样做的问题是:
单个大卷积核会产生 均匀或偏平的权重分布,不像高斯那样“中心高、边缘低”。
结果就是 ERF 偏离了渐近高斯分布,导致像素影响分布不自然。
论文中的 图1 (第1页) 和 图7 (第15页) 就对比了几种方法的 ERF:
-
ResNet:接近高斯,但范围有限。
-
RepLKNet/SLaK:范围大,但分布失真,边界过于“硬”。
-
UniConvNet:范围大且保持平滑高斯分布。
UniConvNet 是怎么保持 AGD 的?
作者的思路是:
-
不去直接用“超大卷积核”,而是用多个 中等大小卷积核 (7×7, 9×9, 11×11) 来 逐层叠加。
-
每一层的输出都近似一个小高斯核;多层叠加后,结果依旧符合“高斯 + 高斯 = 更宽的高斯”的规律。
-
这样一来,既能把感受野扩展到接近大核效果,又能维持高斯分布形态。
四、创新之处
-
三层感受野聚合器(RFA):通过三层聚合和逐层递增卷积核尺寸的策略,成功扩展了感受野,同时保持了其渐近高斯分布。
-
Layer Operator(LO):结合了放大(Amplifier)和判别(Discriminator)模块,分别对感受野进行扩展和优化,从而保持其有效性。
-
轻量化与大规模模型的性能提升:提出的UniConvNet不仅能在轻量化模型中提供更好的性能,还能在大规模模型上有效扩展,达到更高的准确性和效率。
五、实验分析
实验结果表明,UniConvNet在多个视觉识别任务(包括图像分类、物体检测、实例分割等)中,均优于现有的卷积神经网络(如ResNet系列)和视觉变换器(如ViT系列)。特别是,在使用30M参数的UniConvNet-T模型上,其在ImageNet上的Top-1准确率达到84.2%,超越了许多现有模型。
六、核心代码
源代码
# Copyright (c) Meta Platforms, Inc. and affiliates.# All rights reserved.# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.import torch
import torch.nn as nn
from timm.layers import DropPath# try:
from .ops_dcnv3 import modules as opsm
# except:
# pass__all__ = 'UniConvBlock'class to_channels_first(nn.Module):def __init__(self):super().__init__()def forward(self, x):return x.permute(0, 3, 1, 2)class to_channels_last(nn.Module):def __init__(self):super().__init__()def forward(self, x):return x.permute(0, 2, 3, 1)def build_norm_layer(dim,norm_layer,in_format='channels_last',out_format='channels_last',eps=1e-6):layers = []if norm_layer == 'BN':if in_format == 'channels_last':layers.append(to_channels_first())layers.append(nn.BatchNorm2d(dim))if out_format == 'channels_last':layers.append(to_channels_last())elif norm_layer == 'LN':if in_format == 'channels_first':layers.append(to_channels_last())layers.append(nn.LayerNorm(dim, eps=eps))if out_format == 'channels_first':layers.append(to_channels_first())else:raise NotImplementedError(f'build_norm_layer does not support {norm_layer}')return nn.Sequential(*layers)class MLPLayer(nn.Module):r""" MLP layer of InternImageArgs:in_features (int): number of input featureshidden_features (int): number of hidden featuresout_features (int): number of output featuresact_layer (str): activation layerdrop (float): dropout rate"""def __init__(self,in_features,hidden_features=None,out_features=None,# act_layer='GELU',drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = nn.GELU()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass LayerNorm(nn.Module):r""" LayerNorm that supports two data formats: channels_last (default) or channels_first. The ordering of the dimensions in the inputs. channels_last corresponds to inputs with shape (batch_size, height, width, channels) while channels_first corresponds to inputs with shape (batch_size, channels, height, width)."""def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedError self.normalized_shape = (normalized_shape, )def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass ConvMod(nn.Module):def __init__(self, dim):super().__init__()self.norm1 = LayerNorm(dim, eps=1e-6, data_format="channels_first")self.a1 = nn.Sequential(nn.Conv2d(dim // 4, dim // 4, 1),nn.GELU(),nn.Conv2d(dim // 4, dim // 4, 7, padding=3, groups=dim // 4))self.v1 = nn.Conv2d(dim // 4, dim // 4, 1)self.v11 = nn.Conv2d(dim // 4, dim // 4, 1)self.v12 = nn.Conv2d(dim // 4, dim // 4, 1)self.conv3_1 = nn.Conv2d(dim // 4, dim // 4, 3, padding=1, groups=dim//4)self.norm2 = LayerNorm(dim // 2, eps=1e-6, data_format="channels_first")self.a2 = nn.Sequential(nn.Conv2d(dim // 2, dim // 2, 1),nn.GELU(),nn.Conv2d(dim // 2, dim // 2, 9, padding=4, groups=dim // 2))self.v2 = nn.Conv2d(dim//2, dim//2, 1)self.v21 = nn.Conv2d(dim // 2, dim // 2, 1)self.v22 = nn.Conv2d(dim // 4, dim // 4, 1)self.proj2 = nn.Conv2d(dim // 2, dim // 4, 1)self.conv3_2 = nn.Conv2d(dim // 4, dim // 4, 3, padding=1, groups=dim // 4)self.norm3 = LayerNorm(dim * 3 // 4, eps=1e-6, data_format="channels_first")self.a3 = nn.Sequential(nn.Conv2d(dim * 3 // 4, dim * 3 // 4, 1),nn.GELU(),nn.Conv2d(dim * 3 // 4, dim * 3 // 4, 11, padding=5, groups=dim * 3 // 4))self.v3 = nn.Conv2d(dim * 3 // 4, dim * 3 // 4, 1)self.v31 = nn.Conv2d(dim * 3 // 4, dim * 3 // 4, 1)self.v32 = nn.Conv2d(dim // 4, dim // 4, 1)self.proj3 = nn.Conv2d(dim * 3 // 4, dim // 4, 1)self.conv3_3 = nn.Conv2d(dim // 4, dim // 4, 3, padding=1, groups=dim // 4)self.dim = dimdef forward(self, x):x = self.norm1(x)x_split = torch.split(x, self.dim // 4, dim=1)a = self.a1(x_split[0])mul = a * self.v1(x_split[0])mul = self.v11(mul)x1 = self.conv3_1(self.v12(x_split[1]))x1 = x1 + ax1 = torch.cat((x1, mul), dim=1)x1 = self.norm2(x1)a = self.a2(x1)mul = a * self.v2(x1)mul = self.v21(mul)x2 = self.conv3_2(self.v22(x_split[2]))x2 = x2 + self.proj2(a)x2 = torch.cat((x2, mul), dim=1)x2 = self.norm3(x2)a = self.a3(x2)mul = a * self.v3(x2)mul = self.v31(mul)x3 = self.conv3_3(self.v32(x_split[3]))x3 = x3 + self.proj3(a)x = torch.cat((x3, mul), dim=1)return xclass UniConvBlock(nn.Module):def __init__(self, dim,drop=0.,drop_path=0.,mlp_ratio=4,layer_scale_init_value=1e-5,core_op=getattr(opsm, 'DCNv3')):super().__init__()self.attn = ConvMod(dim)self.mlp = MLPLayer(in_features=dim,hidden_features=int(dim * mlp_ratio),drop=drop)self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones(dim),requires_grad=True)self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones(dim),requires_grad=True)self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones(dim),requires_grad=True)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm1 = build_norm_layer(dim, 'LN')self.norm2 = build_norm_layer(dim, 'LN')self.dcn = core_op(channels=dim,kernel_size=3,stride=1,pad=1,dilation=1,group=dim // 8,offset_scale=1.0,)def forward(self, x):x = x + self.drop_path(self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.attn(x))x = x.permute(0, 2, 3, 1)x = x + self.drop_path(self.gamma1 * self.dcn(self.norm1(x)))x = x + self.drop_path(self.gamma2 * self.mlp(self.norm2(x)))return x.permute(0, 3, 1, 2)
注释版本
七、实验总结
通过设计三层感受野聚合器和层操作器,UniConvNet成功地解决了扩展感受野同时保持AGD的问题,且在多项视觉任务上表现出了非常优秀的性能。尤其是在低参数量的情况下,UniConvNet能够有效提高准确率并减少计算成本。