PEFT+DeepSpeed 1 (微调 分布式 显存优化)
个人主页:云端筑梦狮
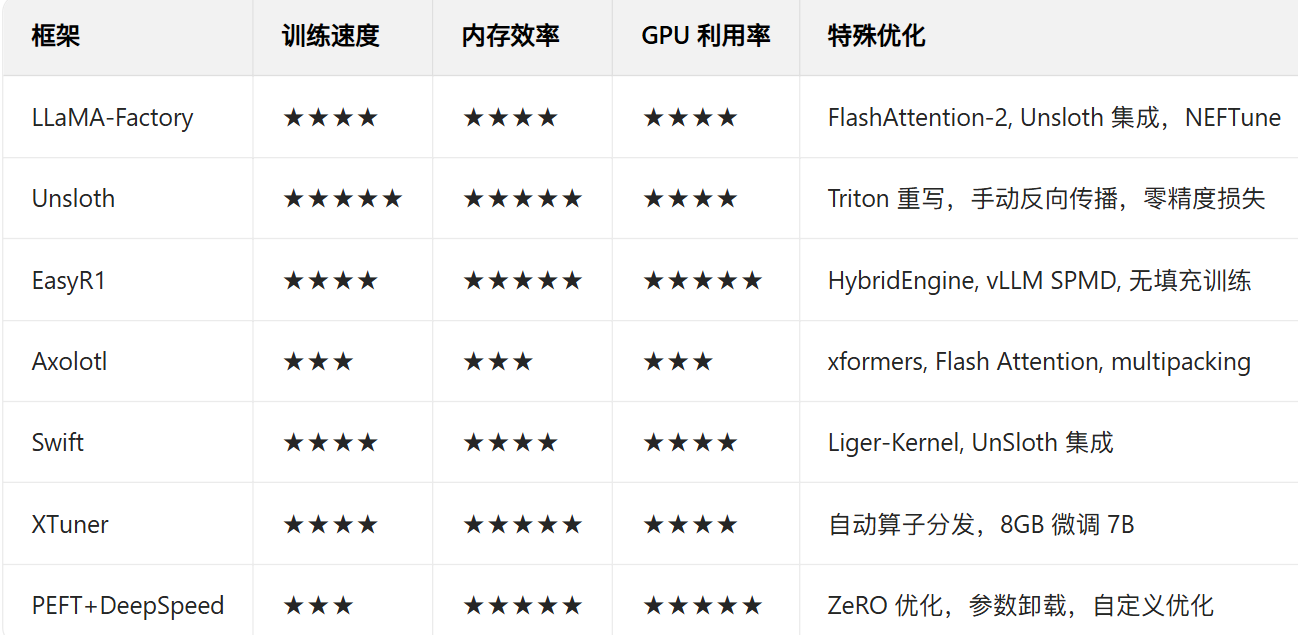
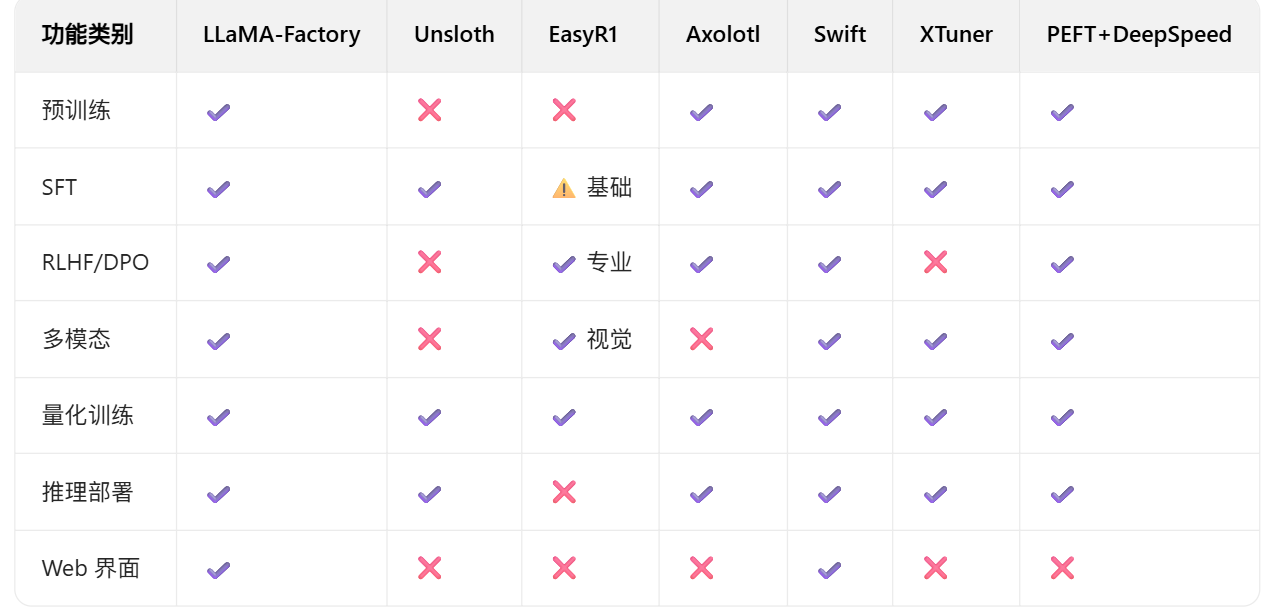
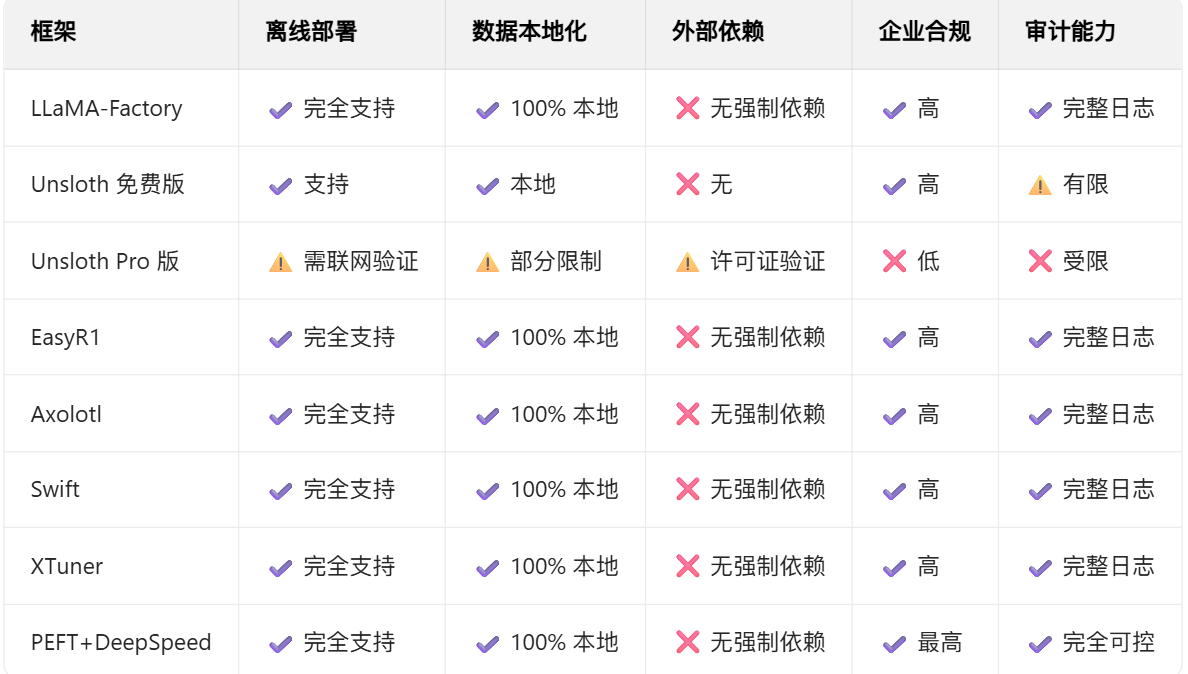
一.不同技术框架(反正就是PEFT+DS就对了)
二. DeepSpeed
1.核心解决的问题
- 传统训练问题:
- 模型太大 → OOM
- 训练太慢 → 等待
- 多卡难用 → 浪费
- DeepSpeed 解决方案:
- 内存优化 → 能跑
- 并行加速 → 更快
- 分布式 → 扩展
2.训练时的GPU显存占用图

1. 模型参数(Parameters)
模型由大量的权重矩阵(如 (W_1, W_2, W_3 .....))和偏置向量(如 (b_1, b_2, b_3 ......))组成。这里使用半精度浮点数(FP16)来存储参数,每个 FP16 参数占 2 字节。 以 70 亿参数(7B)的模型为例,总显存占用约为 7*10^9 * 2 字节 14 GB。这部分是模型本身在显存中的存储量,是训练的基础数据。
2. 梯度(Gradients)
在训练过程中,为了更新模型参数,需要计算每个参数的梯度(用于表示参数的变化方向和幅度)。每个参数对应一个梯度值,且梯度的存储格式与参数相同(这里也是 FP16,2 字节 / 梯度)。 所以,7B 模型的梯度占用显存也约为 7*10^9 * 2 字节 14 GB。这部分是训练时计算参数更新所需的中间数据。
3. 优化器状态(Optimizer States)
训练模型通常使用优化器(如 Adam)来更新参数,优化器需要维护额外的状态信息。Adam 优化器需要存储一阶动量(momentum,用于加速梯度更新)和二阶动量(variance,用于自适应学习率)。
- 一阶动量:每个参数对应一个一阶动量值,用 4 字节(单精度浮点数,FP32)存储,7B 模型的一阶动量占用约 7*10^9 * 4 字节 28 GB GB。
- 二阶动量:每个参数对应一个二阶动量值,同样用 FP32 存储,占用也约为 28 GB。 两者总计约 (28 + 28 = 56) GB。这部分是优化器工作所需的状态存储,是显存占用的 “大户”。
4. 激活值(Activations)
在模型的前向传播过程中,会产生中间结果(即激活值);反向传播时,需要这些激活值来计算梯度。 激活值的显存占用取决于序列长度(输入数据的长度等因素),范围在 5 - 15 GB 之间。图中计算时取了中间值 10 GB 左右。
5. 临时缓冲区
训练过程中,还需要一些临时的显存空间,用于通信(如多卡训练时的参数同步)、临时计算等,占用 2 - 5 GB,图中取 3 GB 左右。
因此会出现显存不足(OOM)的情况,无法顺利进行训练。大模型训练对显存的要求很高,通常需要通过分布式训练、显存优化技术(如模型并行、参数卸载等)来解决显存瓶颈问题。
补充内容
字节(Byte)和位(bit)是计算机存储容量的基本单位,它们的关系是:1 字节 = 8 位。
- 位(bit):是计算机中最小的信息单位,用于表示一个二进制数字(0 或 1),比如二进制数
101就是 3 位。 - 字节(Byte):是计算机中最基本的存储单元,通常由 8 位组成。例如,一个半精度浮点数(FP16)占用 2 字节,也就是 (2 x 8 = 16) 位;单精度浮点数(FP32)占用 4 字节,即 (4 x 8 = 32) 位。
优化器状态(Optimizer States)
优化器的作用是调整神经网络的参数,以最小化损失函数就是调节学习率啥的。
- 一阶动量(momentum):就像开车时的 “惯性记忆”。比如之前车一直往某个方向开(对应模型参数之前的更新方向),一阶动量会记住这个 “惯性”,让参数更新时不轻易突然变方向。要是模型有 70 亿个 “调节按钮”(参数),每个按钮记录惯性的信息需要 4 个字节,那记录所有按钮的惯性,总共就得约 28GB 的空间。
- 二阶动量(variance):好比 “油门控制智慧”。它能看出来之前踩油门(参数更新幅度)的大小变化,然后动态调整现在该踩多深(每个参数的学习率),让车开得更稳。同样,70 亿个按钮,每个用 4 字节记录油门变化情况,这部分也得约 28GB 空间。
激活值(Activations)
激活值是神经网络在进行前向传播时,神经元在经过激活函数处理后的输出结果。
- 前向传播中间结果:在前向传播过程中,数据从输入层开始,经过一层又一层的神经元计算,每一层神经元计算得到的结果就是激活值。这些激活值会作为下一层神经元的输入继续参与计算。
- 反向传播需要保存:在反向传播过程中,需要利用前向传播过程中保存的激活值来计算梯度,从而更新神经网络的参数。反向传播是基于链式求导法则来计算每个参数的梯度,而激活值在计算梯度的过程中起到关键作用。占用的内存空间通常在 5 - 15GB 之间,具体取决于输入序列的长度,序列越长,中间产生的激活值数据量就越大,占用内存也就越多。
临时缓冲区
临时缓冲区是在深度学习训练过程中,为了满足一些临时性的计算和数据传输需求而开辟的内存空间。
- 通信缓冲区:在分布式训练中,多个计算设备(如多块 GPU)之间需要进行数据通信,比如将不同设备上计算得到的梯度进行汇总,或者将更新后的参数分发到各个设备上。通信缓冲区就用于暂存这些需要传输的数据,以确保数据在设备之间能够准确、高效地传输。
- 临时计算空间:在深度学习模型训练过程中,会进行大量的矩阵运算、张量操作等。在这些计算过程中,可能需要一些临时的空间来存储中间计算结果,比如在矩阵乘法中,计算过程中产生的中间结果就需要临时空间存储,直到最终计算完成得到所需的结果。这部分空间的占用通常在 2 - 5GB 之间 ,具体根据不同模型的计算复杂度和训练任务而定。
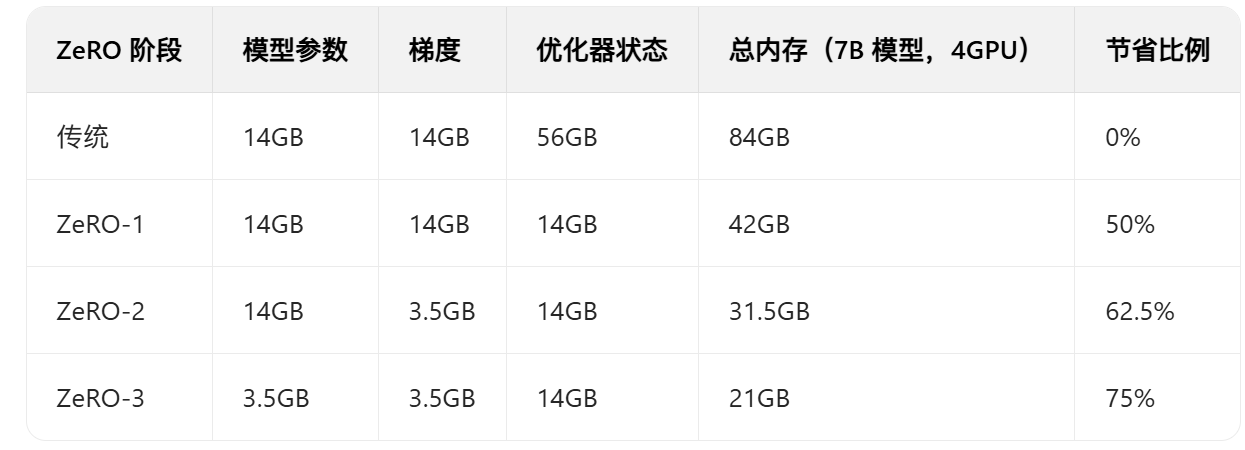
3. DeepSpeed ZeRO 的内存重新分配策略
DeepSpeed 的核心思想是:不是每个 GPU 都需要存储完整的训练状态
- ZeRO-1:只分割优化器状态
- 模型参数:每个 GPU 都有完整副本
- 梯度:每个 GPU 都有完整副本
- 优化器状态:分割到不同 GPU
- ZeRO-2:分割优化器状态 + 梯度
- 模型参数:每个 GPU 都有完整副本
- 梯度:分割到不同 GPU
- 优化器状态:分割到不同 GPU
- ZeRO-3:分割所有内容
- 模型参数:分割到不同 GPU
- 梯度:分割到不同 GPU
- 优化器状态:分割到不同 GPU
ZeRO-1: 优化器状态分片 (Optimizer State Partitioning)
4 个 GPU 的情况下,ZeRO-1 的内存重新分配
- 传统方式(每个 GPU 重复存储):
- GPU 0:[完整模型 14GB] + [完整梯度 14GB] + [完整优化器 56GB] = 84GB
- GPU 1:[完整模型 14GB] + [完整梯度 14GB] + [完整优化器 56GB] = 84GB
- GPU 2:[完整模型 14GB] + [完整梯度 14GB] + [完整优化器 56GB] = 84GB
- GPU 3:[完整模型 14GB] + [完整梯度 14GB] + [完整优化器 56GB] = 84GB
- ZeRO-1(优化器状态分片)就是去重新分配优化器:
- GPU 0:[完整模型 14GB] + [完整梯度 14GB] + [优化器 1/4: 14GB] = 42GB
- GPU 1:[完整模型 14GB] + [完整梯度 14GB] + [优化器 2/4: 14GB] = 42GB
- GPU 2:[完整模型 14GB] + [完整梯度 14GB] + [优化器 3/4: 14GB] = 42GB
- GPU 3:[完整模型 14GB] + [完整梯度 14GB] + [优化器 4/4: 14GB] = 42GB
关键机制
- 分片存储:每个 GPU 只存储 1/N 的优化器状态
- 参数更新时的通信:当需要更新参数时,GPU 之间交换优化器状态
- All-Gather 操作:收集所有 GPU 的优化器状态片段
通信模式
- 前向传播:无额外通信 (所有 GPU 都有完整模型)
- 反向传播:无额外通信 (所有 GPU 都有完整梯度)
- 参数更新: All-Gather 优化器状态 → 更新参数 → 广播新参数
优势
- 通信开销最小
- 训练速度最快
- 实现简单,稳定性最好
劣势
- 内存节省有限 (只节省优化器内存)
- 仍需要大量 GPU 内存存储完整模型和梯度
适用场景
- GPU 内存充足 (40GB+)
- 追求最高训练速度
- 模型不是特别大 (7B-13B)
ZeRO-2 进一步分割梯度,这个是包含Zero1的
- 各 GPU 显存占用:
- GPU 0:[完整模型 14GB] + [梯度 1/4:3.5GB] + [优化器 1/4:14GB] = 31.5GB
- GPU 1:[完整模型 14GB] + [梯度 2/4:3.5GB] + [优化器 2/4:14GB] = 31.5GB
- GPU 2:[完整模型 14GB] + [梯度 3/4:3.5GB] + [优化器 3/4:14GB] = 31.5GB
- GPU 3:[完整模型 14GB] + [梯度 4/4:3.5GB] + [优化器 4/4:14GB] = 31.5GB
- 通信机制:
- Reduce - Scatter:反向传播后,将梯度分散到对应的 GPU
- All - Gather:前向传播前,收集完整梯度用于参数更新
- 通信模式:
- 前向传播:无额外通信
- 反向传播:Reduce - Scatter 梯度(将梯度分散到对应 GPU)
- 参数更新:All - Gather 优化器状态 → 更新参数 → 广播新参数
- 优势:
- 内存节省显著(节省 75% 的梯度内存)
- 通信开销适中
- 性能和内存的良好平衡
- 劣势:
- 反向传播时需要额外通信
- 仍需要完整模型参数
- 适用场景:
- GPU 内存中等(24 - 40GB)
- 平衡性能和内存使用
- 中等 - 大小模型(13B - 30B)
ZeRO-3 进一步分割模型,这个是包含Zero2(这个一般很少用)
- 各 GPU 显存占用:
- GPU 0:[模型 1/4:3.5GB] + [梯度 1/4:3.5GB] + [优化器 1/4:14GB] = 21GB
- GPU 1:[模型 2/4:3.5GB] + [梯度 2/4:3.5GB] + [优化器 2/4:14GB] = 21GB
- GPU 2:[模型 3/4:3.5GB] + [梯度 3/4:3.5GB] + [优化器 3/4:14GB] = 21GB
- GPU 3:[模型 4/4:3.5GB] + [梯度 4/4:3.5GB] + [优化器 4/4:14GB] = 21GB
- 通信模式(最复杂):
- 前向传播:每层都需要 All - Gather 参数 → 计算 → 释放参数
- 反向传播:每层都需要 All - Gather 参数 → 计算梯度 → Reduce - Scatter 梯度
- 参数更新:All - Gather 优化器状态 → 更新参数 → 分片存储
- ZeRO - 3 前向传播的详细通信过程
- 时间轴:
- GPU 0:[参数 1/4] → All - Gather(收集参数)→ 完整参数 → 计算 → 释放 → All - Gather(收集参数)→ …
- GPU 1:[参数 2/4] → All - Gather(收集参数)→ 完整参数 → 计算 → 释放 → All - Gather(收集参数)→ …
- GPU 2:[参数 3/4] → All - Gather(收集参数)→ 完整参数 → 计算 → 释放 → All - Gather(收集参数)→ …
- GPU 3:[参数 4/4] → All - Gather(收集参数)→ 完整参数 → 计算 → 释放 → All - Gather(收集参数)→ …
- 步骤详解:
- All - Gather:每个 GPU 贡献自己的参数片段,组装完整参数
- 计算:所有 GPU 使用完整参数进行前向计算
- 释放:计算完成后立即释放参数,节省内存
- 重复:下一层重复此过程
- 时间轴:
- 优势:
- 内存节省最大(可训练超大模型)
- 支持无限大的模型(理论上)
- 可以在小内存 GPU 上训练大模型
劣势:
通信开销过大
效果总结
三. 什么是Offload?
“Offload” 通常翻译为卸载,指的是将原本在某个计算资源(如 GPU 显存 )上执行或存储的任务、数据,转移到其他计算资源(如 CPU 内存、NVMe 存储设备)上进行处理或存储。
1. 缓解 GPU 显存压力
模型参数、梯度、优化器状态等数据会占用大量的 GPU 显存。当模型规模较大或者训练数据量较多时,可能会出现显存不足(OOM,Out Of Memory)的情况。通过 Offload 技术,将暂时不需要使用的数据(比如暂时不参与计算的模型参数、已经计算完的梯度等)从 GPU 显存卸载到 CPU 内存或者 NVMe 存储中 ,可以释放 GPU 显存空间,使得训练能够继续进行。
例如,DeepSpeed 等深度学习优化库提供了 Offload 功能,允许将优化器状态等数据转移到 CPU 内存,从而在有限显存条件下训练更大规模的模型。
2. 优化计算资源利用
CPU 和 GPU 具有不同的特性,CPU 擅长处理逻辑控制、串行任务,而 GPU 则在并行计算上表现出色。通过 Offload,可以将一些对并行计算需求不高的任务(如数据预处理、部分模型推理步骤等)从 GPU 卸载到 CPU 上执行,让 GPU 专注于更适合并行处理的计算任务(如神经网络的矩阵运算),提高整体计算资源的利用效率。
3. 降低成本
NVMe 存储设备的容量通常比 GPU 显存大得多,且成本相对较低。将一些不常访问的 “冷数据”(如历史训练数据、已经保存的模型检查点等)卸载到 NVMe 存储中,既能满足数据存储需求,又能避免过度使用昂贵的 GPU 显存资源,降低存储成本。
4. 支持大规模分布式计算
在大规模分布式训练场景中,Offload 有助于在不同节点和设备之间更灵活地分配任务和数据。例如,将部分数据卸载到网络中的其他存储节点,实现数据的分布式存储和按需访问,支持更大规模的训练任务。
(注:这部分是对这个东西的概念补充,比较全面 便于概念理解)
- 不用 Offload:所有东西都放在 GPU 显存里
- GPU 显存(40GB)← 模型 + 梯度 + 优化器都在这里
- 用 CPU Offload:把一些东西放到 CPU 内存里
- GPU 显存(40GB):正在计算的数据
- CPU 内存(128GB):暂时不用的数据
- NVMe Offload
- GPU 显存:当前计算数据
- CPU 内存:缓冲数据
- NVMe 存储:冷数据
Offload 可以卸载什么?
Offload 可以选择卸载不同的组件:
- 优化器状态卸载(optimizer offload)
- 把 Adam 的 momentum 和 variance 卸载到 CPU / 磁盘
- 最常用,效果最好
- 模型参数卸载(parameter offload)
- 把模型权重卸载到 CPU / 磁盘
- 只在 ZeRO-3 中可用
- 效果最激进
- 梯度卸载(gradient offload)
- 把梯度卸载到 CPU / 磁盘
- 较少使用,收益有限
Offload 目标位置
可以卸载到三个地方:
- CPU 内存(device: "cpu")
- 速度:中等(比 GPU 慢 10 - 20 倍)
- 容量:大(通常 64GB - 512GB)
- 成本:中等
- NVMe SSD(device: "nvme")
- 速度:慢(比 GPU 慢 100 - 200 倍)
- 容量:很大(1TB - 8TB)
- 成本:低
- 普通硬盘(device: "disk")
- 速度:很慢(比 GPU 慢 1000 倍 +)
- 容量:最大(10TB+)
- 成本:最低
不同 Offload 方式的对比
- 1. 无 Offload(纯 GPU)
- 优点:速度最快
- 缺点:显存占用最多
- 适合:显存充足的情况
- 2. CPU Offload
- 优点:节省显存,速度还可以
- 缺点:比纯 GPU 慢一些
- 适合:显存不够但 CPU 内存充足
- 3. NVMe Offload(硬盘)
- 优点:节省最多显存
- 缺点:速度最慢
- 适合:显存和 CPU 内存都不够的极端情况
代码
# 前向传播
def forward_pass_with_offloading():for layer in model.layers:# 步骤1: 从CPU加载当前层参数到GPUlayer_params = cpu_to_gpu_transfer(layer.cpu_params)# 步骤2: 在GPU上执行计算layer_output = layer.forward(input_data, layer_params)# 步骤3: 如果不是最后几层,将参数卸载回CPUif not layer.is_recent_layer():gpu_to_cpu_transfer(layer_params)input_data = layer_output# 反向传播
def backward_pass_with_offloading():for layer in reversed(model.layers):# 步骤1: 重新加载参数到GPUlayer_params = cpu_to_gpu_transfer(layer.cpu_params)# 步骤2: 计算梯度gradients = layer.backward(grad_output, layer_params)# 步骤3: 将梯度发送到对应的GPU (ZeRO-2)send_gradients_to_owner_gpu(gradients)# 步骤4: 参数卸载回CPUgpu_to_cpu_transfer(layer_params)