cuda stream
基本概念
cuda stream表示GPU的一个操作队列,操作在队列中按照一定的顺序执行,也可以向流中添加一定的操作如核函数的启动、内存的复制、事件的启动和结束等
一个流中的不同操作有着严格的顺序,但是不同流之间没有任何限制
cuda stream中排队的操作和主机都是异步的,所以排队的过程中并不耽误主机的执行
cuda stream的类型
cuda stream 是一种kernel外部级别的并行,包含两种类型的流:
null stream 和 non-null stream
未定义、默认情况下使用的null stream,创建和释放都是自动的;而non-null stream的整个过程都是需要人为定义和管理的
cuda stream的特性和范畴
基于cuda stream的异步内核启动和数据传输支持以下类型的并发
- · 重叠主机和设备的计算
- · 重叠主机计算和主机设备数据传输
- · 重叠主机设备数据传输和设备计算
- · 并发多个设备计算,多个GPU
不支持并发: - · 主机端的页锁内存申请,cudaMallocHost
- · cudaMalloc
- · cudaMemset
- · 两个地址向同一个设备地址的数据传输
- · null stream
cuda stream基本流程
cudaSteam_t steam;
cudaError_t cudaStreamCreate(&steam);
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream);
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);
cudaError_t cudaStreamDestroy(cudaStream_t stream);
使用cuda stream加速应用程序的原理
如图所示,假如要进行一个超大矩阵A和B的求和运算,可以将矩阵分为四份,将原始流中串行执行的数据传输、计算、结果传输过程使用四个stream来重叠一部分数据传输和设备计算,从而达到减少整体耗时的目的。
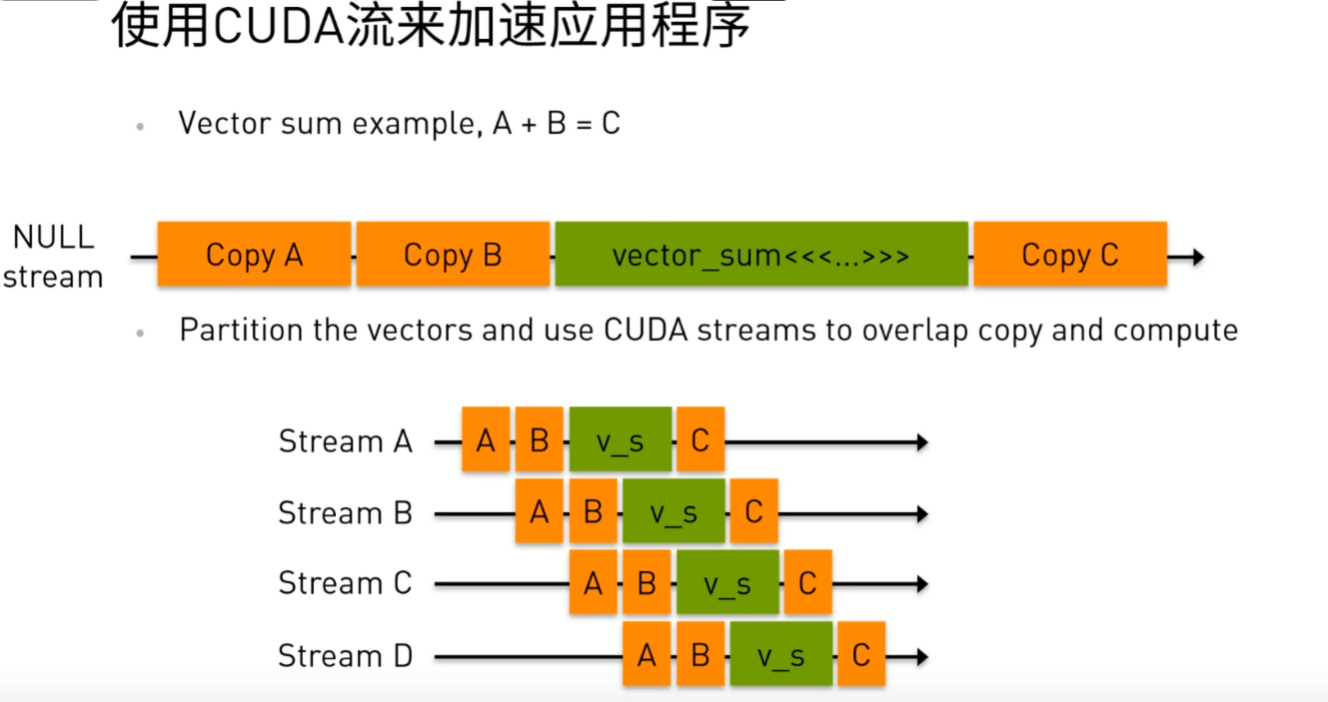
对应的代码如下
for (int i = 0; i < nstreams; i++) {int offset = i * eles_per_stream;cudaMemcpyAsync(&d_A[offset], &h_A[offset], eles_per_stream * sizeof(int), cudaMemcpyHostToDevice, streams[i]);cudaMemcpyAsync(&d_B[offset], &h_B[offset], eles_per_stream * sizeof(int), cudaMemcpyHostToDevice, streams[i]);......vector_sum<<<... , streams[i]>>>(d_A + offset, d_B + offset, d_C + offset);cudaMemcpyAsync(&h_C[offset], &d_C[offset], eles_per_stream * sizeof(int), cudaMemcpyDeviceToHost, streams[i]);
}for (int i = 0; i < nstreams; i++)cudaStreamSynchronize(streams[i]);
其他注意点
使用cuda stream时,kernel调用的第三个参数是共享内存的配置,当使用静态共享内存(如 shared unsigned char s_data[BLOCK_HEIGHT + 10][BLOCK_WIDTH + 10];)时,不需要在核函数调用的第三个参数中设置共享内存大小。因为静态共享内存在编译时就已经确定了大小,定义时直接指定了固定大小(如 [BLOCK_HEIGHT + 10][BLOCK_WIDTH + 10]),编译器会自动为其分配内存,无需运行时指定。核函数参数中共享内存设置的作用:核函数调用的第三个参数(如 <<<grid, block, shared_size>>>)仅用于动态共享内存,动态共享内存需要在运行时指定大小,格式为 extern shared type var[];
两者的区别:
静态共享内存:编译时确定大小,定义时显式指定维度
动态共享内存:运行时确定大小,使用 extern 关键字声明
// 1. 静态共享内存(无需设置第三个参数)
__global__ void staticSharedKernel() {__shared__ unsigned char s_data[BLOCK_HEIGHT + 10][BLOCK_WIDTH + 10];// ...
}// 调用方式(无需第三个参数)
staticSharedKernel<<<gridDim, blockDim, 0, stream>>>(...);// 2. 动态共享内存(需要设置第三个参数)
__global__ void dynamicSharedKernel(int kernelSize) {extern __shared__ unsigned char s_data[]; // 不指定大小// ...
}// 调用方式(需要指定大小)
size_t sharedSize = (BLOCK_WIDTH + 2*half) * (BLOCK_HEIGHT + 2*half) * sizeof(unsigned char);
dynamicSharedKernel<<<gridDim, blockDim, sharedSize, stream>>>(kernelSize);