全网首发! Nvidia Jetson Thor 128GB DK 刷机与测评(四)常用功能测评 - 目标跟踪 Object Tracking 系列
这篇博客是上一篇博客的续集,所有测试和评测均基于第一篇刷机博客的环境上完成的测试。此篇博客对一些目标跟踪领域优秀的开源项目提供了在 Nvidia Jetson Thor 硬件平台上部署的参考操作。
系列博客如下:
- 《全网首发! Nvidia Jetson Thor 128GB DK 刷机与测评(一)刷机与 OpenCV-CUDA、pytorch CUDA13.0+ 使用》;
- 《全网首发! Nvidia Jetson Thor 128GB DK 刷机与测评(二)常用功能测评 Ollama、ChatTTS、Yolov13》;
- 《全网首发! Nvidia Jetson Thor 128GB DK 刷机与测评(三)常用功能测评 DeepAnything 系列》
DeepSORT
DeepSORT 是非常经典的基于深度学习的目标跟踪算法,尽管已经距今 8 年了,但仍然是很多 Paper 的 Benchmark。这一小节将对该算法在 Jetson Thor 设备上如何部署进行介绍。
- DeepSORT: https://github.com/nwojke/deep_sort
该章节涉及到的模型资料我已经放到了网盘中,有需要的话自行提取:
通过网盘分享的文件:DeepSORT
链接: https://pan.baidu.com/s/1Segb58qz0hmdJ3EtQoBm1w?pwd=9rvs 提取码: 9rvs
--来自百度网盘超级会员v5的分享
Step1. 拉取容器
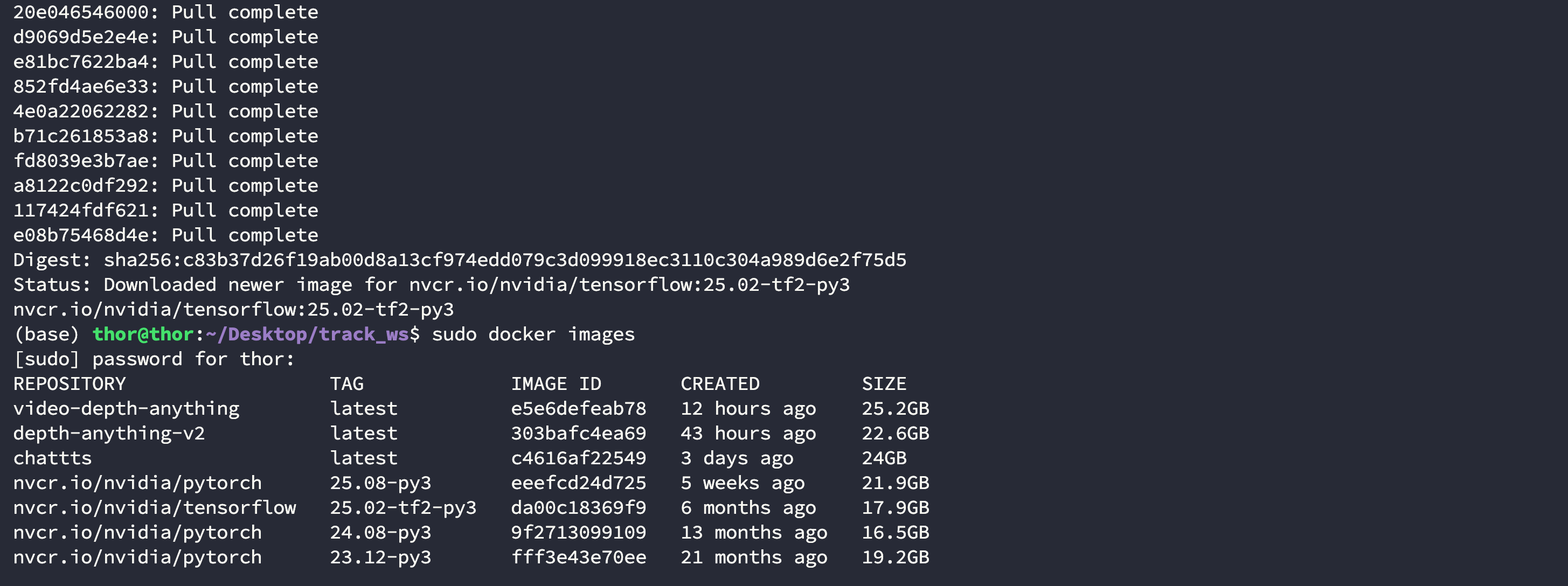
因为 DeepSORT 使用了 Tensorflow 作为深度学习框架,并且制定了细分版本,实验室测试后得到 nvcr.io/nvidia/tensorflow:25.02-tf2-py3 容器是可以使用的:
$ docker pull nvcr.io/nvidia/tensorflow:25.02-tf2-py3$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZE
nvcr.io/nvidia/tensorflow 25.02-tf2-py3 da00c18369f9 6 months ago 17.9GB
Step2. 创建工作空间并拉取源码
这里为了和宿主机 Thor 传输文件方便,建议在宿主机上先创建一个文件夹并映射到容器中,此处以 Deskop/track_ws 为例:
$ cd Desktop
$ mkdir track_ws
进入工作空间 Deskop/track_ws 中拉取 DeepSORT 源码:
$ cd Desktop/track_ws
$ git clone https://github.com/nwojke/deep_sort.git
为了运行官方示例还需要拉取对应资源,你可以通过官方提供的链接下载,也可以直接从我提供的网盘链接下载:
- 官方模型链接:https://drive.google.com/drive/folders/18fKzfqnqhqW3s9zwsCbnVJ5XF2JFeqMp
- 官方数据集链接:https://motchallenge.net/data/MOT16/
- 网盘链接:https://pan.baidu.com/s/1Segb58qz0hmdJ3EtQoBm1w?pwd=9rvs
| 官方模型下载界面 | 官方数据集下载界面 | 网盘资源 |
|---|---|---|
 |  |  |
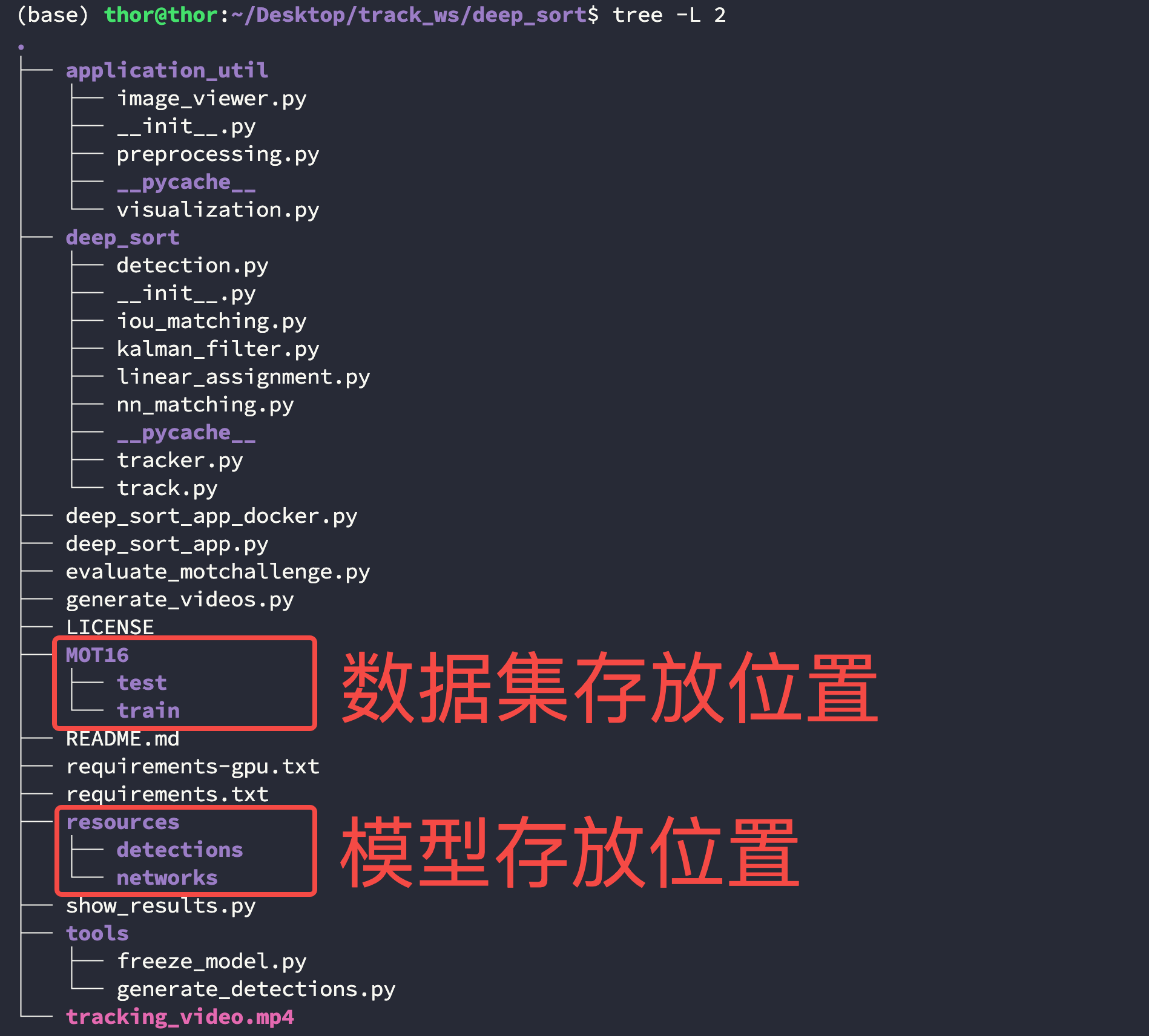
下载好的数据与模型文件放置在如下位置,你需要在 deep_sort 新建 resources 和 MOT16 两个文件夹:
$ cd Desktop/track_ws/deep_sort
$ tree -L 2
Step3. 启动容器
【Note】:这里因为涉及到调用宿主机的显示功能,因此这一章节的操作都需要在宿主机的终端上完成,不能通过 SSH 完成;
在启动容器之前需要先给宿主机终端进行显示授权:
$ sudo xhost +local:docker
然后使用下面的命令运行容器:
$ cd Desktop/track_ws$ docker run -dit \--net=host \--runtime nvidia \--privileged \--ipc=host \-e DISPLAY=$DISPLAY \-v /tmp/.X11-unix:/tmp/.X11-unix \--ulimit memlock=-1 \--ulimit stack=67108864 \-v $(pwd):/workspace \nvcr.io/nvidia/tensorflow:25.02-tf2-py3 \bash$ docker ps -a
$ docker exec -it relaxed_banach /bin/bash

因为这个容器中已经自带了部分 requirements-gpu.txt 文件中涉及到的第三方库,此处只需要手动安装特定的库即可:
$ pip install tf-slim opencv-python==4.7.0.72
安装 libgl:
$ apt-get update
$ apt-get install libgl-dev -y
Step4. 运行示例
使用下面的代码运行官方提供的示例:
$ python deep_sort_app.py \--sequence_dir=./MOT16/test/MOT16-06 \--detection_file=./resources/detections/MOT16_POI_test/MOT16-06.npy \--min_confidence=0.3 \--nn_budget=100 \--display=True
启动后会有一个对应的弹窗,如果你启动后报了一个有关 Qt Plugin 的错误,那么说明 Step3 中启动时显示映射存在问题,仔细检查你的命令是否正确:

Step5. [可选] 保存容器
在完成配置并退出容器后,使用下面的命令提交并保存容为一个稳定镜像:
- 查看当前运行的容器:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b1624bdb5e49 nvcr.io/nvidia/tensorflow:25.02-tf2-py3 "/opt/nvidia/nvidia_…" 35 minutes ago Up 35 minutes relaxed_banach
- 暂停当前运行的容器:
$ docker stop relaxed_banach
relaxed_banach
- 提交刚才运行的容器:
$ docker commit -a "GaohaoZhou" -m "DeepSORT-TF finished" b1624bdb5e49 deep-sort:tensorflow
sha256:81e4fe1592de3299e8ced165fa4d86256c5d1c6b5dc0f5281a34a896a4929322
- 查看当前存在的镜像:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
deep-sort tensorflow 81e4fe1592de 9 seconds ago 18.4GB
nvcr.io/nvidia/tensorflow 25.02-tf2-py3 da00c18369f9 6 months ago 17.9GB

Boxmot
- Boxmot: https://github.com/mikel-brostrom/boxmot
Step1. 拉取容器
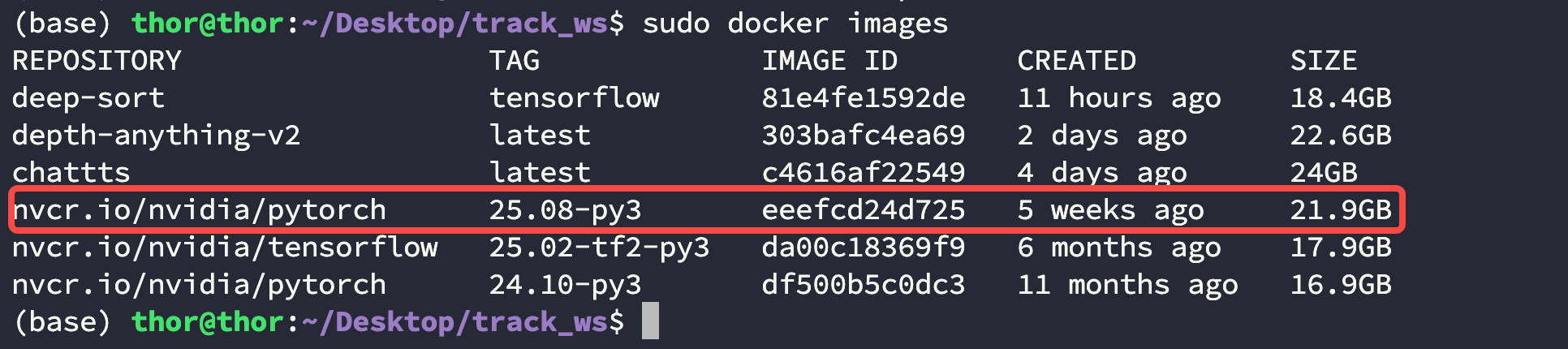
这里使用 nvcr.io/nvidia/pytorch:25.08-py3 容器:
$ docker pull nvcr.io/nvidia/pytorch:25.08-py3
查看容器列表:
$ docker images
Step2. 创建工作空间并拉取源码
这里为了和宿主机 Thor 传输文件方便,建议在宿主机上先创建一个文件夹并映射到容器中,此处以 Deskop/track_ws 为例:
$ cd Desktop
$ mkdir track_ws
进入工作空间 Deskop/track_ws 中拉取 DeepSORT 源码:
$ cd Desktop/track_ws
$ git clone https://github.com/mikel-brostrom/boxmot.git
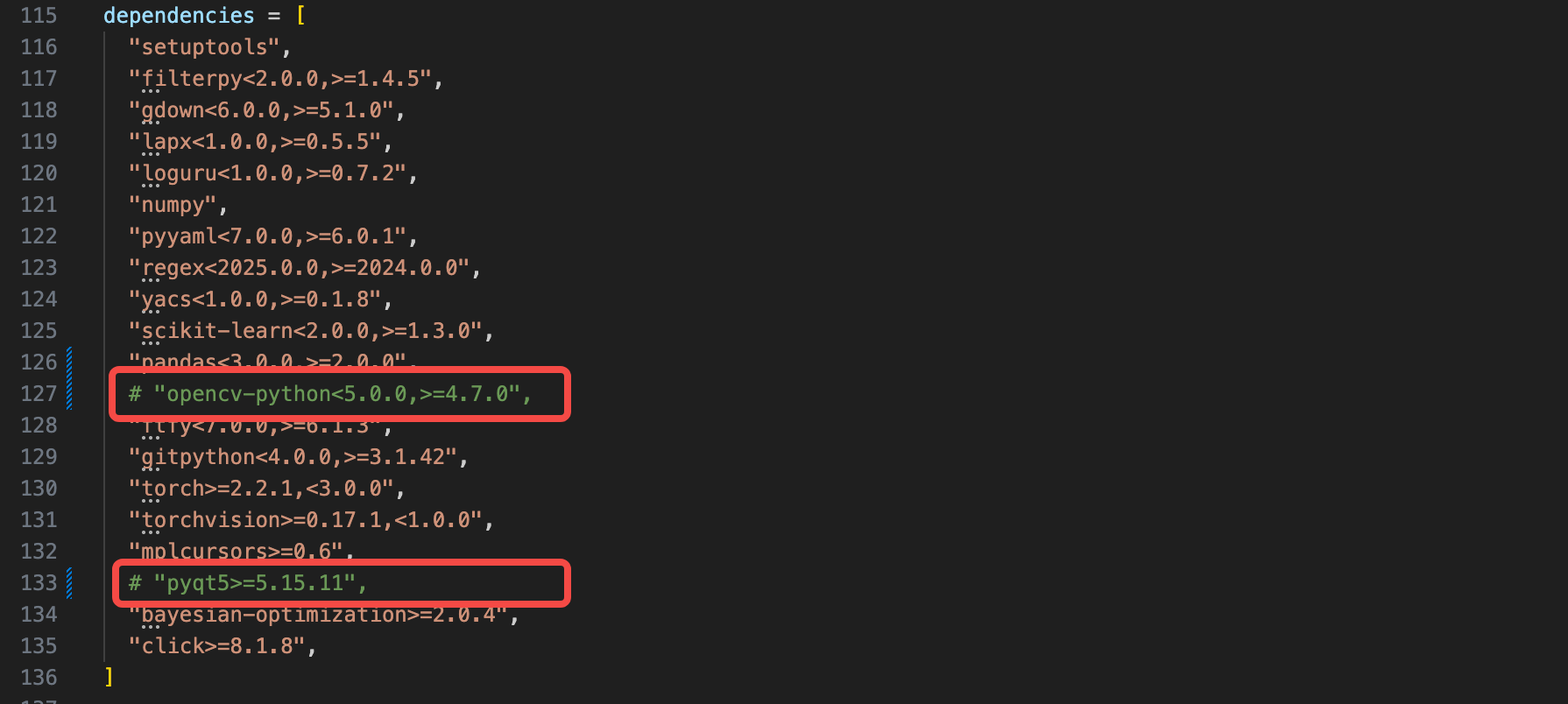
拉取完之后需要修改 pyproject.toml 文件,将该文件中 opencv-python<5.0.0,>=4.7.0 和 pyqt5>=5.15.11 注释掉,分别在 127 和 133 行:
【Note】:虽然安装依赖文件中需要 pyqt,但实际工程中并没有导入这个包,此外还发现在容器中安装 pyqt 存在一些问题,好在不影响当前工程。
"setuptools","filterpy<2.0.0,>=1.4.5","gdown<6.0.0,>=5.1.0","lapx<1.0.0,>=0.5.5","loguru<1.0.0,>=0.7.2","numpy","pyyaml<7.0.0,>=6.0.1","regex<2025.0.0,>=2024.0.0","yacs<1.0.0,>=0.1.8","scikit-learn<2.0.0,>=1.3.0","pandas<3.0.0,>=2.0.0", # "opencv-python<5.0.0,>=4.7.0","ftfy<7.0.0,>=6.1.3","gitpython<4.0.0,>=3.1.42","torch>=2.2.1,<3.0.0","torchvision>=0.17.1,<1.0.0","mplcursors>=0.6",# "pyqt5>=5.15.11","bayesian-optimization>=2.0.4","click>=8.1.8",
]
Step3. 启动容器
使用下面的命令启动容器:
$ docker run -dit \--net=host \--runtime nvidia \--privileged \--ipc=host \--ulimit memlock=-1 \--ulimit stack=67108864 -v $(pwd):/workspace nvcr.io/nvidia/pytorch:25.08-py3 bash
然后查看正在运行的容器:
$ docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0bc8b56a67b7 nvcr.io/nvidia/pytorch:25.08-py3 "/opt/nvidia/nvidia_…" 6 minutes ago Up 6 minutes crazy_gould

进入刚刚启动的容器:
$ docker exec -it crazy_gould /bin/bash

进入容器后依次执行一下命令:
- 更新源并安装
libgl-dev:
$ apt-get update
$ apt-get install libgl-dev
- 源码安装 boxmot 工程:
$ cd /workspace/boxmot/
$ pip install -e .
- 覆盖
opencv与numpy到指定版本:
$ pip install numpy==1.26.4
$ pip install opencv-python==4.7.0.72
Step4. 运行示例
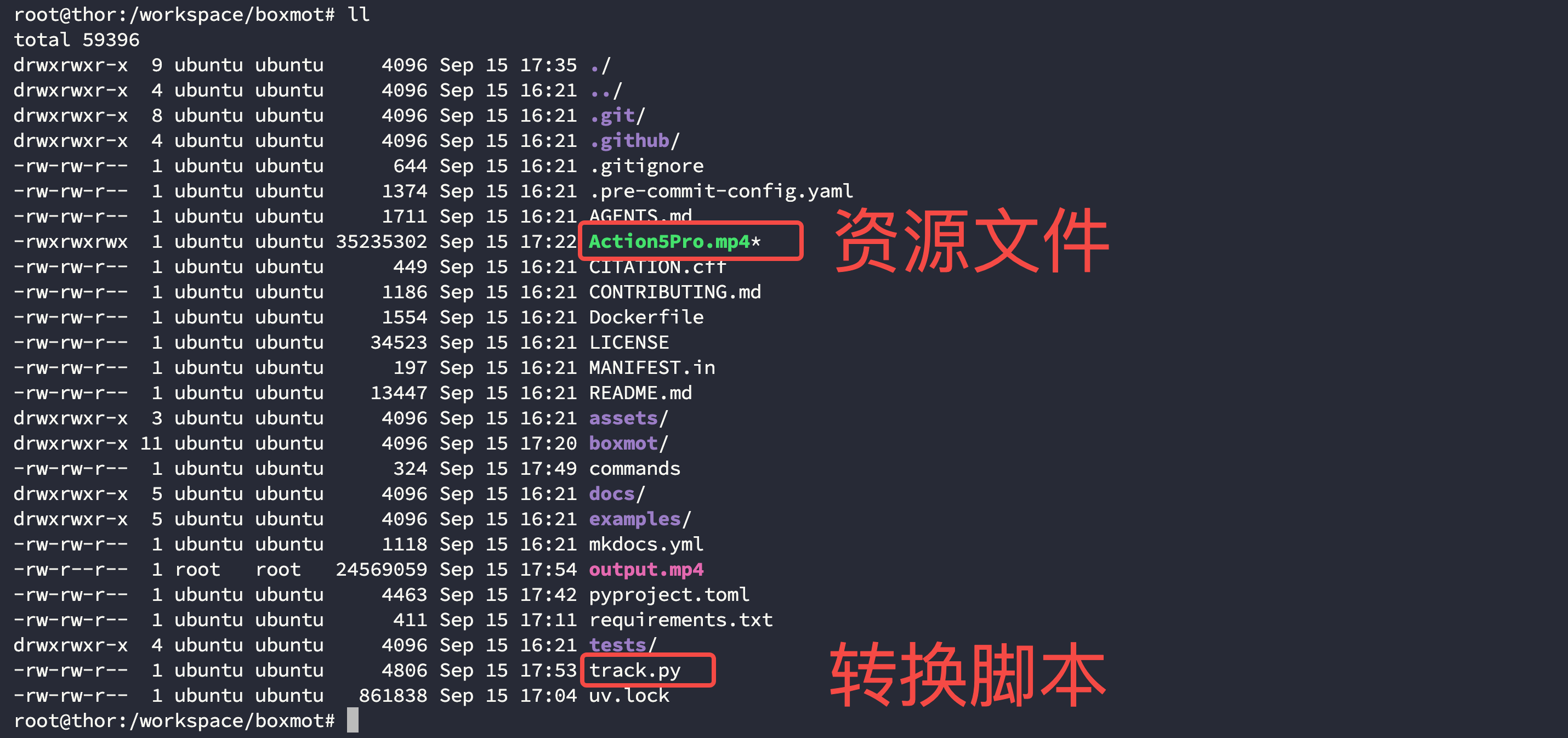
这里提供了一个示例文件,是我们在自动化大厦楼下拍摄的一段视频,不涉及任何版权问题可以随意使用,下载好的文件直接放在 boxmot 项目目录下即可:
通过网盘分享的文件:Action5Pro.mp4
链接: https://pan.baidu.com/s/1pNiMKy5WZHTul6zxTH0wZQ?pwd=bvix 提取码: bvix
--来自百度网盘超级会员v5的分享
我们也提供了一个小脚本用来演示如何转换一个视频文件,将下面的脚本同样放在 boxmot 项目目录下:
import cv2
import torch
import numpy as np
from pathlib import Path
import argparse
import time # 1. 导入 time 模块from boxmot import BoostTrack
from torchvision.models.detection import (fasterrcnn_resnet50_fpn_v2,FasterRCNN_ResNet50_FPN_V2_Weights as Weights
)# --- 1. 设置和解析命令行参数 ---
parser = argparse.ArgumentParser(description="使用 BoXMOT 和 Torchvision 对视频进行目标跟踪")
parser.add_argument('-i', '--video_path',type=str,required=True,help="输入视频的文件路径 (例如: ./input.mp4)"
)
parser.add_argument('-o', '--output_path',type=str,required=True,help="保存处理后视频的文件路径 (例如: ./output.mp4)"
)
args = parser.parse_args()# --- 2. 使用从参数中获取的路径 ---
VIDEO_PATH = Path(args.video_path)
OUTPUT_PATH = Path(args.output_path)# 确保输出目录存在
OUTPUT_PATH.parent.mkdir(parents=True, exist_ok=True)# --- 3. 开始计时:模型加载 ---
print("正在加载模型...")
start_load_time = time.time() # 记录模型加载开始时间# Set device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")# Load model with pretrained weights and preprocessing transforms
weights = Weights.DEFAULT
model = fasterrcnn_resnet50_fpn_v2(weights=weights, box_score_thresh=0.5)
model.to(device).eval()
transform = weights.transforms()# Initialize tracker
tracker = BoostTrack(reid_weights=Path('osnet_x0_25_msmt17.pt'), device=device, half=False)end_load_time = time.time() # 记录模型加载结束时间
model_load_duration = end_load_time - start_load_time
print(f"模型加载完成。")# --- 4. 视频输入(使用参数路径) ---
# 注意:cv2.VideoCapture() 本身很快,真正耗时的是 cap.read()
print(f"正在打开视频文件: {VIDEO_PATH}")
cap = cv2.VideoCapture(str(VIDEO_PATH))if not cap.isOpened():print(f"Error: 无法打开视频文件 {VIDEO_PATH}")exit()# --- 5. 视频输出(使用参数路径) ---
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)fourcc = cv2.VideoWriter_fourcc(*'mp4v')
writer = cv2.VideoWriter(str(OUTPUT_PATH), fourcc, fps, (frame_width, frame_height))print(f"开始处理视频...")
print(f"结果将保存至: {OUTPUT_PATH}")# --- 6. 初始化统计变量 ---
total_frames = 0
total_processing_time = 0 # 仅用于检测和跟踪# --- 7. 处理循环 ---
with torch.inference_mode():while True:# 视频帧读取 (这部分时间不计入检测耗时)success, frame = cap.read()if not success:print("视频处理完成。")break# 帧计数total_frames += 1# 开始计时 (单帧处理)start_frame_time = time.time()# Convert frame to RGB and prepare for modelrgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)tensor = torch.from_numpy(rgb).permute(2, 0, 1).to(torch.uint8)input_tensor = transform(tensor).to(device)# Run detectionoutput = model([input_tensor])[0]scores = output['scores'].cpu().numpy()keep = scores >= 0.5# Prepare detections for trackingboxes = output['boxes'][keep].cpu().numpy()labels = output['labels'][keep].cpu().numpy()filtered_scores = scores[keep]detections = np.concatenate([boxes, filtered_scores[:, None], labels[:, None]], axis=1)# Update tracker and draw resultsres = tracker.update(detections, frame)tracker.plot_results(frame, show_trajectories=True)# 结束计时 (单帧处理)end_frame_time = time.time()total_processing_time += (end_frame_time - start_frame_time)# 写入帧 (这部分时间不计入检测耗时)writer.write(frame)# (可选) 实时显示输出# cv2.imshow('BoXMOT + Torchvision', frame)# if cv2.waitKey(1) & 0xFF == ord('q'):# print("处理被用户终止。")# break# --- 8. 清理和释放资源 ---
cap.release()
writer.release()
cv2.destroyAllWindows()print(f"视频已成功保存到 {OUTPUT_PATH}")# --- 9. 打印统计结果 ---
print("\n--- 性能统计 ---")
print(f"模型加载耗时: {model_load_duration:.4f} 秒")
print(f"总 帧 数: {total_frames} 帧")if total_frames > 0:avg_processing_time = total_processing_time / total_framesavg_fps = 1.0 / avg_processing_time if avg_processing_time > 0 else 0print(f"检测/跟踪总耗时: {total_processing_time:.4f} 秒")print(f"平均每帧耗时: {avg_processing_time:.4f} 秒 (约 {avg_fps:.2f} FPS)")
else:print("未处理任何帧。")
此时你的文件结构应该如下:
$ ll /workspace/boxmot/
运行转换脚本,这里由于为了写入到本地文件中将图像从 GPU 搬到 CPU 中,因此耗时较大:
$ python track.py -i Action5Pro.mp4 -o output.mp4正在加载模型...
使用设备: cuda
模型加载完成。
正在打开视频文件: Action5Pro.mp4
开始处理视频...
结果将保存至: output.mp4
视频处理完成。
视频已成功保存到 output.mp4--- 性能统计 ---
模型加载耗时: 0.6163 秒
总 帧 数: 310 帧
检测/跟踪总耗时: 34.2212 秒
平均每帧耗时: 0.1104 秒 (约 9.06 FPS)
最终效果如下:

Step5. [可选] 保存容器
保存容器核心为 3 步:
- 从容器中退出并暂停容器:
$ docker ps -a
$ docker stop crazy_gould

- 提交容器为镜像并打上自己的信息:
$ docker commit -a "GaohaoZhou" -m "Boxmot finished" 0bc8b56a67b7 boxmot

- 确保打包成功后退出终止容器:
$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZE
boxmot latest 61c48da57490 59 seconds ago 22.8GB
$ docker rm crazy_gould
[预计09月17日] PySOT
- PySOT: https://github.com/STVIR/pysot