核心信息防爬虫盗取技术方案
核心思路:提高爬虫的获取成本,使其难以编写、效率低下、容易被发现,直至无利可图
一、 基础防护(成本低,易于实施,能抵御大多数低级爬虫)
这类措施主要利用Web服务器和框架本身的能力
- 频率限制(Rate Limiting)
- 原理:限制单个IP/用户在一段时间内的请求次数,这是抵御爬虫最有效的手段之一。
- TP5实现:
- 可以使用中间件(Middleware)来实现。创建一个RateLimit中间件。
- 在中间件中,使用Redis或Cache(缓存)以IP或用户ID为键,记录请求次数和重置时间。
- 例如:限制每IP每分钟最多请求60次商品列表API,超过则返回429 Too Many Requests状态码。
- 策略:
- C端:限制可以相对宽松,避免影响正常用户。
- B端:可以结合商家账号进行更精细的限制。对于商品列表等高频接口,限制应更严格。
- 完善的API认证与授权
- 原理:确保每一个请求都来自经过认证的合法用户或客户端。
- B端实现:必须使用强认证,如 OAuth 2.0 或 JWT。每个API请求都必须在Header中携带有效的Access Token。TP5可以在中间件中统一校验Token的有效性和权限范围。
- C端实现:对于App,可以要求用户登录后获取Token再访问商品API。对于小程序,利用其自带的登录机制。对于未登录用户,可以返回少量非敏感数据(如仅首屏商品),或让其体验受限版本。
3.User-Agent校验
- 原理:在服务器端校验请求的User-Agent头。
- 实现:在中间件中检查User-Agent是否为空、是否来自常见浏览器或您官方App的特定标识。不符合规则的请求直接拒绝。但这很容易被伪造,只能作为辅助手段
二、 中级防护(增加爬虫编写难度和成本)
这类措施需要前端和后端配合,改动较大
1.数据动态加载与API令牌化
- 原理:让爬虫无法直接构造出获取数据的完整URL。
- 实现:
- 前端(Web)不再直接拼接商品列表API的URL(如/api/v1/goods?page=1)。
- 改为先请求一个“接口签名”接口,后端根据当前用户会话、时间戳等生成一个一次性或短期有效的令牌(Token),并返回给前端。
- 前端再用这个Token去请求真正的商品API(如/api/v1/goods?token=xxxxx)。
- 后端校验Token的有效性和合法性。这样,爬虫直接构造URL就失效了,必须模拟整个前端流程。
2.请求签名验证
- 原理:确保请求在传输过程中未被篡改,并且是来自合法客户端。
- 实现(尤其适用于App端):
- 客户端:将请求参数、时间戳(Timestamp)、随机数(Nonce)和一个只有客户端与服务器知道的Secret Key(可以编译在App内,但存在泄露风险)按一定规则排序拼接,进行MD5或SHA256哈希,生成一个签名(Sign)。
- 将Sign、Timestamp、Nonce随请求一同发送到服务器。
- 服务器端(TP5):在中间件中,用同样的算法和Secret Key重新计算签名。如果匹配,则通过;如果不匹配或时间戳已过期(如超过5分钟),则拒绝请求。
- 优点:有效防止重放攻击(Replay Attack)和参数篡改。
三、 高级防护(专门对抗自动化工具和高级爬虫)
1.人机验证(Captcha)
- 原理:在可疑行为发生时弹出验证,区分人类和机器。
- 场景:
- 频繁搜索时。
- 从某个IP段发出大量请求时。
- 用户行为模式异常时(如滑动速度极其均匀)。
- 选择:推荐使用更友好的验证码服务,如极验(GeeTest)、行为验证码(滑动拼图、点选文字等),对用户体验影响较小。
2.Web应用防火墙(WAF)
- 原理:使用云服务商(如阿里云、腾讯云)或自建的WAF服务。
- 功能:它可以基于IP信誉库、行为模式自动识别并拦截恶意爬虫IP,为您省去大量自行编写规则和维护IP黑名单的工作。这是非常省心且有效的一层防护
3.客户端反爬(App/小程序)
- 代码混淆:对前端JS或移动端代码进行混淆和加固,增加逆向分析难度。
- 证书绑定(SSL Pinning):在App中防止抓包工具(如Charles/Fiddler)进行中间人攻击,从而分析API。
- 环境检测:检测客户端是否运行在Root/越狱设备、模拟器或Hook框架中,如果是,可以拒绝服务或返回假数据。
4.客户端指纹(Device Fingerprinting)
- 核心思想:不仅仅是识别IP,而是识别背后的一台“设备”。即使用户切换账号或IP,也能通过指纹关联其行为。
- 实现:收集浏览器或App的环境信息(如User-Agent、屏幕分辨率、字体、Canvas渲染特征、WebGL显卡特征等),通过算法生成一个唯一、稳定的设备ID。当一个设备ID表现出异常行为(如短时间内切换大量账号、访问频率极高),可以直接封禁该设备。
四、 运营与监控策略
技术手段之外,持续的监控同样重要
1.日志分析与监控
- 详细记录所有API请求的IP、User-Agent、请求频率、请求量。
- 使用ELK(Elasticsearch, Logstash, Kibana)或监控告警系统,设置规则,一旦发现异常模式(如单个IP请求量暴增、非工作时段频繁访问),立即触发告警
2.IP黑名单
- 对确认为恶意的IP,动态加入黑名单(可以在Redis中设置过期时间),直接拒绝其访问.
3.数据混淆与“投毒”
- 策略:对疑似爬虫的请求(如IP异常、无有效Referer),返回虚假的、误导性的商品数据(“蜜罐”数据)。
- 目的:污染爬虫数据库,使其获取的数据失去价值,从而主动放弃抓取
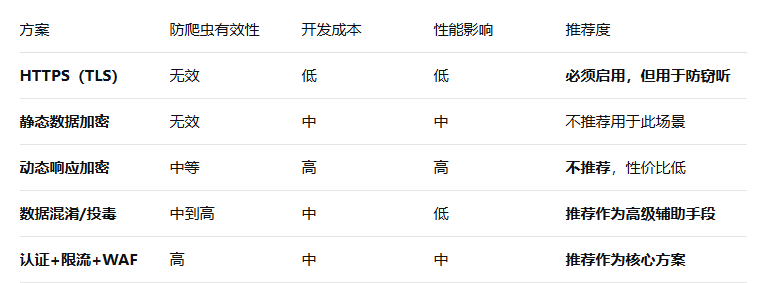
- 数据加密策略
1. 静态数据加密(价值有限,不推荐)
- 方案:在数据库里存储加密后的商品信息,服务器取出后解密再通过API返回。
- 为什么无效:这对于防爬虫几乎完全无效。因为爬虫攻击的是您的API接口,而不是您的数据库。API返回的已经是解密后的明文数据,爬虫拿到的是最终结果,完全绕过了这层加密。
- 正确用途:静态加密主要用于防止数据库脱库后的数据泄露,是安全纵深防御的一环,而非防爬虫手段。
2. 动态响应加密(针对性方案,增加破解难度)
这是一种更高级的思路,其核心是:“即使你通过了认证,拿到了数据,也无法轻易读懂”。这需要前后端紧密配合。
- 原理:服务器返回的并非明文JSON,而是一串加密的密文。前端拥有解密密钥,需要自行解密后才能渲染页面。
- 实现(示例):
- 后端(TP5):在返回数据前,对原本的JSON响应体使用一种对称加密算法(如AES)进行加密,密钥(Key)和偏移量(IV)可以动态生成。
- 后端:将加密后的密文和解密所需的参数(如Key和IV)通过HTTP响应头(Header)或其他字段返回给前端。注意:密钥本身也需要用非对称加密或前端公钥加密后再传输,以提高安全性。
- 前端:收到响应后,先从Header中获取加密的密钥,解密出真正的AES密钥,然后再对响应体进行解密,最后得到可读的JSON数据。
- 优点:
- 使得爬虫无法直接解析JSON,必须模拟前端的整套解密流程。
- 网络抓包工具(如Charles)看到的是密文,无法直接读懂业务内容。
- 缺点:
- 非常影响性能:服务器端和客户端都增加了加密/解密的计算开销。
- 开发复杂度高:前后端联调复杂度急剧上升。
- 并不能绝对防止:爬虫开发者只要逆向分析您的JavaScript代码,就能找到解密算法和密钥获取方式,然后依样画葫芦实现解密。这是一种“提高门槛”的策略,而非彻底防御。
- 对用户体验不友好:可能增加前端渲染的延迟。
3. 数据混淆与“投毒”(更实用的策略)
这可以看作是一种“创造性”地使用加密/编码的策略,性价比更高。
- 方案:对返回的JSON数据中的关键字段(如商品ID、价格、库存)进行自定义的编码或轻量级加密变换。
- 实现:
- 后端在返回数据前,对敏感字段进行一次可逆的变换。例如,将商品ID乘以一个固定系数再加一个盐值:encrypted_id = (raw_id * factor) + salt。
- 或者使用一个简单的 XOR 运算。
- 前端收到数据后,再通过对应的逆运算还原真实数据。
- 优点:
- 爬虫直接拿到的是错误/混乱的数据,无法直接使用,必须分析出转换规则。
- 性能和开发成本远低于全报文加密。
- 您可以给不同的客户(B端商家)使用不同的变换算法和密钥,使得一个客户的爬虫规则无法用于另一个客户。
- 终极用法——“蜜罐”:对识别出的可疑请求(如频率过高),返回看似正常但包含大量虚假商品信息(蜜罐数据)的响应。爬虫无法分辨真伪,一旦抓取了这些垃圾数据,其数据价值就被污染,从而迫使其放弃。
- 总结
不要将数据加密作为防爬虫的主要手段。 您应该优先实施并加固之前提到的:
- 严格的API认证与授权体系(JWT/OAuth)。
- 基于IP和用户ID的精细化速率限制(Redis)。
- 部署WAF(Web应用防火墙),利用云服务商的强大能力来识别和拦截恶意流量。
在以上基础上,如果仍需提升防护等级,可以考虑:
- 对关键字段进行轻量级数据混淆,增加爬虫解析数据的成本。
- 建立监控告警系统,对异常行为进行“数据投毒”,反制爬虫。
这样构建的体系才是成本、性能和安全性之间的最佳平衡