基于YOLO8的打架斗殴行为检测系统【源码+数据集+文章】
文末附源码下载链接

开发目的
近年来,公共场所的暴力事件如打架斗殴频发,严重威胁社会治安与公民人身安全,尤其在校园、地铁站、酒吧、广场等人员密集区域,此类突发事件具有极强的突发性与扩散性,若未能及时干预,极易造成恶劣后果。尽管当前视频监控系统已广泛部署,但传统监控仍依赖人工实时值守或事后回溯,难以实现对暴力行为的即时发现与响应,存在反应滞后、人力成本高、监控盲区多等显著局限。为突破这一技术瓶颈,亟需一种能够自动、精准、实时识别异常行为的智能检测手段。
基于YOLOv8的打架斗殴行为检测系统应运而生,该模型作为当前目标检测领域的前沿成果,继承并优化了YOLO系列在速度、精度与泛化能力上的优势,具备强大的动态行为特征捕捉能力,能够在复杂场景下高效识别多人交互中的异常姿态与运动模式。本系统深度融合计算机视觉与深度学习技术,实现了对打架斗殴行为的端到端实时监测与预警,克服了光照变化、遮挡、密集人群等现实干扰因素,支持在边缘设备与云端多种平台稳定运行。
该系统的研发不仅显著提升了公共安全防控的智能化水平,缩短了应急响应时间,还有效降低了安保人力投入,为构建“事前可预警、事中可干预、事后可追溯”的立体化安防体系提供了关键技术支撑,对推动智慧安防、平安城市和智能社会治理具有重要的现实意义与应用价值。
YOLO介绍
YOLOv8:更高效、更精准的目标检测新标杆
YOLOv8由Ultralytics团队于2023年推出,作为YOLO系列的最新成员,它在继承YOLOv5高效架构的基础上,融合了多项前沿技术,在检测精度和推理速度之间实现了更优平衡。本文将从骨干网络(Backbone)、Neck结构以及检测头(Head)三个方面深入解析YOLOv8,并对比其与YOLOv5、YOLOv7相比的关键改进与创新。
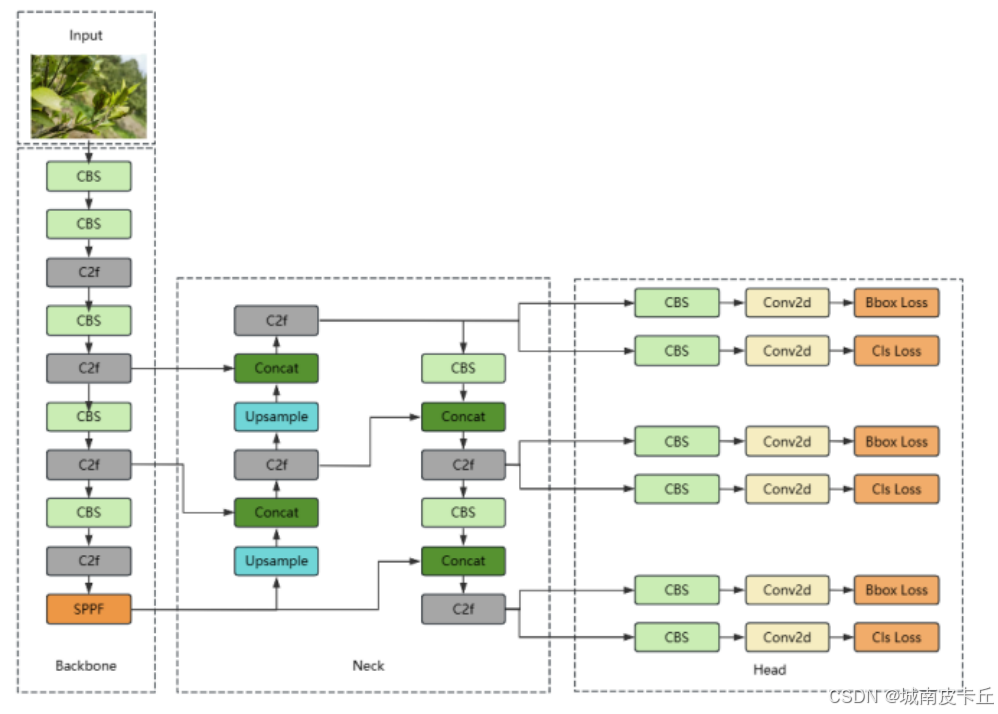
一、YOLOv8网络结构详解
-
骨干网络(Backbone):CSPDarknet 的进化
YOLOv8沿用了Darknet作为主干特征提取网络,但对CSP(Cross Stage Partial)结构进行了优化升级。与YOLOv5中的CSPDarknet不同,YOLOv8采用了更加高效的梯度流设计,通过重构CSP模块,减少了冗余计算,增强了特征复用能力。此外,YOLOv8在每个卷积层后统一使用SiLU(Swish)激活函数,提升了模型非线性表达能力。同时,摒弃了传统的自动锚框(Anchor Auto-learning)机制,转而采用Anchor-Free的检测范式,简化了训练流程并提升了小目标检测性能。 -
Neck结构:PANet 的精细化改进
YOLOv8的Neck部分延续了路径聚合网络(PANet)的思想,但在结构上进行了重要调整。不同于YOLOv5中采用“上采样-拼接-下采样”的标准PAN结构,YOLOv8引入了更简洁高效的“梯形”特征金字塔结构,去除了CBM(Conv-BN-Mish)模块中的BN层冗余设计,改用C2f模块替代原有的C3模块。C2f模块通过更稀疏的跨阶段连接方式,在保持强特征融合能力的同时显著降低了参数量和计算开销,提升了模型整体效率。 -
检测头(Head):解耦头 + Anchor-Free 设计
YOLOv8采用了完全解耦的检测头(Decoupled Head),将分类任务和回归任务分离为两个独立分支,避免了多任务间的干扰,提升了检测精度。更重要的是,YOLOv8彻底放弃了基于Anchor的检测机制,转向Anchor-Free方案,直接预测目标中心点与边界偏移量。这一改变不仅简化了模型设计,还增强了对不规则或密集目标的适应能力。同时,配合Task-Aligned Assigner正样本分配策略,实现分类分数与定位精度的动态对齐,大幅提升检测质量。
二、YOLOv8 vs YOLOv5 & YOLOv7:核心改进与创新
- 相比YOLOv5的提升
- 结构优化:YOLOv8采用C2f模块替代C3模块,增强梯度传播,减少参数量;
- 激活函数统一:全网使用SiLU激活函数,提升收敛速度与稳定性;
- 检测头革新:引入解耦头与Anchor-Free设计,摆脱先验框限制;
- 标签分配策略升级:采用Task-Aligned Assigner,优于YOLOv5的SimOTA,提升正样本选择质量。
- 相比YOLOv7的差异化优势
- 架构简洁性:YOLOv8未采用YOLOv7中复杂的E-ELAN、可编程梯度信息(PGI)等复杂模块,更易于部署与迁移;
- 训练效率更高:YOLOv8无需辅助头(Auxiliary Head)进行多阶段训练,端到端训练更稳定快速;
- 工程友好性:继承YOLOv5的良好工程实践,支持ONNX、TensorRT等格式导出,部署便捷;
- 性能全面领先:在相同规模下,YOLOv8在COCO数据集上的mAP和推理速度均优于YOLOv7。
总结
YOLOv8并非简单的版本迭代,而是一次面向工业落地的深度优化。它在骨干网络中强化特征复用,在Neck结构中追求高效融合,在检测头上实现解耦与无锚化,全面提升了检测性能与部署灵活性。相较于YOLOv5,它更具先进性;相比YOLOv7,它更注重实用性与泛化能力。YOLOv8凭借其出色的精度-速度权衡,已成为当前目标检测领域最具竞争力的模型之一。
系统设计
数据集
(1) 数据集基本情况
本项目所使用的数据集为专门用于打架斗殴行为识别的图像数据集,全部图片均已标注完毕,适用于YOLO系列目标检测模型训练。根据获取的信息:
- 数据来源:该数据集由公开监控视频与网络行为数据整理而来,经过筛选和清洗后构建而成,主要用于异常行为识别研究。
- 图片数量:
- 训练集:2291张
- 验证集:540张
- 类别信息:共包含1个类别,即
fight(打架斗殴)。 - 标注格式:每张图片对应一个
.txt标注文件,符合YOLO目标检测的标准格式。 - 可用性验证:该数据集已实际测试可用于YOLOv8s模型训练,实测 mAP@50 达到 86.3%,表明其具有较高的可用性和检测精度。
所有数据无需额外处理即可直接用于模型训练,极大提升了开发效率。


(2) 数据集处理
在原始图像收集完成后,我们采用 LabelMe 工具进行手动标注。LabelMe 是一款开源的图形化图像标注工具,支持多边形、矩形等多种标注方式,适合复杂场景下的目标框标注。
标注流程如下:
- 使用
labelme打开图像; - 使用矩形框选中打架人物区域;
- 设置标签为
fight; - 导出为 JSON 文件。
随后,通过自定义脚本将 LabelMe 生成的 JSON 文件批量转换为 YOLO 支持的文本格式(.txt),每个 .txt 文件内容如下:
class_id center_x center_y width height
其中:
class_id:类别索引(从0开始),此处为0(代表 fight);center_x,center_y:归一化后的边界框中心坐标;width,height:归一化后的边界框宽高。
示例:
0 0.45 0.67 0.23 0.31
这种格式是YOLO系列模型训练所必需的标准输入格式,确保了模型能够正确读取并学习目标位置与类别信息。
模型训练
为了实现高效的打架斗殴行为检测,我们选用当前最先进的 YOLOv8 模型架构,并使用 Ultralytics 提供的官方实现进行训练。
安装 Ultralytics
首先安装 ultralytics 库:
pip install ultralytics
该库封装了YOLOv8的所有功能,包括训练、验证、推理和导出,接口简洁高效。
训练代码编写
创建配置文件 data.yaml,内容如下:
train: /path/to/train/images
val: /path/to/val/imagesnc: 1
names: ['fight']
启动训练命令(Python脚本或CLI均可):
from ultralytics import YOLO# 加载预训练模型
model = YOLO('yolov8s.pt')# 开始训练
results = model.train(data='data.yaml',epochs=100,imgsz=640,batch=16,name='yolov8_fight_detection'
)
超参数设置说明
Ultralytics 在训练过程中允许高度自定义超参数,以下是关键超参数及其含义与推荐取值:
| 超参数 | 取值示例 | 含义说明 |
|---|---|---|
epochs | 100 | 训练轮数,控制模型学习迭代次数 |
batch | 16 | 每批次输入图像数量,影响内存占用与梯度稳定性 |
imgsz | 640 | 输入图像尺寸(H×W),越大细节越丰富但计算量增加 |
optimizer | ‘SGD’ 或 ‘Adam’ | 优化器类型,默认SGD适用于大多数情况 |
lr0 | 0.01 | 初始学习率,过大易震荡,过小收敛慢 |
lrf | 0.01 | 最终学习率与初始学习率的比值(余弦退火) |
momentum | 0.937 | SGD动量因子,提升收敛速度 |
weight_decay | 0.0005 | L2正则化系数,防止过拟合 |
warmup_epochs | 3.0 | 学习率热身阶段的epoch数 |
warmup_momentum | 0.8 | 热身期间使用的动量值 |
box, cls, dfl | 7.5, 0.5, 1.5 | 损失函数中各部分权重(回归、分类、分布焦点损失) |
fl_gamma | 0.0 | Focal Loss gamma 参数,用于难样本挖掘 |
hsv_h, hsv_s, hsv_v | 0.015, 0.7, 0.4 | 图像色调、饱和度、明度增强范围 |
degrees, translate, scale, shear | 0.0, 0.1, 0.5, 0.0 | 数据增强中的几何变换参数 |
这些参数可根据具体任务调整以获得最佳性能。例如,在本项目中由于数据集较小,适当增强了数据增强策略以提高泛化能力。
训练后评估
模型训练完成后,必须对其进行科学评估,以判断其在真实场景中的表现能力。评估不仅能反映模型精度,还能帮助发现潜在问题(如过拟合、漏检等)。
常用评价指标介绍
1. PR曲线(Precision-Recall Curve)
PR曲线描述的是精确率(Precision) 与 召回率(Recall) 之间的关系。
-
Precision(精确率):预测为正类中确实是正类的比例
P=TPTP+FPP = \frac{TP}{TP + FP} P=TP+FPTP -
Recall(召回率):真实正类中被正确预测的比例
R=TPTP+FNR = \frac{TP}{TP + FN} R=TP+FNTP
其中:
- TP:真正例(正确检测出打架)
- FP:假正例(误报为打架)
- FN:假反例(未检测出打架)
PR曲线越靠近右上角,说明模型性能越好。
2. mAP(mean Average Precision)
mAP 是目标检测中最核心的综合评价指标,表示各类别AP的平均值。对于单类别(fight),mAP 就等于 AP。
- AP:PR曲线下面积(AUC),通常在不同IoU阈值下计算,如:
- mAP@0.5:IoU阈值为0.5时的AP
- mAP@0.5:0.95:多个IoU阈值(0.5~0.95步进0.05)下的平均AP
数学表达式为:
AP=∫01P(R)dRAP = \int_0^1 P(R) \, dR AP=∫01P(R)dR
实际中通过插值法近似计算。
本项目中,YOLOv8s 模型在验证集上达到了 mAP@50 = 86.3%,表明模型具备较强的打架行为识别能力。

模型推理
完成训练后,使用训练好的模型对新图像和视频进行推理。以下为基于 ultralytics 的推理代码实现。
图片推理
from ultralytics import YOLO
from PIL import Image# 加载模型
model = YOLO('runs/detect/yolov8_fight_detection/weights/best.pt')# 加载图像
image = Image.open('test.jpg')# 推理
results = model.predict(source=image, conf=0.25, iou=0.45)# 可视化结果
annotated_img = results[0].plot()
annotated_img = Image.fromarray(annotated_img[:, :, ::-1]) # BGR to RGB
annotated_img.show()
视频推理
# 推理视频
results = model.predict(source='input_video.mp4',conf=0.25,iou=0.45,save=True, # 保存结果视频project='output/',name='fight_result'
)
上述代码会自动输出带检测框的结果视频,便于后续分析。
系统UI设计
本系统采用 Streamlit 框架搭建交互式Web界面,极大简化了前端开发流程,使开发者可以专注于算法逻辑。
Streamlit 框架优点
- 简单易用:纯Python编写,无需HTML/CSS/JS知识;
- 快速部署:一行命令
streamlit run app.py即可启动本地服务; - 组件丰富:提供按钮、滑块、文件上传、视频播放等UI控件;
- 实时渲染:支持动态更新页面内容,适合AI推理展示;
- 响应式布局:适配PC与移动端浏览。
结合代码说明UI实现
根据提供的源码,系统主要结构如下:
st.set_page_config(page_title="基于YOLO8的打架斗殴检测系统", layout="centered")
设置网页标题和居中布局。
登录注册模块
系统加入简单的身份认证机制:
- 用户需先注册账号;
- 登录后进入主界面;
- 区分“管理员”与“游客”权限(管理员可查看详细检测表格)。
配置面板(侧边栏)
model_type = st.sidebar.selectbox("选取模型", MODEL_LIST)
confidence = st.sidebar.slider("调整置信度", 10, 100, 25) / 100
iou = st.sidebar.slider("调整iou", 10, 100, 45) / 100
source = st.sidebar.radio('检测类型', ['图片检测', '视频检测', '本地摄像头检测'])
用户可通过滑块调节置信度与IoU阈值,灵活控制检测灵敏度。
多模式检测支持
- 图片检测:上传图片 → 显示原图与检测结果 → 输出检测详情表;
- 视频检测:上传MP4文件 → 实时逐帧推理 → 页面动态刷新检测画面;
- 摄像头检测:调用本地摄像头(cv2.VideoCapture(0))→ 实时流式检测。
所有结果显示均通过 st.image() 和 st.video() 实现,结合OpenCV处理帧图像,流畅展示检测效果。
此外,系统隐藏了Streamlit默认的菜单与页脚:
hide_streamlit_style = """<style>MainMenu {visibility: hidden;}footer {visibility: hidden;}header {visibility: hidden;}</style>"""
st.markdown(hide_streamlit_style, unsafe_allow_html=True)
提升整体视觉专业性。

系统功能
基于所提供的完整代码,本打架斗殴检测系统具备以下核心功能:
-
用户身份管理
- 支持用户注册与登录;
- 分级权限控制(管理员可查看详细数据表格,游客仅能查看结果图像);
-
多模型选择
- 支持加载多种YOLOv8模型(如 yolov8n, yolov8s, yolov8m 等),可在侧边栏自由切换;
-
置信度与IoU阈值调节
- 提供滑块实时调整
conf与iou参数,动态影响检测结果;
- 提供滑块实时调整
-
三种检测模式
- 图片检测:支持上传 JPG/PNG 格式图片,返回标注结果及检测对象统计;
- 视频检测:上传 MP4 视频文件,逐帧推理并实时播放检测画面;
- 摄像头实时检测:调用本地摄像头进行现场行为监控,适用于安防场景;
-
结果可视化与数据输出
- 图像/视频结果叠加边界框与标签;
- 表格形式展示每帧检测的序号、类别、置信度、坐标信息;
- 管理员权限下可编辑查看完整数据表;
-
高性能推理支持
- 基于
ultralytics YOLO实现高效推理; - 支持GPU加速(若环境配置CUDA);
- 视频帧率控制(如每2帧处理一次)以平衡实时性与资源消耗;
- 基于
-
易部署与可扩展性强
- 整体代码结构清晰,模块化设计(
app.py,utils.py,config.py); - 可轻松集成到校园、地铁、监狱等公共安全监控系统中。
- 整体代码结构清晰,模块化设计(
总结
综上所述,本系统成功构建了一套基于YOLOv8的打架斗殴行为智能检测解决方案,实现了从数据准备、模型训练、性能评估到实际部署的全流程闭环。依托YOLOv8在精度与速度上的卓越表现,系统能够在复杂现实场景中准确识别打架行为,具备高mAP@50(达86.3%)的检测能力,并支持多平台实时推理。通过Streamlit搭建的交互式界面,系统提供了友好的用户体验,涵盖身份认证、参数调节、多模态输入(图片、视频、摄像头)等功能,满足不同用户的操作需求。
更重要的是,该系统不仅是一个技术原型,更具备显著的现实应用价值。它有效弥补了传统监控依赖人工的短板,实现了“主动发现、实时预警”的智能化升级,为公共安全管理提供了强有力的技术支撑。未来可进一步拓展至更多异常行为识别场景(如跌倒、聚集、持械等),并与报警系统、调度平台联动,形成完整的智能安防生态。本项目的实施标志着AI在社会治理领域的深度渗透,也为构建更安全、更智慧的城市环境提供了可行路径。
另外,限于本篇文章的篇幅,无法一一细致讲解系统原理、项目代码、模型训练等细节,需要数据集、项目源码、训练代码、系统原理说明文章的小伙伴可以从下面的链接中下载:
YOLO8打架斗殴行为检测系统