Kafka实时数据管道:ETL在流式处理中的应用
过去,企业数据集成大多采用ETL(提取、转换、加载)批处理模式,即在夜间或业务低峰期将数据从业务库同步到数据仓库。然而,在数字化转型的浪潮下,实时推荐、实时风控、实时监控等场景要求数据能在秒级甚至毫秒级内得到处理和分析。
ETLCloud作为一个专业的数据集成平台,提供了强大的实时数据集成与ETL处理能力,能够高效采集业务系统的增量数据并进行实时转换。然而,在实际应用中,任何处理平台都会面临资源(如内存、CPU)的物理限制。如果在某一时刻,涌入的数据流量远远超过平台的处理能力,就可能导致数据处理延迟、数据积压,甚至在极端情况下影响系统稳定性。
为了解决这一问题,我们通常引入Apache Kafka作为分布式流处理平台的典范,以其高吞吐、可持久化、多订阅者的特性,将其作为实时数据管道的“中枢神经系统”和缓冲层。具体流程如下:
-
首先将产生的流数据可靠地推送至Kafka集群。Kafka的高吞吐和持久化特性确保了数据在涌入高峰时也不会丢失。
-
其次,由ETLCloud等处理平台以自身最优的处理速度从Kafka中消费数据。Kafka的解耦特性允许处理平台根据自身能力平稳消费,避免了被数据洪峰冲垮的风险。
-
最后,这种“生产者-Kafka-消费者”的架构,通过将数据存储与数据处理分离,不仅显著提升了系统的弹性和容错能力,更是实现了系统间解耦,为保障端到端的数据一致性提供了坚实的基础。
那么本文将对这一场景进行示例配置。
一、ETLCloud数据源配置
这里我们要配置四个数据源,分别是
源端数据库:产生增量流数据;
Kafka生产者:将流数据推送到Kafka主题;
Kafka消费者:消费推送到Kafka主题的消息;
目标端数据库:将消费到的消息进行处理推送到目标库;
来到ETLCLoud平台首页,进入数据源管理模块。
首先我们来创建Kafka的数据源
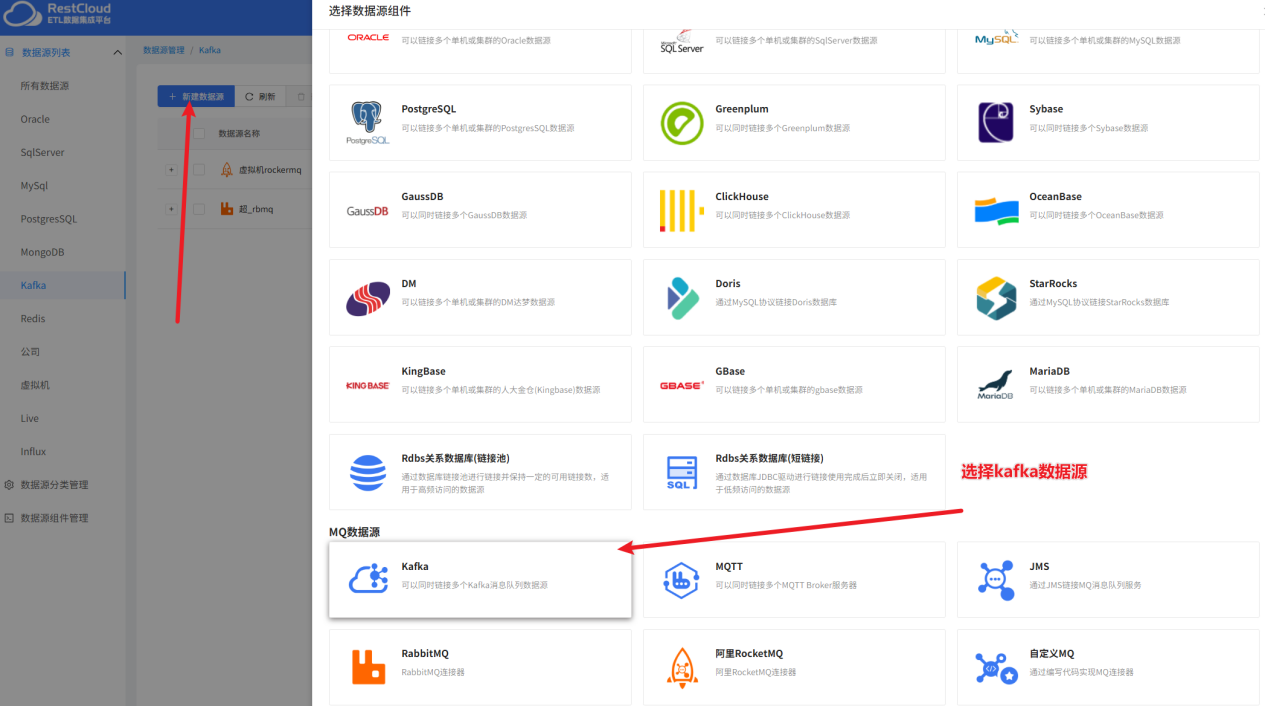
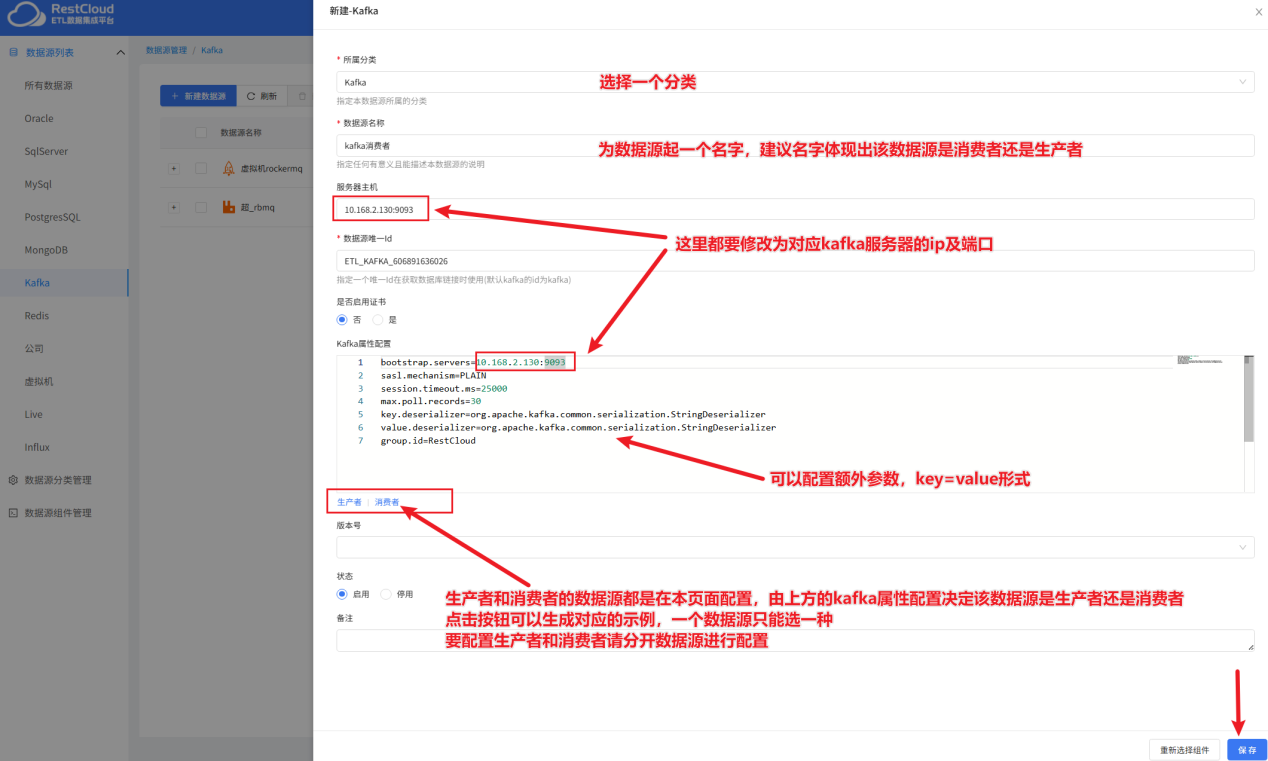
注意,一个Kafka的数据源只能在属性这里选择是生产者和消费者其中一种属性进行配置,所以我们要配置两个Kafka数据源,一个消费者,一个生产者
消费者配置示例:
生产者配置示例:
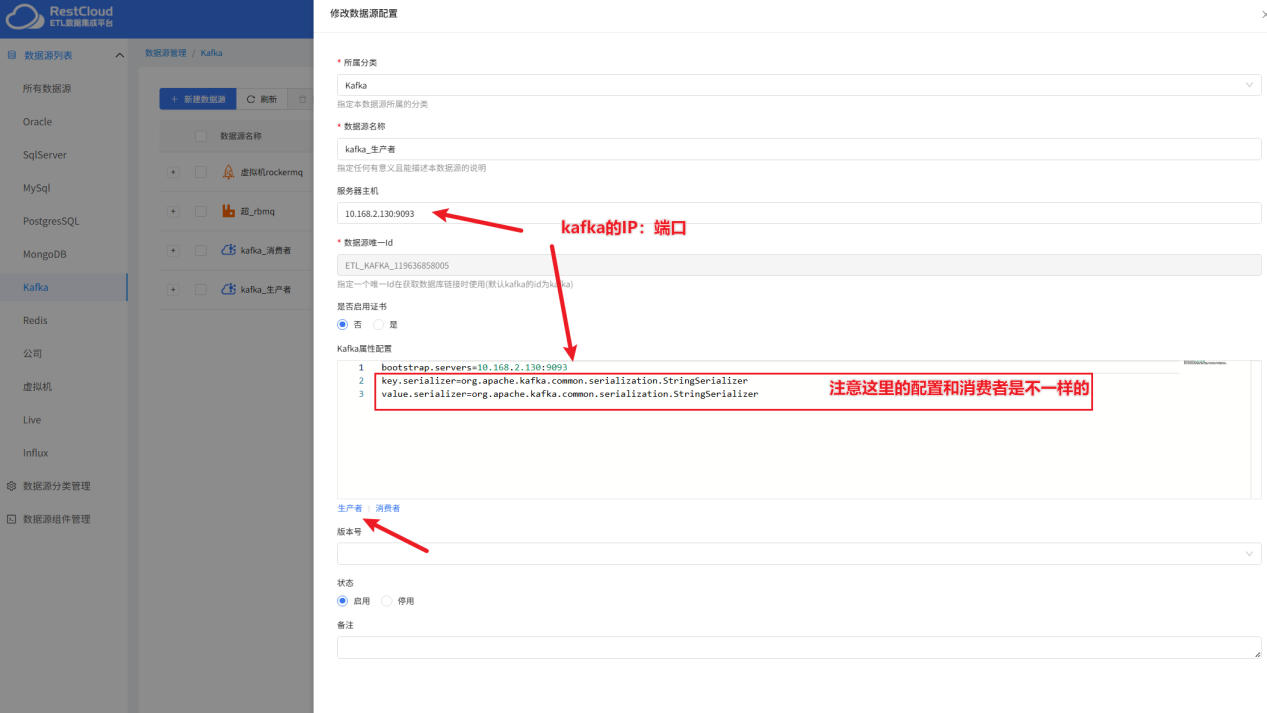
配置完了Kafka的数据源接下来配置源端和目标端的数据源,这里源端MySql产生增量流数据,最后将数据推送到PostgreSql中去
mysql数据源配置:
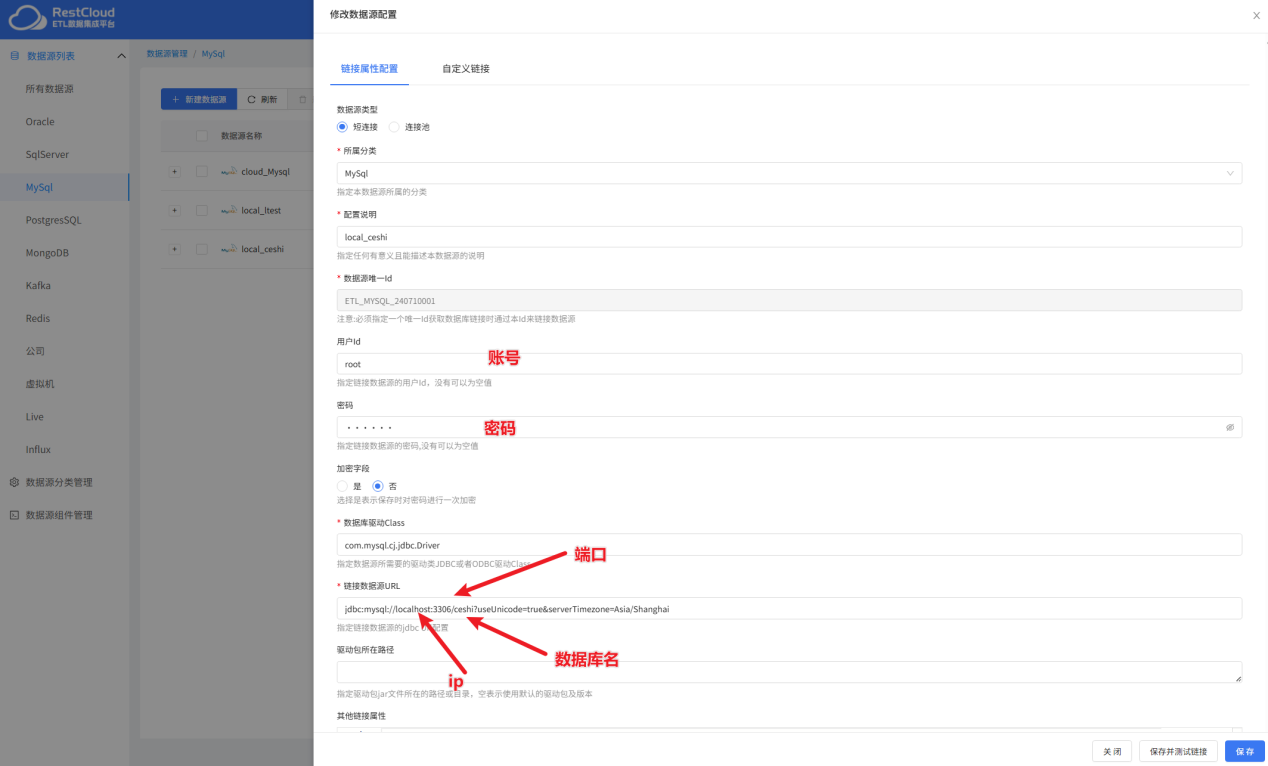
PostgreSql数据源:
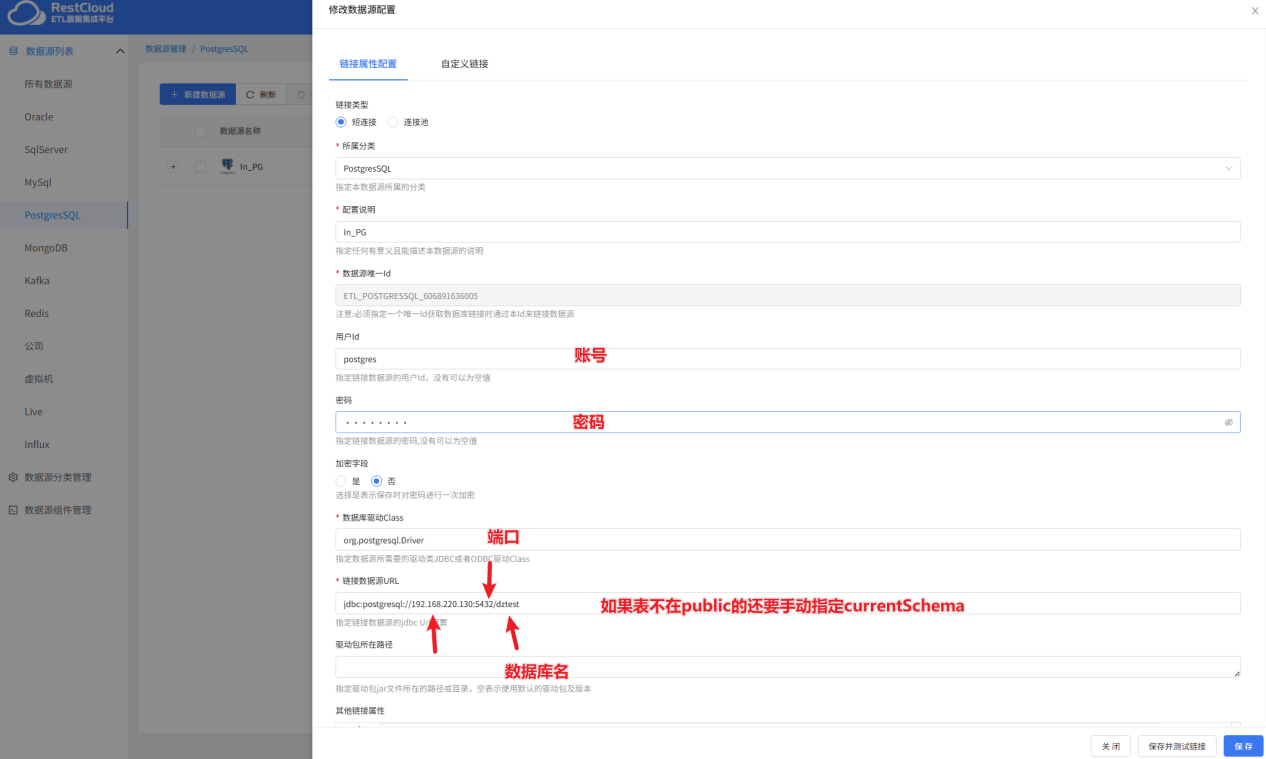
二、配置数据库监听器
配置完了数据源,接下来配置数据库监听器,数据库监听器的作用是监听源端的数据变更,捕获到数据变更推送到后续流程。
来到实时数据集成模块,新建监听器:
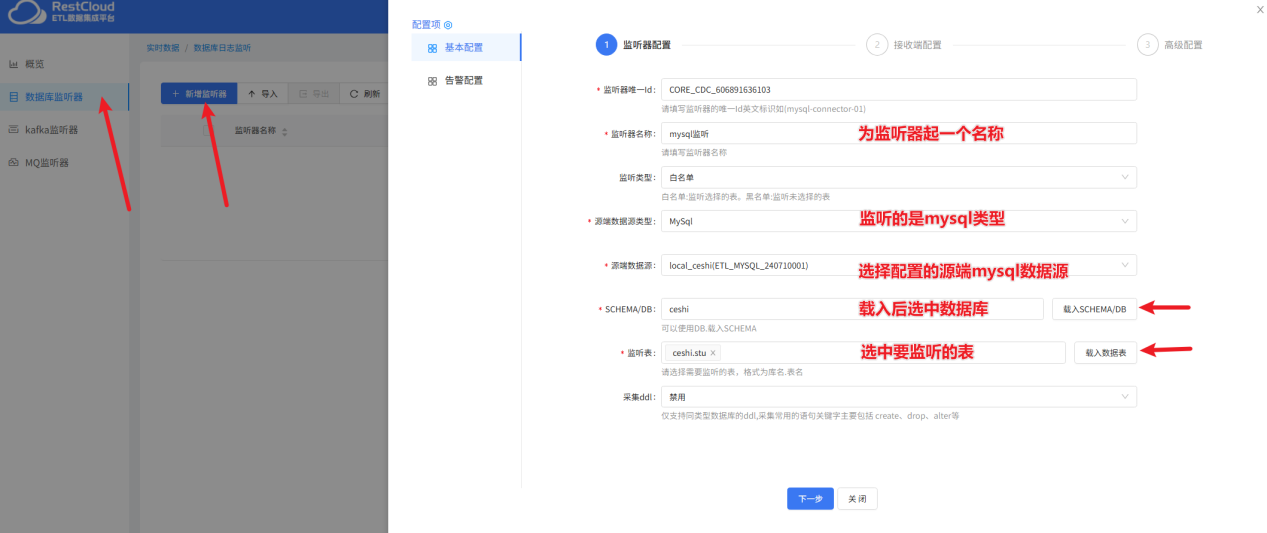
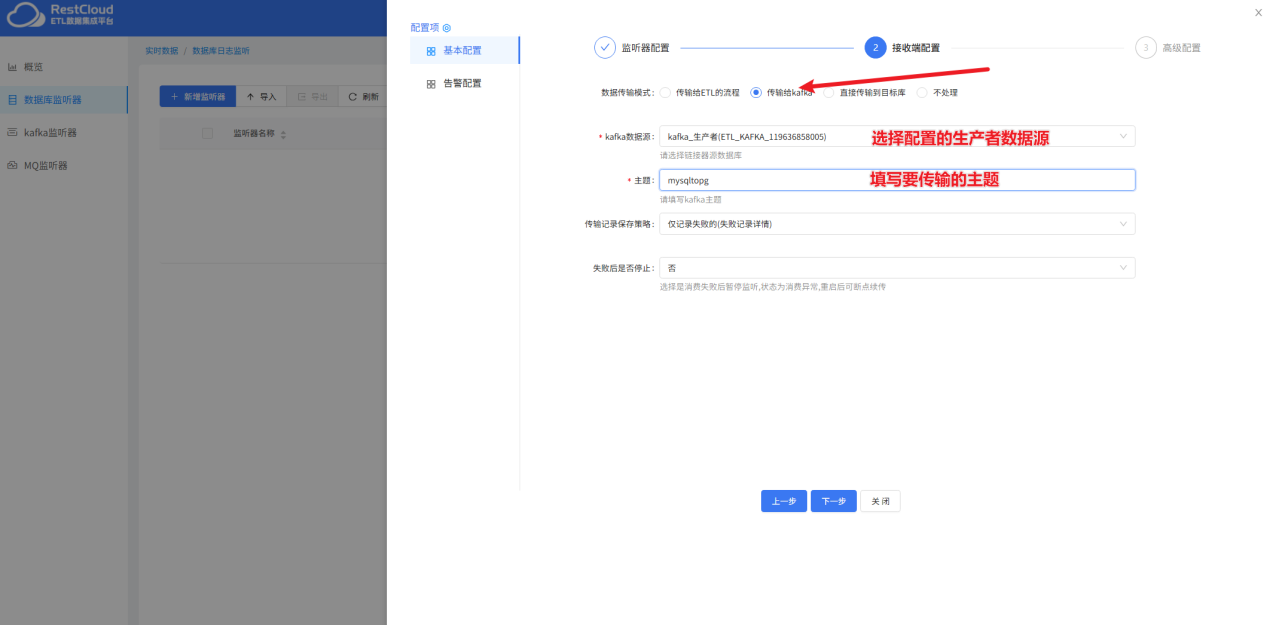
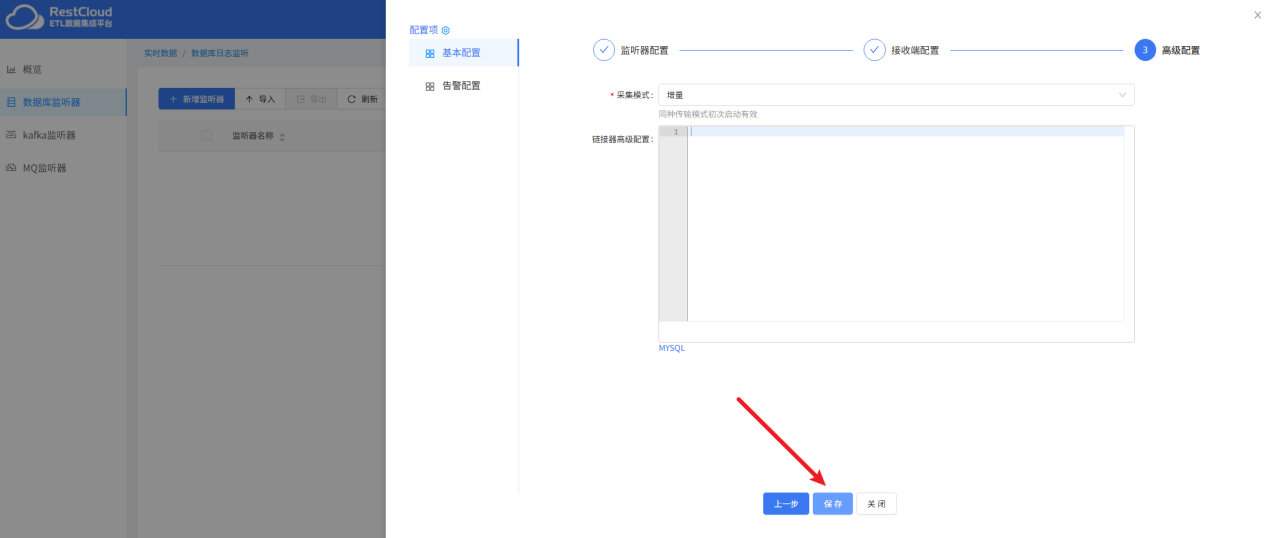
三、配置Kafka消息处理流程
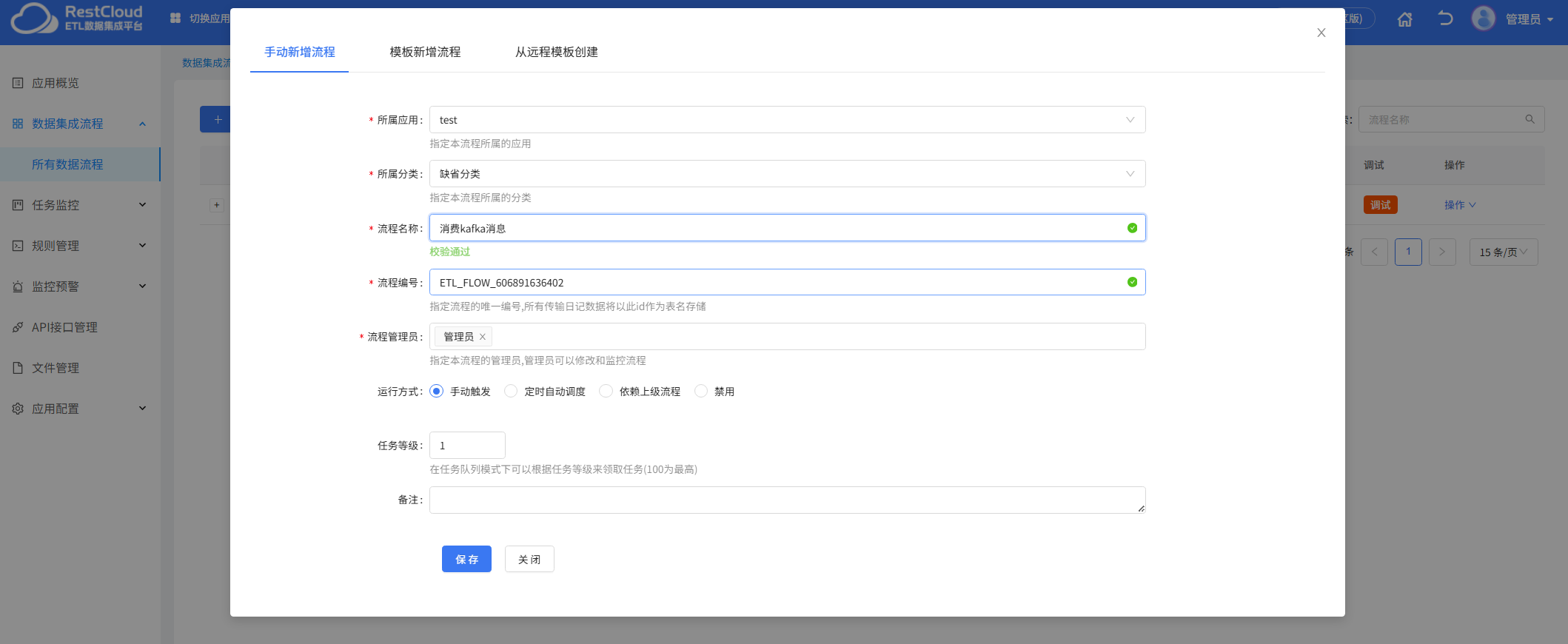
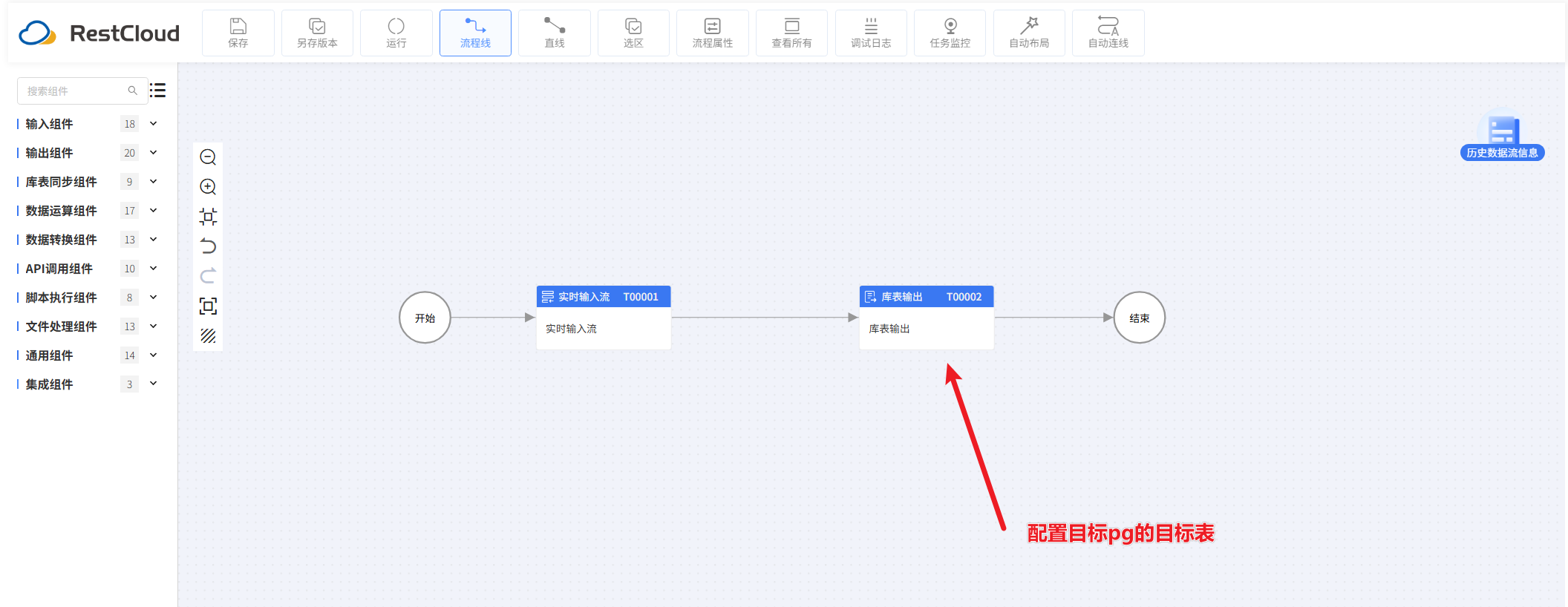
首先来到离线数据集成模块,先创建一个流程
四、配置Kafka监听器
接着,来到实时数据集成,创建Kafka监听器
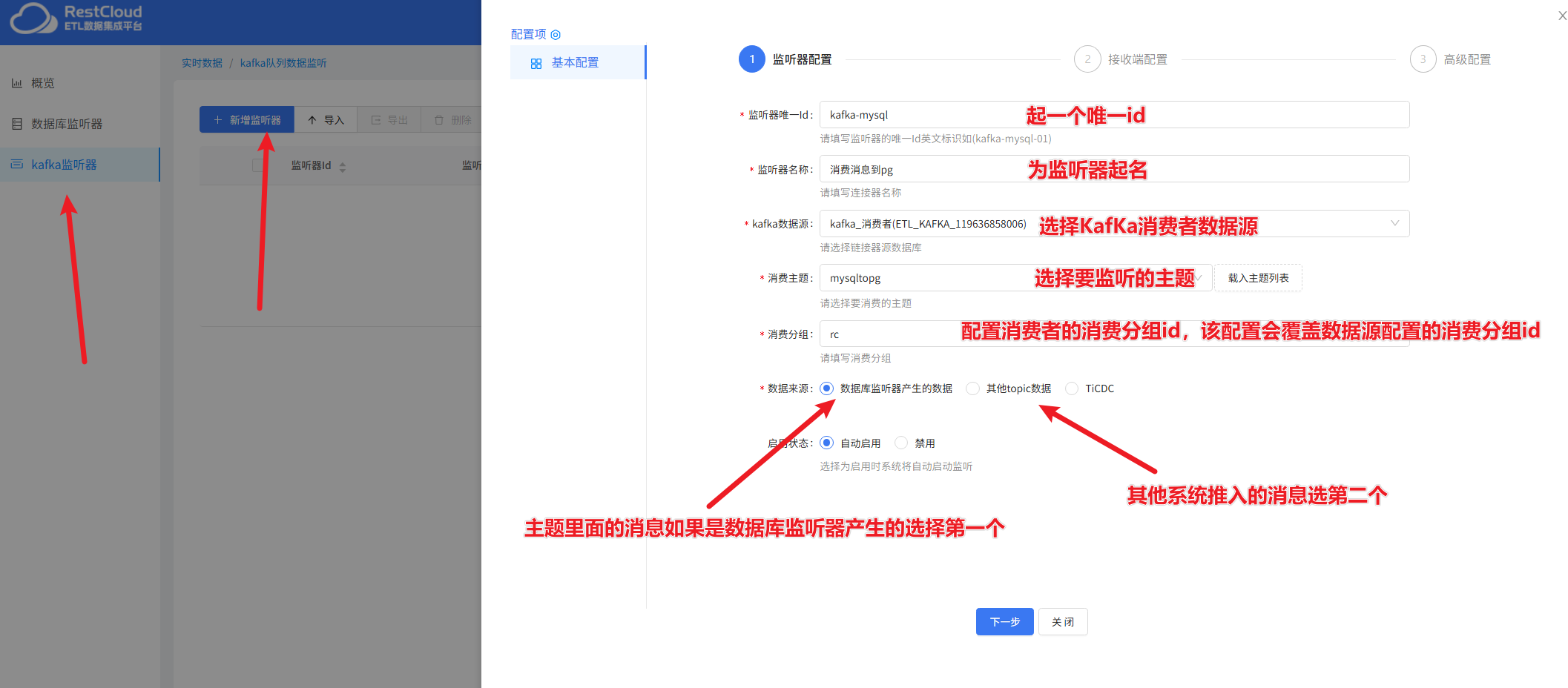
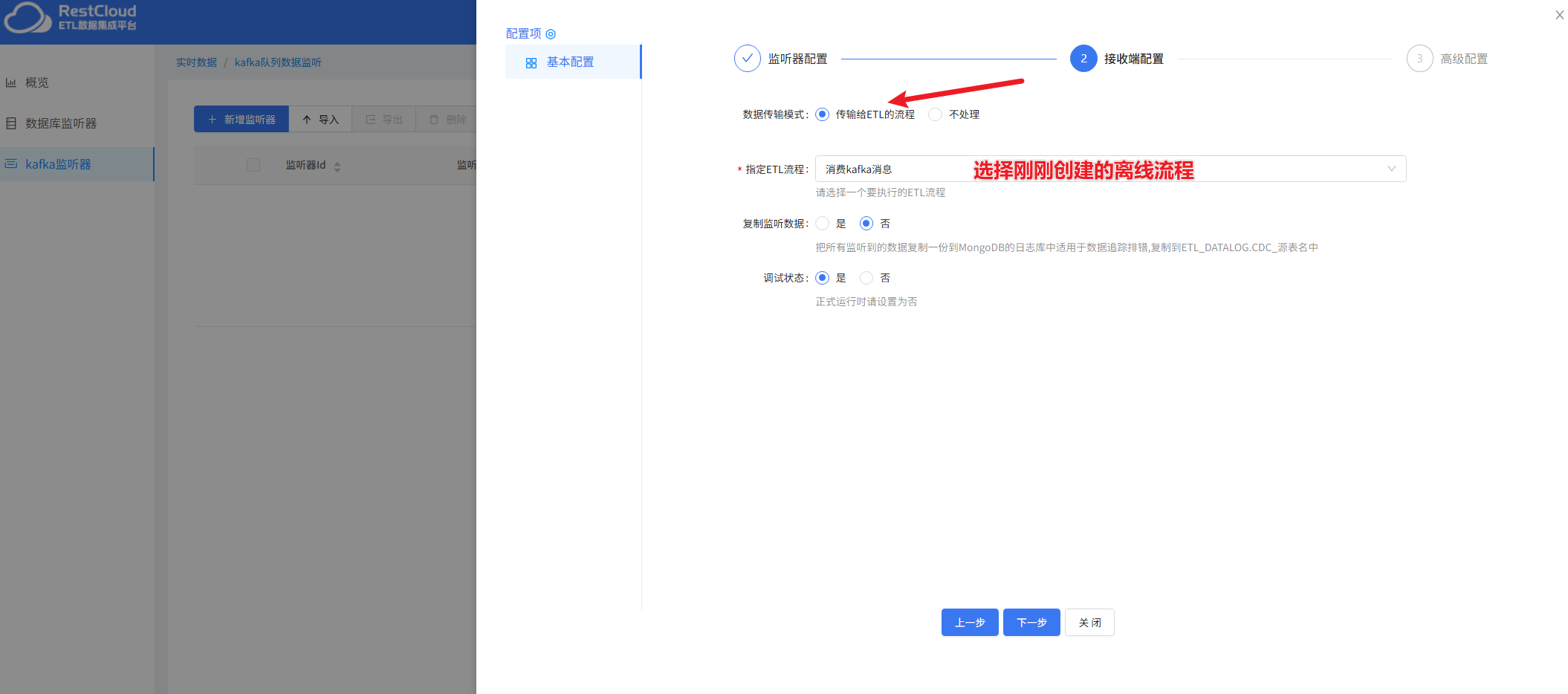
保存后,启动Kafka监听器后启动数据库监听器
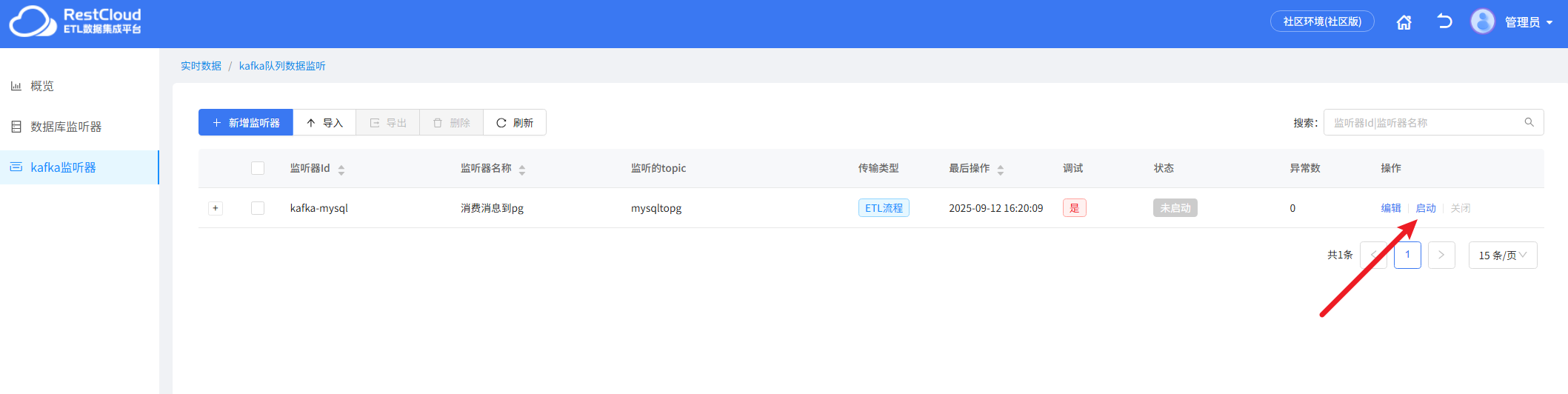

监听器会监听源端mysql表的数据推送到Kafka中去

五、运行
源端插入10条数据
数据库监听器里面监听到数据并往Kafka里面推送
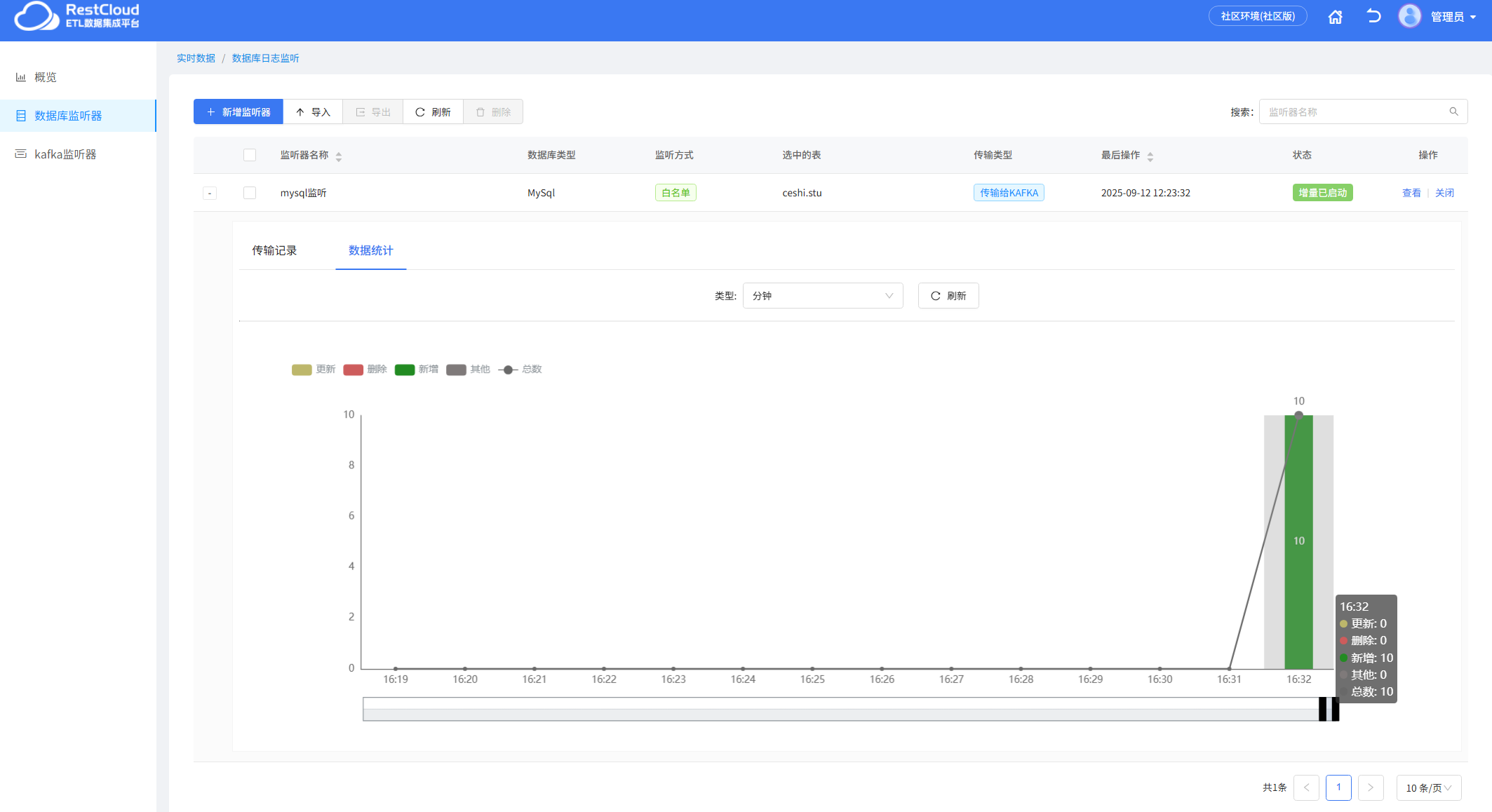
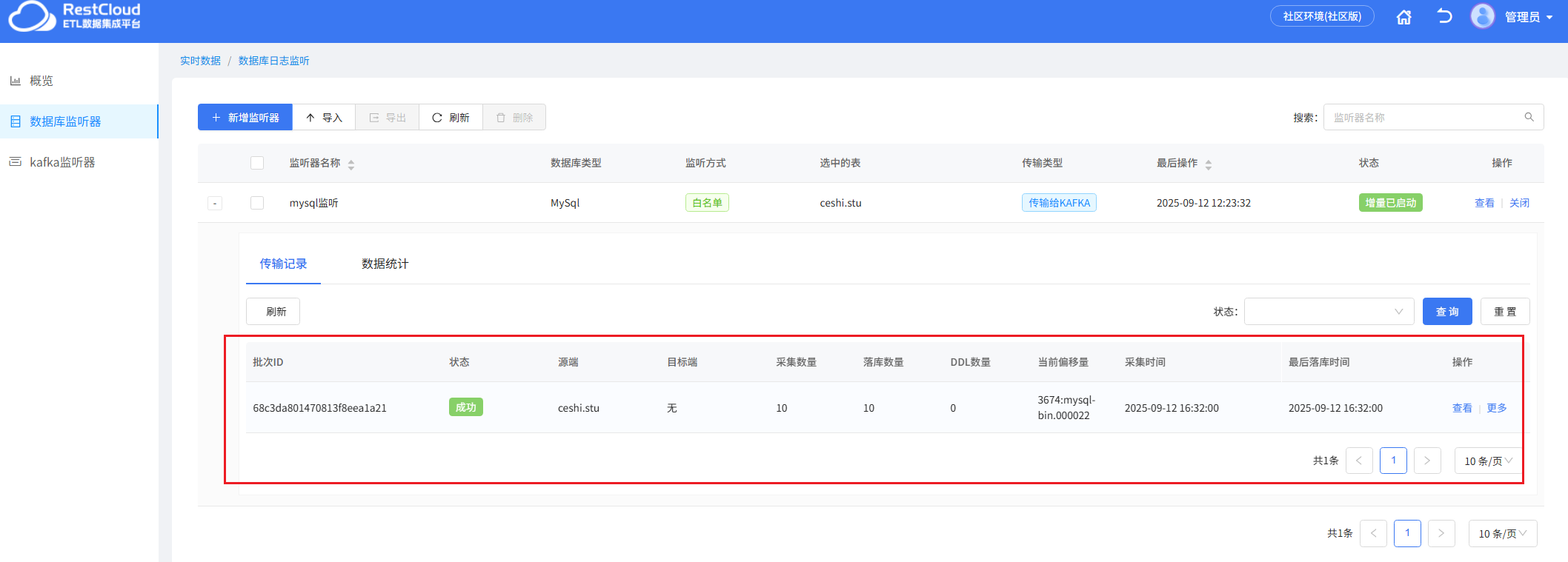
数据成功被推到Kafka主题
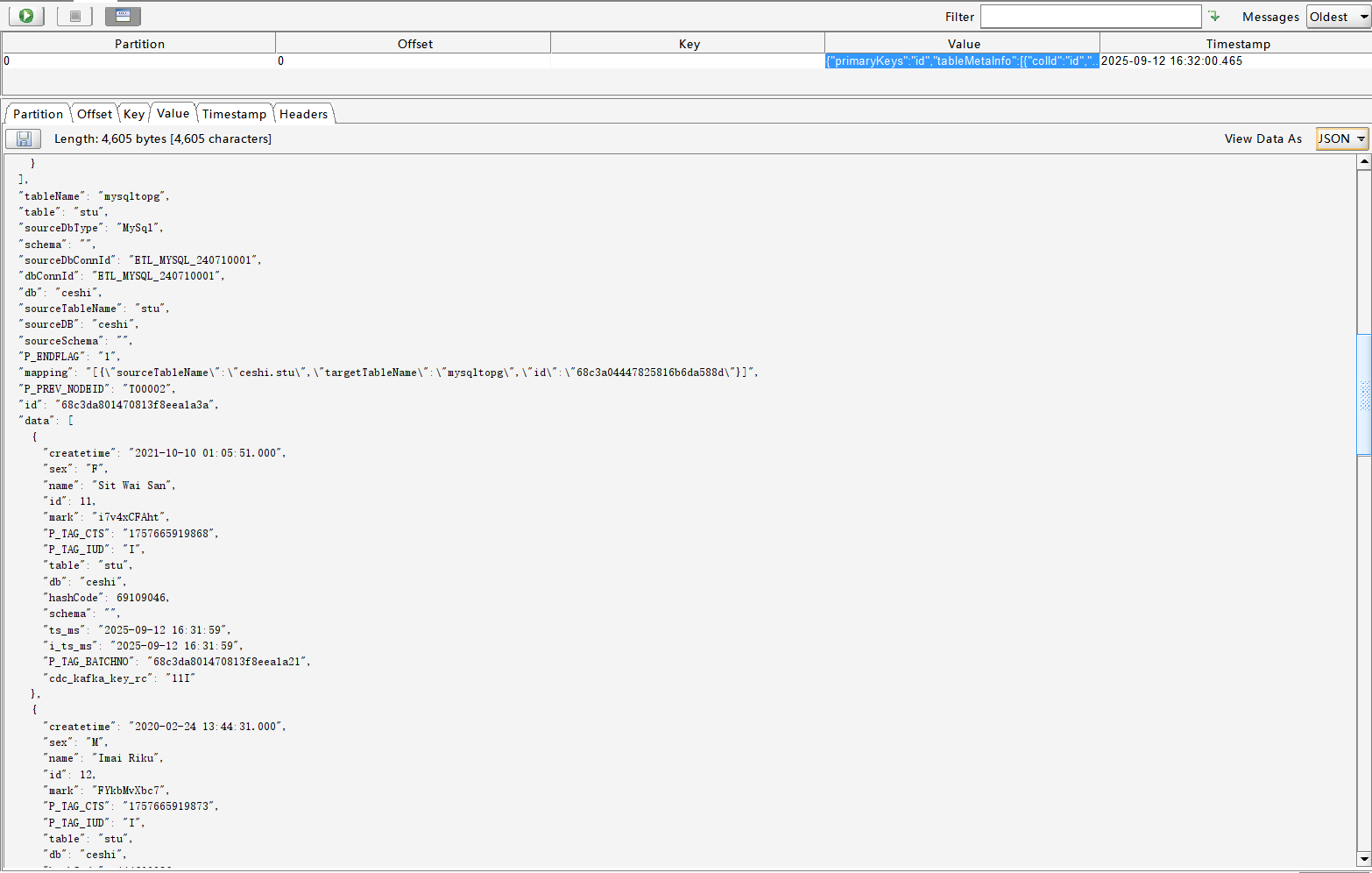
消息推送到主题后,Kafka监听器监听到消息并启动离线流程,在流程中将数据推送到数据库中去
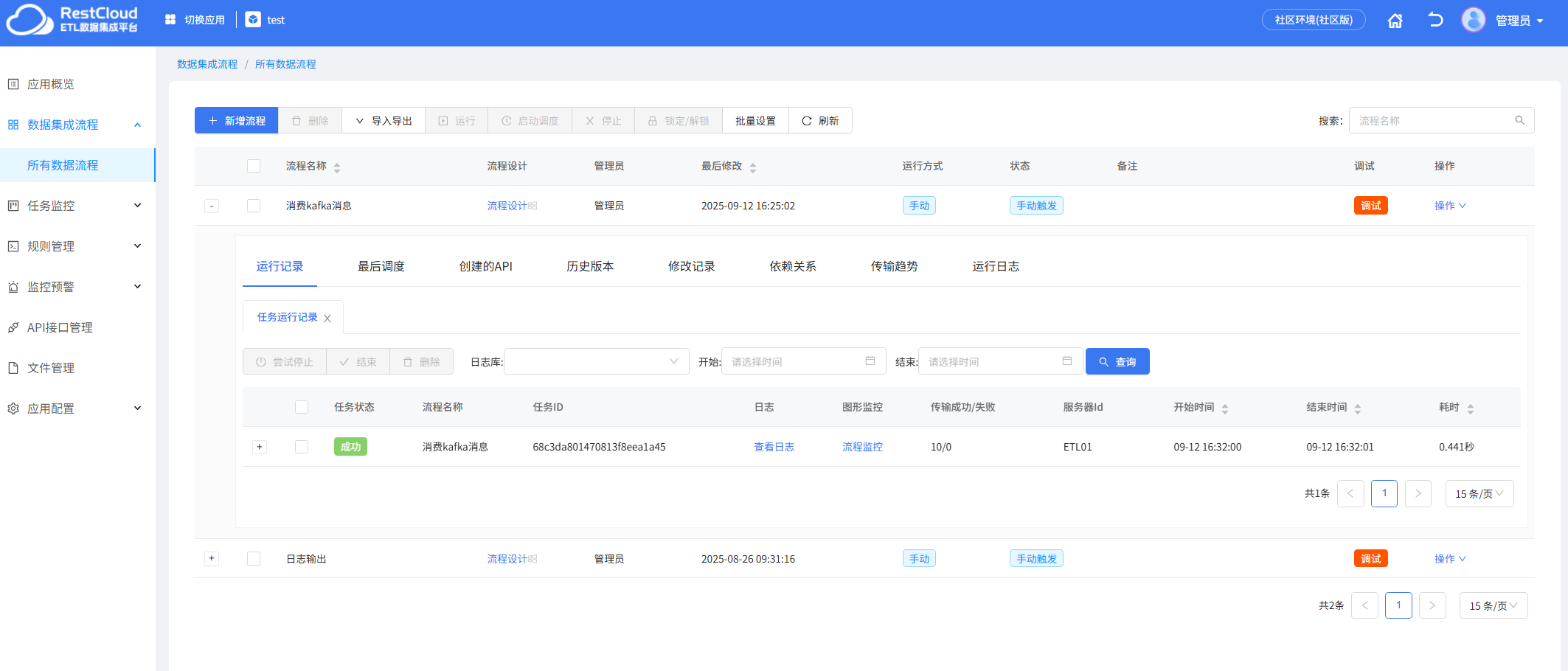
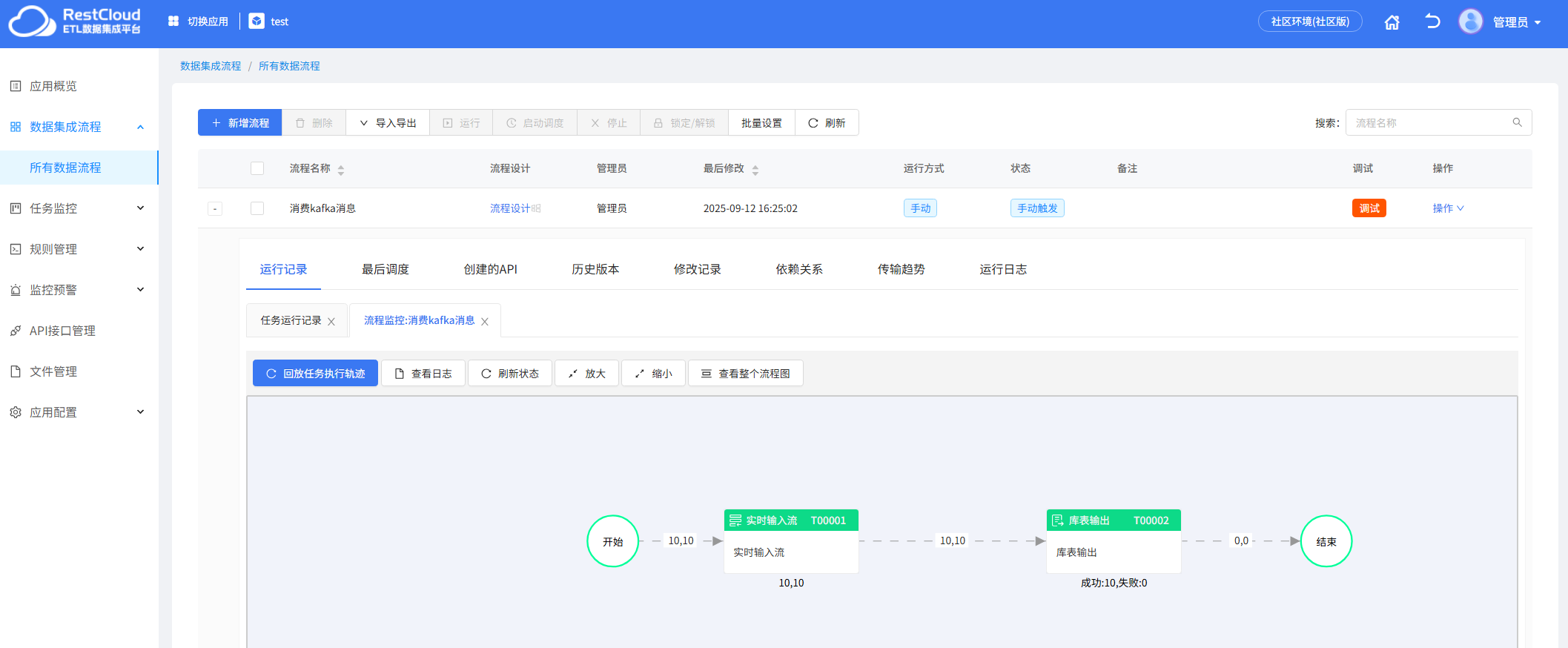
检查数据库,数据成功插入
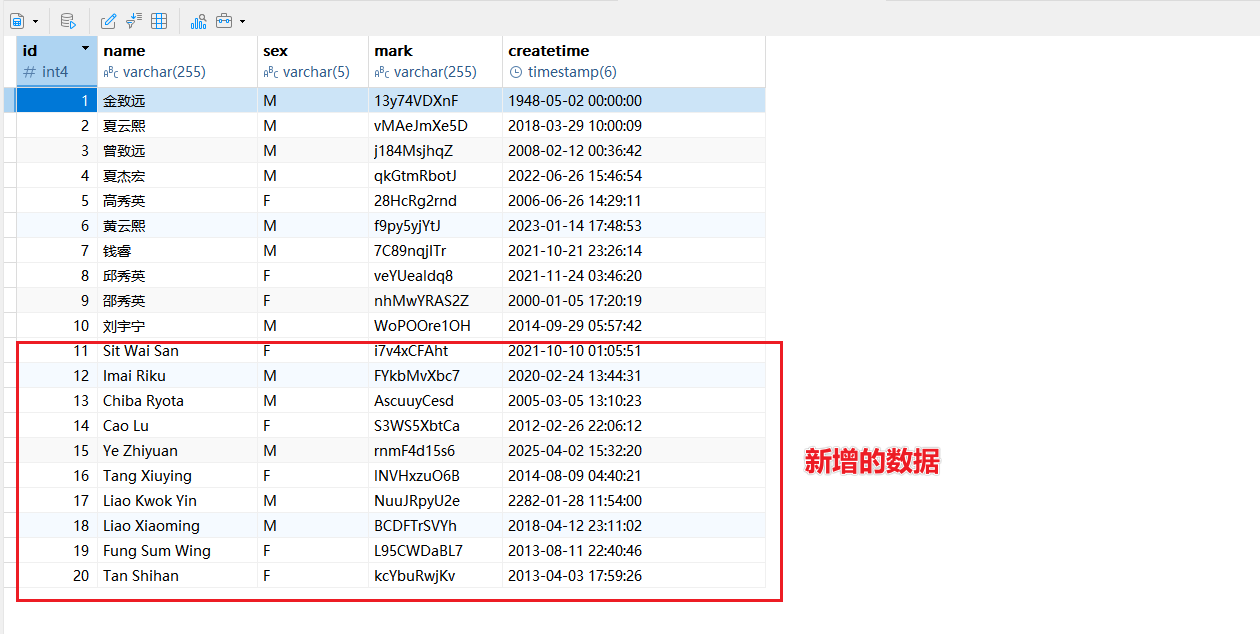
以上便是通过ETLCloud构建Kafka实时数据管道的过程,ETLCloud通过其可视化开发、强大转换能力、多目标支持和企业级可靠性,将流式ETL的复杂技术细节封装起来,让数据工程师和分析师能够更专注于业务逻辑本身,而非底层实现,极大地加速了企业从数据到实时洞察的进程,是构建现代实时数据架构的理想选择。