D005 vue+django音乐推荐大数据|推荐算法|多权限| 可视化|完整源码
文章结尾部分有CSDN官方提供的学长 联系方式名片
up主B站: 麦麦大数据
关注B站,有好处!
编号: D005
视频
D17vue+django 音乐推荐大数据系统源码|协同过滤推荐算法|多角色| mysql | 爬虫|
1 系统简介
系统简介:本系统是一个基于Vue.js和Django框架构建的音乐推荐系统,旨在为用户提供个性化的音乐推荐服务和丰富的音乐数据分析功能。系统包含两大核心角色:管理员和普通用户。管理员主要负责用户管理、歌曲管理、歌手管理以及系统权限管理,而普通用户则可以享受音乐推荐、音乐库浏览、评分、数据可视化分析等功能。系统的数据来源于网易云音乐的爬取,通过UserCF(用户协同过滤)和ItemCF(物品协同过滤)双推荐算法,为用户提供个性化的音乐推荐。同时,系统还提供了丰富的数据可视化功能,包括音乐数据统计、评分分析、发行量展示、歌曲流行趋势(通过面积图表示)、版权分析(通过饼图展示)、音乐热度分析(通过散点图展示)以及歌词词云分析,帮助用户更直观地了解音乐市场动态和流行趋势。此外,用户还可以自行修改个人信息、头像和密码,提升用户体验和系统的个性化性。技术栈上采用Vue.js和Django框架,前后端分离设计,不仅提高了开发效率,也便于系统的扩展和维护。
2 功能设计
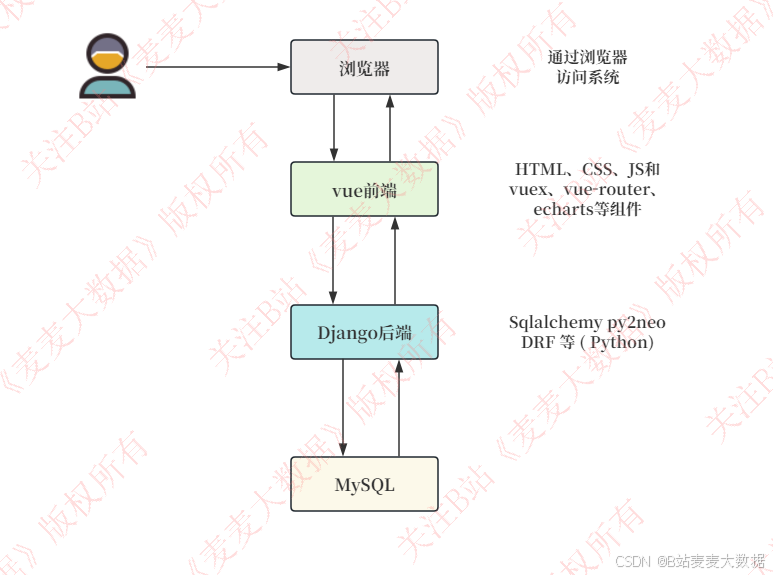
本音乐推荐系统采用经典的前后端分离架构设计,确保系统的高效性、可扩展性和良好的用户体验。用户通过浏览器客户端访问系统,浏览器负责渲染由Vue.js前端提供的用户界面(UI)。前端基于HTML、CSS、JavaScript,并结合Vue.js生态系统中的Vuex进行全局状态管理,Vue Router实现页面路由跳转,Echarts组件用于构建丰富的可视化图表,以直观呈现音乐数据和分析结果。前端通过Ajax异步通信与Django后端交互,后端负责处理业务逻辑,包括音乐推荐算法(UserCF和ItemCF)、数据查询、用户管理、歌曲管理等功能,并通过Django ORM框架与MySQL数据库进行交互,完成数据的持久化存储和管理。系统还包含一个独立的爬虫模块,负责从网易云音乐抓取相关数据并导入数据库,为系统提供数据支撑。此外,系统还提供了完善的用户管理功能,允许用户自行修改头像、个人信息和密码,提升系统的安全性和用户体验。整个系统采用分层设计,模块化程度高,代码耦合度低,便于开发、部署和维护。
2.1系统架构图
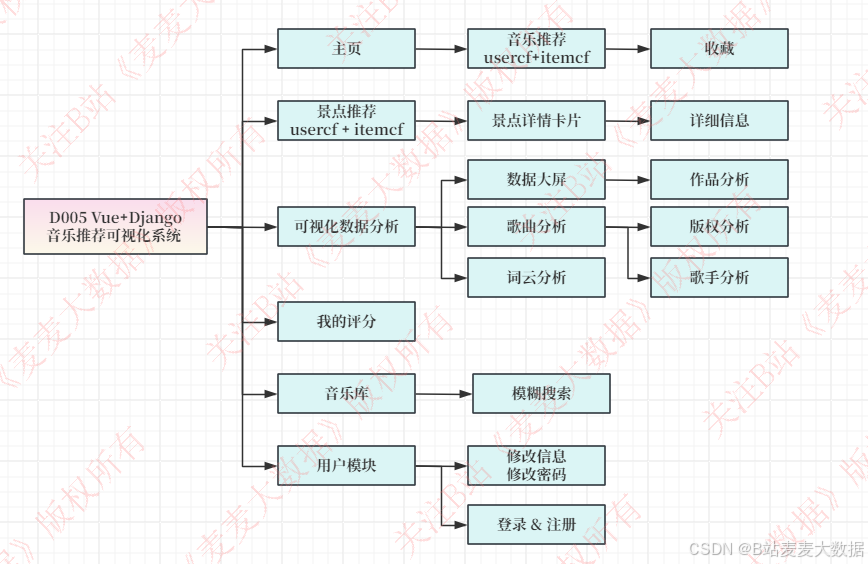
2.2 功能模块图
包含双角色
用户角色:
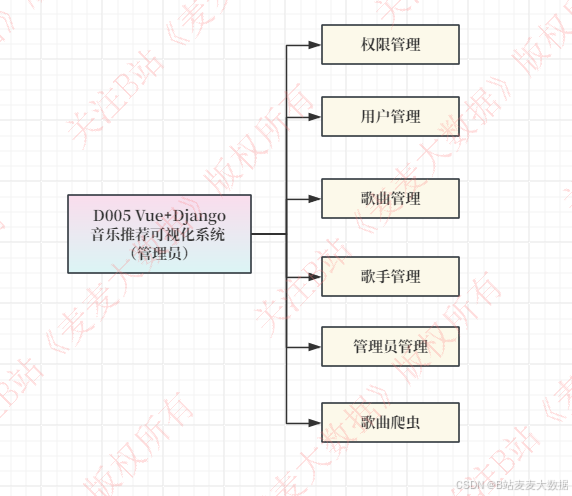
管理员角色:
2.3 文档 1.7字

3 功能展示
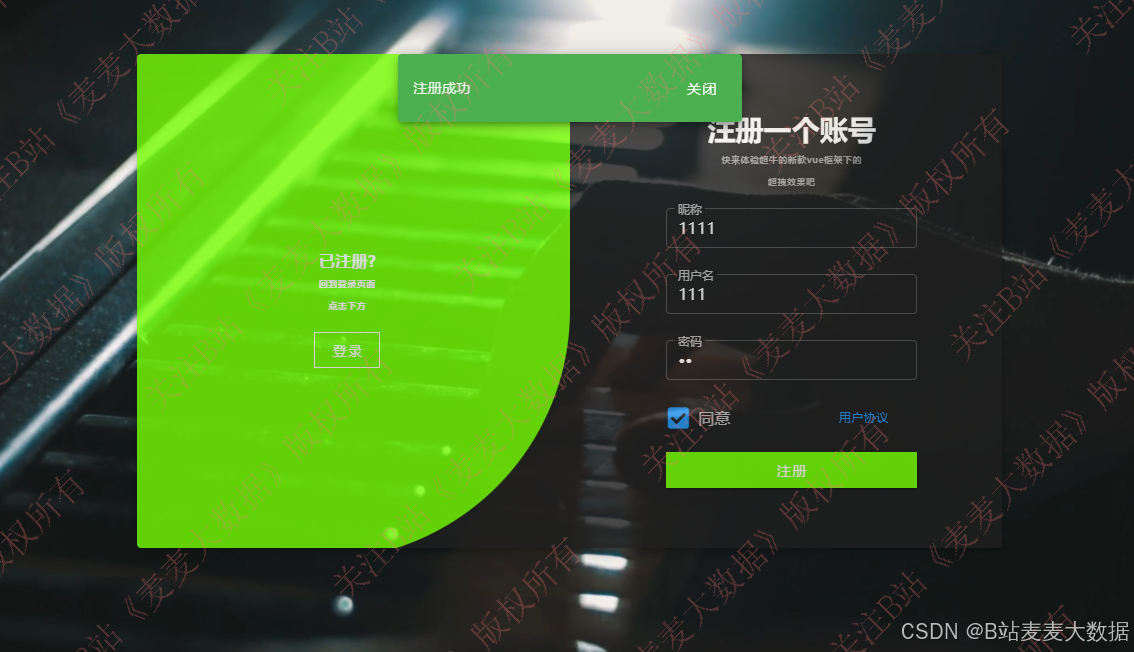
3.1 登录 & 注册
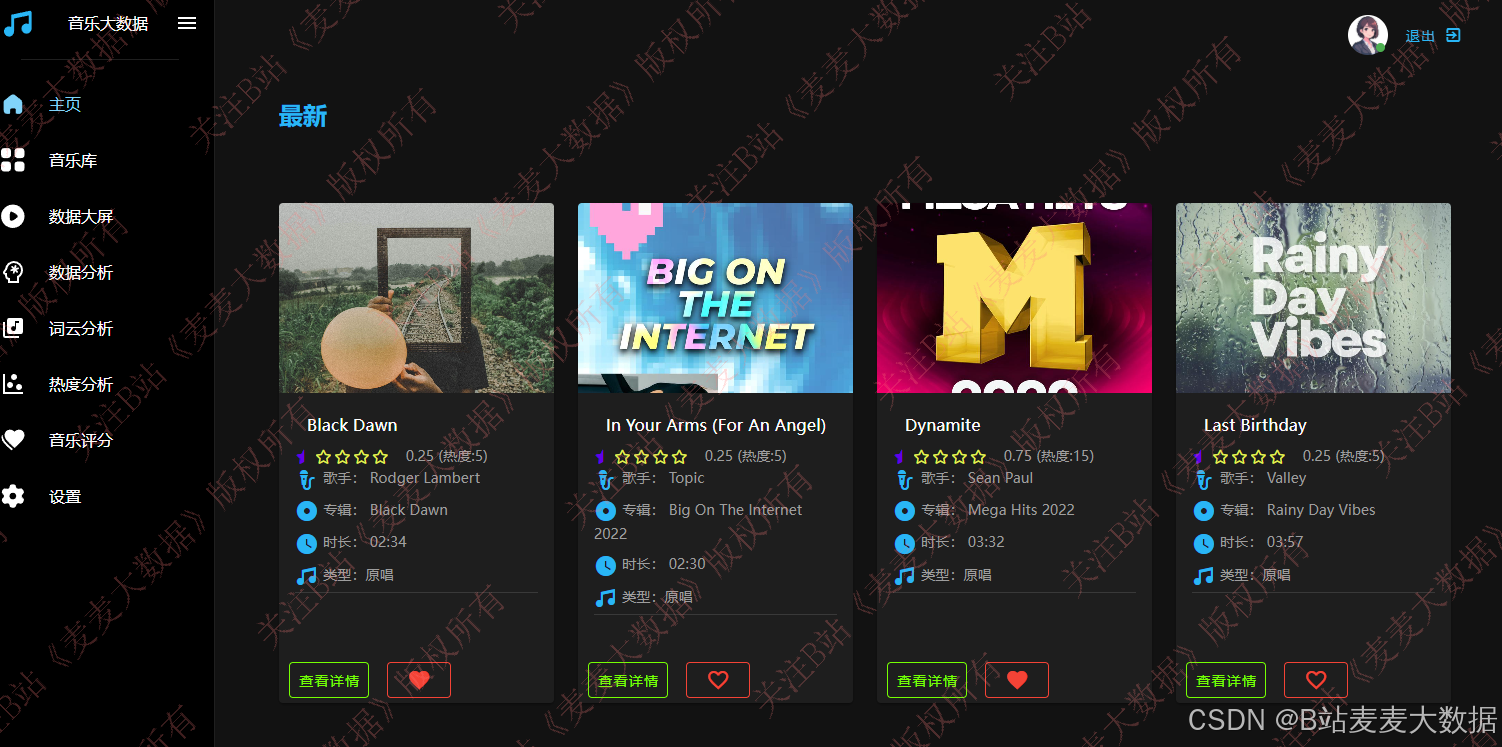
3.2 最新歌曲和推荐算法
最新歌曲:
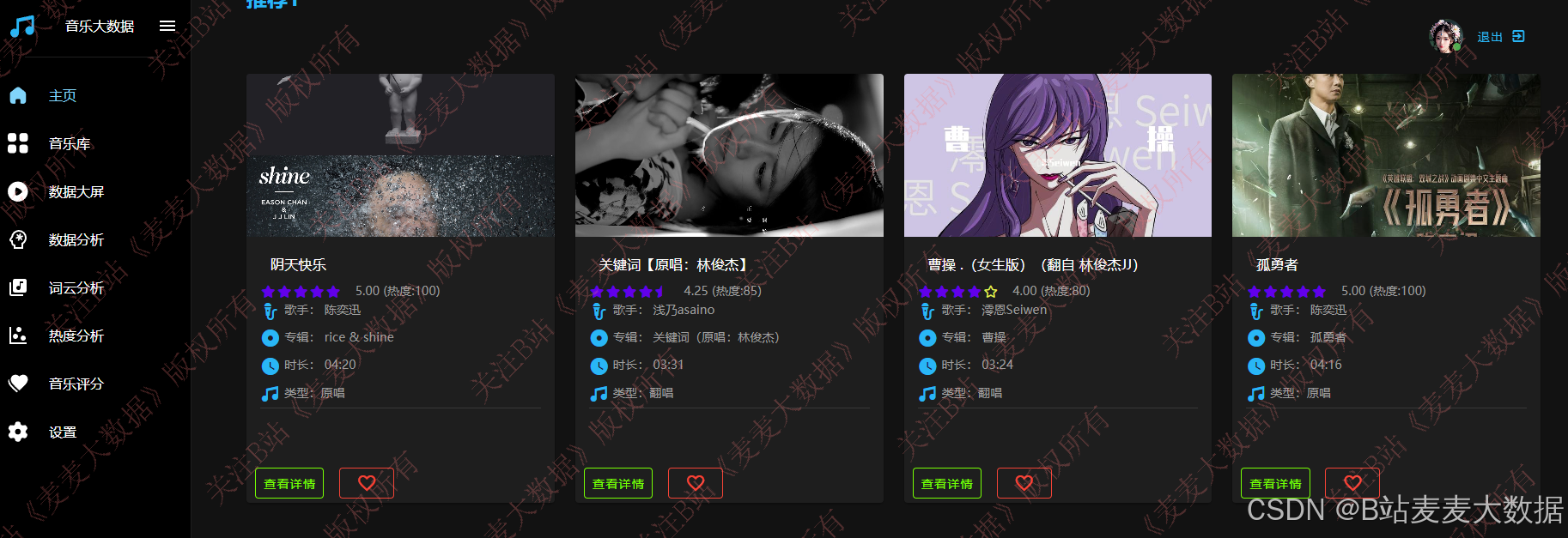
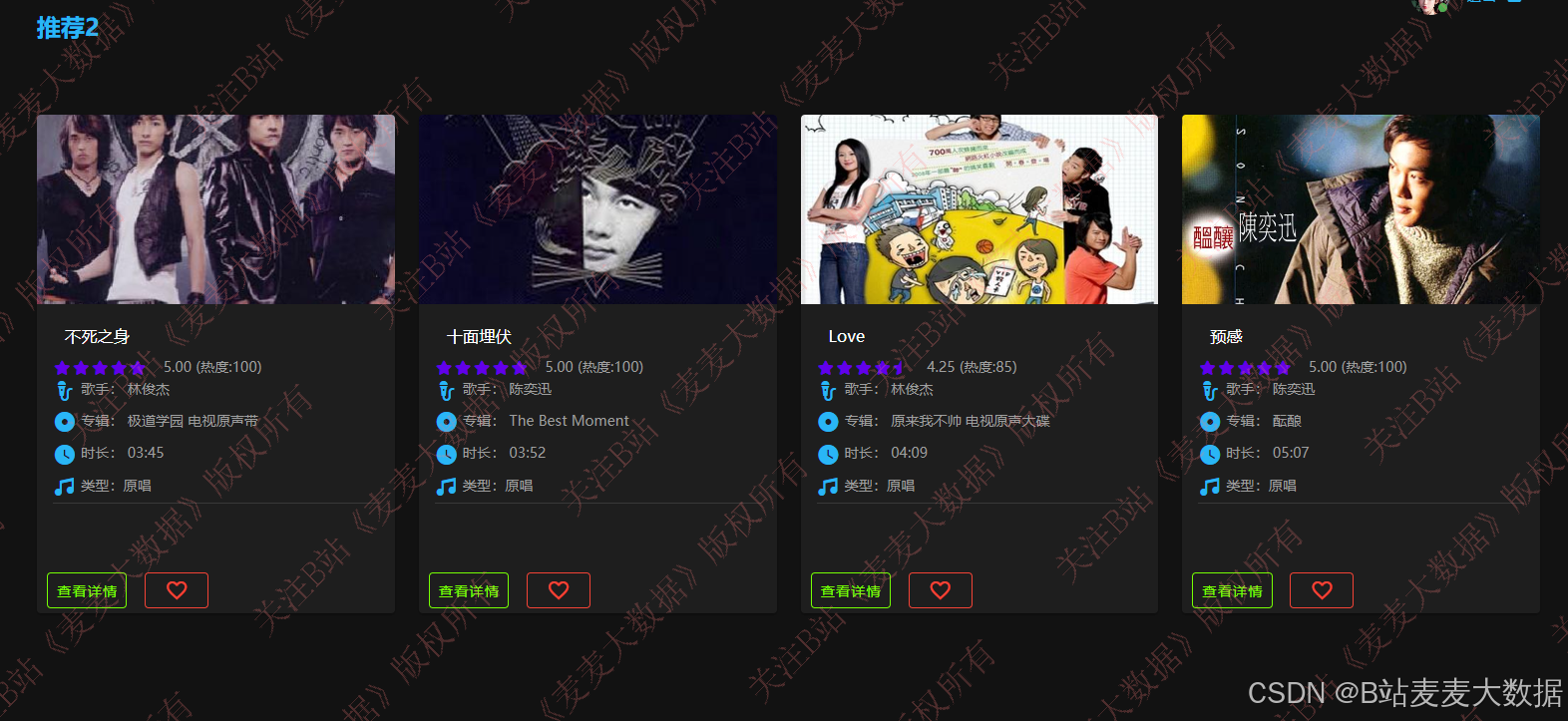
双推荐算法,基于usercf和itemcf双推荐:
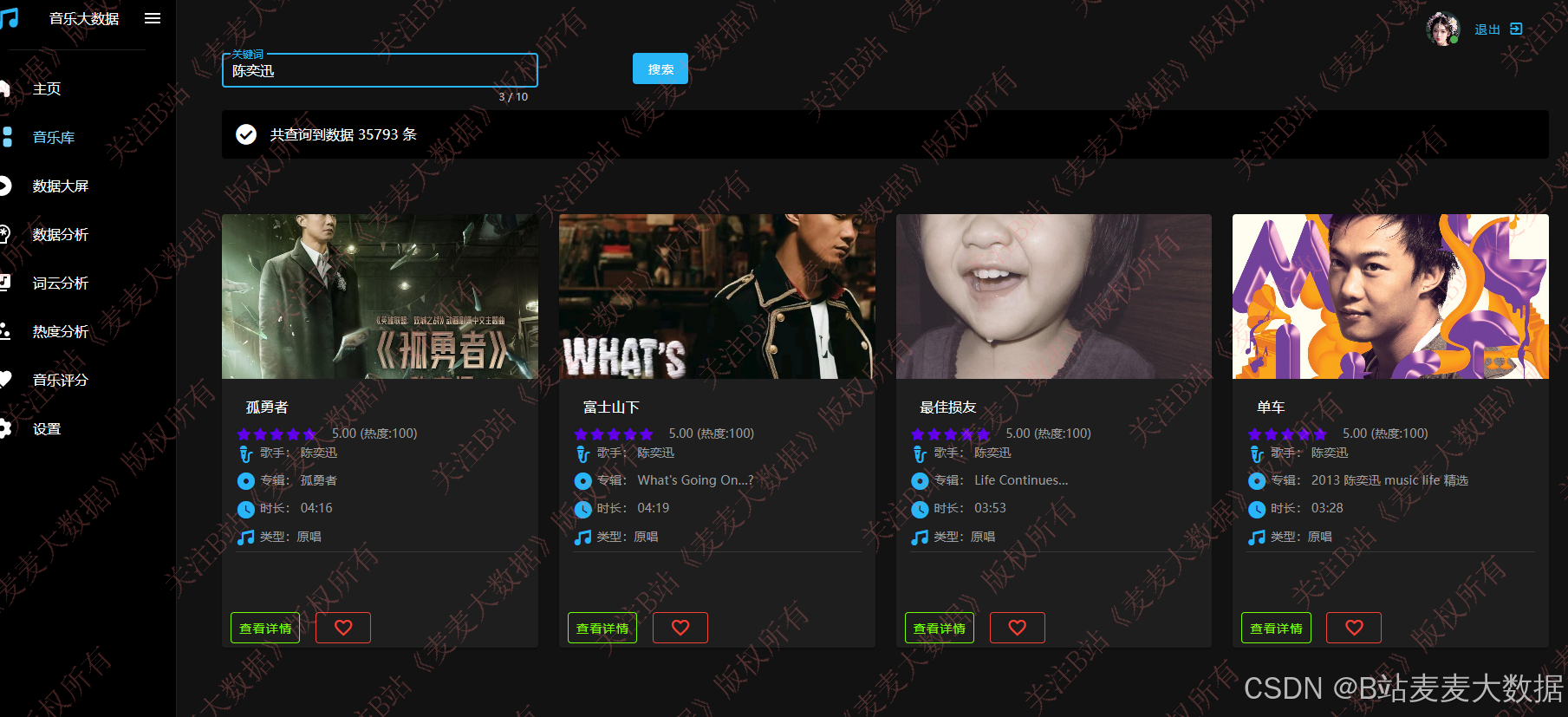
3.3 音乐库
支持模糊搜索:
3.4 数据分析
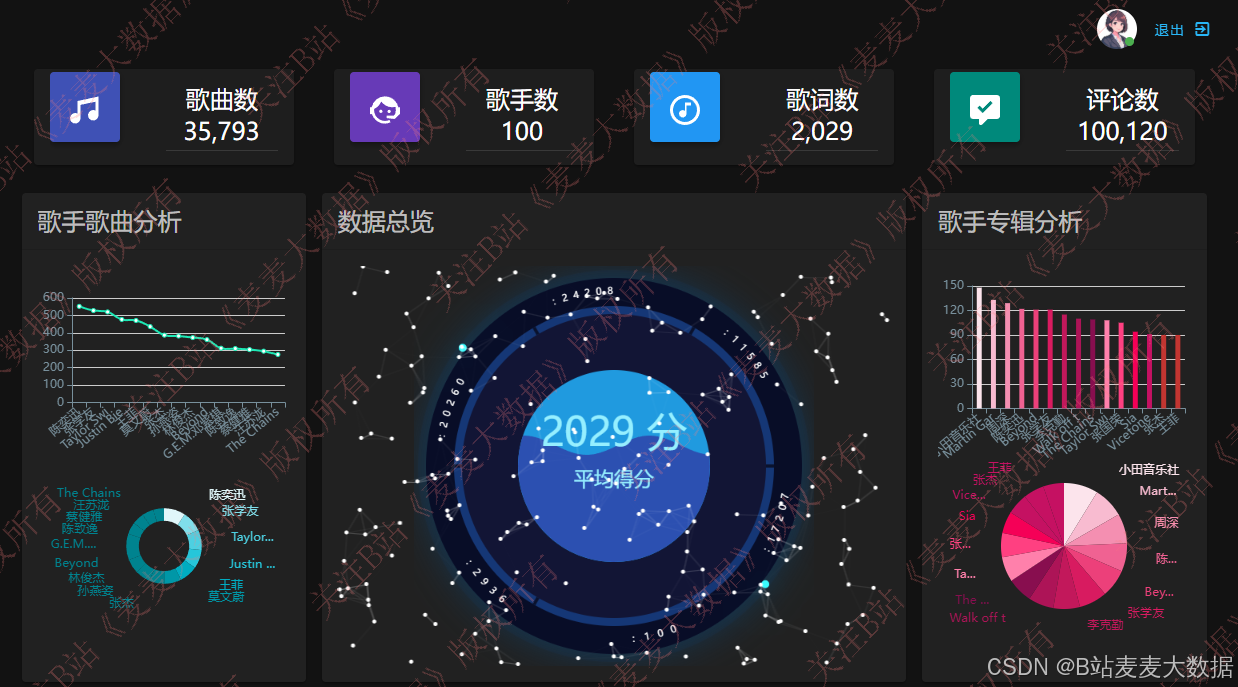
数据统计大屏“:
热度分析:

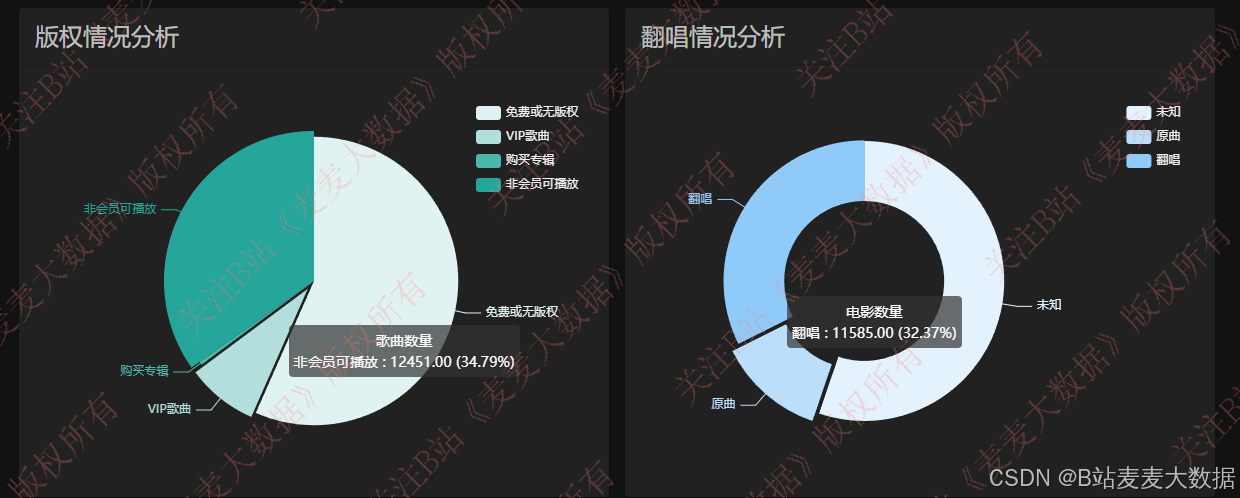
版权分析:
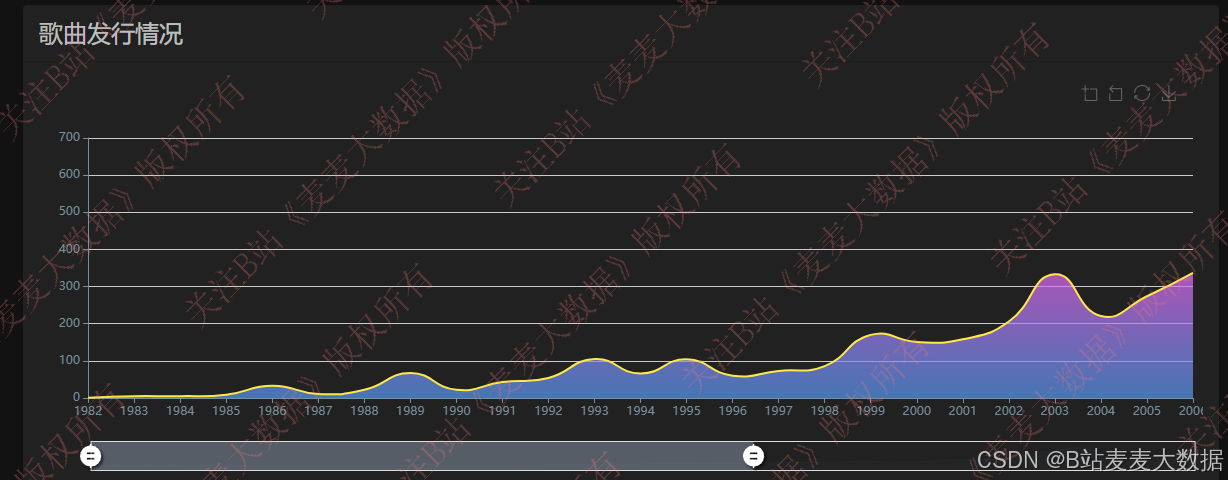
发行分析:
歌手作品分析:
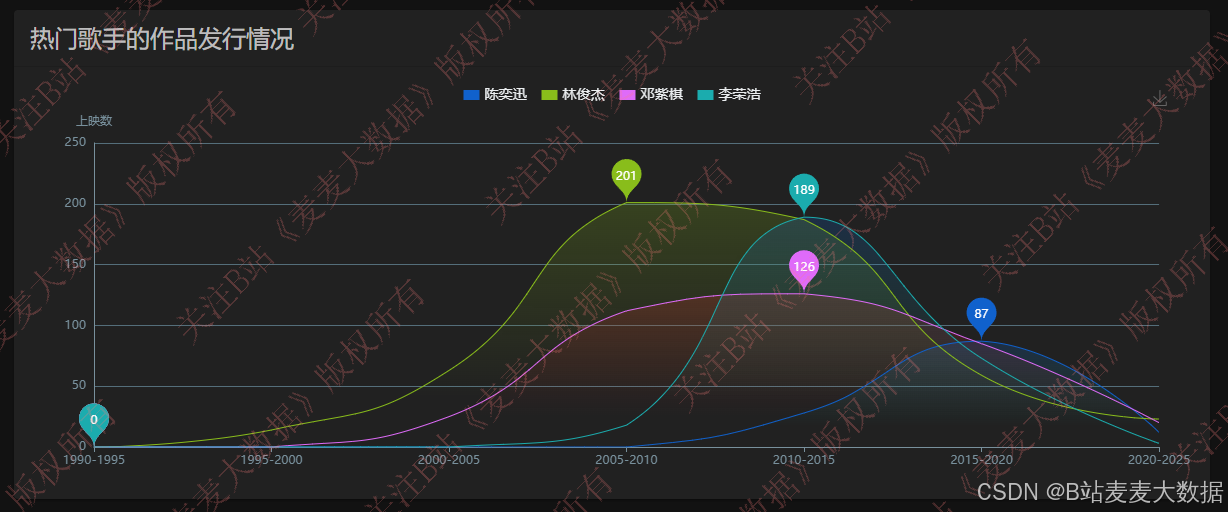
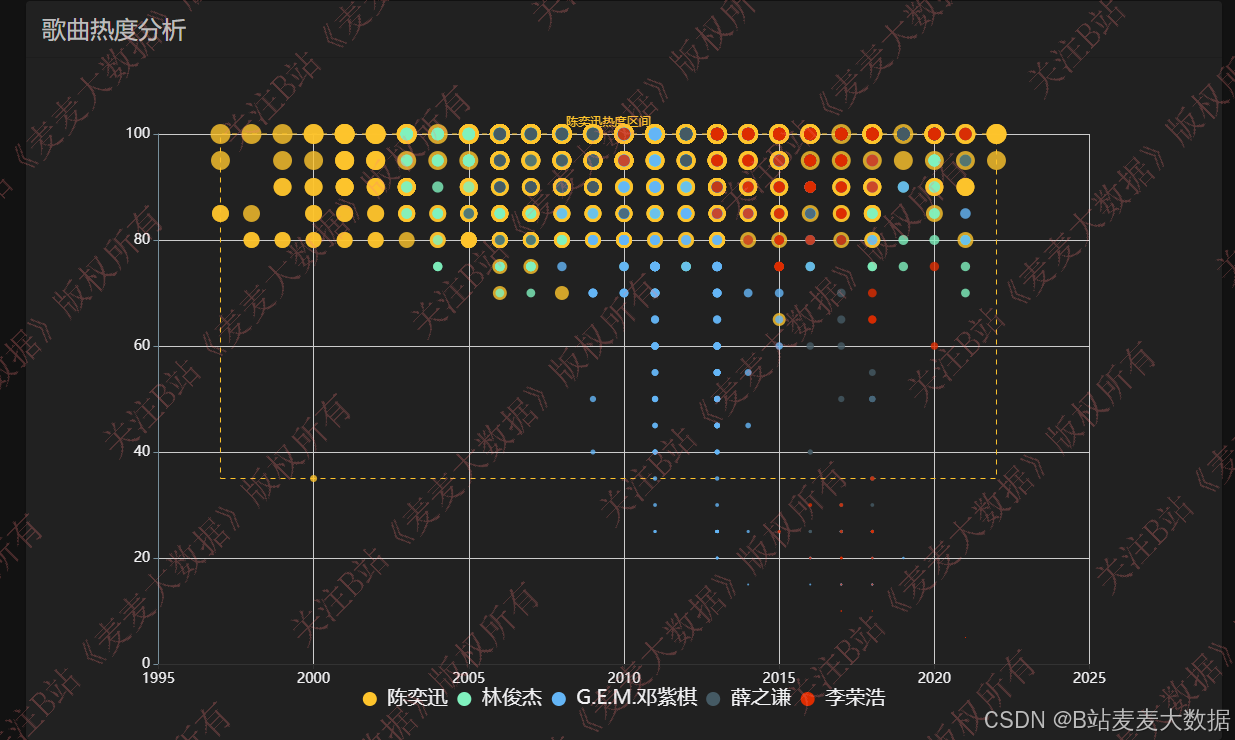
3.5 热度分析
使用散点图对歌曲热度进行分析:
3.6 词云分析
利用jieba分词算法对关键词进行词频分析,并且可视化:

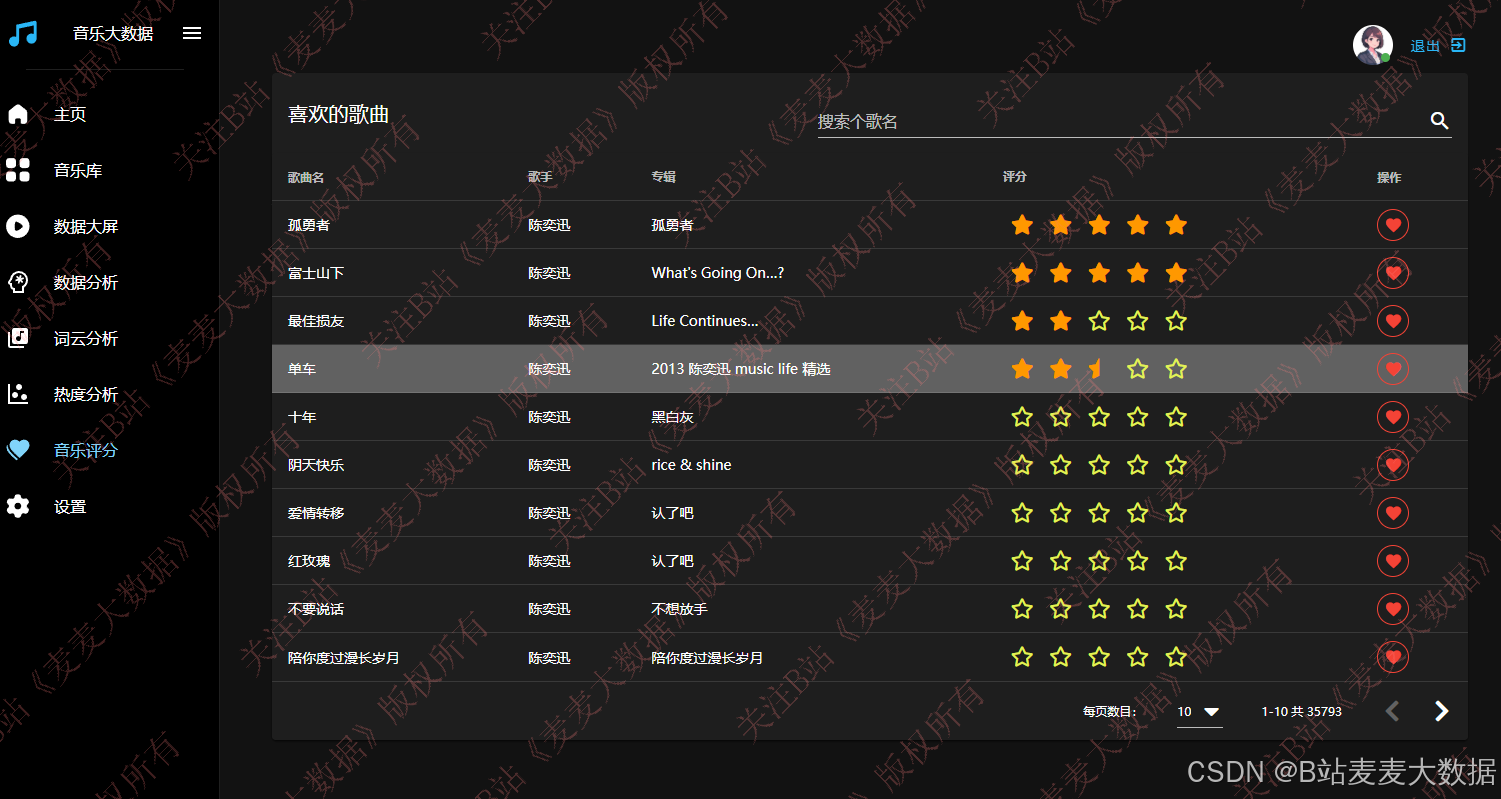
3.7 音乐评分
用户评分过的音乐可以在这里查看,也可以修改对歌曲的评分:
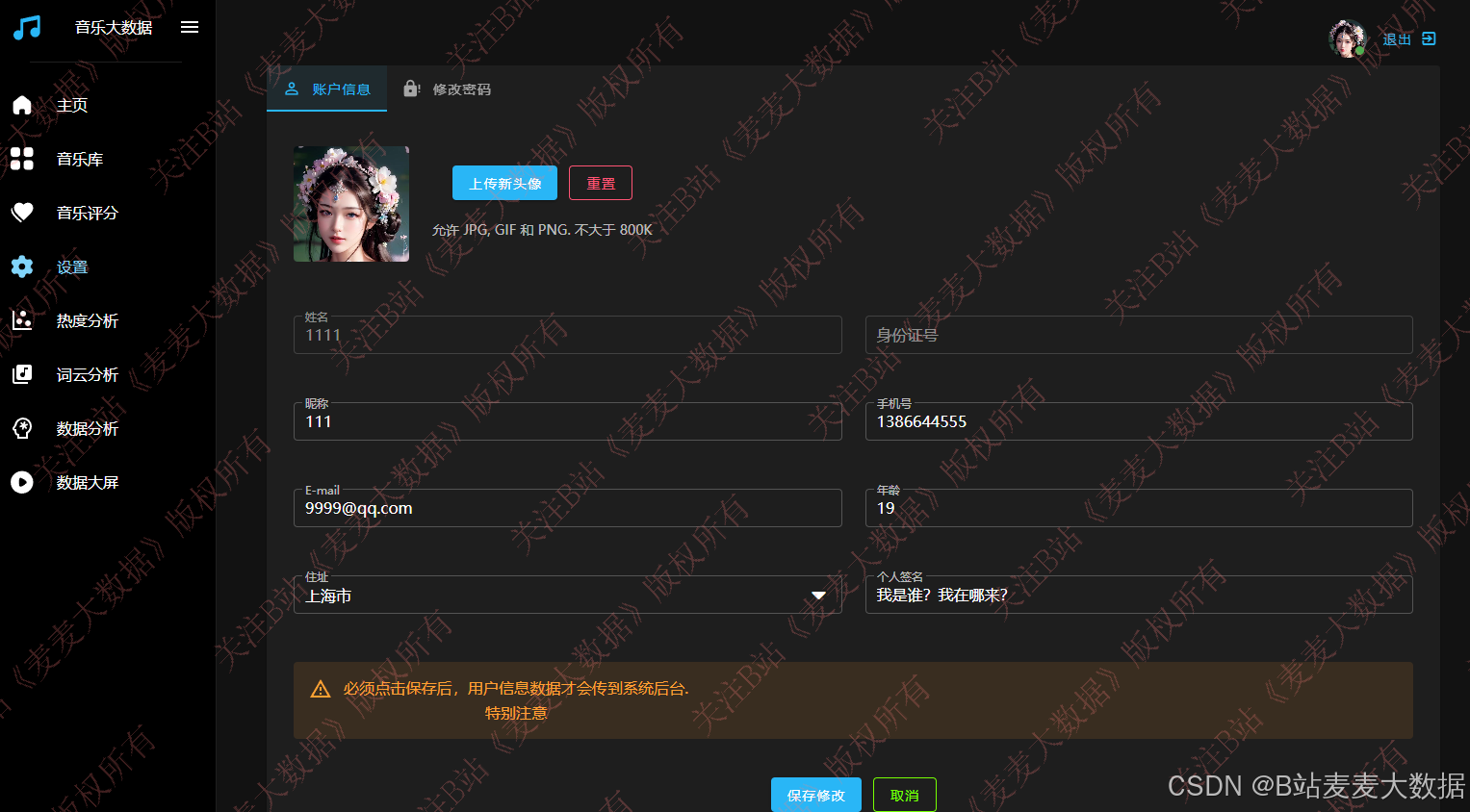
3.8 个人设置
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
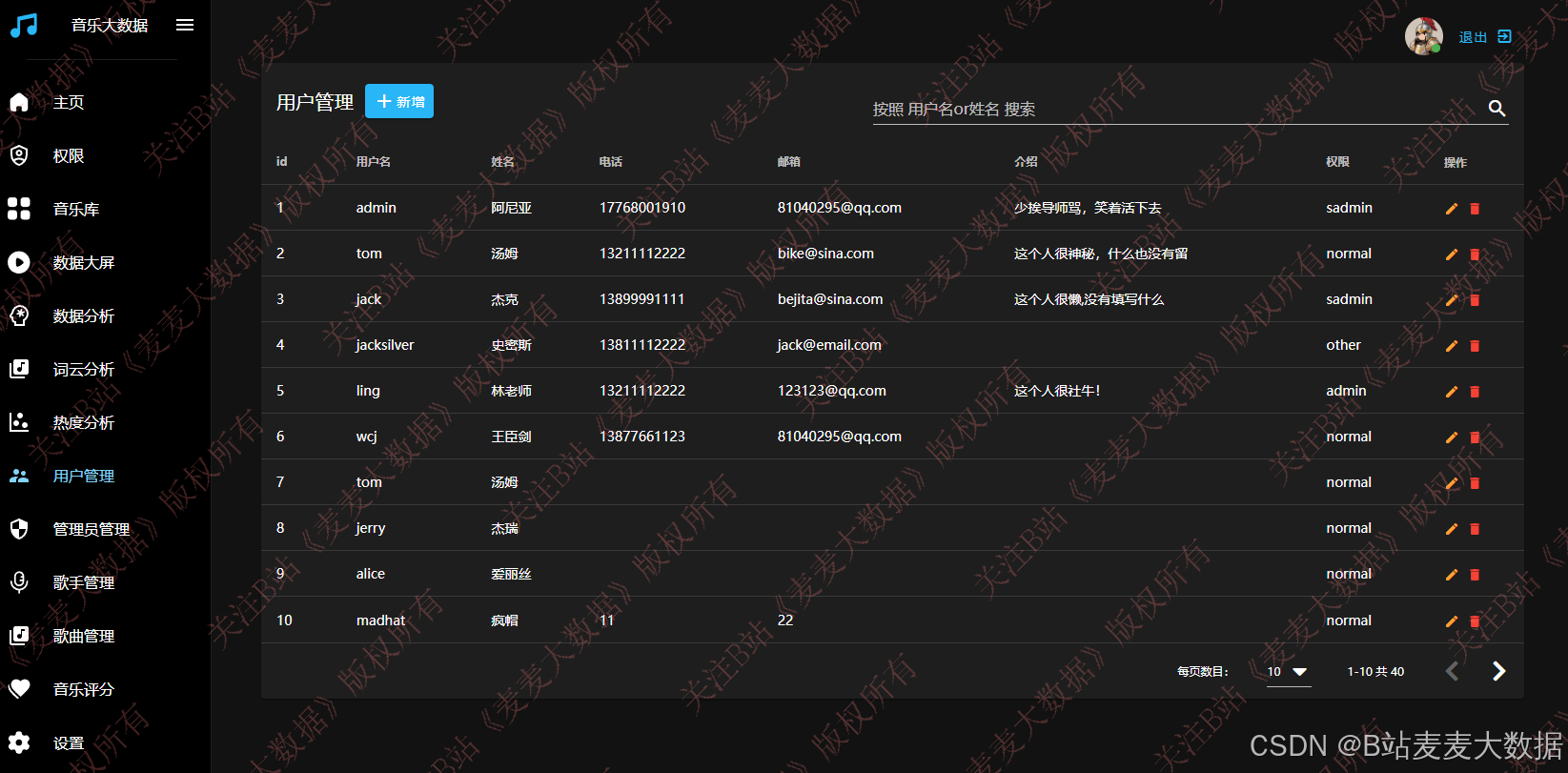
3.9 管理员 用户管理
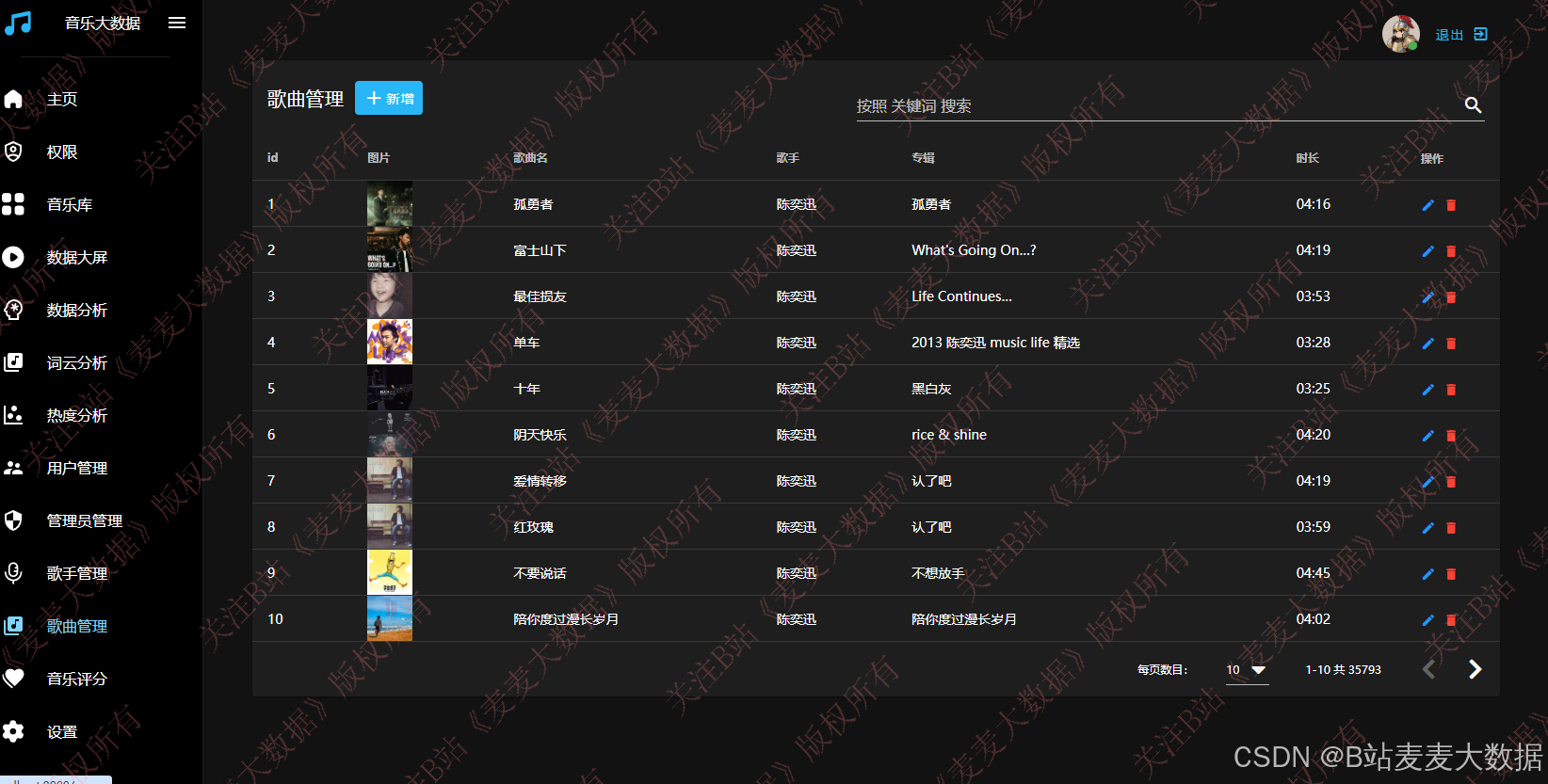
3.10 管理员 歌曲管理
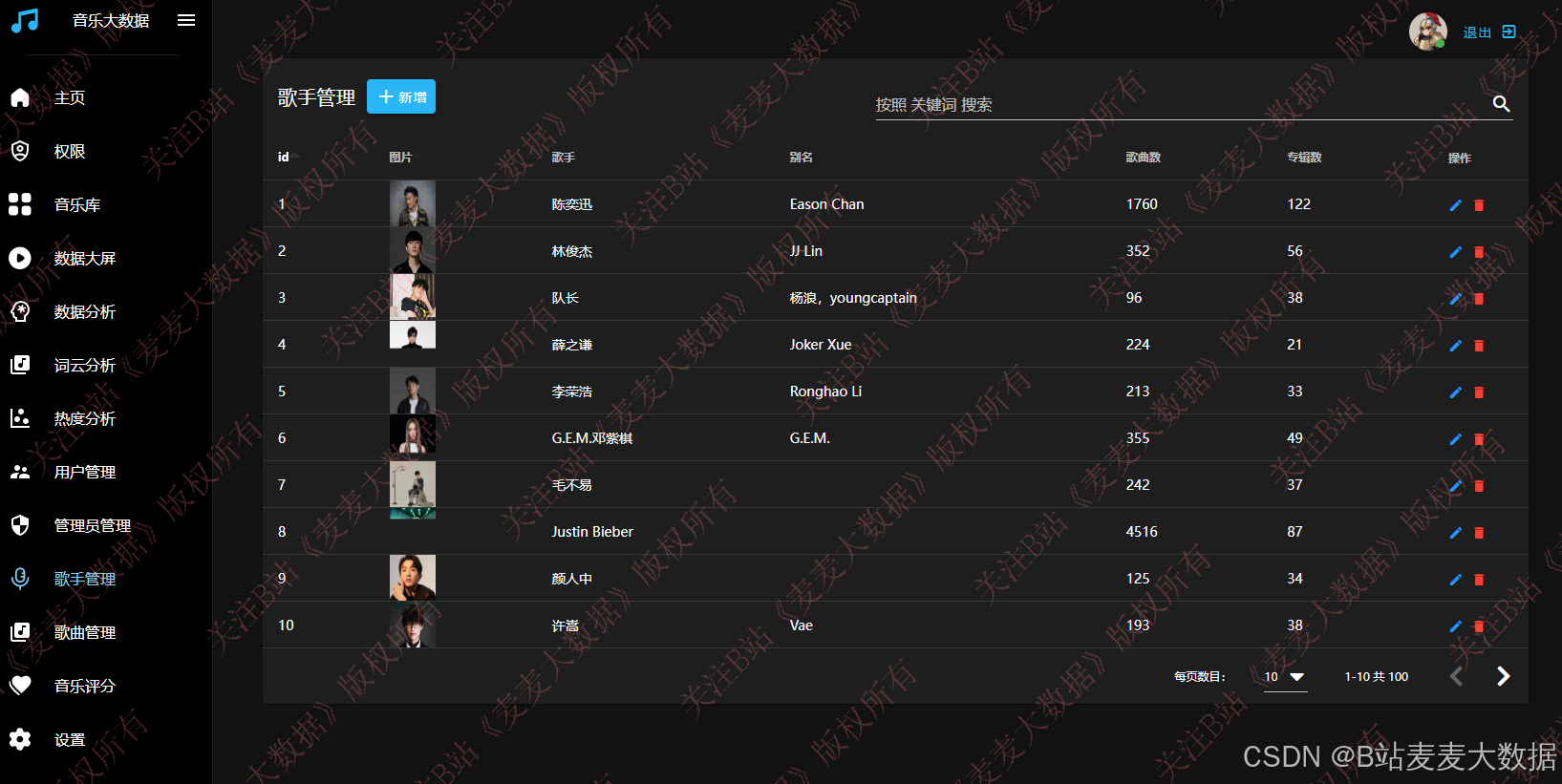
3.11 管理员 歌手管理
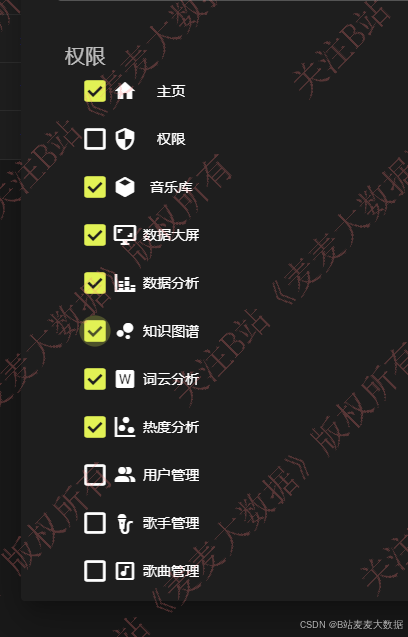
3.12 管理员 权限管理
管理员可以改变用户可以看到的菜单:
3.13 歌曲爬虫
歌曲、歌手、专辑数据可以通过爬虫进行更新:
4程序代码
4.1 代码说明
代码介绍:基于物品的协同过滤(ItemCF)算法的Python实现代码,用于音乐推荐系统。代码包括以下几个主要部分:
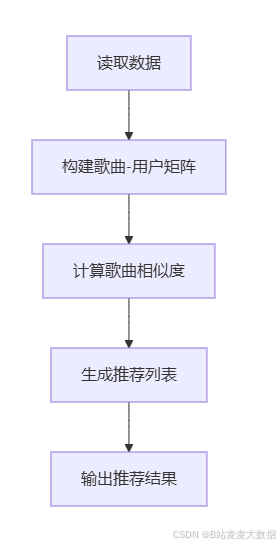
数据读取与预处理:从用户-歌曲的评分数据中构建歌曲的特征向量。
构建歌曲相似度矩阵:通过计算歌曲之间的Jaccard相似度,生成歌曲的相似度矩阵。
生成推荐列表:根据目标歌曲与其他歌曲的相似度,生成推荐列表。
4.2 流程图
4.3 代码实例
# ItemCF音乐推荐算法实现# 步骤1:读取用户-歌曲评分数据
def read_data():data = {'user1': {'song1': 5, 'song2': 3},'user2': {'song1': 4, 'song3': 5},'user3': {'song2': 4, 'song3': 3},}return data# 步骤2:构建歌曲-用户倒置矩阵
def build_item_matrix(data):item_matrix = {}songs = set()for user, ratings in data.items():for song in ratings:songs.add(song)songs = list(songs)for song in songs:item_matrix[song] = {}for user in data:item_matrix[song][user] = data[user].get(song, 0)return item_matrix# 步骤3:计算歌曲相似度(Jaccard)
def calculate_similarity(item_matrix):similarity = {}songs = list(item_matrix.keys())for i in range(len(songs)):song1 = songs[i]similarity[song1] = {}for j in range(i+1, len(songs)):song2 = songs[j]intersect = 0union = 0for user in item_matrix[song1]:if item_matrix[song1][user] > 0:union += 1if item_matrix[song2].get(user, 0) > 0:intersect += 1if union == 0:sim = 0else:sim = intersect / unionsimilarity[song1][song2] = simsimilarity[song2][song1] = simreturn similarity# 步骤4:生成推荐
def generate_recommendation(similarity, target_song, num_recs=3):if target_song not in similarity:return []candidates = sorted(similarity[target_song].items(), key=lambda x: x[1], reverse=True)return [song for song, sim in candidates if song != target_song][:num_recs]# 主程序
if __name__ == "__main__":data = read_data()item_matrix = build_item_matrix(data)similarity = calculate_similarity(item_matrix)recommendations = generate_recommendation(similarity, 'song1')print("推荐的歌曲:", recommendations)