CSP-S 2021 提高级 第一轮(初赛) 阅读程序(3)
【题目】
CSP-S 2021 提高级 第一轮(初赛) 阅读程序(3)
01 #include <iostream>
02 #include <string>
03 using namespace std;
04
05 char base[64];
06 char table[256];
07
08 void init()
09 {
10 for (int i = 0; i < 26; i++) base[i] = 'A' + i;
11 for (int i = 0; i < 26; i++) base[26 + i] = 'a' + i;
12 for (int i = 0; i < 10; i++) base[52 + i] = '0' + i;
13 base[62] = '+', base[63] = '/';
14
15 for (int i = 0; i < 256; i++) table[i] = 0xff;
16 for (int i = 0; i < 64; i++) table[base[i]] = i;
17 table['='] = 0;
18 }
19
20 string encode(string str)
21 {
22 string ret;
23 int i;
24 for (i = 0; i + 3 <= str.size(); i += 3) {
25 ret += base[str[i] >> 2];
26 ret += base[(str[i] & 0x03) << 4 | str[i + 1] >> 4];
27 ret += base[(str[i + 1] & 0x0f) << 2 | str[i + 2] >> 6];
28 ret += base[str[i + 2] & 0x3f];
29 }
30 if (i < str.size()) {
31 ret += base[str[i] >> 2];
32 if (i + 1 == str.size()) {
33 ret += base[(str[i] & 0x03) << 4];
34 ret += "==";
35 }
36 else {
37 ret += base[(str[i] & 0x03) << 4 | str[i + 1] >> 4];
38 ret += base[(str[i + 1] & 0x0f) << 2];
39 ret += "=";
40 }
41 }
42 return ret;
43 }
44
45 string decode(string str)
46 {
47 string ret;
48 int i;
49 for (i = 0; i < str.size(); i += 4) {
50 ret += table[str[i]] << 2 | table[str[i + 1]] >> 4;
51 if (str[i + 2] != '=')
52 ret += (table[str[i + 1]] & 0x0f) << 4 | table[str[i + 2]] >> 2;
53 if (str[i + 3] != '=')
54 ret += table[str[i + 2]] << 6 | table[str[i + 3]];
55 }
56 return ret;
57 }
58
59 int main()
60 {
61 init();
62 cout << int(table[0]) << endl;
63
64 int opt;
65 string str;
66 cin >> opt >> str;
67 cout << (opt ? decode(str) : encode(str)) << endl;
68 return 0;
69 }
假设输入总是合法的(一个整数和一个不含空白字符的字符串,用空格隔开),完成下面
的判断题和单选题:
- 判断题
- 程序总是先输出一行一个整数,再输出一行一个字符串。( )
- 对于任意不含空白字符的字符串 str1,先执行程序输入“0 str1”,得到输出的第二行记为 str2;再执行程序输入“1 str2”,输出的第二行必为 str1。( )
- 当输入为“1 SGVsbG93b3JsZA==”时,输出的第二行为“HelloWorld”。( )
- 单选题
- 设输入字符串长度为 n,encode 函数的时间复杂度为( )。
A. Θ(𝑛)\Theta (\sqrt{𝑛})Θ(n). B. Θ(𝑛)Θ(𝑛)Θ(n) C. Θ(𝑛log𝑛)Θ(𝑛 log 𝑛)Θ(nlogn) D. Θ(𝑛!)Θ(𝑛!)Θ(n!) - 输出的第一行为( )。
A. “0xff” B. “255” C. “0xFF” D. “-1” - (4 分)当输入为“0 CSP2021csp”时,输出的第二行为( )。
A. “Q1NQMjAyMWNzcAv=” B. “Q1NQMjAyMGNzcA==”
C. “Q1NQMjAyMGNzcAv=” D. “Q1NQMjAyMWNzcA==”
【题目考点】
1. 映射关系
- base64编码
3. 位运算
4. 字符串
【解题思路】
1. 代码解析
本题为base64编码的编码和解码过程。
base64编码为把数据在二进制下每6位为一个单位切分开,每6位二进制数可以表示的数值范围为0~63。将0~63映射为64种不同的字符。base64编码下每个字符表示6位二进制数,因此可以使用base64编码字符串表示数据(可以是任意类型的数据,如字符串数据,图片数据,视频数据等)。
05 char base[64];
06 char table[256];
07
08 void init()
09 {
10 for (int i = 0; i < 26; i++) base[i] = 'A' + i;
11 for (int i = 0; i < 26; i++) base[26 + i] = 'a' + i;
12 for (int i = 0; i < 10; i++) base[52 + i] = '0' + i;
13 base[62] = '+', base[63] = '/';
14
15 for (int i = 0; i < 256; i++) table[i] = 0xff;
16 for (int i = 0; i < 64; i++) table[base[i]] = i;
17 table['='] = 0;
18 }
base下标范围为0~63,base是字符型数组,每个下标对应一个字符。
i从0到25,base[i] = 'A'+i,那么base数组下标0对应A,下标1对应B,…,下标25对应Z。
i从0到25,base[26+i] = 'a'+i,那么base数组下标26对应a,27对应b,。。。,51对应z。
i从0到9,base[26+i] = 'a'+i,那么base接下来base数组下标52对应‘0’,53对应’1’,。。。,61对应’9’。
62对应+,63对应/。
table数组也是char类型的,每个元素只有1字节,下标范围为0~255。将每个元素设为0xff,也就是将每个元素的补码设为1111 1111,转成原码为1000 0001,将其转为int类型,值就是-1。因此第62行输出int(table[0])会输出-1。
table[base[i]] = i,即可以通过字符base[i]取到该字符在base64中的编号i。
table['=']=0,是要将字符’='转为0。
概念上,base64字符的编号从0到63(类似于ASCII码),实质是6位二进制数可能表示的所有数值。base64的字符有A~Z,a~z,0~9以及+,-。从base64的编号到字符是一种一一对应的映射关系。
base[i]为根据base64编号i取到其对应的字符。table[i]会根据base64的字符i取到其对应的编号。
特殊地,字符=会转为编号0,字符=用于占位,这一点会在后面解释。
映射表为:
| 编号i | 字符base[i] |
|---|---|
| 0 | A |
| 1 | B |
| 2 | C |
| 3 | D |
| 4 | E |
| 5 | F |
| 6 | G |
| 7 | H |
| 8 | I |
| 9 | J |
| 10 | K |
| 11 | L |
| 12 | M |
| 13 | N |
| 14 | O |
| 15 | P |
| 16 | Q |
| 17 | R |
| 18 | S |
| 19 | T |
| 20 | U |
| 21 | V |
| 22 | W |
| 23 | X |
| 24 | Y |
| 25 | Z |
| 26 | a |
| 27 | b |
| 28 | c |
| 29 | d |
| 30 | e |
| 31 | f |
| 32 | g |
| 33 | h |
| 34 | i |
| 35 | j |
| 36 | k |
| 37 | l |
| 38 | m |
| 39 | n |
| 40 | o |
| 41 | p |
| 42 | q |
| 43 | r |
| 44 | s |
| 45 | t |
| 46 | u |
| 47 | v |
| 48 | w |
| 49 | x |
| 50 | y |
| 51 | z |
| 52 | 0 |
| 53 | 1 |
| 54 | 2 |
| 55 | 3 |
| 56 | 4 |
| 57 | 5 |
| 58 | 6 |
| 59 | 7 |
| 60 | 8 |
| 61 | 9 |
| 62 | + |
| 63 | / |
20 string encode(string str)
21 {
22 string ret;
23 int i;
24 for (i = 0; i + 3 <= str.size(); i += 3) {
25 ret += base[str[i] >> 2];
26 ret += base[(str[i] & 0x03) << 4 | str[i + 1] >> 4];
27 ret += base[(str[i + 1] & 0x0f) << 2 | str[i + 2] >> 6];
28 ret += base[str[i + 2] & 0x3f];
29 }
30 if (i < str.size()) {
31 ret += base[str[i] >> 2];
32 if (i + 1 == str.size()) {
33 ret += base[(str[i] & 0x03) << 4];
34 ret += "==";
35 }
36 else {
37 ret += base[(str[i] & 0x03) << 4 | str[i + 1] >> 4];
38 ret += base[(str[i + 1] & 0x0f) << 2];
39 ret += "=";
40 }
41 }
42 return ret;
43 }
首先考虑将原字符串编码为base64字符串的程。
(在CSP-J 2021 阅读程序(2) 题目中,没有给出将原字符串编码为base64字符串过程。但可以通过解码过程反推编码过程。)
base64编码每个字符表示6位二进制数,原字符串每个字符表示8位二进制数。因此每4个base64字符,可以转化成3个原字符。
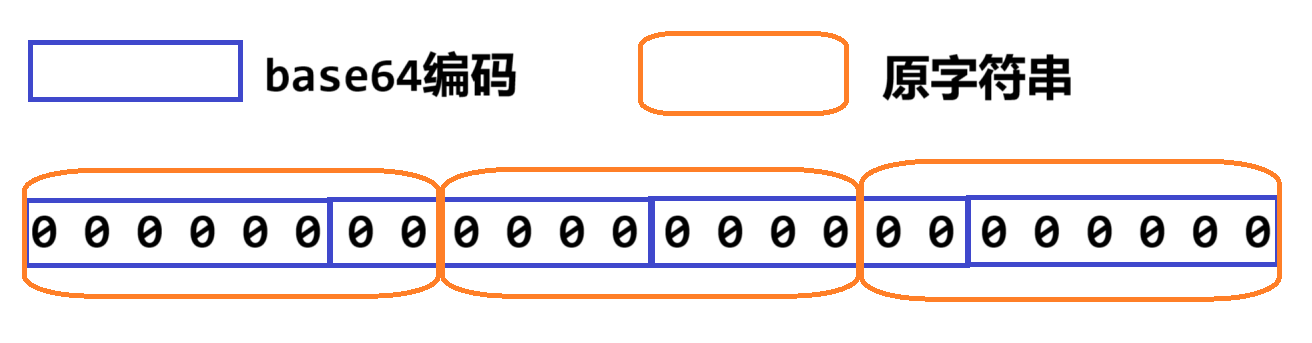
设原字符串三个连续字符的二进制形式分别为ABCD EFGH,IJKL MNOP,QRST UVWX。
以每6个二进制位为一组,应将切分为:ABC DEF,GHI JKL,MNO PQR,STU VWX四个数。将每个数通过base数组转为base64字符。这就是编码后的字符。
如果原字符串的字符数量不是3的倍数,则在原字符串末尾添加若干'\0',即ASCII码为0的字符,使其字符数量为3的倍数。经过每6位一组切分后,末尾会得到若干000 000,这样的数值对应使用base64编码中字符'='表示,'='起到占位的作用。得到的base64字符串的长度一定是4的倍数。
每次循环取
str[i],str[i+1],str[i+2]3个原字符。
str[i]的二进制形式为ABCD EFGH
str[i+1]的二进制形式为IJKL MNOP
str[i+2]的二进制形式为QRST UVWX
第1个base64字符的编号为00AB CDEF,即str[i]>>2,因此第1个base64字符为base[str[i]>>2]。
第2个base64字符的编号为00GH IJKL。str[i] & 0x03得到0000 00GH。(str[i] & 0x03) << 4得到00GH 0000,str[i+1] >> 4得到0000 IJKL,二者进行按位或运算(str[i] & 0x03) << 4 | str[i+1] >> 4得到00GH IJKL。因此第2个base64字符为base[(str[i] & 0x03) << 4 | str[i+1] >> 4]
特殊地,如果i+1为str字符串的长度,即str[i]为字符串的最后一个字符,最后一个base64字符的编号为00GH 0000,为(str[i] & 0x03) << 4,因此第2个base64字符为base[(str[i] & 0x03) << 4],后面还得添加两个=字符补位,保证base64字符串的长度是4的倍数。
第3个base64字符的编号为00MN OPQR。str[i+1] & 0x0f得到0000 MNOP。(str[i+1] & 0x0f) << 2得到00MN OP00。str[i+2]>>6得到0000 00QR,二者进行按位或运算(str[i+1] & 0x0f) << 2 | str[i+2] >> 6,得到00MN OPQR,因此第3个base64字符为base[(str[i+1] & 0x0f) << 2 | str[i+2] >> 6]
特殊地,如果i+2为str字符串的长度,即str[i+1]是字符串str的最后一个字符,
倒数第二个字符的base64字符的编号为00GH IJKL,上述已经讨论过,获取该编码的表达式为base[(str[i] & 0x03) << 4 | str[i+1] >> 4]。
最后一个字符的base64字符的编号为00MN OP00。str[i+1] & 0x0f得到0000 MNOP,再左移两位(str[i+1] & 0x0f) << 2为00MN OP00,因此最后一个base64字符为base[(str[i+1] & 0x0f) << 2]。
该组3个原字符只产生了3个base64字符,还需要一个base64字符补位,因此添加补位字符=,保证得到的base64字符串的长度是4的倍数。
第4个base64字符的编号为00ST UVWX。str[i + 2] & 0x3f即可得到00ST UVWX,因此第4个base64字符为base[str[i + 2] & 0x3f]。
20 string decode(string str)
21 {
22 string ret;
23 int i;
24 for (i = 0; i < str.size(); i += 4) {
25 ret += table[str[i]] << 2 | table[str[i + 1]] >> 4;
26 if (str[i + 2] != '=')
27 ret += (table[str[i + 1]] & 0x0f) << 4 | table[str[i + 2]] >> 2;
28 if (str[i + 3] != '=')
29 ret += table[str[i + 2]] << 6 | table[str[i + 3]];
30 }
31 return ret;
32 }
decode函数的作用是将base64编码构成的字符串str转为原字符串。每次循环取出4个加密后的base64字符,通过talbe数组将其转为6位二进制数可以表示的数值,而后将二进制数拼接为每8位一组,每组作为一个char类型的字符。遇到=即结束解码。这样就完成了从base64字符串到原字符串的解码过程。
每次循环取
str[i], str[i+1], str[i+2], str[i+3]四个base64编码后的字符。
可以通过table数组取到每个base64字符对应的6位二进制数表示的数值。
由于table数组每个元素是char类型的,每个char类型变量是1字节,实际还是8位二进制数,base64编码只使用这8位的低6位保存数据。
设table[str[i]]的二进制形式为00ABCD EF(由于只使用低6位,其中最高两位一定是0,每个字母代表一个二进制位。)
table[str[i+1]]的二进制形式为00GH IJKL。
table[str[i+2]]的二进制形式为00MN OPQR。
table[str[i+3]]的二进制形式为00ST UVWX。
- 第1个原字符的二进制形式为
ABCDF EFGH
需要将table[str[i]]左移两位table[str[i]] << 2,得到ABCD EF00
将table[str[i+2]]右移四位table[str[i+2]] >> 4,得到0000 00MN
二者进行按位或运算:table[str[i]] << 2 | table[str[i+2]] >> 4,结果为ABCD EFMN。将该字符添加到ret末尾。
如果str[i+2]是=,则已经访问到加密字符串的末尾,不需要将=转为原字符串中的字符。- 第2个原字符的二进制形式为
IJKL MNOP。
将table[str[i+1]]取低四位:table[str[i+1]] & 0x0f,得到0000 IJKL。再将其左移4位,(table[str[i+1]] & 0x0f) << 4的值为IJKL 0000。
table[str[i+2]]右移两位,table[str[i+2]] >> 2为0000 MNOP。
二者进行按位或运算(table[str[i+1]] & 0x0f) << 4 | table[str[i+2]] >> 2,结果为IJKL MNOP,这就是解码后得到的第二个原字符,接在ret字符串的末尾。
如果str[i+3]是=,则已经访问到加密字符串的末尾,可以结束字符转换。- 第3个原字符的二进制形式为
QRST UVWX。
将table[str[i+2]]左移6位,table[str[i+2]] << 6,得到QR00 0000。
table[str[i+3]]是00ST UVWX。
将该数与table[str[i+3]]进行按位或运算,table[str[i + 2]] << 6 | table[str[i + 3]],得到QRST UVWX。将其接在ret末尾。
最后ret即为解码后得到的原字符串。
59 int main()
60 {
61 init();
62 cout << int(table[0]) << endl;
63
64 int opt;
65 string str;
66 cin >> opt >> str;
67 cout << (opt ? decode(str) : encode(str)) << endl;
68 return 0;
69 }
主函数为:先输出table[0]的ASCII码。而后输入整数opt以及字符串。
- 如果opt不为0,即为真,那么str是base64字符串,将其解码为原字符串,输出原字符串。
- 如果opt为0,即为假,那么str是原字符串,将其编码为base64字符串,输出编码后的base64字符串。
2. 问题解答
判断题
1. 程序总是先输出一行一个整数,再输出一行一个字符串。( )
答:F
已知输入是一个整数和一个不含空白字符的字符串。
如果输入的opt不为0,那么要进行对base64字符串的解码过程,该字符串中必须只能有base64编码所规定的字符(A~Z,a~z,0~9,+/=),如果出现了其它字符,则不能正常解码。
例:输入opt为1,str为
$$$$,$不是base64编码所规定的字符。那么在解码过程中会取table['$'],由于通过memset将table数组每个元素初值设为值为0xff,所以table['$']为0xff。经过拼接后得到的原字符串中的字符的机器数也是0xff,将其转为原码,可知该字符变量保存的整数值为-1。得到的原字符串包含3个char类型变量,每个变量的值为-1。由于-1在ASCII码表中不对应字符,输出这样的字符会输出“空白”(不是ASCII码为32的空格,但占了位置),因此该字符串无法正常输出,输出会得到一串空白,不能算一个字符串。
可以运行下面代码看看会输出什么,本程序输入1 $$$$ 后就会输出什么。
#include<bits/stdc++.h>
using namespace std;
int main()
{string s(3, -1);//3个值为-1的字符 cout << s;//会输出空白//cout << '|' << s << '|';//可以在两侧输出的竖线用于参照return 0;
}
因此第二行可能不输出字符串,本题叙述错误。
2. 对于任意不含空白字符的字符串 str1,先执行程序输入“0 str1”,得到输出的第二行记为 str2;再执行程序输入“1 str2”,输出的第二行必为 str1。( )
答:T
输入"0 str1",得到的结果str2为原字符串str1经过base64编码后得到的字符串。再输入"1 str2",即为将编码后的base64字符串解码为原字符串,自然就会得到str1。
3. 当输入为“1 SGVsbG93b3JsZA==”时,输出的第二行为“HelloWorld”。( )
答:F
将base64字符串SGVsbG93b3JsZA==解码:
每个base64字符对应的数码为6位二进制数。每个原字符字符的ASCII码为8位二进制数。
每4位base64字符为一组,可以解码得到3个原字符串中的字符。
可以分别在base64字符串中取4个字符,转成二进制数。再从原字符串取3个字符,转成二进制数,看二者得到的二进制数是否相同。
第一组:base64字符SGVs,原字符串字符:Hel
| base64字符 | base64数码 | 二进制base64数码 |
|---|---|---|
| S | 18 | 010010 |
| G | 6 | 000110 |
| V | 21 | 010101 |
| s | 44 | 101100 |
连成24位二进制数为010010000110010101101100
| 原字符串字符 | ASCII码 | 二进制ASCII码 |
|---|---|---|
| H | 72 | 01001000 |
| e | 101 | 01100101 |
| l | 108 | 01101100 |
连成24位二进制数为010010000110010101101100,和上述根据base64字符串得到的二进制数相同。
第二组:base64字符bG93,原字符串字符:loW
| base64字符 | base64数码 | 二进制base64数码 |
|---|---|---|
| b | 27 | 011011 |
| G | 6 | 000110 |
| 9 | 61 | 111101 |
| 3 | 55 | 110111 |
连成24位二进制数为011011000110111101110111
| 原字符串字符 | ASCII码 | 二进制ASCII码 |
|---|---|---|
| l | 108 | 01101100 |
| o | 111 | 0110 1111 |
| W | 87 | 0101 0111 |
连成24位二进制数为011011000110111101010111,和上述根据base64字符串得到的二进制数不相同。
为了更好理解解码过程,下面给出后面各字符从base64字符解码为原字符的过程。
第三组:base64字符b3Js,原字符串字符:orl
| base64字符 | base64数码 | 二进制base64数码 |
|---|---|---|
| b | 27 | 011011 |
| 3 | 55 | 110111 |
| J | 9 | 001001 |
| s | 44 | 101100 |
连成24位二进制数为011011110111001001101100
| 原字符串字符 | ASCII码 | 二进制ASCII码 |
|---|---|---|
| o | 111 | 0110 1111 |
| r | 114 | 0111 0010 |
| l | 108 | 01101100 |
连成24位二进制数为011011110111001001101100,和上述根据base64字符串得到的二进制数相同。
第四组:base64字符ZA==,原字符串字符:d\0\0(原字符串字符每3个一组,取到末尾时,可以在其末尾添加字符’\0’,构成一组)
| base64字符 | base64数码 | 二进制base64数码 |
|---|---|---|
| Z | 25 | 011001 |
| A | 0 | 000000 |
| = | 0 | 000000 |
| = | 0 | 000000 |
连成24位二进制数为011001000000000000000000
| 原字符串字符 | ASCII码 | 二进制ASCII码 |
|---|---|---|
| d | 100 | 0110 0100 |
| \0 | 0 | 0000 0000 |
| \0 | 0 | 0000 0000 |
连成24位二进制数为011001000000000000000000,和上述根据base64字符串得到的二进制数相同。
本题中 base64字符串SGVsbG93b3JsZA==解码得到的原字符串实际为Helloworld,w是小写的而不是大写的。
因此本题叙述错误。
- 单选题
4. 设输入字符串长度为 n,encode 函数的时间复杂度为( )。
A. Θ(𝑛)\Theta (\sqrt{𝑛})Θ(n). B. Θ(𝑛)Θ(𝑛)Θ(n) C. Θ(𝑛log𝑛)Θ(𝑛 log 𝑛)Θ(nlogn) D. Θ(𝑛!)Θ(𝑛!)Θ(n!)
答:B
看encode函数的for循环,循环控制变量i从0循环到str.size(),也就是从0循环到n,i每次增加3,循环的次数大概为n3\dfrac{n}{3}3n。循环外执行的语句是有限的,不超过10次。因此程序执行的时间频度可以大概写为T(n)=n3+10T(n)=\dfrac{n}{3}+10T(n)=3n+10,时间复杂度Θ(T(n))=Θ(n3+10)=Θ(n)\Theta(T(n))=\Theta(\dfrac{n}{3}+10)=\Theta(n)Θ(T(n))=Θ(3n+10)=Θ(n)。
5. 输出的第一行为( )。
A. “0xff” B. “255” C. “0xFF” D. “-1”
答:D
table数组也是char类型的,每个元素只有1字节,下标范围为0~255。
15 for (int i = 0; i < 256; i++) table[i] = 0xff;
将每个元素设为0xff,也就是将每个元素的补码设为1111 1111,转成原码为1000 0001,将其转为int类型,值就是-1。因此第一行输出int(table[0])会输出-1。
6. (4 分)当输入为“0 CSP2021csp”时,输出的第二行为( )。
A. “Q1NQMjAyMWNzcAv=” B. “Q1NQMjAyMGNzcA==”
C. “Q1NQMjAyMGNzcAv=” D. “Q1NQMjAyMWNzcA==”
答:D
输入0,要做的就是将原字符串CSP2021csp编码为base64编码的字符串。
先看原字符串的长度,为10个字符,每3个一组,最后一个字符一组,共4组。
分组情况为:CSP 202 1cs p
每组转成4个base64字符,因此base64字符串共有16个字符。四个选项都有16个字符。
对比各个选项的base64字符串,只有最后的8个字符不同,也就是最后两组。
取原字符串最后两组字符1cs p,将其转为base64字符
第一组:1cs
| 原字符串字符 | ASCII码 | 二进制ASCII码 |
|---|---|---|
| 1 | 49 | 0011 0001 |
| c | 99 | 0110 0011 |
| s | 115 | 0111 0011 |
得到二进制数:001100010110001101110011
每6位一组:001100 010110 001101 110011
| 二进制base64数码 | base64数码 | base64字符 |
|---|---|---|
| 001100 | 12 | M |
| 010110 | 22 | W |
| 001101 | 13 | N |
| 110011 | 51 | z |
该组得到的base64字符串为MWNz。
第二组:p,不足3个字符,末尾补`\0’
| 原字符串字符 | ASCII码 | 二进制ASCII码 |
|---|---|---|
| p | 112 | 0111 0000 |
| \0 | 0 | 0000 0000 |
| \0 | 0 | 0000 0000 |
得到二进制数:011100000000000000000000
每6位一组:011100 000000 000000 000000
(注意原字符p的二进制数有8位,需要使用两个base64字符中的二进制位表示这8位数,如果第二组的值为0,应该转为字符A。最后再使用两个=补位)
| 二进制base64数码 | base64数码 | base64字符 |
|---|---|---|
| 011100 | 28 | c |
| 000000 | 0 | A |
| 000000 | 0 | = |
| 000000 | 0 | = |
该组得到的base64字符串为cA==。
因此原字符串最后几个字符1csp编码后得到的base64字符串为MWNzcA==,因此选D。
【答案】
- F
- T
- F
- B
- D
- D