Redis的RedLock
RedLock算法深度解析
RedLock是Redis作者针对分布式环境设计的多节点锁算法,核心目标是解决单点Redis在分布式锁场景中的可靠性缺陷。
传统方案的局限性
单节点Redis锁的问题
单点故障:单个Redis实例宕机导致所有锁服务不可用
可靠性不足:无法保证锁服务的高可用性
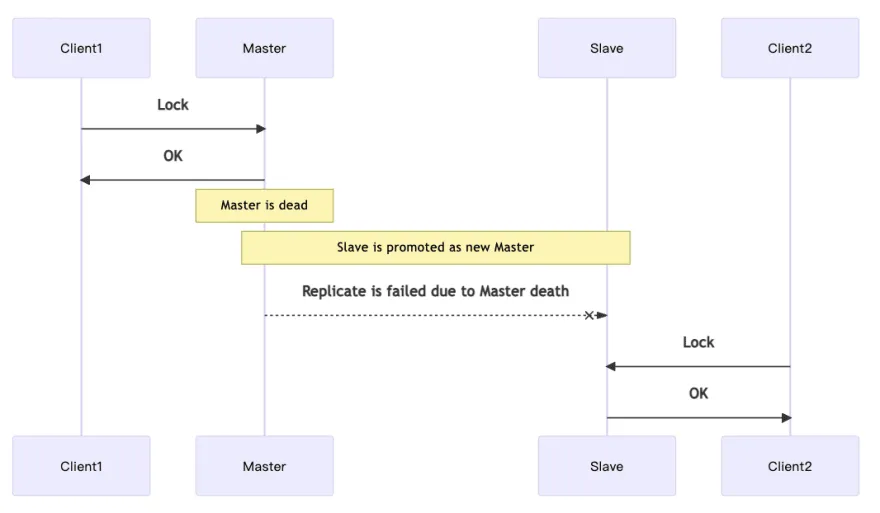
主从架构的隐患
数据不一致:主节点写入成功但未同步到从节点时发生故障
锁状态丢失:故障转移后新主节点缺失锁信息,导致重复加锁
RedLock核心设计原理
多节点共识机制
RedLock基于分布式系统中的**多数派原则**,要求客户端必须在超过半数的Redis节点上成功获取锁,才能认为加锁成功。这种设计确保即使部分节点故障,锁服务仍然可用。
算法关键要素
节点独立性:每个Redis节点都是独立部署,避免共同故障点
多数派投票:需要(N/2 + 1)个节点同意才能获得锁
时钟同步:所有节点和客户端保持时间同步
唯一标识:每个锁使用全局唯一标识避免冲突
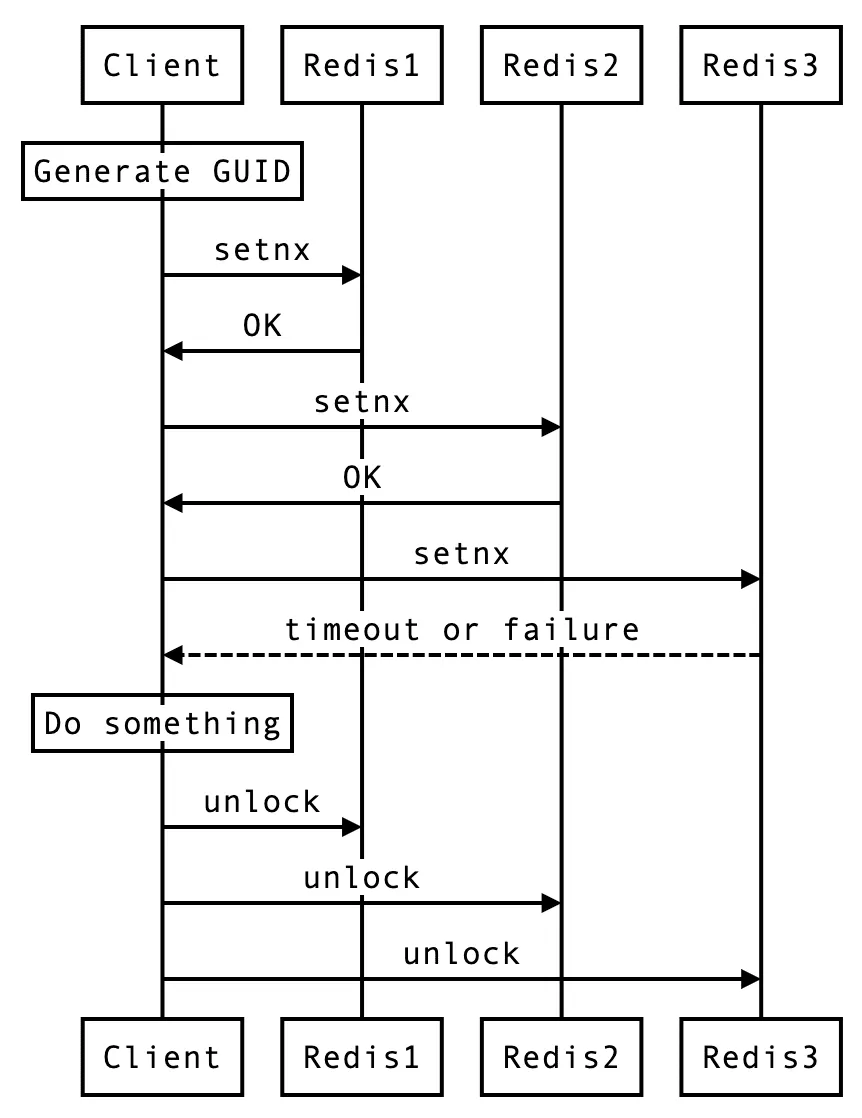
RedLock工作流程
加锁过程
客户端生成唯一标识(通常基于时间戳和随机数)
依次向所有Redis节点发送加锁命令:
SET lock_key unique_id NX PX 30000计算加锁成功的节点数量
如果成功节点数 ≥ (N/2 + 1),加锁成功
实际锁有效期为设置时间减去加锁过程耗时
释放过程
无论加锁是否成功,客户端都必须向所有节点发送释放命令,确保状态清理。
📊 算法优势与挑战
核心优势
高可用性:容忍最多(N-1)/2个节点故障
强一致性:多数派机制防止脑裂场景下的锁冲突
自动容错:单个节点故障不影响整体锁服务
实施挑战
性能开销:需要与多个节点通信,增加延迟
部署复杂度:需要维护多个独立Redis实例
时钟敏感性:对系统时钟同步要求较高
网络依赖:节点间网络延迟影响锁获取效率
🔧 实践建议
节点配置
推荐使用5个Redis节点部署RedLock,这样可以容忍2个节点故障同时保持较好的性能平衡。
超时设置
锁超时时间应该根据业务操作的最长时间合理设置,并包含网络通信和安全余量:
// 建议设置 int lockTimeout = estimatedBusinessTime * 2 + networkLatencyMargin;
错误处理
实现完善的重试机制和超时控制,处理网络分区和节点故障场景。
总结
RedLock通过多节点共识机制有效提升了分布式锁的可靠性,但同时也带来了额外的复杂性和性能开销。在实际应用中,需要根据业务的具体需求和基础设施条件进行权衡选择。对于大多数应用场景,主从复制配合适当的超时机制可能已经足够,而对于金融级的关键业务,RedLock提供的强一致性保障则是必要的。