支持向量机:从理论到实践
支持向量机:从理论到实践
文章目录
- 支持向量机:从理论到实践
- 一。理论概述
- 1. 线性可分支持向量机
- 1.1 基本概念与数学形式
- 1.2 函数间隔与几何间隔
- 1.3 间隔最大化与优化问题
- 1.4 拉格朗日对偶理论与求解
- 1.5 支持向量与决策函数
- 2. 近似线性可分数据(软间隔SVM)
- 2.1 松弛变量与软间隔概念
- 2.2 软间隔的对偶问题与支持向量分类
- 3. 非线性支持向量机与核方法
- 3.1 核技巧的数学原理
- 3.2 常用核函数及其特性
- 3.3 核函数的选择与模型选择
- 3.4 Mercer定理与核函数有效性
- 4. 支持向量机的扩展与变体
- 4.1 支持向量回归(SVR)
- 4.2 多类支持向量机
- 4.3 结构化SVM
- 5. 支持向量机的实践考虑
- 5.1 数据预处理与特征缩放
- 5.2 计算效率与大规模数据处理
- 5.3 模型解释性与特征重要性
- 6. 支持向量机的局限性与挑战
- 二。SVM模型应用于人脸分类
- 1. 数据加载与预处理
- 2. 训练测试划分与数据标准化
- 3. 主成分分析(PCA)降维
- 4. 支持向量机超参数优化
- 5. 模型预测与评估
- 6. 预测结果标题生成与可视化
- 7. 特征脸可视化
一。理论概述
支持向量机(Support Vector Machine, SVM)是机器学习中最强大和最广泛使用的算法之一,尤其在小样本、高维数据的分类任务中表现出色。其核心思想基于统计学习理论中的结构风险最小化原则,通过构建最大间隔超平面来实现分类任务。本文将从数学基础到实际应用,全面深入地解析SVM的工作原理和实现细节。
1. 线性可分支持向量机
1.1 基本概念与数学形式
对于完全线性可分的数据集,存在无数个超平面能够将两类样本完全分开。SVM通过间隔最大化原则从中选择唯一的最优超平面,该超平面不仅能够正确分类所有训练样本,而且具有最好的泛化能力。
超平面的数学表示为:
wTx+b=0w^T x + b = 0wTx+b=0
其中w∈Rnw \in \mathbb{R}^nw∈Rn是超平面的法向量,决定了超平面的方向;b∈Rb \in \mathbb{R}b∈R是位移项,决定了超平面与原点的距离。
样本点xix_ixi到超平面的几何距离为:
di=∣wTxi+b∣∥w∥d_i = \frac{|w^T x_i + b|}{\|w\|}di=∥w∥∣wTxi+b∣
1.2 函数间隔与几何间隔
函数间隔的概念引入了类别信息:
γ^i=yi(wTxi+b)\hat{\gamma}_i = y_i(w^T x_i + b)γ^i=yi(wTxi+b)
其中yi∈{−1,1}y_i \in \{-1, 1\}yi∈{−1,1}是样本的类别标签。函数间隔的符号表示分类的正确性,绝对值表示分类的确信度。
整个数据集的函数间隔定义为所有样本中函数间隔的最小值:
γ^=mini=1,…,Nγ^i\hat{\gamma} = \min_{i=1,\dots,N} \hat{\gamma}_iγ^=i=1,…,Nminγ^i
然而,函数间隔存在一个显著问题:对www和bbb进行等比例缩放时,超平面不变但函数间隔会改变。为解决这个问题,我们引入几何间隔:
γi=γ^i∥w∥=yi(wTxi+b)∥w∥\gamma_i = \frac{\hat{\gamma}_i}{\|w\|} = \frac{y_i(w^T x_i + b)}{\|w\|}γi=∥w∥γ^i=∥w∥yi(wTxi+b)
几何间隔表示样本点到超平面的真实欧几里得距离,具有缩放不变性,能够真实反映分类的确信度。
1.3 间隔最大化与优化问题
SVM的核心目标是找到最大几何间隔的超平面,这可以表述为以下优化问题:
maxw,bγ\max_{w,b} \gammaw,bmaxγ
s.t. yi(wTxi+b)∥w∥≥γ,i=1,…,N\text{s.t. } \frac{y_i(w^T x_i + b)}{\|w\|} \geq \gamma, \quad i=1,\dots,Ns.t. ∥w∥yi(wTxi+b)≥γ,i=1,…,N
通过令γ^=1\hat{\gamma} = 1γ^=1(这可以通过调整www和bbb的尺度实现),问题转化为等价的约束优化问题:
minw,b12∥w∥2\min_{w,b} \frac{1}{2} \|w\|^2w,bmin21∥w∥2
s.t. yi(wTxi+b)≥1,i=1,…,N\text{s.t. } y_i(w^T x_i + b) \geq 1, \quad i=1,\dots,Ns.t. yi(wTxi+b)≥1,i=1,…,N
这是一个典型的凸二次规划问题,具有全局最优解。目标函数中的12\frac{1}{2}21是为了后续求导方便而添加的系数,不影响优化结果。
1.4 拉格朗日对偶理论与求解
应用拉格朗日乘子法,我们引入拉格朗日乘子αi≥0\alpha_i \geq 0αi≥0,构造拉格朗日函数:
L(w,b,α)=12∥w∥2−∑i=1Nαi[yi(wTxi+b)−1]L(w,b,\alpha) = \frac{1}{2} \|w\|^2 - \sum_{i=1}^N \alpha_i [y_i(w^T x_i + b) - 1]L(w,b,α)=21∥w∥2−i=1∑Nαi[yi(wTxi+b)−1]
根据KKT条件,原问题的最优解满足:
∇wL=w−∑i=1Nαiyixi=0\nabla_w L = w - \sum_{i=1}^N \alpha_i y_i x_i = 0∇wL=w−i=1∑Nαiyixi=0
∂L∂b=−∑i=1Nαiyi=0\frac{\partial L}{\partial b} = -\sum_{i=1}^N \alpha_i y_i = 0∂b∂L=−i=1∑Nαiyi=0
αi[yi(wTxi+b)−1]=0,i=1,…,N\alpha_i [y_i(w^T x_i + b) - 1] = 0, \quad i=1,\dots,Nαi[yi(wTxi+b)−1]=0,i=1,…,N
代入拉格朗日函数,得到对偶问题:
maxα−12∑i=1N∑j=1NαiαjyiyjxiTxj+∑i=1Nαi\max_{\alpha} -\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j x_i^T x_j + \sum_{i=1}^N \alpha_iαmax−21i=1∑Nj=1∑NαiαjyiyjxiTxj+i=1∑Nαi
s.t. αi≥0,∑i=1Nαiyi=0\text{s.t. } \alpha_i \geq 0, \quad \sum_{i=1}^N \alpha_i y_i = 0s.t. αi≥0,i=1∑Nαiyi=0
1.5 支持向量与决策函数
从KKT条件中的互补松弛条件αi[yi(wTxi+b)−1]=0\alpha_i [y_i(w^T x_i + b) - 1] = 0αi[yi(wTxi+b)−1]=0可知:
- 当αi=0\alpha_i = 0αi=0时,对应样本不是支持向量,对决策边界没有影响
- 当αi>0\alpha_i > 0αi>0时,必有yi(wTxi+b)=1y_i(w^T x_i + b) = 1yi(wTxi+b)=1,对应样本是支持向量
支持向量是位于间隔边界上的样本点,它们决定了最终的超平面。这一特性使得SVM的解具有稀疏性,仅依赖于少数支持向量。
最终的决策函数为:
f(x)=sign(∑i=1NαiyixiTx+b)f(x) = \text{sign} \left( \sum_{i=1}^N \alpha_i y_i x_i^T x + b \right)f(x)=sign(i=1∑NαiyixiTx+b)
其中bbb可以通过任意支持向量计算得到:b=yi−wTxib = y_i - w^T x_ib=yi−wTxi(对于满足0<αi0 < \alpha_i0<αi的样本)。
2. 近似线性可分数据(软间隔SVM)
2.1 松弛变量与软间隔概念
在实际应用中,数据很少是完美线性可分的,可能存在噪声或异常点。软间隔SVM通过引入松弛变量ξi≥0\xi_i \geq 0ξi≥0,允许一些样本被错误分类,从而提高模型的鲁棒性。
优化问题变为:
minw,b,ξ12∥w∥2+C∑i=1Nξi\min_{w,b,\xi} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^N \xi_iw,b,ξmin21∥w∥2+Ci=1∑Nξi
s.t. yi(wTxi+b)≥1−ξi,ξi≥0,i=1,…,N\text{s.t. } y_i(w^T x_i + b) \geq 1 - \xi_i, \quad \xi_i \geq 0, \quad i=1,\dots,Ns.t. yi(wTxi+b)≥1−ξi,ξi≥0,i=1,…,N
其中C>0C > 0C>0是正则化参数,控制误分类惩罚与间隔大小之间的平衡:
- CCC值较大时,误分类惩罚重,间隔较小,可能过拟合
- CCC值较小时,误分类惩罚轻,间隔较大,可能欠拟合
2.2 软间隔的对偶问题与支持向量分类
软间隔SVM的对偶问题与硬间隔形式相似:
maxα−12∑i=1N∑j=1NαiαjyiyjxiTxj+∑i=1Nαi\max_{\alpha} -\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j x_i^T x_j + \sum_{i=1}^N \alpha_iαmax−21i=1∑Nj=1∑NαiαjyiyjxiTxj+i=1∑Nαi
s.t. 0≤αi≤C,∑i=1Nαiyi=0\text{s.t. } 0 \leq \alpha_i \leq C, \quad \sum_{i=1}^N \alpha_i y_i = 0s.t. 0≤αi≤C,i=1∑Nαiyi=0
KKT条件扩展为:
αi[yi(wTxi+b)−1+ξi]=0\alpha_i [y_i(w^T x_i + b) - 1 + \xi_i] = 0αi[yi(wTxi+b)−1+ξi]=0
(C−αi)ξi=0(C - \alpha_i) \xi_i = 0(C−αi)ξi=0
支持向量分为三类:
- αi=0\alpha_i = 0αi=0:正确分类的非支持向量,对决策边界没有影响
- 0<αi<C0 < \alpha_i < C0<αi<C:位于间隔边界上的支持向量,满足yi(wTxi+b)=1y_i(w^T x_i + b) = 1yi(wTxi+b)=1
- αi=C\alpha_i = Cαi=C:被错误分类的支持向量或落在间隔内的样本,满足ξi>0\xi_i > 0ξi>0
3. 非线性支持向量机与核方法
3.1 核技巧的数学原理
当数据在原始特征空间中线性不可分时,可以通过非线性映射ϕ:Rd→H\phi: \mathbb{R}^d \to \mathcal{H}ϕ:Rd→H将数据映射到高维特征空间H\mathcal{H}H,在其中数据变得线性可分。
在高维空间中的优化问题变为:
minw,b12∥w∥2+C∑i=1Nξi\min_{w,b} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^N \xi_iw,bmin21∥w∥2+Ci=1∑Nξi
s.t. yi(wTϕ(xi)+b)≥1−ξi,ξi≥0\text{s.t. } y_i(w^T \phi(x_i) + b) \geq 1 - \xi_i, \quad \xi_i \geq 0s.t. yi(wTϕ(xi)+b)≥1−ξi,ξi≥0
对偶问题为:
maxα−12∑i=1N∑j=1Nαiαjyiyjϕ(xi)Tϕ(xj)+∑i=1Nαi\max_{\alpha} -\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j \phi(x_i)^T \phi(x_j) + \sum_{i=1}^N \alpha_iαmax−21i=1∑Nj=1∑Nαiαjyiyjϕ(xi)Tϕ(xj)+i=1∑Nαi
直接计算ϕ(xi)Tϕ(xj)\phi(x_i)^T \phi(x_j)ϕ(xi)Tϕ(xj)可能非常困难(甚至不可能),因此引入核函数:
K(xi,xj)=ϕ(xi)Tϕ(xj)K(x_i, x_j) = \phi(x_i)^T \phi(x_j)K(xi,xj)=ϕ(xi)Tϕ(xj)
3.2 常用核函数及其特性
-
线性核:K(xi,xj)=xiTxjK(x_i, x_j) = x_i^T x_jK(xi,xj)=xiTxj
- 参数少,速度快,适用于线性可分情况
- 简单,可解释性强
-
多项式核:K(xi,xj)=(xiTxj+c)dK(x_i, x_j) = (x_i^T x_j + c)^dK(xi,xj)=(xiTxj+c)d
- 参数ddd控制映射后的空间维度
- 当ddd较大时计算可能不稳定
-
高斯径向基核(RBF):K(xi,xj)=exp(−γ∥xi−xj∥2)K(x_i, x_j) = \exp(-\gamma \|x_i - x_j\|^2)K(xi,xj)=exp(−γ∥xi−xj∥2)
- 应用最广泛的核函数,具有很强的非线性映射能力
- 参数γ\gammaγ控制高斯函数的宽度,影响模型的复杂度
-
Sigmoid核:K(xi,xj)=tanh(κxiTxj+θ)K(x_i, x_j) = \tanh(\kappa x_i^T x_j + \theta)K(xi,xj)=tanh(κxiTxj+θ)
- 来源于神经网络理论,在某些特定问题上表现良好
- 不是对所有参数都满足Mercer条件
3.3 核函数的选择与模型选择
核函数的选择依赖于具体问题和数据特性:
- 文本分类:通常使用线性核,因为文本数据往往已经是高维的
- 图像识别:常用RBF核或多项式核,可以捕捉像素间的复杂关系
- 生物信息学:RBF核表现优异,适用于基因序列等复杂数据
模型选择涉及参数调优,常用交叉验证来确定最优的CCC和核参数(如RBF核的γ\gammaγ)。
3.4 Mercer定理与核函数有效性
核函数必须满足Mercer条件:对任意函数g(x)g(x)g(x)满足∫g(x)2dx<∞\int g(x)^2 dx < \infty∫g(x)2dx<∞,有:
∬K(x,y)g(x)g(y)dxdy≥0\iint K(x, y) g(x) g(y) dx dy \geq 0∬K(x,y)g(x)g(y)dxdy≥0
这保证了核矩阵K=[K(xi,xj)]K = [K(x_i, x_j)]K=[K(xi,xj)]是半正定的,对应的优化问题是凸的,有全局最优解。
4. 支持向量机的扩展与变体
4.1 支持向量回归(SVR)
支持向量机也可以用于回归任务,称为支持向量回归。其基本思想是:寻找一个函数f(x)=wTϕ(x)+bf(x) = w^T \phi(x) + bf(x)=wTϕ(x)+b,使得f(x)f(x)f(x)与yyy的偏差不超过ϵ\epsilonϵ,同时保持函数尽量平坦。
优化问题为:
minw,b12∥w∥2+C∑i=1N(ξi+ξi∗)\min_{w,b} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^N (\xi_i + \xi_i^*)w,bmin21∥w∥2+Ci=1∑N(ξi+ξi∗)
s.t. {yi−wTϕ(xi)−b≤ϵ+ξiwTϕ(xi)+b−yi≤ϵ+ξi∗ξi,ξi∗≥0\text{s.t. } \begin{cases} y_i - w^T \phi(x_i) - b \leq \epsilon + \xi_i \\ w^T \phi(x_i) + b - y_i \leq \epsilon + \xi_i^* \\ \xi_i, \xi_i^* \geq 0 \end{cases}s.t. ⎩⎨⎧yi−wTϕ(xi)−b≤ϵ+ξiwTϕ(xi)+b−yi≤ϵ+ξi∗ξi,ξi∗≥0
4.2 多类支持向量机
SVM本质上是二分类器,扩展多类分类的方法主要有:
- 一对多(One-vs-Rest):为每个类别训练一个二分类器
- 一对一(One-vs-One):为每两个类别训练一个二分类器
- 多类SVM:直接修改优化目标,考虑所有类别
4.3 结构化SVM
用于结构化输出问题,如序列标注、解析树构建等,通过定义适当的损失函数和特征映射来处理复杂的输出结构。
5. 支持向量机的实践考虑
5.1 数据预处理与特征缩放
SVM对数据缩放敏感,特别是使用基于距离的核函数(如RBF核)时。常见的预处理方法:
- 标准化:将特征缩放到均值为0,方差为1
- 归一化:将特征缩放到[0,1]或[-1,1]区间
5.2 计算效率与大规模数据处理
传统SVM训练算法的时间复杂度约为O(n3)O(n^3)O(n3),空间复杂度约为O(n2)O(n^2)O(n2),难以处理大规模数据集。改进方法包括:
- 分解算法(如SMO)
- 随机梯度下降
- 近似核方法
- 分布式计算
5.3 模型解释性与特征重要性
虽然核SVM具有良好的分类性能,但模型解释性较差。提高解释性的方法:
- 使用线性核或可解释性强的核函数
- 分析支持向量的权重
- 使用模型无关的解释方法(如LIME、SHAP)
6. 支持向量机的局限性与挑战
- 计算复杂度:对于大规模数据集,训练时间较长,内存消耗大,限制了其在实际中的应用。
- 核函数选择:核函数及其参数的选择很大程度上依赖于经验和实验,缺乏系统的理论指导。
- 概率输出:标准SVM不直接提供概率输出,需要通过 Platt scaling 等额外方法进行校准。
- 多类分类:SVM本质上是二分类器,多类扩展需要额外的策略,增加了复杂性。
二。SVM模型应用于人脸分类
1. 数据加载与预处理
from time import timeimport matplotlib.pyplot as plt
from scipy.stats import loguniformfrom sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.metrics import ConfusionMatrixDisplay, classification_report
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
people_faces = fetch_lfw_peopletch()
# 从 LFW(Labeled Faces in the Wild)数据集中下载人脸图片
# min_faces_per_person=70 → 只保留至少有 70 张照片的人物
# resize=0.4 → 将图片缩小到原来的 40%,降低计算量
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# 获取数据集的基本形状信息
n_samples, h, w = lfw_people.images.shape # 样本数、高度、宽度# 机器学习使用拉平后的像素数据(忽略像素的空间位置信息)
X = lfw_people.data # 每张图片展平成一维向量
n_features = X.shape[1] # 特征数(像素个数)# 标签(人物 ID)
y = lfw_people.target
target_names = lfw_people.target_names # 人物姓名
n_classes = target_names.shape[0] # 类别数# 打印数据集大小信息
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)结果:
Total dataset size:
n_samples: 1288
n_features: 1850
n_classes: 7
从LFW(Labeled Faces in the Wild)数据集中加载人脸图像数据,并进行初步预处理。通过设置min_faces_per_person=70筛选出至少有70张图像的人物,确保每个类别有足够的样本;resize=0.4将图像缩小到原尺寸的40%,显著降低计算复杂度。随后,将图像数据展平为一维向量作为特征,提取对应的类别标签和人物名称,输出数据集的基本统计信息(样本数、特征维度和类别数)
2. 训练测试划分与数据标准化
# 划分训练集和测试集,比例 70% 训练 / 30% 测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2025
)# 数据标准化(均值为 0,方差为 1),有助于加快收敛并提升模型性能
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 用训练集拟合并转换
X_test = scaler.transform(X_test) # 用相同参数转换测试集
将数据集按7:3比例划分为训练集和测试集。采用StandardScaler对数据进行标准化处理,使每个特征的均值为0、方差为1。这一步骤至关重要,因为SVM对特征尺度敏感,标准化可以加速模型收敛并提升性能。注意测试集使用训练集拟合的缩放参数进行转换,避免数据泄露。
3. 主成分分析(PCA)降维
# 设定 PCA 要保留的主成分个数,这里是 100 个
n_components = 100# 记录开始时间,用于计算运行耗时
start = time()# 创建 PCA 对象并拟合训练数据
# 参数解释:
# n_components=n_components -> 保留的主成分数量
# svd_solver="randomized" -> 使用随机化 SVD 算法,加速计算(适合高维数据)
# whiten=True -> 白化处理,使得每个主成分的方差为 1(有助于后续分类器性能)
# .fit(X_train) -> 在训练集上拟合 PCA 模型,学习主成分方向
pca = PCA(n_components=n_components, svd_solver="randomized", whiten=True).fit(X_train)# 获取 PCA 学到的主成分(特征向量),并将它们还原成 h×w 的二维图像
# 这些主成分在脸部识别领域被称为 "eigenfaces"(特征脸)
eigenfaces = pca.components_.reshape((n_components, h, w))# 记录结束时间
end = time()# 使用训练好的 PCA 模型将训练集投影到主成分空间
# 得到的 X_train_pca 是降维后的特征表示
X_train_pca = pca.transform(X_train)# 同样地,将测试集投影到主成分空间
X_test_pca = pca.transform(X_test)# 输出整个 PCA 特征提取过程的耗时
print("finished in %0.3fs" % (end - start))使用PCA对高维图像特征进行降维,保留100个主要成分。设置whiten=True对主成分进行白化处理,使各维度方差归一化,有助于提升后续分类器性能。采用随机化SVD算法(svd_solver="randomized")提高计算效率。降维后将训练集和测试集分别投影到主成分空间,得到低维特征表示(X_train_pca和X_test_pca),同时提取特征脸(eigenfaces)用于可视化。
4. 支持向量机超参数优化
# 记录开始时间
start = time()# 定义超参数搜索范围 param_grid
# 这里使用的是 loguniform 分布(对数均匀分布),适合搜索跨度很大的超参数
# - "C" 是 SVM 的正则化参数,控制分类器对训练集的拟合程度
# - "gamma" 是 RBF 核函数的核宽度参数,影响单个样本的影响范围
# 范围:
# C: 从 1e3 到 1e5
# gamma: 从 1e-4 到 1e-1
param_grid = {"C": loguniform(1e3, 1e5),"gamma": loguniform(1e-4, 1e-1),
}# 创建一个随机搜索交叉验证器 RandomizedSearchCV
# - SVC(kernel="rbf", class_weight="balanced") :使用 RBF 核的支持向量机,类别权重平衡处理
# - param_distributions=param_grid :指定要搜索的参数分布
# - n_iter=10 :随机采样 10 组参数组合进行测试
clf = RandomizedSearchCV(SVC(kernel="rbf", class_weight="balanced"), param_grid, n_iter=10
)# 在训练集(PCA 降维后的特征)上拟合模型并进行超参数搜索
# X_train_pca:降维后的训练数据
# y_train:对应的标签
clf = clf.fit(X_train_pca, y_train)# 输出搜索过程耗时
print("finished in %0.3f" % (time() - start))# 输出搜索得到的最优模型(包含最佳参数 C 和 gamma)
print(clf.best_estimator_)使用随机搜索(RandomizedSearchCV)优化SVM的超参数(正则化参数C和RBF核参数gamma)。参数搜索范围设置为对数均匀分布(loguniform),涵盖合理的数值区间。采用带类别权重平衡(class_weight="balanced")的RBF核SVM,以处理类别样本量不均衡的问题。通过10次参数采样和交叉验证,寻找最优超参数组合。
5. 模型预测与评估
# 记录开始时间
start = time()# 使用训练好的分类器(clf)对测试集特征进行预测
# X_test_pca 是经过 PCA 降维的测试集数据
# y_pred 是预测得到的标签
y_pred = clf.predict(X_test_pca)# 输出预测过程耗时
print("finished in %0.3fs" % (time() - start))# 打印分类性能评估报告
# classification_report 会输出:
# - precision(精确率)
# - recall(召回率)
# - f1-score(F1 分数)
# - support(每个类别的样本数量)
# target_names 用于显示每个类别的真实名称(这里是人物姓名)
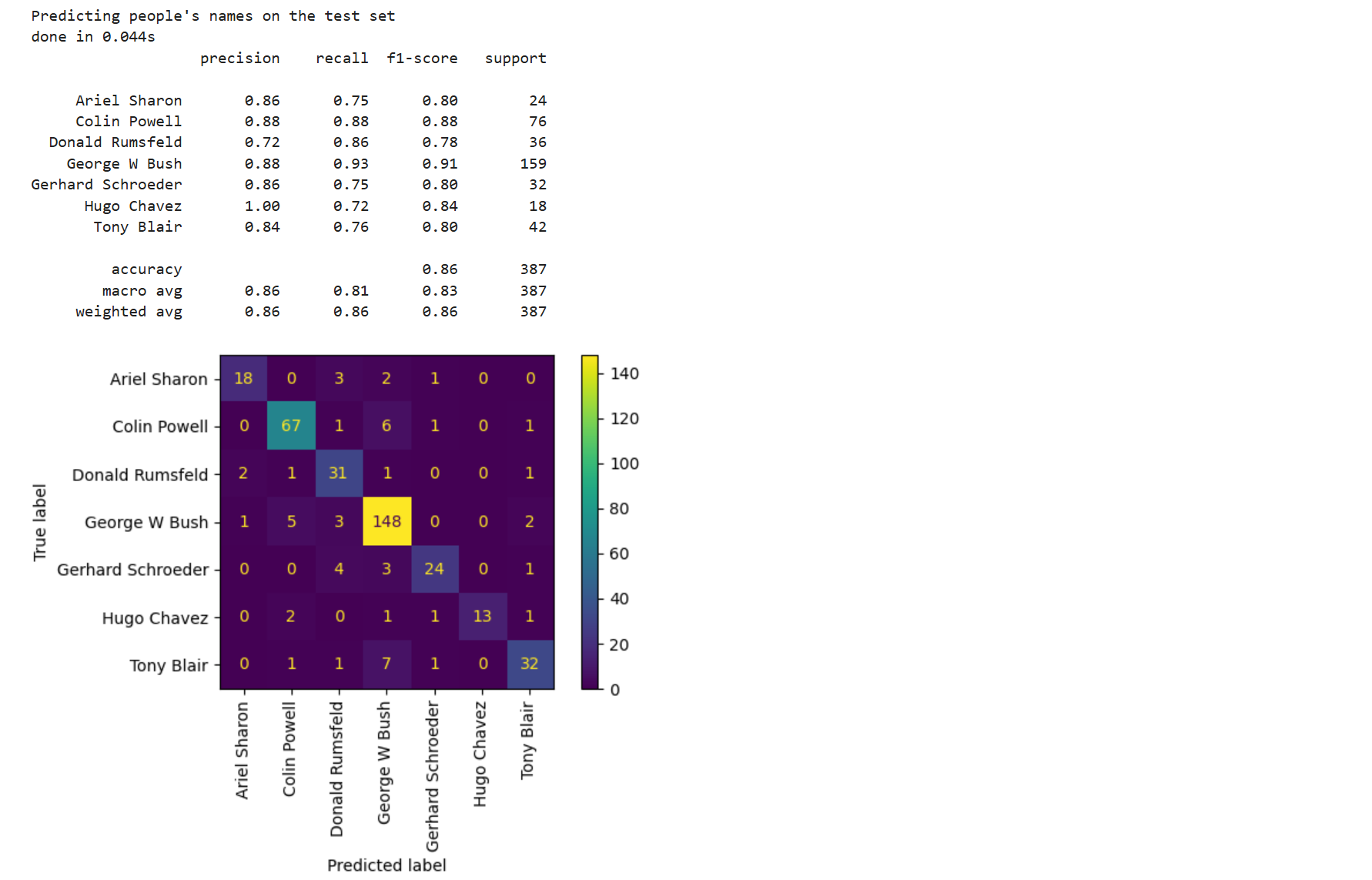
print(classification_report(y_test, y_pred, target_names=target_names))# 绘制混淆矩阵(Confusion Matrix)
# ConfusionMatrixDisplay.from_estimator 会:
# - 用分类器 clf
# - 输入测试集数据和真实标签
# - 自动计算混淆矩阵并绘制
# display_labels=target_names 用于显示真实的类别名称
# xticks_rotation="vertical" 让横轴标签竖直显示,防止文字重叠
ConfusionMatrixDisplay.from_estimator(clf, X_test_pca, y_test, display_labels=target_names, xticks_rotation="vertical"
)# 自动调整子图布局,避免文字或图像被遮挡
plt.tight_layout()# 显示绘制好的混淆矩阵图
plt.show()使用优化后的SVM模型对测试集进行预测,并输出详细分类报告(包括精确率、召回率、F1分数等指标)和混淆矩阵。混淆矩阵可视化展示了各类别的分类情况。
6. 预测结果标题生成与可视化
import matplotlib.pyplot as pltdef plot_gallery(images, titles, h, w, n_row=4, n_col=4):"""绘制图像网格(gallery)"""fig, axes = plt.subplots(n_row, n_col, figsize=(1.8 * n_col, 2.4 * n_row)) # 创建子图axes = axes.flatten() # 展平成一维,方便索引for i in range(n_row * n_col):axes[i].imshow(images[i].reshape((h, w)), cmap=plt.cm.gray) # 显示灰度图axes[i].set_title(titles[i], size=12) # 设置标题axes[i].set_xticks([]) # 去掉横坐标刻度axes[i].set_yticks([]) # 去掉纵坐标刻度plt.tight_layout() # 自动调整布局plt.show()定义plot_gallery函数,用于以网格形式展示多张图像。函数接受图像数据、标题列表和图像尺寸参数,自动创建子图布局,显示灰度图像并设置标题。
def title(y_pred, y_test, target_names, i):"""生成第 i 张图片的预测与真实标签标题"""pred_name = target_names[y_pred[i]].rsplit(" ", 1)[-1] # 预测姓名(取姓氏)true_name = target_names[y_test[i]].rsplit(" ", 1)[-1] # 真实姓名(取姓氏)return "predicted: %s\ntrue: %s" % (pred_name, true_name)# 生成预测结果标题列表
prediction_titles = [title(y_pred, y_test, target_names, i) for i in range(y_pred.shape[0])
]# 绘制测试集图片及预测结果
plot_gallery(X_test, prediction_titles, h, w)
根据预测结果和真实标签生成每张测试图像的标题,格式为“预测姓名/真实姓名”。仅使用人物姓氏(通过rsplit提取)简化显示。

7. 特征脸可视化
# 生成特征脸(Eigenfaces)标题
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]# 绘制特征脸
plot_gallery(eigenfaces, eigenface_titles, h, w)plt.show()
调用plot_gallery函数可视化PCA提取的前100个特征脸。特征脸反映了人脸图像的主要变化模式,是PCA降维的基础。
