LMCache:KV缓存管理
原文:http://www.hubwiz.com/blog/lmcache-kv-cache-management/amp/

LMCache不仅仅是一个KV缓存系统——它正在成为KV缓存系统。
从开源到企业,从Red Hat到Kubernetes再到NVIDIA和Moonshot,表现最好的LLM推理堆栈都在押注LMCache。如果你正在构建可扩展、高速或成本效益高的系统,那么可能也是时候这样做。
随着LLM的规模和使用量不断增加,有一件事是明确的:高效的键值(KV)缓存管理不再是可选的——而是必不可少的。
无论你是在运行一个长上下文聊天机器人、文档摘要器还是多租户API后端,性能都取决于你在计算节点之间如何管理KV缓存。在过去几个月里,这个领域出现了一个明显的领导者:LMCache.
为什么KV缓存比以往任何时候都更重要
现代基于Transformer的LLM如LLaMA、Mixtral和DeepSeek需要持久化的注意力键/值缓存来高效地处理长提示。但这些缓存是有代价的:GPU内存压力、重新计算延迟和路由复杂性。
这就是LMCache发挥作用的地方——一个专为LLM推理设计的分布式KV缓存引擎。它支持:
- 多GPU共享
- CPU卸载
- 分离计算(预填充/解码拆分)
- 持久化KV重用
- 前缀感知路由
它速度快、内存效率高,并且可以无缝集成到现有堆栈中。
谁在使用LMCache?
让我们看看一些最近的采用者和集成案例,这些案例巩固了LMCache作为该领域事实上的标准的地位:
1、vLLM
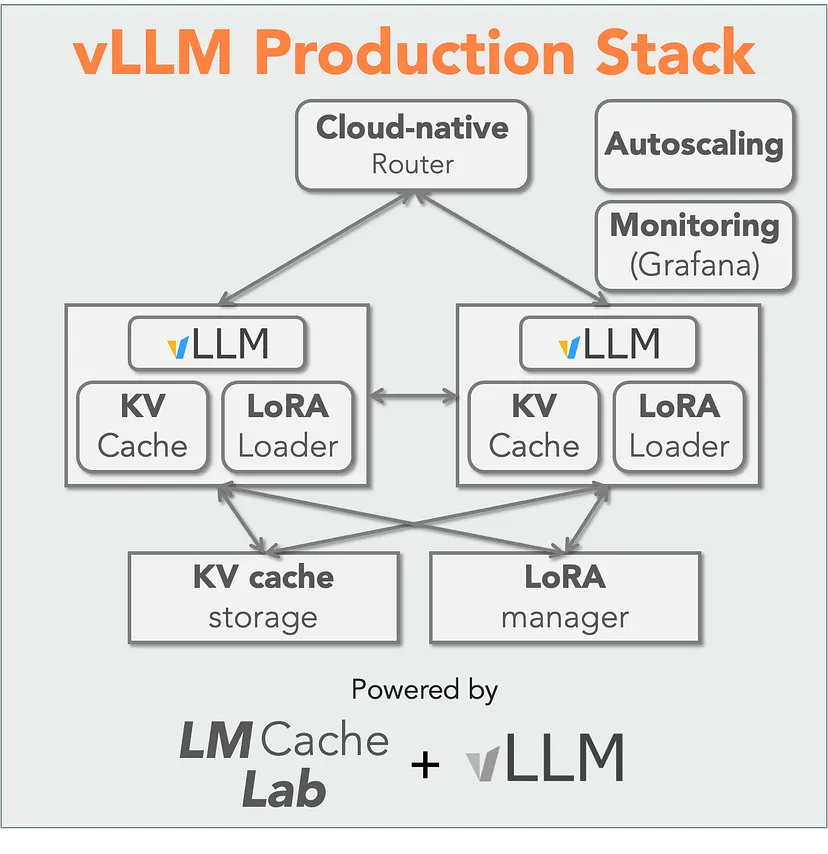
开源社区长期以来一直依赖于vLLM来进行快速、高效的LLM推理。但随着LMCache进入vLLM生产堆栈,性能水平达到了新的高度。通过支持分离的预填充和解码、多GPU对等KV共享和CPU卸载,vLLM + LMCache可以说是目前可用的最强大的开源推理堆栈。
企业级?检查。开源?检查。LMCache?当然。
2、KServe
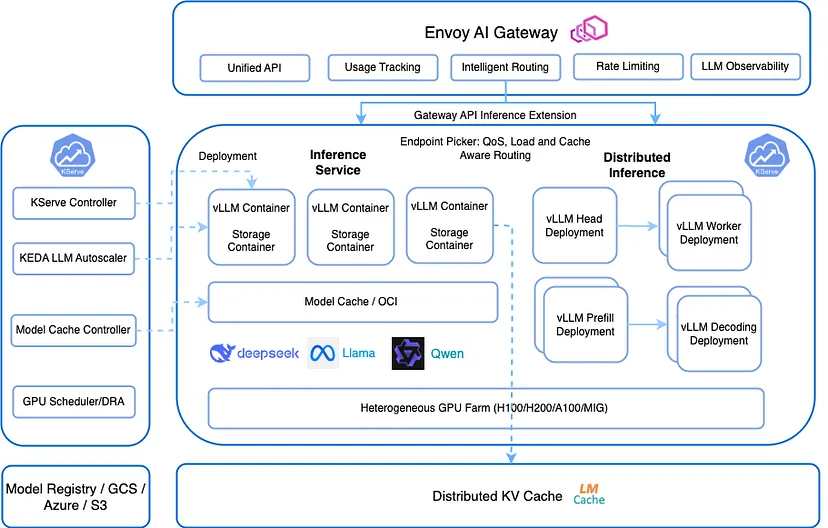
KServe在其0.15版本中集成了LMCach
在Kubernetes生态系统中,KServe是历史悠久的部署框架之一,最近在其0.15版本中增加了LMCache支持。这一添加使KServe能够以显著提高的吞吐量和延迟保证处理长上下文LLM工作负载——这对实时推理尤其关键。了解更多关于LMCache集成的信息这里。
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata: name: huggingface-llama3-lmcache
spec: predictor: minReplicas: 2 model: modelFormat: name: huggingface args: - --model_name=llama3 - --model_id=meta-llama/meta-llama-3-70b - --kv-transfer-config - '{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}' - --enable-chunked-prefill
3、Red Hat llm-d
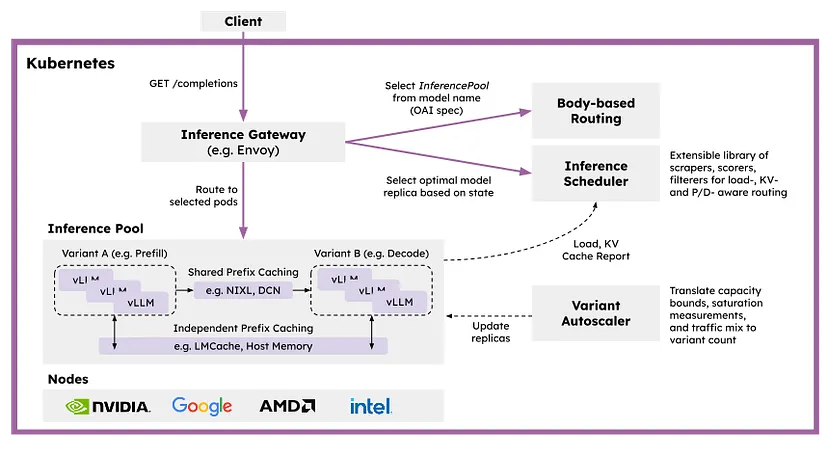
llm-d 使用 lmcache 提供可插拔的缓存用于之前的计算
Red Hat最近宣布的llm-d是一个专为分布式推理而设计的Kubernetes原生框架。在其架构中,最引人注目的部分就是——LMCache。
llm-d 使用与分离服务中使用的vLLM KV连接器API相同,为之前的计算提供可插拔缓存,包括将KVs卸载到主机、远程存储和像LMCache这样的系统。更多细节,请参阅他们的文档:llm-d Prefix Caching Northstar
4、NVIDIA Dynamo
甚至连NVIDIA也在投入。他们内部的推理系统Dynamo,使用LMCache作为现成的替代品,以提升KV缓存处理能力。有了LMCache,他们能够完全分离预填充和解码阶段,优化GPU计算周期,并更好地协调跨节点的推理调度。
5、Mooncake
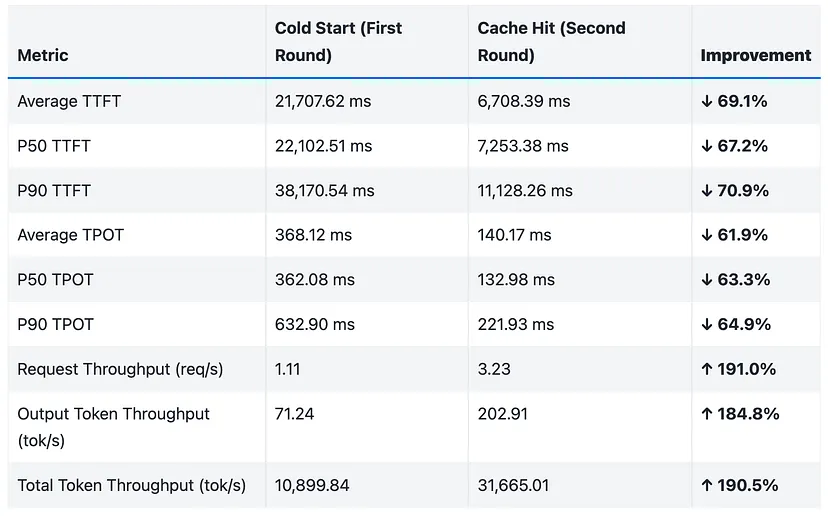
这些结果清楚地说明了LMCache和Mooncake的协作集成如何通过KV缓存重用显著提高延迟、吞吐量和整体系统效率。
LMCache还与Mooncake集成,这是一个面向Kimi的部署平台。Mooncake和LMCache共同创建了一个混合内存模型,提高了LLM部署系统的效率,使其能够处理各种工作负载并满足苛刻的延迟要求。
6、结束语
未来的LLM部署堆栈将是快速、分布和分离的。在那个未来,有效地管理KV缓存不再是可选的——而是基本要求。
原文链接:LMCache Is Becoming the De Facto Standard for KV Cache Management in LLM Inference