【Redis#10】渐进式遍历 | 数据库管理 | redis_cli | RES
一、渐进式遍历 – scan
📕 在 Redis 中,渐进式遍历 是一种 “分批次”地遍历大型数据集的机制 ,主要用于处理 KEYS、SCAN、SSCAN、HSCAN、ZSCAN 等命令。
它解决了传统一次性遍历带来的性能问题:一次性遍历大量数据会导致 Redis 阻塞,影响其他客户端请求响应时间。❗
- 比如:
keys *指令用于获取 Redis 中所有的 key,采用 遍历 的方式。但当 Redis 存储的 key 较多时,该操作可能会 阻塞 Redis,影响其他指令执行。【不推荐使用 KEYS 的原因🚫 】
为避免上述问题,可以使用 scan 指令进行渐进式遍历。这种方式可以在 不卡死服务器(不占用主线程过久) 的情况下获取所有 key,并且 每次执行命令只获取其中的一小部分数据,如果 key 较多,则需要多次执行 scan 命令,这样 保证 Redis 的高可用性和低延迟
1. 渐进式遍历的核心思想
Redis 使用 哈希表 + rehashing + 游标(cursor)机制 实现了非阻塞式的遍历方式。
你可以把它理解为:“一边走,一边看”,而不是一口气把所有东西都翻一遍。
底部实现原理如下:
Redis 内部使用 两个哈希表(ht[0] 和 ht[1]) 来实现动态扩容和 rehash,渐进式遍历 就是在这个基础上实现的:
- 初始游标
0表示从ht[0]的第一个桶开始。 - 每次遍历一部分 bucket,并返回下一个游标。
- 如果正在进行 rehash,则同时遍历
ht[0]和ht[1]。 - 当游标再次变为
0时,表示遍历结束。
2. Redis 支持渐进式遍历的命令
| 命令 | 描述 |
|---|---|
SCAN cursor [MATCH pattern] [COUNT count] | 遍历数据库中的 key |
SSCAN key cursor [MATCH pattern] [COUNT count] | 遍历 Set 中的元素 |
HSCAN key cursor [MATCH pattern] [COUNT count] | 遍历 Hash 中的字段 |
ZSCAN key cursor [MATCH pattern] [COUNT count] | 遍历 Sorted Set 中的元素 |
这些命令都会返回一个 新的游标值 ,用于下一次调用。
常见指令 - scan
语法:scan cursor [MATCH pattern] [COUNT count] [TYPE type]
功能:以渐进式方式对 Redis 中的所有键进行遍历。
- cursor:表示从哪个 光标 开始遍历。光标为 0 时,表示从头开始遍历。光标的概念不可以理解为 下标 ,它不是一个连续递增的整数,他只是一个普通的字符串在每次遍历后返回下次遍历开始的光标(若 返回的字符串是 0,说明遍历已经完成)。
- 可能程序员不理解,但是 Redis服务器是可以知道这个光标对应的元素的位置的.
- pattern:匹配指定模式的 key。
- count:限制每次返回的元素个数,默认为 10。需要注意的是,这里的 count 只是客户端给 Redis 服务器的一个 建议,具体返回多少取决于实际情况。
- type:指定 key 对应 value 的类型,包含 5 个通用类型和 5 个特殊场景使用的类型。
示例
# 第一次调用,从游标 0 开始
127.0.0.1:6379> SCAN 0 MATCH user:* COUNT 10
1) "15" # 新的游标值
2) 1) "user:1001"2) "user:1002"...10) "user:1010"# 第二次调用,使用上一次返回的游标值 15
127.0.0.1:6379> SCAN 15 MATCH user:* COUNT 10
1) "0" # 游标为 0 表示遍历完成
2) 1) "user:1011"2) "user:1012"...10) "user:1020"
- 注意:尽管
scan解决了阻塞问题,但在 遍历期间如果键有所变化(增加、修改或删除),可能会导致重复遍历或遗漏。
不仅仅是 Redis,遍历其他内容的时候,也是比较忌讳一边遍历一边修改的,比如:C++ STL 的遍历 + 修改/新增/删除 => 迭代器失效,如下:
std::vector<int> v = {1, 2, 3, 4};
for (auto it = v.begin(); it != v.end(); ++it) {v.erase(it);
}
- 注意!!这样的代码,就会导致“迭代器失效”。当删除完成之后,it 这个迭代器指向哪里,已经不知道了!
此时循环体结束之后再次 ++it,不一定就能指向下一个元素了,因此 在遍历过程中,不要一边遍历一边修改。
【C++ 中的迭代器在删除元素后可能会失效】
大部分编程语言中,++ 都是后置写的,C++ 更偏好前置 ++,原因如下:
- 在 C++ 里 前置 ++ 比后置 ++ 性能更高(少了一次临时对象的构造)
- Java 中 ++ 只是针对数字,数字本身无论是前置后置都是足够快。而 C++ 中 ++ 可能是针对一个对象(C++ 有运算符重载),不像 C++ 里可能就崩溃了
Redis 虽然不会给你崩溃,但是可能会出现 遗漏重复。
3. 渐进式遍历的特点
| 特性 | 描述 |
|---|---|
| ⏱️ 非阻塞 | 每次只返回一部分数据,避免长时间阻塞 Redis,适合 大数据集 |
| 📦 分批获取 | 可控制每次获取的数据量(通过COUNT参数),相当于分批次返回结果 |
| 🔁 可中断 | 可随时暂停或停止遍历,下次继续 |
| 📁 元素可能重复或遗漏 | 因为 Redis 是边遍历边修改的结构,所以可能会有重复或遗漏(不保证唯一性) |
| 🧩 适用于大数据 | 尤其适合键空间巨大、不能容忍阻塞的场景 |
4. 为什么 SCAN 不保证绝对一致性?
理解:在遍历过程中,不会在服务器中保存任何状态信息,如光标位置等。遍历可以随时终止,不会对服务器产生副作用。
- 就像我们去吃烧烤,如果有一部分烧烤还没有上来,我们就需要退款,这时候老板就到后厨看了一眼,说已经烤上了,退不了了。
- 再比如我们在遍历 Redis 服务器中的 key 的时候,遍历了一半,不想遍历了,但是这时候又取消不了,如果强行退出,这时候 服务器就会保存状态,这时候就会对服务造成一定的影响,这时候就相当于服务器保存了客户端的状态。
- 再比如我们去超市买东西,如果我们在结账的时候,发现钱没有带够,后面的东西不想要了,这时候 可以不扫后面的商品。
- 这时就像 Redis 中的渐进式遍历,没有保存之前遍历的状态,可以随时停止。
原因:因为 Redis 的 SCAN 是“基于快照的近似遍历 ”,它并不冻结数据。因此可能出现以下情况:
| 情况 | 是否可能 |
|---|---|
| 同一个 key 被返回多次 | ✅ 是 |
| 某些新增/删除的 key 被遗漏 | ✅ 是 |
| 所有 key 都被准确返回一次 | ❌ 否 |
这与你是否正在做 rehash、是否有写入操作有关。
5. 适用场景
| 场景 | 推荐使用 SCAN 系列指令 |
|---|---|
| 查看数据库中有哪些 key | ✅SCAN |
| 统计某个 Set 或 Hash 的全部内容 | ✅SSCAN/HSCAN |
| 定期清理或迁移数据 | ✅SCAN+ 匹配规则 |
| 大数据量下避免阻塞 | ✅ 必须使用 SCAN 替代 KEYS |
🔥 小结:Redis 的渐进式遍历是一种非阻塞、分批次、支持匹配模式的遍历方式,适用于大数据量下的安全访问,特别适合生产环境替代 KEYS、SMEMBERS 等一次性全量命令。
二、数据库管理
1. 多数据库支持(Multi-database)
🔥类似于 MySQL 中的 database 概念,Redis 中也有 database 的概念,但用户不能随意创建或删除数据库。Redis提供了几个面向Redis数据库的操作,分别是 dbsize、select、flushdb、flushall
说明:
- 许多关系型数据库,例如MySQL支持在⼀个实例下有多个数据库存在的,但是 与关系型数据库用字符来区分不同数据库名不同,Redis只是用数字作为多个数据库的实现
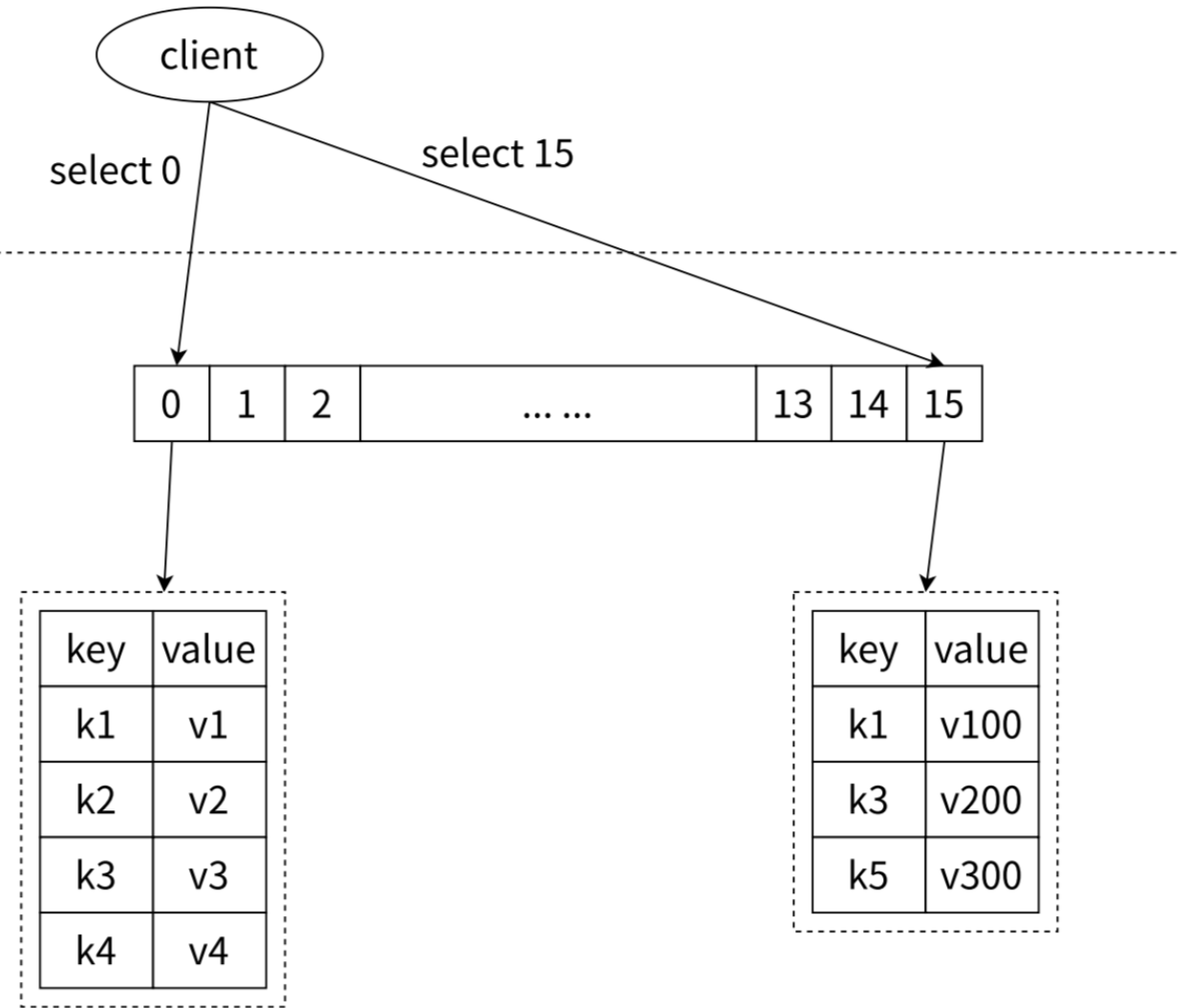
- Redis默认配置中是有 16 个数据库,可以以通过
SELECT <index>命令切换。- 比如:
select 0操作会切换到第一个数据库,select 15会切换到最后一个数据库
- 比如:
- 0号数据库和15号数据库 保存的数据是完全不冲突的,即各种有各自的键值对。默认情况下,我们处于数据库0
Redis 管理的数据库如下图:
- 选择数据库:可以通过
select dbIndex(例如select 1) 来切换数据库。 - 清除数据库:
flushdb:清除当前数据库中的所有数据。flushall:清除 Redis 服务器中的所有数据
示例如下:
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> SELECT 0
OK
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> keys *
(empty array)
🚫 警告:永远不要在线上环境 执行清除数据的操作,除非你想要体验“从删库到跑路”的操作。
💡 注意:Redis中虽然支持多数据库,但随着版本的升级,其实不是特别建议使用多数据库特性
-
如果真的需要完全隔离的两套键值对,更好的做法是维护多个Redis实例,而不是在⼀个 Redis实例中维护多数据库
-
这是因为本⾝Redis并没有为多数据库提供太多的特性,其次无论是否有多个数据库,Redis都是使用 单线程模型,所以彼此之间还是需要 排队等待命令的执行,同时多数据库还会让开发、调试和运维工作变得 复杂
实践中,始终使用 数据库0 其实是⼀个很好的选择
⚠️ 注意事项
- Redis 的“数据库”是命名空间级别的隔离,并不是真正的物理隔离。
- 所有数据库共享同一个内存池。
- 不适合用作生产环境的多租户隔离,建议通过部署多个 Redis 实例实现。
2. 数据持久化机制(Persistence)
Redis 是内存数据库,为了防止数据丢失,它提供了两种持久化方式:
- RDB(Redis Database Backup):【快照持久化:将某一时刻的数据保存为
.rdb文件】 - AOF(Append Only File):【日志持久化:记录所有写操作命令,重启时重放日志恢复数据】
🔁 混合模式(推荐):Redis 4.0+ 支持 AOF + RDB 混合持久化模式,兼顾性能与可靠性。
示例配置:
# 启用 RDB 快照
save 900 1
save 300 10
save 60 10000# 启用 AOF
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
3. 安全认证(Authentication)
Redis 提供了简单的密码认证机制,用于限制未授权访问。
- 为什么需要设置密码:避免 redis 的 key 变成 backup([解决redis的key都变成了backup,redis所有缓存被清空_)
注意事项
- 开启Redis的远程访问前,请确保已经配置了合适的防火墙规则,只允许受信任的IP地址访问Redis端口
- 考虑设置一个密码来增强安全性。可以在
/etc/redis/redis.conf中找到 requirepass 指令并设置一个强密码(需要重启 Redis) - 如果你的Redis服务器暴露在互联网上,建议使用SSL/TLS加密通信,以防止数据泄露
密码设置两种方式
① 在 redis.conf 中添加:
requirepass yourpassword# 连接后进行认证
AUTH yourpassword # 使用方式
② 不需要重启redis服务的密码设置方式
127.0.0.1:6379> config set requirepass 123456
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"# 退出重进
lighthouse@VM-8-10-ubuntu:~$ redis-cli
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> ping
PONG
注意:通过命令行修改了密码之后,配置文件的 requirepass 字段后面的密码是不会随之修改的。
三、redis-cli
前面学习的主要是各种 redis 的基本操作/命令,都是在 redis 命令行客户端 手动执行的。
- 但是这种操作方式不是我们日常开发中主要的形式更多的时候,是使用 redis 的 api,来实现定制化的 redis 客户端程序,进一步操作 redis 服务器。
- 相当于用程序来操作 redis
以前学习 MySQL 的时候~也会涉及到,关于使用程序来操作 MySQL 服务器
- C++:MySQL 原生 API
- Java:JDBC & MyBatis
redis 提供的命令行客户端 / 第三方的图形化客户端 …他们本质上都属于是“通用的客户端程序”
相比之下,在工作中更希望使用到的是 “专用的”“定制化”的客户端程序~
那么是不是表示前面学习的这些 redis 命令没有价值了呢? ==> 当然不是的!!【redis 命令相当于使用代码来执行】
使用:无论 C++还是 Java各自如何编程实现对应的 redis 客户端,其实要做的事情本质上是一样的~
- 注意:网上关于 redis 这块的编程,基本都是 Java 为主,难道是,其他语言不配操作 redis 嘛? ==> 当然不是!!!redis 能支持很多很多种编程语言

博主这里主要是基于 C++ 来讲解
四、RESP 自定义协议
1. 前言
网络通信中的协议层次:应用层、传输层(TCP / UDP 协议)、网络层(IP 协议)、数据链路层(以太网)、物理层【五层协议】
虽然业界有很多 成熟的应用层协议,如 HTTP,但在某些情况下,会“自定义”应用层协议
Redis 使用的就是一种自定义的应用层协议。客户端和服务器之间的交互:
- 客户端按照应用层协议发送请求;
- 服务器按照该协议解析请求,并根据请求构造响应;
- 客户端再解析从服务器返回的响应。
关于我们能否 自己 编写自定义 Redis 客户端:
直接基于未公开的协议去编写是不可行的。然而,对于 Redis 来说,其使用的自定义协议(即 RESP)是公开的。
就像一些开源项目通过逆向工程实现了 QQ 客户端一样,实现过程依赖于 开发者对协议的理解和技术水平。
自主 开发 Redis 客户端的前提:
- 需要 了解 Redis 的应用层协议(暗号),即 RESP 协议
- 由于 Redis 官方已经 公开 了这一协议规范,因此可以依据这些信息来 编写客户端
2. 基本概念
RESP(Redis Serialization Protocol) 是 Redis 客户端与服务端之间通信所使用的 应用层协议 ,它是一种 高效、简单、可读性强的二进制安全文本协议 。
✅ Redis 使用 RESP 来封装客户端发送的命令和服务器返回的结果。
RESP 的设计目标🔍
- 简单易实现
- 高效性:支持二进制安全传输
- 可读性强:使用 ASCII 编码,方便调试
- 易解析:结构清晰,易于编写客户端/服务端解析器
- 多种数据类型支持:支持字符串、整数、数组、错误、批量字符串等
与 TCP 的关系:
-
基于 TCP 传输,但不强耦合于 TCP。
-
请求-响应模型是 一问一答 的形式。
Redis 中的使用方式:
- 客户端发送命令到 Redis 服务器,服务器以 RESP 数组形式接收并处理。
- 根据命令的不同,服务器将以不同的 RESP 类型进行响应,例如:直接返回
ok、返回整数、返回数组…
3. RESP 支持的数据类型(前缀标识)
每种数据类型都用一个特定字符开头表示:
| 类型 | 前缀字符 | 示例 | 含义 |
|---|---|---|---|
| 简单字符串 | + | +OK\r\n | 不带空格的字符串(如状态响应) |
| 错误信息 | - | -ERR invalid password\r\n | 错误信息,客户端应抛出异常 |
| 整数 | : | :1000\r\n | 返回一个整数值(如 INCR 操作结果) |
| 批量字符串(Bulk String) | $ | $6\r\nfoobar\r\n | 表示长度为 6 的字符串 “foobar” |
| 数组 | * | *2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n | 表示包含两个元素的数组:[“foo”, “bar”] |
- Simple Strings:用于传输非二进制安全的文本字符串,开销最小。
- Bulk Strings:用于传输二进制安全的数据。
- 可以发现 resp 比 htttps 的设计简单不少~
开发提示:不需要手动解析或构造符合 RESP 规范的字符串,因为已有许多成熟的库支持这种操作。我们只需要 使用大佬们 提供的库,就可以比较简单方便的来完成和 redis 服务器通信的操作了
