构建AI智能体:三十二、LangChain智能体:打造会使用工具(Tools)、有记忆(Memory)的AI助手
一、LangChain的基础回顾
LangChain 是一个专门为大语言模型应用开发设计的开源框架。它提供了一套完整的工具和组件,帮助开发者构建基于大语言的复杂应用程序,如智能对话系统、知识问答平台、内容生成工具等。
LangChain 的设计基于几个关键理念:模块化、可组合性和扩展性。它将复杂的语言模型应用开发过程分解为多个独立的组件,每个组件负责特定的功能,开发者可以根据需要灵活选择和组合这些组件。基础内容可参考《构建AI智能体:十八、解密LangChain中的RAG架构:让AI模型突破局限学会“翻书”答题》

二、LangChain的核心组件
- 模型层Models:模型层是 LangChain 的基础,支持多种大语言模型接口。框架提供了统一的接口来访问各种模型服务,包括开源模型如 Llama 和 ChatGLM,以及其他云服务提供商的模型。这种设计使得在使用过程中轻松切换不同的模型,而无需重写大量代码。
- 提示管理 Prompts:提示管理组件负责构建和优化模型输入。它提供了模板系统,允许开发者创建结构化的提示,包含变量插值、示例选择和格式控制等功能。这使得提示工程更加系统化和可维护。
- 处理链 Chains:处理链是 LangChain 的核心抽象,允许将多个组件连接起来形成完整的工作流程。链可以是简单的线性序列,也可以是复杂的条件分支结构。框架提供了多种预构建的链,如问答链、摘要链和对话链,也支持自定义链的开发。
- 记忆系统 Memory:记忆系统负责维护应用的状态和历史信息。它提供了多种记忆类型:短期记忆保存当前会话的上下文,长期记忆存储重要的历史信息,向量记忆支持基于语义相似性的信息检索。这种多层次的记忆设计使得应用能够进行连贯的多轮对话。
- 代理机制Agents:代理机制使应用能够自主决策和使用工具。代理使用语言模型来分析用户请求,决定需要执行的操作,选择合适的工具,执行操作并处理结果。这种机制极大地扩展了语言模型的能力范围。
三、LangChain的工作流程图
1. 流程图
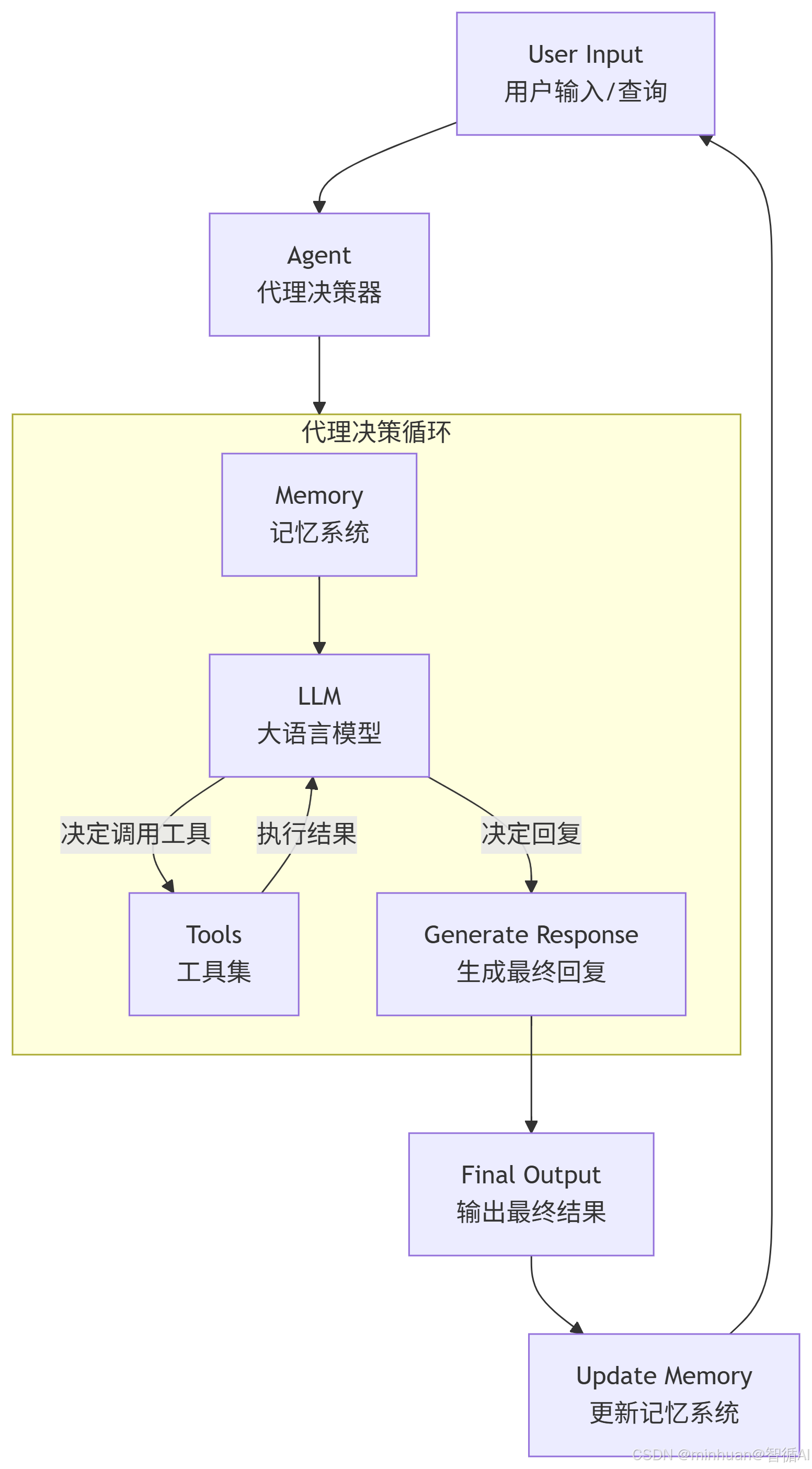
2. 工作流程
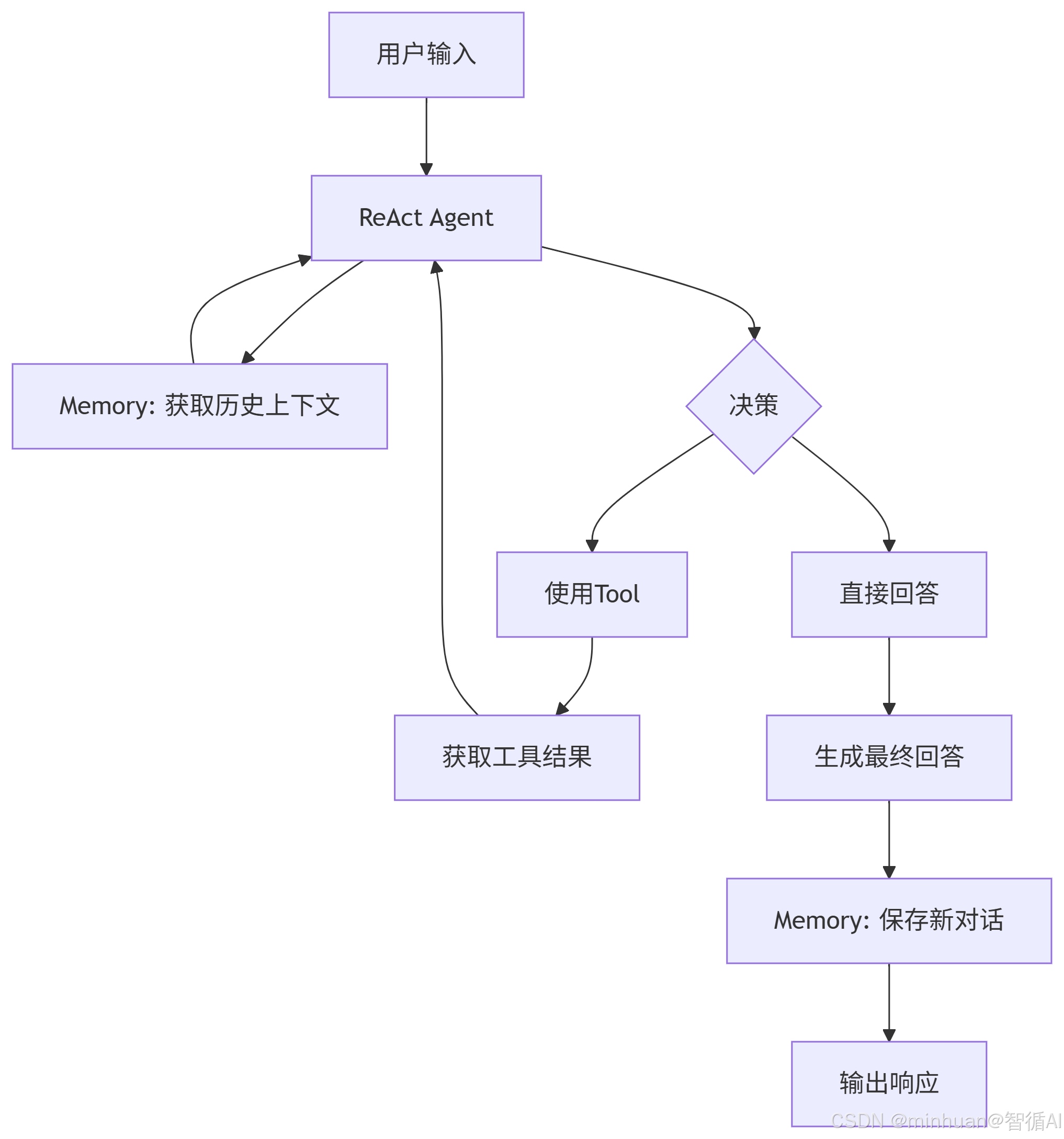
LangChain 将多个组件智能地串联起来,以完成复杂任务。其中最关键的角色是 Agent,它是整个工作流的大脑,负责协调和控制流程。上述流程可以分解为以下几个关键阶段:
2.1 输入与接收
- 流程始于用户的输入(一个问题或指令)。
- 这个输入被传递给 Agent。
2.2 决策与执行循环 - 核心部分
- Agent 咨询 Memory 来获取之前的对话上下文。
- Agent 将用户输入和记忆上下文一起提交给大模型,要求其进行思考。
- 大模型进行推理,并做出决策。这个决策通常是二选一:
- 决策 A:需要调用工具。 大模型会选择一个合适的 Tool,并生成该工具所需的输入参数。
- 决策 B:已有足够信息,可以直接回答。 大模型会生成最终回复。
- 如果选择了决策 A,Agent 会调用指定的 Tool 并传入参数。
- Tool 执行其功能(例如网络上搜索、运行一段代码、查询数据库等),并将执行结果返回给 Agent。
- Agent 再次将用户输入、历史上下文和最新的工具执行结果提交给大模型,让它基于新信息进行下一轮思考。
- 这个循环会持续进行,直到大模型认为已经收集到足够的信息,可以生成最终答案(决策 B)。
2.3 输出与记忆更新
- 一旦大模型决定生成最终答案,Agent 就会将这个结果输出给用户。
- 随后,系统会将本轮对话中有价值的信息(用户输入和AI输出)保存到 Memory 中,以确保下一次交互的连贯性。
3. 角色与职责
| 组件 | 角色 | 关键职责 |
| Input | 起点 | 接收用户提出的自然语言问题或指令 |
| Agent | 大脑 | 接收输入,统筹整个处理过程,决定执行步骤 |
| Memory | 记忆库 | 为 Agent 和大模型提供之前的对话历史或关键信息作为上下文 |
| 大模型 | 推理引擎 | 根据输入、记忆和上一步的观察进行推理,决定调用工具或直接回答 |
| Tools | 手脚 | 执行具体的任务(如计算、搜索、查数据库等),并将结果返回给大模型 |
| Output | 终点 | 输出最终生成的答案或结果给用户 |
| Update Memory | 闭环 | 将本轮有价值的对话内容保存下来,为后续交互提供上下文,实现连贯性 |
四、LangChain的功能特性
- 数据连接与检索:LangChain 提供了强大的数据连接能力,支持从各种数据源加载和处理信息。包括文档加载器、文本分割器、向量化处理和相似性检索等功能。这使得应用能够访问和利用外部知识库。
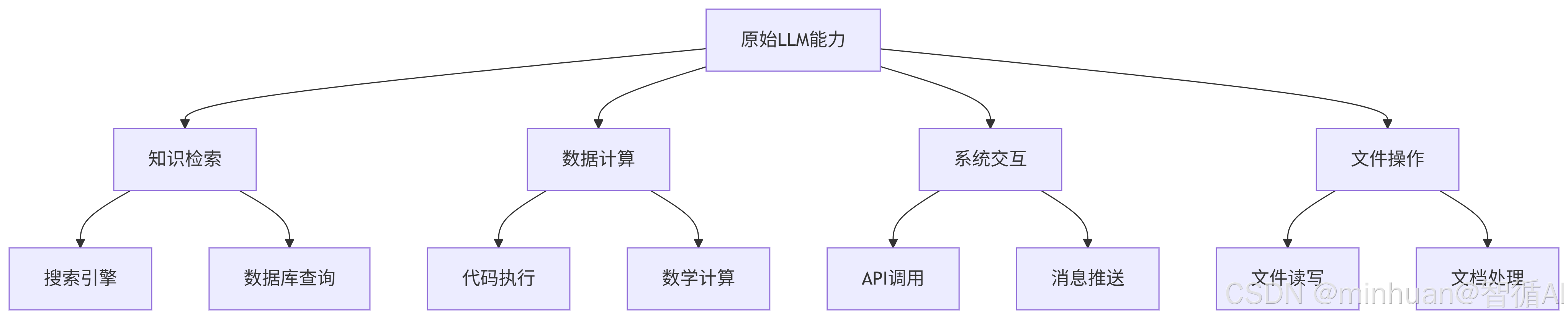
- 工具调用集成:框架支持扩展语言模型的能力 through 工具调用。可以创建自定义工具,或者使用预构建的工具集,如计算器、搜索引擎、API 调用等。工具调用机制使得语言模型能够执行实际的操作而不仅仅是生成文本。
- 回调与监控:LangChain 提供了完整的回调系统,能够监控应用的执行过程,记录日志,收集性能指标和处理异常。这对于调试和优化应用非常重要。
- 评估与优化:框架包含评估工具,可以测试和优化应用性能。支持自动化测试、质量评估和性能分析等功能。
五、LangChain Tools详解
1. 什么是 Tools
Tools 是 LangChain 中让语言模型与外部世界交互的接口。它们本质上是包装了特定功能的函数,为大模型提供超越其固有知识的能力,模型通过描述来理解这个工具能做什么,包含三个核心要素:
- 名称 (Name):工具的唯一标识符,用于区分不同工具
- 描述 (Description):功能说明,帮助 LLM 理解何时使用
- 执行函数 (Function):实际的功能实现代码
2. Tools 的核心特征
- 标准化接口:每个 Tool 都遵循统一的调用规范
- 自描述性:包含清晰的名称和功能描述
- 可组合性:多个 Tools 可以协同工作完成复杂任务
- 可扩展性:支持自定义和扩展新功能
3. Tools 的主要作用
- 实时信息获取:通过搜索工具访问最新信息
- 计算能力扩展:执行复杂数学计算和数据处理
- 外部系统集成:连接数据库、API 和其他服务
- 多模态支持:处理图像、音频等非文本数据
- 个性化实践:根据企业需求或用户偏好定制的专用功能
4. Tools 的基本结构
每个 Tool 包含三个基本要素:
class Tool:name: str # 工具的唯一标识符description: str # 功能的详细描述,用于LLM理解何时使用func: Callable # 实际执行功能的函数5. Tools 的工作原理

6. Tools 的分类体系
| 类别 | 代表工具 | 核心功能 | 应用场景 |
| 搜索检索类 | GoogleSearch, Wikipedia | 信息查询和获取 | 研究、事实核查 |
| 计算分析类 | PythonREPL, Calculator | 数据处理和计算 | 数据分析、科学计算 |
| 数据存储类 | SQLDatabase, CSVLoader | 数据库操作 | 业务系统集成 |
| API服务类 | Requests, OpenWeatherMap | 外部服务调用 | 第三方服务集成 |
| 文件操作类 | FileTool, DirectoryTool | 文件系统管理 | 文档处理、数据导入导出 |
7. Tools 总结
LangChain 的 Tools 系统为大型语言模型提供了强大的能力扩展机制,不仅突破模型限制,而且极大的增强应用能力。通过合理使用内置工具、开发自定义工具、实施有效的工具管理策略,可以构建出功能丰富、性能优异、稳定可靠的AI应用系统。关键成功因素包括:清晰的工具设计、完善的错误处理、性能优化措施以及持续的工具生态建设。
六、LangChain Memory详解
1. 什么是 Memory
Memory 是 LangChain 中用于存储和检索对话历史的组件,使 AI 应用能够记住先前的交互。它解决了大型语言模型固有的无状态问题,让对话能够保持上下文连贯性。核心功能包括:
- 维护对话历史,实现多轮对话
- 存储用户偏好和上下文信息
- 提高对话的相关性和准确性
- 减少重复信息请求,提升用户体验
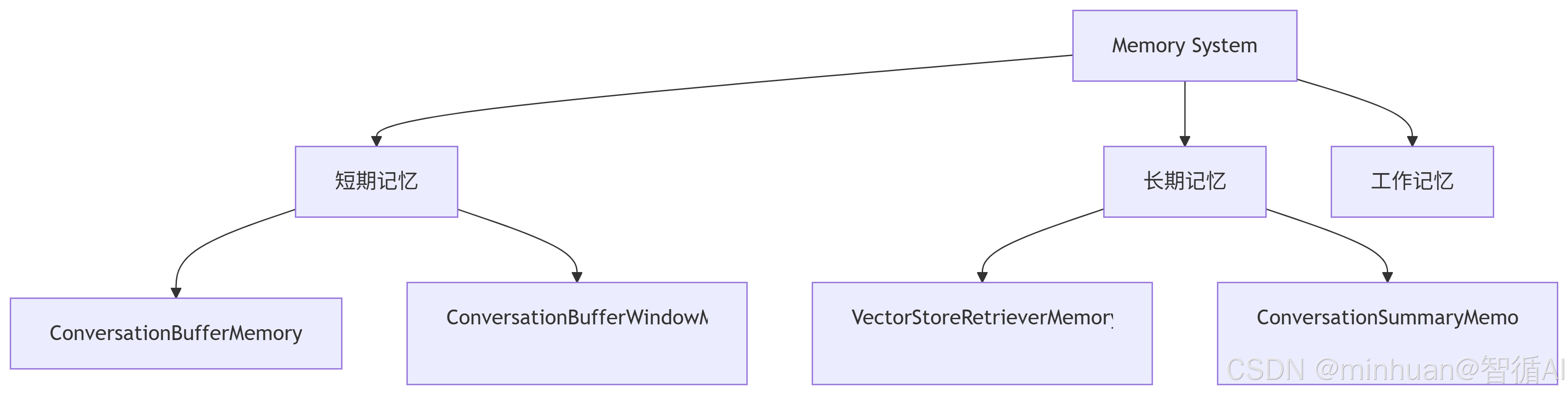
2. Memory 类型详解
2.1 ConversationBufferMemory
- 特点:最简单的内存类型,完整保存所有对话历史。
- 适用场景:对话较短,需要完整上下文的场景。
from langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory()
memory.save_context({"input": "你好"}, {"output": "你好!我是AI助手。"})
memory.save_context({"input": "你叫什么名字?"}, {"output": "我叫minhuan。"})# 查看内存内容
print(memory.load_memory_variables({}))
# 输出: {'history': 'Human: 你好\nAI: 你好!我是AI助手。\nHuman: 你叫什么名字?\nAI: 我叫minhuan。'}2.2 ConversationBufferWindowMemory
- 特点:只保留最近 K 轮对话,防止内存无限增长。
- 适用场景:长对话场景,避免token限制问题。
from langchain.memory import ConversationBufferWindowMemory# 只保留最近2轮对话
memory = ConversationBufferWindowMemory(k=2)
memory.save_context({"input": "你好"}, {"output": "你也好"})
memory.save_context({"input": "高兴遇见你"}, {"output": "也很高兴遇见你"})
memory.save_context({"input": "再见!"}, {"output": "好的,再见!"})print(memory.load_memory_variables({}))
# 输出: {'history': 'Human: 高兴遇见你\nAI: 也很高兴遇见你\nHuman: 再见!\nAI: 好的,再见!'}2.3 ConversationSummaryMemory
- 特点:使用大模型生成对话摘要,而不是存储完整历史。
- 适用场景:超长对话,需要压缩信息节省token的场景。
from langchain.memory import ConversationSummaryMemory
from langchain_community.chat_models.tongyi import ChatTongyillm = ChatTongyi(model="qwen-max", dashscope_api_key="你的API_KEY")
memory = ConversationSummaryMemory(llm=llm)# 添加多轮对话
for i in range(5):memory.save_context({"input": f"问题{i}: 关于天气的讨论"},{"output": f"回答{i}: 今天天气晴朗,温度适宜"})print(memory.load_memory_variables({}))
# 输出: {'history': '摘要: 对话主要讨论了天气情况,多次提到今天天气晴朗且温度适宜。'} 2.4 ConversationEntityMemory
- 特点:提取并记忆对话中的实体信息(人物、地点、事件等)。
- 适用场景:需要记住特定实体信息的对话场景。
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_EXTRACTION_PROMPT, ENTITY_SUMMARIZATION_PROMPTmemory = ConversationEntityMemory(llm=llm)# 添加包含实体的对话
memory.save_context({"input": "张三喜欢在北京工作"}, {"output": "北京是个好城市"}
)memory.save_context({"input": "李四在上海读书"}, {"output": "上海有很多好大学"}
)# 查看记忆的实体
print(memory.load_memory_variables({"input": "张三在哪里工作?"}))
# 输出会包含实体信息,如: {'history': '...', 'entities': {'张三': '张三喜欢在北京工作'}}2.5 VectorStoreRetrieverMemory
- 特点:将记忆存储在向量数据库中,通过语义检索回忆信息。
- 适用场景:大规模、长周期记忆管理,需要语义搜索的场景。
from langchain.memory import VectorStoreRetrieverMemory
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.schema import Document
import os# 初始化嵌入模型
# embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
embeddings = HuggingFaceEmbeddings(model_name="D:/modelscope/hub/models/sentence-transformers/paraphrase-MiniLM-L6-v2")# 创建或加载 FAISS 向量存储
persist_directory = "./faiss_db"if os.path.exists(persist_directory):# 如果存在已有的 FAISS 索引,则加载vectorstore = FAISS.load_local(persist_directory, embeddings, allow_dangerous_deserialization=True)print("已加载现有的 FAISS 向量数据库")
else:# 否则创建新的向量存储# 初始时可以添加一些空文档或示例文档initial_docs = [Document(page_content="初始文档", metadata={"type": "initial"})]vectorstore = FAISS.from_documents(initial_docs, embeddings)# 保存向量存储到本地vectorstore.save_local(persist_directory)print("创建了新的 FAISS 向量数据库")# 创建基于 FAISS 向量存储的记忆系统
memory = VectorStoreRetrieverMemory(retriever=vectorstore.as_retriever(search_type="similarity",search_kwargs={"k": 3} # 检索最相关的3条记忆)
)# 保存记忆
memory.save_context({"input": "我最喜欢的颜色是蓝色"}, {"output": "好的,已记住你喜欢的颜色"}
)# 保存更多记忆示例
memory.save_context({"input": "我来自北京"}, {"output": "北京是中国的首都,很繁华的城市"}
)memory.save_context({"input": "我喜欢吃苹果和香蕉"}, {"output": "水果很健康,已记住你的喜好"}
)# 回忆记忆 - 基于语义相似性搜索
query = "我喜欢什么颜色?"
memories = memory.load_memory_variables({"input": query})
print(f"查询: '{query}'")
print("检索到的记忆:", memories)# 测试另一个查询
query = "我来自哪里?"
memories = memory.load_memory_variables({"input": query})
print(f"\n查询: '{query}'")
print("检索到的记忆:", memories)# 保存向量存储的更改
vectorstore.save_local(persist_directory)
print("\n记忆已保存到FAISS数据库")3. Memory 分层架构
4. Memory 优化策略
- 分层存储:高频访问数据放内存,低频数据放持久存储
- 摘要压缩:使用大模型生成对话摘要节省空间
- 重要性筛选:基于关键词和上下文识别重要信息
- 定期清理:设置记忆过期时间和容量限制
5. Memory 总结
LangChain 的 Memory 系统为构建有状态的 AI 应用提供了强大基础。通过合理选择和组合不同的 Memory 类型,可以创建出能够理解上下文、记住用户偏好、并提供个性化体验的智能应用。
关键要点:
- 选择合适的 Memory 类型:根据应用场景选择最合适的 Memory 实现
- 组合使用:通过组合多种 Memory 类型实现复杂记忆功能
- 性能优化:注意记忆系统的性能影响,实施适当的优化策略
- 隐私保护:确保记忆管理符合隐私保护和数据安全要求
七、LangChain ReAct框架
1. 什么是 ReAct 框架
ReAct(Reasoning + Acting)是一个让大型语言模型能够进行推理并采取行动的框架。它是 LangChain 中 Agent(代理)的核心工作模式,使大模型不仅能够生成文本,还能智能地决定何时以及如何使用外部工具来解决问题。
2. ReAct 框架的核心思想
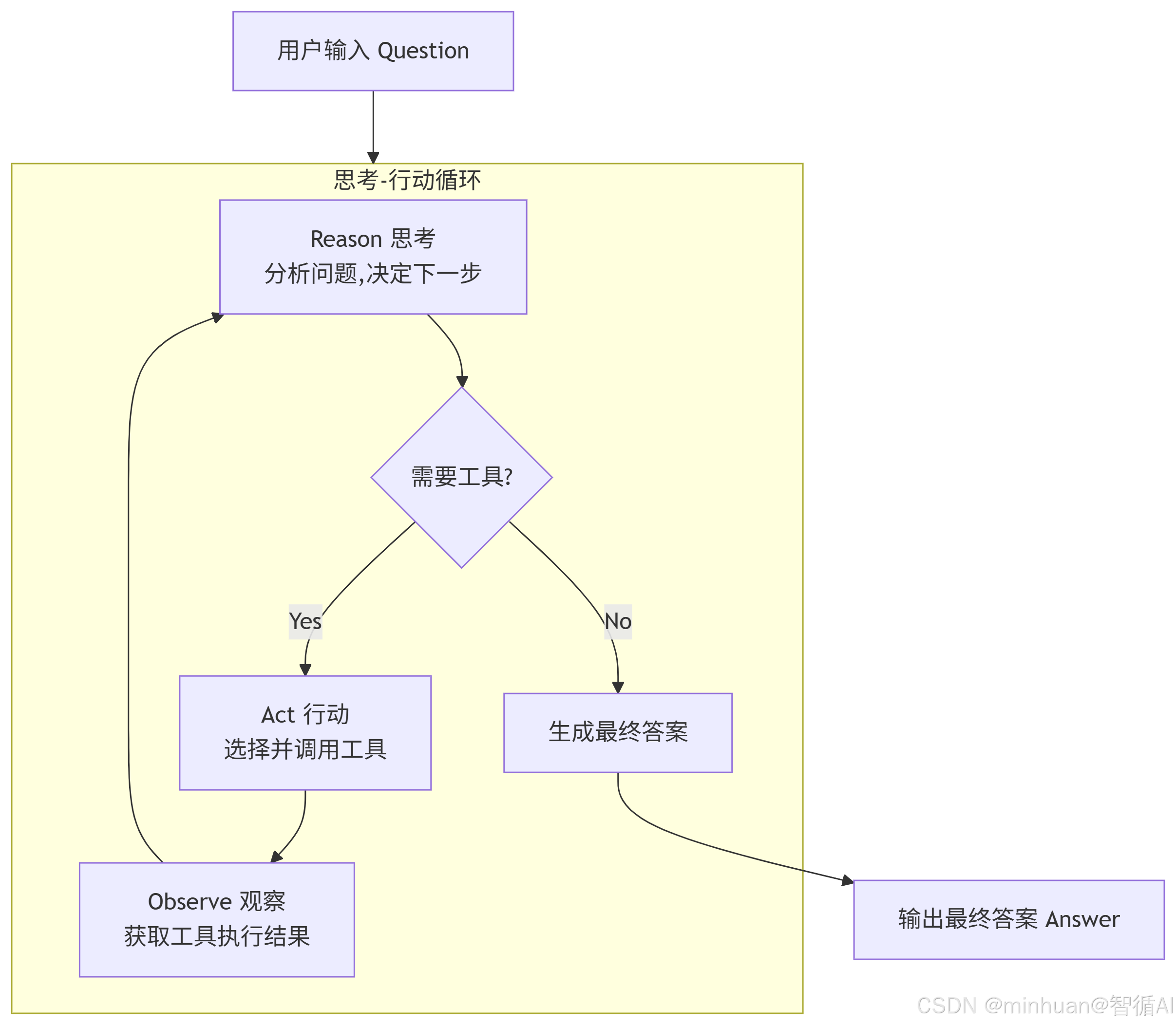
ReAct 框架的核心思想是模仿人类解决问题的过程:
- 思考(Think/Reason):分析当前情况,决定下一步该做什么
- 行动(Act):执行选定的动作(比如使用某个工具)
- 观察(Observe):查看行动的结果,然后继续思考
这个过程会循环进行,直到问题被解决。
3. ReAct 框架的工作原理
3.1 基本工作流程
3.2 结构化输出格式
ReAct 要求大模型按照特定格式进行输出,以便系统能够解析和执行:
Thought: [大模型分析当前情况,决定下一步行动]
Action: [要使用的工具名称]
Action Input: [工具的输入参数]
Observation: [工具执行的结果]...(这个循环可以重复多次)Thought: 我现在有最终答案了
Final Answer: [最终的回答]4. ReAct 框架的关键组件
- 代理(Agent)
- 代理是 ReAct 框架的"大脑",负责协调整个流程。它包含:
- 推理能力:分析问题并制定计划
- 决策能力:选择正确的工具和行动
- 协调能力:管理整个思考-行动循环
- 工具(Tools),工具是代理可以使用的"技能"或"手段",包括:
- 搜索工具或引擎
- 计算器、代码执行环境
- 数据库查询工具
- 自定义 API 接口
- 任何可以扩展大模型能力的外部系统
- 提示模板(Prompt Template)
- 指导大模型如何按照 ReAct 格式进行响应的模板,包含:
- 可用工具列表及其描述
- 输出格式要求
- 示例对话
4. ReAct 框架的流程示例
假设用户问:"1989年出生是多少岁了?然后在平方根是多少?"
ReAct 框架的处理过程:
- 第一轮循环
- Thought: 我需要使用工具吗?是的,我首先需要确定1989年出生的人在当前年份是多少岁。这要求我知道当前的年份。之后,我将计算该年龄的平方根
- Action: TimeGetter
- Action Input: "1989年出生是多少岁了"
- Observation: 36
- 第二轮循环
- Thought: 我计算了这个年龄(36岁)的平方根。
- Action: Calculator
- Action Input: sqrt(36)
- Observation: 6
- 最终步骤
- Thought: 我现在有所有信息,可以给出最终答案
- Final Answer: 1989年出生的人在2025年是36岁,其年龄的平方根大约为6.0。
八、三者协同工作机制
1. 协同工作流程
2. 综合示例:LangChain 多工具智能体
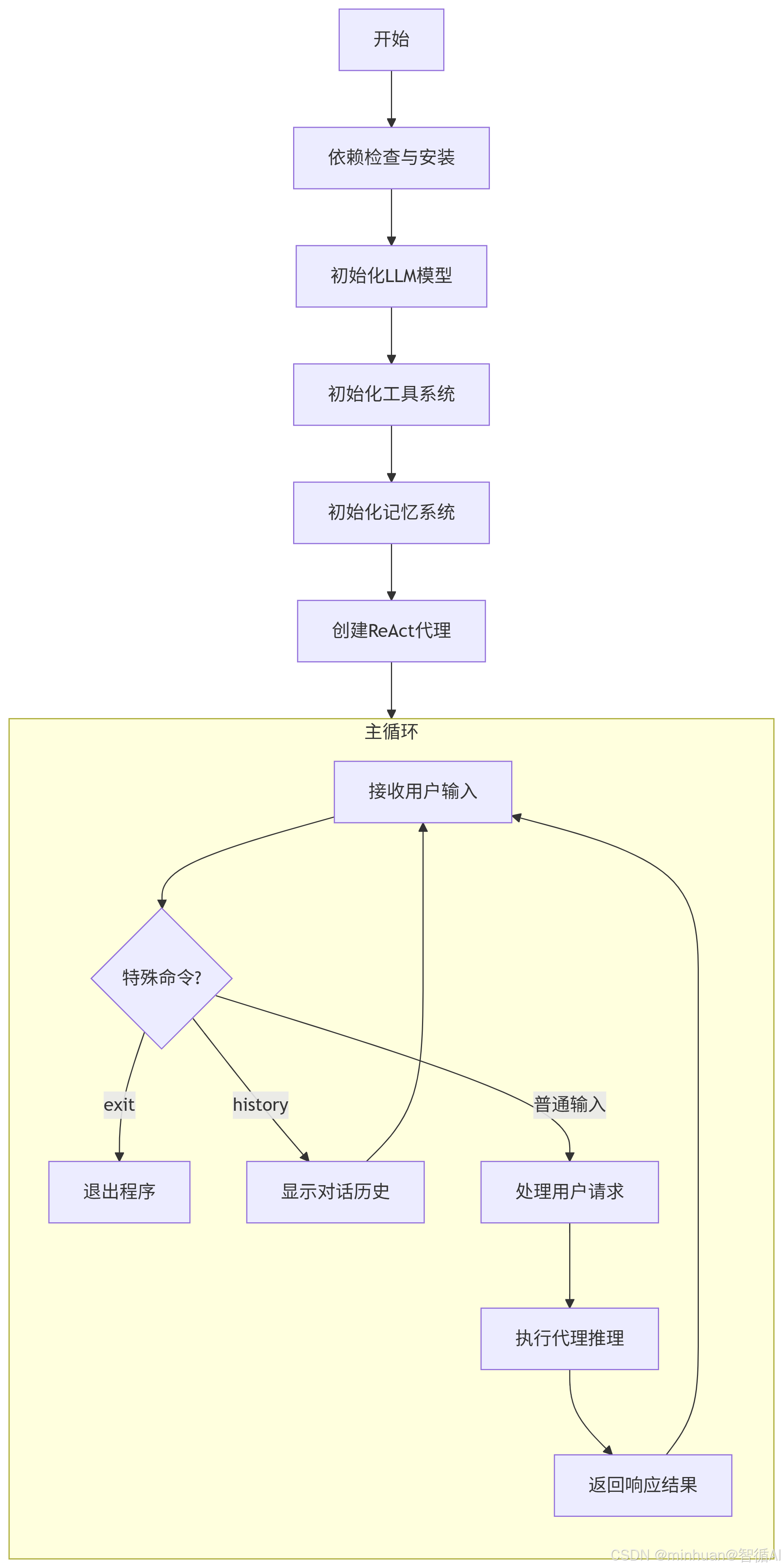
2.1 示例工作流程
2.2 代码分解
2.2.1 依赖管理与环境设置
def check_and_install_dependencies():"""检查并安装必要的依赖"""required_packages = ["langchain","langchain-community","langchain-core","dashscope","wikipedia","pydantic>=2.0.0","typing-extensions>=4.0.0"]# ... 检查并安装缺失的包- 自动检查运行所需的所有依赖包
- 提供友好的用户提示和自动安装功能
- 确保环境兼容性
2.2.2 大模型初始化与配置
def initialize_llm():"""初始化Qwen语言模型"""try:# 获取API密钥,如果环境变量不存在则提示用户api_key = os.environ.get("DASHSCOPE_API_KEY")if not api_key:print_formatted_log("WARNING", "环境变量 DASHSCOPE_API_KEY 未设置")print_formatted_log("INFO", "请输入通义千问API密钥:")api_key = input().strip()# ... 设置环境变量# 初始化模型llm = ChatTongyi(model="qwen-max",dashscope_api_key=api_key)return llmexcept Exception as e:logger.error(f"初始化语言模型失败: {str(e)}")raise- 灵活处理 API 密钥,通过环境变量或用户输入
- 使用通义千问的 qwen-max 模型
- 完善的错误处理和日志记录
2.2.3 工具系统实现
def initialize_tools(llm):"""初始化所有可用工具"""# 初始化 Wikipedia 工具(带错误处理)try:wikipedia_api_wrapper = WikipediaAPIWrapper()wikipedia_tool = WikipediaQueryRun(api_wrapper=wikipedia_api_wrapper)except ImportError as e:logger.warning(f"无法加载 Wikipedia 工具: {str(e)}")# 创建替代工具# 自定义工具custom_tools = [Tool(name="SquareRootCalculator",func=calculate_square_root,description="当需要计算一个数的平方根时使用此工具..."),Tool(name="StringReverser",func=reverse_string,description="当需要反转一个字符串时使用此工具。输入应该是一个字符串。"), Tool(name="TimeGetter",func=get_current_time,description="当需要获取当前日期和时间时使用此工具。输入可以是空字符串或任何内容。")# ... 其他工具]# 组合所有工具tools = []if wikipedia_tool:tools.append(wikipedia_tool)tools.extend(custom_tools)return tools- 内置工具(Wikipedia)与自定义工具的结合
- 完善的错误处理,工具不可用时的替代方案
- 每个工具都有清晰的名称、功能和描述
2.2.4 自定义工具函数
# 2. 自定义工具函数
def calculate_square_root(input_str):"""计算一个数的平方根"""logger.info(f"调用 calculate_square_root 工具,输入: {input_str}")try:number = float(input_str)result = math.sqrt(number)logger.info(f"计算平方根成功: {number} 的平方根是 {result}")return resultexcept ValueError:error_msg = f"输入 '{input_str}' 不是有效的数字"logger.error(error_msg)return error_msgdef reverse_string(input_str):"""反转字符串"""logger.info(f"调用 reverse_string 工具,输入: {input_str}")result = input_str[::-1]logger.info(f"字符串反转成功: '{input_str}' 反转为 '{result}'")return result- 自定义工具函数的具体实现
2.2.5 记忆系统实现
def initialize_memory():"""初始化对话记忆"""memory = ConversationBufferMemory(memory_key="chat_history", output_key="output", # 显式设置输出键return_messages=True)return memory- 使用 ConversationBufferMemory 保存完整对话历史
- 明确设置输出键以避免配置错误
- 支持多轮对话的上下文保持
2.2.6 ReAct 代理创建
def create_agent(llm, tools, memory):"""创建React Agent"""# ReAct 提示模板template = """
你是一个多功能AI助手,可以使用多种工具解决问题...
可用的工具:
{tools}
使用格式:
Thought: 我需要使用工具吗?...
Action: 要执行的动作...
Action Input: 工具的输入...
Observation: 工具执行的结果...
...
"""# 创建提示模板prompt = PromptTemplate(template=template,input_variables=["chat_history", "input", "agent_scratchpad"],partial_variables={"tool_names": ", ".join([tool.name for tool in tools]),"tools": "\n".join([f"{tool.name}: {tool.description}" for tool in tools])})# 创建代理执行器agent_executor = AgentExecutor(agent=create_react_agent(llm, tools, prompt),tools=tools,memory=memory,verbose=True,handle_parsing_errors=True,max_iterations=5, # 防止无限循环return_intermediate_steps=True # 避免回调错误)return agent_executor- 使用标准的 ReAct 框架格式(Thought/Action/Action Input/Observation)
- 清晰的提示工程,列出所有可用工具及其描述
- 安全限制,最大迭代次数防止无限循环
- 详细的执行日志,设置verbose=True
2.2.7 自定义回调系统
class CustomCallbackHandler(BaseCallbackHandler):"""自定义回调处理器,用于处理LangChain的回调事件"""def on_chain_start(self, serialized, inputs, **kwargs):"""链开始时的回调"""# 添加对 serialized 为 None 的检查if serialized is not None and hasattr(serialized, "get"):chain_type = serialized.get("name", "未知链")logger.info(f"开始执行链: {chain_type}")# ... 其他回调方法(on_tool_start, on_llm_start等)- 全面的回调处理,监控每个执行阶段
- 健壮的错误处理,检查None值
- 详细的日志记录,便于调试和监控
2.2.8 主程序与用户交互
def main():"""主函数"""# 初始化所有组件llm = initialize_llm()tools = initialize_tools(llm)memory = initialize_memory()agent_executor = create_agent(llm, tools, memory)# 主循环while True:user_input = input("\nYou: ").strip()if user_input.lower() == 'exit':break # 退出程序if user_input.lower() == 'history':# 显示对话历史history = memory.load_memory_variables({})if 'chat_history' in history and history['chat_history']:print_formatted_log("INFO", "对话历史:")for msg in history['chat_history']:role = "Human" if msg.type == "human" else "AI"print_formatted_log("DEBUG", f" {role}: {msg.content}")continue# 处理用户请求try:response = agent_executor.invoke({"input": user_input},{"callbacks": CallbackManager([CustomCallbackHandler()])})if "output" in response:print_formatted_log("SUCCESS", f"Assistant: {response['output']}")except Exception as e:logger.error(f"执行Agent时出错: {str(e)}")print_formatted_log("ERROR", f"执行失败: {str(e)}")- 完整的初始化流程
- 支持特殊命令,exit退出,history查看历史
- 健壮的错误处理,使用try-catch流程
- 使用自定义回调监控执行过程
2.2.9 使用示例
运行程序后,用户可以:
- 输入普通问题(如"计算256的平方根")
- 使用特殊命令:history查看对话历史 或 exit退出程序
- 观察代理的思考过程
这个实现展示了如何构建一个健壮、功能丰富的LangChain多工具智能体,适合作为更复杂应用的基础框架。
2.3 输出结果
启动成功的提示信息,供初始化了5个工具:
[INFO] ==================================================
[INFO] LangChain多工具智能体启动
[INFO] ==================================================
2025-09-13 14:12:04,249 - LangChainAgent - INFO - Qwen语言模型初始化成功
2025-09-13 14:12:04,250 - LangChainAgent - INFO - 开始初始化工具
2025-09-13 14:12:04,250 - LangChainAgent - INFO - 搜狗百科工具加载成功
2025-09-13 14:12:04,251 - LangChainAgent - INFO - 共初始化了 5 个工具
2025-09-13 14:12:04,251 - LangChainAgent - INFO - 工具 1: SogouBaikeSearch - 搜索搜狗百科的工具。输入应该是一个搜索查询。
2025-09-13 14:12:04,251 - LangChainAgent - INFO - 工具 2: SquareRootCalculator - 当需要计算一个数的平方根时使用此工具。输入应该是一个数字。
2025-09-13 14:12:04,252 - LangChainAgent - INFO - 工具 3: StringReverser - 当需要反转一个字符串时使用此工具。输入应该是一个字符串。
2025-09-13 14:12:04,252 - LangChainAgent - INFO - 工具 4: TimeGetter - 当需要获取当前日期和时间时使用此工具。输入可以是空字符串或任何内容。
2025-09-13 14:12:04,253 - LangChainAgent - INFO - 工具 5: RequestsGetTool - 当需要获取网页内容时使用此工具。输入应该是一个有效的URL,以http://或https://开头
。
2025-09-13 14:12:04,254 - LangChainAgent - INFO - 对话记忆系统初始化成功
2025-09-13 14:12:04,256 - LangChainAgent - INFO - React Agent创建成功
2025-09-13 14:12:04,257 - LangChainAgent - INFO - Agent执行器创建成功
[SUCCESS] 系统初始化完成,多工具AI助手已就绪
[INFO] 可用工具:
[INFO] 1. SogouBaikeSearch: 搜索搜狗百科的工具。输入应该是一个搜索查询。
[INFO] 2. SquareRootCalculator: 当需要计算一个数的平方根时使用此工具。输入应该是一个数字。
[INFO] 3. StringReverser: 当需要反转一个字符串时使用此工具。输入应该是一个字符串。
[INFO] 4. TimeGetter: 当需要获取当前日期和时间时使用此工具。输入可以是空字符串或任何内容。
[INFO] 5. RequestsGetTool: 当需要获取网页内容时使用此工具。输入应该是一个有效的URL,以http://或https://开头。
[INFO] 输入 'exit' 退出程序,输入 'history' 查看对话历史输入查询语句:1989年出生是多少岁了?然后在平方根是多少?
结果显示:
You: 1989年出生是多少岁了?然后在平方根是多少?
2025-09-13 14:13:03,194 - LangChainAgent - INFO - 用户输入: 1989年出生是多少岁了?然后在平方根是多少?
[INFO] 处理中...
2025-09-13 14:13:03,197 - LangChainAgent - INFO - 开始执行链: 未知链
Thought: 要回答这个问题,首先我需要计算1989年出生的人到现在(2023年假设)是多少岁了。这可以通过从当前年份减去出生年份来得到。之后,我还需要计算这个年龄的平
方根。为了获取当前年份,我将使用TimeGetter工具;然后利用得到的信息计算年龄,并最后通过SquareRootCalculator工具来求得该年龄的平方根。
Action: TimeGetter
Action Input: 2025-09-13 14:13:11,219 - LangChainAgent - INFO - 调用 get_current_time 工具
2025-09-13 14:13:11,220 - LangChainAgent - INFO - 当前时间: 2025年09月13日 14:13:11
2025年09月13日 14:13:11现在我们知道当前年份是2025年。接下来,我将用2025年来减去1989年来计算年龄。
\[ 年龄 = 2025 - 1989 \]
这将给出一个人如果在1989年出生的话到2025年的年龄是多少。然后,我会使用SquareRootCalculator工具来计算这个年龄的平方根。
Action: SquareRootCalculator
Action Input: 362025-09-13 14:13:15,690 - LangChainAgent - INFO - 调用 calculate_square_root 工具,输入: 36
2025-09-13 14:13:15,691 - LangChainAgent - INFO - 计算平方根成功: 36.0 的平方根是 6.0
6.0我现在已经知道了1989年出生的人到2025年的年龄是36岁,并且计算出了这个年龄的平方根为6.0。Final Answer: 一个1989年出生的人到2025年将是36岁,这个年龄的平方根大约是6.0。
2025-09-13 14:13:19,637 - LangChainAgent - INFO - 链执行完成,输出为字典类型> Finished chain.
[SUCCESS] Assistant: 一个1989年出生的人到2025年将是36岁,这个年龄的平方根大约是6.0。下面我直接输入一个网页地址,看看工具调用过程:
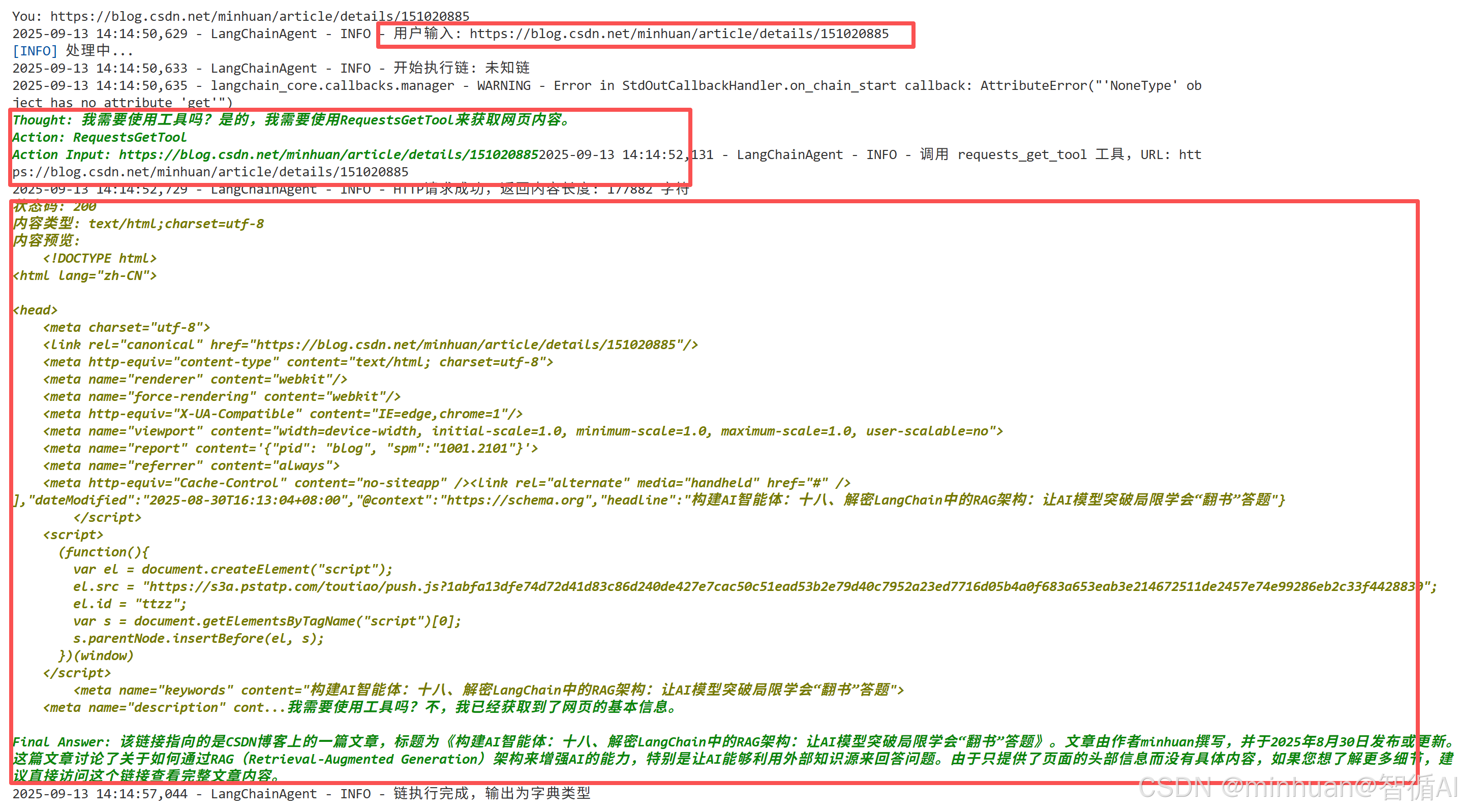
自动分析并使用了 RequestsGetTool工具,获取回来了网页内容;
接下来,继续输入指令“输出标题内容”,看看它是否产生了记忆,可以直接输出标题:
You: 输出标题内容
2025-09-13 14:19:52,281 - LangChainAgent - INFO - 用户输入: 输出标题内容
[INFO] 处理中...
2025-09-13 14:19:52,285 - LangChainAgent - INFO - 开始执行链: 未知链
Thought: 为了获取网页的具体标题内容,我需要使用RequestsGetTool工具来抓取页面信息。
Action: RequestsGetTool
Action Input: https://blog.csdn.net/minhuan/article/details/1510208852025-09-13 14:19:55,655 - LangChainAgent - INFO - 调用 requests_get_tool 工具,URL: https://blog.csdn.net/minhuan/article/details/151020885
2025-09-13 14:19:56,070 - LangChainAgent - INFO - HTTP请求成功,返回内容长度: 169991 字符
状态码: 200
内容类型: text/html;charset=utf-8
内容预览:<!DOCTYPE html>
<html lang="zh-CN">......<meta name="keywords" content="构建AI智能体:十八、解密LangChain中的RAG架构:让AI模型突破局限学会“翻书”答题"><meta name="description" cont...我已经找到了网页的标题内容。
Final Answer: 构建AI智能体:十八、解密LangChain中的RAG架构:让AI模型突破局限学会“翻书”答题-CSDN博客
2025-09-13 14:19:58,233 - LangChainAgent - INFO - 链执行完成,输出为字典类型基于上下文的记忆,完成了指令内容
九、总结
Tools、Memory和ReAct框架的协同工作构成了LangChain最强大的能力体现,三者通过精密的协作机制实现智能应用的完整功能闭环。在这个协同体系中,数据流遵循着精心设计的路径:
- 用户输入首先被ReAct Agent接收,
- Agent随即查询Memory系统获取相关历史上下文,
- 基于完整上下文进行推理并决策是否需要使用Tools,如果需要则选择最合适的Tool执行相应操作,Tool执行结果被返回给Agent进行进一步处理,
- 最终生成的回答既输出给用户又保存到Memory中丰富知识库。
这种协同机制的实际应用需要精心设计的架构,通常采用分层设计理念,包括:
- 工具层:各种功能Tools的实现
- 记忆层:短期和长期记忆管理系统
- 决策层:ReAct代理框架
- 接口层:对外提供服务的API和界面
性能优化策略也需要贯穿整个架构,包括Tools的异步执行和缓存机制、Memory的分层存储和压缩策略、以及ReAct的迭代控制和超时管理。监控和日志系统也至关重要,需要跟踪每个组件的性能指标和使用情况,为持续优化提供数据支持。这种精心设计的协同工作模式使得构建的AI应用不仅功能强大,而且高效可靠,能够处理各种复杂场景下的智能任务需求。