【Spring AI】Filter 简单使用
目录
关于Filter
Filter的操作符
基本使用步骤
结合RAG实战
注意
关于Filter
在 Spring AI 中,Filter 通常指 Filter.Expression(或其构建器 FilterExpressionBuilder),它用于在向量检索(如使用 VectorStore)时基于文档的元数据(metadata)进行条件过滤。这与向量相似度搜索结合,形成混合检索模式,既考虑语义相似度,也满足业务条件。
Spring AI 主要通过 FilterExpressionBuilder 来构建复杂的过滤表达式
主要应用场景
-
属性过滤:例如,只检索某个分类、某个作者或某个时间段的文档。
-
权限控制:例如,只检索用户有权限访问的文档。
-
业务逻辑约束:例如,只检索已发布状态的文章。
Filter的操作符
| 操作符 | 方法名 | 说明 | 示例(假设) |
|---|---|---|---|
== | eq | 等于 | b.eq("category", "news") |
!= | ne | 不等于 | b.ne("status", "draft") |
> | gt | 大于 | b.gt("publishDate", "2024-01-01") |
>= | gte | 大于等于 | b.gte("rating", 4.5) |
< | lt | 小于 | b.lt("price", 100) |
<= | lte | 小于等于 | b.lte("viewCount", 1000) |
IN | in | 在集合中 | b.in("tag", "tech", "ai") |
NIN | nin | 不在集合中 | b.nin("lang", "cn", "en") |
AND | and | 逻辑与 | b.and(b.eq("a", "1"), b.gt("b", 2)) |
OR | or | 逻辑或 | b.or(b.eq("x", "a"), b.eq("x", "b")) |
NOT | not | 逻辑非 | b.not(b.eq("status", "deleted")) |
基本使用步骤
-
构建 SearchRequest:使用
SearchRequest.query(your_query_string)创建搜索请求。 -
创建 FilterExpression:使用
FilterExpressionBuilder构建过滤条件。 -
设置过滤条件:通过
SearchRequest的withFilterExpression()方法设置过滤表达式。 -
执行搜索:调用
VectorStore.similaritySearch(SearchRequest)方法执行检索。
简单使用过滤条件:
@Service
public class DocumentSearchService {@Autowiredprivate VectorStore vectorStore;public List<Document> searchRecentTechNews(String userQuery) {// 1. 创建 FilterExpressionBuilderFilterExpressionBuilder b = new FilterExpressionBuilder();// 2. 构建过滤表达式: (category == "tech" OR category == "ai") AND publishYear >= 2023 AND status != "draft"Filter.Expression expression = b.and(b.and(b.or(b.eq("category", "tech"),b.eq("category", "ai")),b.gte("publishYear", 2023)),b.ne("status", "draft")).build();// 3. 创建搜索请求,设置查询语句、返回数量(topK)和过滤表达式SearchRequest searchRequest = SearchRequest.query(userQuery).withTopK(10).withSimilarityThreshold(0.7).withFilterExpression(expression);// 4. 执行搜索List<Document> results = vectorStore.similaritySearch(searchRequest);return results;}
}结合RAG实战
在 RAG(Retrieval-Augmented Generation)应用中,Filter 常与 QuestionAnswerAdvisor 或 RetrievalAugmentationAdvisor 结合使用,在检索阶段注入业务过滤逻辑。
需求:跟据用户的提示词和过滤条件,筛选出合适的文档Document
比如Document类的metadata,这就是一个hashMap,用来存储每篇文档的元数据:

可能的数据如下,可以这篇文章看到有四个元数据:
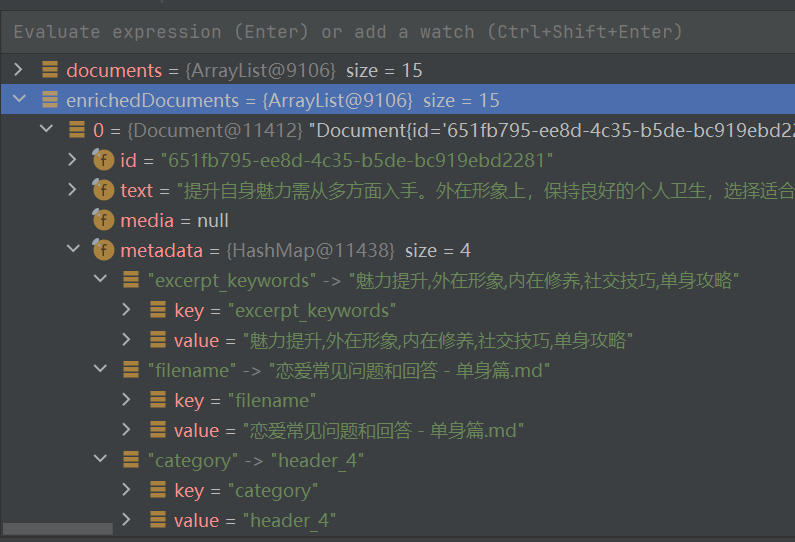
而我们要的Filter就是基于上面的这四个元数据展开过滤,比如我现在就要过滤filename元数据,规定字段"filename"的值不能包含参数filename:
Filter.Expression expression = new FilterExpressionBuilder().nin("filename", filename) // 添加不包含条件:字段"filename"的值不能包含参数filename.build(); // 构建过滤表达式这样,一个简单的过滤条件就搞定了,我们还可以将这个过滤器放到文档检索器里面,同时设置一些参数,:
// 创建文档检索器,配置检索参数// VectorStoreDocumentRetriever是DocumentRetriever的一个实现类DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder().vectorStore(vectorStore) // 设置向量存储源.filterExpression(expression) // 设置过滤条件:按状态过滤文档.similarityThreshold(0.5) // 设置相似度阈值:只返回相似度大于0.5的文档(0-1范围).topK(3) // 设置返回文档数量:最多返回3个最相关的文档.build(); // 构建DocumentRetriever实例我们可以再顺手将这个文档检索器放进检索增强顾问RetrievalAugmentationAdvisor里面,自动返回一个Advisor:
// 创建并返回检索增强顾问// 该顾问将在AI生成回答时,自动从vectorStore中检索相关文档作为上下文return RetrievalAugmentationAdvisor.builder().documentRetriever(documentRetriever) // 设置文档检索器.build(); // 构建RetrievalAugmentationAdvisor实例将上面的代码封装成一个类,也叫自定义的 RAG 检索增强顾问类,里面的主要方法的参数是VectorStore(向量存储实例)和String(要过滤的条件),然后我们在需要的地方使用ChatClient的adviosors()方法进行调用即可:
chatClient.prompt().user().advisors(填入你的检索增强顾问).call().chatResponse();如果对ChatClient不明白怎么用的话可以看看我之前的文章【Spring AI】ChatClient 使用详解-CSDN博客
注意
-
元数据键的命名:确保过滤条件中使用的元数据键(如
"category")与存入VectorStore的Document元数据键一致。 -
值的类型:过滤时,值的类型(字符串、数字、布尔值)应与元数据中存储的类型匹配。
-
底层向量数据库的支持:不同的向量数据库(如 Elasticsearch6、Redis、Pgvector)对过滤操作符的支持度和语法可能有细微差异。Spring AI 的
FilterExpressionBuilder会尽力转换为底层数据库的查询语法,但极端复杂的情况仍需测试。
看到这里了,如果对你有帮助,可以点个赞么~