Vision Transformer (ViT) :Transformer在computer vision领域的应用(二)
METHOD,论文主要部分
In model design we follow the original Transformer (Vaswani et al., 2017) as closely as possible. An advantage of this intentionally simple setup is that scalable NLP Transformer architectures – and their efficient implementations – can be used almost out of the box.
论文一上来就强调了,ViT基本上就是采用的原始Transformer结构。接下来的一句中的几个关键点:
- intentionally simple setup,简单化设计。指的就是直接使用Transformer结构,而没有做其他的适配性的结构改造,强调模型的简洁性。
- out of the box,强调开箱可用。
ViT模型架构
这一节一上来就放了模型架构图:
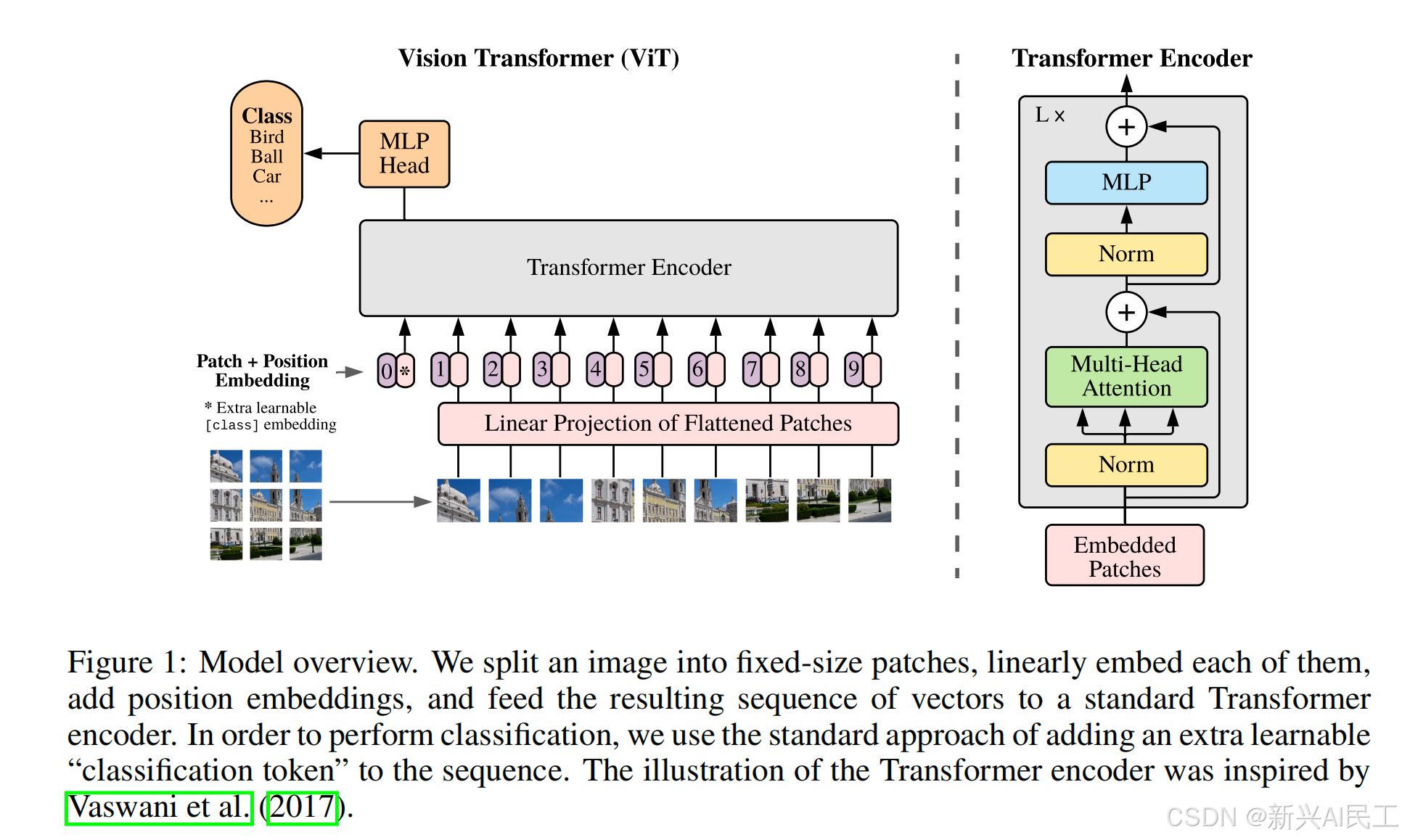
- 论文一上来就说了Transformer在图像领域最关键的问题,如何把一个2D图像(包含多通道)变成一个一维的数据:The standard Transformer receives as input a 1D
se