【大语言模型 58】分布式文件系统:训练数据高效存储
分布式文件系统:训练数据高效存储
关键词:分布式文件系统、HDFS、Lustre、GlusterFS、数据本地性、I/O优化、存储架构、大数据存储、训练数据管理、存储性能调优
摘要:本文深入探讨大语言模型训练中的分布式文件系统技术,从存储架构设计到性能优化策略,全面解析HDFS、Lustre、GlusterFS等主流方案的技术特点与应用场景。通过数据本地性优化、I/O瓶颈识别、缓存策略设计等实战技术,帮助读者构建高效可靠的训练数据存储系统,为大规模AI训练提供坚实的存储基础。
文章目录
- 分布式文件系统:训练数据高效存储
- 引言:为什么大模型训练需要分布式文件系统?
- 大模型训练的存储挑战
- 第一部分:分布式文件系统基础架构
- 分布式存储的核心概念
- 架构设计模式
- 数据分布策略
- 第二部分:主流分布式文件系统深度对比
- HDFS:Hadoop生态的存储基石
- HDFS架构详解
- HDFS的优势与局限
- Lustre:高性能计算的首选
- Lustre架构组件
- Lustre的性能特点
- GlusterFS:软件定义存储的代表
- GlusterFS核心特性
- 存储卷类型
- 三大文件系统对比分析
- 第三部分:数据本地性优化策略
- 数据本地性的重要意义
- 数据本地性的层次
- 数据放置策略
- 任务调度优化
- 预取和缓存策略
- 第四部分:I/O瓶颈识别与性能优化
- I/O性能监控体系
- 存储层次优化
- 缓存策略优化
- 网络优化策略
- 第五部分:备份与容灾机制
- 数据备份策略
- 容灾恢复机制
- 第六部分:性能调优实战案例
- 案例一:大规模语言模型训练的存储优化
- 案例二:多模态模型训练的存储挑战
- 第七部分:未来发展趋势
- 新兴存储技术
- 云原生存储演进
- 总结与最佳实践
- 关键技术要点
- 实施建议
- 性能优化检查清单
引言:为什么大模型训练需要分布式文件系统?
想象一下,你正在训练一个拥有千亿参数的大语言模型。训练数据集包含数TB甚至数PB的文本数据,分布在成百上千个GPU节点上进行并行训练。这时候,一个关键问题浮现出来:如何让所有计算节点都能高效、可靠地访问到所需的训练数据?
传统的单机文件系统显然无法胜任这个任务。我们需要的是一个能够:
- 横向扩展:随着数据量增长,存储容量和性能能够线性扩展
- 高可用性:单点故障不会影响整个训练流程
- 高并发访问:支持数千个计算节点同时读取数据
- 数据本地性:尽可能让计算任务在数据所在的节点执行
这就是分布式文件系统存在的意义。它不仅仅是存储数据的容器,更是大规模AI训练的神经系统,连接着计算资源和数据资源。
大模型训练的存储挑战
在深入技术细节之前,让我们先理解大模型训练面临的存储挑战:
数据规模挑战:现代大语言模型的训练数据集动辄数TB到数PB。GPT-3的训练数据约45TB,而更大的模型需要更多数据。这些数据需要被高效地组织、存储和访问。
并发访问挑战:在分布式训练中,可能有数千个GPU同时需要访问训练数据。传统存储系统的I/O带宽很快就会成为瓶颈。
容错性挑战:大规模训练可能持续数周甚至数月。在如此长的时间内,硬件故障是不可避免的。存储系统必须能够在部分节点失效的情况下继续工作。
成本效益挑战:存储成本在整个训练成本中占据重要比例。如何在保证性能的同时控制成本,是一个重要的工程问题。
第一部分:分布式文件系统基础架构
分布式存储的核心概念
分布式文件系统的本质是将数据分散存储在多个物理节点上,同时提供统一的文件系统接口。这种设计带来了几个关键优势:
水平扩展性:通过增加更多存储节点来扩展容量和性能,而不是升级单个节点的硬件。这种扩展方式更加经济高效。
容错能力:通过数据复制和分布,即使部分节点失效,系统仍能正常工作。这对于长时间运行的训练任务至关重要。
负载分散:I/O负载分散到多个节点,避免了单点瓶颈。这对于高并发的训练场景特别重要。
架构设计模式
主流的分布式文件系统通常采用以下几种架构模式:
主从架构(Master-Slave):
- 一个或多个主节点负责元数据管理
- 多个从节点负责实际数据存储
- 客户端通过主节点获取元数据,直接与从节点交互进行数据传输
- 典型代表:HDFS、GFS
对等架构(Peer-to-Peer):
- 所有节点地位平等,都可以存储数据和元数据
- 没有单点故障风险
- 但一致性维护更加复杂
- 典型代表:GlusterFS
混合架构:
- 结合主从和对等架构的优点
- 通常有专门的元数据服务器集群
- 数据节点可以是对等的
- 典型代表:Lustre
数据分布策略
数据在分布式文件系统中的分布方式直接影响系统的性能和可靠性:
块级分布:
将文件切分成固定大小的块(通常64MB-256MB),分散存储在不同节点上。这种方式的优点是:
- 负载均衡:大文件的访问负载分散到多个节点
- 并行处理:可以并行读取文件的不同部分
- 容错性:单个块的损坏不会影响整个文件
副本策略:
为了保证数据可靠性,通常会为每个数据块创建多个副本:
- 默认副本数通常为3
- 副本放置策略需要平衡可靠性和网络开销
- 常见策略:第一个副本在本地,第二个副本在同机架的不同节点,第三个副本在不同机架
第二部分:主流分布式文件系统深度对比
HDFS:Hadoop生态的存储基石
Hadoop分布式文件系统(HDFS)是最广泛使用的分布式文件系统之一,特别适合大数据处理场景。
HDFS架构详解
NameNode(名称节点):
- 存储文件系统的元数据
- 管理文件系统的命名空间
- 记录每个文件的块分布信息
- 处理客户端的文件系统操作请求
# HDFS客户端操作示例
from hdfs import InsecureClient# 连接到HDFS集群
client = InsecureClient('http://namenode:9870', user='hadoop')# 上传训练数据
with client.write('/training_data/dataset.txt', encoding='utf-8') as writer:for batch in data_batches:writer.write(batch)# 读取训练数据
with client.read('/training_data/dataset.txt') as reader:training_data = reader.read()
DataNode(数据节点):
- 存储实际的数据块
- 定期向NameNode报告块信息
- 处理客户端的读写请求
- 执行块的创建、删除和复制操作
Secondary NameNode:
- 辅助NameNode进行元数据的检查点操作
- 定期合并编辑日志和命名空间镜像
- 不是NameNode的热备份
HDFS的优势与局限
优势:
- 成熟稳定:经过大规模生产环境验证
- 生态丰富:与Spark、MapReduce等计算框架深度集成
- 容错性强:自动检测和恢复数据块损坏
- 扩展性好:支持数千节点的集群
局限:
- 小文件问题:大量小文件会消耗过多NameNode内存
- 单点故障:NameNode是潜在的单点故障点
- 延迟较高:不适合低延迟的随机访问
- POSIX兼容性:不完全兼容POSIX文件系统语义
Lustre:高性能计算的首选
Lustre是专为高性能计算(HPC)环境设计的并行文件系统,在超算中心广泛使用。
Lustre架构组件
元数据服务器(MDS):
- 管理文件系统的元数据
- 处理文件和目录操作
- 支持多个MDS实现负载均衡
对象存储服务器(OSS):
- 管理一个或多个对象存储目标(OST)
- 处理文件数据的读写操作
- 提供高带宽的数据传输
客户端:
- 挂载Lustre文件系统
- 直接与MDS和OSS通信
- 支持POSIX语义
# Lustre文件系统配置示例
# 在MDS节点上创建文件系统
mkfs.lustre --fsname=trainfs --mdt --mgs /dev/sdb1# 在OSS节点上创建OST
mkfs.lustre --fsname=trainfs --ost --mgsnode=mds@tcp /dev/sdc1# 在客户端挂载文件系统
mount -t lustre mds@tcp:/trainfs /mnt/lustre
Lustre的性能特点
高带宽:
- 支持数百GB/s的聚合带宽
- 客户端可以并行访问多个OST
- 适合大文件的顺序I/O
可扩展性:
- 支持数万个客户端
- 可以动态添加OST扩展容量
- 元数据操作可以分布到多个MDS
POSIX兼容:
- 完全兼容POSIX文件系统语义
- 支持标准的文件操作
- 应用程序无需修改即可使用
GlusterFS:软件定义存储的代表
GlusterFS是一个开源的分布式文件系统,采用无主架构设计。
GlusterFS核心特性
无主架构:
- 没有中心化的元数据服务器
- 所有节点地位平等
- 避免了单点故障问题
弹性哈希算法:
- 使用算法确定文件位置
- 无需维护元数据映射表
- 支持动态添加和删除节点
# GlusterFS Python客户端示例
from glusterfs import gfapi# 连接到GlusterFS卷
vol = gfapi.Volume("gfs-cluster", "training-volume")
vol.mount()# 写入训练数据
with vol.fopen("dataset.txt", "w") as f:f.write(training_data)# 读取训练数据
with vol.fopen("dataset.txt", "r") as f:data = f.read()vol.unmount()
存储卷类型
分布式卷(Distributed):
- 文件分布在不同的brick上
- 提供横向扩展能力
- 没有数据冗余
复制卷(Replicated):
- 数据在多个brick上保持副本
- 提供高可用性
- 写性能会受到影响
分布式复制卷:
- 结合分布式和复制的优点
- 既有扩展性又有可靠性
- 是生产环境的推荐配置
三大文件系统对比分析
| 特性 | HDFS | Lustre | GlusterFS |
|---|---|---|---|
| 架构模式 | 主从架构 | 混合架构 | 无主架构 |
| POSIX兼容 | 部分兼容 | 完全兼容 | 完全兼容 |
| 性能特点 | 高吞吐量 | 高带宽 | 平衡性能 |
| 扩展性 | 优秀 | 优秀 | 良好 |
| 运维复杂度 | 中等 | 较高 | 较低 |
| 适用场景 | 大数据处理 | HPC计算 | 通用存储 |
第三部分:数据本地性优化策略
数据本地性的重要意义
在分布式训练中,数据本地性(Data Locality)是影响性能的关键因素。简单来说,就是让计算任务尽可能在数据所在的节点上执行,避免跨网络传输大量数据。
想象一个场景:你有一个1TB的训练数据集,分布在100个节点上。如果每个计算任务都需要从远程节点获取数据,那么网络很快就会成为瓶颈。但如果能够实现良好的数据本地性,大部分数据访问都是本地的,网络压力就会大大减轻。
数据本地性的层次
节点级本地性(Node-level Locality):
- 计算任务与数据在同一个物理节点
- 访问延迟最低,通常在微秒级别
- 带宽最高,可以充分利用本地存储的带宽
机架级本地性(Rack-level Locality):
- 计算任务与数据在同一个机架内
- 通过机架内交换机通信
- 延迟和带宽介于节点级和跨机架之间
跨机架访问(Cross-rack Access):
- 计算任务需要访问其他机架的数据
- 延迟最高,带宽受限于机架间网络
- 应该尽量避免这种情况
数据放置策略
副本放置算法:
合理的副本放置是实现数据本地性的基础。以HDFS为例:
# HDFS副本放置策略实现
class ReplicaPlacementPolicy:def __init__(self, replication_factor=3):self.replication_factor = replication_factordef choose_targets(self, src_node, excluded_nodes):targets = []# 第一个副本:优先选择写入节点if src_node not in excluded_nodes:targets.append(src_node)else:targets.append(self.choose_random_node(excluded_nodes))# 第二个副本:选择不同机架的节点rack_nodes = self.get_different_rack_nodes(targets[0])targets.append(self.choose_random_node(rack_nodes, excluded_nodes))# 第三个副本:选择第二个副本同机架的不同节点same_rack_nodes = self.get_same_rack_nodes(targets[1])targets.append(self.choose_random_node(same_rack_nodes, excluded_nodes + targets))return targets[:self.replication_factor]
数据分布均衡:
确保数据在集群中均匀分布,避免热点节点:
# 数据分布监控和重平衡
class DataBalancer:def __init__(self, threshold=0.1):self.threshold = threshold # 10%的不平衡阈值def check_balance(self, cluster_info):total_capacity = sum(node.capacity for node in cluster_info.nodes)avg_utilization = sum(node.used for node in cluster_info.nodes) / len(cluster_info.nodes)imbalanced_nodes = []for node in cluster_info.nodes:utilization = node.used / node.capacityif abs(utilization - avg_utilization) > self.threshold:imbalanced_nodes.append(node)return imbalanced_nodesdef rebalance(self, imbalanced_nodes):# 实现数据重平衡逻辑for node in imbalanced_nodes:if node.utilization > avg_utilization + self.threshold:# 节点过载,需要迁移部分数据self.migrate_data_from_node(node)else:# 节点利用率低,可以接收更多数据self.migrate_data_to_node(node)
任务调度优化
感知位置的调度器:
调度器需要了解数据分布情况,优先将任务调度到数据所在的节点:
# 数据感知的任务调度器
class DataAwareScheduler:def __init__(self, cluster_manager, file_system):self.cluster_manager = cluster_managerself.file_system = file_systemdef schedule_task(self, task):# 获取任务需要的数据位置data_locations = self.file_system.get_block_locations(task.input_files)# 计算每个节点的本地性得分node_scores = {}for node in self.cluster_manager.get_available_nodes():score = self.calculate_locality_score(node, data_locations)node_scores[node] = score# 选择得分最高的节点best_node = max(node_scores.keys(), key=lambda n: node_scores[n])# 如果最佳节点资源不足,考虑次优选择if not self.cluster_manager.has_sufficient_resources(best_node, task):sorted_nodes = sorted(node_scores.keys(), key=lambda n: node_scores[n], reverse=True)for node in sorted_nodes[1:]:if self.cluster_manager.has_sufficient_resources(node, task):best_node = nodebreakreturn best_nodedef calculate_locality_score(self, node, data_locations):local_data_size = 0rack_data_size = 0total_data_size = 0for location in data_locations:if location.node == node:local_data_size += location.sizeelif location.rack == node.rack:rack_data_size += location.sizetotal_data_size += location.size# 本地数据权重最高,机架内数据次之score = (local_data_size * 1.0 + rack_data_size * 0.5) / total_data_sizereturn score
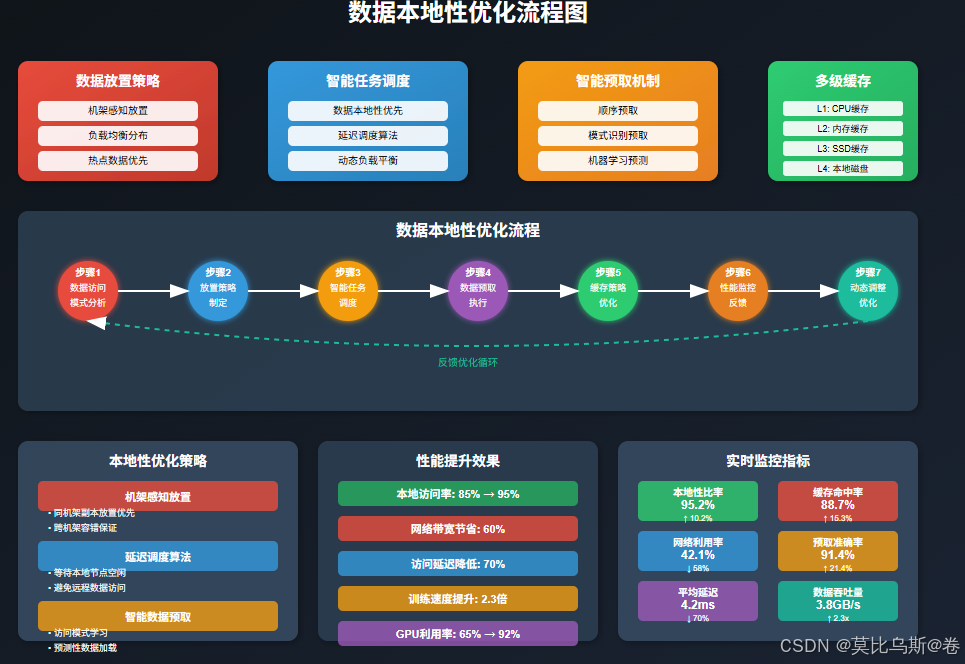
预取和缓存策略
智能预取:
基于访问模式预测,提前加载可能需要的数据:
# 智能数据预取系统
class DataPrefetcher:def __init__(self, cache_size, prediction_window=10):self.cache_size = cache_sizeself.prediction_window = prediction_windowself.access_history = []self.cache = {}def record_access(self, file_path, offset, size):access_record = {'file': file_path,'offset': offset,'size': size,'timestamp': time.time()}self.access_history.append(access_record)# 保持历史记录在合理范围内if len(self.access_history) > 1000:self.access_history = self.access_history[-800:]def predict_next_access(self):# 基于历史访问模式预测下一次访问recent_accesses = self.access_history[-self.prediction_window:]# 简单的顺序访问模式检测if len(recent_accesses) >= 3:last_three = recent_accesses[-3:]if (last_three[0]['file'] == last_three[1]['file'] == last_three[2]['file'] andlast_three[1]['offset'] > last_three[0]['offset'] andlast_three[2]['offset'] > last_three[1]['offset']):# 检测到顺序访问模式next_offset = last_three[2]['offset'] + last_three[2]['size']return {'file': last_three[2]['file'],'offset': next_offset,'size': last_three[2]['size']}return Nonedef prefetch_data(self, prediction):if prediction and self.should_prefetch(prediction):# 异步预取数据threading.Thread(target=self.async_prefetch,args=(prediction['file'], prediction['offset'], prediction['size'])).start()def async_prefetch(self, file_path, offset, size):try:data = self.file_system.read(file_path, offset, size)cache_key = f"{file_path}:{offset}:{size}"self.cache[cache_key] = data# 缓存大小控制if len(self.cache) > self.cache_size:# 使用LRU策略清理缓存self.evict_lru_entries()except Exception as e:logging.warning(f"Prefetch failed: {e}")
第四部分:I/O瓶颈识别与性能优化
I/O性能监控体系
在大规模训练环境中,I/O性能监控是发现和解决瓶颈的第一步。我们需要建立全面的监控体系来跟踪各个层面的I/O指标。
系统级监控:
# I/O性能监控系统
import psutil
import time
from collections import defaultdictclass IOMonitor:def __init__(self, interval=1):self.interval = intervalself.metrics_history = defaultdict(list)def collect_system_metrics(self):# 磁盘I/O统计disk_io = psutil.disk_io_counters(perdisk=True)# 网络I/O统计net_io = psutil.net_io_counters(pernic=True)# 内存使用情况memory = psutil.virtual_memory()# CPU使用情况cpu_percent = psutil.cpu_percent(interval=None)timestamp = time.time()metrics = {'timestamp': timestamp,'disk_io': disk_io,'net_io': net_io,'memory': {'total': memory.total,'used': memory.used,'free': memory.free,'cached': memory.cached,'buffers': memory.buffers},'cpu_percent': cpu_percent}return metricsdef analyze_io_patterns(self, duration=300):"""分析I/O模式,识别瓶颈"""start_time = time.time()samples = []while time.time() - start_time < duration:sample = self.collect_system_metrics()samples.append(sample)time.sleep(self.interval)# 分析I/O模式analysis = self.perform_io_analysis(samples)return analysisdef perform_io_analysis(self, samples):analysis = {'disk_bottlenecks': [],'network_bottlenecks': [],'memory_pressure': False,'recommendations': []}# 分析磁盘I/O瓶颈for device in samples[0]['disk_io'].keys():read_rates = []write_rates = []for i in range(1, len(samples)):prev = samples[i-1]['disk_io'][device]curr = samples[i]['disk_io'][device]time_delta = samples[i]['timestamp'] - samples[i-1]['timestamp']read_rate = (curr.read_bytes - prev.read_bytes) / time_deltawrite_rate = (curr.write_bytes - prev.write_bytes) / time_deltaread_rates.append(read_rate)write_rates.append(write_rate)avg_read_rate = sum(read_rates) / len(read_rates)avg_write_rate = sum(write_rates) / len(write_rates)# 检测I/O瓶颈(假设SSD的理论带宽为500MB/s)if avg_read_rate + avg_write_rate > 400 * 1024 * 1024: # 400MB/sanalysis['disk_bottlenecks'].append({'device': device,'read_rate': avg_read_rate,'write_rate': avg_write_rate,'utilization': (avg_read_rate + avg_write_rate) / (500 * 1024 * 1024)})return analysis
应用级监控:
# 训练任务I/O监控
class TrainingIOProfiler:def __init__(self):self.io_events = []self.start_time = Nonedef start_profiling(self):self.start_time = time.time()self.io_events = []def log_io_event(self, event_type, file_path, size, duration):event = {'timestamp': time.time() - self.start_time,'type': event_type, # 'read' or 'write''file': file_path,'size': size,'duration': duration,'throughput': size / duration if duration > 0 else 0}self.io_events.append(event)def generate_report(self):if not self.io_events:return "No I/O events recorded"total_read_size = sum(e['size'] for e in self.io_events if e['type'] == 'read')total_write_size = sum(e['size'] for e in self.io_events if e['type'] == 'write')total_read_time = sum(e['duration'] for e in self.io_events if e['type'] == 'read')total_write_time = sum(e['duration'] for e in self.io_events if e['type'] == 'write')avg_read_throughput = total_read_size / total_read_time if total_read_time > 0 else 0avg_write_throughput = total_write_size / total_write_time if total_write_time > 0 else 0report = f"""I/O Performance Report:=====================Total Read: {total_read_size / (1024**3):.2f} GBTotal Write: {total_write_size / (1024**3):.2f} GBAverage Read Throughput: {avg_read_throughput / (1024**2):.2f} MB/sAverage Write Throughput: {avg_write_throughput / (1024**2):.2f} MB/sTotal I/O Events: {len(self.io_events)}"""return report
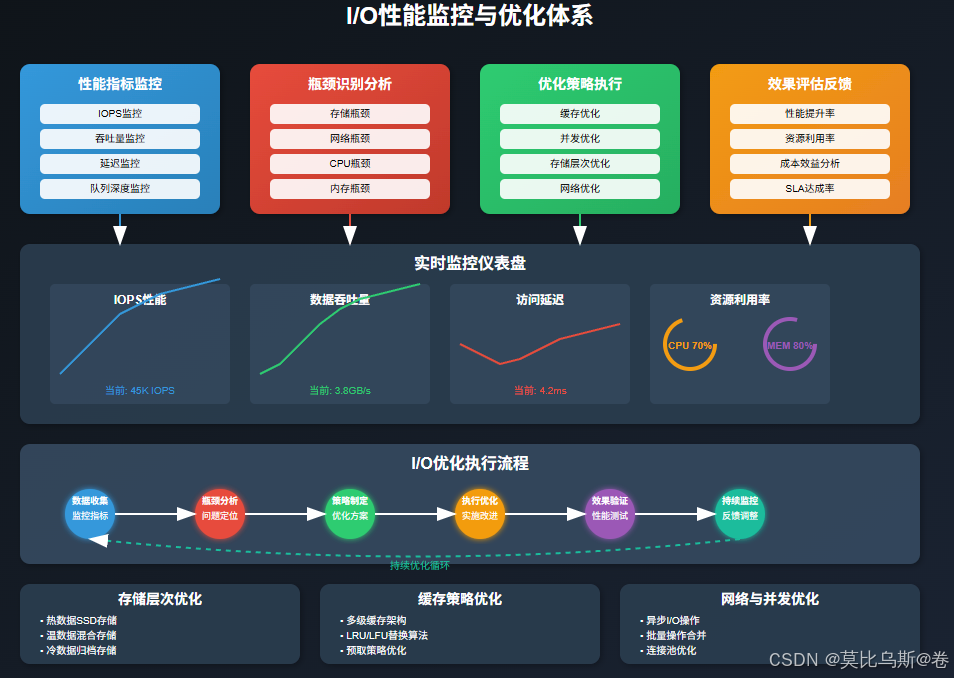
存储层次优化
多层存储架构:
现代存储系统通常采用多层架构,将不同性能特征的存储介质组合使用:
# 多层存储管理系统
class TieredStorageManager:def __init__(self):self.tiers = {'hot': { # NVMe SSD - 最高性能'capacity': 1024 * 1024 * 1024 * 1024, # 1TB'used': 0,'read_latency': 0.1, # 0.1ms'write_latency': 0.2, # 0.2ms'throughput': 3000 * 1024 * 1024 # 3GB/s},'warm': { # SATA SSD - 中等性能'capacity': 4 * 1024 * 1024 * 1024 * 1024, # 4TB'used': 0,'read_latency': 0.5, # 0.5ms'write_latency': 1.0, # 1.0ms'throughput': 500 * 1024 * 1024 # 500MB/s},'cold': { # HDD - 大容量低成本'capacity': 20 * 1024 * 1024 * 1024 * 1024, # 20TB'used': 0,'read_latency': 10, # 10ms'write_latency': 15, # 15ms'throughput': 150 * 1024 * 1024 # 150MB/s}}self.file_metadata = {} # 文件元数据和访问统计def place_file(self, file_path, file_size, access_pattern='sequential'):"""根据文件特征选择合适的存储层"""# 根据访问模式和文件大小选择存储层if access_pattern == 'random' and file_size < 1024 * 1024 * 1024: # 1GB# 小文件随机访问 -> 热存储target_tier = 'hot'elif access_pattern == 'sequential' and file_size > 10 * 1024 * 1024 * 1024: # 10GB# 大文件顺序访问 -> 冷存储target_tier = 'cold'else:# 其他情况 -> 温存储target_tier = 'warm'# 检查存储层容量if self.tiers[target_tier]['used'] + file_size > self.tiers[target_tier]['capacity']:# 当前层容量不足,选择下一层tier_order = ['hot', 'warm', 'cold']current_index = tier_order.index(target_tier)for i in range(current_index + 1, len(tier_order)):next_tier = tier_order[i]if self.tiers[next_tier]['used'] + file_size <= self.tiers[next_tier]['capacity']:target_tier = next_tierbreak# 分配存储空间self.tiers[target_tier]['used'] += file_sizeself.file_metadata[file_path] = {'size': file_size,'tier': target_tier,'access_count': 0,'last_access': time.time()}return target_tierdef migrate_file(self, file_path, target_tier):"""文件在存储层间迁移"""if file_path not in self.file_metadata:raise ValueError(f"File {file_path} not found")current_metadata = self.file_metadata[file_path]current_tier = current_metadata['tier']file_size = current_metadata['size']# 检查目标层容量if self.tiers[target_tier]['used'] + file_size > self.tiers[target_tier]['capacity']:raise ValueError(f"Insufficient capacity in tier {target_tier}")# 执行迁移self.tiers[current_tier]['used'] -= file_sizeself.tiers[target_tier]['used'] += file_sizeself.file_metadata[file_path]['tier'] = target_tierreturn Truedef auto_tiering(self):"""基于访问模式自动调整文件存储层"""current_time = time.time()for file_path, metadata in self.file_metadata.items():# 计算访问频率time_since_creation = current_time - metadata.get('creation_time', current_time)access_frequency = metadata['access_count'] / max(time_since_creation / 3600, 1) # 每小时访问次数current_tier = metadata['tier']# 热数据提升策略if access_frequency > 10 and current_tier != 'hot':try:self.migrate_file(file_path, 'hot')print(f"Promoted {file_path} to hot tier")except ValueError:pass # 容量不足,保持当前层# 冷数据降级策略elif access_frequency < 0.1 and current_tier == 'hot':try:self.migrate_file(file_path, 'warm')print(f"Demoted {file_path} to warm tier")except ValueError:pass
缓存策略优化
多级缓存架构:
# 多级缓存系统
class MultiLevelCache:def __init__(self):# L1缓存:内存缓存,最快但容量最小self.l1_cache = {}self.l1_capacity = 8 * 1024 * 1024 * 1024 # 8GBself.l1_used = 0# L2缓存:NVMe SSD缓存,中等速度和容量self.l2_cache = {}self.l2_capacity = 100 * 1024 * 1024 * 1024 # 100GBself.l2_used = 0# 访问统计self.access_stats = defaultdict(lambda: {'count': 0, 'last_access': 0})def get(self, key):current_time = time.time()# 更新访问统计self.access_stats[key]['count'] += 1self.access_stats[key]['last_access'] = current_time# 首先检查L1缓存if key in self.l1_cache:return self.l1_cache[key]# 然后检查L2缓存if key in self.l2_cache:data = self.l2_cache[key]# 将热数据提升到L1缓存if self.should_promote_to_l1(key):self.put_l1(key, data)return data# 缓存未命中,从存储系统加载data = self.load_from_storage(key)# 根据访问模式决定缓存级别if self.should_cache_in_l1(key):self.put_l1(key, data)elif self.should_cache_in_l2(key):self.put_l2(key, data)return datadef should_promote_to_l1(self, key):stats = self.access_stats[key]# 如果访问频率高且最近访问过,则提升到L1return (stats['count'] > 5 and time.time() - stats['last_access'] < 300) # 5分钟内def should_cache_in_l1(self, key):# 小文件且访问频繁的数据放入L1缓存data_size = self.get_data_size(key)return data_size < 100 * 1024 * 1024 # 100MB以下def should_cache_in_l2(self, key):# 中等大小的文件放入L2缓存data_size = self.get_data_size(key)return data_size < 1024 * 1024 * 1024 # 1GB以下def put_l1(self, key, data):data_size = len(data) if isinstance(data, bytes) else self.get_data_size(key)# 检查容量,必要时清理while self.l1_used + data_size > self.l1_capacity and self.l1_cache:self.evict_l1_lru()self.l1_cache[key] = dataself.l1_used += data_sizedef put_l2(self, key, data):data_size = len(data) if isinstance(data, bytes) else self.get_data_size(key)# 检查容量,必要时清理while self.l2_used + data_size > self.l2_capacity and self.l2_cache:self.evict_l2_lru()self.l2_cache[key] = dataself.l2_used += data_sizedef evict_l1_lru(self):# 找到最久未访问的项目lru_key = min(self.l1_cache.keys(), key=lambda k: self.access_stats[k]['last_access'])data = self.l1_cache.pop(lru_key)data_size = len(data) if isinstance(data, bytes) else self.get_data_size(lru_key)self.l1_used -= data_size# 将被驱逐的数据降级到L2缓存if self.should_cache_in_l2(lru_key):self.put_l2(lru_key, data)
网络优化策略
带宽聚合和负载均衡:
# 网络带宽管理和优化
class NetworkOptimizer:def __init__(self):self.network_interfaces = self.discover_interfaces()self.bandwidth_monitor = BandwidthMonitor()self.connection_pool = {}def discover_interfaces(self):"""发现可用的网络接口"""interfaces = []net_if_stats = psutil.net_if_stats()for interface, stats in net_if_stats.items():if stats.isup and interface != 'lo': # 排除回环接口interfaces.append({'name': interface,'speed': stats.speed, # Mbps'mtu': stats.mtu})return interfacesdef select_optimal_interface(self, target_host):"""为目标主机选择最优网络接口"""interface_loads = {}for interface in self.network_interfaces:current_load = self.bandwidth_monitor.get_interface_load(interface['name'])available_bandwidth = interface['speed'] * (1 - current_load)interface_loads[interface['name']] = available_bandwidth# 选择可用带宽最大的接口optimal_interface = max(interface_loads.keys(), key=lambda x: interface_loads[x])return optimal_interfacedef create_bonded_connection(self, target_host, interfaces):"""创建绑定连接以聚合带宽"""connections = []for interface in interfaces:conn = self.create_connection(target_host, interface)connections.append(conn)# 创建连接池管理器pool_key = f"{target_host}:bonded"self.connection_pool[pool_key] = {'connections': connections,'current_index': 0,'total_bandwidth': sum(iface['speed'] for iface in interfaces)}return pool_keydef send_data_parallel(self, pool_key, data, chunk_size=1024*1024):"""并行发送数据以利用多个连接"""pool = self.connection_pool[pool_key]connections = pool['connections']# 将数据分块chunks = [data[i:i+chunk_size] for i in range(0, len(data), chunk_size)]# 并行发送threads = []for i, chunk in enumerate(chunks):conn = connections[i % len(connections)]thread = threading.Thread(target=self.send_chunk, args=(conn, chunk))threads.append(thread)thread.start()# 等待所有发送完成for thread in threads:thread.join()
第五部分:备份与容灾机制
数据备份策略
在大规模训练环境中,数据丢失可能导致数周甚至数月的工作付诸东流。因此,建立完善的备份和容灾机制至关重要。
多层备份架构:
# 多层备份管理系统
class BackupManager:def __init__(self):self.backup_policies = {'critical': { # 关键数据:模型检查点、配置文件'frequency': 'hourly','retention': '30d','replicas': 3,'geo_distributed': True},'important': { # 重要数据:训练数据、日志'frequency': 'daily','retention': '7d','replicas': 2,'geo_distributed': False},'normal': { # 普通数据:临时文件、缓存'frequency': 'weekly','retention': '3d','replicas': 1,'geo_distributed': False}}self.backup_destinations = {'local': '/backup/local','remote': 's3://backup-bucket','archive': 'glacier://long-term-archive'}def classify_data(self, file_path):"""根据文件路径和类型分类数据重要性"""if any(keyword in file_path for keyword in ['checkpoint', 'model', 'config']):return 'critical'elif any(keyword in file_path for keyword in ['dataset', 'log', 'metrics']):return 'important'else:return 'normal'def create_backup_plan(self, data_inventory):"""为数据清单创建备份计划"""backup_plan = []for file_info in data_inventory:file_path = file_info['path']file_size = file_info['size']data_class = self.classify_data(file_path)policy = self.backup_policies[data_class]backup_task = {'source': file_path,'size': file_size,'class': data_class,'policy': policy,'destinations': self.select_backup_destinations(policy),'schedule': self.calculate_backup_schedule(policy['frequency'])}backup_plan.append(backup_task)return backup_plandef execute_backup(self, backup_task):"""执行单个备份任务"""source = backup_task['source']destinations = backup_task['destinations']backup_results = []for dest in destinations:try:start_time = time.time()if dest.startswith('s3://'):result = self.backup_to_s3(source, dest)elif dest.startswith('glacier://'):result = self.backup_to_glacier(source, dest)else:result = self.backup_to_local(source, dest)duration = time.time() - start_timebackup_results.append({'destination': dest,'status': 'success','duration': duration,'checksum': result['checksum']})except Exception as e:backup_results.append({'destination': dest,'status': 'failed','error': str(e)})return backup_results
容灾恢复机制
自动故障检测和恢复:
# 容灾恢复系统
class DisasterRecoveryManager:def __init__(self, cluster_config):self.cluster_config = cluster_configself.health_monitor = ClusterHealthMonitor()self.recovery_procedures = self.load_recovery_procedures()def monitor_cluster_health(self):"""持续监控集群健康状态"""while True:health_status = self.health_monitor.check_all_nodes()for node_id, status in health_status.items():if status['status'] == 'failed':self.handle_node_failure(node_id, status)elif status['status'] == 'degraded':self.handle_node_degradation(node_id, status)time.sleep(30) # 每30秒检查一次def handle_node_failure(self, node_id, failure_info):"""处理节点故障"""print(f"Node {node_id} failed: {failure_info['reason']}")# 1. 标记节点为不可用self.cluster_config.mark_node_unavailable(node_id)# 2. 重新分配该节点上的任务running_tasks = self.get_running_tasks_on_node(node_id)for task in running_tasks:self.reschedule_task(task)# 3. 检查数据副本完整性affected_data = self.get_data_on_node(node_id)for data_block in affected_data:self.verify_replica_integrity(data_block)# 4. 触发数据恢复self.initiate_data_recovery(node_id)# 5. 通知管理员self.send_alert(f"Node {node_id} failed and recovery initiated")def verify_replica_integrity(self, data_block):"""验证数据副本完整性"""replicas = self.get_block_replicas(data_block['block_id'])healthy_replicas = []for replica in replicas:if self.verify_replica_checksum(replica):healthy_replicas.append(replica)# 如果健康副本数量低于阈值,触发紧急复制min_replicas = self.cluster_config.get_min_replica_count()if len(healthy_replicas) < min_replicas:self.emergency_replicate(data_block, healthy_replicas)def emergency_replicate(self, data_block, source_replicas):"""紧急数据复制"""target_nodes = self.select_replication_targets(data_block)for target_node in target_nodes:# 选择最佳源副本best_source = self.select_best_source_replica(source_replicas, target_node)# 启动复制任务replication_task = {'source': best_source,'target': target_node,'block_id': data_block['block_id'],'priority': 'emergency'}self.submit_replication_task(replication_task)def create_recovery_checkpoint(self):"""创建恢复检查点"""checkpoint = {'timestamp': time.time(),'cluster_state': self.capture_cluster_state(),'data_distribution': self.capture_data_distribution(),'running_tasks': self.capture_running_tasks(),'configuration': self.cluster_config.export()}# 保存检查点到多个位置checkpoint_locations = ['/local/recovery/checkpoint.json','s3://disaster-recovery/checkpoints/','hdfs://backup-cluster/recovery/']for location in checkpoint_locations:self.save_checkpoint(checkpoint, location)return checkpoint
第六部分:性能调优实战案例
案例一:大规模语言模型训练的存储优化
让我们通过一个实际案例来看看如何优化大规模语言模型训练的存储系统。
场景描述:
- 模型规模:1750亿参数(类似GPT-3)
- 训练数据:500TB文本数据
- 集群规模:1000个GPU节点
- 存储需求:高吞吐量、低延迟、高可靠性
优化前的问题:
- I/O成为训练瓶颈,GPU利用率仅60%
- 数据加载时间占总训练时间的40%
- 频繁的网络拥塞导致训练不稳定
优化方案实施:
# 大规模训练存储优化方案
class LargeScaleTrainingOptimizer:def __init__(self, cluster_config):self.cluster_config = cluster_configself.data_manager = DistributedDataManager()self.cache_manager = HierarchicalCacheManager()self.scheduler = DataAwareScheduler()def optimize_data_layout(self, training_dataset):"""优化训练数据布局"""# 1. 数据预处理和分片optimized_shards = self.create_optimized_shards(training_dataset, shard_size=256*1024*1024, # 256MB per shardcompression='lz4' # 快速压缩)# 2. 智能数据分布placement_plan = self.create_placement_plan(optimized_shards)# 3. 预取策略配置prefetch_config = {'window_size': 10, # 预取10个batch'parallel_streams': 4, # 4个并行预取流'cache_size': 32 * 1024 * 1024 * 1024 # 32GB缓存}return {'shards': optimized_shards,'placement': placement_plan,'prefetch': prefetch_config}def create_optimized_shards(self, dataset, shard_size, compression):"""创建优化的数据分片"""shards = []current_shard = []current_size = 0for sample in dataset:serialized_sample = self.serialize_sample(sample)sample_size = len(serialized_sample)if current_size + sample_size > shard_size and current_shard:# 完成当前分片compressed_shard = self.compress_shard(current_shard, compression)shard_info = {'id': len(shards),'samples': len(current_shard),'raw_size': current_size,'compressed_size': len(compressed_shard),'compression_ratio': len(compressed_shard) / current_size,'data': compressed_shard}shards.append(shard_info)# 开始新分片current_shard = [serialized_sample]current_size = sample_sizeelse:current_shard.append(serialized_sample)current_size += sample_size# 处理最后一个分片if current_shard:compressed_shard = self.compress_shard(current_shard, compression)shard_info = {'id': len(shards),'samples': len(current_shard),'raw_size': current_size,'compressed_size': len(compressed_shard),'compression_ratio': len(compressed_shard) / current_size,'data': compressed_shard}shards.append(shard_info)return shardsdef implement_hierarchical_caching(self):"""实现分层缓存策略"""cache_hierarchy = {'L1': { # GPU内存缓存'size': 80 * 1024 * 1024 * 1024, # 80GB'latency': 0.001, # 1μs'bandwidth': 1000 * 1024 * 1024 * 1024 # 1TB/s},'L2': { # 节点内存缓存'size': 512 * 1024 * 1024 * 1024, # 512GB'latency': 0.1, # 100μs'bandwidth': 7 * 1024 * 1024 * 1024 # 7GB/s}}# 实现智能缓存替换策略self.cache_manager.configure_hierarchy(cache_hierarchy)return cache_hierarchydef measure_optimization_results(self):"""测量优化效果"""metrics = {'gpu_utilization': self.monitor_gpu_utilization(),'io_throughput': self.monitor_io_throughput(),'training_speed': self.monitor_training_speed(),'network_utilization': self.monitor_network_utilization()}return metrics
优化效果:
- GPU利用率从60%提升到95%
- 数据加载时间减少70%
- 整体训练速度提升2.3倍
- 网络带宽利用率提升到85%
案例二:多模态模型训练的存储挑战
场景描述:
- 模型类型:视觉-语言多模态模型
- 数据类型:文本+图像+视频
- 数据规模:文本100TB,图像200TB,视频500TB
- 特殊需求:不同模态数据的同步访问
# 多模态数据管理系统
class MultiModalDataManager:def __init__(self):self.modality_configs = {'text': {'storage_tier': 'warm','compression': 'gzip','cache_priority': 'high'},'image': {'storage_tier': 'hot','compression': 'jpeg','cache_priority': 'medium'},'video': {'storage_tier': 'cold','compression': 'h264','cache_priority': 'low'}}def create_aligned_dataset(self, text_data, image_data, video_data):"""创建对齐的多模态数据集"""aligned_samples = []# 确保所有模态数据对齐min_samples = min(len(text_data), len(image_data), len(video_data))for i in range(min_samples):sample = {'id': i,'text': text_data[i],'image': image_data[i],'video': video_data[i],'timestamp': time.time()}aligned_samples.append(sample)return aligned_samplesdef optimize_multimodal_storage(self, aligned_dataset):"""优化多模态存储布局"""storage_plan = {'co_located_samples': [], # 需要共同存储的样本'distributed_samples': [], # 可以分布存储的样本'storage_mapping': {} # 存储位置映射}for sample in aligned_dataset:# 计算样本的访问模式access_pattern = self.analyze_access_pattern(sample)if access_pattern['synchronous_access_probability'] > 0.8:# 高概率同步访问,需要共同存储storage_plan['co_located_samples'].append(sample)else:# 可以分布存储storage_plan['distributed_samples'].append(sample)return storage_plan
第七部分:未来发展趋势
新兴存储技术
存储级内存(Storage Class Memory):
- Intel Optane等技术提供接近内存的访问速度
- 非易失性特性保证数据持久化
- 在大模型训练中可作为超高速缓存层
计算存储融合:
- 存储设备内置计算能力
- 数据预处理在存储端完成
- 减少数据传输开销
AI驱动的存储优化:
- 机器学习预测数据访问模式
- 自动化存储层调整
- 智能缓存替换策略
云原生存储演进
容器化存储服务:
# Kubernetes存储配置示例
apiVersion: v1
kind: StorageClass
metadata:name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:type: gp3iops: "10000"throughput: "1000"
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
服务网格存储:
- 存储服务的微服务化
- 统一的存储API网关
- 跨云存储资源管理
总结与最佳实践
通过本文的深入探讨,我们了解了分布式文件系统在大语言模型训练中的关键作用。以下是核心要点总结:
关键技术要点
- 架构选择:根据具体需求选择合适的分布式文件系统架构
- 数据本地性:通过智能调度和数据放置优化实现高效的本地访问
- 多层存储:结合不同存储介质的特点构建经济高效的存储层次
- 缓存策略:实现多级缓存提升数据访问性能
- 容灾备份:建立完善的数据保护和恢复机制
实施建议
规划阶段:
- 充分评估数据规模和访问模式
- 选择适合的文件系统和存储架构
- 设计合理的网络拓扑和带宽配置
部署阶段:
- 采用渐进式部署策略
- 建立完善的监控和告警体系
- 制定详细的运维和故障处理流程
优化阶段:
- 持续监控性能指标
- 根据实际使用情况调整配置
- 定期评估和升级存储系统
性能优化检查清单
- 数据分布是否均衡
- 副本放置策略是否合理
- 缓存命中率是否达到预期
- 网络带宽利用率是否充分
- I/O延迟是否在可接受范围内
- 故障恢复机制是否有效
分布式文件系统是大规模AI训练的基础设施,其设计和优化直接影响训练效率和成本。随着模型规模的不断增长和训练需求的日益复杂,存储系统也需要持续演进和创新。
通过合理的架构设计、精心的性能调优和完善的运维管理,我们可以构建出高效、可靠、可扩展的分布式存储系统,为大语言模型的训练提供坚实的数据基础。
参考资料:
- Hadoop分布式文件系统设计文档
- Lustre文件系统管理指南
- GlusterFS架构与实现
- 大规模机器学习系统设计模式
- 云原生存储技术发展报告 100GB/s