Transformer架构详解:革命性深度学习架构的原理与应用
Transformer架构详解:革命性深度学习架构的原理与应用
“Attention Is All You Need” - Google Research, 2017
摘要
Transformer是2017年由Google提出的一种全新的神经网络架构,它彻底改变了深度学习领域,成为了现代自然语言处理、计算机视觉和多模态AI系统的基础。本文将从原理、架构、实现到应用全面解析Transformer网络结构。
目录
- 引言:为什么需要Transformer
- 核心创新与设计理念
- 架构详解
- 关键组件深度解析
- 数学原理与公式推导
- 代码实现示例
- Transformer变体与发展
- 应用场景与案例
- 性能优化与挑战
- 未来发展趋势
引言:为什么需要Transformer
传统序列建模的局限性
在Transformer出现之前,序列建模主要依赖循环神经网络(RNN)和长短期记忆网络(LSTM):
RNN/LSTM的问题:
- 顺序计算:必须按顺序处理序列,无法并行化
- 梯度消失:难以捕获长距离依赖关系
- 计算效率低:训练时间长,难以扩展到大规模数据
- 信息瓶颈:固定大小的隐藏状态限制了信息传递
Transformer的突破
Transformer通过纯注意力机制解决了这些根本性问题:
传统方法: 输入 → RNN → RNN → RNN → 输出
Transformer: 输入 ⇒ 全局注意力 ⇒ 并行处理 ⇒ 输出
核心创新与设计理念
1. 完全基于注意力机制
设计哲学: “Attention Is All You Need”
- 摒弃所有循环和卷积操作
- 使用自注意力机制直接建模序列中任意两个位置的关系
- 实现真正的并行计算
2. 多头注意力机制
核心思想: 让模型同时关注不同类型的信息
单头注意力 → 只能学习一种关系模式
多头注意力 → 并行学习多种关系模式
3. 位置编码
解决问题: 如何在没有循环结构的情况下保留位置信息
创新方案: 使用数学函数为每个位置生成独特的编码
架构详解
整体架构图
输入序列↓
输入嵌入 + 位置编码↓
┌─────────────────┐
│ 编码器层 × N │ ← Multi-Head Attention
│ │ Feed Forward Network
│ │ 残差连接 + LayerNorm
└─────────────────┘↓
┌─────────────────┐
│ 解码器层 × N │ ← Masked Multi-Head Attention
│ │ Encoder-Decoder Attention
│ │ Feed Forward Network
└─────────────────┘↓
线性层 + Softmax↓
输出概率分布
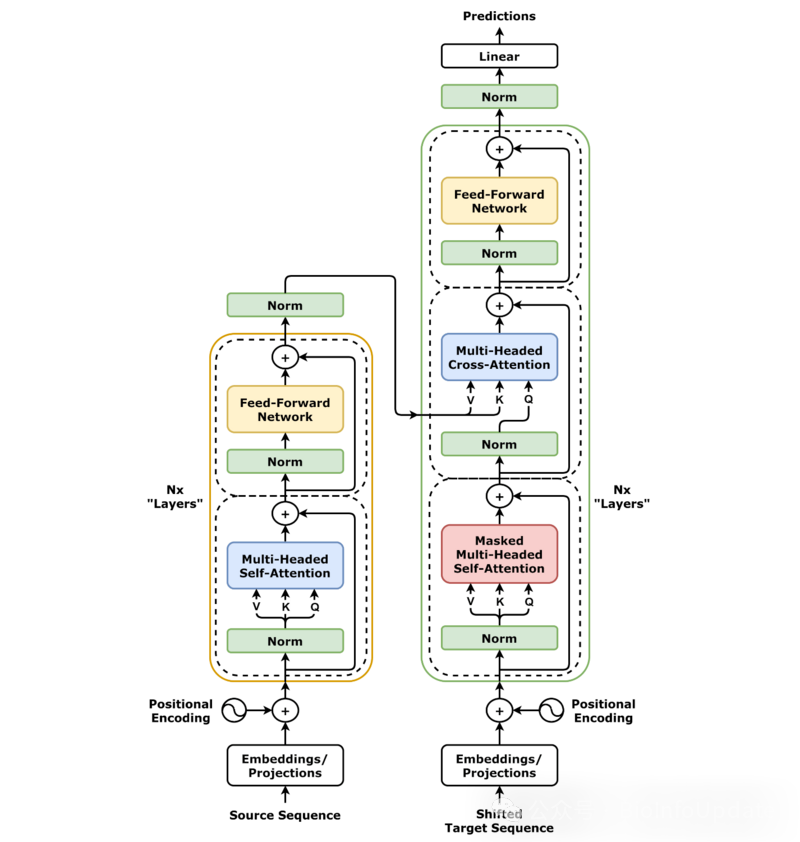
编码器-解码器结构
编码器(Encoder):
- 将输入序列编码成语义表示
- 6层相同的层堆叠
- 每层包含:多头自注意力 + 前馈网络
解码器(Decoder):
- 基于编码器输出生成目标序列
- 6层相同的层堆叠
- 每层包含:掩码多头自注意力 + 编码器-解码器注意力 + 前馈网络
关键组件深度解析
1. 多头自注意力机制(Multi-Head Self-Attention)
基本原理
自注意力机制计算序列中每个位置与所有位置(包括自己)的关联程度:
对于序列: [我, 爱, 自然, 语言, 处理]"我" 与每个词的关联度: [0.8, 0.1, 0.03, 0.05, 0.02]
"爱" 与每个词的关联度: [0.6, 0.9, 0.1, 0.15, 0.08]
...
多头机制
为什么需要多头?
单头注意力只能学习一种关系模式,多头允许模型并行学习多种不同类型的关系:
- Head 1: 学习语法关系(主谓宾)
- Head 2: 学习语义关系(近义词、反义词)
- Head 3: 学习位置关系(相邻词汇)
- Head 4: 学习长距离依赖
计算流程
1. 线性变换生成 Q, K, VQ = XW_Q, K = XW_K, V = XW_V2. 缩放点积注意力Attention(Q,K,V) = softmax(QK^T / √d_k)V3. 多头并行计算MultiHead(Q,K,V) = Concat(head_1, ..., head_h)W_O4. 残差连接 + 层归一化Output = LayerNorm(X + MultiHead(X))
2. 位置编码(Positional Encoding)
为什么需要位置编码?
Transformer没有循环结构,模型无法区分词汇的顺序:
- “我爱你” 和 “你爱我” 在没有位置信息的情况下是相同的
编码方案
使用正弦和余弦函数为每个位置生成独特的编码:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
特性:
- 每个位置有唯一的编码
- 相对位置关系可以通过三角函数性质学习
- 可以处理训练时未见过的序列长度
3. 前馈神经网络(Feed Forward Network)
结构
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2
- 两层全连接网络
- 中间使用ReLU激活函数
- 对每个位置独立应用
作用
- 增加模型的非线性表达能力
- 为每个位置提供位置相关的变换
- 扩展模型容量
4. 残差连接与层归一化
残差连接
Output = LayerNorm(X + Sublayer(X))
好处:
- 缓解梯度消失问题
- 允许信息直接传递
- 使深层网络训练更稳定
层归一化
对每个样本的特征维度进行归一化:
LayerNorm(x) = γ * (x - μ) / σ + β
数学原理与公式推导
缩放点积注意力
基本公式
Attention(Q,K,V) = softmax(QK^T / √d_k)V
详细推导
Step 1: 计算注意力分数
scores = QK^T / √d_k
- Q: 查询矩阵 (seq_len × d_k)
- K: 键矩阵 (seq_len × d_k)
- V: 值矩阵 (seq_len × d_v)
- √d_k: 缩放因子,防止softmax饱和
Step 2: 归一化获得注意力权重
weights = softmax(scores)
Step 3: 加权求和得到输出
output = weights × V
为什么要缩放?
当d_k较大时,点积结果的方差为d_k,会导致softmax函数进入饱和区,梯度变得很小。除以√d_k可以将方差控制为1。
多头注意力数学表示
MultiHead(Q,K,V) = Concat(head_1, head_2, ..., head_h)W_O其中 head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
参数矩阵:
- W_i^Q ∈ R^(d_model × d_k)
- W_i^K ∈ R^(d_model × d_k)
- W_i^V ∈ R^(d_model × d_v)
- W_O ∈ R^(hd_v × d_model)
位置编码数学推导
公式
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
相对位置关系
利用三角函数的加法定理:
PE(pos+k, 2i) = sin((pos+k) / 10000^(2i/d_model))= sin(pos/10000^(2i/d_model))cos(k/10000^(2i/d_model)) + cos(pos/10000^(2i/d_model))sin(k/10000^(2i/d_model))
这允许模型学习相对位置关系。
代码实现示例
PyTorch实现核心组件
1. 多头自注意力
import torch
import torch.nn as nn
import mathclass MultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads):super(MultiHeadAttention, self).__init__()assert d_model % n_heads == 0self.d_model = d_modelself.n_heads = n_headsself.d_k = d_model // n_heads# 线性变换层self.W_q = nn.Linear(d_model, d_model)self.W_k = nn.Linear(d_model, d_model)self.W_v = nn.Linear(d_model, d_model)self.W_o = nn.Linear(d_model, d_model)def scaled_dot_product_attention(self, Q, K, V, mask=None):# 计算注意力分数scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)# 应用掩码if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# 计算注意力权重attention_weights = torch.softmax(scores, dim=-1)# 加权求和output = torch.matmul(attention_weights, V)return output, attention_weightsdef forward(self, query, key, value, mask=None):batch_size = query.size(0)# 线性变换并重塑为多头格式Q = self.W_q(query).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)K = self.W_k(key).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)V = self.W_v(value).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)# 计算缩放点积注意力attention_output, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask)# 合并多头输出attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)# 最终线性变换output = self.W_o(attention_output)return output
2. 位置编码
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_seq_length=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_seq_length, d_model)position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(0), :]
3. Transformer编码器层
class TransformerEncoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(TransformerEncoderLayer, self).__init__()self.self_attention = MultiHeadAttention(d_model, n_heads)self.feed_forward = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):# 多头自注意力 + 残差连接 + 层归一化attn_output = self.self_attention(x, x, x, mask)x = self.norm1(x + self.dropout(attn_output))# 前馈网络 + 残差连接 + 层归一化ff_output = self.feed_forward(x)x = self.norm2(x + self.dropout(ff_output))return x
4. 完整Transformer模型
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_layers, d_ff, max_seq_length, dropout=0.1):super(Transformer, self).__init__()self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model, max_seq_length)self.encoder_layers = nn.ModuleList([TransformerEncoderLayer(d_model, n_heads, d_ff, dropout)for _ in range(n_layers)])self.layer_norm = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, src, mask=None):# 词嵌入 + 位置编码x = self.embedding(src) * math.sqrt(self.d_model)x = self.positional_encoding(x)x = self.dropout(x)# 通过编码器层for encoder_layer in self.encoder_layers:x = encoder_layer(x, mask)return self.layer_norm(x)
使用示例
# 模型参数
vocab_size = 10000
d_model = 512
n_heads = 8
n_layers = 6
d_ff = 2048
max_seq_length = 1000# 创建模型
model = Transformer(vocab_size, d_model, n_heads, n_layers, d_ff, max_seq_length)# 输入数据
batch_size = 32
seq_length = 100
src = torch.randint(0, vocab_size, (batch_size, seq_length))# 前向传播
output = model(src)
print(f"输出形状: {output.shape}") # [32, 100, 512]
Transformer变体与发展
1. BERT (Bidirectional Encoder Representations from Transformers)
特点:
- 仅使用编码器部分
- 双向注意力机制
- 通过掩码语言模型进行预训练
架构改进:
# BERT的关键创新
class BERTModel(nn.Module):def __init__(self, config):super().__init__()self.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config) # 只有编码器self.pooler = BertPooler(config)def forward(self, input_ids, attention_mask=None, token_type_ids=None):# 双向上下文编码embedding_output = self.embeddings(input_ids, token_type_ids)encoder_outputs = self.encoder(embedding_output, attention_mask)return encoder_outputs
2. GPT (Generative Pre-trained Transformer)
特点:
- 仅使用解码器部分
- 因果(单向)注意力机制
- 自回归生成
核心差异:
# GPT的掩码注意力
def create_causal_mask(seq_length):"""创建因果掩码,防止看到未来信息"""mask = torch.tril(torch.ones(seq_length, seq_length))return mask
3. T5 (Text-To-Text Transfer Transformer)
特点:
- 完整编码器-解码器架构
- 所有任务统一为"文本到文本"格式
- 相对位置编码
4. Vision Transformer (ViT)
创新:
- 将图像分块处理,每个块作为一个"词汇"
- 直接应用Transformer架构到视觉任务
class VisionTransformer(nn.Module):def __init__(self, img_size, patch_size, num_classes, d_model, n_heads, n_layers):super().__init__()self.patch_size = patch_sizeself.num_patches = (img_size // patch_size) ** 2# 图像分块嵌入self.patch_embedding = nn.Conv2d(3, d_model, kernel_size=patch_size, stride=patch_size)# 位置嵌入self.pos_embedding = nn.Parameter(torch.randn(1, self.num_patches + 1, d_model))# 类别标记self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))# Transformer编码器self.transformer = TransformerEncoder(d_model, n_heads, n_layers)# 分类头self.classifier = nn.Linear(d_model, num_classes)def forward(self, x):batch_size = x.shape[0]# 图像分块x = self.patch_embedding(x).flatten(2).transpose(1, 2)# 添加类别标记cls_tokens = self.cls_token.expand(batch_size, -1, -1)x = torch.cat([cls_tokens, x], dim=1)# 添加位置编码x += self.pos_embedding# Transformer编码x = self.transformer(x)# 分类return self.classifier(x[:, 0])
应用场景与案例
1. 自然语言处理
机器翻译
# 使用Transformer进行机器翻译的完整流程
class TranslationModel(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, d_model, n_heads, n_layers):super().__init__()self.encoder = TransformerEncoder(src_vocab_size, d_model, n_heads, n_layers)self.decoder = TransformerDecoder(tgt_vocab_size, d_model, n_heads, n_layers)def forward(self, src, tgt, src_mask=None, tgt_mask=None):encoder_output = self.encoder(src, src_mask)decoder_output = self.decoder(tgt, encoder_output, src_mask, tgt_mask)return decoder_output
文本摘要
- 编码器:理解原文内容
- 解码器:生成摘要文本
- 注意力机制:关注重要信息
问答系统
# BERT-based问答系统
class QAModel(nn.Module):def __init__(self, bert_model):super().__init__()self.bert = bert_modelself.qa_outputs = nn.Linear(bert_model.config.hidden_size, 2) # start和end位置def forward(self, input_ids, attention_mask=None, token_type_ids=None):outputs = self.bert(input_ids, attention_mask, token_type_ids)sequence_output = outputs[0]logits = self.qa_outputs(sequence_output)start_logits, end_logits = logits.split(1, dim=-1)return start_logits.squeeze(-1), end_logits.squeeze(-1)
2. 计算机视觉
图像分类
- Vision Transformer (ViT)
- 将图像分解为patches
- 应用标准Transformer架构
目标检测
- DETR (Detection Transformer)
- 将目标检测转换为集合预测问题
- 使用Transformer替代传统的锚框方法
3. 多模态应用
CLIP (Contrastive Language-Image Pre-Training)
class CLIP(nn.Module):def __init__(self, image_encoder, text_encoder, temperature=0.07):super().__init__()self.image_encoder = image_encoder # Vision Transformerself.text_encoder = text_encoder # Text Transformerself.temperature = temperaturedef forward(self, images, texts):image_features = self.image_encoder(images)text_features = self.text_encoder(texts)# 标准化特征image_features = F.normalize(image_features, dim=-1)text_features = F.normalize(text_features, dim=-1)# 计算相似度矩阵logits_per_image = (image_features @ text_features.T) / self.temperaturelogits_per_text = logits_per_image.Treturn logits_per_image, logits_per_text
4. 语音处理
Whisper
- 使用Transformer进行语音识别
- 编码器:处理音频特征
- 解码器:生成文本转录
5. 代码生成
Codex/GitHub Copilot
# 代码生成任务的示例
def generate_code(model, prompt, max_length=100):"""使用预训练的代码生成模型生成代码"""input_ids = tokenizer.encode(prompt, return_tensors='pt')with torch.no_grad():output = model.generate(input_ids,max_length=max_length,num_return_sequences=1,temperature=0.7,do_sample=True,pad_token_id=tokenizer.eos_token_id)generated_code = tokenizer.decode(output[0], skip_special_tokens=True)return generated_code[len(prompt):]# 使用示例
prompt = "# 实现一个计算斐波那契数列的函数\ndef fibonacci(n):"
generated = generate_code(model, prompt)
print(generated)
性能优化与挑战
1. 计算复杂度问题
自注意力的时间复杂度
O(n²d) - 其中n是序列长度,d是特征维度
优化方案
1. Sparse Attention
# 稀疏注意力:只关注局部和全局重要位置
class SparseAttention(nn.Module):def __init__(self, d_model, n_heads, window_size=128):super().__init__()self.window_size = window_sizeself.attention = MultiHeadAttention(d_model, n_heads)def create_sparse_mask(self, seq_len):# 创建稀疏注意力掩码mask = torch.zeros(seq_len, seq_len)# 局部窗口for i in range(seq_len):start = max(0, i - self.window_size // 2)end = min(seq_len, i + self.window_size // 2 + 1)mask[i, start:end] = 1# 全局注意力(每隔一定距离)mask[::self.window_size, :] = 1mask[:, ::self.window_size] = 1return mask
2. Linear Attention
# 线性注意力:将复杂度降低到O(nd²)
class LinearAttention(nn.Module):def __init__(self, d_model, n_heads):super().__init__()self.d_model = d_modelself.n_heads = n_headsdef forward(self, q, k, v):# 使用核方法近似softmaxq = F.elu(q) + 1k = F.elu(k) + 1# 线性化的注意力计算kv = torch.einsum("nld,nlv->ndv", k, v)out = torch.einsum("nld,ndv->nlv", q, kv)# 归一化z = torch.einsum("nld,nd->nl", q, k.sum(dim=-2))out = out / z.unsqueeze(-1)return out
2. 内存优化
Gradient Checkpointing
import torch.utils.checkpoint as checkpointclass MemoryEfficientTransformerLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff):super().__init__()self.attention = MultiHeadAttention(d_model, n_heads)self.feed_forward = FeedForward(d_model, d_ff)def forward(self, x):# 使用gradient checkpointing节省内存x = checkpoint.checkpoint(self._attention_block, x)x = checkpoint.checkpoint(self._feed_forward_block, x)return xdef _attention_block(self, x):return x + self.attention(x, x, x)def _feed_forward_block(self, x):return x + self.feed_forward(x)
3. 训练稳定性
学习率预热和衰减
class TransformerLRScheduler:def __init__(self, d_model, warmup_steps=4000):self.d_model = d_modelself.warmup_steps = warmup_stepsdef get_lr(self, step):# Transformer原始论文中的学习率调度arg1 = step ** (-0.5)arg2 = step * (self.warmup_steps ** (-1.5))return (self.d_model ** (-0.5)) * min(arg1, arg2)
层归一化位置优化
# Pre-LN vs Post-LN
class PreLNTransformerLayer(nn.Module):"""Pre-LayerNorm版本,训练更稳定"""def forward(self, x):# 先归一化,再应用子层x = x + self.attention(self.norm1(x))x = x + self.feed_forward(self.norm2(x))return xclass PostLNTransformerLayer(nn.Module):"""Post-LayerNorm版本,原始实现"""def forward(self, x):# 先应用子层,再归一化x = self.norm1(x + self.attention(x))x = self.norm2(x + self.feed_forward(x))return x
未来发展趋势
1. 模型规模扩展
参数规模发展
GPT-1 (2018): 117M 参数
GPT-2 (2019): 1.5B 参数
GPT-3 (2020): 175B 参数
GPT-4 (2023): ~1.7T 参数 (估计)
扩展法则 (Scaling Laws)
- 模型性能与参数量、数据量、计算量呈幂律关系
- 计算最优模型:参数量和训练数据量应该同时扩展
2. 效率优化方向
MoE (Mixture of Experts)
class MoELayer(nn.Module):def __init__(self, d_model, num_experts, top_k=2):super().__init__()self.num_experts = num_expertsself.top_k = top_k# 专家网络self.experts = nn.ModuleList([FeedForward(d_model, d_model * 4) for _ in range(num_experts)])# 门控网络self.gate = nn.Linear(d_model, num_experts)def forward(self, x):# 计算门控权重gate_scores = self.gate(x)top_k_gates, top_k_indices = torch.topk(gate_scores, self.top_k, dim=-1)top_k_gates = F.softmax(top_k_gates, dim=-1)# 只激活top-k个专家output = torch.zeros_like(x)for i in range(self.top_k):expert_idx = top_k_indices[..., i]gate_weight = top_k_gates[..., i].unsqueeze(-1)for j, expert in enumerate(self.experts):mask = (expert_idx == j).float().unsqueeze(-1)expert_output = expert(x)output += mask * gate_weight * expert_outputreturn output
3. 多模态融合
统一的多模态架构
class UnifiedMultiModalTransformer(nn.Module):def __init__(self, config):super().__init__()# 不同模态的编码器self.text_encoder = TextTransformer(config.text)self.image_encoder = VisionTransformer(config.image)self.audio_encoder = AudioTransformer(config.audio)# 跨模态融合层self.fusion_layers = nn.ModuleList([CrossModalTransformerLayer(config.d_model)for _ in range(config.fusion_layers)])def forward(self, text=None, image=None, audio=None):features = []if text is not None:text_features = self.text_encoder(text)features.append(text_features)if image is not None:image_features = self.image_encoder(image)features.append(image_features)if audio is not None:audio_features = self.audio_encoder(audio)features.append(audio_features)# 跨模态融合fused_features = torch.cat(features, dim=1)for fusion_layer in self.fusion_layers:fused_features = fusion_layer(fused_features)return fused_features
4. 长序列处理
无限长序列的挑战
class InfiniteTransformer(nn.Module):"""处理无限长序列的Transformer变体"""def __init__(self, d_model, n_heads, memory_size=1024):super().__init__()self.memory_size = memory_sizeself.transformer = TransformerLayer(d_model, n_heads)# 可学习的压缩记忆self.memory_compression = nn.Linear(d_model, d_model // 4)self.memory_expansion = nn.Linear(d_model // 4, d_model)def forward(self, x, memory=None):if memory is None:memory = torch.zeros(x.size(0), self.memory_size, x.size(-1))# 将当前输入与记忆连接extended_input = torch.cat([memory, x], dim=1)# 应用Transformeroutput = self.transformer(extended_input)# 更新记忆new_memory = output[:, -self.memory_size:, :]compressed_memory = self.memory_compression(new_memory)new_memory = self.memory_expansion(compressed_memory)return output[:, self.memory_size:, :], new_memory
总结
Transformer架构自2017年提出以来,已经彻底改变了深度学习领域。其核心创新包括:
关键成就
- 并行计算:摒弃循环结构,实现真正的并行训练
- 长距离建模:通过自注意力机制直接建模任意距离的关系
- 可解释性:注意力权重提供了模型决策的直观解释
- 通用性:在NLP、CV、语音、多模态等多个领域取得突破
技术优势
- 效率:训练速度快,可扩展性强
- 效果:在多个基准测试中达到SOTA性能
- 灵活性:易于适应不同的任务和数据类型
- 可解释性:注意力机制提供决策透明度
挑战与限制
- 计算复杂度:O(n²)的注意力计算限制了序列长度
- 内存需求:大模型需要大量GPU内存
- 数据依赖:需要大量高质量训练数据
- 能耗问题:训练大模型需要巨大的计算资源
发展方向
- 效率优化:稀疏注意力、线性注意力、MoE等
- 长序列处理:解决序列长度限制问题
- 多模态融合:统一处理不同类型的数据
- 模型压缩:知识蒸馏、量化等技术
Transformer不仅仅是一个模型架构,它代表了深度学习的一个新范式。从GPT系列到BERT,从Vision Transformer到多模态模型,Transformer的影响将继续塑造人工智能的未来。
参考文献
- Vaswani, A., et al. (2017). Attention Is All You Need. NIPS.
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers. NAACL.
- Radford, A., et al. (2019). Language Models are Unsupervised Multitask Learners. OpenAI.
- Dosovitskiy, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR.
- Raffel, C., et al. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR.