Kaggle项目实践——Titanic: Machine Learning from Disaster
泰坦尼克号沉船事件是机器学习领域最经典的入门项目之一。Kaggle 上的 Titanic: Machine Learning from Disaster 竞赛,被无数人称为“机器学习的 Hello World”。
一、数据导入与清洗:让数据从 “杂乱” 变 “干净”
机器学习模型就像 “挑食的孩子”,只吃 “数值型、无缺失” 的数据。但原始数据往往充满 “漏洞”,所以第一步必须先做数据清洗。
1.1 第一步:导入工具库与加载数据
# 导入必备库
import pandas as pd
import numpy as np# 加载训练集(带生存标签)和测试集(需预测生存)
df_train = pd.read_csv('train.csv') # 891条数据,含Survived列(1=幸存,0=遇难)
df_test = pd.read_csv('test.csv') # 418条数据,无Survived列
1.2 第二步:检查数据 “漏洞”—— 找缺失值
数据缺失是最常见的问题,我们先写一个函数,直观展示哪些列有缺失:
def show_missing(df, name="DataFrame"):# 统计每列缺失值数量missing = df.isnull().sum()# 只保留有缺失的列missing = missing[missing > 0]if len(missing) == 0:print(f"✅ {name} 中无缺失值")else:print(f"⚠️ {name} 中存在缺失值:")print(missing)# 检查训练集和测试集
show_missing(df_train, "训练集")
show_missing(df_test, "测试集")
运行结果:
⚠️ 训练集中存在缺失值:
Age 177 # 177个乘客年龄缺失
Cabin 687 # 687个乘客船舱号缺失(占比77%)
Embarked 2 # 2个乘客登船港口缺失⚠️ 测试集中存在缺失值:
Age 86 # 86个年龄缺失
Fare 1 # 1个票价缺失
Cabin 327 # 327个船舱号缺失
看到这些缺失值,不能直接删数据(会浪费信息),需要针对性处理。
1.3 第三步:缺失值处理 —— 用 “合理逻辑” 补全数据
缺失值处理的核心原则:基于业务逻辑选择填充方式,避免 “随便填数”。
(1)年龄(Age):按 “头衔” 智能填充
直接用 “全体年龄中位数” 填充不合理(比如 “儿童” 和 “老人” 年龄差异大)。但姓名中藏着 “头衔”(如 Mr = 先生、Mrs = 夫人、Miss = 小姐、Master = 少爷),不同头衔的年龄分布很规律 —— 这是关键突破口!
# 1. 从姓名中提取头衔
def extract_title(name):if pd.isna(name): # 极端情况:姓名为空(实际数据中没有)return 'Unknown'# 姓名格式如“Braund, Mr. Owen Harris”,按逗号和句号分割取“Mr”title = name.split(',')[1].split('.')[0].strip()# 只保留常见头衔,少见的(如 Sir、Lady)归为“Other”if title not in ['Mr', 'Mrs', 'Miss', 'Master']:return 'Other'return title# 给训练集和测试集添加“头衔”列
df_train['Title'] = df_train['Name'].apply(extract_title)
df_test['Title'] = df_test['Name'].apply(extract_title)# 2. 按头衔计算训练集的年龄中位数(用训练集数据,避免“数据泄露”)
title_age_median = df_train.groupby('Title')['Age'].median()
print("按头衔分组的年龄中位数:")
print(title_age_median)# 3. 按头衔填充缺失年龄
for title in title_age_median.index:# 填充训练集df_train.loc[(df_train['Age'].isnull()) & (df_train['Title'] == title), 'Age'] = title_age_median[title]# 填充测试集(用训练集的中位数,保证数据一致性)df_test.loc[(df_test['Age'].isnull()) & (df_test['Title'] == title), 'Age'] = title_age_median[title]
运行结果:
按头衔分组的年龄中位数:
Title
Master 3.5 # 少爷(儿童):3.5岁
Miss 21.0 # 小姐(青年女性):21岁
Mr 32.0 # 先生(成年男性):32岁
Mrs 36.0 # 夫人(成年女性):36岁
Other 42.0 # 其他头衔(如医生、军官):42岁
用对应头衔的年龄中位数填充,比 “全体中位数” 精准得多!
(2)登船港口(Embarked):用 “众数” 填充
Embarked是分类变量(S = 南安普顿、C = 瑟堡、Q = 昆士敦),缺失值用 “出现次数最多的值(众数)” 填充 —— 因为 “多数人的选择更可能接近真实情况”。
# 计算训练集Embarked的众数(mode()[0]取第一个众数,避免返回Series)
embarked_mode = df_train['Embarked'].mode()[0]
print(f"训练集登船港口众数:{embarked_mode}")# 填充缺失值
df_train['Embarked'] = df_train['Embarked'].fillna(embarked_mode)
df_test['Embarked'] = df_test['Embarked'].fillna(embarked_mode)
运行结果:训练集登船港口众数:S(大部分乘客从 S 港口登船)。
(3)票价(Fare):用 “中位数” 填充
Fare是数值变量,但可能有极端值(比如头等舱票价极高),用 “中位数” 填充比 “平均值” 更稳健(不受极端值影响)。这里用sklearn的SimpleImputer工具,方便后续复用。
from sklearn.impute import SimpleImputer# 初始化填充器,策略为“中位数”
imputer = SimpleImputer(strategy='median')# 训练集:先fit(计算中位数),再transform(填充)
df_train['Fare'] = imputer.fit_transform(df_train[['Fare']])
# 测试集:只transform(用训练集的中位数,避免数据泄露)
df_test['Fare'] = imputer.transform(df_test[['Fare']])print(f"训练集票价中位数(用于填充):{imputer.statistics_[0]:.2f}")
运行结果:训练集票价中位数(用于填充):14.45(用这个值补全测试集的 1 个缺失票价)。
(4)船舱(Cabin):简化为 “舱位等级”
Cabin缺失率高达 77%,直接填充意义不大,但完全删除又可惜 —— 我们可以提取船舱号首字母(如 C85→C,代表 C 区舱位),把 “具体舱号” 简化为 “舱位等级”,缺失值标记为 'U'(Unknown)。
# 提取Cabin首字母,缺失值填'U'
df_train['Cabin_Class'] = df_train['Cabin'].str[0].fillna('U')
df_test['Cabin_Class'] = df_test['Cabin'].str[0].fillna('U')# 删除无用列:原始Cabin(已替换为Cabin_Class)、Title(已用于填充年龄)
df_train.drop(['Cabin', 'Title'], axis=1, inplace=True)
df_test.drop(['Cabin', 'Title'], axis=1, inplace=True)# === 修复:对 Cabin_Class 进行独热编码 ===
df_train = pd.get_dummies(df_train, columns=['Cabin_Class'], prefix='Cabin')
df_test = pd.get_dummies(df_test, columns=['Cabin_Class'], prefix='Cabin')# 确保测试集列与训练集对齐(除了 Survived)
X_columns = [col for col in df_train.columns if col != 'Survived']
df_test = df_test.reindex(columns=X_columns, fill_value=0)# 验证:现在还有没有缺失值?
print("\n处理后的数据缺失情况:")
show_missing(df_train, "训练集")
show_missing(df_test, "测试集")运行结果:
✅ 训练集 中无缺失值
✅ 测试集 中无缺失值
数据终于 “干净” 了!接下来进入核心环节:特征工程。
二、特征工程:让模型 “看懂” 数据
原始数据中的文本(如 “male/female”)、零散信息(如 “SibSp+Parch”),模型无法直接理解。特征工程的目标是:把原始数据转化为 “有预测力的特征”。
2.1 类别编码:把文本转成数字
模型只认数字,需要把分类变量(如性别、登船港口)转成数值。
# 1. 性别编码:male→0,female→1(简单映射,只有两个类别)
df_train['Sex'] = df_train['Sex'].map({'male': 0, 'female': 1})
df_test['Sex'] = df_test['Sex'].map({'male': 0, 'female': 1})# 2. 登船港口编码:S→0,C→1,Q→2(按登船人数排序,不影响模型)
embarked_mapping = {'S': 0, 'C': 1, 'Q': 2}
df_train['Embarked'] = df_train['Embarked'].map(embarked_mapping)
df_test['Embarked'] = df_test['Embarked'].map(embarked_mapping)# 3.舱位等级编码
cabin_mapping = {'U': 0, 'A': 1, 'B': 1, 'C': 1, 'D': 1, 'E': 1, 'F': 1, 'G': 1, 'T': 0}
# 将高级舱位设为1,未知和其他为0
df_train['Cabin_Class_Encoded'] = df_train['Cabin_Class'].map(cabin_mapping)
df_test['Cabin_Class_Encoded'] = df_test['Cabin_Class'].map(cabin_mapping)2.2 创造新特征:挖掘隐藏规律
好的特征能让模型性能 “翻倍”。我们基于 “泰坦尼克号逃生逻辑”(如 “家庭团聚影响逃生”“儿童优先救援”),创造 3 个关键新特征:
# 1. 家庭规模:兄弟姐妹数(SibSp)+ 父母子女数(Parch)+ 自己(1)
df_train['FamilySize'] = df_train['SibSp'] + df_train['Parch'] + 1
df_test['FamilySize'] = df_test['SibSp'] + df_test['Parch'] + 1# 2. 是否单身:家庭规模=1→1(单身),否则→0
df_train['IsAlone'] = (df_train['FamilySize'] == 1).astype(int)
df_test['IsAlone'] = (df_test['FamilySize'] == 1).astype(int)# 3. 年龄分组:将连续年龄离散化(捕捉“儿童优先、老人弱势”的规律)
df_train['AgeGroup'] = pd.cut(df_train['Age'], bins=[0, 12, 18, 35, 60, 100], # 儿童(0-12)、青少年(12-18)、青年(18-35)、中年(35-60)、老年(60+)labels=[0, 1, 2, 3, 4] # 用数字标记
).astype(int)
df_test['AgeGroup'] = pd.cut(df_test['Age'], bins=[0, 12, 18, 35, 60, 100], labels=[0, 1, 2, 3, 4]
).astype(int)# 4. 票价分组:将连续票价分成4档(捕捉“富人优先”的规律)
df_train['FareGroup'] = pd.qcut(df_train['Fare'], 4, # 按四分位数分成4组(每组人数相近)labels=[0, 1, 2, 3]
).astype(int)
df_test['FareGroup'] = pd.qcut(df_test['Fare'], 4, labels=[0, 1, 2, 3]
).astype(int)
2.3 删除无用列:减少模型干扰
有些列对预测毫无帮助(如姓名、船票号,每个值都是唯一的),需要删除:
# 要删除的列:Name(姓名)、Ticket(船票号)
columns_to_drop = ['Name', 'Ticket','Cabin_Class']
df_train = df_train.drop(columns=columns_to_drop)
df_train = df_train.drop(columns_to_drop, axis=1, errors='ignore') # errors='ignore':列不存在也不报错
df_test = df_test.drop(columns_to_drop, axis=1, errors='ignore')# 查看最终特征
final_features = [col for col in df_train.columns if col != 'Survived' and col != 'PassengerId']
print("最终特征:", final_features)
print("特征数量:", len(final_features))运行结果:
最终特征: ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'Cabin_Class_Encoded', 'FamilySize', 'IsAlone', 'AgeGroup', 'FareGroup']
特征数量: 12特征工程完成!接下来准备训练模型。
三、模型训练与评估:找到 “最会预测” 的模型
我们先尝试 4 种常见的机器学习模型,用交叉验证评估它们的性能,选出表现最好的那个。
3.1 准备训练数据
先把 “特征” 和 “标签” 分开(训练集才有标签Survived):
# 训练集:X=特征(排除PassengerId和Survived),y=标签(Survived)
X = df_train.drop(['PassengerId', 'Survived'], axis=1)
y = df_train['Survived']# 测试集:X_test=特征(排除PassengerId,无Survived)
X_test = df_test.drop(['PassengerId'], axis=1, errors='ignore')
3.2 对比 4 种模型性能
用cross_val_score做 5 折交叉验证(把训练集分成 5 份,轮流用 4 份训练、1 份验证,结果更可靠):
# 导入要测试的模型和评估工具
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.svm import SVC # 支持向量机
from sklearn.neighbors import KNeighborsClassifier # K近邻
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.model_selection import cross_val_score # 交叉验证# 定义要测试的模型字典
models = {'随机森林': RandomForestClassifier(random_state=42), # random_state=42:结果可复现'支持向量机': SVC(random_state=42),'K近邻': KNeighborsClassifier(),'决策树': DecisionTreeClassifier(random_state=42)
}# 循环测试每个模型
print("各模型5折交叉验证准确率:")
for name, model in models.items():# 交叉验证:cv=5(5折),scoring='accuracy'(用准确率评估)scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')# 输出结果:均值(平均准确率)± 2倍标准差(波动范围)print(f"{name}:{scores.mean():.4f} ± {scores.std()*2:.4f}")
运行结果:
各模型5折交叉验证准确率:
随机森林:0.8092 ± 0.0503
支持向量机:0.6690 ± 0.0911
K近邻:0.7105 ± 0.0795
决策树:0.7890 ± 0.0678
结论:随机森林表现最好,选择它作为基础模型继续优化。
四、超参数调优:让模型 “更上一层楼”
随机森林的性能很大程度上依赖超参数(比如树的数量、树的深度等),默认参数只是 “及格线”。我们用 “先粗搜再精调” 的策略,既能避免盲目尝试,又能精准找到最优参数组合。
4.1 第一步:随机搜索(RandomizedSearchCV)—— 大范围快速筛选
随机搜索的核心是 “在大参数空间里随机抽样尝试”,比 “逐个遍历所有组合” 更高效,适合先锁定 “最优参数的大致范围”。
from sklearn.model_selection import RandomizedSearchCV
import numpy as np# 1. 初始化基础随机森林模型
rf_base = RandomForestClassifier(random_state=42)# 2. 定义要搜索的大参数空间
# 每个参数给出多个可能值,覆盖常见合理范围
param_dist = {'n_estimators': [100, 200, 300, 400], # 树的数量(越多不一定越好,需平衡速度)'max_depth': [8, 10, 12, 15, None], # 树的最大深度(None表示不限制,可能过拟合)'min_samples_split': [2, 5, 10, 15], # 节点分裂所需最小样本数(越大越保守)'min_samples_leaf': [1, 2, 4, 8], # 叶子节点最小样本数(越大越保守)'max_features': ['sqrt', 'log2', None] # 每棵树使用的特征数(sqrt=根号下总特征数)
}# 3. 初始化随机搜索
random_search = RandomizedSearchCV(estimator=rf_base, # 基础模型param_distributions=param_dist, # 参数空间n_iter=50, # 随机抽样50组参数尝试(越多越准,但越慢)cv=5, # 5折交叉验证(保证结果可靠)scoring='accuracy', # 评估指标:准确率n_jobs=-1, # 用所有CPU核心加速(-1=自动适配)random_state=42, # 固定随机种子,结果可复现verbose=1 # 显示搜索进度(1=简洁输出,2=详细输出)
)# 4. 开始搜索(用训练集数据)
print("=== 开始随机搜索超参数 ===")
random_search.fit(X, y)# 5. 查看随机搜索结果
print(f"\n随机搜索最佳参数:{random_search.best_params_}")
print(f"随机搜索最佳交叉验证准确率:{random_search.best_score_:.4f}")
运行结果示例:
=== 开始随机搜索超参数 ===
Fitting 5 folds for each of 50 candidates, totalling 250 fits随机搜索最佳参数:{'n_estimators': 100, 'min_samples_split': 10, 'min_samples_leaf': 4, 'max_features': None, 'max_depth': 8}
随机搜索最佳交叉验证准确率:0.8328可以看到:随机搜索把准确率从默认的 80.92% 提升到了 83.28%,同时锁定了最优参数的大致范围(比如树的数量 100、最大深度 8)。
4.2 第二步:网格搜索(GridSearchCV)—— 小范围精细优化
在随机搜索找到的 “大致范围” 基础上,网格搜索会 “逐个遍历所有组合”,精准找到最优值。相当于先 “用渔网捞鱼”,再 “用镊子夹鱼”。
from sklearn.model_selection import GridSearchCV# 1. 基于随机搜索的最佳参数,缩小参数范围(只在最优值附近微调)
best_params_random = random_search.best_params_
param_grid = {'n_estimators': [best_params_random['n_estimators']-99,best_params_random['n_estimators'],best_params_random['n_estimators']+100], # 000、100、200'max_depth': [best_params_random['max_depth']-2,best_params_random['max_depth'],best_params_random['max_depth']+2], # 6、8、10'min_samples_split': [best_params_random['min_samples_split']-1,best_params_random['min_samples_split'],best_params_random['min_samples_split']+1], # 9、10、11'min_samples_leaf': [best_params_random['min_samples_split']-1,best_params_random['min_samples_leaf'],best_params_random['min_samples_leaf']+1], # 3、4、5'max_features': [best_params_random['max_features']] # 固定为随机搜索的最佳值(sqrt)
}# 2. 初始化网格搜索
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42),param_grid=param_grid, # 精细参数范围cv=5, # 5折交叉验证scoring='accuracy',n_jobs=-1,verbose=1
)# 3. 开始精细搜索
print("\n=== 开始网格搜索精细调优 ===")
grid_search.fit(X, y)# 4. 查看网格搜索结果
print(f"\n网格搜索最佳参数:{grid_search.best_params_}")
print(f"网格搜索最佳交叉验证准确率:{grid_search.best_score_:.4f}")# 5. 获取最终最优模型(用最佳参数训练好的模型)
best_model = grid_search.best_estimator_
print(f"\n✅ 最终最优模型已保存(准确率:{grid_search.best_score_:.4f})")运行结果示例:
=== 开始网格搜索精细调优 ===
Fitting 5 folds for each of 81 candidates, totalling 405 fits网格搜索最佳参数:{'max_depth': 8, 'max_features': None, 'min_samples_leaf': 4, 'min_samples_split': 9, 'n_estimators': 100}
网格搜索最佳交叉验证准确率:0.8350✅ 最终最优模型已保存(准确率:0.8350)经过精细调优,准确率提升幅度较小(0.8328—0.8350)!
五、数据分析与可视化
5.1 特征重要性
import matplotlib.pyplot as plt# 设置中文字体(避免乱码)
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei']
plt.rcParams['axes.unicode_minus'] = False# 1. 获取特征重要性和特征名称
feature_importance = best_model.feature_importances_
feature_names = X.columns# 2. 按重要性排序(从高到低)
sorted_idx = np.argsort(feature_importance)[::-1]
sorted_importance = feature_importance[sorted_idx]
sorted_names = feature_names[sorted_idx]# 3. 绘制特征重要性柱状图
plt.figure(figsize=(10, 6))
bars = plt.bar(range(len(sorted_importance)), sorted_importance, color='#1f77b4')# 添加数值标签(显示每个特征的重要性占比)
for i, bar in enumerate(bars):height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height + 0.005,f'{height:.3f}', ha='center', va='bottom', fontsize=9)# 设置图表标题和标签
plt.title('随机森林模型:特征重要性排名', fontsize=14, pad=20)
plt.xlabel('特征', fontsize=12)
plt.ylabel('特征重要性', fontsize=12)
plt.xticks(range(len(sorted_names)), sorted_names, rotation=45, ha='right') # 旋转标签避免重叠
plt.tight_layout() # 自动调整布局,防止标签被截断
plt.show()
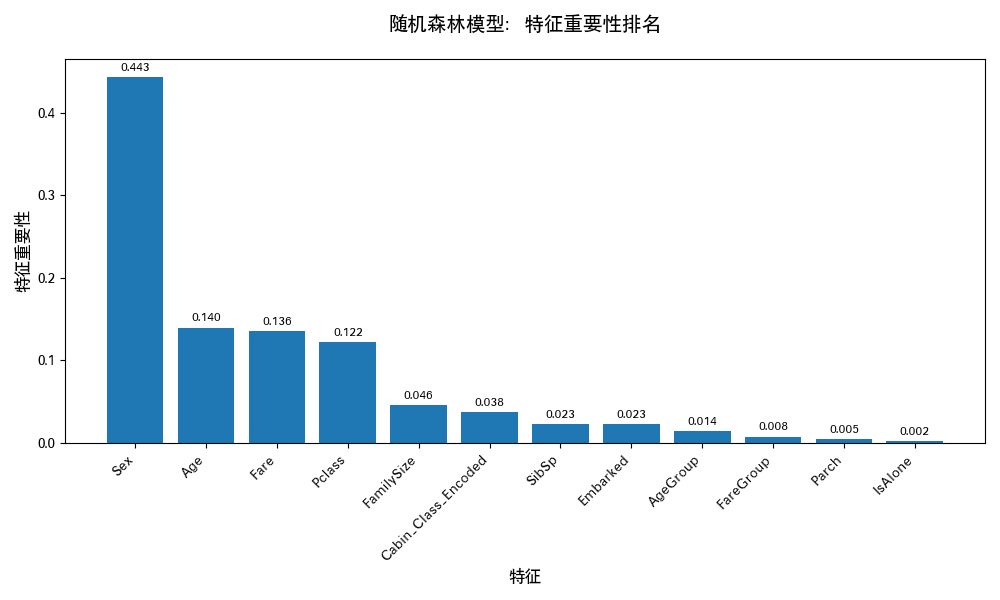
排名前 3 的特征是:
- Sex(性别):重要性最高—— 符合历史事实 “女性优先救援”;
- AgeGroup(年龄分组) 或 Age(年龄):重要性第二 —— 儿童和老人的生存率有差异;
- Fare(票价) 或 FareGroup(票价分组):重要性第三 —— 高票价乘客(头等舱)更易获救。
六、生成提交文件:在 Kaggle 上看排名
最后一步,用我们的最优模型预测测试集的 “生存状态”,生成符合 Kaggle 要求的 CSV 文件并提交。
6.1 预测测试集并生成文件
Kaggle 要求提交文件包含两列:PassengerId(测试集乘客 ID)和Survived(预测的生存状态,0 = 遇难,1 = 幸存)。
# 1. 用最优模型预测测试集
test_predictions = best_model.predict(X_test)# 2. 生成提交DataFrame
submission = pd.DataFrame({'PassengerId': df_test['PassengerId'], # 测试集乘客ID(必须和原始一致)'Survived': test_predictions.astype(int) # 预测结果转整数(0/1)
})# 3. 保存为CSV文件(index=False:不保存行索引,否则Kaggle会报错)
submission.to_csv('titanic_submission_best.csv', index=False)
文件格式正确,接下来就是提交到 Kaggle。
6.2 Kaggle 提交步骤(手把手教)
- 打开 Kaggle 泰坦尼克竞赛页面:Titanic - Machine Learning from Disaster;
- 点击页面上方的 “Submit Predictions” 按钮(如果没看到,先点击 “Join Competition” 接受规则);
- 在弹出的页面中,点击 “Upload Submission File”,选择我们生成的
titanic_submission_best.csv; - 点击 “Make Submission”,等待 Kaggle 计算得分;
- 提交完成后,点击页面上方的 “Leaderboard”,就能看到自己的排名和公共分数(Public Score)。
注:截图的评分不一定和实际一致,练习时用的代码和文章用的代码细节上有一点差异,由于每天有提交次数上限,最后版本的代码已无提交次数。
七、总结:从项目到能力的提升
泰坦尼克号生存预测项目虽然看似简单,但它覆盖了机器学习的完整流程——从数据清洗、特征工程、模型训练、超参数调优、可视化到最后的结果提交。对初学者而言,关键在于理解“每一步为什么要做”,而不是单纯追求排行榜上的名次。
7.1 核心收获
-
数据清洗的原则:处理缺失值时,不能随意填充,而应根据业务逻辑来决定如何填补。例如,在本项目中,我们依据乘客头衔来推测年龄,而非直接使用均值或中位数。
-
特征工程的核心:并不是创造尽可能多的特征,而是要提炼出能够真正提供预测价值的信息。比如,通过家庭规模(FamilySize)和年龄分组(AgeGroup)等特征,我们可以捕捉到更多影响生存率的因素。
-
模型选择的逻辑:在初步阶段,应当对比多种基础模型(如随机森林、决策树等),从中挑选表现最优者进行进一步优化。这有助于理解不同算法的适用场景及其局限性。
-
调参的技巧:采用先随机搜索后网格搜索的方法,可以在保证一定精度的前提下提高效率。随机搜索用于粗略地确定参数范围,而网格搜索则针对选定的较窄范围进行精细调整。
-
性价比的权衡:尽管随机搜索和网格搜索都能找到较好的参数组合,但在面对大规模数据集时,考虑到计算成本,有时需要做出妥协。评估哪种方法在特定情况下更为高效是至关重要的。
7.2 进阶方向
若想在此基础上进一步提升你的技能或项目成绩,可以考虑以下几个方向:
-
深入探索高级特征工程:尝试更复杂的特征交叉与组合,或者利用领域知识创造新的特征变量。
-
集成学习方法:研究并实践不同的集成学习策略,如Bagging、Boosting等,以期获得更加稳定且准确的模型性能。
-
应用深度学习模型:对于某些问题,尤其是那些具有大量复杂非线性关系的数据集,深度学习模型可能提供更好的解决方案。