# AI(学习笔记第八课) 使用langchain的embedding models
文章目录
- AI(学习笔记第八课) 使用langchain的embedding models
- 学习内容:
- 1.`embedding model`的基本概念
- 1.1 学习`embedding model url`
- 1.2 为什么学习`embedding model`
- 1.3 使用`embedding model`将文本转换成数字向量
- 1.3.1 最初的代码
- 1.3.2 执行结果
- 1.3.3 embed query
- 2.将`embedding`保存到DB
- 2.1 将`embedding`保存到DB的代码
- 2.2 整体逻辑
- 3.对`db`进行`query`
AI(学习笔记第八课) 使用langchain的embedding models
- 为什么需要使用
embedding models - 如何使用
embedding models
学习内容:
embedding model的基本概念- 为什么使用
embedding model - 如何使用
embedding model
1.embedding model的基本概念
1.1 学习embedding model url
- langchain的
embedding models - 整体的练习代码
- 练习文件state of the union
1.2 为什么学习embedding model
embedding model能将文本转换成固定长度(fixed length)的有语义的数组,这样以来,不光能基于文件检索,而是能通过语义检索,对文本进行检索。
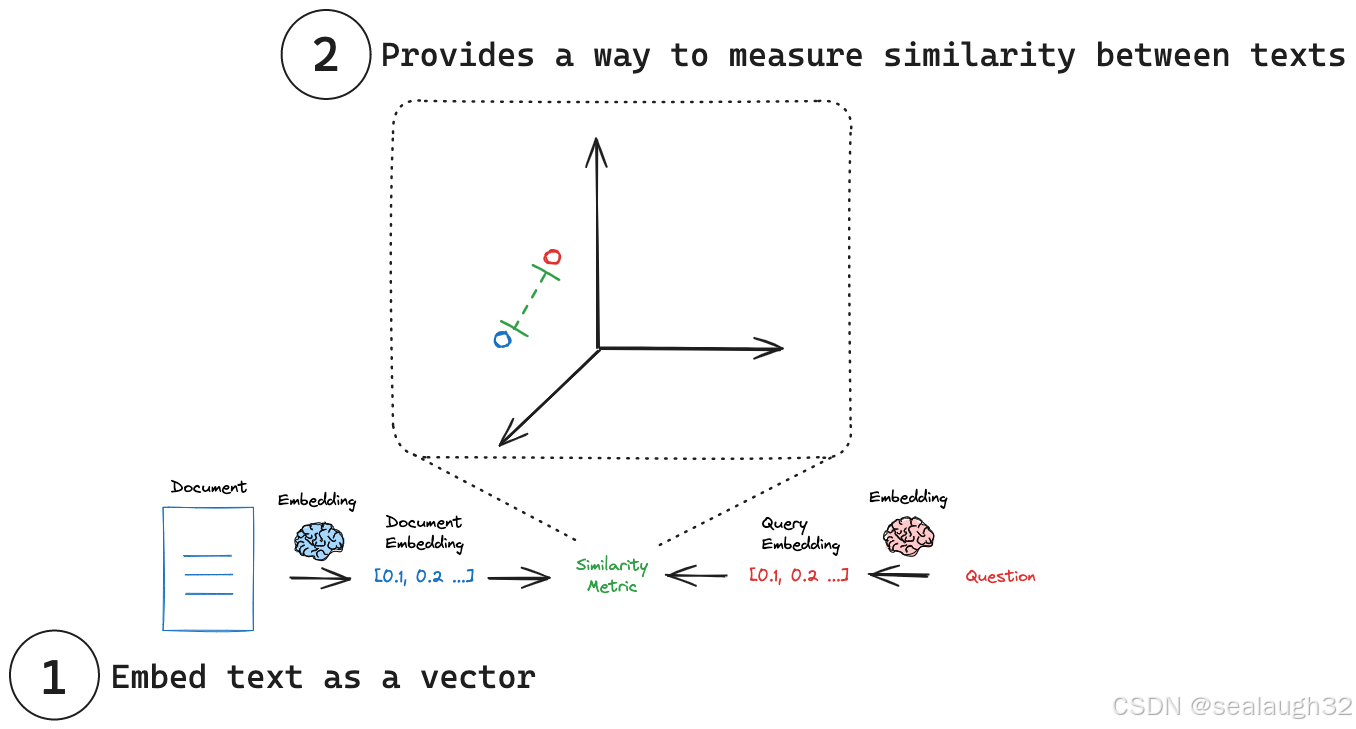
- 左面蓝字将文本文档
document经过embedding model转换成长度相等的数字向量(numerical vector representation) - 右面的红字将问题(
question)也转换成数字向量(numerical vector representation) - 最后对两个数字向量(
numerical vector representation)可以进行相似度比较(similarity metric)。
1.3 使用embedding model将文本转换成数字向量
1.3.1 最初的代码
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)from langchain_ollama import OllamaEmbeddings
from langchain.chains import RetrievalQA
try:# 使用Ollama的嵌入模型embeddings_model = OllamaEmbeddings(base_url='http://192.168.2.208:11434',model="nomic-embed-text")embeddings = embeddings_model.embed_documents(["Hi there!","Oh, hello!","What's your name?","My friends call me World","Hello World!"])print(len(embeddings))print (embeddings[0])except Exception as e:error_msg = f"执行错误: {e}"print(error_msg) # Continue 会捕获控制台输出
- 这里将5个英文短句,进行了向量化。
- 模型采用
Ollama的本地模型,这里引入了ollama的python API
1.3.2 执行结果
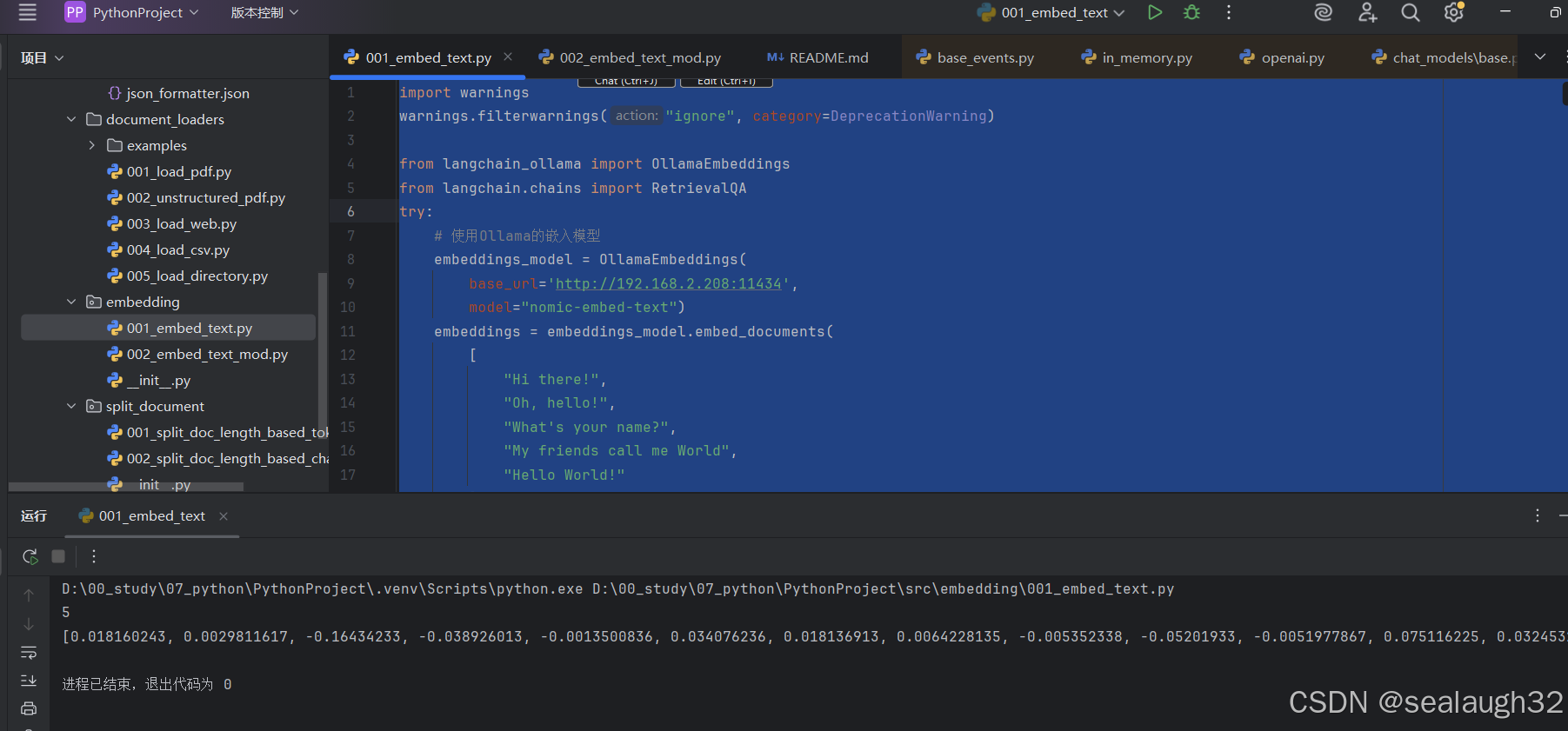
- 五个英文的短句,每个对应的生成了一个数字向量。
print (len(embeddings[0])),这里尝试将第一个数字向量的length进行打印,结果是768。- 当然,
embeddings[1]的length也是768,所以说是定长的向量fixed length。
1.3.3 embed query
embeding model添加了document之后,可以使用embedding model进行embed query,向量查询了。
print(len(embeddings))print (len(embeddings[1]))embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")print(embedded_query[:5])
这里使用What was the name mentioned in the conversation?这个句子对embedding vector进行提问。
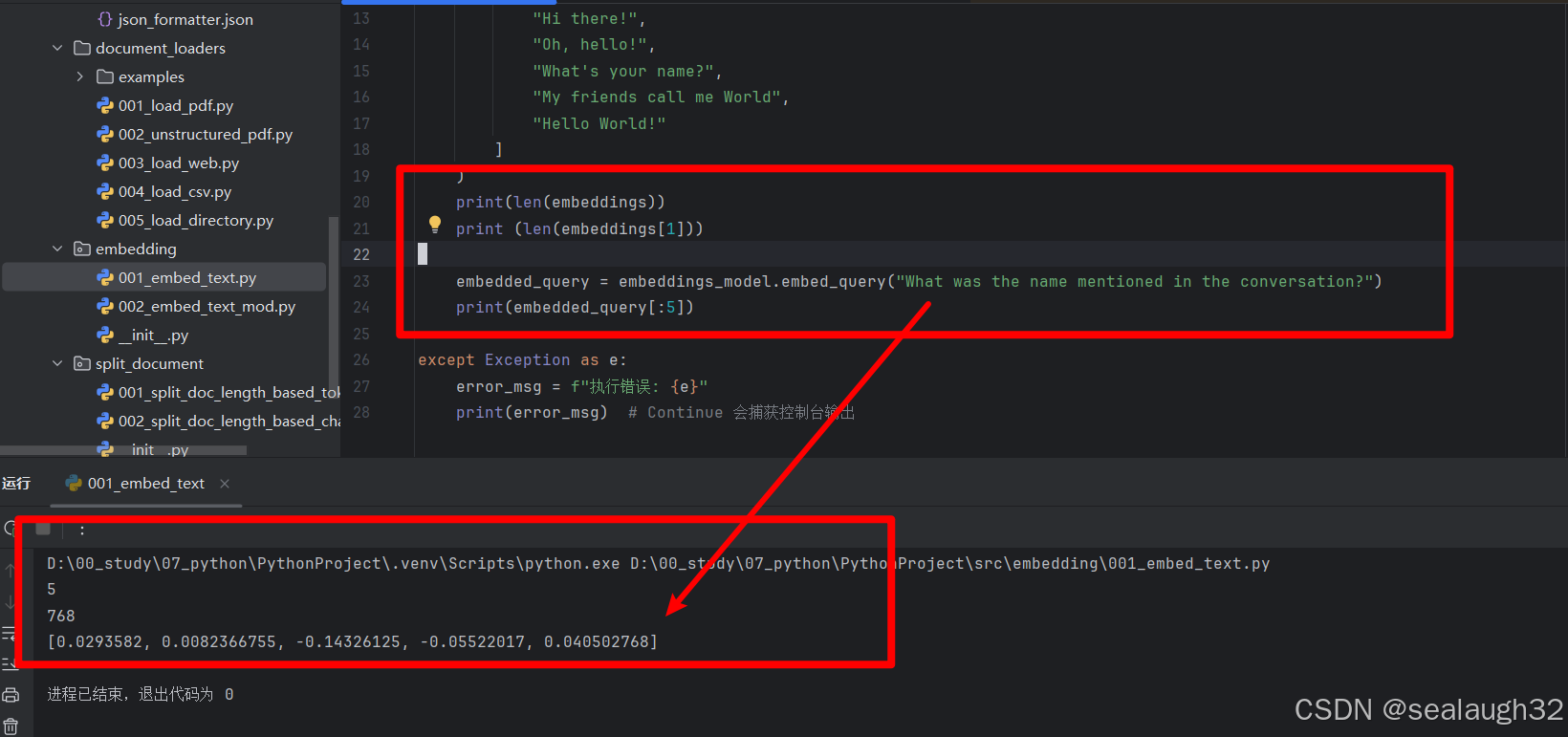
这里,结果数组里面有个五元素,分别代表了提出的query和docoment中的5个向量的cosin相似度。
2.将embedding保存到DB
2.1 将embedding保存到DB的代码
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain_community.document_loaders import TextLoader
from langchain_ollama import OllamaEmbeddings
import hashlib,os
from langchain_community.vectorstores import FAISSfrom langchain_text_splitters import CharacterTextSplitter# 使用更强的SHA-256编码器
def sha256_encoder(text: str) -> str:return hashlib.sha256(text.encode()).hexdigest()#使用Ollama的嵌入模型
embeddings_model = OllamaEmbeddings(base_url='http://192.168.2.208:11434',model="nomic-embed-text")store = LocalFileStore("C:\\Users\\Dell\\workspace\\ai_example\\cache\\")
cached_embedder = CacheBackedEmbeddings.from_bytes_store(embeddings_model, store,key_encoder=sha256_encoder,
)
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir,"state_of_the_union.txt")
raw_documents = TextLoader(file_path,encoding="utf-8").load()
# text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
text_splitter = CharacterTextSplitter(separator=" ",chunk_size=400,chunk_overlap=200,length_function=len,is_separator_regex=False,
)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, cached_embedder)
print(list(store.yield_keys())[:5])query = "where did i see the power of hope"
docs = db.similarity_search(query)
print(len(docs))
print(docs[0].page_content)
2.2 整体逻辑
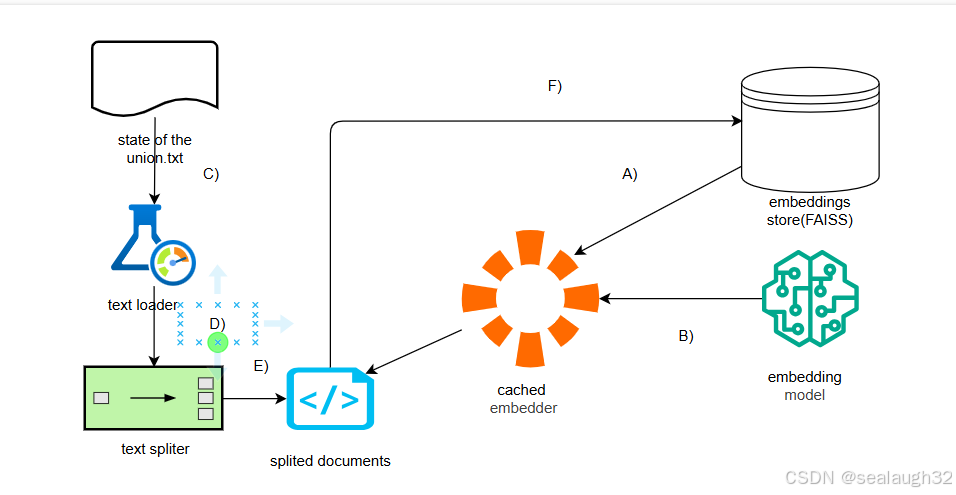
- A) 生成
cached embedder,并设定embedding store,其实就是设定本地文件(使用db的形式) - B) 对
cached embedder设定model,这里使用本地的embedding model(ollama本地搭建) - C) 使用
langchain的text loader对文件进行load - D) 使用
langchain的text spliter对字符串进行split - E) 最后使用
cached embedder进行构建embedding store
代码执行之后,可以看到对本地文件,生成了embedding store
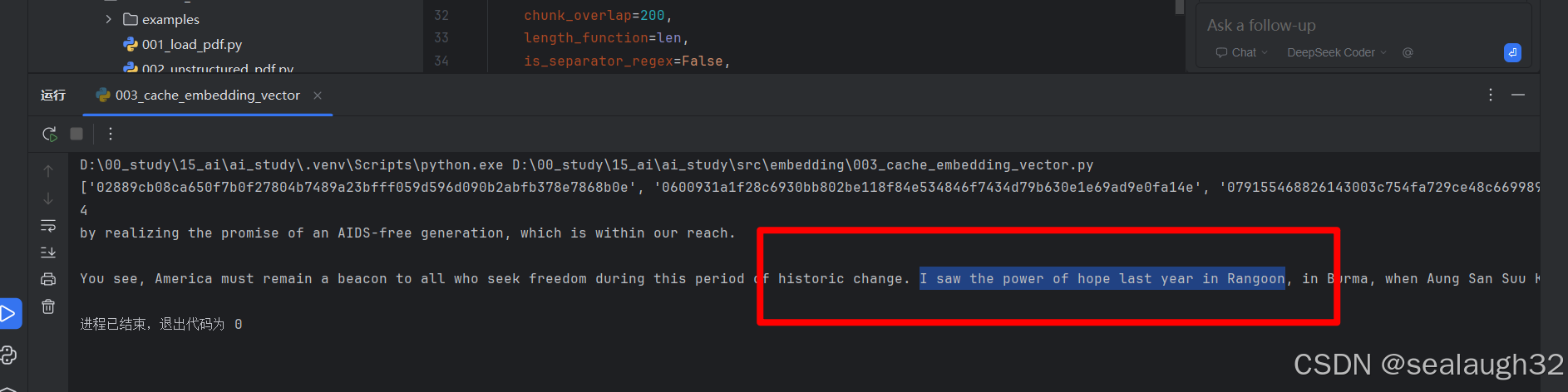
3.对db进行query
query = "where did i see the power of hope"
docs = db.similarity_search(query)
print(len(docs))
print(docs[0].page_content
可以看到,这里对文档的query结果相当精确。而且是自然语言程度的匹配。