【ComfyUI】HiDream E1.1 Image Edit带来更高精度的图像与文本编辑
今天带来的是一个基于 HiDream 模型 的 ComfyUI 图像编辑工作流,它通过 InstructPix2Pix 的方式对输入图像进行细节修改,重点展示了如何结合强大的文本编码器和扩散模型,在保持原图主体的前提下完成局部的自然化调整。




效果演示中,人物的发型被精准修改为自然散落的效果,同时背景与整体画面保持一致性,让读者直观地感受到工作流在图像生成与编辑中的应用价值。
文章目录
- HiDream ComfyUI 图像编辑工作流
- 工作流介绍
- 核心模型
- Node 节点
- 工作流程
- 应用场景
- 开发与应用
HiDream ComfyUI 图像编辑工作流
工作流介绍
该工作流基于 HiDream-E1 扩散模型和多种文本编码器组合构建而成,旨在通过文本指令直接修改现有图像局部内容。其核心思路是加载预训练的 UNet 模型、VAE 解码器与多路 CLIP/T5/LLama 编码器,结合 InstructPix2Pix 条件生成方式,实现自然、高保真的局部修改。整个流程由模型加载、图像输入、Prompt 提示、采样生成与最终保存五大环节组成,确保从输入到输出的链路清晰且高效。
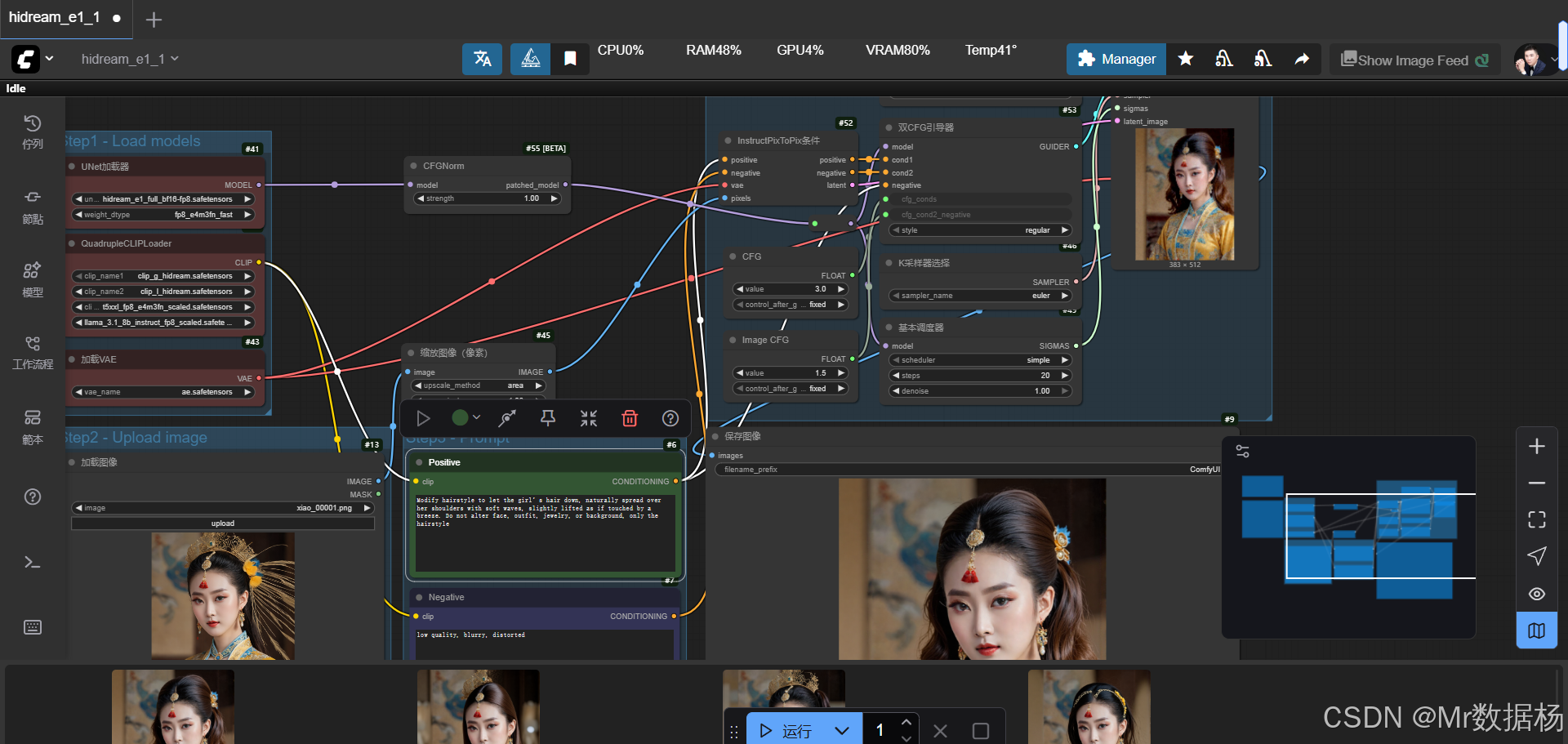
核心模型
核心模型的配置围绕 UNet 扩散模型、VAE 模型 和 多模态文本编码器展开。HiDream 的扩散模型提供了稳定的潜空间生成能力,VAE 模块用于潜变量与图像的解码转换,而 QuadrupleCLIPLoader 同时引入了 CLIP、T5 以及 LLama 编码器,使得文本指令在风格与语义上更具多样性与准确性。这些模型的配合保证了图像修改过程的可控性与效果还原度。
| 模型名称 | 说明 |
|---|---|
| hidream_e1_1_bf16.safetensors | HiDream-E1 扩散模型,负责潜空间生成与迭代采样 |
| ae.safetensors | VAE 模型,用于潜变量与图像之间的解码与还原 |
| clip_g_hidream.safetensors | CLIP 文本编码器 G 版本,强化语义理解 |
| clip_l_hidream.safetensors | CLIP 文本编码器 L 版本,提升细节捕捉 |
| t5xxl_fp8_e4m3fn_scaled.safetensors | T5-XXL 编码器,增强复杂指令的处理能力 |
| llama_3.1_8b_instruct_fp8_scaled.safetensors | LLama 指令模型,用于处理自然语言提示并转化为控制条件 |
Node 节点
节点的设计涵盖了输入、文本编码、条件构建、采样与输出等完整链路。LoadImage 节点负责图像的读取,CLIPTextEncode 将正向与负向提示转化为条件,InstructPixToPixConditioning 则结合输入图像与提示生成潜空间条件。DualCFGGuider 与 SamplerCustomAdvanced 节点共同完成扩散采样,最后通过 VAEDecode 将潜变量还原为最终图像并由 SaveImage 保存。节点之间的连接逻辑保证了文本提示、图像输入和生成控制的一致性,从而实现高质量的局部编辑。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 读取输入图像作为编辑基底 |
| CLIPTextEncode (Positive/Negative) | 将文本提示转化为条件编码 |
| InstructPixToPixConditioning | 将图像与提示结合,形成潜空间条件 |
| DualCFGGuider | 控制正向与负向提示的平衡,增强生成可控性 |
| RandomNoise | 初始化扩散过程所需的噪声输入 |
| SamplerCustomAdvanced | 自定义采样过程,生成潜空间结果 |
| VAEDecode | 将潜变量解码为图像输出 |
| SaveImage | 保存生成的最终图像 |
工作流程
该工作流的执行路径从模型加载到最终图像输出,环环相扣。首先由 QuadrupleCLIPLoader、UNetLoader 与 VAELoader 完成核心模型的加载,确保扩散、解码与文本理解的能力就绪。随后,LoadImage 节点导入原始图像,经过 ImageScaleToTotalPixels 调整至合适分辨率,为后续处理奠定基础。文本提示通过 CLIPTextEncode 编码为正向与负向条件,进入 InstructPixToPixConditioning,结合输入图像与 VAE 生成潜在条件。此后,RandomNoise 初始化扩散噪声,配合 KSamplerSelect 与 BasicScheduler 定义采样策略,再由 DualCFGGuider 对条件权重进行平衡,最终在 SamplerCustomAdvanced 中完成潜变量采样。生成结果由 VAEDecode 还原为图像,并通过 SaveImage 保存。整个流程既强调了可控性,也保证了生成结果的细腻程度。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 加载文本编码器、扩散模型与 VAE,为工作流提供基础能力 | QuadrupleCLIPLoader, UNETLoader, VAELoader |
| 2 | 图像输入 | 读取原始图像并调整分辨率 | LoadImage, ImageScaleToTotalPixels |
| 3 | 提示处理 | 将正向与负向文本提示转化为条件编码 | CLIPTextEncode (Positive/Negative) |
| 4 | 条件构建 | 结合输入图像、提示与 VAE 输出潜空间条件 | InstructPixToPixConditioning |
| 5 | 采样配置 | 定义采样器与调度器,并加入随机噪声 | RandomNoise, KSamplerSelect, BasicScheduler |
| 6 | 指令引导 | 控制正负向条件权重,提升生成可控性 | DualCFGGuider |
| 7 | 潜变量采样 | 完成潜空间的采样与生成 | SamplerCustomAdvanced |
| 8 | 解码与输出 | 将潜变量还原为图像并保存 | VAEDecode, SaveImage |
应用场景
该工作流的设计适用于多种实际场景。对于摄影后期,可以快速对局部细节进行调整,例如修改发型、服饰或光影效果,同时保持整体画面不变。在插画与二次元创作中,能够通过文本提示灵活实现风格细化,提升作品的表达力。在影视与广告制作中,利用 InstructPix2Pix 条件编辑,能减少重复拍摄成本,快速生成替代镜头或补充画面。此外,在 AI 教育与研究领域,该工作流也是教学范例,能帮助学习者理解文本引导扩散模型的工作机制。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 摄影后期 | 调整局部细节,优化照片表现力 | 摄影师、修图师 | 人物发型、服装纹理 | 真实自然的修改效果 |
| 插画创作 | 增强风格化表达,快速迭代设计 | 插画师、CG艺术家 | 二次元角色、背景细化 | 高度个性化的艺术效果 |
| 影视广告 | 替代镜头生成,节省制作成本 | 影视制作人、广告设计师 | 局部画面修改或增强 | 高效低成本的镜头替换 |
| 学术研究 | 探索文本驱动图像生成机制 | 研究人员、学生 | 模型可控性实验 | 可复现的研究范例 |
| 教学培训 | 展示 AI 图像生成工作原理 | 教师、教育机构 | 可视化工作流案例 | 直观理解生成原理 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
ComfyUI使用教程、开发指导、资源下载
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用