如何在Anaconda中配置你的CUDA Pytorch cuNN环境(2025最新教程)
目录
一、简介
二、下载CUDA
三、下载Pytorch-GPU版本
四、下载CUDNN
五、总结
六、测试代码
一、简介
啥是Anaconda?啥是CUDA?啥是CUDNN?它们和Pytorch、GPU之间有啥关系?
怎么通俗解释它们三者的用途和关系?
1.GPU(图形处理单元):
-用途:GPU就像一个超级快的数学计算器。它特别擅长同时处理很多相同的计算任务,比如在视频游戏中渲染成千上万的像素点,
或者在深度学习中同时更新成千上万的神经网络参数。
-比喻:想象一下你有一个非常擅长做加减乘除的大脑,而GPU就像是很多这样的大脑同时工作,一起解决数学问题。
2.CUDA(计算统一设备架构):
-用途:CUDA是一个帮助程序员使用GPU的工具。它允许程序员编写代码,然后这些代码可以被GPU理解并执行。没有CUDA,程
序员就需要用更复杂的方式来指挥GPU工作。
-比喻:CUDA就像是GPU的语言翻译器。程序员用一种语言写代码,CUDA把它翻译成GPU能理解的语言。
3. PyTorch(一个深度学习库):
-用途:PyTorch是一个帮助人们轻松创建和训练深度学习模型的工具。深度学习模型是用于图像识别、语音识别、语言翻译等复杂任
务的计算机程序。
-比喻:PyTorch就像是一个高级的“积木箱”,里面有很多现成的积木(代码)。你可以用这些积木来搭建复杂的模型,比如一个可
以识别猫和狗的模型。
它们之间的关系:
-当你使用PyTorch来创建一个深度学习模型时,如果你想要这个模型训练得更快,你可以让它利用GPU的计算能力。这时,CUDA就
像是一个桥梁,帮助PyTorch和GPU沟通,让GPU来加速模型的训练。
4.CUDNN(NVIDIA打造的针对深度神经网络的加速库)
CUDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库
而Anaconda是包管理器,用来承载你所配置的虚拟环境的包,像深度学习的cpu和gpu相关配置都要在这上面的虚拟环境配置好,下次无论你使用jupter还是pycharm都可以直接在这个虚拟环境上运行啦!!!
Anaconda的下载具体见这篇博客:
【2025最新】下载安装Anaconda_anaconda下载-CSDN博客
二、下载CUDA
实际上如果你用conda去调用GPU的话不用特意下载CUDA,因为使用了 conda 安装的 cudatoolkit(仅包含运行时库,没有编译器 nvcc),
-
CUDA 相关文件的实际位置
就在你的虚拟环境目录中:
D:\Anaconda\envs\pytorch\Library
(这里包含了 PyTorch 运行所需的 CUDA 动态链接库) -
如果需要
nvcc编译器
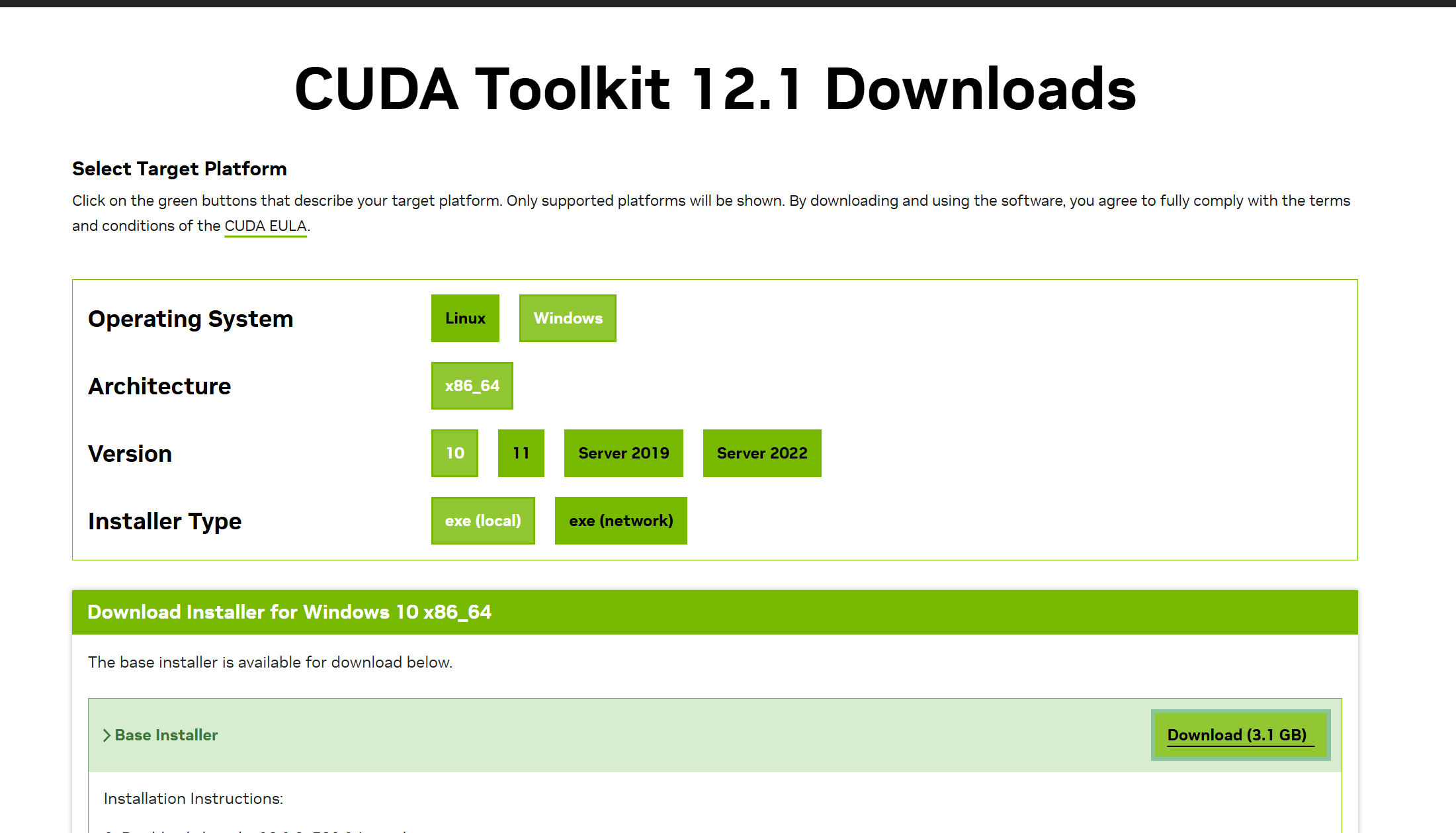
(比如编译自定义 CUDA 算子),则需要单独安装完整的 CUDA Toolkit:- 下载对应版本(12.1)的安装包:NVIDIA CUDA Toolkit 12.1
- 安装时会自动配置
nvcc路径和环境变量。
这是CUDA的下载地址:
CUDA Toolkit Archive | NVIDIA Developer

在这里你可以下载以前的CUDA版本,选择你自己电脑兼容的。
像我的电脑是要下载12.5以下的CUDA版本。
然后进行exe程序包后下载:

等待下载完成即可
三、下载Pytorch-GPU版本
1.查看现有的CUDA版本
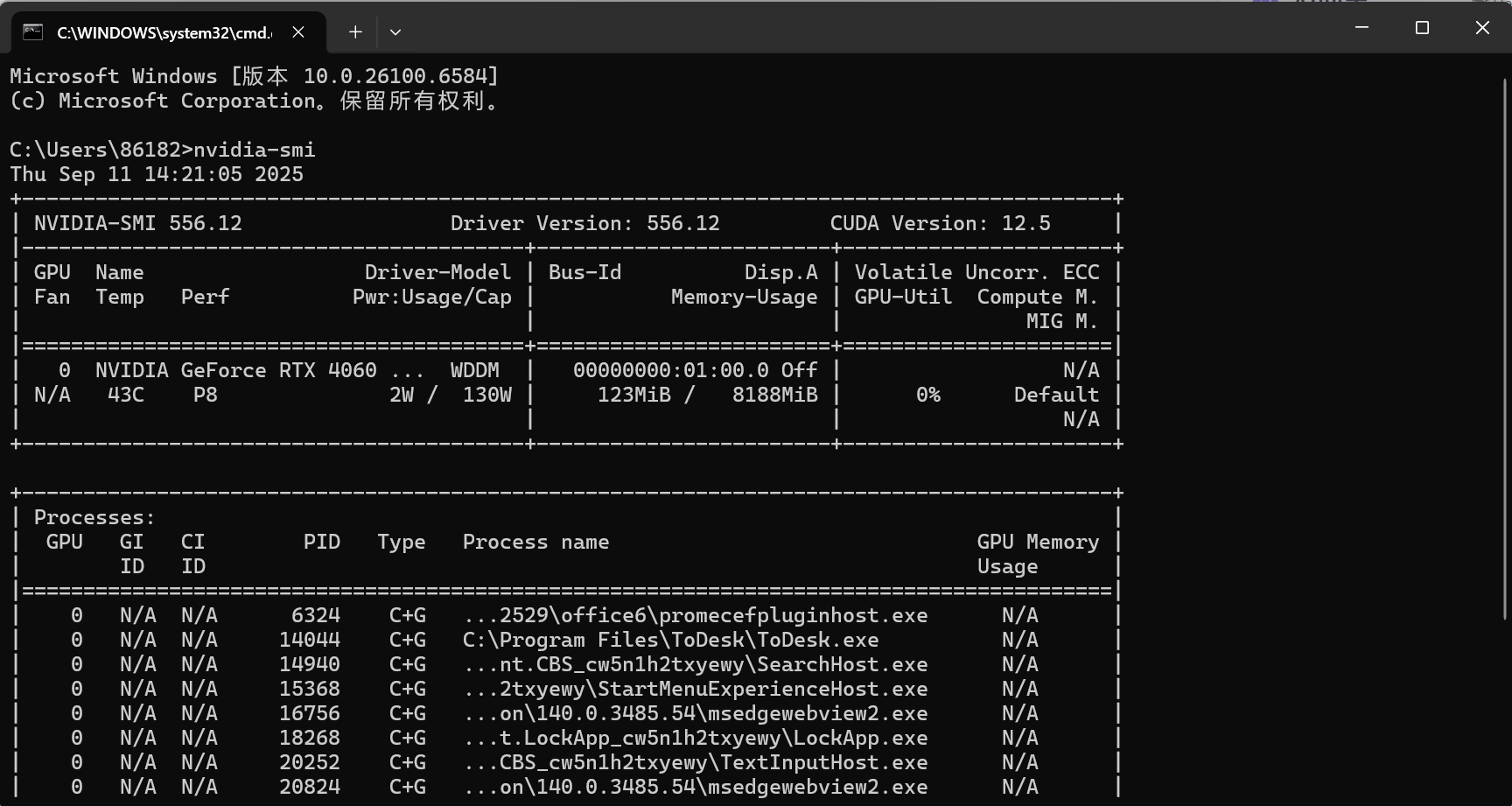
在shell中输入:nvidia-smi可以查看你当前的CUDA版本信息,可以看见我的版本是12.5
接下来下载Pytorch的时候就要根据这个来下载(向下兼容)
2.查看Anaconda中的Pytorch的版本:
1.进入虚拟环境
2.输入python
3.输入:
import torch
print(torch.__version__)
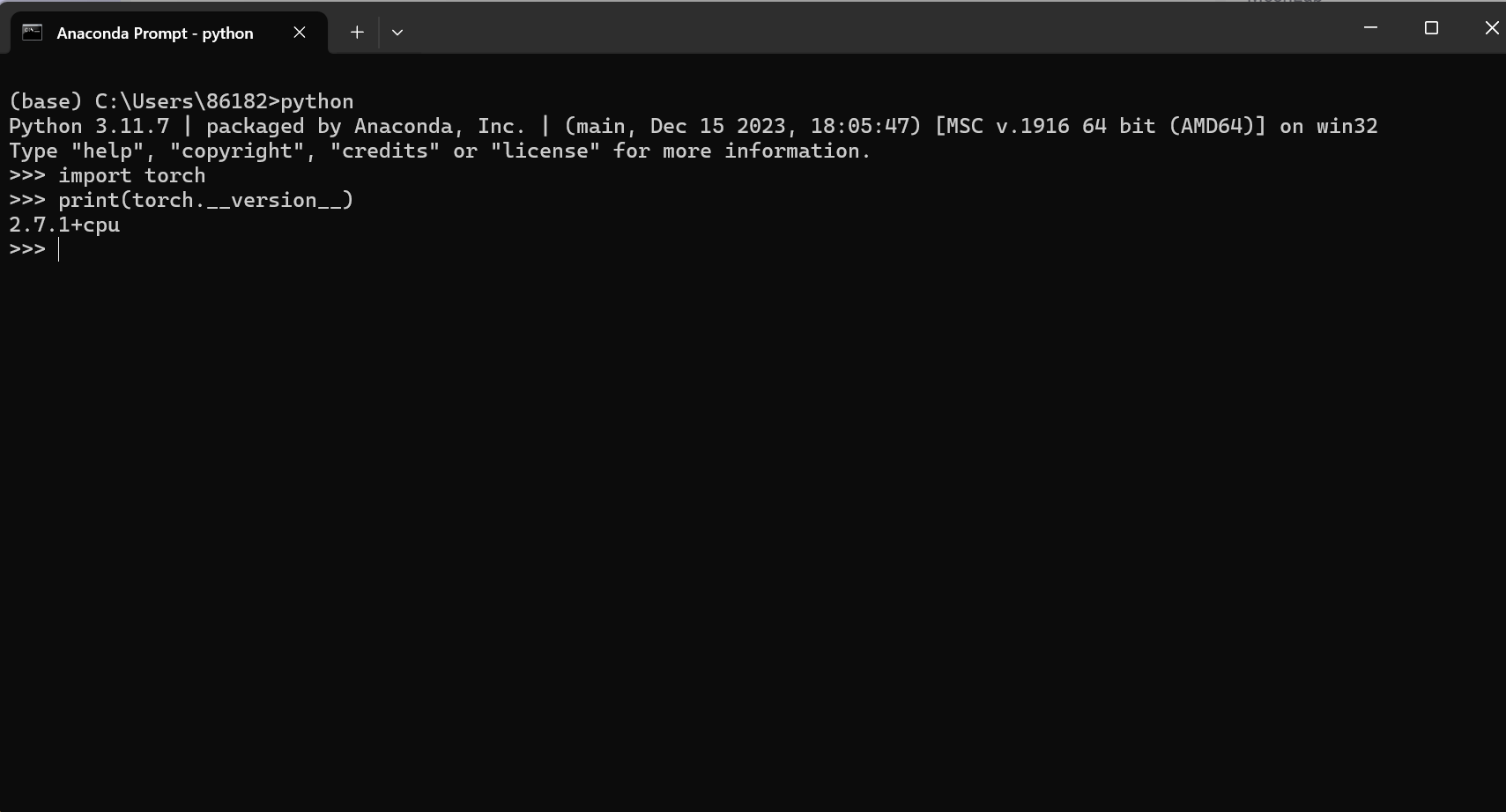
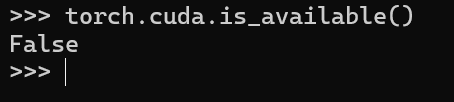
这一步说明我的虚拟环境中下载的是cpu版本的pytorch
2.7.1:这是 PyTorch 的主版本号,其中2是大版本,7是次版本,1是补丁版本,用于标识具体的软件版本迭代。+cpu:表示这个 PyTorch 版本是 仅支持 CPU 计算 的版本,不包含 GPU 加速功能(如 CUDA 支持)。如果你的电脑没有 NVIDIA 显卡,或者安装时选择了仅 CPU 版本,就会显示这个标识。
如果需要使用 GPU 加速(需满足 NVIDIA 显卡且支持 CUDA 架构),需要安装带有 +cuXXX 标识的版本(如 2.7.1+cu121,其中 cu121 表示支持 CUDA 12.1)
3.查看可用的CUDA数量
import torch #如果pytorch安装成功即可导入
print(torch.cuda.device_count()) #查看可用的CUDA数量这时候我需要新建一个虚拟环境用作GPU版本的pytorch运行
进入conda prompt,然后输出python查看你目前的pytorch版本:

# 创建名为myenv的虚拟环境,指定Python版本为3.11
conda create --name pytorch python=3.11执行命令后,会显示将要安装的包,输入y并回车确认安装。
这样就新建好虚拟环境啦,然后就是要下载用于Pytorch跑GPU的CUDA版本啦
第一种方法是在CUDA的官网下载CUDA:点击下面这个链接
Get Started
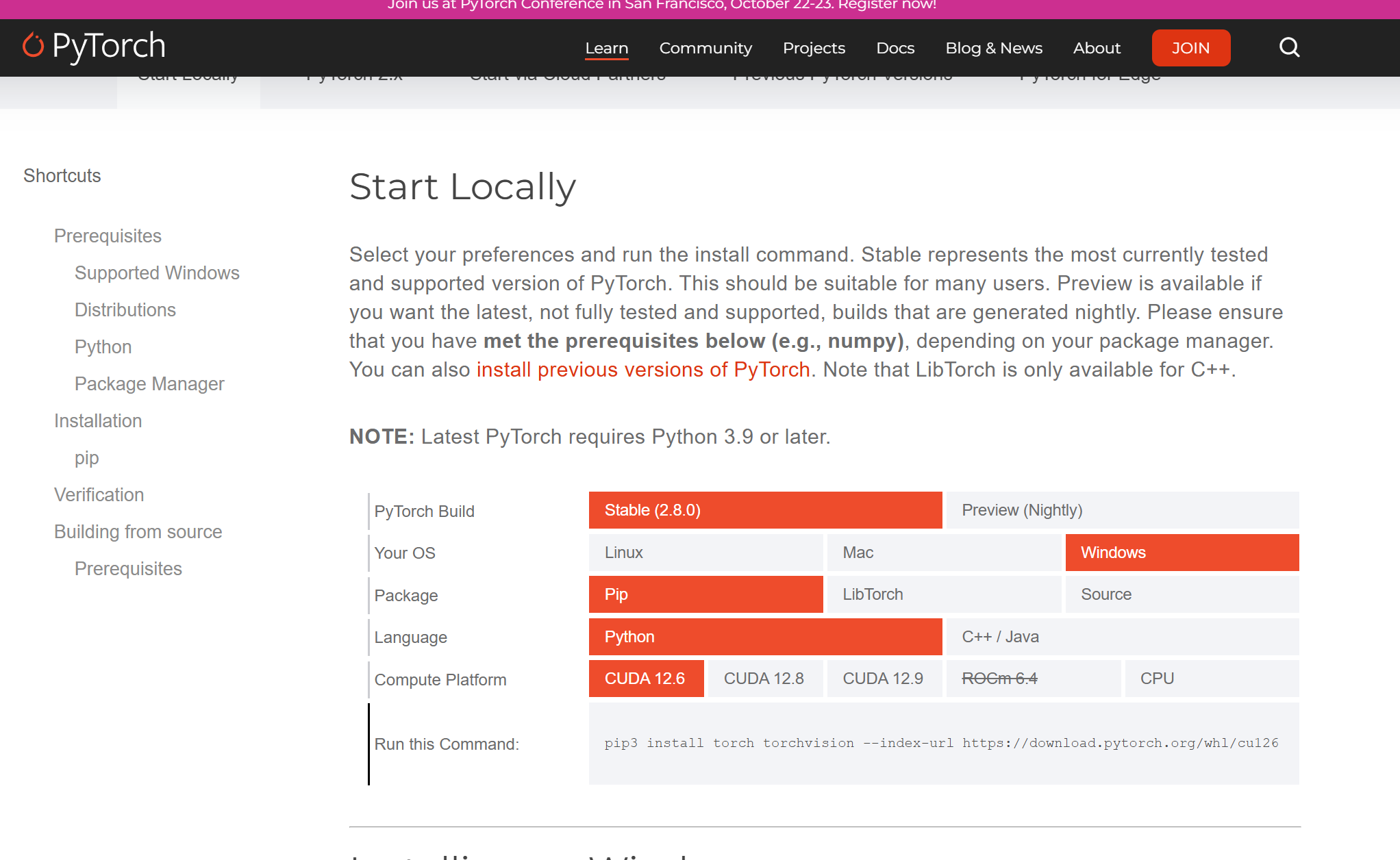
首先先激活你的pytorch虚拟环境,然后复制上面的链接就可以开始下载啦
值得一提的是目前由于conda环境难维护,官方已经不维护conda环境的下载了,只能选择pip的下载方式。
下面一种方法适合你当前电脑的CUDA版本比官网上的最低版本还低,而且又懒得升级CUDA版本的,就去下面这个链接下载以前版本的pytorch。
Previous PyTorch Versions
到上面这个网址里下载过去版本的pytorch
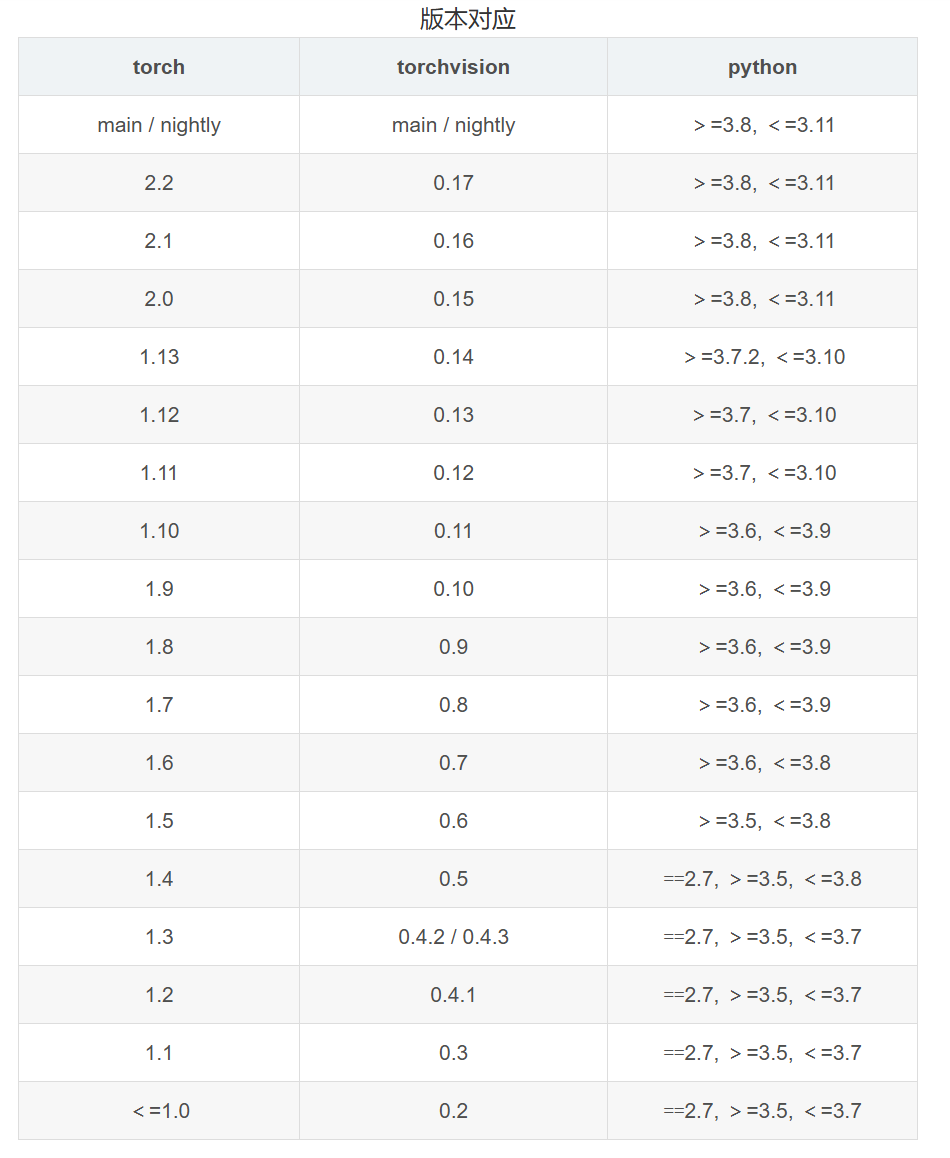
根据版本对应关系和上面你的CUDA版本情况输入指令:
例如:
pip install pytorch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 pytorch-cuda=11.7 -c pytorch -c nvidia同样也是将这段bash复制到你激活的虚拟环境里

这样就安装完成啦~
如果觉得慢的也可以使用其它源:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121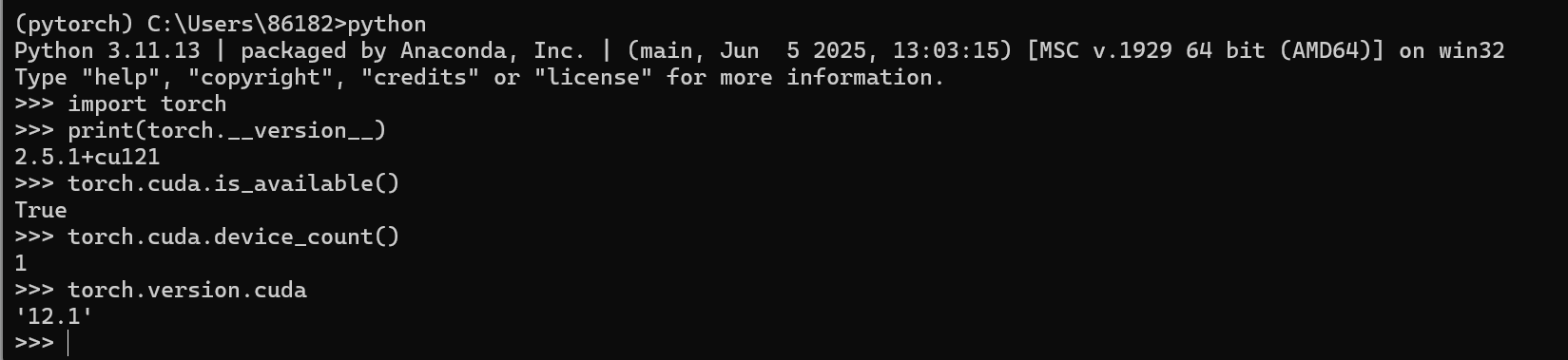
import torch
torch.cuda.is_available() # 查看pytorch是否支持CUDA
torch.cuda.device_count() # 查看可用的CUDA数量
torch.version.cuda # 查看对应CUDA的版本号
可以发现我现在已经配置好了pytorch的GPU版的虚拟环境
四、下载CUDNN
CUDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
第一次下载需要注册英伟达账号
下载链接:
知乎 - 安全中心
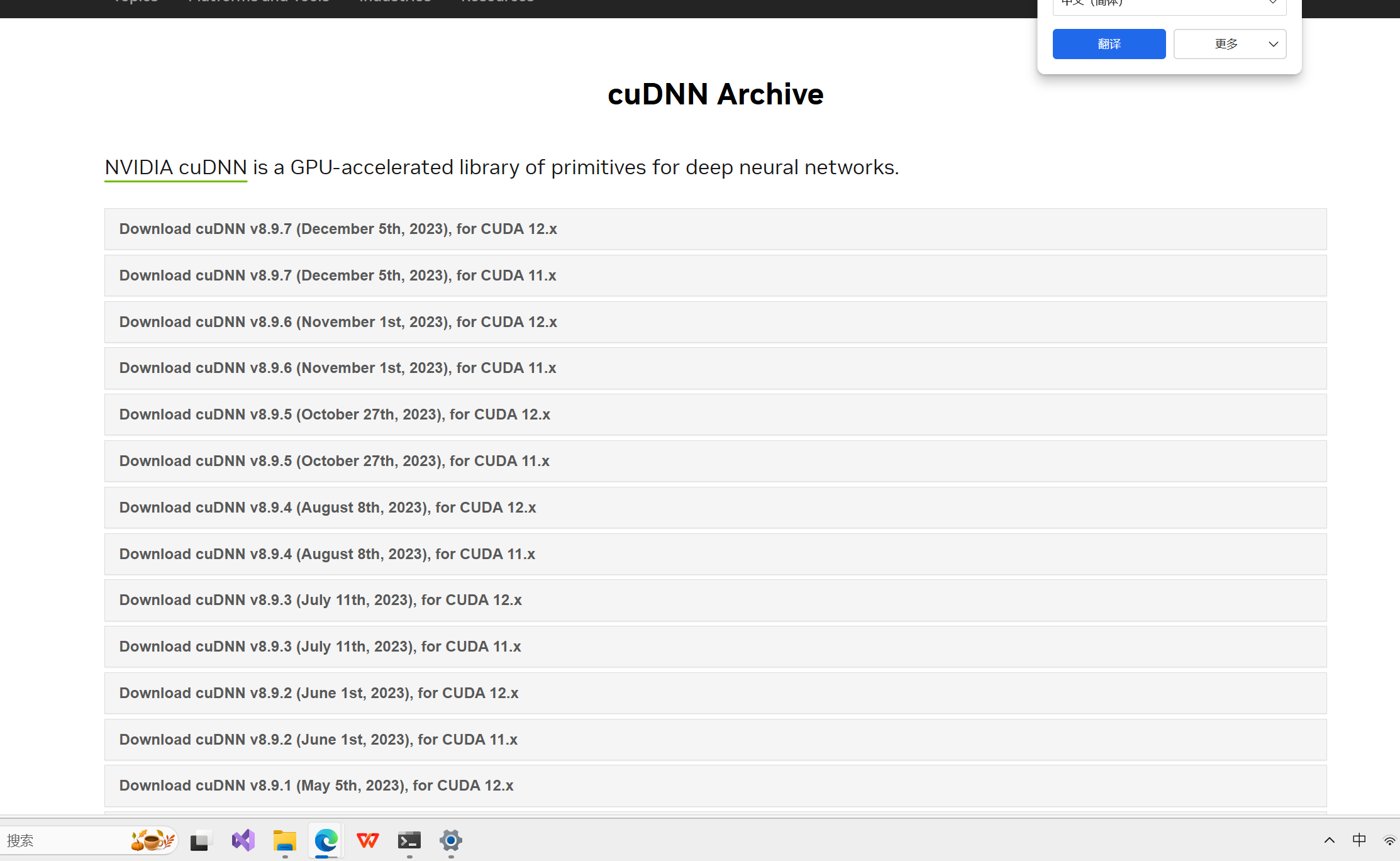
下载好之后解压
将bin,include,lib文件夹中的文件分别移动到Cuda对应的文件夹中:
路径类似: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12
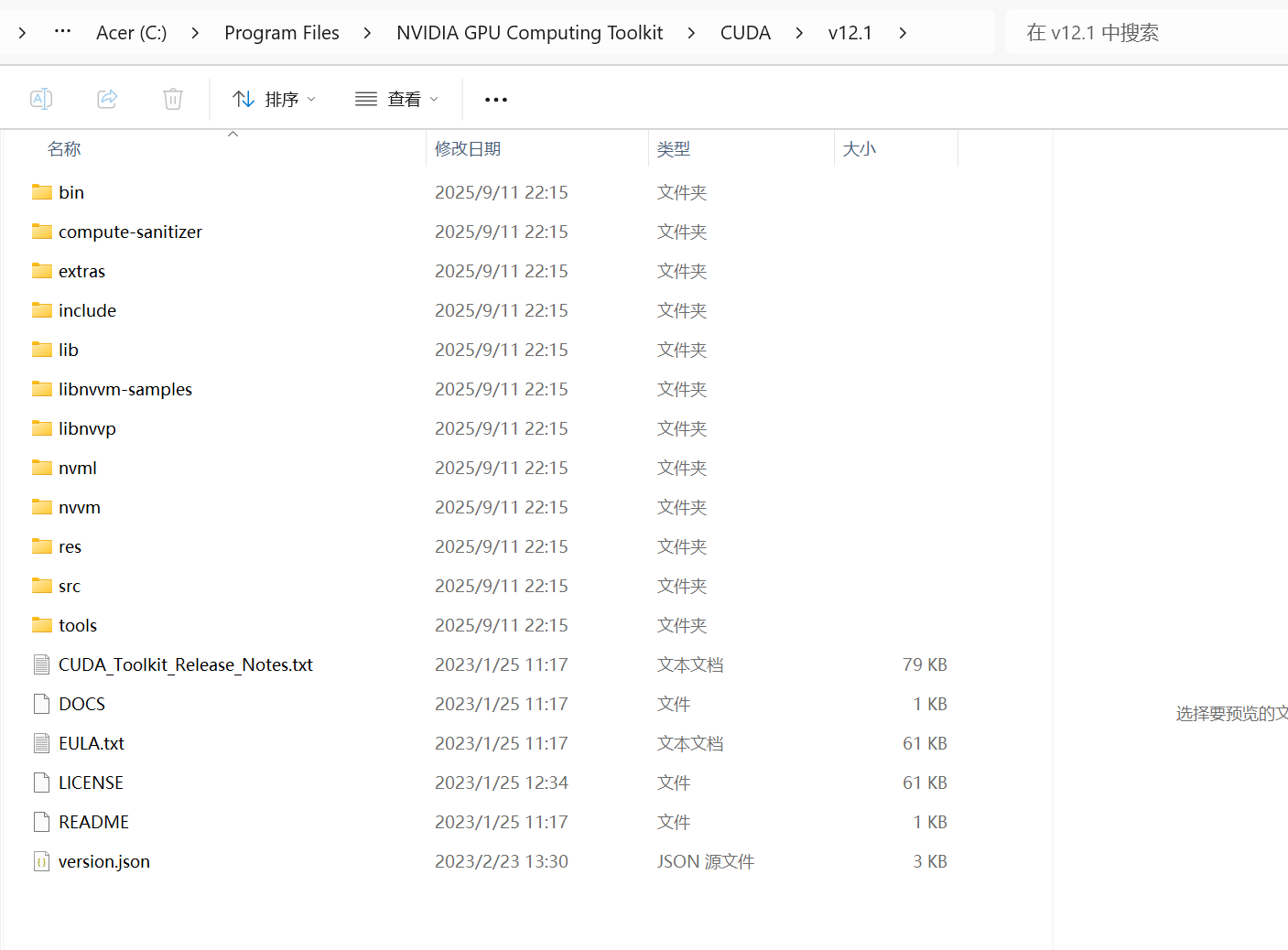
替换后找到类似这个文件夹:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\extras\demo_suite
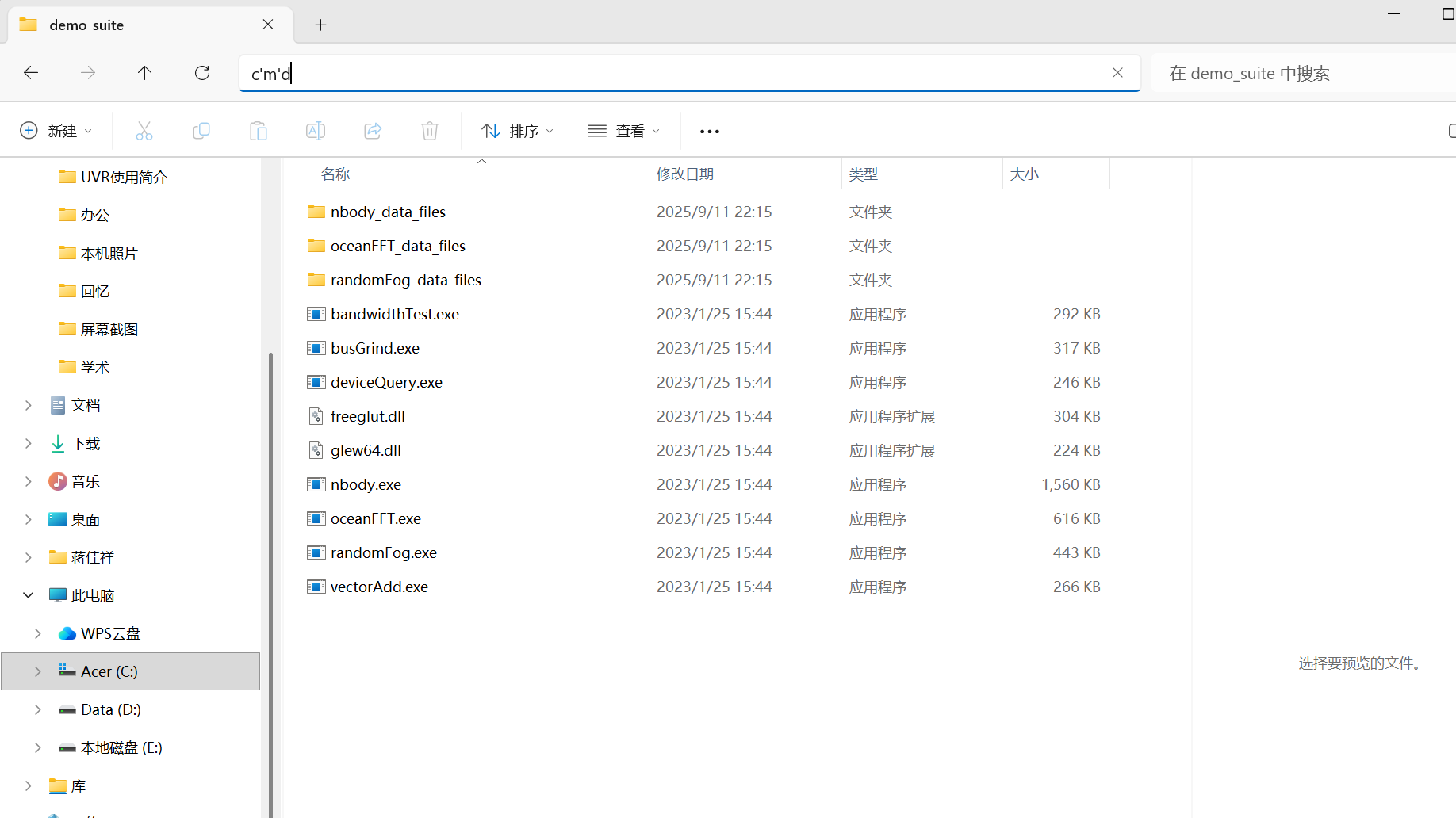 输入cmd,点回车,打开命令行:
输入cmd,点回车,打开命令行:
分别输入一下两个命令:
bandwidthTest.exe
deviceQuery.exe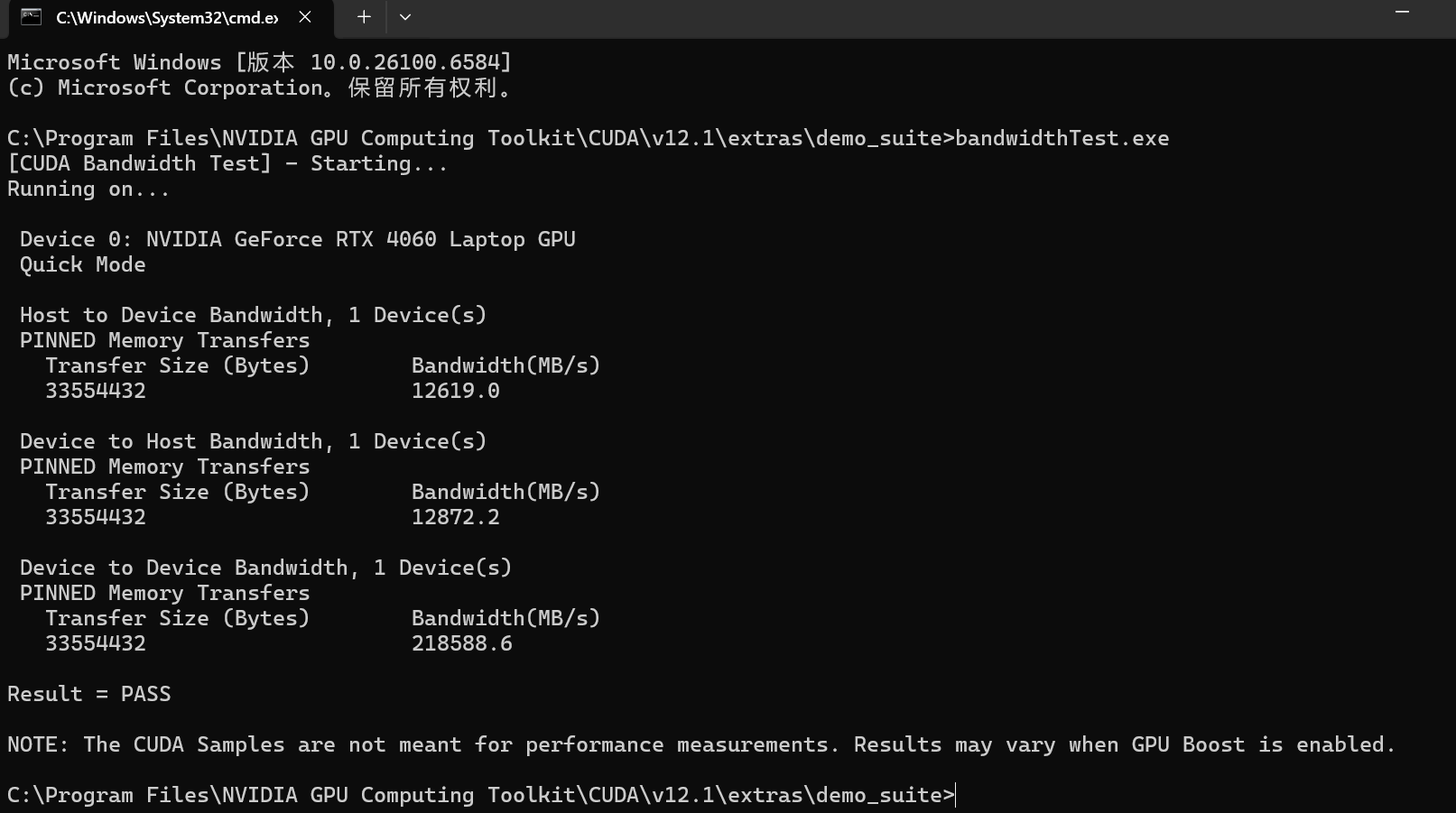
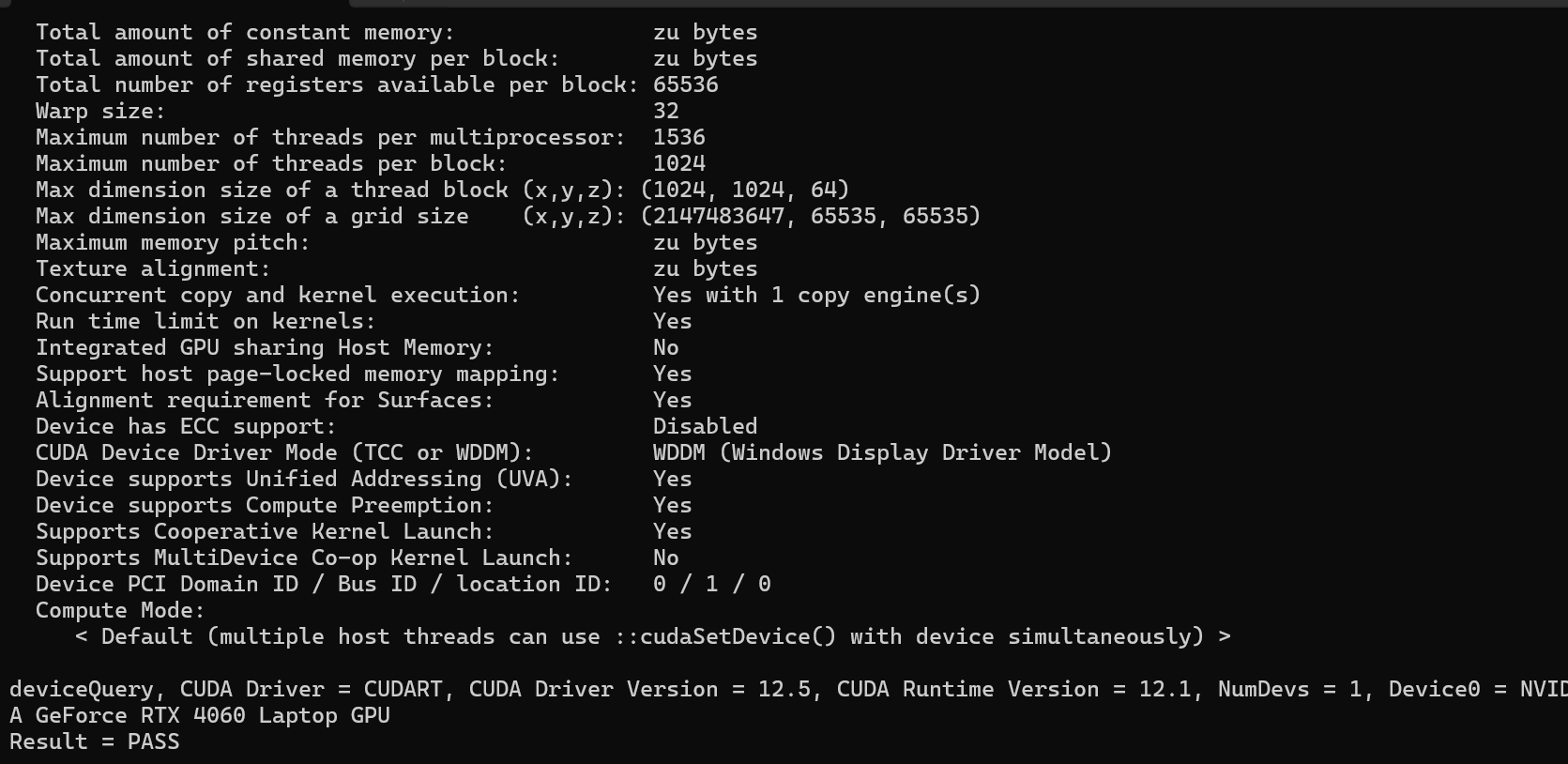
如果出现Result=PASS,则说明安装成功。
接下来就可以在你建立的虚拟环境中愉快地玩耍深度学习啦~
五、总结
其实本质上就是anaconda作为包管理工具,Pytorch要根据自己电脑支持的CUDA版本下载到这个环境上,另外CUDA也要相同的版本,至于说CUDNN是CUDA的一部分,也是深度学习的工具。实际上我们电脑自己就有CUDA-CPU版本,不用再下载了,只要在相应环境上下载Pytorch包就可以。CUDA-GPU版本可以单独下载,也可以在虚拟环境上下载好Pytorch-GPU后直接使用,因为anaconda里包含了 PyTorch 运行所需的 CUDA 动态链接库,如果需要 nvcc 编译器(比如编译自定义 CUDA 算子和CUDNN),则需要单独安装完整的 CUDA Toolkit。即如果只是用 PyTorch 跑模型,不需要额外操作;如果需要编译 CUDA 代码,才需要安装完整的 CUDA Toolkit。
六、测试代码
import torchdef test_cuda_and_cudnn():# 检查CUDA是否可用print(f"CUDA可用: {torch.cuda.is_available()}")if not torch.cuda.is_available():print("请检查CUDA配置,当前无法使用GPU")return# 查看CUDA版本和设备信息print(f"CUDA版本: {torch.version.cuda}")print(f"GPU设备数量: {torch.cuda.device_count()}")print(f"当前使用的GPU: {torch.cuda.get_device_name(0)}") # 查看第0号GPU名称# 测试GPU计算print("\n测试GPU计算...")# 在GPU上创建张量a = torch.tensor([1.0, 2.0, 3.0], device='cuda')b = torch.tensor([4.0, 5.0, 6.0], device='cuda')c = a + b # 在GPU上执行加法print(f"GPU计算结果: {c.cpu().numpy()}") # 转回CPU并打印# 测试CuDNNprint("\n测试CuDNN加速...")# 检查CuDNN是否可用print(f"CuDNN可用: {torch.backends.cudnn.enabled}")# 使用CuDNN加速的卷积操作# 创建随机输入张量和卷积权重(均在GPU上)input_tensor = torch.randn(1, 3, 64, 64, device='cuda') # 批次1,3通道,64x64conv = torch.nn.Conv2d(3, 16, kernel_size=3, device='cuda') # 卷积层# 开启CuDNN加速(默认开启)torch.backends.cudnn.benchmark = True# 执行卷积操作output = conv(input_tensor)print(f"CuDNN加速的卷积输出形状: {output.shape}") # 应输出(1, 16, 62, 62)print("\n所有测试完成,CUDA和CuDNN工作正常!")if __name__ == "__main__":test_cuda_and_cudnn()结果:
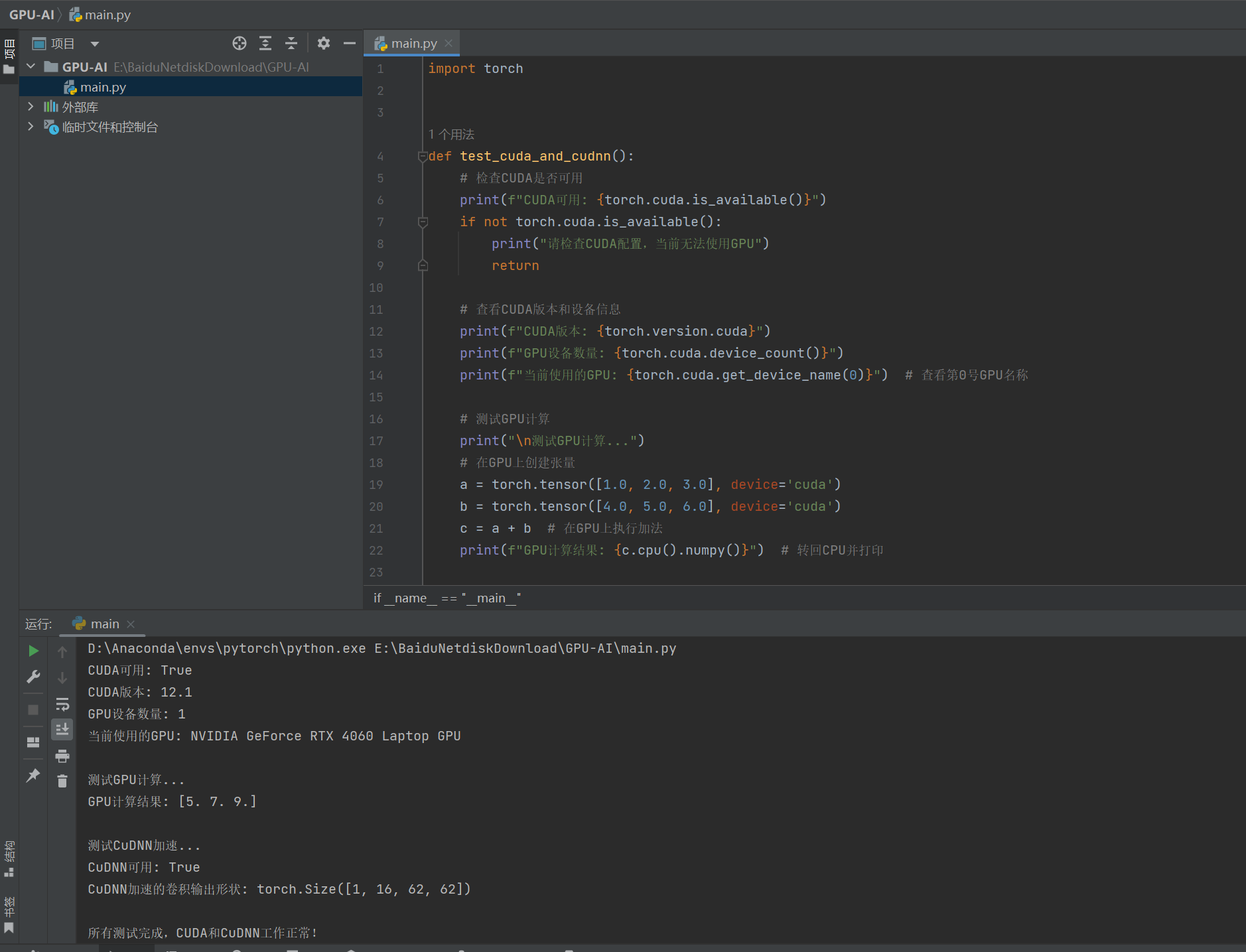
一切正常!!!记得环境使用你创建的那个Pytorch-GPU的虚拟环境~
参考博客:
1.(59 封私信 / 80 条消息) 安装Cuda和cudnn,以及Pytorch的GPU版本 - 知乎
2.CUDA&Pytorch安装使用(保姆级避坑指南)_pytorch cuda-CSDN博客
3.啥是CUDA?它和Pytorch、GPU之间有啥关系? - Tutu007 - 博客园