EFK+DeepSeek 智能运维方案:技术架构与实施步骤
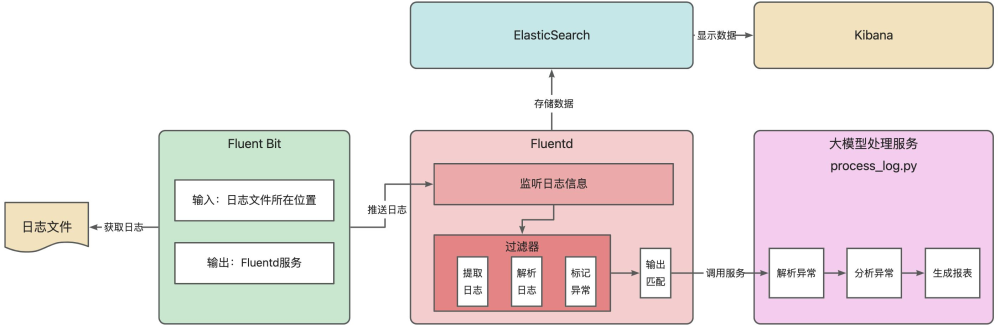
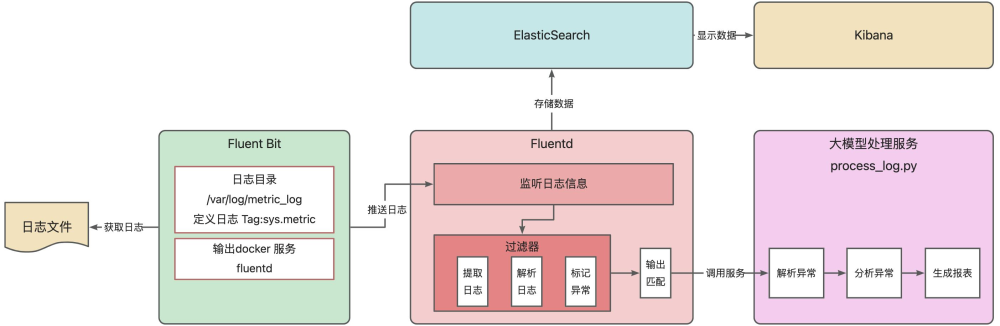
本文将围绕 EFK(Fluent Bit + Fluentd + Elasticsearch + Kibana)结合 AI 大模型的日志智能运维方案展开。先利用 Fluent Bit 从指定位置获取日志,依解析规则处理后推送给 Fluentd;Fluentd 监听日志,经过滤器提取、解析并标记异常,再输出给 Elasticsearch 存储,同时调用大模型处理服务;Elasticsearch 存储

开篇
在日常 IT 运营场景里,EFK(Elasticsearch +Fluent Bit + Fluentd + Kibana )组合是日志管理与分析的经典方案,被广泛应用于各类系统运维中。它凭借 Fluent Bit 轻量高效的日志采集能力,快速获取多源日志;依托 Fluentd 灵活的日志处理机制,完成过滤、格式化等操作;借由 Elasticsearch 强大的分布式存储与检索特性,实现日志的高效存储和快速查询;再通过 Kibana 直观的可视化界面,让运维人员能清晰洞察日志数据背后的系统状态,以 “采集 - 处理 - 存储 - 可视化” 的完整链路,助力运维团队及时发现系统问题,成为保障 IT 系统稳定运行的有力工具。
然而,在实际运维过程中,面对日志里海量的错误异常信息,仅靠传统 EFK 方案仍存在短板。IT 运维人员受限于精力和时间,面对繁杂的异常日志,难以逐一对其深入拆解、分析根源,常常错过最佳修复时机,导致小故障演变成影响业务的大问题。为突破这一困境,我们尝试引入 AI 运维模式,借助 AI 大模型对 EFK 采集到的异常信息进行智能分析,让机器替代人工完成繁琐的异常诊断、根因定位等工作,以此提升运维效率与质量。
如下图所示,本文将围绕 EFK(Fluent Bit + Fluentd + Elasticsearch + Kibana)结合 AI 大模型的日志智能运维方案展开。先利用 Fluent Bit 从指定位置获取日志,依解析规则处理后推送给 Fluentd;Fluentd 监听日志,经过滤器提取、解析并标记异常,再输出给 Elasticsearch 存储,同时调用大模型处理服务;Elasticsearch 存储的数据可在 Kibana 可视化展示;大模型处理服务则对异常日志解析、分析并生成报表。以 CPU 使用率异常场景为例,演示从日志采集、处理到智能诊断的全流程。
安装环境
工欲善其事必先利其器,在开始案例之前我们先把需要用到的应用和环境安装上,首先保证 docker 安装完成,然后从文件夹到容器的安装,按照如下流程进行。
创建文件夹
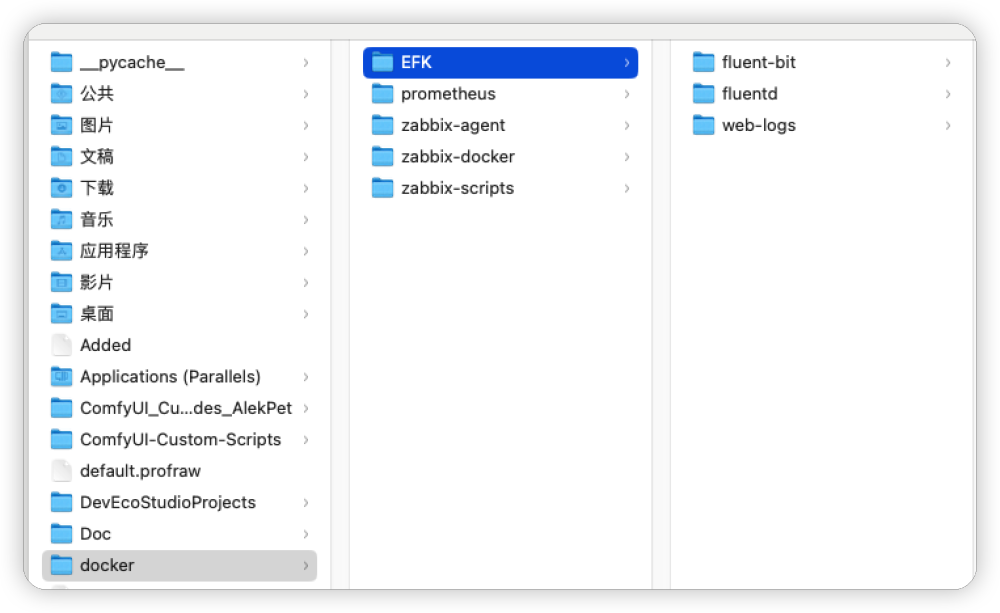
准备好 fluent-bit、fluentd 以及 web-logs 文件夹。分别用来放置容器的配置文件和对应的日志文件。
请注意,我这里以/Users/cuihao/docker 为基础目录, 在这个目录下创建文件夹和文件,大家可以按照自己的操作系统和目录情况规划目录以及存放文件。
如下图所示, 我们可以看到 fluent-bit、fluentd 以及 weblogs 三个目录。稍后我们会分别在这三个目录下面放置对应应用的配置文件,用来完成日志采集、分析、过滤、输出等操作。
在完成文件夹的创建之后,接着在 fluent-bit 文件夹下创建 etc 目录,后面会在 etc 下面创建 fluent-bit.conf 文件,用来配置日志采集的输入和输出信息。
完成 fluent-bit 文件夹创建之后,接着在 fluentd 文件夹下面创建 conf 文件夹,为 fluent.conf 的创建做好准备。这里可以剧透一下,在fluent.conf 会有日志采集、过滤、标记、调用智能报表等配置信息。
最后,就是保证创建一个 web-logs 目录,下面的 metric_log 文件是我们用来模拟 CPU 使用率数据的日志文件。也是案例的起点, fluent-bit 会从这里采集数据。
创建 FluentD Docker 文件
完成目录布局之后,我们大致知道完成案例大致需要的配置信息,接着在目录/Users/cuihao/docker/EFK/fluentd/ 下创建 Dockerfile 文件。这个文件用来安装 fluentd 的基础镜像以及对应的插件。
复制
# 使用的基础镜像FROM fluent/fluentd:edge-debian# 切换用户为root方便接下来执行安装命令USER root# 安装系统依赖RUN apt-get update && \apt-get install -y curl && \rm -rf /var/lib/apt/lists/*# 卸载可能存在的高版本 Elasticsearch gemRUN gem uninstall elasticsearch elasticsearch-api -a -x || true# 安装指定版本 gem 和 Fluentd Elasticsearch 插件RUN gem install elasticsearch -v 8.17.1 --no-document && \gem install elasticsearch-api -v 8.17.1 --no-document && \gem install fluent-plugin-elasticsearch -v 5.4.3 --no-documentUSER fluent- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
上述 Dockerfile 文件以官方 fluentd 的 edge-debian 版本,在这个版本的基础上 fluentd 还需要配置数据转发或聚合操作,比如本例中需要转发到ES,就需要安装对应的插件(fluent-plugin-elasticsearch)。这些插件就需要通过 Dockerfile 文件的方式安装。
从文件中可以看到,首先切换到 root 用户安装系统依赖 curl,再清理可能存在的高版本 Elasticsearch 相关组件,随后安装 8.17.1 版本的 elasticsearch(注意这里使用的 ES 版本)、elasticsearch-api gem 包及 5.4.3 版本的 fluent-plugin-elasticsearch 插件,确保与目标 Elasticsearch 服务兼容,最后切换回 fluent 普通用户以遵循最小权限原则,最终生成一个可直接用于 EFK 日志栈中收集并向 Elasticsearch 发送日志的定制化镜像。
创建 EFK 组件docker-compose 文件
由于本案例需要安装 fluent-bit、fluentd、elasticsearch、kibana 等应用,为了方便安装与调试,我们计划使用 docker 方式对他们进行安装。于是 docker compose 的安装方式就成了最佳选择,它可以用于定义和管理多容器 Docker 应用的 YAML 配置文件,能将多个关联的容器(如应用服务、数据库、缓存等)的配置(镜像、端口映射、数据卷、环境变量、依赖关系等)集中整合,通过 docker compose 命令一键实现多容器的创建、启动、停止、重启等操作。其核心益处在于简化了多容器应用的部署与管理流程,避免了手动逐个操作容器的繁琐;通过统一配置文件确保了环境一致性,同时清晰的依赖关系定义保证了容器按正确顺序启动。
为了保证安装的顺利进行我们选择Fluentd官网的docker-compose 文件,并在其基础上进行修改,从而适应安装需求。
由于该文件内容比较长,这里我们通过一张大图将文件的内容进行描述,如下:
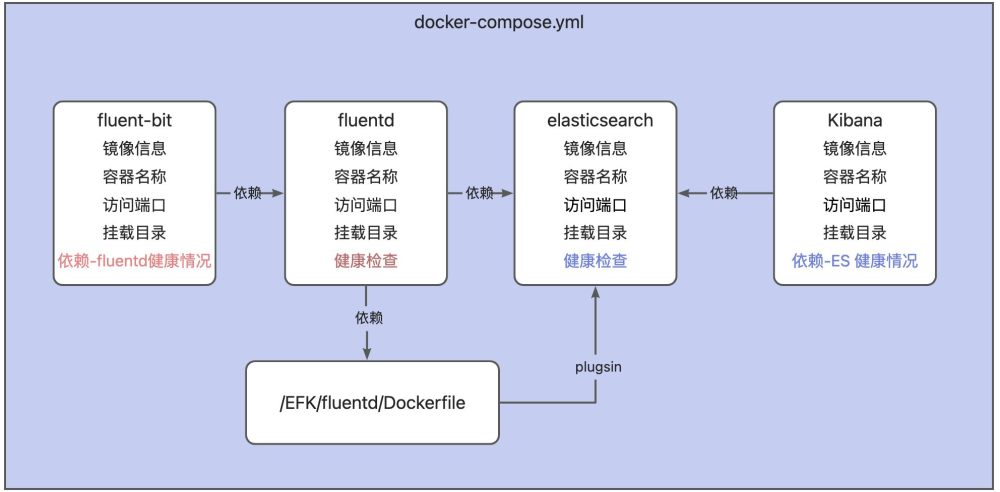
该文件用于搭建 EFK(Fluent Bit + Fluentd + Elasticsearch + Kibana)日志管理系统。通过定义 fluent-bit(轻量采集容器日志,依赖 fluentd 健康后启动,配置挂载日志目录与配置文件)、fluentd(基于自定义 Dockerfile 构建,格式化日志,依赖 elasticsearch 健康后启动,配置挂载、端口及健康检查 )、elasticsearch(存储日志,单节点模式、关闭安全功能,配置健康检查与端口 )、kibana(可视化日志,依赖 elasticsearch 健康后启动,映射 Web 端口 )四个服务,利用 Docker Compose 实现多容器协同,让日志从采集、处理、存储到可视化全流程自动化部署与管理,各服务间通过健康检查依赖保障启动顺序与运行状态,方便快速搭建日志分析环境。
文件内容如下:
复制
# 定义本文件中所有要启动的服务(容器)services:# Fluent Bit:轻量收集容器日志# 【服务名】是的,'fluent-bit' 就是这个服务的名称。它在 Docker Compose 网络内部被识别为此名。fluent-bit:# 使用的镜像:从 Docker Hub 拉取最新的 Fluent Bit 官方镜像image: fluent/fluent-bit:latest# 指定容器启动后的名称,通过 `docker ps` 等命令可以看到这个名字container_name: fluent-bit# 依赖关系:指定此服务的启动依赖于另一个服务 'fluentd'depends_on:fluentd:# 条件:只有当 'fluentd' 服务通过健康检查(healthy)后,才会启动 fluent-bitcondition: service_healthy# 端口映射:将宿主机的端口映射到容器内的端口# 格式 - "宿主机端口:容器端口"ports:- "2020:2020" # 将容器内的 2020 端口(Fluent Bit 的 HTTP Server,常用于健康检查或监控)映射到宿主机的 2020 端口# 数据卷挂载:将宿主机的目录或文件挂载到容器内,实现数据持久化或配置注入volumes:# 将宿主机的 '/Users/cuihao/docker/EFK/web-logs' 目录挂载到容器内的 '/var/log/' 目录。# Fluent Bit 会监控这个目录下的日志文件变化,并收集新产生的日志。#/var/log/metric_log#/Users/cuihao/docker/EFK/web-logs- /Users/cuihao/docker/EFK/web-logs:/var/log/# 将宿主机的 Fluent Bit 主配置文件挂载到容器内,替代镜像内的默认配置。# 这个文件定义了数据输入(Input)、处理(Parser, Filter)和输出(Output)的规则。- /Users/cuihao/docker/EFK/fluent-bit/etc/:/fluent-bit/etc/# Fluentd:格式化# 【服务名】'fluentd' 是这个服务的名称。fluentd:container_name: fluent# 不是使用现成的镜像,而是通过指定构建上下文路径(E:\EFK\fluentd)来构建自定义镜像。# 该路径下应该有一个名为 'Dockerfile' 的文件,默认读取 'Dockerfile' 文件。build: /Users/cuihao/docker/EFK/fluentdvolumes:# 将宿主机上的 Fluentd 配置目录挂载到容器内,使配置变更无需重新构建镜像。- /Users/cuihao/docker/EFK/fluentd/conf:/fluentd/etcdepends_on:elasticsearch:condition: service_healthyports:- "24224:24224" # Fluentd 默认的 TCP 端口,用于接收来自 Fluent Bit 或其他客户端转发来的日志,这个端口会配置到fluent-bit的OUTPUT中- "24224:24224/udp" # Fluentd 默认的 UDP 端口,用途同上- "24220:24220" # Fluentd 的健康检查 API 端口# 健康检查配置:Docker 会根据此规则判断容器是否正常启动healthcheck:test: ["CMD-SHELL", "curl -fs http://localhost:24220/api/plugins.json || exit 1"] # 检查健康检查端点是否返回成功interval: 5s # 每 5 秒检查一次timeout: 3s # 每次检查超时时间为 3 秒retries: 5 # 连续失败 5 次才标记为不健康start_period: 10s # 容器启动后,等待 10 秒再进行第一次健康检查# Elasticsearch:存储日志# 【服务名】'elasticsearch' 是这个服务的名称。elasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:8.17.1 # 使用 Elastic 官方的 8.17.1 版本镜像container_name: elasticsearchhostname: elasticsearch # 设置容器内部的主机名,在集群中很有用environment:- discovery.type=single-node # 设置为单节点模式,适合开发和测试- xpack.security.enabled=false # 关闭 X-Pack 安全功能(用户认证、HTTPS等)。生产环境必须开启,但测试时关闭更简单。healthcheck:test: ["CMD", "curl", "-f", "http://localhost:9200/_cluster/health"] # 检查 ES 集群健康状态 APIinterval: 10sretries: 5timeout: 5sports:- "9200:9200" # 将 ES 的 HTTP REST API 端口映射到宿主机,方便通过浏览器或命令访问# Kibana:日志可视化# 【服务名】'kibana' 是这个服务的名称。kibana:container_name: kibanaimage: docker.elastic.co/kibana/kibana:8.17.1 # Kibana 版本需要与 Elasticsearch 版本一致depends_on:elasticsearch:condition: service_healthy # 等待 Elasticsearch 健康后再启动ports:- "5601:5601" # 将 Kibana 的 Web 界面端口映射到宿主机,通过 http://localhost:5601 访问- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
启动 EFK 组件
有了前面的准备, EFK 都通过 Docker 镜像的方式进行了定义,接着只需要执行 docker compose 命令就可以安装了。
执行如下命令启动容器安装 EFK 组件:
复制
docker compose -f /Users/cuihao/docker/EFK/docker-compose.yml up -d- 1.
如果出现如下错误:
复制
=> ERROR [fluentd internal] load metadata for docker.io/fluent/fluentd:edge-debian 31.1s------> [fluentd internal] load metadata for docker.io/fluent/fluentd:edge-debian:------failed to solve: DeadlineExceeded: DeadlineExceeded: DeadlineExceeded: fluent/fluentd:edge-debian: failed to resolve source metadata for docker.io/fluent/fluentd:edge-debian: failed to authorize: DeadlineExceeded: failed to fetch anonymous token: Get "https://auth.docker.io/token?scope=repository%3Afluent%2Ffluentd%3Apull&service=registry.docker.io": dial tcp 75.126.124.162:443: i/o timeout- 1.
- 2.
- 3.
- 4.
- 5.
说明需要手动拉取 fluentd 的镜像,执行如下命令:
复制
docker pull fluent/fluentd:edge-debian- 1.
再次执行如下命令:
复制
docker compose -f /Users/cuihao/docker/EFK/docker-compose.yml up -d- 1.
完成安装之后,可以通过 docker desktop 看到容器服务正常运行。如下图所示,

配置日志采集与分析
完成 EFK 的安装之后,接下来就开始应用之间的配置了。在配置之前,我们先回顾一下案例的整体思路,fluent-bit 是日志采集的第一步,它会从日志文件中采集日志的信息,这里需要定义日志目录。如图所示,绿色区域中我们需要配置“日志目录”,同时还需要制定fluent-bit 采集之后需要将日志信息输出到 fluentd 中,这里需要填入“fluentd”作为输出的服务名。
配置 Fluent Bit
从上面的描述,我们清楚需要对 fluent-bit 的输入和输出进行配置,接下来就是编写配置文件了。在/Users/cuihao/docker/EFK/fluent-bit/etc 创建 fluent-bit.conf 文件如下:
复制
############################################### 输入插件配置(收集日志)############################################### 输入源1:采集cpu日志文件[INPUT]# 使用 tail 插件监控文件变化Name tail# 自定义标签,标识为系统指标类日志Tag sys.metric # 系统指标日志文件路径(可能是由其他工具生成的指标数据)Path /var/log/metric_log# 检查文件变化的间隔时间(秒)Refresh_Interval 10 ############################################### 输出插件(转发到 Fluentd)##############################################[OUTPUT]# 使用 forward 插件将日志转发到Fluentd聚合器Name forward# 匹配所有标签的日志(* 是通配符,表示所有输入源)Match *# Fluentd 服务地址(使用Docker Compose服务名进行服务发现)Host fluentd# Fluentd 监听端口(forward插件的默认端口)Port 24224# 网络故障时的最大重试次数,防止无限重试消耗资源Retry_Limit 10# 输出源2:同时输出到控制台(用于调试和监控)[OUTPUT]# 使用 stdout 插件在控制台打印日志Name stdout# 匹配所有标签的日志Match *# 注意:生产环境通常应注释或移除此输出,避免日志重复和性能开销- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
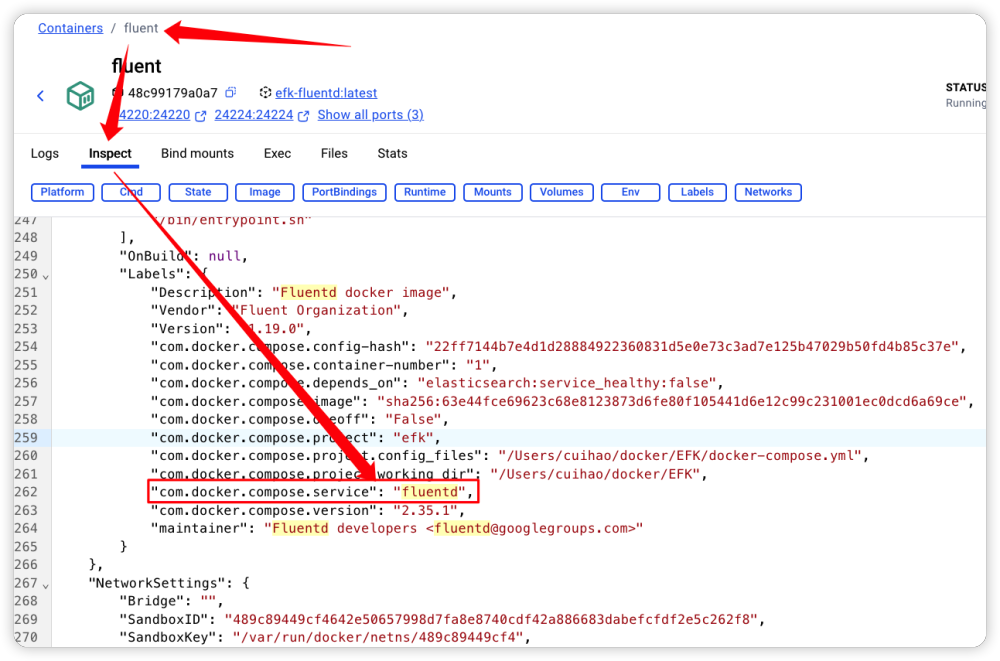
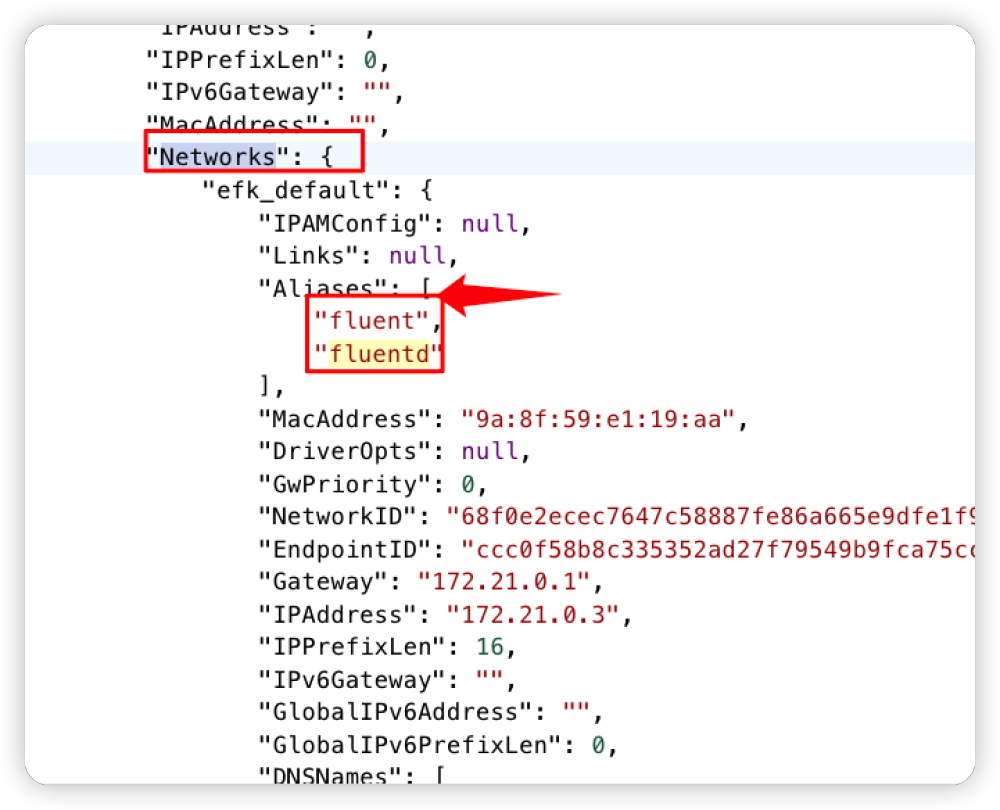
由于文件中的配置信息都用了备注,比较容易理解就不逐一解释了。需要注意的是配置文件中的 Host 对应的 fluentd 是 docker 容器的服务名,由于这几个应用是通过 docker compose 安装的能够保证在相同的网络内,所以可以通过服务名进行访问,通过下图的方式查询。
配置 Fluentd
完成 fluent bit 的配置之后,紧接着就需要对 fluentd 进行配置了,它是整个配置环节的重头戏,这里还是以案例整体大图为例。将 fluentd 的部分进行展开说明, 如下图所示。Fluent Bit 从日志文件获取日志并推送给 Fluentd,Fluentd 经 24224 端口监听接收。先由过滤器按规则提取日志(过滤指定 Tag、正则提取 JSON )、解析日志(自定义 JSON 解析器处理原始日志),若 CPU 使用率超 80% 则标记异常;接着通过多路输出,将日志存至 Elasticsearch、输出到控制台,还会对标记异常的日志,调用大模型处理服务(process_log.py )进一步分析。
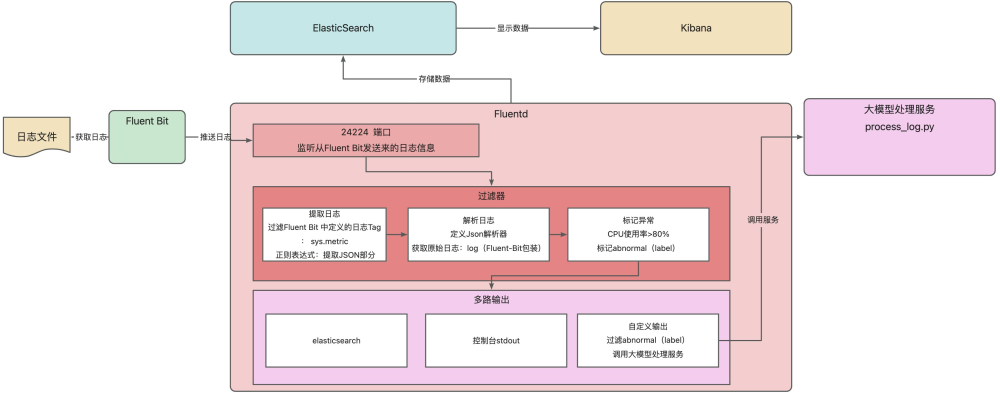
在/Users/cuihao/docker/EFK/fluentd/conf 目录下创建 fluent.conf 文件,内容如下:
复制
################################ Fluentd 健康检查(monitor_agent)###############################<source>@type monitor_agent # 启用监控代理插件,用于收集Fluentd自身运行指标bind 0.0.0.0 # 监听所有网络接口port 24220 # 监控服务端口,可通过此端口获取Fluentd运行状态信息</source>################################ Fluentd 日志输入(forward)###############################<source>@type forward # 启用forward输入插件,接收来自Fluent-bit或其他Fluentd节点的日志port 24224 # 转发协议监听端口bind 0.0.0.0 # 监听所有网络接口</source>################################ 处理 collectd 采集的CPU指标数据################################ 第一步:提取log字段中write_log后的JSON部分(现有配置)<filter sys.metric> # 过滤系统指标数据@type parser # 使用解析器插件key_name log # 解析log字段内容reserve_data true # 保留所有原始字段remove_key_name_field false # 不移除原始的key_name字段<parse>@type regexp # 使用正则表达式解析# 正则表达式匹配collectd的CPU数据格式,使用命名捕获组提取CPU信息expression /write_log values:(?:#012|\s)*(?<log>\[\{.*?\}\])/ # 非贪婪匹配确保只取一个数组time_key time # 指定时间字段time_type float # 时间格式为浮点数(Unix时间戳)</parse></filter># 第二步:将log字段的JSON字符串解析为JSON对象<filter sys.metric>@type parserkey_name log # 解析第一步提取的log字段(此时是JSON字符串)reserve_data true # 保留所有字段remove_key_name_field false # 保留解析后的log字段<parse>@type json # 用JSON解析器处理json_parser json # 使用默认JSON解析器array true # 强制将JSON数组字符串解析为数组对象</parse></filter># 第三步:标记异常日志(增加详细调试字段)<filter sys.metric>@type record_transformerenable_ruby true<record># 直接判断 values[0] 是否大于 80status ${(record["plugin"] == "cpu" && record["type"] == "percent" && record["values"].is_a?(Array) && !record["values"].empty? && record["values"][0].to_f > 80) ? "abnormal" : "normal"}debug_plugin ${record["plugin"].to_s}debug_type ${record["type"].to_s}debug_values_content ${record["values"].inspect}</record></filter>################################ 输出到 Elasticsearch 8、stdout 和 HTTP端点###############################<match *.**> # 匹配所有标签的日志Tag@type copy # 复制插件,将日志同时发送到多个输出目的地# 第一个输出目标:Elasticsearch<store>@id es_output@type elasticsearch # 输出到Elasticsearchhost elasticsearch # ES主机地址(可以是主机名或IP)port 9200 # ES服务端口scheme http # 使用HTTP协议logstash_format true # 使用Logstash格式索引命名logstash_prefix fluentd-${tag} # 索引前缀加上标签名logstash_dateformat %Y%m%d # 索引日期格式年月日include_tag_key true # 在输出中包含标签字段tag_key @log_name # 标签字段的键名flush_interval 1s # 刷新间隔1秒</store><store>@id output@type stdout # 输出到控制台/stdoutkey status # 字段pattern ^normal$ # 正则匹配</store><store>@type relabel # 使用 relabel 输出插件进行标签重路由@label @abnormal # 将所有匹配到的数据重新路由到 @abnormal 标签处理流程</store></match>################################ 异常日志输出到 HTTP端点###############################<label @abnormal># 这个 filter 块会对所有进入 @abnormal 标签的数据进行过滤# 只有通过这个过滤器的数据才会继续流向后面的 match 块<filter **>@type grep # 使用 grep 过滤器<regexp>key status # 检查每条记录的 status 字段pattern ^abnormal$ # 只保留 status 值为 "abnormal" 的记录</regexp></filter># 这个 match 块会接收到经过上面 filter 过滤后的数据<match **>@id http_output@type http # HTTP输出插件endpoint http://host.docker.internal:5001/analyze-fluentd-log # 日志分析API端点,host.docker.internal是Docker特殊主机名,指向宿主机http_method post # 使用POST方法发送<format>@type json # 数据格式为JSON</format><buffer># 缓冲配置区块:控制数据如何缓冲和重试发送# 用于提高网络输出的可靠性和性能,避免频繁的小数据包发送# 缓冲刷新间隔:每2秒强制刷新一次缓冲区# - 即使缓冲区未满,也会每2秒发送一次累积的数据# - 平衡实时性和网络效率:太短会增加网络请求,太长会降低实时性flush_interval 2s# 重试策略:使用指数退避算法# - 第一次重试等待:基础等待时间# - 第二次重试等待:基础时间 × 2# - 第三次重试等待:基础时间 × 4,依此类推# - 避免网络拥塞时的大量重试导致雪崩效应retry_type exponential_backoff# 基础重试等待时间:第一次重试前等待1秒# - 首次重试的初始等待间隔# - 后续重试会根据指数退避算法递增retry_wait 1s# 最大重试间隔:单次重试最多等待30秒# - 防止指数增长后的等待时间过长# - 即使使用指数退避,也不会超过30秒的间隔retry_max_interval 30s# 总重试超时时间:10分钟后放弃重试# - 从第一次失败开始计算,10分钟后停止重试# - 防止因为长期不可用的目标服务导致无限重试# - 超时后数据可能会被丢弃(取决于配置)retry_timeout 10m</buffer></match></label>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
生成智能报表
在完成配置 fluent bit 与 fluentd 的配置之后,我们来到生成智能报表的环节, 这里需要根据 fluentd 传入的告警信息(CPU 使用率>80%),进行分析并生成报表。
在/Users/cuihao/docker/EFK/目录下创建process_log.py 文件, 写入如下内容:
复制
from flask import Flask, request, jsonify, Responsefrom openai import AsyncOpenAIimport osimport jsonimport threadingimport asynciofrom datetime import datetimefrom dotenv import load_dotenv# 加载环境变量load_dotenv()# 创建Flask应用实例app = Flask(__name__)# 初始化客户端DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")if not DEEPSEEK_API_KEY:raise ValueError("未找到DEEPSEEK_API_KEY,请在.env文件中配置")client = AsyncOpenAI(api_key=DEEPSEEK_API_KEY,base_url="https://api.deepseek.com")# 路径配置current_dir = os.path.dirname(os.path.abspath(__file__))report_dir = os.path.join(current_dir, "report")OUTPUT_REPORT_PATH = os.path.join(report_dir, "incident_report.json")ERROR_INFO_PATH = os.path.join(current_dir, "api_error.log")OPERATION_LOG_PATH = os.path.join(current_dir, "api_operation.log") # 新增操作日志文件os.makedirs(report_dir, exist_ok=True)def write_operation_log(message, request_id=None):"""记录操作日志,包含时间戳和可选的请求ID"""timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3] # 精确到毫秒request_id = request_id or "N/A"log_entry = f"[{timestamp}] [REQUEST={request_id}] OPERATION: {message}\n"try:with open(OPERATION_LOG_PATH, 'a', encoding='utf-8') as f:f.write(log_entry)print(log_entry.strip()) # 同时输出到控制台except Exception as e:print(f"[日志系统错误] 写入操作日志失败: {str(e)} | 原始消息: {message}")def write_error_log(error_message, request_id=None):"""记录错误日志,包含时间戳和请求ID"""timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]request_id = request_id or "N/A"log_entry = f"[{timestamp}] [REQUEST={request_id}] ERROR: {error_message}\n"try:with open(ERROR_INFO_PATH, 'a', encoding='utf-8') as f:f.write(log_entry)print(log_entry.strip()) # 同时输出到控制台except Exception as e:print(f"[日志系统错误] 写入错误日志失败: {str(e)} | 原始错误: {error_message}")def append_to_json_file(data, timestamp, request_id):"""将数据追加到JSON文件,带日志记录"""try:write_operation_log("开始写入分析报告", request_id)data_with_timestamp = {"timestamp": timestamp,"request_id": request_id, # 新增请求ID便于追踪**data}existing_data = []if os.path.exists(OUTPUT_REPORT_PATH):try:with open(OUTPUT_REPORT_PATH, 'r', encoding='utf-8') as f:existing_data = json.load(f)write_operation_log(f"成功读取现有报告({len(existing_data)}条记录)", request_id)except (json.JSONDecodeError, FileNotFoundError):error_msg = "报告文件损坏或不存在,将重新初始化"write_error_log(error_msg, request_id)existing_data = []existing_data.append(data_with_timestamp)with open(OUTPUT_REPORT_PATH, 'w', encoding='utf-8') as f:json.dump(existing_data, f, ensure_ascii=False, indent=2)write_operation_log("分析报告写入成功", request_id)return Trueexcept Exception as e:error_msg = f"写入JSON报告文件时出错: {str(e)}"write_error_log(error_msg, request_id)return Falseasync def process_llm_background(log_content, call_timestamp, request_id):"""后台处理LLM调用,带详细日志"""try:write_operation_log("开始后台LLM处理流程", request_id)# 构造提示词write_operation_log("开始构建提示词", request_id)prompt = f"""你是一名系统运维专家。以下是异常日志,请生成根因分析报告:日志内容:{log_content}请输出格式:【标题】...【异常原因分析】...【修复建议】..."""write_operation_log("提示词构建完成,准备调用LLM", request_id)# 调用LLMwrite_operation_log("开始调用DeepSeek API", request_id)response = await client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "你是经验丰富的运维专家,负责分析日志并提供修复建议"},{"role": "user", "content": prompt}],temperature=0.7,max_tokens=800,stream=False)write_operation_log("DeepSeek API调用成功", request_id)# 处理结果report_text = response.choices[0].message.contentresult_data = {"raw_log": log_content,"root_cause_report": report_text}write_operation_log("LLM返回结果解析完成", request_id)# 保存结果if append_to_json_file(result_data, call_timestamp, request_id):write_operation_log("分析结果已成功保存到报告文件", request_id)else:write_error_log("分析结果保存失败", request_id)write_operation_log("后台LLM处理流程完成", request_id)except Exception as e:error_msg = f"LLM调用失败: {str(e)}"write_error_log(error_msg, request_id)def run_async_task(log_content, call_timestamp, request_id):"""线程包装器,带日志"""try:write_operation_log("启动异步任务处理线程", request_id)asyncio.run(process_llm_background(log_content, call_timestamp, request_id))except Exception as e:write_error_log(f"异步任务线程执行失败: {str(e)}", request_id)def build_log_content_from_records(records, request_id):"""构建日志内容,带日志记录"""write_operation_log("开始构建日志内容", request_id)lines = []for i, record in enumerate(records or []):if isinstance(record, dict) and ("log" in record):value = record.get("log")if value is not None and str(value).strip() != "":lines.append(str(value))write_operation_log(f"成功提取第{i+1}条记录的log字段", request_id)else:write_operation_log(f"第{i+1}条记录的log字段为空,已忽略", request_id)else:write_operation_log(f"第{i+1}条记录不包含log字段,已忽略", request_id)log_content = "\n".join(lines).strip()write_operation_log(f"日志内容构建完成,共包含{len(lines)}条有效记录", request_id)return log_content@app.route('/analyze-fluentd-log', methods=['POST'])def analyze_fluentd_log():"""主接口:带详细日志记录的请求处理"""# 生成唯一请求ID,便于全流程追踪request_id = datetime.now().strftime("%Y%m%d%H%M%S") + f"-{os.urandom(4).hex()}"write_operation_log("收到新的请求", request_id)try:# 1. 记录请求基本信息call_timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")write_operation_log(f"请求方法: {request.method}, 客户端IP: {request.remote_addr}, Content-Type: {request.content_type}", request_id)# 2. 验证请求类型if request.content_type != "application/x-ndjson":error_msg = f"不支持的Content-Type: {request.content_type},仅接受application/x-ndjson"write_error_log(error_msg, request_id)return jsonify({"error": error_msg,"request_id": request_id}), 415# 3. 解析NDJSON数据write_operation_log("开始解析NDJSON数据", request_id)ndjson_data = request.data.decode().splitlines()records = []for i, line in enumerate(ndjson_data):if line.strip():try:record = json.loads(line)records.append(record)write_operation_log(f"成功解析第{i+1}行NDJSON数据", request_id)except json.JSONDecodeError as e:error_msg = f"第{i+1}行NDJSON解析失败: {str(e)}"write_error_log(error_msg, request_id)records.append({"message": line, "parse_error": str(e)})else:write_operation_log(f"第{i+1}行是空白行,已忽略", request_id)write_operation_log(f"NDJSON数据解析完成,共{len(records)}条记录", request_id)# 4. 过滤有效日志记录write_operation_log("开始过滤有效日志记录", request_id)log_records = [r for r in records if isinstance(r, dict) and 'log' in r and str(r.get('log', '')).strip()]write_operation_log(f"有效日志记录过滤完成: {len(log_records)}/{len(records)}", request_id)if not log_records:error_msg = "未找到有效日志记录(缺少log字段)"write_error_log(error_msg, request_id)return Response(json.dumps({"status": "ignored","reason": error_msg,"raw_records_count": len(records),"request_id": request_id}, ensure_ascii=False, indent=2),mimetype="application/json")# 5. 构建日志内容log_content = build_log_content_from_records(log_records, request_id)if not log_content:error_msg = "日志内容为空"write_error_log(error_msg, request_id)return jsonify({"error": error_msg,"request_id": request_id}), 400# 6. 参数验证通过,准备启动后台任务write_operation_log("参数验证通过,准备启动后台处理任务", request_id)# 7. 启动后台线程处理LLM调用thread = threading.Thread(target=run_async_task,args=(log_content, call_timestamp, request_id),daemnotallow=True)thread.start()write_operation_log("后台处理线程已启动", request_id)# 8. 立即返回响应response_data = {"status": "accepted","message": "请求已接收,正在后台处理","timestamp": call_timestamp,"log_records_count": len(log_records),"request_id": request_id # 返回请求ID便于追踪}write_operation_log("请求处理完成,已返回响应", request_id)return Response(json.dumps(response_data, ensure_ascii=False, indent=2),mimetype="application/json",status=202)except Exception as e:error_msg = f"参数验证失败: {str(e)}"write_error_log(error_msg, request_id)return jsonify({"error": error_msg,"request_id": request_id}), 400@app.route('/health', methods=['GET'])def health_check():"""健康检查接口,带日志"""request_id = f"health-{datetime.now().strftime('%Y%m%d%H%M%S')}"write_operation_log("收到健康检查请求", request_id)response = jsonify({"status": "healthy","timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"request_id": request_id})write_operation_log("健康检查响应已返回", request_id)return responseif __name__ == '__main__':print("Flask API 启动中...")print("环境变量配置:")print(f" - 从 .env 文件加载 DEEPSEEK_API_KEY: {'已配置' if DEEPSEEK_API_KEY else '未配置'}")print("日志文件路径:")print(f" - 操作日志: {OPERATION_LOG_PATH}")print(f" - 错误日志: {ERROR_INFO_PATH}")print("可用的端点:")print(" - POST /analyze-fluentd-log - 接收日志并在后台处理")print(" - GET /health - 服务健康检查")app.run(host="0.0.0.0", port=5001, debug=True)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
- 175.
- 176.
- 177.
- 178.
- 179.
- 180.
- 181.
- 182.
- 183.
- 184.
- 185.
- 186.
- 187.
- 188.
- 189.
- 190.
- 191.
- 192.
- 193.
- 194.
- 195.
- 196.
- 197.
- 198.
- 199.
- 200.
- 201.
- 202.
- 203.
- 204.
- 205.
- 206.
- 207.
- 208.
- 209.
- 210.
- 211.
- 212.
- 213.
- 214.
- 215.
- 216.
- 217.
- 218.
- 219.
- 220.
- 221.
- 222.
- 223.
- 224.
- 225.
- 226.
- 227.
- 228.
- 229.
- 230.
- 231.
- 232.
- 233.
- 234.
- 235.
- 236.
- 237.
- 238.
- 239.
- 240.
- 241.
- 242.
- 243.
- 244.
- 245.
- 246.
- 247.
- 248.
- 249.
- 250.
- 251.
- 252.
- 253.
- 254.
- 255.
- 256.
- 257.
- 258.
- 259.
- 260.
- 261.
- 262.
- 263.
- 264.
- 265.
- 266.
- 267.
- 268.
- 269.
- 270.
- 271.
- 272.
- 273.
- 274.
- 275.
- 276.
- 277.
- 278.
- 279.
- 280.
- 281.
- 282.
- 283.
- 284.
- 285.
- 286.
- 287.
- 288.
- 289.
- 290.
- 291.
- 292.
- 293.
- 294.
- 295.
- 296.
- 297.
- 298.
- 299.
- 300.
- 301.
- 302.
- 303.
- 304.
- 305.
- 306.
- 307.
- 308.
- 309.
- 310.
代码是基于 Flask 框架的日志分析 API 服务,用于接收并处理 EFK 体系中 Fluentd 推送的异常日志,结合 AI 大模型实现智能运维分析。代码首先加载环境变量获取 DeepSeek API 密钥,初始化异步客户端;通过定义日志记录函数,实现操作日志、错误日志的详细追踪,以及分析报告的 JSON 持久化存储。核心接口/analyze-fluentd-log接收 NDJSON 格式的日志数据,生成唯一请求 ID 用于全流程追踪,解析日志后过滤出含有效log字段的记录,构建日志内容并启动后台线程,异步调用 DeepSeek 大模型生成根因分析报告(含标题、异常原因、修复建议),最终将结果写入 JSON 文件。
测试
接下来需要将整个案例进行测试,从日志文件生成到采集、分析、调用大模型。
日志生成与报表展示
由于需要生成测试的日志文件以及查看生成的智能日志,所以需要在 EFK 目录下创建log_generator.py 和log_ui.py 分别完成上述功能。
复制
import streamlit as stimport jsonimport reimport osfrom log_generator import LogGenerator# 初始化日志生成器log_generator = LogGenerator()# ========================# 读取 JSON 文件# ========================#file_path = r"report\incident_report.json"file_path = os.path.join("report", "incident_report.json")# 初始化reports变量reports = []# 检查文件是否存在和读取数据if os.path.exists(file_path) and os.path.getsize(file_path) > 0:try:with open(file_path, "r", encoding="utf-8") as f:reports = json.load(f)except json.JSONDecodeError as e:st.sidebar.error(f"JSON文件格式错误: {e}")except Exception as e:st.sidebar.error(f"读取文件时发生错误: {e}")else:if not os.path.exists(file_path):st.sidebar.warning(f"📁 文件 {file_path} 不存在")else:st.sidebar.warning(f"📄 文件 {file_path} 为空")# ========================# 提取标题(标题在【标题】后的下一行)# ========================def extract_title(report_text):# 去掉空行,逐行处理lines = [line.strip() for line in report_text.splitlines() if line.strip()]for i, line in enumerate(lines):if line.startswith("【标题】"):# 找到【标题】,取下一行作为真正的标题if i + 1 < len(lines):return lines[i + 1].strip()else:return "未命名报告"return "未命名报告"# ========================# 按【字段】分段解析报告# 例如:分出 "异常原因分析"、"修复建议"、"异常日志"# ========================def split_sections(report_text):sections = {}# 用正则把【xxx】作为分隔符拆开parts = re.split(r"(【.*?】)", report_text)current_key = Nonefor part in parts:if not part.strip():continueif part.startswith("【") and part.endswith("】"):# 当前是一个小节标题,例如【异常原因分析】current_key = part.strip("【】")sections[current_key] = ""else:# 当前是小节内容if current_key:sections[current_key] += part.strip() + "\n"return sections# ========================# 侧边栏:搜索功能# ========================st.sidebar.title("异常报告列表")# 如果没有报告数据,显示提示信息if not reports:st.sidebar.info("📊 暂无报告数据")# 右侧主内容区域显示友好提示st.title("📊 异常报告系统")st.info("""## 欢迎使用异常报告系统!### 📁 当前状态- 报告数据文件未找到或为空- 请确保 `report/incident_report.json` 文件存在且包含有效数据### 🔧 如何添加数据1. 在 `report` 文件夹中创建 `incident_report.json` 文件2. 按照以下格式添加报告数据:```json[{"timestamp": "2024-01-01 10:00:00","raw_log": "日志内容...","root_cause_report": "【标题】\n报告标题\n【异常原因分析】\n分析内容..."}]```### 💡 功能说明- 支持按时间倒序查看报告- 支持搜索报告内容- 自动解析报告结构并展示""")st.stop()# 倒序排序:最新的报告排在最前面reports_sorted = sorted(reports, key=lambda x: x["timestamp"], reverse=True)# 添加搜索输入框search_query = st.sidebar.text_input("🔍 搜索报告内容(标题/日志/分析/建议)").strip()# 判断一条报告是否匹配搜索条件def report_matches(report, query):if not query:return Truequery = query.lower()if query in extract_title(report["root_cause_report"]).lower():return Trueif query in report["raw_log"].lower():return Trueif query in report["root_cause_report"].lower():return Truereturn False# 根据搜索条件过滤报告filtered_reports = [r for r in reports_sorted if report_matches(r, search_query)]# 构建侧边栏显示内容(报告生成时间 | 标题)sidebar_items = [f"{r['timestamp']} | {extract_title(r['root_cause_report'])}" for r in filtered_reports]# 没有结果时提示if not sidebar_items:st.sidebar.warning("未找到匹配的报告")st.stop()# 侧边栏选择框selected_item = st.sidebar.radio("选择报告", sidebar_items)# ========================# 侧边栏:测试区域# ========================st.sidebar.markdown("---")st.sidebar.subheader("🧪 测试数据生成")# 日志类型选择log_type = st.sidebar.radio("选择日志类型",["CPU"],help="CPU: 生成CPU使用率日志",)# CPU使用率输入(仅在选择CPU类型时显示)cpu_usage = Noneif log_type == "CPU":cpu_usage = st.sidebar.number_input("CPU使用率 (%)",min_value=0.1,max_value=100.0,value=85.0,step=0.1,help="输入0.1-100之间的CPU使用率值")# 生成按钮if st.sidebar.button(f"生成{log_type}日志", type="primary"):with st.spinner("正在生成日志..."):result = log_generator.generate_and_save_log(log_type.lower(), cpu_usage)if result['status'] == 'success':st.sidebar.success(result['message'])st.sidebar.info(f"日志文件: {result['log_file']}")if 'log_content_preview' in result:st.sidebar.code(result['log_content_preview'], language="text")else:st.sidebar.error(result['message'])# 根据选择找到对应的报告selected_index = sidebar_items.index(selected_item)selected_report = filtered_reports[selected_index]# 提取报告标题report_title = extract_title(selected_report["root_cause_report"])# ========================# 右侧内容展示# ========================st.title(report_title)st.subheader(f"**报告生成时间**: {selected_report['timestamp']}")# ---- 原始日志(默认折叠) ----with st.expander("原始日志", expanded=False):st.code(selected_report["raw_log"], language="text")# ---- 根因分析报告 ----sections = split_sections(selected_report["root_cause_report"])# 去掉【标题】部分,避免重复展示sections.pop("标题", None)for key, value in sections.items():st.subheader(key) # 小节标题,例如 “异常原因分析” st.markdown(value.strip()) # 小节内容- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
- 175.
- 176.
- 177.
- 178.
- 179.
- 180.
- 181.
- 182.
- 183.
- 184.
- 185.
- 186.
- 187.
- 188.
- 189.
- 190.
- 191.
- 192.
- 193.
- 194.
- 195.
- 196.
- 197.
- 198.
- 199.
- 200.
- 201.
- 202.
- 203.
- 204.
启动 EFK 服务
按照下图所示,启动 EFK 服务,如果已经启动,建议重启一下,保证配置文件修改之后可以生效。
启动分析服务
当大模型(DeepSeek)接收到告警信息之后会生成对应的报告。
执行如下指令:
复制
python process_log.py- 1.
看到如下内容的时候, 说明该服务启动了。
复制
Flask API 启动中...环境变量配置:- 从 .env 文件加载 DEEPSEEK_API_KEY: 已配置日志文件路径:- 操作日志: /Users/cuihao/docker/EFK/api_operation.log- 错误日志: /Users/cuihao/docker/EFK/api_error.log可用的端点:- POST /analyze-fluentd-log - 接收日志并在后台处理- GET /health - 服务健康检查* Serving Flask app "process_log" (lazy loading)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
生成测试数据
通过如下命令执行启动测试和报告查看界面。
复制
streamlit run log_ui.py- 1.
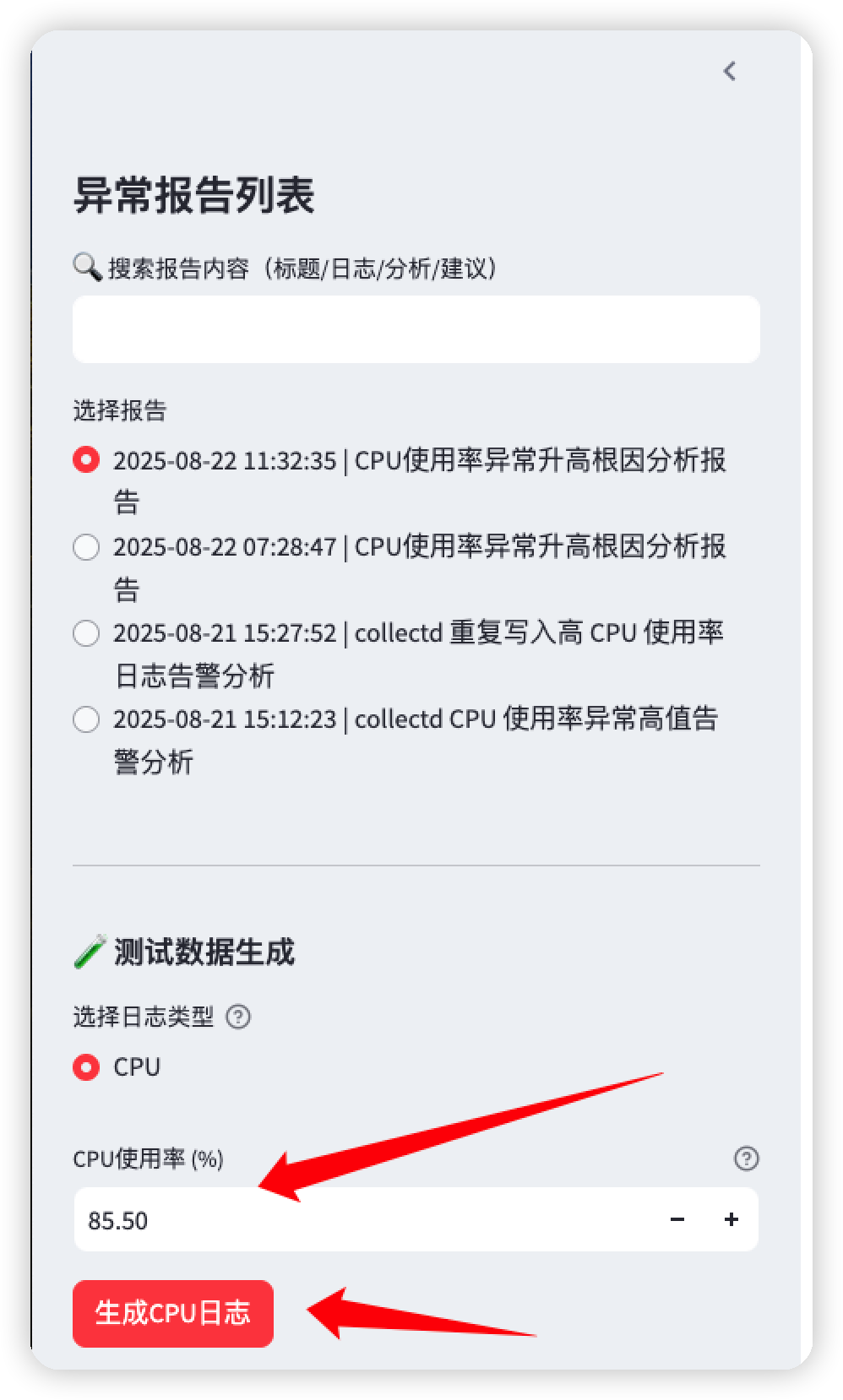
如下图所示,在打开的 Web UI 界面的左侧,输入 CPU 使用率为 85.5%,并点击“生成 CPU 日志”。
观察结果
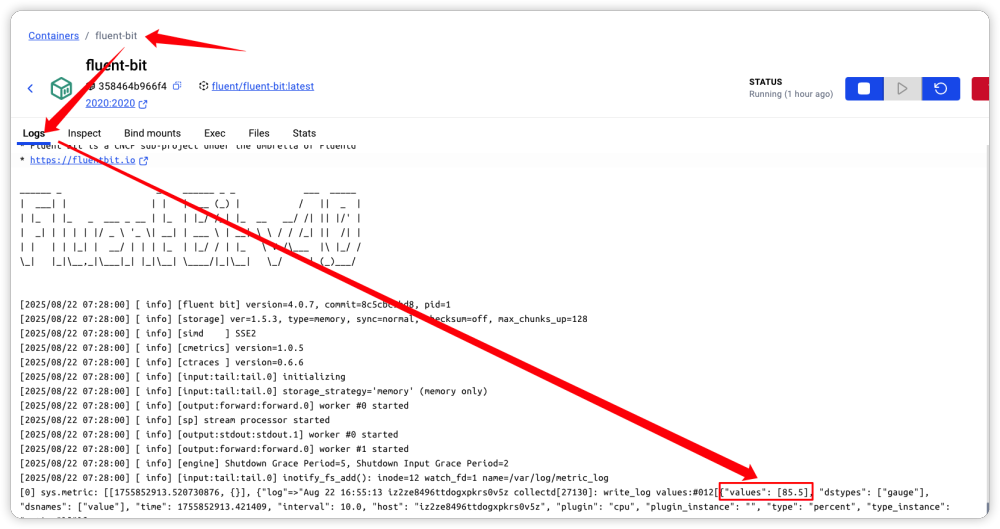
由于日志文件写入了内容, 日志采集服务、过滤服务以及处理服务都启动了,接下来就可以观察日志处理的过程了。通过在容器中执行 Fluent-bit 的日志文件可以发现,它已经采集到了对应的日志信息,如下:
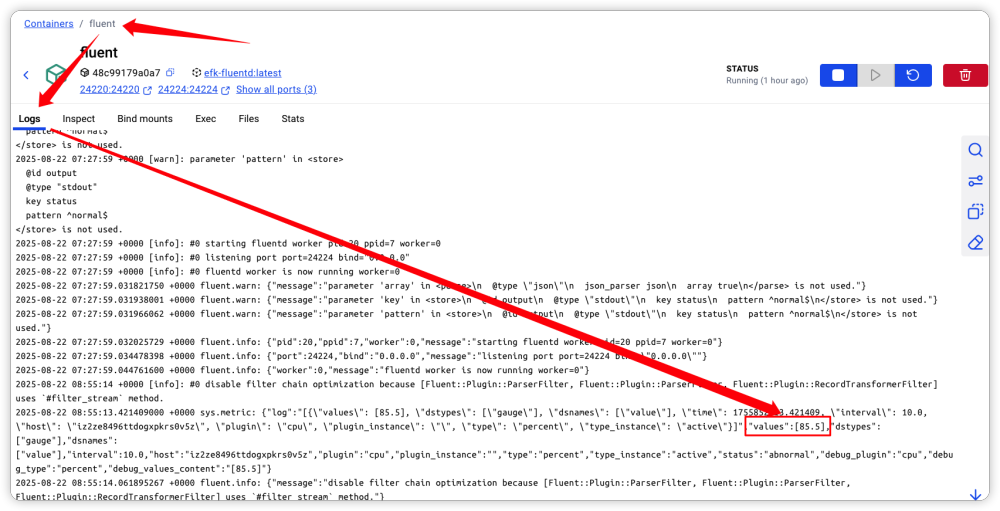
通过是在 Fluent-D 中也可以看到接收到的日志信息,如下:
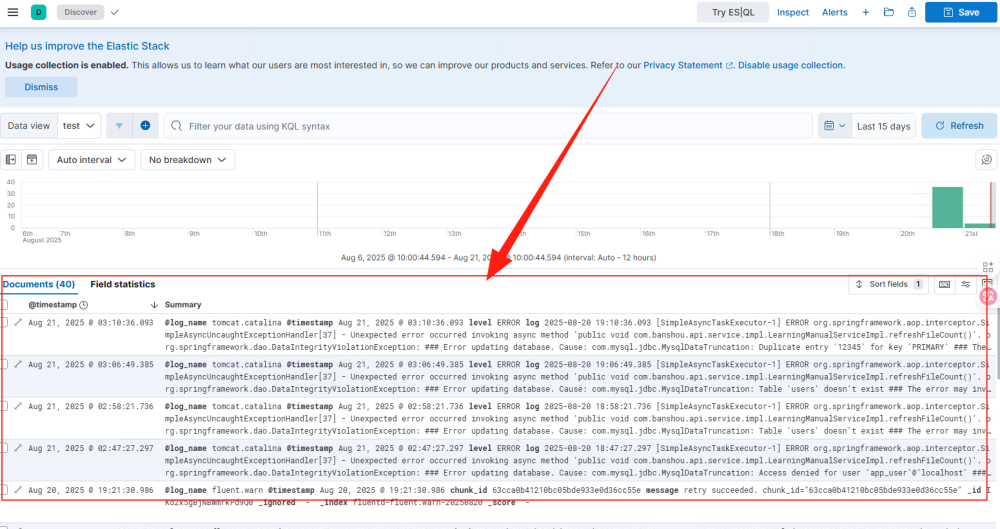
ES + Kibana 日志展示
这里只是展示日志内容,包含了正常和异常两类数据,但是没有对智能日志的显示。
配置确认
ES和Kibana的镜像版本都是使用的8.17.1,版本保持要一致,ES和Kibana服务的配置在docker-compse中。

ES的数据来自fluentd转发,由于转发功能依赖fluentd的插件fluent-plugin-elasticsearch,fluentd的dockerfile文件中配置有安装插件的命令,在通过docker compose生成容器启动时会执行dockerfile中的命令安装插件到fluentd容器中。

转发到ES需要修改配置文件fluent.conf,通过服务名进行转发到ES。

KIbana镜像中默认配置连接到ES(ES默认启动的端口是9200,如果ES的端口需要手动修改,这里也需要改成相应的端口)。
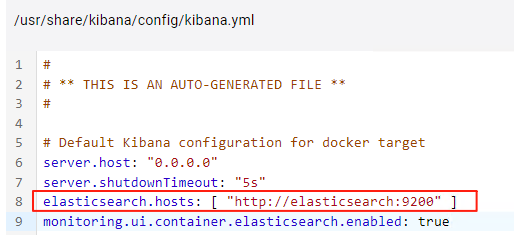
日志展示
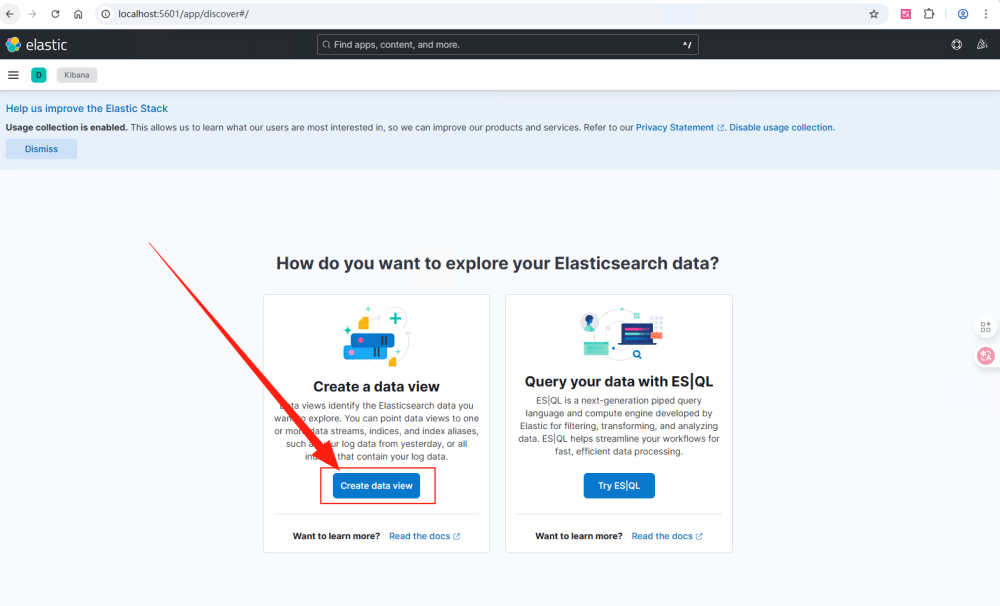
我在 fluentd 中完成了到ES的转发配置,并成功转发才会生成索引。通过配置文件可以看出,Kibana的访问端口为 5601。通过如下地址:http://localhost:5601/app/discover#/ 访问,如果首次Kibana打开会提示创建数据视图。
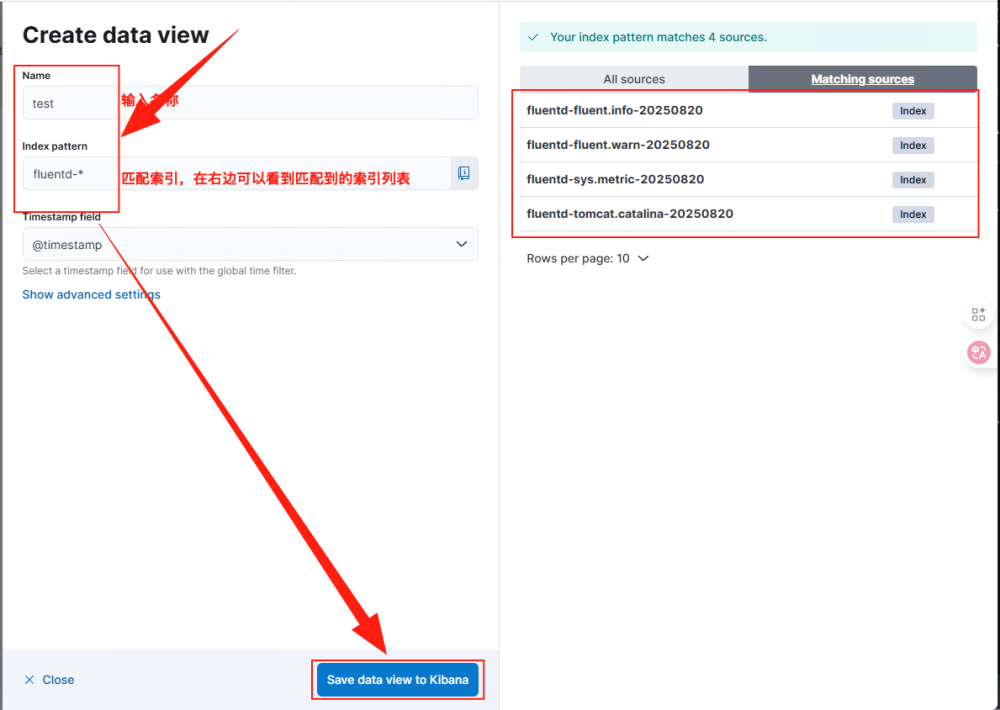
如下图所示,在弹窗中配置名称和匹配索引的规则。fluentd-*表示匹配所有fluentd-开头的索引,在右边列表会显示匹配的索引。
视图创建完成后会跳转到展示页面,默认显示最近15分钟的数据。
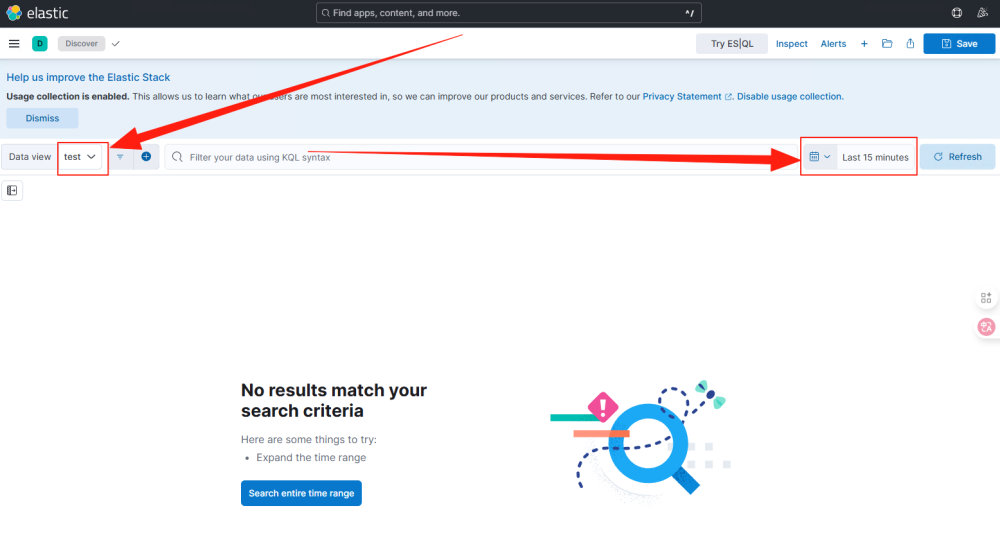
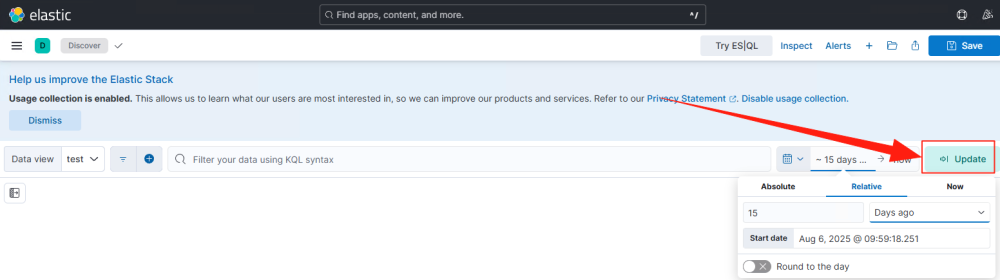
修改时间范围,这里切换到15天,右边的Refresh按钮会变成Update。
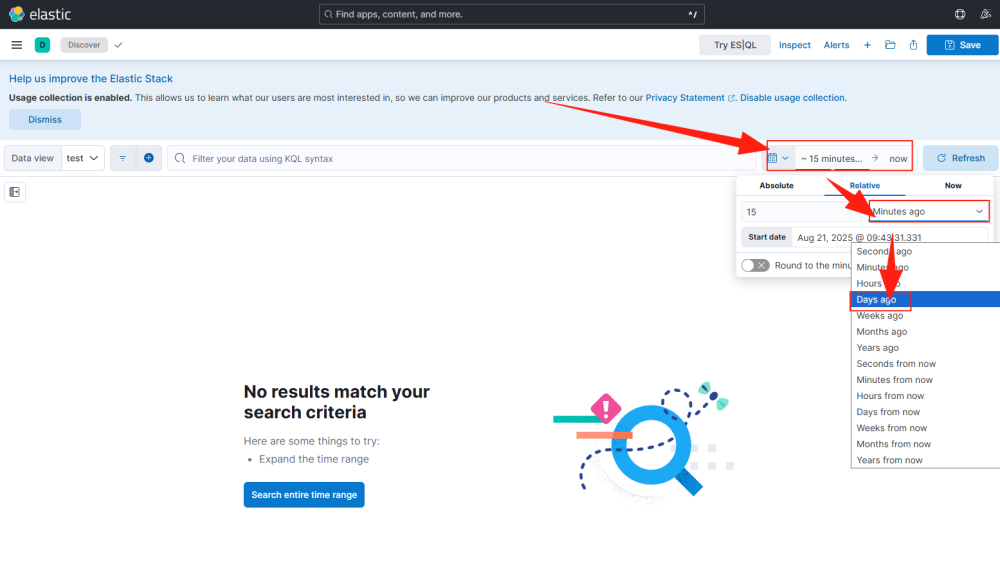
点击Update,就可以看到数据列表。