ALBEF(Align Before Fuse)
ALBEF(Align Before Fuse)是由 DAMO 学院提出的多模态预训练模型,旨在通过先对齐(align)再融合(fuse)的方式,提高视觉-语言任务的性能。该模型在多个下游任务中表现出色,包括图像-文本检索、视觉问答和跨模态分类等。
主要特点:
- 通过对比学习方法使图像和文本嵌入在同一潜在空间中对齐;
- 在对齐的基础上,进一步融合图像和文本信息,以增强模型的表现;
- 引入掩码图像建模(Masked Image Modeling, MIM)和掩码语言建模(Masked Language Modeling, MLM),提高了模型的鲁棒性和泛化能力
模型结构
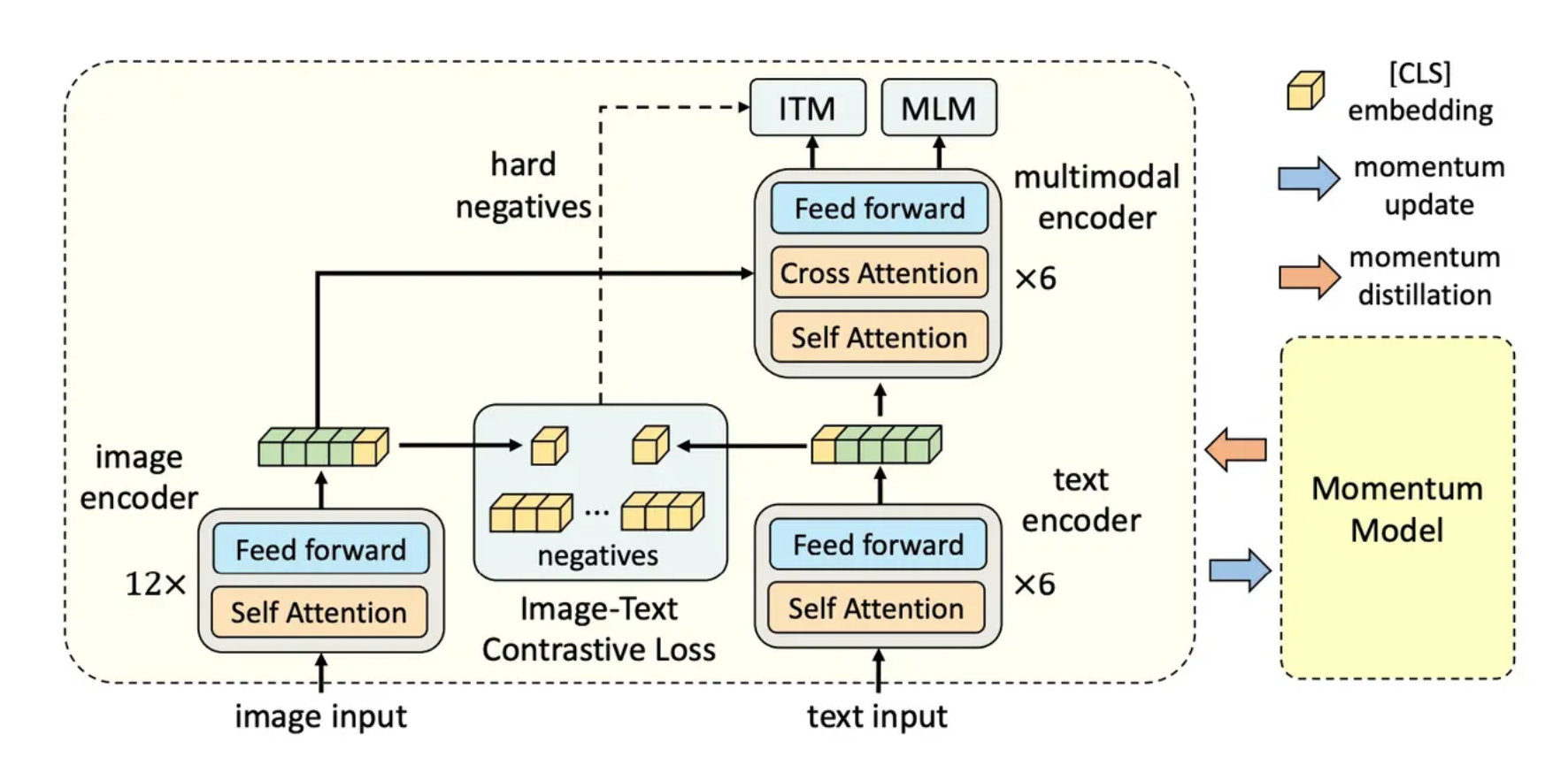
ALBEF 包含一个图像编码器、一个文本编码器和一个多模态编码器。
图像编码器:使用12层ViT-B/16(在ImageNet-1k预训练)。
文本编码器:采用6层Transformer encoder,基于BERTbase前6层权重初始化。
多模态编码器:也是 6 层的 Transformer encoder,从 BERTbase的后6层初始化。
训练目标
ALBEF预训练有三个训练目标,分别是图文对比(Image-Text Contrastive Learning)、掩码建模(Masked Language Modeling)和图文匹配(Image-Text Matching)。
Image-Text Contrastive Learning:目的是在融合前更好地学习单模态表征。它学习了一个相似函数![]() ,匹配的图像-文本对具有更高的相似性得分。gv和gw是线性变换,将[CLS]嵌入映射到标准化的低维(256-d)表示。受MoCo的启发,我们维护两个队列来存储单模态的动量编码器的最新M个图像-文本表示。动量编码器的归一化特征记为
,匹配的图像-文本对具有更高的相似性得分。gv和gw是线性变换,将[CLS]嵌入映射到标准化的低维(256-d)表示。受MoCo的启发,我们维护两个队列来存储单模态的动量编码器的最新M个图像-文本表示。动量编码器的归一化特征记为![]() 和
和![]() 。
。![]() 、
、![]() 。对于每个图像和文本,我们计算softmax标准化的 图像到文本和文本到图像的相似度:
。对于每个图像和文本,我们计算softmax标准化的 图像到文本和文本到图像的相似度:
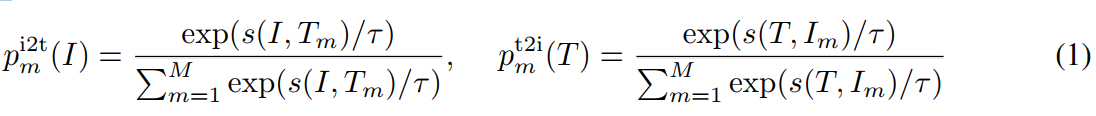
其中τ是一个可学习的温度参数,![]() 和
和![]() 代表 GT one-hot 相似性。匹配图文对的余弦相似度趋近1,不匹配对趋近0。图像-文本对比损失定义为p和y之间的交叉熵H:
代表 GT one-hot 相似性。匹配图文对的余弦相似度趋近1,不匹配对趋近0。图像-文本对比损失定义为p和y之间的交叉熵H:
![]()
Masked Language Modeling:利用图像和上下文文本来预测被屏蔽的单词。我们以15%的概率随机屏蔽掉输入的token,并用特殊的token[mask]代替它们。![]() 代表被mask的文本,
代表被mask的文本,![]() 代表模型对被mask掉的token的预测概率。MLM是最小化交叉熵loss:
代表模型对被mask掉的token的预测概率。MLM是最小化交叉熵loss:
![]()
Ymsk是一个one-hot词汇表分布,其中GT mask token的概率为1。
Image-Text Matching:预测图像文本对是否匹配。我们使用多模态编码器的的输出嵌入[CLS]标记作为图像-文本对的联合表示,并添加一个全连接(FC)层和softmax来预测两类概率pitm。ITM损失为:
![]()
yitm是一个二维的one-hot向量,代表的是GT的标签。如果图像和文本对具有相似的语义但细粒度细节不同,则称其为难负样本。我们提出了一种策略,用于为 ITM 任务采样难样本,且无需额外计算开销。我们使用公式 1 中的对比相似度在批次内找到难负样本。对于批次中的每张图像,我们根据对比相似度分布从同一批次中采样一个负文本,其中与图像更相似的文本被采样的概率更高。同样,对于每个文本,我们也采样一张难负图像。
ALBEF的完整的训练目标是:
![]()
动量蒸馏
用于预训练的图像文本对通常收集自网络,其中往往存在噪声。故而,正样本对常常是弱相关的,表现为文本中包含与图像无关的文字,或者图像中存在文本未描述的实体。在图像 - 文本对比学习(ITC)中,图像的负样本文本可能也会与图像内容相匹配。对于掩码语言建模(MLM)而言,可能存在其他与标注不同的词却能更好地描述图像。然而,ITC 和 MLM 的 one-hot 标签会惩罚所有负标签预测,而不考虑其正确性。
为解决这一问题,作者提出从动量模型生成的伪目标中学习。动量模型是一个持续发展的教师模型,它包含单模态和多模态编码器的指数移动平均版本。在训练过程中,作者训练基本模型,使其预测值与动量模型相匹配。对于 ITC,作者首先利用来自动量单模态编码器的特征计算图像文本相似度,进而计算伪目标。