InnoDB 逻辑存储结构:好似 “小区管理” 得层级结构
目录
一、核心逻辑结构:从 “小区” 到 “住户” 的 5 层架构
1. 表空间(Tablespace):小区的 “总占地”
2. 段(Segment):小区的 “楼栋”
3. 区(Extent):楼栋的 “单元”
4. 页(Page):单元的 “楼层”
(1)常见页类型
(2)数据页的结构(核心)
5. 行(Row):楼层的 “住户”
(1)隐藏列(必含,用户不可见)
(2)行记录格式(4 种,对应不同优化场景)
(3)行溢出(大字段的特殊存储)
二、基础支撑:索引组织表与主键选择
1. 主键的选择规则(优先级从高到低)
三、延伸概念:分区与视图
1. 分区(水平分区,类似 “小区分区域管理”)
常见分区类型及用途
2. 视图(虚拟表,类似 “小区住户统计表”)
四、总结:InnoDB 逻辑结构的核心特点
InnoDB 的逻辑存储结构是 “层层嵌套的层级结构”—— 从最高的 “表空间” 到最小的 “行记录”,就像一个 “小区” 的管理体系:小区(表空间)→ 楼栋(段)→ 单元(区)→ 楼层(页)→ 住户(行)。每个层级都有明确分工,确保数据存储高效、有序。
一、核心逻辑结构:从 “小区” 到 “住户” 的 5 层架构
InnoDB 的所有数据都按 “表空间→段→区→页→行” 的层级存储,每层对应小区管理的一个环节,职责清晰:
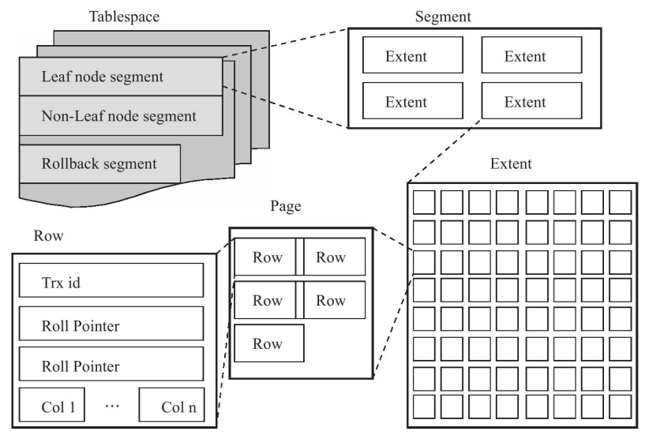
| 逻辑层级 | 小区管理类比 | 核心作用 | 关键参数 / 大小 |
|---|---|---|---|
| 表空间 | 整个小区 | 存储所有数据的 “大容器”,分共享 / 独立两种 | 共享表空间(ibdata1)、 独立表空间(.ibd) |
| 段 | 小区里的楼栋 | 按功能划分 如 :“居民楼(数据段)” “快递楼(索引段)” | 由 InnoDB 自动管理,DBA 无需干预 |
| 区 | 楼栋里的单元 | 保证数据连续性,减少磁盘寻道开销 | 固定 1MB,含 64 个 16KB 页(默认页大小) |
| 页 | 单元里的楼层 | 磁盘管理的最小单位,每层存 “住户记录” | 默认 16KB(可设 4K/8K),最多存 7992 行 |
| 行 | 楼层里的住户 | 实际存储数据的最小单位 | 含用户列 + 隐藏列(事务 ID、回滚指针等) |
1. 表空间(Tablespace):小区的 “总占地”
表空间是 InnoDB 数据存储的 “顶层容器”,对应小区的 “总占地范围”,分两种类型:
(1)共享表空间(默认)
-
类比:小区的 “公共区域 + 所有楼栋共享占地”
-
所有 InnoDB 表的 data、索引、undo 日志、Doublewrite Buffer 都存在一个(或多个)共享文件中(默认
ibdata1)。
-
-
配置:用
innodb_data_file_path指定,例:innodb_data_file_path=ibdata1:2G;ibdata2:2G:autoextend(两个共享文件,ibdata2满了自动扩容)。 -
特点:文件一旦创建,大小不能缩小(即使删数据,空间也只标记为 “可用”,不释放给操作系统)。
(2)独立表空间(推荐)
-
类比:小区里 “每栋楼有独立占地”—— 每个 InnoDB 表对应一个独立文件(
表名.ibd),仅存该表的 data、索引、插入缓冲 Bitmap。 -
配置:开启
innodb_file_per_table=ON(MySQL 5.6 + 默认开启)。 -
注意:独立表空间不存 “公共数据”——undo 日志、Doublewrite Buffer、系统事务信息仍存于共享表空间,所以共享表空间仍会随业务增长。
2. 段(Segment):小区的 “楼栋”
段是 “表空间下按功能划分的子容器”,对应小区的 “楼栋”,每种功能对应一栋楼:
-
数据段:B + 树的叶子节点(存实际数据,对应 “居民楼”);
-
索引段:B + 树的非叶子节点(存索引键,对应 “快递分拣楼”);
-
回滚段:存 undo 日志(对应 “物业档案楼”,记录住户变更历史)。
关键特点:段由 InnoDB 自动管理,DBA 无需手动创建 / 删除 —— 比如创建一个索引,InnoDB 会自动生成 “索引段 + 数据段”。
3. 区(Extent):楼栋的 “单元”
区是 “连续页的集合”,对应楼栋的 “单元”,核心作用是保证数据连续性(减少磁盘寻道时间):
-
固定大小:无论页大小是多少,区的大小永远是1MB;
-
页数量:由页大小决定 —— 默认 16KB 页→1MB/16KB=64 个页;若页大小为 4KB→256 个页;
-
碎片页优化:小表 /undo 段刚开始不占用完整区,而是先用32 个碎片页(每个页独立分配),用完后再分配完整区 —— 避免小表浪费空间(比如 100 行数据的表,不用一开始就占 1MB)。
4. 页(Page):单元的 “楼层”
页是 InnoDB磁盘管理的最小单位,对应单元的 “楼层”—— 每次读写磁盘,至少读 / 写一个完整的页(比如读 1 行数据,也要把整个 16KB 页载入内存)。
(1)常见页类型
| 页类型 | 小区类比 | 作用 |
|---|---|---|
| 数据页(B-tree Node) | 居民楼层 | 存行记录数据(住户信息) |
| undo 页(undo Log Page) | 物业档案楼层 | 存 undo 日志(住户变更历史) |
| 插入缓冲位图页 | 快递登记楼层 | 记录哪些单元的快递(插入缓冲)可合并 |
| 系统页 | 小区物业办公室楼层 | 存 InnoDB 系统信息(如表结构、参数) |
(2)数据页的结构(核心)
每个数据页就像 “楼层信息卡”,包含 7 个固定 / 动态部分,确保数据有序存储和完整性:
| 数据页部分 | 小区楼层类比 | 大小 | 核心作用 |
|---|---|---|---|
| File Header(文件头) | 楼层编号 + 建造时间 | 38 字节 | 记录页的唯一标识(如空间 ID、页号)、校验信息 |
| Page Header(页头) | 楼层住户统计 | 56 字节 | 记录页内行数、空闲空间位置、B + 树层级等 |
| Infimum/Supremum 记录 | 楼层首尾虚拟住户 | 固定 | 标记页内记录的边界(最小 / 最大主键值) |
| User Records(用户记录) | 实际住户信息 | 动态 | 存储行记录数据(用户列 + 隐藏列) |
| Free Space(空闲空间) | 楼层空闲房间 | 动态 | 未使用的空间,用链表管理(删记录后回收) |
| Page Directory(页目录) | 楼层住户索引表 | 动态 | 记录行的相对位置(类似 “住户门牌号索引”),加速查找 |
| File Trailer(文件尾) | 楼层完整性校验 | 8 字节 | 对比 File Header 的校验值,确保页未损坏 |
类比理解:比如查看 “3 单元 5 楼” 的页 ——File Header 告诉你 “这是小区 1 的 3 单元 5 楼”,Page Header 告诉你 “当前住了 20 户,还有 5 个空房间”,Page Directory 帮你快速找到 “502 住户”(行记录),File Trailer 确认 “这层楼没被损坏”。
5. 行(Row):楼层的 “住户”
行是 InnoDB实际存储数据的最小单位,对应楼层的 “住户”—— 每个行记录包含 “用户定义的列” 和 “InnoDB 自动添加的隐藏列”。
(1)隐藏列(必含,用户不可见)
| 隐藏列 | 大小 | 作用 |
|---|---|---|
| 事务 ID 列(DB_TRX_ID) | 6 字节 | 记录修改该行的事务 ID(支持 MVCC) |
| 回滚指针列(DB_ROLL_PTR) | 7 字节 | 指向该行的 undo 日志(用于回滚、MVCC 读) |
| 行 ID 列(DB_ROW_ID) | 6 字节 | 无显式主键时自动生成(唯一标识行) |
(2)行记录格式(4 种,对应不同优化场景)
InnoDB 支持 4 种行格式,分属两种 “文件格式”(Antelope/Barracuda),就像 “住户的装修风格”,各有适用场景:
| 文件格式 | 行格式 | 核心特点 | 适用场景 |
|---|---|---|---|
| Antelope | Redundant | 兼容旧版本,字段长度偏移列表占空间较多 | MySQL 5.0 前的旧表,需兼容时使用 |
| Antelope | Compact | 紧凑存储(NULL 不占空间,变长字段长度逆序存) | 大多数场景(MySQL 5.1 + 默认) |
| Barracuda | Dynamic | 大字段(VARCHAR/BLOB)优先存溢出页 | 表含大字段,需节省数据页空间时 |
| Barracuda | Compressed | 对行数据用 zlib 压缩,支持页压缩 | 大字段多、磁盘空间紧张的场景 |
关键区别举例:
- Compact 格式:存 “住户姓名(VARCHAR (10))” 时,只记录 “姓名长度 + 实际字符”,NULL 值只在 “NULL 标志位” 打勾,不占实际空间;
- Compressed 格式:会把 “住户的长备注(TEXT)” 压缩后存储,原本 1KB 的备注可能压到 200 字节,节省空间。
(3)行溢出(大字段的特殊存储)
如果行记录太大(比如含 10KB 的 TEXT 字段),InnoDB 会把 “超出部分” 存到 “溢出页”(类似 “住户的大件行李存到小区仓库”),数据页只存 “溢出页的指针”。
溢出条件:数据页至少要存 2 条行记录 —— 若 1 条记录占满 16KB(默认页大小),则超出部分存溢出页(确保页内至少有 2 条记录,维持 B + 树结构)。
二、基础支撑:索引组织表与主键选择
InnoDB 是 **“索引组织表(IOT)”**—— 数据按主键顺序存储(类似小区住户按门牌号排序),主键是数据的 “核心索引”,决定行记录在 B + 树中的位置。
1. 主键的选择规则(优先级从高到低)
如果创建表时未显式定义主键,InnoDB 会按以下规则自动选择 / 创建:
- 优先选 “非空唯一索引(UNIQUE NOT NULL)”—— 若表中有多个,选建表时第一个定义的(不是列的顺序);
- 若无上述索引,自动创建 6 字节的
DB_ROW_ID作为主键(自增,唯一标识行)。
举例:
CREATE TABLE user (id INT UNIQUE NOT NULL, -- 第1个非空唯一索引,被选为主键name VARCHAR(10) NOT NULL,phone VARCHAR(20) UNIQUE NOT NULL -- 虽非空唯一,但定义在后面,不做主键
) ENGINE=InnoDB;
三、延伸概念:分区与视图
1. 分区(水平分区,类似 “小区分区域管理”)
MySQL 支持水平分区(按行拆分,比如 “1-10 栋住老业主,11-20 栋住新业主”),不支持垂直分区(按列拆分),且仅支持 “局部分区索引”(每个分区的索引和数据存在一起)。
常见分区类型及用途
| 分区类型 | 核心逻辑 | 适用场景 |
|---|---|---|
| RANGE | 按连续范围拆分(如时间) | 按日期分区日志表(2024 年 1 月→分区 1,2 月→分区 2) |
| LIST | 按离散值拆分(如地区) | 按省份分区用户表(北京 / 上海→分区 1,广州 / 深圳→分区 2) |
| COLUMNS | 支持非整型分区(直接比较) | 按字符串分区(如按用户名首字母 A-F→分区 1) |
| HASH | 按哈希值均分 | 需均匀拆分数据,无明确范围时(如按用户 ID 哈希分 8 个区) |
注意:NULL 值在分区中的处理 ——RANGE 分区将 NULL 归为 “最小范围”,LIST 分区需显式指定 NULL 所属分区,HASH/KEY 分区将 NULL 视为 0。
2. 视图(虚拟表,类似 “小区住户统计表”)
视图是 “基于 SQL 查询的虚拟表”(无实际数据存储),就像 “小区的住户统计表”—— 只展示需要的信息,不存储原始数据。
- 作用:简化查询(隐藏复杂 JOIN)、权限控制(只给部分用户看部分列);
- MySQL 的限制:不支持 “物化视图”(无法预存查询结果),若需类似功能,需手动创建 “聚合表”(定时执行查询并插入数据)。
四、总结:InnoDB 逻辑结构的核心特点
- 层级存储:从表空间到行,层层嵌套,确保数据有序且高效读写(类似小区管理的 “分级负责”);
- 索引组织:数据按主键顺序存储,主键是核心索引(数据即索引,索引即数据);
- 灵活适配:支持独立表空间(小表省空间)、多种行格式(适配大字段 / 压缩需求)、水平分区(大表易管理);
- 安全可靠:数据页的完整性校验(File Header/Trailer)、隐藏列支持 MVCC 和事务回滚,保证数据一致性。
理解这套 “小区管理” 类比,就能快速掌握 InnoDB 逻辑存储的核心 —— 每个层级都是为了 “更高效地存储、管理、查找数据”,就像小区的每个环节都是为了 “更有序地服务住户”。