【高级】系统架构师 | 2025年上半年综合真题DAY3
A. 1B. 2
C. 3
D. 4
解析:
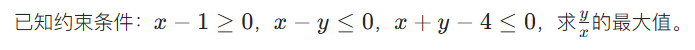

著作人的()表示作品可以公布与众。
A. 著作权
B. 发表权
C. 网络传播权
D. 发行权解析:
根据著作权法相关规定:
- 发表权:是指著作权人决定作品是否公之于众的权利,直接对应 “作品可以公布与众” 的表述。
- 著作权:是著作权人对作品享有的一系列权利(如发表权、署名权、复制权等)的统称,并非专门指向 “公布作品” 的单一权利。
- 网络传播权:侧重于以有线或无线方式向公众提供作品,使公众能在个人选定的时间和地点获取作品,强调 “网络传播” 的特定途径,而非 “公布作品” 的概括性权利。
- 发行权:是指以出售或赠与方式向公众提供作品原件或复制件的权利,核心是 “提供作品载体”,而非 “公布作品内容” 的行为。
关系模式中存在函数依赖 a -> cd、c -> b,问候选码是()。
A. a
B. b
C. b
D. d解析:
候选码的定义是:能唯一标识关系中元组,且不含多余属性的属性(或属性组),需满足 “能推出关系的所有属性”。
对各选项分析如下:
- 选项 A(a):由 a -> cd,a 可推出 c 和 d;再由 c -> b,c 可推出 b。因此 a 能推出关系的所有属性(a、b、c、d),符合候选码要求。
- 选项 B(b):没有函数依赖能从 b 推出 (a、c、d),无法唯一标识元组,不是候选码。
- 选项 C(b):同选项 B,理由一致,不是候选码。
- 选项 D(d):没有函数依赖能从 d 推出 (a、b、c),无法唯一标识元组,不是候选码。
不属于非实时操作系统的是()。
A. iOS
B. Android
C. VxWorks
D. WinCE解析:
操作系统分为实时操作系统(对响应时间有严格要求,能在规定时间内完成事件处理并响应,多用于工业控制、航空航天等对时间敏感的场景)和非实时操作系统(对响应时间无严格实时限制,更侧重通用交互、多任务等,如消费级移动 / 桌面系统)。
对选项逐一分析:
- iOS:苹果移动设备的操作系统,属于非实时操作系统,注重用户交互与通用应用支持,无严格实时响应要求。
- Android:安卓移动设备的操作系统,属于非实时操作系统,面向通用移动应用场景。
- VxWorks:是实时操作系统(RTOS),广泛应用于航空航天、工业控制等对时间敏感性极高的领域,因此不属于非实时操作系统。
- WinCE(Windows Embedded Compact):属于嵌入式操作系统,更偏向通用嵌入式场景,属于非实时操作系统(相对强实时系统而言)。
一个对象继承了另一个对象的所有功能,并实现了另一个接口的功能,子类比父类强大,这是什么类型的继承?()
A. 取代
B. 包含
C. 特化
D. 受限解析:
在面向对象的继承关系中:
- 特化(Specialization):是泛化的逆过程,意味着子类是父类的 “特殊形式”。子类会继承父类的所有属性与方法,还能进一步扩展(如实现新接口、添加新功能等),从而让子类比父类更 “强大” 或更具针对性,与题目中 “继承所有功能且实现另一个接口,子类比父类强大” 的描述完全匹配。
- 取代继承:核心是子类 “替代” 父类功能,不突出子类对父类的扩展与增强。
- 包含继承:通常涉及 “包含” 的结构关系(如组合、聚合),并非用于描述子类对父类的 “扩展式继承” 逻辑。
- 受限继承:强调继承存在访问权限等限制,和 “子类比父类强大” 的扩展逻辑无关。
哪一层表达业务概念、业务状态信息和业务规则采用的技术?
A. 基础设施层
B. 用户接口层
C. 领域层
D. 应用层解析:
在 领域驱动设计(DDD) 的分层架构中:
- 领域层是核心层,负责封装业务概念、业务状态信息和业务规则,是业务逻辑的核心载体,直接对应题目中 “表达业务概念、业务状态信息和业务规则” 的描述。
- 基础设施层:聚焦底层技术实现(如数据库、文件系统、第三方服务对接等),不直接表达业务逻辑。
- 用户接口层:负责与用户交互(如页面展示、输入收集),核心是 “界面交互”,而非业务逻辑表达。
- 应用层:主要协调领域对象完成业务流程,自身不直接封装业务概念和规则,是 “业务流程的编排者” 而非 “业务逻辑的持有者”。
RUP(统一软件开发过程)设计确定系统体系结构,每个循环生成一个新的版本,每个循环依次由多个阶段组成,其中设计及确定系统的体系结构,制定计划和资源要求的阶段是()。
A. 初始
B. 构造
C. 细化
D. 移交解析:
RUP(Rational Unified Process)将软件开发过程分为初始、细化、构造、移交四个主要阶段,各阶段核心任务如下:
- 初始阶段:聚焦项目范围定义、业务可行性分析,不涉及系统体系结构的详细设计与资源计划制定。
- 细化阶段:核心任务是设计并确定系统的体系结构,同时制定项目计划、明确资源需求,并解决关键技术风险,与题目中 “设计及确定系统的体系结构,制定计划和资源要求” 的描述完全匹配。
- 构造阶段:基于细化阶段的设计,开展系统的构建与开发,生成可运行的版本,并非体系结构设计与资源计划的阶段。
- 移交阶段:主要完成产品交付、用户培训、部署等工作,不涉及体系结构设计。
黑盒测试不包括()。
A. 等价类
B. 边界值
C. 因果图
D. 路径覆盖解析:
黑盒测试的核心是不考虑程序内部逻辑结构,仅通过输入输出的外部行为设计测试用例;白盒测试则需基于程序内部的代码逻辑、控制流等开展测试。
对各选项分析:
- 等价类划分:黑盒测试方法,将输入数据划分为 “等价类”(输入效果等价的集合),从每类选代表用例,减少测试量。
- 边界值分析:黑盒测试方法,聚焦输入 / 输出的 “边界值”(如范围的最小 / 最大值、临界值),因边界是错误高频出现区域。
- 因果图:黑盒测试方法,通过分析输入条件组合(因)与输出结果(果)的逻辑关系,设计覆盖因果逻辑的用例。
- 路径覆盖:白盒测试方法,目标是覆盖程序内部所有可能的执行路径,需深入了解代码逻辑结构(如分支、循环),因此不属于黑盒测试。
一次可编程只读存储器是()。
A. ROM
B. EEPROM
C. EPROM
D. PROM解析:
要解决此题,需明确各类只读存储器(ROM)的可编程特性:
- 选项 A(ROM):普通只读存储器,通常由厂家在生产时预先写入数据,用户无法自行编程修改。
- 选项 B(EEPROM):电可擦除可编程只读存储器,可通过电信号多次擦除、重新编程,并非 “一次可编程”。
- 选项 C(EPROM):可擦除可编程只读存储器,需用紫外线擦除数据,能多次编程,也不符合 “一次可编程”。
- 选项 D(PROM):可编程只读存储器(Programmable ROM),仅能进行一次编程,编程后内容永久固定、无法再修改,完全符合 “一次可编程只读存储器” 的定义。
在逆向工程中,在用户的指导下通过搜索和变换方法导出的数据属于哪个级别?
A. 实现级和结构级
B. 实现级和领域级
C. 结构级和领域级
D. 结构级、实现级和领域级解析:
逆向工程的抽象级别分为实现级、结构级、领域级,各层级特点及题干匹配性分析如下:
- 实现级:聚焦系统的代码实现细节(如恢复程序结构、算法逻辑等),“搜索和变换方法” 可对代码层面进行逆向分析,能覆盖此级别。
- 结构级:关注系统的整体结构(如模块划分、组件依赖关系等),通过 “搜索和变换” 可分析系统结构,能覆盖此级别。
- 领域级:聚焦业务领域层面(提取业务概念、规则等),需深度结合业务知识,仅通过 “用户指导下的搜索和变换(偏技术手段)” 难以直接导出领域级信息。
题干中 “在用户指导下通过搜索和变换方法导出数据”,更适合覆盖实现级(代码 / 实现层面)和结构级(系统结构层面),无法直接达到领域级。因此答案选 A。
UML 中,()是原子的,不能被分解的。
A. 原子状态
B. 活动状态
C. 初始状态
D. 动作状态解析:
在 UML 的状态机模型中:
- 动作状态(Action State):表示一个不可分割的原子动作,执行时无法被中断,也不能进一步分解为更细的子状态或动作,符合 “原子的、不能被分解” 的描述。
- 原子状态:并非 UML 中定义的特定、精准的状态类型(是对 “不可再分” 状态的泛称,而非具体状态类别)。
- 活动状态(Activity State):可以分解为多个子活动或动作,不具备 “原子性、不可分解” 的特点。
- 初始状态(Initial State):属于 “伪状态”,仅用于标识状态机的起始点,并非用于表示 “原子性动作执行” 的状态,也不涉及 “可分解 / 不可分解” 的动作特性。
REST API 中,()用于对一个资源进行部分修改,不需要发送整个资源。
A. PUT
B. PATCH
C. PART
D. POST解析:
在 RESTful API 的 HTTP 方法中:
- PUT:用于替换或创建整个资源,需要发送资源的完整表示,不支持 “部分修改”。
- PATCH:专门用于对资源进行部分更新,只需提交需要修改的部分数据,无需发送整个资源,符合题意。
- PART:并非标准 REST API 中的 HTTP 方法,属于干扰项。
- POST:主要用于创建新资源或执行非幂等的操作(如提交复杂表单、触发特定动作),不针对 “资源的部分修改” 场景。
不属于数据中台的应用场景的是()。
A. 数据库扩容
B. 风险控制
C. 数据治理
D. 用户画像解析:
数据中台的核心价值是整合企业数据、提供数据服务,支撑各类业务场景(如通过数据治理统一数据标准、通过用户画像支撑精准运营、通过风险控制数据模型辅助决策等)。
对各选项分析:
- 选项 A(数据库扩容):属于数据库自身的运维操作,目的是扩展数据库的存储或性能容量,与数据中台 “整合数据、服务化支撑业务” 的核心场景无关。
- 选项 B(风险控制):可通过数据中台整合多源数据,构建风险模型,属于数据中台的应用场景。
- 选项 C(数据治理):数据中台的重要基础工作(如统一数据标准、清理数据质量等),属于数据中台的应用场景。
- 选项 D(用户画像):依赖数据中台整合的用户全维度数据来构建,属于数据中台的应用场景。
从管理角度出发,可将影响软件质量的因素分为三组,分别反映用户在使用软件产品时的三种不同倾向和观点,这三组分别是()。
A. 产品运行、产品修改和产品健壮
B. 产品重用、产品修改和产品可用
C. 产品运行、产品修改和产品重构
D. 产品运行、产品修改和产品转移解析:
从管理角度对影响软件质量的因素进行分类时,通常分为以下三组,分别对应用户使用软件的不同视角:
- 产品运行:关注软件在运行过程中的质量属性,如正确性、可靠性、效率、可用性等(即软件 “好不好用、稳不稳定”)。
- 产品修改:关注软件的可维护性、可扩展性、可测试性等(即软件 “容不容易修改、迭代”)。
- 产品转移:关注软件的可移植性、可重用性、互操作性等(即软件 “能不能在不同环境迁移、能不能被复用”)。
对选项逐一分析:
- 选项 A:“产品健壮” 并非管理角度的标准分组维度,排除。
- 选项 B:“产品重用” 属于 “产品转移” 的子范畴,“产品可用” 属于 “产品运行” 的子范畴,并非独立分组,排除。
- 选项 C:“产品重构” 是开发过程的技术行为,不是管理角度的质量因素分组,排除。
- 选项 D:“产品运行、产品修改、产品转移” 完全匹配管理角度的三组分类。
ERP 中的企业资源包括企业的 “三流” 资源,即()。
A. 物流资源、税务流资源和信息流资源
B. 物流资源、资金流资源和税务流资源
C. 物流资源、资金流资源和信息流资源
D. 税务流资源、资金流资源和信息流资源解析:
ERP(企业资源计划)的核心逻辑围绕企业的物流(物资的采购、生产、销售等流动过程)、资金流(资金的收支、流转等财务过程)、信息流(数据、信息的传递与整合,支撑物流和资金流的协同)这 “三流” 展开,三者相互关联、同步运转,实现企业资源的高效管理。
选项中,“税务流” 并非 ERP 定义里核心的 “三流” 范畴,因此只有选项 C(物流资源、资金流资源和信息流资源)符合 ERP 对企业核心资源 “三流” 的界定。
()使软件系统适用于多种软硬件平台。
A. 可移植性
B. 可变性
C. 互操作性
D. 可扩展性解析:
软件的可移植性是指软件从一个运行环境(如不同的硬件平台、操作系统、编译器等)转移到另一个运行环境时的难易程度。具备可移植性的软件,能够适应多种软硬件平台,符合题目中 “适用于多种软硬件平台” 的描述。
- 可变性:侧重于软件自身易于修改的特性,与 “适应多平台” 无关。
- 互操作性:强调不同系统之间交互、交换信息的能力,并非单一软件适应多平台的能力。
- 可扩展性:关注软件新增功能的便捷性,和跨平台无直接关联。
综上,答案选 A。
某工程项目包含 10 个作业 A~J,各作业所需时间及其衔接关系如下表。如果作业 D 推迟 3 天开始,其他因素不变,整个工程工期将推迟()天。
作业 A B C D E F G H I J 紧前作业 - - A,B B A C E,F D,F G,H I 所需时间(天) 2 3 4 5 6 3 2 3 6 5 A. 3
B. 2
C. 1
D. 5
解析:
步骤 1:确定正常情况下的关键路径
关键路径是总持续时间最长的作业路径,决定工程总工期。通过梳理各作业的紧前关系和时间,计算各可能路径的总时长:
- 路径 1(A→E→G→I→J):(2 + 6 + 2 + 6 + 5 = 21)天
- 路径 2(A→C→F→G→I→J):(2 + 4 + 3 + 2 + 6 + 5 = 22)天
- 路径 3(A→C→F→H→I→J):(2 + 4 + 3 + 3 + 6 + 5 = 23)天
- 路径 4(B→C→F→G→I→J):(3 + 4 + 3 + 2 + 6 + 5 = 23)天
- 路径 5(B→C→F→H→I→J):(3 + 4 + 3 + 3 + 6 + 5 = 24)天
- 路径 6(B→D→H→I→J):(3 + 5 + 3 + 6 + 5 = 22)天
因此,正常关键路径为 B→C→F→H→I→J,总工期为 24 天。
步骤 2:分析作业 D 推迟 3 天的影响
作业 D 的紧前是 B(B 工期 3 天,正常完成时间为第 3 天),因此:
- 正常情况下,D 的最早开始时间为第 3 天,最早完成时间为 (3 + 5 = 8) 天。
- 推迟 3 天后,D 的最早开始时间变为 (3 + 3 = 6) 天,最早完成时间变为 (6 + 5 = 11) 天。
步骤 3:评估对后续作业及总工期的影响
作业 H 的紧前是D 和 F:
- F 的紧前是 C(C 工期 4 天,最早完成时间为 (max(2,3) + 4 = 7) 天),因此 F 的最早完成时间为 (7 + 3 = 10) 天。
- D 推迟后最早完成时间为 11 天,因此 H 的最早开始时间变为 (max(10, 11) = 11) 天,最早完成时间为 (11 + 3 = 14) 天(正常情况下 H 最早完成时间为 13 天,推迟了 1 天)。
作业 I 的紧前是G 和 H:
- G 的紧前是 E 和 F(E 最早完成时间为 (2 + 6 = 8) 天,F 最早完成时间为 10 天),因此 G 最早完成时间为 (10 + 2 = 12) 天。
- H 最早完成时间为 14 天,因此 I 的最早开始时间变为 (max(12, 14) = 14) 天,最早完成时间为 (14 + 6 = 20) 天。
作业 J 的最早开始时间为 20 天,最早完成时间为 (20 + 5 = 25) 天(正常总工期为 24 天)。
步骤 4:计算工期推迟天数
总工期从 24 天变为 25 天,因此推迟了 1 天。
综上,答案选 C。
在数据流图的四种基本元素中,()表示对数据进行的加工和转换。
A. 外部项
B. 数据流
C. 处理
D. 业务单元解析:
数据流图(DFD)的四种基本元素为外部项(外部实体)、数据流、处理(加工)、数据存储,各元素作用如下:
- 外部项:表示系统之外的实体(如用户、其他系统等),用于提供或接收系统的数据,不负责数据的加工转换。
- 数据流:表示数据的流动方向与路径,是数据的载体,并非对数据进行加工的操作。
- 处理(加工):是数据流图的核心元素之一,用图形(如圆形、矩形)表示,作用是对输入的数据流进行加工、转换,生成输出数据流,符合 “对数据进行加工和转换” 的描述。
- 业务单元:并非数据流图的基本元素。
下列选项中会导致线程从执行态变为就绪态的是()。
A. 执行信号量的wait()操作
B. 缺页异常
C. 键盘输入
D. 主动让出 CPU解析:
线程的状态主要包括执行态(占用 CPU 运行)、就绪态(具备运行条件,等待 CPU 调度)、阻塞态(因等待资源 / 事件,无法立即运行)。分析各选项对线程状态的影响:
- 选项 A:执行信号量的
wait()操作时,若信号量计数为 0,线程会因等待信号量而进入阻塞态(等待其他线程释放信号量),而非就绪态。- 选项 B:缺页异常发生时,线程需等待操作系统从外存加载页面到内存,此过程会进入阻塞态(等待 I/O 完成),而非就绪态。
- 选项 C:线程等待键盘输入时,会因等待外部设备的 I/O 事件而进入阻塞态,而非就绪态。
- 选项 D:线程主动让出 CPU(如调用
yield()方法)时,会从 “执行态” 释放 CPU,回到 “就绪态”(仍具备运行条件,只需等待下一次 CPU 调度)