【VLMs篇】06:Cosmos-Reason1:从物理常识到具身推理
1. 摘要介绍表
| 项目 | 描述 |
|---|---|
| 论文标题 | Cosmos-Reason1: 从物理常识到具身推理 (From Physical Common Sense To Embodied Reasoning) |
| 作者/机构 | NVIDIA |
| 问题 | 当前的AI模型(尤其是LLM)虽然在文本和编码任务上表现出色,但缺乏对物理世界的深入理解和推理能力,即所谓的“物理常识”,这限制了它们在机器人、自动驾驶等具身AI领域的应用。 |
| 核心创新点 | 1. 系统的知识框架: 首次为物理AI定义了两个核心本体——“物理常识本体”(空间、时间、物理)和“具身推理本体”(涵盖多种智能体和能力),为模型训练和评估提供了理论基础。 2. 两阶段训练范式: 结合了大规模监督微调(SFT)和创新的强化学习(RL),利用基于规则、可验证的奖励机制,有效提升了模型在物理任务上的推理能力。 3. 高质量的专用数据集: 构建了一个包含约400万个视频-文本对的大规模、高质量数据集,专门用于训练和评估模型的物理常识和具身推理能力。 4. 强大的模型性能: 推出的Cosmos-Reason1模型(7B和56B)在专门构建的物理和具身推理基准测试中,性能显著超过了现有的顶尖多模态模型,尤其在直觉物理(如时间箭头、物体恒存性)等任务上实现了巨大飞跃。 |
| 方法论 | 1. 模型架构: 采用仅解码器(Decoder-only)的多模态LLM架构,并试验了Transformer和混合Mamba-MLP-Transformer作为骨干。 2. 数据策划: 结合人类标注和模型蒸馏(使用DeepSeek-R1)来创建包含问答、描述和思维链(CoT)的SFT数据集;为RL阶段创建了大量的多项选择题(MCQ)数据集。 3. 训练流程: 第一阶段 (SFT) - 在策划的数据集上对预训练的视觉语言模型进行微调,注入物理知识。第二阶段 (RL) - 使用一种名为GRPO的RL算法,通过MCQ的正确答案作为奖励信号,进一步优化模型的推理能力和决策准确性。 |
| 主要成果 | 1. SFT训练使模型在物理常识和具身推理基准上的性能比其基础模型提升了超过10%。 2. RL训练在此基础上进一步将准确率提升了超过5%。 3. Cosmos-Reason1能够学习现有模型难以掌握的直觉物理概念,如判断视频是正放还是倒放,以及理解物体即使被遮挡也依然存在。 |
2. 论文实现流程
该论文的实现流程可以概括为一个从理论构建到数据准备,再到模型训练和评估的完整闭环。
输入 (Input):
- 原始数据: 大量来自互联网和特定领域(如机器人操作、自动驾驶)的视频。
- 模型训练输入: 视频片段 (video clips) + 文本提示 (text prompts)。文本提示可以是问题、指令或任务描述。
核心处理流程 (Processing Flow):
-
第一步: 理论框架定义 (Ontology Definition)
- 目标: 为“物理AI”建立一个可以衡量和指导模型学习的知识体系。
- 产出:
- 物理常识本体: 将知识分为空间、时间、基础物理三大类,并细分为16个子类。
- 具身推理本体: 一个二维矩阵,定义了5种智能体(如人类、机器人)在4种核心能力(如处理感官输入、预测行动效果)上的表现。
-
第二步: 数据策划与准备 (Data Curation)
- 目标: 基于上述本体,创建高质量的训练和评估数据集。这是一个复杂的数据工程。
- 数据流:
- 视频采集与剪辑: 从原始视频源中筛选和剪辑出与物理场景相关的短视频。
- 视频内容理解 (Captioning): 使用强大的视觉语言模型(VLM)或人工对视频进行详细的文本描述,形成“状态-动作”上下文。
- 问答对生成 (QA Curation):
- 理解性问题: 根据视频描述生成可以直接回答的问题。
- 推理行问题: 使用大型语言模型(LLM, 如DeepSeek-R1)基于视频描述生成需要深层推理才能回答的问题(例如,假设性问题、规划问题)。
- 思维链提取 (Reasoning Trace Extraction): 再次利用LLM,让它在回答推理问题时生成详细的“思考过程”(Chain-of-Thought),并将其作为训练数据的一部分。
- 数据清洗与重写: 自动化脚本清理生成的文本,去除无关引用,确保数据质量。
- 产出:
- SFT数据集: 约400万个(视频,问题,答案,思维链)样本。
- RL数据集: 将SFT数据中的推理问题转换为带有唯一正确答案的多项选择题(MCQ),用于奖励模型的生成。
- 基准测试集 (Benchmark): 单独创建的一组高质量、经过人工筛选的问答对,用于最终评估。
-
第三步: 模型训练 (Model Training)
- 阶段一: 物理AI监督微调 (Physical AI SFT)
- 逻辑: 将预训练好的多模态大模型(如Qwen2.5-VL)在SFT数据集上进行微调。
- 目的: 让模型学习物理世界的特定知识和推理模式。
- 阶段二: 物理AI强化学习 (Physical AI RL)
- 逻辑: 在SFT模型的基础上,使用RL数据集进行后训练。模型为每个MCQ生成答案,如果答案正确,则获得奖励。通过GRPO算法优化模型,使其更倾向于生成正确且推理可靠的答案。
- 目的: 进一步提高模型的准确性和决策能力,减少幻觉。
- 阶段一: 物理AI监督微调 (Physical AI SFT)
输出 (Output):
- 模型: 经过两阶段训练的Cosmos-Reason1模型(7B和56B版本)。
- 模型生成内容:
- 对于给定的视频和问题,模型会生成一段自然语言回答。
- 这个回答通常包含一个
<think>标签内的思维链 (Chain-of-Thought),展示其推理过程,以及一个<answer>标签内的最终答案。
数据与逻辑流转总结:
原始视频 -> 标注/生成 -> SFT数据集 -> SFT训练 -> SFT模型 -> 转换为MCQ -> RL数据集 -> RL训练 -> 最终的Cosmos-Reason1模型。
在推理(评估)阶段,流程是:测试视频+问题 -> Cosmos-Reason1模型 -> 生成带思维链的答案 -> 与标准答案对比 -> 计算准确率。
3. 有趣的白话版详细解说
想象一下,我们想教一个非常聪明的“数字大脑”(AI)如何理解我们生活的这个物理世界。
这个AI的现状是什么?
现在的AI,比如你可能用过的ChatGPT,是个“学霸”,但有点书呆子。你让它写首诗、编个程,它做得很好。但如果你给它看一段视频,问“这个杯子会掉下来吗?”或者“机器人下一步该干嘛才能把苹果放进篮子?”,它可能就懵了。因为它读了很多书,但从没“生活”过,缺乏我们人类与生俱来的“物理直觉”。
NVIDIA的科学家们想做什么?
他们想给这个“数字大脑”补上“生活课”,让它变得“手脑协调”,能看懂物理世界的门道。这个新大脑,他们取名叫Cosmos-Reason1。
教学计划是怎样的?分三步走:
第一步:编写一本“生活常识教科书” (定义本体)
在上课之前,得先有教材。科学家们做了两件事:
- 写了本《物理世界入门》: 他们把物理常识分成了三大章:空间(东西在哪,有多大)、时间(事情发生的顺序,因果)、物理(重力、碰撞、物体会不会消失)。这就像教科书的目录,让AI知道要学哪些知识点。
- 制定了份《行动指南》: 他们定义了不同“角色”(比如人类、机械臂、自动驾驶汽车)在行动时需要具备的“能力”(比如看懂周围环境、预测自己动一下会发生什么)。
有了这本“教科书”,AI的学习就有了清晰的目标。
第二步:布置海量的“课后作业” (监督微调 SFT)
光有教科书不行,还得做题。科学家们创建了一个巨大的“题库”:
他们找来几百万段小视频,内容五花八门,有机器人做家务的,有汽车在路上开的,有小球滚动的。然后,他们像老师出题一样,给每个视频配上问题和标准答案。
- “看图说话”题: “视频里发生了什么?”
- “逻辑推理”题: “如果这个人想把水倒进杯子,他下一步该做什么?”
- “开放思考”题: 他们还让另一个AI(DeepSeek-R1)来扮演“解题高手”,不仅给出答案,还写下详细的“解题思路”(这就是“思维链”)。
然后,他们把这些带有标准答案和解题思路的“作业”全部交给Cosmos-Reason1去做。这个过程就像一个学生不断学习例题,模仿“学霸”的解题方法,这个过程在AI领域叫**“监督微调”**。做完这几百万道题后,Cosmos-Reason1对物理世界有了初步的理解。
第三步:进行一场“模拟考试”并给予奖罚 (强化学习 RL)
做完作业,得考试才能进步。科学家们把之前的推理题改成了**“选择题”**。
他们把SFT训练好的Cosmos-Reason1拉过来,让它不断做这些选择题。
- 答对了,给个“赞” (奖励):模型内部的参数会调整,让它更倾向于做出类似这样的正确推理。
- 答错了,没奖励: 模型就会知道此路不通,下次要换个思路。
这个“奖罚分明”的训练过程,就是**“强化学习”**。它让Cosmos-Reason1的知识更扎实,推理更准确,不再是死记硬背,而是真正学会了思考。
最终的“毕业生成绩”如何?
毕业后,Cosmos-Reason1去参加了一场专门为物理AI设计的“高考”。结果非常惊人!
- 它在理解物体关系、预测下一步行动等方面的成绩,把其他所有“竞争对手”(包括一些非常知名的AI模型)远远甩在了后面。
- 更厉害的是,它甚至学会了一些非常微妙的“物理直觉”。比如,给它看一段“粉末从碗里飞回到勺子里”的视频,它能判断出“这视频是倒放的,不符合物理规律!”;给它看一个球滚到沙发后面,它知道“球只是被挡住了,不是凭空消失了”,这就是“物体恒存性”。这是其他AI很难做到的。
我的观点和理解:
这篇论文最让我兴奋的一点是,它不再满足于让AI成为一个“虚拟世界的文科状元”,而是真正开始着手解决AI与物理世界脱节这个核心难题。这就像是科幻电影里智能机器人诞生的前奏。
他们的方法非常系统化和务实。“先定义规则,再创造数据,最后分阶段训练” 这个路径,为后续的研究铺平了道路。特别是“强化学习”的应用,把一个模糊的“物理推理好不好”的问题,转换成了“选择题答没答对”这个简单、可验证的奖励信号,非常巧妙。
当然,Cosmos-Reason1目前主要还是通过“看视频”来学习,它还没有真正的手和脚去“亲身实践”。这就像一个人通过看无数遍游泳视频来学游泳,理论知识满了,但下水可能还是会呛水。所以,未来的关键一步,是让这样的模型与真实的机器人结合,实现“从互动中学习”,在实践中不断试错、迭代。
总而言之,Cosmos-Reason1是物理AI领域的一个重要里程碑。它让我们看到了未来AI的模样:不仅能说会道,还能看懂、理解、并最终安全、高效地在我们的物理世界中行动。从智能管家到无人驾驶,再到更复杂的科学探索,这项技术将是开启下一个AI时代大门的关键钥匙。
摘要
物理AI系统需要在物理世界中感知、理解和执行复杂的动作。在本文中,我们提出了Cosmos-Reason1模型,该模型能够理解物理世界,并通过长链思维推理过程,以自然语言生成适当的具身决策(例如,下一步行动)。我们首先为物理AI推理定义了关键能力,重点关注物理常识和具身推理。为了表示物理常识,我们使用了一个层次化的本体,它捕捉了关于空间、时间和物理学的基本知识。对于具身推理,我们依赖一个二维本体,该本体可以泛化到不同的物理实体。在这些能力的基础上,我们开发了两个多模态大语言模型,Cosmos-Reason1-7B和Cosmos-Reason1-56B。我们策划数据并在两个阶段训练我们的模型:物理AI监督微调(SFT)和物理AI强化学习(RL)。为了评估我们的模型,我们根据我们的本体构建了用于物理常识和具身推理的综合基准。评估结果表明,物理AI SFT和RL带来了显著的改进。为了促进物理AI的发展,我们将我们的代码和预训练模型在NVIDIA开放模型许可下提供,地址为 https://github.com/nvidia-cosmos/cosmos-reason1。
1. 引言
物理AI系统旨在与物理世界进行交互。为了有效地遵循指令并采取适当的行动以实现预期目标,它们需要首先感知、理解和推理物理世界。最近,随着通过长链思维(CoT)过程进行的后训练和测试时扩展的突破,大型语言模型(LLMs)在解决编码和数学等领域的复杂问题方面表现出了卓越的通用推理能力(OpenAI, 2024; DeepSeek-AI, 2025)。然而,这些模型的一个关键限制在于它们将知识根植于物理世界的能力。虽然在互联网上大量文本数据上训练的LLMs可能会获得推理物理世界所需的基本知识,但它们通常难以将这些知识与现实世界的互动和动态联系起来。
在本文中,我们首先定义了物理AI系统所必需的基本能力。与设计擅长解决编码和数学问题的模型不同,我们的重点是赋予模型基于现实世界的物理常识知识和具身推理能力。为了建立一个共享的框架并帮助衡量进展,我们提出了两个本体。首先,一个层次化本体,将物理常识组织成三个主要类别——空间、时间和基础物理学——并进一步划分为16个细粒度的子类别。该本体封装了关于物理世界如何在物理定律下运作以及它如何响应与具身智能体互动的知识。其次,我们引入了一个用于具身推理的二维本体,它涵盖了五种类型的具身智能体的四种关键推理能力。基于物理常识的有效具身对于理解和规划在现实世界中实现特定目标的行动至关重要。详细信息在第2节中描述。
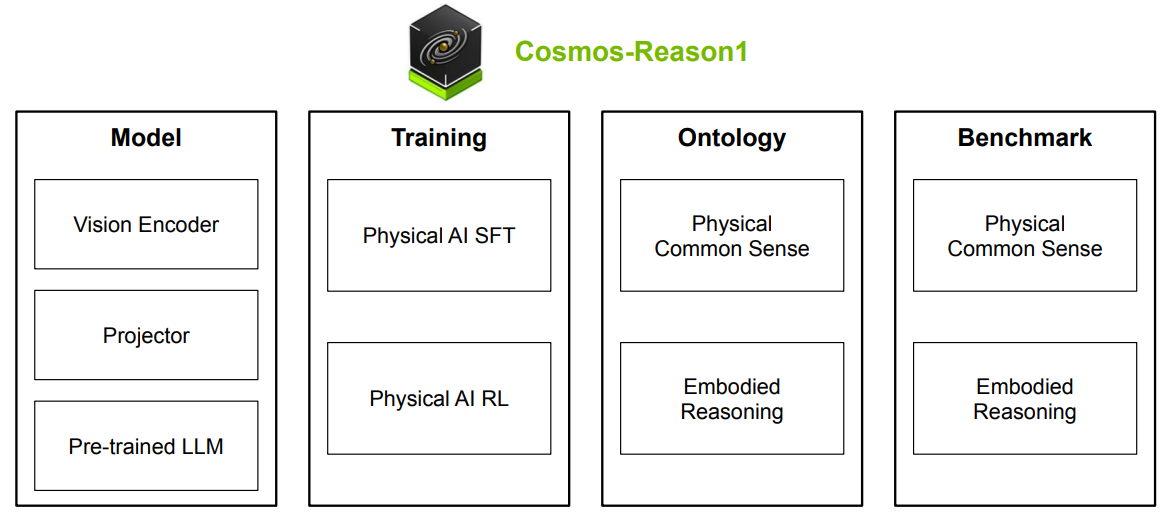
图1: Cosmos-Reason1的概览。Cosmos-Reason1包含两个7B和56B的多模态大语言模型,通过两个阶段进行训练,包括物理AI SFT和物理AI RL。我们还为物理常识和具身推理定义了两个本体,并构建了两个基准来评估模型的物理AI推理能力。
我们引入Cosmos-Reason1,作为使多模态LLMs能够生成更具物理基础响应的一步。我们关注视觉世界,其中对世界的观察以视频形式呈现。Cosmos-Reason1通过视频输入感知物理世界,理解它,并通过长链思维过程进行推理,然后生成响应。这些以自然语言表达的响应,既包括解释性见解,也包括具身决策,例如确定下一步要采取的行动。我们采用一个仅解码器的多模态LLM架构,其中输入视频由视觉编码器处理,然后通过一个投影器与文本标记嵌入对齐,再输入到LLM中。我们试验了密集Transformer和混合Mamba-MLP-Transformer架构作为LLM骨干。Cosmos-Reason1提供两种模型尺寸:Cosmos-Reason1-7B和Cosmos-Reason1-56B。我们将在第3节中详细描述模型架构。
构建基于规则、可验证的奖励在规模上对于推理LLMs在解决数学和编码问题上的成功至关重要。我们能否为训练具有强化学习的物理AI推理模型设计基于规则、可验证的奖励?在这项工作中,我们探索了两种基于回答多项选择题(MCQs)的奖励类型。第一种MCQs是基于人类注释设计的。受视频自监督学习的启发,我们自动生成第二种MCQ,基于视频数据本身的结构,例如解决时空视频块被打乱的谜题或预测视频是向前播放还是向后播放的时间箭头。所有这些奖励都是基于规则、可验证的,并且与物理AI能力高度相关。我们将在第4节中讨论RL训练算法和基础设施的设计。
数据决定了我们模型的上限。为了加强我们模型的物理常识和具身推理能力,我们精心策划了大约400万个视频和文本对的注释,包括用于物理理解的字幕、多项选择题和长链思维推理轨迹。我们开发了两个流程,根据我们的本体来策划这些物理常识和具身推理数据。这些数据是基于人类注释和从DeepSeek-R1(DeepSeek-AI, 2025)进行的模型蒸馏,用于物理AI监督微调。有关数据的详细信息在第5节中讨论。
为了评估我们的模型,我们在第6节中构建了新的基准来评估物理AI能力。对于第6.1节中的物理常识,我们构建了三个基准(空间、时间和基础物理学),包含来自426个视频的604个问题。对于第6.2节中的具身推理,我们构建了六个基准包含来自600个视频的610个问题,涵盖了包括人类、机械臂、人形机器人和自动驾驶汽车在内的各种物理实体的广泛任务。
第7节展示了Cosmos-Reason1的评估结果以及与现有模型的比较。在第7.1节中,我们介绍了实验设置,包括物理AI SFT的训练细节,以及SFT模型在我们基准上的评估结果。在第7.2节中,我们展示了物理AI RL的评估结果。使用我们在RL后训练中基于规则、可验证的奖励进行训练,导致了我们所有基准的改进。
图1展示了Cosmos-Reason1的概览。总之,我们引入了两个多模态大语言模型,Cosmos-Reason1-7B和Cosmos-Reason1-56B。这些模型分两个阶段训练:物理AI SFT和物理AI RL。我们为物理常识和具身推理定义了本体,并构建了基准来评估模型的物理AI推理能力。为了促进物理AI的进步,我们将代码和预训练模型在NVIDIA开放模型许可下提供在 https://github.com/nvidia-cosmos/cosmos-reason1。构建物理AI的推理模型是一个远未解决的开放问题,我们希望我们的论文能为该领域的进步做出贡献。
2. 物理AI推理
我们确定了物理AI推理模型的两个重要能力——物理常识推理和具身推理。首先,物理AI模型应具备物理常识,即对环境的通用、与实体无关的理解,并构成预测现实世界中何为可能与不可能的基础。其次,物理AI模型还应帮助具身智能体感知、推理和做出关于规划未来与物理环境互动的决策。我们寻求将“系统1”和“系统2”都融入物理常识推理和具身推理中。“系统1”能够实现快速、直观的反应,如模式识别和本能判断,而“系统2”则运行得更慢,为复杂决策进行深思熟虑的推理(Kahneman, 2011)。
2.1. 常识推理
人类主要通过对世界的被动观察来获得物理常识。例如,婴儿在出生后几个月内就能理解物体恒存性和重力等基本概念(Riochet et al., 2021)。这种常识包含了一系列关于现实世界中什么是可能的、不可能的或可能发生的知识。在真实世界环境中训练AI系统是昂贵的,并且可能对系统及其周围环境构成风险。利用物理常识,AI系统可以以最少的试错快速学习新技能,同时避免在不确定场景中犯下严重错误(LeCun, 2022)。
为了定义物理常识,我们引入了一个包含三个大类的本体:空间、时间和其他基础物理学,并进一步划分为16个细粒度的子类别。受Morris et al. (2024)的启发,我们关注能力而非过程。具体来说,我们的本体确定了物理AI模型应具备的关键能力,而没有具体说明系统完成任务的机制或实体。例如,我们认为理解物体的空间关系、事件的时间顺序和物体恒存性是物理AI的基础。然而,这样的系统不必像人类一样行动,例如用灵巧的手指抓取或用两条腿走路。
我们在图2中展示了我们的物理常识本体。空间类别包括物体之间的关系、它们的互动以及周围环境。它包括关系、可能性、可供性(Affordance)和环境等概念。时间类别涉及随时间展开的动作和事件,涵盖动作、顺序、因果关系、相机和规划。最后,我们引入了基础物理学类别,以解决物体和核心物理原理,包括属性、状态、物体恒存性、力学、电磁学、热力学和反物理学。所有子类别的详细定义在表1中描述。
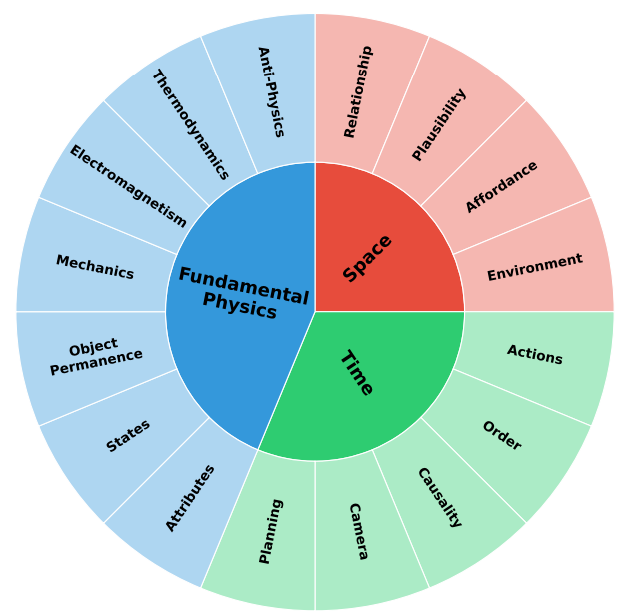
图2: 展示我们物理常识本体的饼图。该本体包含三个类别(空间、时间和基础物理学)和16个细粒度子类别。
2.2. 具身推理
物理AI在现实世界中运作,环境是动态、不确定且受复杂物理互动支配的。与在结构化和确定性方式下操纵符号的数学和编程中的抽象推理不同,具身推理要求AI系统与物理世界互动并从中学习。与被动理解不同,具身AI中的推理通常以行动为基础,使机器人不仅能理解它们当前观察到的情况,还能为未来在不确定和动态环境中规划智能行为。具体来说,具身推理需要具备以下能力:
- 处理复杂的感官输入。 与处理干净数据表示的符号推理不同,具身推理必须从原始、通常不完整和模糊的感官输入中提取有意义的模式。
- 预测行动效果。 行动会产生物理后果,有效的推理需要对因果关系有直观的把握。AI系统必须预测物体对力的反应,机器人的身体如何与周围环境互动,或者车辆的运动将如何受到地形和物理学的影响。
- 遵守物理约束。 与通常涉及优化离散选择的抽象问题解决不同,具身推理必须考虑现实世界的物理学,如惯性、摩擦和材料属性。它要求AI生成在给定物理约束下可行的长期行动计划,确保执行的稳定性、效率和安全性。
- 从互动中学习。 在物理AI中,行动不是孤立发生的;每一个动作或决定都会影响环境并产生反馈。具身推理必须根据这些互动不断更新其理解,允许系统动态地完善其行为。
具身推理也不局限于单一类型的智能体——它适用于人类、动物和各种形式的机器人(例如,机械臂、人形机器人或自动驾驶汽车)。它们都需要发展类似的具身推理技能,以在不同的环境条件和任务目标下导航、操纵和做出适应性决策。我们在表2中将物理实体的能力和类型及其示例总结为一个二维本体。
[表1: 物理AI系统能力定义]
表1标题: 我们常识本体中每个子类别的物理AI系统能力定义。
| 类别: 子类别 | 能力 |
|---|---|
| 空间: 关系 | 确定场景中物体的空间关系。视角很重要;例如,一个物体在人的左边还是在相机视角的左边。 |
| 空间: 可能性 | 确定一个可能的空间关系是否可行。 |
| 空间: 可供性 (Affordance) | 理解物体与主体(如人类、动物、机器人等)的互动。 |
| 空间: 环境 | 理解场景或周围环境。 |
| 时间: 动作 | 理解动作,包括准确描述动作(移动、方向、强度等),确定动作目标,子任务或目标分解,以及确定任务/目标是否成功完成。 |
| 时间: 顺序 | 理解事件的时间戳和顺序。 |
| 时间: 因果关系 | 理解事件A是否导致事件B。 |
| 时间: 相机 | 确定相机的位置和移动,包括相机移动、相机角度/位置和场景转换。 |
| 时间: 规划 | 基于过去的观察提出未来计划。 |
| 基础物理学: 属性 | 确定物体的物理属性,包括语义描述、尺寸、颜色、材料、质量、温度、坚固性(物体能否穿过彼此?)等。 |
| 基础物理学: 状态 | 确定物体状态并理解状态变化(例如,冰变成水,鸡蛋从生变熟)。 |
| 基础物理学: 物体恒存性 | 理解物体恒存性,即在特定条件下哪些属性可以/不可以改变(重量、形状、尺寸、颜色等)。 |
| 基础物理学: 力学 | 理解与力学相关的物理定律,包括静力学(平衡、稳定、支撑、弹性、变形、质心等)、运动学(速度、加速度、线性运动、圆周运动、旋转运动等)和动力学(重力、碰撞、摩擦、滑动、惯性、动量守恒、流体和粒子等)。 |
| 基础物理学: 电磁学 | 理解与电磁学相关的物理定律,包括光学(光照、阴影、遮挡、反射、折射、衍射、吸收、透射等)、电学和磁学。 |
| 基础物理学: 热力学 | 理解与热力学相关的物理定律,如热量、温度变化、蒸发、热传递、热胀冷缩等。 |
| 基础物理学: 反物理学 | 理解违背物理定律的情况,如反重力、时间倒流、永动机、突然消失等。 |
在本文中,我们关注上面定义的前三个具身推理能力,并将“从互动中学习”作为未来工作。具体来说,我们关注视频输入作为“处理复杂感官输入”的一个代表性例子。对于“预测行动效果”,我们关注两个任务,包括用于确定任务是否已完成的任务完成验证,以及用于预测实现目标的下一个合理行动的下一个合理行动预测。对于“遵守物理约束”,我们关注行动可供性,以评估是否可能对目标执行特定行动。我们收集了跨不同智能体的视频,包括人类、机械臂、人形机器人和自动驾驶汽车。通过研究这些不同案例,我们旨在加深我们对具身推理如何实现与物理世界智能互动的理解。
3. Cosmos-Reason1
Cosmos-Reason1是一个专为物理AI推理而设计的多模态大语言模型家族。该家族包括两个模型:Cosmos-Reason1-7B和Cosmos-Reason1-56B。在本节中,我们介绍我们的多模态架构设计和LLM骨干的选择。
表2: 具身推理本体,包含每种能力和智能体类型组合的示例。
| 自然智能体 (人类, 动物) | 机器人系统 (机械臂, 人形机器人, 自动驾驶汽车) | |
|---|---|---|
| 处理复杂感官输入 | 一个人观看关于烹饪食谱的视频。 一只蝙蝠利用回声定位来定位猎物。 | 一个机械臂使用其摄像头识别物体。 一个机器人在行走时检测障碍物。 一辆自动驾驶汽车识别停车标志和行人。 |
| 预测行动效果 | 一个木匠在切割前预料到木头会 splintering(裂开)。 一只狗估算球的落点以便接住它。 | 一个机械臂在抓取物体前补偿动量。 一个机器人在举起物体前估算其重量。 一辆自动驾驶汽车预测冰面上的轮胎打滑。 |
| 遵守物理约束 | 一名飞行员在空气动力学限制内保持高度。 一只猎豹限制速度以避免肌肉拉伤。 | 一个机器人夹爪限制其力量以防止压碎物体。 一个机器人调整关节扭矩以防止摔倒。 一架无人机避免超过风阻阈值。 |
| 从互动中学习 | 一位高尔夫球手在观察球的轨迹后纠正自己的站姿。 一只狗通过反复尝试学会开门。 | 一个工厂机器人在检测到错位后改进对齐。 一个机器人学习新的握手方式。 一辆自动驾驶汽车优化其刹车距离。 |
3.1. 多模态架构
在使用现有的纯文本LLM骨干和视觉编码器构建多模态大语言模型(LLMs)方面,存在不同的架构设计。常用的架构有仅解码器架构(例如,LLaVA (Liu et al., 2023))和基于交叉注意力的架构(例如,Flamingo (Alayrac et al., 2022) 和 Llama 3-V (Grattafiori et al., 2024))。我们采用了与LLaVA (Liu et al., 2023) 和 NVLM-D (Dai et al., 2024) 类似的仅解码器架构,因为它简单且通过将其他模态的令牌(图像或视频)对齐到文本令牌嵌入空间中,实现了对所有模态的统一处理。具体来说,模型从视觉编码器(Chen et al., 2024)开始,然后是一个包含一个下采样双层MLP的投影器,最后是仅解码器的LLM骨干(Nvidia et al., 2024; Waleffe et al., 2024; DeepSeek-AI, 2025)。
对于Cosmos-Reason1-7B,我们选择Qwen2.5-VL (Bai et al., 2025) 作为我们的预训练模型,并遵循相同的图像和视频处理方式。对于Cosmos-Reason1-56B,我们利用InternViT-300M-V2.5 (Chen et al., 2024) 作为我们的视觉编码器,并使用Nemotron-H (NVIDIA, 2025) 作为我们的LLM骨干。我们对Cosmos-Reason1-56B混合模型执行以下处理。对于每个输入图像,我们根据图像的分辨率,动态地将其调整到预定义的宽高比,并将其分割成1到12个图块,每个图块大小为448 × 448像素。此外,我们生成一个缩略图图块;一个完整图像的缩小版本,以保留全局上下文。更多细节可以在Dai et al. (2024)中找到。对于每个输入视频,我们以每秒最多2帧的速率均匀采样最多32帧,并将每帧大小调整为448 × 448像素。对于每个448 × 448的视频帧输入,视觉编码器生成1,024个视觉令牌,其补丁大小为14 × 14,然后使用PixelShuffle (Shi et al., 2016) 将其下采样2 × 2倍,通过将空间维度转换为通道维度,将其减少到256个令牌。来自多个图块的图像令牌与交错的图块ID标签连接在一起,如Dai et al. (2024)所述,而来自多个帧的视频令牌则直接连接。关于混合LLM骨干的更多讨论见第3.2节。我们在图3中说明了我们的混合多模态架构,并在表3中总结了我们的模型配置。
3.2. 混合Mamba-MLP-Transformer骨干
自推出以来,Transformer架构 (Vaswani et al., 2017) 彻底改变了语言建模领域,成为构建基础模型的实际标准。然而,其自注意力机制相对于其上下文长度具有二次方的时间复杂度。相比之下,最近提出的Mamba架构 (Gu and Dao, 2023) 引入了具有选择性状态空间的线性时间序列建模使其在处理长序列时效率显著提高。在实践中,Mamba的选择性状态空间可能不足以捕捉长序列中的所有细节。为了解决这个问题,我们引入了一小部分Transformer层用于长上下文建模,从而产生了混合Mamba-MLP-Transformer架构 (Waleffe et al., 2024)。
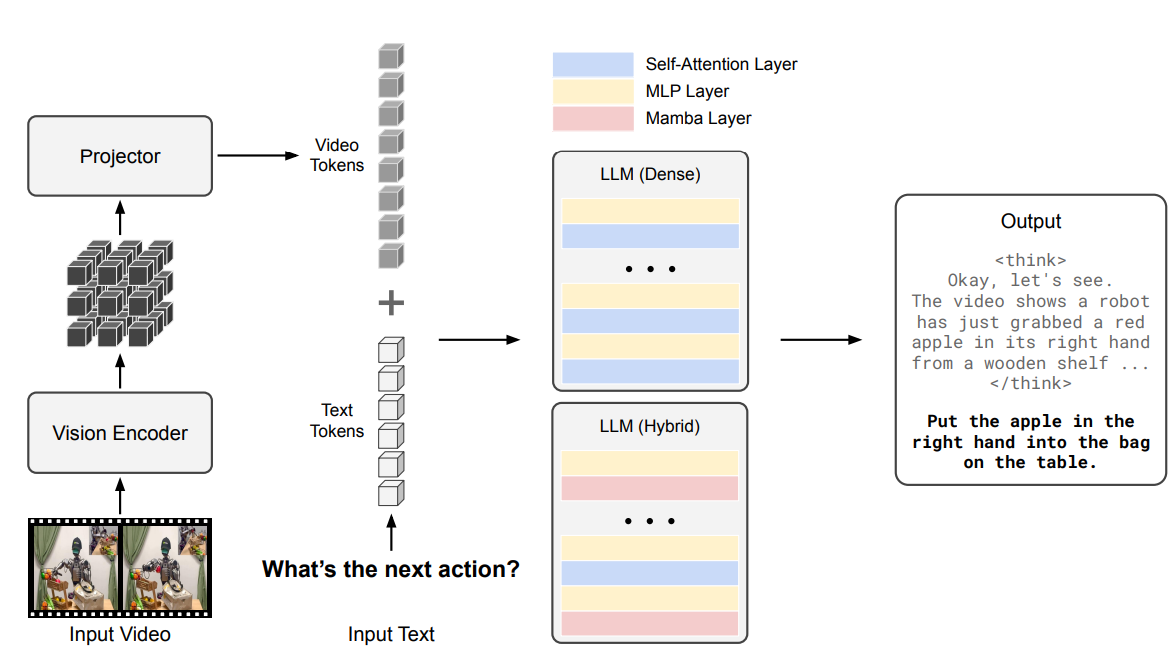
图3: 我们的多模态大语言模型架构示意图。给定一个输入视频和一个输入文本提示,视频通过视觉编码器和投影器被投影到LLM的令牌嵌入空间中,成为视频令牌。文本令牌与视频令牌连接后被送入LLM骨干,这是一个密集的Transformer或混合Mamba-MLP-Transformer架构。我们的模型可以输出带有长链思维推理过程的响应。
表3: Cosmos-Reason1模型的配置详情。
| 配置 | Cosmos-Reason1-7B | Cosmos-Reason1-56B |
|---|---|---|
| 视觉编码器 | ||
| 架构 | ViT-676M | ViT-300M |
| 输入尺寸 | 动态 | 448 x 448 |
| 补丁尺寸 | 14 x 14 | 14 x 14 |
| 层数 | 32 | 24 |
| 模型维度 | 1,280 | 1,024 |
| FFN隐藏维度 | 3,456 | 4,096 |
| 投影器 | ||
| 下采样 (HxWxT) | 2×2×2 | 2×2×1 |
| 层数 | 2 | 2 |
| 输入维度 | 1,280 | 4,096 |
| 隐藏维度 | 5,120 | 32,768 |
| 输出维度 | 3,584 | 8,192 |
| LLM骨干 | ||
| 架构 | Transformer | Mamba-MLP-Transformer |
| 层数 | 28 | 118 |
| 模型维度 | 3,584 | 8,192 |
| FFN隐藏维度 | 18,944 | 32,768 |
| 注意力头数 | 28 | 64 |
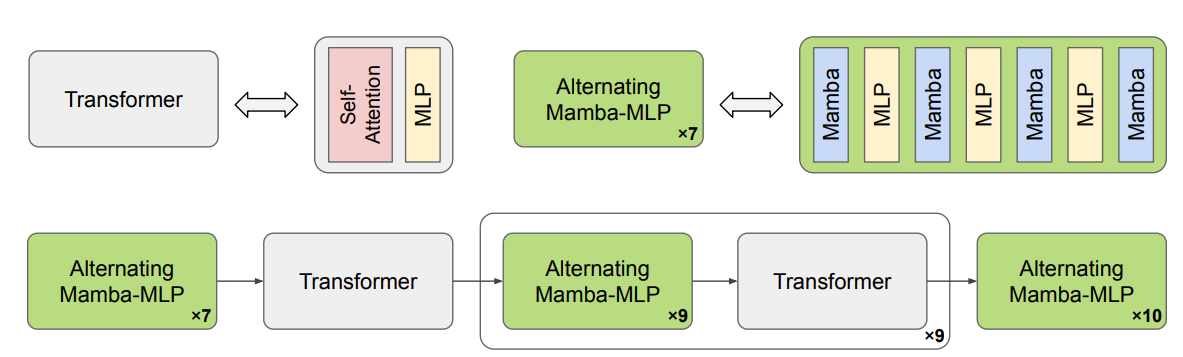
图4: 我们在Cosmos-Reason1-56B中使用的混合Mamba-MLP-Transformer骨干架构示意图。一个Transformer块由一个自注意力层和一个MLP层组成。我们还在图的上方展示了一个交替的Mamba-MLP模块的例子。
(图中展示了Transformer块与交替的Mamba-MLP块的组合结构。)
在Cosmos-Reason1-56B中,我们使用一个预训练的混合Mamba-MLP-Transformer架构模型 (NVIDIA, 2025) 作为我们的骨干。56B LLM架构的示意图可以在图4中找到。我们使用4路张量并行(TP=4)(Shoeybi et al., 2019) 来训练Cosmos-Reason1-7B密集模型,而Cosmos-Reason1-56B混合模型则使用8路张量并行和2路流水线并行(TP=8, PP=2)进行训练。
4. 强化学习
我们采用物理AI SFT和物理AI RL两个训练阶段,将一个预训练的视觉语言模型(例如,Qwen2.5-VL (Bai et al., 2025) 或 Nemotron-H-VLM (NVIDIA, 2025))适配成一个物理AI推理模型。在SFT阶段之后,我们使用RL对我们的模型进行后训练,专注于物理AI的任务,以进一步增强它们的物理常识和具身推理能力。在本节中,我们解释了算法和定制的训练框架,该框架对RL训练非常高效和稳健。
4.1. 算法
我们选择GRPO (Shao et al., 2024) 作为我们的RL算法,因为它简单且计算效率高,避免了训练和维护一个单独的评论家模型的必要性。GRPO实现了一种简化的策略优化方法,其中优势函数是通过对每个提示生成的一组响应内的奖励进行归一化得到的。设R(oᵢ)表示响应oᵢ的奖励,在一组响应G = {o₁, o₂, …, oₙ}中,计算出的优势可以表示为:
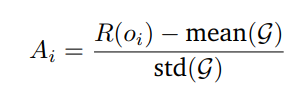
4.2. 训练框架
为了更有效地使用RL训练数据,我们还提出了一个新颖的、完全异步且高度稳健的RL训练框架。该架构如图5所示。首先,与主流的同地部署框架(Hu et al., 2024; Sheng et al., 2024)因同步开销而导致资源利用效率低下不同,我们提出的框架采用了策略训练和actor rollout的异构部署策略。通过利用一个统一的调度器来安排和分派训练提示,我们的设计在整个训练流程中实现了异步并行。这实现了端到端的异步性,同时保持了训练的有效性,与同地部署的框架相比,训练效率提高了约160%。其次,归功于我们新颖设计的训练网格管理逻辑,该框架能够快速地自我重新配置,并在训练期间即使有任何节点失败也能继续当前的训练步骤,而无需昂贵的重启或恢复过程。此外,调度器的冗余机制也提高了整体框架的稳健性,并且容错设计天生支持动态扩展,包括向上和向下扩展,从而能够根据工作负载需求进行灵活的资源分配。
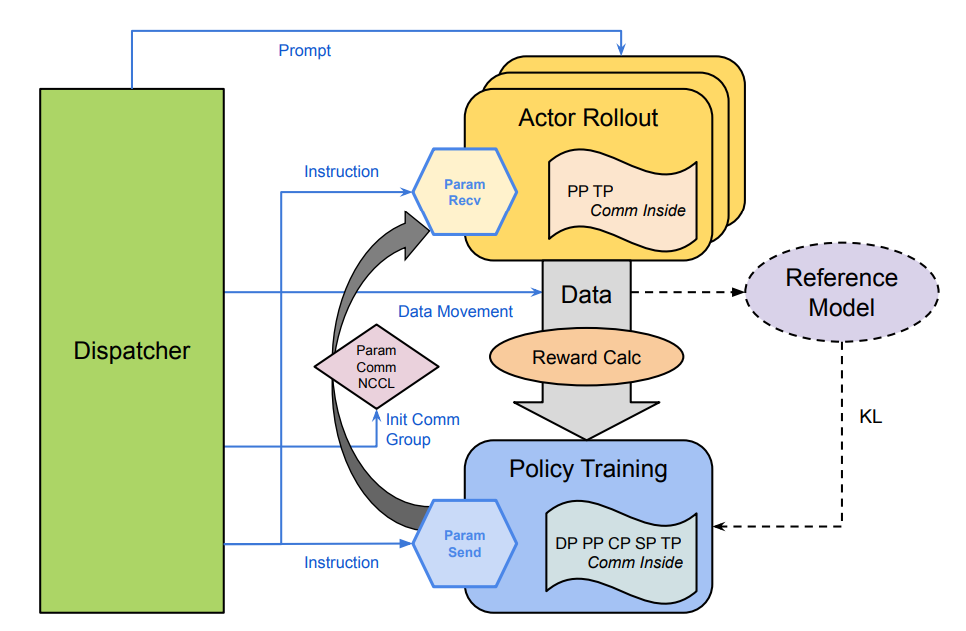
图5: 提出的RL训练框架的架构。主要有三部分。(1) 调度器:调度和分发训练数据,管理框架的状态。(2) Actor Rollout:从提示生成响应,为策略训练计算奖励和优势。(3) 策略训练:在actor上执行RL算法,并根据奖励和其他约束来优化actor。策略训练节点支持5D并行,即数据并行(DP)、流水线并行(PP)、上下文并行(CP)、完全分片数据并行(FSDP)和张量并行(TP)。actor rollout节点支持DP、PP和TP。我们采用定制的NCCL通信器在调度器和rollout/策略节点之间进行通信。
5. 数据
在本节中,我们解释了用于训练Cosmos-Reason1模型的物理AI SFT和RL的数据来源及其策划过程。
5.1. 物理AI监督微调
在此阶段,我们对前一阶段的模型在领域特定数据上进行微调,以专门研究物理AI。此过程旨在实现两个关键结果:(1) 增强模型在物理AI特定数据上的视觉语言能力,以及 (2) 发展两种关键的推理能力——物理常识推理和具身推理(详见第2.1节和第2.2节)。与前两个训练阶段不同,现有的数据源不能直接用于物理AI SFT。为了应对这一挑战,我们开发了一个专门的流程,为物理常识和具身推理应用精心策划SFT数据集。一部分物理AI SFT数据,特别是视觉问答(VQA)对,是通过“模型在环”的方法生成的,而不是直接来自人类策划。
对于物理常识,我们构建VQA数据集来回答来自视频的自由格式和多项选择题。对于具身推理,我们对现有数据集进行二次采样和转换,形成我们的SFT数据集,其中我们涵盖了包括人类、机械臂、人形机器人和自动驾驶汽车在内的不同实体的广泛任务。对于每个数据集,我们收集两种类型的注释:理解和推理。一个理解注释包含视频的问题和答案(对于常识)以及视频中状态和动作的详细描述(一个结构化的视频字幕)。一个推理注释包含对于给定的文本提示和输入视频的长链思维(CoT)轨迹。此外,我们进一步策划了特定的推理SFT数据集,以增强我们的模型理解时空视觉刺激(通过视频中的谜题和时间箭头)以及物体恒存性(通过基于物理的模拟)的能力。这些数据集统称为直觉物理。表4总结了我们用于物理AI SFT的数据集,图6展示了来自我们物理AI监督微调数据集的视频帧示例。接下来,我们详细描述特定设置的策划流程。

图6: 物理AI SFT数据集视频帧示例
5.1.1. 物理常识SFT
如前所述,对于物理常识,我们收集了包含自由格式和多项选择题(MCQs)的VQA数据集。我们的物理常识数据策划流程包括五个阶段:
- 人机协作视频策划。 我们根据人类偏好策划了一组高质量视频。我们从这些视频中提取短片,并将其用作训练样本。
- 详细字幕。 我们雇佣可靠的人类标注员或使用预训练的视觉语言模型(VLMs)来提取视频的详细描述。这些描述作为“字幕”,我们用它们来构建理解和推理注释。
- 策划问答对。 我们提示一个LLM根据详细的剪辑描述构建自由格式或多项选择题。我们构建两种类型的问题:(1) “理解”问题,涵盖视频内容(通过字幕观察到的);(2) 假设性的“推理”问题,这些问题需要字幕中的信息来构建问题,但不能直接根据详细字幕回答。“推理”问题需要超越仅仅感知剪辑中的事件和对象进行更多的思考。我们的推理问题侧重于来自视频的常识推理、空间推理和时间推理。附录A.1展示了用于生成推理问题的样本问题构建提示模板。
- 提取推理轨迹。 为了获得完整的“推理”注释,我们提示DeepSeek-R1 (DeepSeek-AI, 2025) 使用详细字幕作为上下文来回答推理子集的问题。然后,我们将DeepSeek-R1的响应解析为思维轨迹和答案。我们发现,提出无法直接从字幕中回答的问题非常重要。否则,R1可以直接从提供的字幕中检索答案,使得思维轨迹对于模型训练无效。我们的“推理”注释由推理问题、相应的剪辑、思维轨迹和答案组成。附录A.2展示了用于从DeepSeek-R1引出推理的样本提示。
表4: 用于物理AI监督微调的数据集摘要

- 清理与重写。 最后,我们采用一个基于规则的清理和重写阶段,为“推理”注释生成有效的SFT样本。由于我们将剪辑的视觉上下文压缩为文本,重写有助于移除SFT训练样本中不希望出现的引用,如“描述”或“字幕”。
使用上述流程,我们策划了包含自由格式和多项选择题的物理常识VQA数据集,并考虑了以下几点:
自由格式问题: 我们使用了来自“高质量”剪辑策划集的9900个视频,并获得了相应的人工标注的详细描述。人工标注字幕的平均长度为297.4 ± 46.4个词。对于自由格式问题,我们通过上述流程获得了约9.9万个理解SFT样本和约5.94万个推理SFT样本。
多项选择题(MCQs): 为确保我们的模型能够回答多项选择题(MCQs),我们额外为高质量的策划剪辑收集了一套“理解”和“推理”MCQs。与自由格式问题不同,我们首先用来自VLM的详细字幕标注了约120万个高质量剪辑。使用这些字幕,我们构建了约240万个“理解”MCQs。然后,我们选取了约35.6万个剪辑的子集,并使用详细字幕生成了约60万个“推理MCQs”。
5.1.2. 具身推理SFT
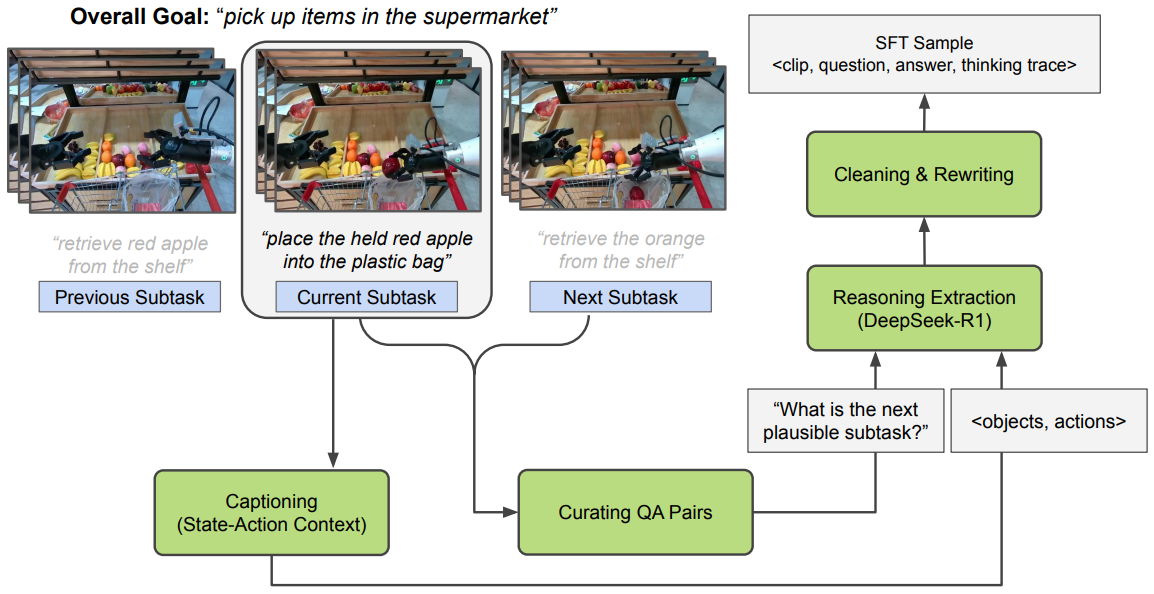
图7: 具身推理SFT数据策划流程。我们以AgiBot为例进行说明,其中我们(1)提取与子任务对应的短时域片段,(2)为提取的片段添加字幕以获得状态-动作上下文,(3)为“下一个合理的子任务预测”策划问答对,(4)用问题和字幕提示R1以引出推理,(5)清理和重写推理轨迹以获得有效的SFT样本。
我们的具身推理SFT数据策划流程专注于对物理AI智能体决策至关重要的三个关键属性:(1) “任务完成验证”:确定一个任务或子任务是否已成功完成的能力;(2) “动作可供性”:评估执行特定动作或朝着目标前进是否可能的能力;以及(3) “下一个合理动作预测”:识别最合理的下一个动作或子任务以推进指定目标的能力。这些属性对于跨各种实体和任务配置的有效决策至关重要。为了发展这些推理能力,我们从公共和专有数据集中策划SFT样本。我们使用的具身推理SFT数据集包含结构化条目,每个条目有四个组成部分:视觉字幕、问题、相应答案和详细的推理轨迹。
展示物理AI智能体追求目标导向任务的视频是我们具身推理数据的主要来源。我们从展示人类、机器人或车辆执行特定任务的来源收集SFT数据。对于具身推理,我们特别关注与我们感兴趣的关键属性相关的短时域推理——确定智能体是否能对紧接的下一个子任务或动作进行推理(可供性和下一个合理动作预测),或评估短时域任务的成功完成(验证任务完成)。由于现有的物理AI演示数据集可能缺乏提取此类局部动作或子任务序列所需的密集注释,我们使用一系列专门的步骤来提取这些片段。我们确保我们策划的数据集在多样性、短时域粒度(紧接的下一个动作或紧接的下一个子任务)、实体和推理提示方面是丰富的。我们使用的策划流程具有以下一般步骤(也在图7中说明):
- 提取短时域片段。 由于我们对短时域推理任务感兴趣,我们将长视频演示分解为专注于短时域推理任务的简洁剪辑。这些片段捕捉单个动作(例如,“向左移动”)或不同的子任务(例如,“打开冰箱门”)。当现有数据集已经提供适当分段的剪辑或时间戳时,我们直接利用它们。否则,我们利用互补的注释,如动作基元和计划,来提取这些短时域片段。
- 标注状态-动作上下文。 对于每个短时域剪辑,我们使用一个VLM来生成结构化字幕,详细说明存在的对象、它们的属性和相关的动作。当数据集提供可以增强此类结构化字幕质量的补充注释时,我们将此信息纳入VLM提示中。这些构成了我们具身推理SFT的“理解”注释。对于AV数据,我们直接使用人工标注的字幕。
- 策划推理问答对。 我们根据可用的子任务和动作注释,开发专注于我们感兴趣的关键属性的推理问答对。对于已经包含解决我们目标属性的合适问答对的数据集,我们应用最少的基于规则的预处理,然后将它们添加到我们的具身推理SFT数据池中。
- 提取推理轨迹。 我们利用DeepSeek-R1 (DeepSeek-AI, 2025) 为我们策划的问答对生成推理轨迹。由于R1缺乏视觉处理能力,我们构建包含状态-动作上下文、问题和附加信息(如子任务指令或总体目标)的提示,以引出适当的推理轨迹。图7演示了此过程,而附录A.3展示了一个将视觉信息转换为短时域问题“下一个合理动作”的文本上下文的示例用户提示。
- 清理与重写。 最后,我们使用基于规则的清理和重写来仅保留有效和有用的推理轨迹。由于我们将剪辑的视觉上下文压缩为文本,重写有助于移除对“描述”或“字幕”的不必要引用。
策划流程中每一步的具体细节因数据集而异,但总体流程保持不变。我们现在描述此流程如何应用于各个数据源。
BridgeData V2: BridgeData V2 (Walke et al., 2023) 旨在通过提供广泛的机器人操作行为来推进可扩展的机器人学习。该数据集强调基础的物体操作任务,如拾取和放置、推动和清扫,以及更复杂的活动,如堆叠积木和折叠布料。它包括60,096个轨迹,包括50,365个遥操作演示和9,731个脚本化的拾取和放置展示,跨越13种不同技能和24个不同环境。每个轨迹都用与机器人执行的任务相对应的自然语言指令进行注释。环境分为四组(玩具厨房、桌面、玩具水槽等),其中有显著的一部分数据来自七个独特的玩具厨房,这些厨房具有水槽、炉灶和微波炉的组合。我们首先从数据集的“训练”分割中分割视频,获得12.95万个视频剪辑。然后,我们使用一个VLM为视频剪辑添加字幕,作为理解注释。在字幕提示中,我们还提供了额外信息,如从ECOT (Zawalski et al., 2024)检测到的对象和动作序列。我们仅为BridgeData V2生成“下一个合理动作预测”的推理问答对,其中答案对应于如“向左移动”这样的动作基元。推理注释是通过将字幕和问题输入DeepSeek-R1生成的。
RoboVQA: RoboVQA (Sermanet et al., 2024) 是一个大规模的、以机器人为中心的视觉问答数据集。它由视频、指令和智能体(机器人、人类、带抓取工具的人类)执行任务的问答对组成。RoboVQA有6种不同的问题类型,涵盖了与规划、验证任务完成、判别性可供性、生成性可供性、过去描述和未来预测相关的方面(这些对应于之前概述的属性)。我们直接使用RoboVQA中的剪辑而不进行任何剪辑,以获得约22万个剪辑的数据集。我们使用VLM为这些剪辑添加字幕,并通过将任务上下文、字幕和问题组合成一个合适的用户提示,从DeepSeek-R1中提取推理轨迹。这导致了约93万个带有推理轨迹的问答对。我们过滤一个合适的子集进行后处理,并使用数据集中“训练”分割的剪辑和问答对进行SFT。来自RoboVQA的SFT样本涵盖了我们具身推理策划流程中所有3个期望的属性。
AgiBot: AgiBot World (AgiBot, 2024) 是一个高保真的机器人操作数据集。数据是使用AgiBot G1硬件平台收集的,涵盖了广泛的现实生活任务。它包含36个任务。每个任务包含多个在环境和对象方面有所不同的剧集。我们为每个任务二次采样一部分剧集,总共得到3,300个视频。每个视频都用整体任务信息和多个子任务注释进行标注,包括开始和结束帧。我们利用这些动作注释将视频分割成剪辑,最终得到一个1.98万个剪辑的数据集。这些剪辑由VLM添加字幕,以将视觉信息转换为场景/对象描述及其移动。我们仅为AgiBot生成“下一个合理的子任务预测”问题,其中答案对应于一个子任务(“将黄瓜放入袋中”)。然后,我们使用DeepSeek-R1根据生成的字幕来推理完成任务所需的下一个可能的子任务。
HoloAssist: 以自我为中心(Egocentric)的数据集捕捉了关键的第一人称视角,为人类行为提供了自然和沉浸式的理解,但也带来了独特的挑战,包括相机运动、微妙的动作、遮挡、视野外的物体、空间视角问题以及对全局场景理解的需求。尽管存在这些挑战,它们对于在物理AI系统中开发具身决策能力仍然很有价值,可能实现类似人类的解释和对真实世界环境的响应。我们选择在HoloAssist (Wang et al., 2023) 的基础上进行构建,该数据集包含166小时以对象为中心的操纵任务的以自我为中心的视频。值得注意的是,HoloAssist独特地包含了人类的错误以及为纠正它们所采取的步骤。这些见解可以帮助物理AI以一种反映人类如何学习并完善他们对真实世界中物体理解的方式进行学习。使用来自HoloAssist的带时间戳的粗粒度和细粒度动作注释,我们将1,758个视频分割成一个最终的139,653个剪辑的数据集。我们使用一个VLM来生成字幕注释。我们仅为HoloAssist生成“下一个合理的子任务预测”问题,其中答案对应于一个子任务。我们使用DeepSeek-R1为预测完成任务所需的下一个可能子任务生成推理轨迹,基于生成的字幕。在每个流程中,我们提供任务注释作为总体目标,并提供细粒度注释作为当前子任务,以补充字幕。
自动驾驶汽车 (AV): 作为物理AI的一个关键领域,自动驾驶汽车(AV)依赖于大规模、高质量的数据来实现安全可靠的自动驾驶体验,特别是在快速扩展的端到端系统时代。在这项工作中,为了避免字幕幻觉——尤其是在微妙的行为和复杂的互动中——我们利用了带有高质量人工标注字幕的专有数据集。我们的数据集包含约12.4万个视频,每个视频长20秒,总时长约70小时。每个字幕包括三个类别:(1) 一般描述,详细说明了自车行为、环境条件(例如,场景类型、一天中的时间、天气、道路状况)和关键对象(例如,车辆、行人、骑自行车的人、交通灯、交通标志);(2) 驾驶难度,根据所需驾驶员注意力的水平和场景的独特性或风险,对驾驶复杂性进行简明评估;以及(3) 注意,突出显示了显著事件,如标志和信号、道路使用者互动和异常行为。通过利用这些字幕,我们将驾驶视频转换为结构化描述。然后使用DeepSeek-R1生成推理轨迹,以根据这些结构化描述预测自车最可能采取的下一个即时动作。
5.1.3. 直觉物理SFT:空间谜题、时间箭头和物体恒存性
虽然之前的SFT阶段能够为物理AI应用实现领域特定的推理,但我们加入了额外的SFT阶段,以发展围绕直觉物理的基本推理能力。尽管直觉物理推理能力涵盖了广泛的分类(见表1),我们特别关注三个关键方面:关于空间连续性的推理(通过空间谜题)、关于时间箭头的推理(通过视频中事件的时间顺序)以及关于物体性的推理(通过评估物体恒存性的模拟设置)。这些任务在构建上是内在地自监督的,这简化了数据策划过程。尽管在更复杂的任务上取得了显著进展,但当前最先进的VLM在这些更简单的基本推理目标上仍然表现不佳。为了解决这些限制,我们策划了针对空间连续性、时间箭头和物体恒存性的专门SFT数据集。
关于空间连续性的推理:空间谜题。 除了空间关系,理解空间连续性对于物理AI任务至关重要。为了让我们的模型具备对空间连续性的基本理解,我们进一步在解决空间谜题的任务上对它们进行微调。具体来说,我们策划了3000个具有不同背景、运动和相机姿态的视频。对于每个视频,我们提取第一帧并将其分成2×2的补丁。然后将这些补丁打乱以创建一个新的剪辑,其中一帧就是一个补丁。我们提示模型识别相对于原始帧的左、上、下、右位置。为了进一步增加任务的复杂性,我们引入了七个额外的干扰图像,每个也分成2×2的补丁。这导致一个样本总共有32个打乱的帧,提供给模型以推理正确的位置。此外,我们设计了一些“身份”驱动的补充任务——确定哪两帧或三帧与第一帧来自同一图像。类似于对比学习,这个任务要求模型在区分相关和不相关样本的同时发展出强大的空间推理能力,但现在是带有推理的。
为了生成高质量的空间连续性推理数据,我们首先使用一个VLM为32个补丁中的每一个添加字幕,并将这些描述输入DeepSeek-R1来解决三个任务之一。我们只保留R1做出正确预测的样本。3,000个图像中的每一个都用不同的干扰物和打乱顺序处理多次。过滤后,我们的最终数据集包含1.1万个视频。附录A.4展示了一个用于引出推理轨迹的样本提示。
关于时间的推理:时间箭头 (AoT)。 与空间类似,我们也让我们的模型具备了推理时间的能力,特别是宏观尺度上事件的时间顺序。我们希望我们的模型理解时间在宏观尺度上是内在不可逆的,并且同样可以通过视频中的运动和活动模式感知到。能够推理单向的时间箭头对于物理AI至关重要,因为它与熵、重力和因果关系等基本物理现象密切相关。此外,它可以作为学习直觉物理的代理监督信号。特别是,时间上被改变或反转的视频包含物理AI能够评估的违背物理学的伪影。
我们构建了一个包含30,000个短视频剪辑及其反转版本的SFT数据集,使用的是来自Cosmos-Predict1 (NVIDIA, 2025) 训练数据集的视频子集。这个子集中的视频包含多样化和复杂的任务,这些任务经常涉及显著的运动。我们优先选择具有大运动的视频,因为它们是区分时间箭头的最具代表性的例子。与之前的阶段不同,我们使用一个VLM直接为正向和反向播放的剪辑提取推理轨迹。我们发现,应用与第5.1.2节相同的程序,使用R1提取思维轨迹的结果不理想。为了改进策划,我们在用户提示中明确指出视频是正向播放还是反向播放,帮助VLM生成更合理的论证。此外,我们精心设计提示,以确保两个播放方向的推理轨迹保持一致的风格和长度。附录A.5展示了用于此目的的示例提示模板。为了鼓励推理的多样性,我们为每个正向和反向视频策划了两个不同的推理轨迹。
关于物体性的推理:物体恒存性。 虽然空间连续性和时间顺序为理解物理关系和序列提供了基础,但物体恒存性——即理解即使不能直接观察到物体也依然存在的概念——代表了对物理AI智能体至关重要的推理能力。没有强大的物体恒存性推理,VLM将在即使是基本的真实世界场景中也会遇到困难,在这些场景中,物体经常移入和移出视野或被遮挡,从而严重限制了它们在需要一致的物体跟踪和预测能力的物理AI应用中的效用。
对于物体恒存性,我们构建了一个包含1万个由机器人模拟平台Libero (Liu et al., 2023)合成的剪辑的SFT数据集。Libero提供了130个机器人臂物体操作任务,跨越不同的环境、桌面物体和预先录制的臂部动作序列。为了增强场景多样性,我们从这些任务中随机抽样设置,并应用物体排列和扰动。相机被定位在面向桌子中心的位置,并通过在球体上选择一个随机的起点和终点来围绕场景轨道移动。在播放预先录制的臂部动作期间,相机从起点平滑插值到终点,然后返回其起始位置附近。在此过渡期间,一些物体可能会被暂时遮挡,一旦完全遮挡,某些物体可能会被随机地从场景中移除。我们用适当的上下文提示模型,并要求它分析每个剪辑,确定是否有任何物体意外消失,从而违反了物体恒存性。为了确保模型生成一致导向正确答案的推理轨迹,我们在提示中包含了关于哪些物体消失并不再出现的提示。然而,在最终的SFT数据集中,这些提示被移除了。对于物体恒存性,我们发现将视觉上下文压缩为字幕的标准流程对于提取有用的SFT推理轨迹是次优的。为了解决这个问题,我们从一个Cosmos-Reason1-7B的中间版本中提取思维轨迹。附录A.6展示了一个用于从Cosmos-Reason1-7B引出推理轨迹的样本提示。
5.2. 物理AI强化学习
表5: 用于物理AI强化学习后训练的数据集

虽然微调建立了基础的物理常识和具身推理能力,我们通过强化学习后训练进一步增强了这些能力。这种方法需要有效的奖励机制,我们遵循DeepSeek-AI (2025) 使用经过验证的基于规则和可验证的奖励来实现。与LLM领域如数学和编码——其中正确答案和格式被精确定义——不同,物理常识和具身推理通常涉及自由形式、开放式的响应,这使得奖励分配复杂化。
为了应对这一挑战,我们将我们的推理SFT数据源(不包括思维轨迹)中的样本转换为具有单一正确答案的多项选择题(见表5中的样本数量)。这个转换天生地使得对响应进行简单的、基于规则的验证成为可能。我们的RL后训练数据集包含了来自所有物理AI SFT数据源的样本,其中某些子集——特别是空间谜题、AoT和物体恒存性数据——已经以二元问题格式存在,使其无需修改即可直接适用于MCQs。我们手动验证了用于RL后训练的样本质量。我们下面详细说明各个数据源的具体特征:
物理常识RL数据。 我们从1989个视频中收集了5133个人工标注的二元和多项选择题。为了帮助控制问题的难度,我们使用标注的问题来评估四个模型,包括GPT-4o、Gemini Flash 2.0、Qwen2.5-VL-7B和我们的Cosmos-Reason1-7B模型。根据评估结果,我们进一步将收集的数据分为两个子集:(1) 简单子集,所有模型都答对了问题;(2) 困难子集,至少有一个模型答错了问题。
具身推理RL数据。 我们从每个具身推理数据源中选择200-250个SFT样本,并将它们转换为多项选择题(MCQs)。为确保高质量的RL后训练,我们仔细验证这些样本没有答案和指令上的歧义,同时在MCQ选项中保持平衡分布,以防止潜在的奖励 hacking。这个过程需要一些人工干预,特别是非二元问题,我们必须选择既合理又明显不正确的干扰选项。需要人工参与以确保问题质量,这使得大规模生成MCQ训练数据变得困难。
直觉物理RL数据。 如前所述,我们的自监督直觉物理SFT数据通过设计自然地以MCQ格式存在,使其可扩展以生成多样化的问题。对于这些任务,我们实施了额外的质量保证措施,以确保所有样本中的选项分布均衡。我们仔细避免了与SFT期间使用的剪辑的任何重叠,以防止RL后训练期间的早期饱和。对于RL后训练阶段,我们在空间连续性、时间箭头和物体恒存性任务中策划了24079个高质量样本。
6. 基准测试
我们将在一个专门用于衡量关于物理常识、具身决策推理能力的基准上,将我们训练的模型与其他对应模型进行比较。在本节中,我们讨论构建我们的常识和具身推理基准的程序(表6)。我们通过询问基于视频上下文的二元是/否问题或多项选择题(MCQs)来评估模型。我们注意到,我们的基准通过构建需要推理(才能得出正确答案),并且我们只测量最终答案的准确性。我们将对思维轨迹质量的定量评估留作未来工作。
表6: 我们策划的基准测试的统计数据

6.1. 物理常识推理
我们通过根据第2.1节中定义的本体手动策划关于互联网视频剪辑的问题,构建了一个物理常识推理基准。我们最初收集了5737个问题池,包括2828个二元问题和2909个多项选择题。图8显示了根据我们的本体的问题类别分布。之后,我们经过一个手动过程,仔细挑选了来自426个视频剪辑的604个问题的子集,作为我们的物理常识基准,其中336个是二元问题,268个是多项选择题。在604个问题中,80个(13.25%)关于空间,298个(49.33%)关于时间,226个(37.4%)关于基础物理。
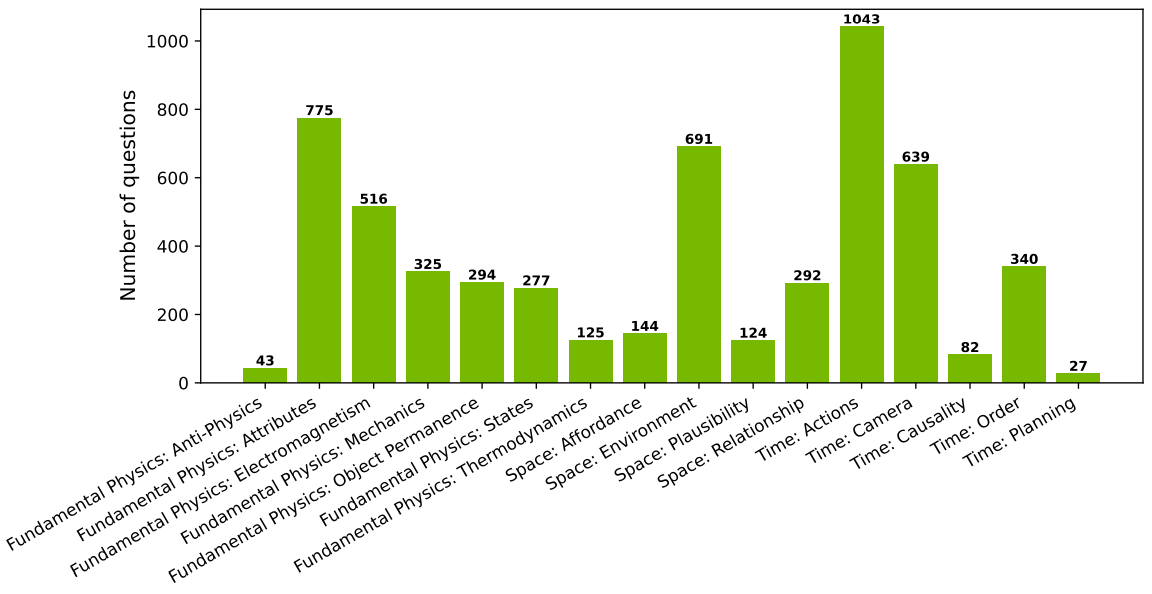
图8: 展示为物理常识基准收集的初始问题类别分布图,该本体定义在表1中。我们从中选择了一个包含604个问题的子集作为我们的评估基准。
6.2. 具身推理
与我们用于具身推理的SFT数据策划流程类似,我们将我们的具身推理基准限制在之前概述的属性上——(1) “任务完成验证”:确定任务或子任务是否已成功完成的能力;(2) “动作可供性”:评估执行特定动作或朝目标前进是否可能的能力;以及(3) “下一个合理动作预测”:识别推进指定目标的最合理下一个动作或子任务的能力。我们将我们的具身推理基准样本以多项选择题(MCQs)的形式呈现,以便在不同模型间进行自动评估。我们采取了几个关键步骤来确保我们的基准对于衡量具身推理能力是有用的。
- 统一的问题模板。 我们采用统一的问题表述格式,以确保推理是基于视觉输入而非文本线索。这种方法还有助于统一动作粒度并减少不同数据集之间的歧义。
- 统一的动作粒度。 我们特别关注动作的粒度。在预测下一个即时动作时,多个选项可能都是正确的。例如,动作“给植物浇水”可能涉及“拿起浇水壶”、“移动浇水壶”和“倾倒浇水壶”等步骤。然而,这些步骤也可以分解为更精细的子动作,如“向左移动”或“向下倾斜”。为了解决这种复杂性,我们使用了一个动作层次结构(Belkhale et al., 2024):我们将原子级别的动作定义为“动作”,更粗粒度的动作定义为“子任务”,以及特定于数据集的任务定义为“目标”。
- 手动优化。 除了这些系统性的解决歧义的方法外,我们还手动优化了MCQ选项。这些修改有助于解决过于相似的选项,通过防止答案仅从文本推断来强制进行视觉推理,并强调整个剪辑的完整上下文而不仅仅是前面的帧。
RoboVQA: 我们从处理过的RoboVQA样本的“val”分割(从SFT训练中排除)中抽样了101个剪辑作为我们的基准。为了进行基准测试,我们只考虑那些对应于验证任务完成(提供的指令是否被成功执行)或可供性(是否可能遵循指令/完成任务)的剪辑和问答对。这些被包含为多项选择的是/否问题。
RoboFail: 除了RoboVQA,我们还从RoboFail (Liu et al., 2023) 数据集中手动策划和标注了100个示例,以创建一个更难的“动作可供性”和“任务完成验证”评估分割,其中样本的难度由以下因素决定:(1) 需要高度观察力的感知或全面的时间上下文处理,(2) 识别阻碍动作执行的物理约束(与RoboVQA中因感知不匹配或无关指令而无法完成动作不同),以及(3) 能够对细微问题进行推理。
BridgeData V2: 我们将BridgeData V2的“val”分割中的视频以与训练集相同的方式分割成剪辑。然后我们抽样100个剪辑来创建100个多项选择的问答对作为基准。在每个问题中,我们提供机器人夹爪被指示在剪辑中执行的任务,并询问在机器人已经完成的动作之后,最合理的下一个即时动作是什么。
AgiBot: 我们从处理过的AgiBot SFT数据中抽样100个剪辑,以生成100个多项选择的问答对。对于每个剪辑,我们额外提供任务信息,并询问给定的子任务中哪个是机器人最可能应该努力完成的下一个子任务。我们从剪辑整个轨迹的子任务序列中随机抽样选项。值得注意的是,这些轨迹被排除在训练集之外。
HoloAssist: 我们从处理过的HoloAssist SFT数据中抽样100个剪辑,以生成100个多项选择的问答对。对于每个剪辑,我们额外提供粗粒度的动作注释作为总体目标,并询问给定的子任务中哪个是最可能的下一个子任务。我们从该粗粒度动作下的其他细粒度动作注释中随机抽样选项。所有包含这些剪辑的34个视频(总共1758个)都从训练集中排除,以防止剧集泄漏。
AV: 我们从专有数据中策划100个视频,以构建100个多项选择的问答对。这些视频展示了多样的横向和纵向行为,以及丰富的互动。问题的设计旨在(1)预测自车最可能采取的下一个即时动作,(2)验证先前执行的动作的完成情况,以及(3)评估在给定场景中特定动作的可能性。请注意,基准中的这些样本被排除在训练集之外。
7. 实验
在本节中,我们说明了物理AI监督微调和物理AI强化学习对Cosmos-Reason1的实验设置,并讨论了我们基准上的评估结果。
7.1. 物理AI监督微调
我们训练Cosmos-Reason1-7B 12.5K次迭代,使用余弦退火学习率从1 × 10⁻⁵衰减到1 × 10⁻⁶。我们训练Cosmos-Reason1-56B 30K次迭代,学习率为1 × 10⁻⁵,随后20K次迭代的学习率衰减为1 × 10⁻⁶。我们对Cosmos-Reason1-7B使用256的全局批量大小,对Cosmos-Reason1-56B使用32。使用融合的Adam优化器,其中β₁, β₂ = (0.9, 0.95),权重衰减为0.1。我们在训练期间遵循平衡的数据抽样策略,以便在SFT期间没有特定的兴趣领域被过度代表。除非另有说明,对于我们的模型,我们报告5次推断的平均准确率(温度0.6和top-p 0.95),使用不同的随机种子。对于评估其他模型,我们采用零样本链式思维提示(Kojima et al., 2022),通过调用它们的API(GPT-4o, OpenAI o1, Gemini 2.0 Flash)或使用它们的开源模型检查点(Qwen2.5-VL)。
7.1.1. 物理常识结果
表7显示了在物理常识基准上的评估结果。与它们各自的骨干相比,Cosmos-Reason1-7B和Cosmos-Reason1-56B在物理常识基准上表现出显著提高的能力56B变体取得了最佳准确率,略微超过了OpenAI o1。这些结果突显了我们策划的常识数据集的有效性,为进一步的RL改进奠定了坚实的基础。
表7: 在物理常识基准上的评估
| 方法 | 空间 | 时间 | 其他物理 | 平均 |
|---|---|---|---|---|
| Gemini 2.0 Flash | 53.8 | 50.0 | 46.9 | 50.2 |
| GPT-4o | 61.3 | 54.7 | 50.9 | 55.6 |
| OpenAI o1 | 63.8 | 58.1 | 58.0 | 59.9 |
| Qwen2.5-VL-7B | 48.8 | 56.4 | 37.2 | 47.4 |
| Nemotron-H-56B | 61.3 | 68.1 | 45.1 | 58.2 |
| Cosmos-Reason1-7B | 54.2 | 58.7 | 50.0 | 54.3 (+6.9) |
| Cosmos-Reason1-56B | 61.3 | 65.5 | 53.9 | 60.2 (+2.0) |
7.1.2. 具身推理结果
表8显示了在具身推理基准上的评估结果。Cosmos-Reason1模型在该基准上取得了比基线模型明显更强的结果,7B和56B变体与它们各自的骨干VLM相比都表现出超过10%的改进。结果表明,我们的物理AI SFT在提升模型的物理AI具身推理能力方面非常有效。
表8: 在具身推理基准上的评估
| 模型 | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | RoboFail | 平均 |
|---|---|---|---|---|---|---|---|
| Gemini 2.0 Flash | 25.0 | 78.2 | 29.0 | 44.0 | 37.0 | 67.0 | 46.7 |
| GPT-4o | 42.0 | 71.8 | 32.0 | 65.0 | 46.0 | 63.0 | 53.3 |
| OpenAI o1 | 42.0 | 80.0 | 44.0 | 63.0 | 37.0 | 61.0 | 54.5 |
| Qwen2.5-VL-7B | 38.0 | 82.5 | 40.4 | 50.0 | 36.0 | 57.6 | 50.8 |
| Nemotron-H-56B | 37.0 | 77.2 | 37.0 | 65.0 | 41.0 | 64.0 | 53.5 |
| Cosmos-Reason1-7B | 58.8 | 83.8 | 49.4 | 63.0 | 55.6 | 60.0 | 61.8 (+11.0) |
| Cosmos-Reason1-56B | 65.0 | 80.0 | 47.6 | 57.8 | 65.8 | 66.2 | 63.7 (+10.2) |
7.1.3. 直觉物理结果
尽管VLM通常被认为是达到超人性能的专家,但我们的研究揭示,许多模型在基础物理推理方面存在困难。为了测试模型理解直觉物理的能力,我们为三个任务中的每一个策划了100个视频:时间箭头、空间谜题和物体恒存性,并根据第5.1.3节的流程生成了100个问题。我们进行了数据去污,以确保与训练数据没有重叠。我们在策划的测试集上评估模型性能。
表10显示,现有模型在时间箭头和物体恒存性任务上难以达到高于随机猜测的水平。值得注意的是,GPT-4o和OpenAI o1在处理空间谜题方面比随机猜测要好得多。这一观察结果表明,当前的多模态模型在推理空间关系方面比时间动态更为熟练。鉴于这些模型通常在像MMMU这样的标准基准上表现良好,这表明现有的评估未能捕捉它们对物理世界的理解。然而,我们策划的直觉物理数据集使7B模型能够在所有三个任务上显著提高,展示了Cosmos-Reason1在直觉物理中进行推理的基本能力。
7.2. 物理AI强化学习
我们用简单的、基于规则的可验证奖励来后训练Cosmos-Reason1,以进一步增强它们的物理AI推理能力。我们总结了我们在物理常识、具身和直觉物理推理任务上的实验发现。
7.2.1. 实验设置
我们采用两种类型的基于规则的奖励来优化我们的模型,使其能够准确地进行物理AI推理:
- 准确性奖励 评估模型的响应(包含在
<answer></answer>标签内)是否与真实情况匹配。由于我们在RL中专门使用MCQs,这个验证可以通过简单的字符串匹配来完成。 - 格式奖励 鼓励模型将思考过程封装在
<think></think>标签中,将答案封装在<answer></answer>标签中。这是通过正则表达式匹配来实现的。
在训练期间,我们以相等的概率从每个RL数据集中抽样,确保在不同领域之间的平衡表示。我们还在运行中动态地打乱MCQ选项以鼓励泛化。我们使用128个问题的全局批量大小,对于每个问题我们抽样9个输出,每个输出的最大长度截断为6144个令牌。我们将学习率设置为4 × 10⁻⁶,KL惩罚项的系数为0.005,并训练模型500次迭代。
[表9: 在物理常识和具身推理基准上的评估]
| 模型 | 常识 | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | RoboFail | 平均 |
|---|---|---|---|---|---|---|---|---|
| Cosmos-Reason1-7B | 54.3 | 58.8 | 83.8 | 49.4 | 63.0 | 55.6 | 60.0 | 60.7 |
| + 物理AI RL | 56.2 | 73.5 | 86.8 | 54.2 | 60.0 | 67.0 | 62.0 | 65.7 (+5.0) |
[表10: 在直觉物理基准上的评估]
| 模型 | 时间箭头 | 空间谜题 | 物体恒存性 | 平均 |
|---|---|---|---|---|
| 随机猜测 | 50.0 | 25.0 | 50.0 | 41.7 |
| Gemini 2.0 Flash | 50.0 | 31.0 | 48.0 | 43.0 |
| GPT-4o | 50.0 | 77.0 | 48.0 | 58.3 |
| OpenAI o1 | 51.0 | 64.0 | 49.0 | 54.7 |
| Qwen2.5-VL-7B | 50.2 | 27.2 | 48.8 | 42.1 |
| Cosmos-Reason1-7B | 56.0 | 85.4 | 82.0 | 74.5 (+32.4) |
| + 物理AI RL | 64.5 | 94.0 | 86.0 | 81.5 (+7.0) |
7.2.2. 物理常识和具身推理结果
对于物理常识和具身推理,我们发现物理AI RL后训练提高了大多数基准组件的性能,除了RoboFail。结果总结在表9中。在SFT和RL阶段,RoboFail上的性能始终具有挑战性。考虑到RoboFail被特意设计为一个手工策划的基准,其中包含测试“动作可供性”和“任务完成验证”的困难真实世界场景,这并不奇怪。该基准的难度源于几个因素:(1)样本需要高度观察力的感知或全面的时间上下文处理,以及(2)可供性问题涉及复杂的物理约束在动作执行中,不像RoboVQA中的那些。
我们将RoboFail上停滞不前的性能主要归因于代表性训练数据不足。这一假设得到了对微调和后训练模型中特定错误模式的检查的支持,这些模式包括:对复杂可供性场景的推理不足,未能充分观察关键视觉细节,以及在遇到细微的分布外问题时过度思考。我们相信,对类似代表性样本的针对性训练将显著提高在这个具有挑战性的基准上的性能。我们特意将RoboFail保留在我们的评估套件中,作为需要进一步发展具身推理能力的宝贵指标。

图9: RL前后有趣的结果。当面对一个模棱两可的问题时,我们观察到在RL之后,我们的模型学会了根据其知识拒绝所有提供的选项。
有趣的是,我们发现通过RL,我们的模型学会了仔细评估所提供的选项,并在问题模棱两可时拒绝所有选项。如图9所示,模型评估了每个选项的可行性,并在出现歧义时采取了不在选项范围内的保守行动。
7.2.3. 直觉物理结果
与自监督学习类似,直觉物理的一个关键优势是数据扩展的简便性。为时间箭头生成训练数据仅需简单的视频反转,空间谜题可以应用于任何图像以创建具有挑战性的空间连续性问题,而物体恒存性可以在任何模拟环境中轻松实现。此外,这些数据源可以无缝地适应于具有可验证奖励的RL训练。通过这个方法,我们成功地创建了一个比常识和具身推理任务更大规模的RL数据集,且人工投入最少。
表10显示,通过精心的SFT数据策划和有针对性的训练,Cosmos-Reason1-7B在所有任务上都取得了显著的改进,而物理AI RL能够进一步增强空间谜题和物体恒存性的能力。然而,关于时间箭头的推理仍然是一个挑战。
通过物理AI RL,我们发现模型在空间、时间和物体恒存性方面的推理能力得到了进一步发展。图10说明了Cosmos-Reason1在RL前后对时间进行推理的差异。模型可以识别反物理运动——例如,粉末 defying(违背)重力上升到碗中——同时不受视频中静止干扰物的影响。这表明其推理超越了单纯的感知。类似地,在图11中,没有经过RL的模型倾向于将空间问题与时间推理混淆。虽然它们可以感知到第二帧与第一帧缺乏相似性,但它们固有的偏见导致它们默认按视频顺序来判断,这表明它们更多地依赖时间线索而非真正的空间理解。带有空间谜题的RL使模型能够从第一帧中提取关键特征,并系统地在多个帧之间进行比较,从而使其能够准确地确定空间关系。最后,图12显示,即使有长链思维(CoT),没有物理AI RL的模型在物体恒存性方面也存在困难,经常在推理物体的出现和消失时感到困惑。相比之下,RL模型通过直接和简洁的推理迅速得出结论。
8. 相关工作
8.1. 物理AI的基础模型
早期将大型预训练模型集成到具身智能体中的方法主要依赖于使用现有的大型语言模型(LLMs)和视觉语言模型(VLMs)作为静态模块。例如,使用LLM作为零样本任务规划器的工作线(Li et al., 2022; Song et al., 2023; Huang et al., 2022; Ahn et al., 2022)直接从预训练的LLMs中提取高级动作计划的自然语言,而无需额外的微调,展示了LLMs在机器人任务中泛化的能力。类似地,Code as Policies(Liang et al., 2022)将LLMs的用途扩展到为机器人控制生成结构化代码。然而,这些预训练模型,特别是VLMs,并非为物理交互而明确设计,因此常常缺乏物理常识理解,并导致次优的计划和执行。
另一条工作线专注于直接为具身智能体端到端地训练视觉-语言-动作(VLA)模型(Brohan et al., 2023; Driess et al., 2023; Kim et al., 2024; Yang et al., 2025; Gemini Robotics Team, 2025)。它们通常从一个预训练的视觉语言模型开始,并用机器人数据对其进行微调以生成具身动作。这种方法在提高机器人任务的泛化性和稳健性方面显示出巨大的潜力。这些方法中一个显著的子类别引入了分层策略表示,将高级的语言驱动规划与低级动作执行分开(Shi et al., 2025; Li et al., 2025)。这些系统通常使用一个高级VLM来解释自然语言指令并生成计划,而低级VLA则执行精细的运动控制。这些分层架构改进了任务和分解。

图10: 在RL之前,模型难以理解和关联感知与反向动作,而RL使其能够跨时间进行推理,同时避免如静止文本等干扰。
最近的努力试图使具身AI具备更强的推理能力。其中一种方法是具身链式思维(CoT)框架(Zawalski et al., 2024),它使机器人智能体能够在执行动作之前通过顺序决策进行推理。这与AI中更广泛的趋势一致,即显式推理机制可以提高可解释性和适应性。类似地,Liu et al. (2023); Elhafsi et al. (2023) 引入了逐步推理的方法来解释和纠正失败。虽然这些方法提升了具身AI的认知能力,但大多数仍然依赖手动提示来构建其推理过程,限制了它们的自主适应和泛化。CoT-VLA(Zhao et al., 2025)引入了一个CoT过程,它首先预测一个未来的图像,然后预测应该与环境互动以实现预测的未来图像的动作。
除了机器人技术,VLA模型还被应用于其他物理实体,如自动驾驶。例如,CoVLA(Arai et al., 2024)为自动驾驶应用引入了一个大规模的视觉-语言-动作数据集,促进了对自动驾驶系统中多模态决策的研究。
8.2. 视觉语言模型
社区在构建视觉语言模型方面取得了长足的进步。著名的模型家族包括Flamingo(Alayrac et al., 2022)、LLaVA(Liu et al., 2023)、InternVL(Chen et al., 2024)、QwenVL(Bai et al., 2025)、NVLM(Dai et al., 2024)、Llama-3.2-Vision(Grattafiori et al., 2024)。这些视觉语言模型通常采用两种常见架构之一:仅解码器架构,如在LLaVA(Liu et al., 2023)和InternVL(Chen et al., 2024)中看到的,它将图像令牌集成到LLM的自注意力层中;以及基于交叉注意力的架构,以Flamingo(Alayrac et al., 2022)和Llama-3.2-Vision(Grattafiori et al., 2024)为例,其中图像令牌通过LLM的交叉注意力层进行处理。Dai et al. (2024)在最先进的设置中比较了两种架构,并发现仅解码器架构在视觉上下文下的大学水平多学科知识和数学推理任务中表现出更强的推理能力。在此基础上,我们采用仅解码器架构来为物理AI开发推理模型。
8.3. 具有推理能力的LLMs和VLMs
早期的研究表明,大型语言模型(LLMs)在数学(Cobbe et al., 2021)、编码(Chen et al., 2021)和一般推理任务中表现出基本的推理能力。这些能力可以通过链式思维提示进一步增强(Wei et al., 2022)。最近,OpenAI o1(OpenAI, 2024; Jaech et al., 2024)证明了LLMs在编码和数学方面的推理能力可以通过大规模强化学习得到显著增强。值得注意的是,开源的DeepSeek-R1(DeepSeek-AI, 2025)与社区分享了其训练方法,为构建高性能推理模型提供了宝贵的见解。然而,现有的研究主要集中在与编码、数学和STEM领域相关的推理任务上(Liu et al., 2024),即使在多模态推理设置中也是如此(Qwen-Team, 2024)。最近,将R1的推理能力集成到VLM中的努力激增(Liu et al., 2025; Zhou et al., 2025; Zhao et al., 2025; Huang et al., 2025; Haonan Wang, 2025)。在这项工作中,我们在物理AI的背景下探索推理能力。
9. 结论
在这项工作中,我们提出了Cosmos-Reason1,一个专门用于物理世界理解和推理的多模态大语言模型家族。为了使模型专注于物理AI,我们定义了本体来封装物理AI模型的基础能力,并相应地构建了用于常识和具身推理的监督微调数据和基准。我们进一步探索了物理AI RL crafting(构建)基于规则、可验证的奖励,并使用强化学习来提高模型在空间、时间和直觉物理方面的推理能力。我们的实验表明,物理AI SFT将骨干VLM在提议的物理常识和具身推理基准上的性能提高了10%以上。物理AI RL进一步将准确率提高了5%以上。通过物理AI SFT和RL,Cosmos-Reason1可以学习现有模型难以掌握的直觉物理,例如时间箭头和物体恒存性。我们将开源我们的代码和模型权重,以加快构建能够理解和在物理世界中执行复杂任务的物理AI系统的进程。