C++学习记录(7)vector
前言
严格来说,我们之前学的string类并不能作为容器,简单来说,我们的string一般就当成顺序表来用了,这个顺序表非常严格,只能用来管理字符序列;除此之外,我们学习string类的时候可以注意到,好多库里面的接口都与c-str有关,也就意味着string和我们C语言是紧密联系的。
最好的类比就是我们买的马克杯,倒里面点水没毛病,你不能说倒点茶就不允许,倒点咖啡饮料就不可以,string就好像限量版容器一样,非常挑剔。
带着这样的认知,我们来学习STL里真正意义上的容器之一vector。
一、vector的简单认知
1.阅读库里的vector
vector的中文释义其实各位非常熟悉,那就是向量、矢量。其实我个人不太理解为什么一个容器以这样一个单词命名,不过对于学习编程不是重点。
vector在库里的描述是这样的:

我大致阅读了一下,大致得到了这样的几个特点:
- 库里的vector实际上是个类的模板
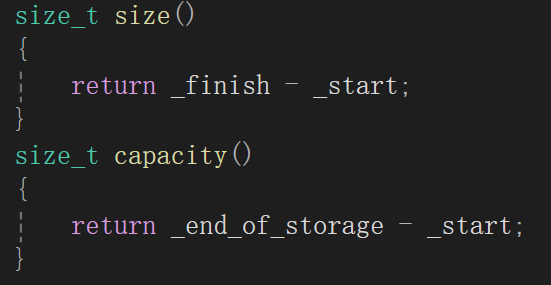
- vector的数据其实是以顺序表的方式管理的,即我们熟悉的数组指针,size和capacity控制
- 谈到顺序表,可以看到大篇大篇介绍了vector的内存开辟和释放的特点,以及扩容
- vector可以以数组的形式来遍历,也可用STL的标准接口-迭代器iterator来实现(当然,如果用现代的编译器范围for这些也是支持的)
最重要的就是vector是类的模板,可以通过制定类型来创建独立的类来存储和管理数据,做到了真正的泛型编程,这才符合容器的特点。
vector其实感觉和string的那些管理内存和遍历的方式差不多。这点其实在下面就能清楚的看到。
2.成员类型
![]()
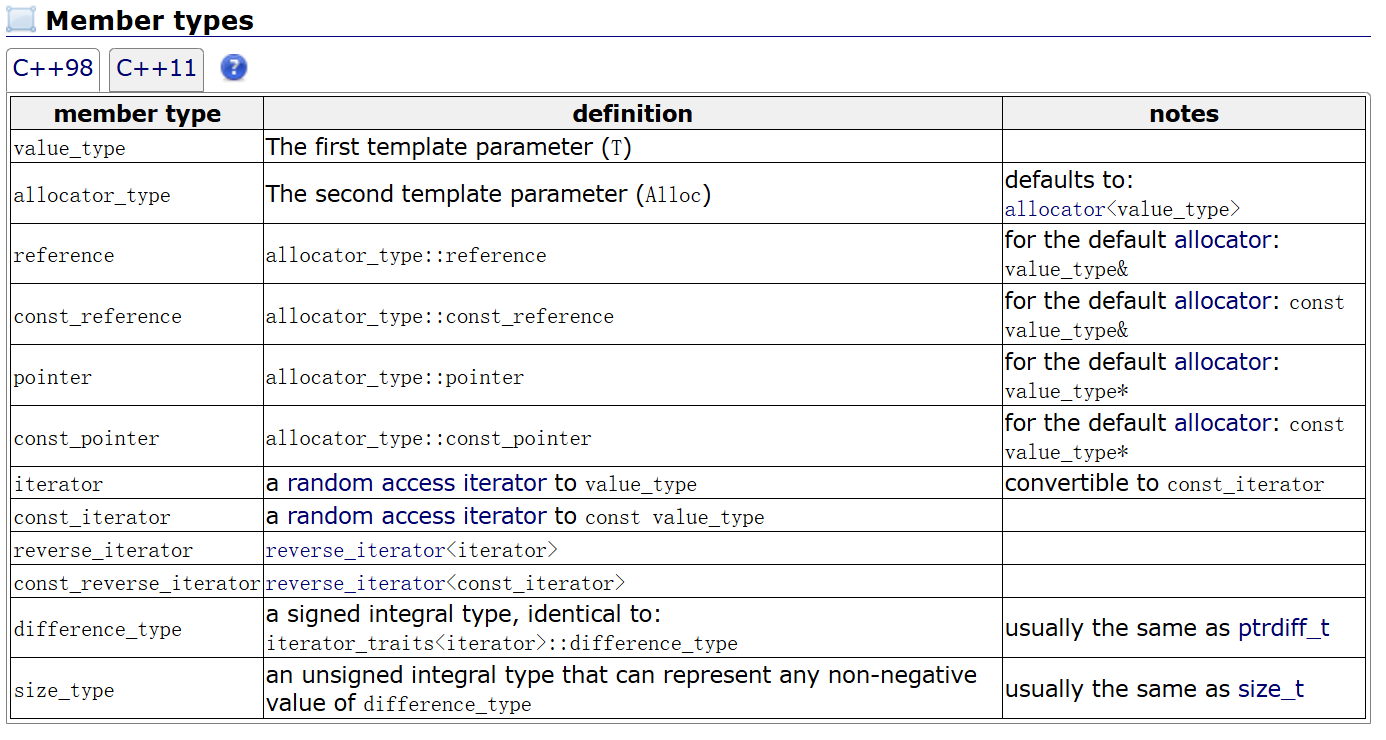
vector是个模板类嘛,所以如果给模板类传参应该传什么?
传类型T,当然,类型包括内置类型和自定义类型,value_type就是T,或者说value_type是T的别名。
allocator_type这个参数不太用管,比如看到模板的第二个参数:
![]()
第二个参数大致上就是一个类来管理内存,也就是我们说过的内存池,因为STL需要频繁的申请和释放内存,所以就创建了个内存池供它们使用,还是类比大学生向爸爸妈妈要生活费理解,不多解释。

这仨不太用管解释,直接看注释:
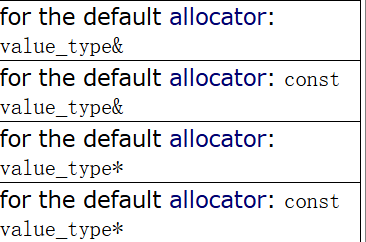
一眼懂。

这几个同样道理,类比string类是什么?iterator迭代器。
剩下的不多解释,而通过大致看成员类型对vector有个基本上的了解了,下面来学习vector的接口。
二、vector接口的认知与学习
1.简单看看所有的接口
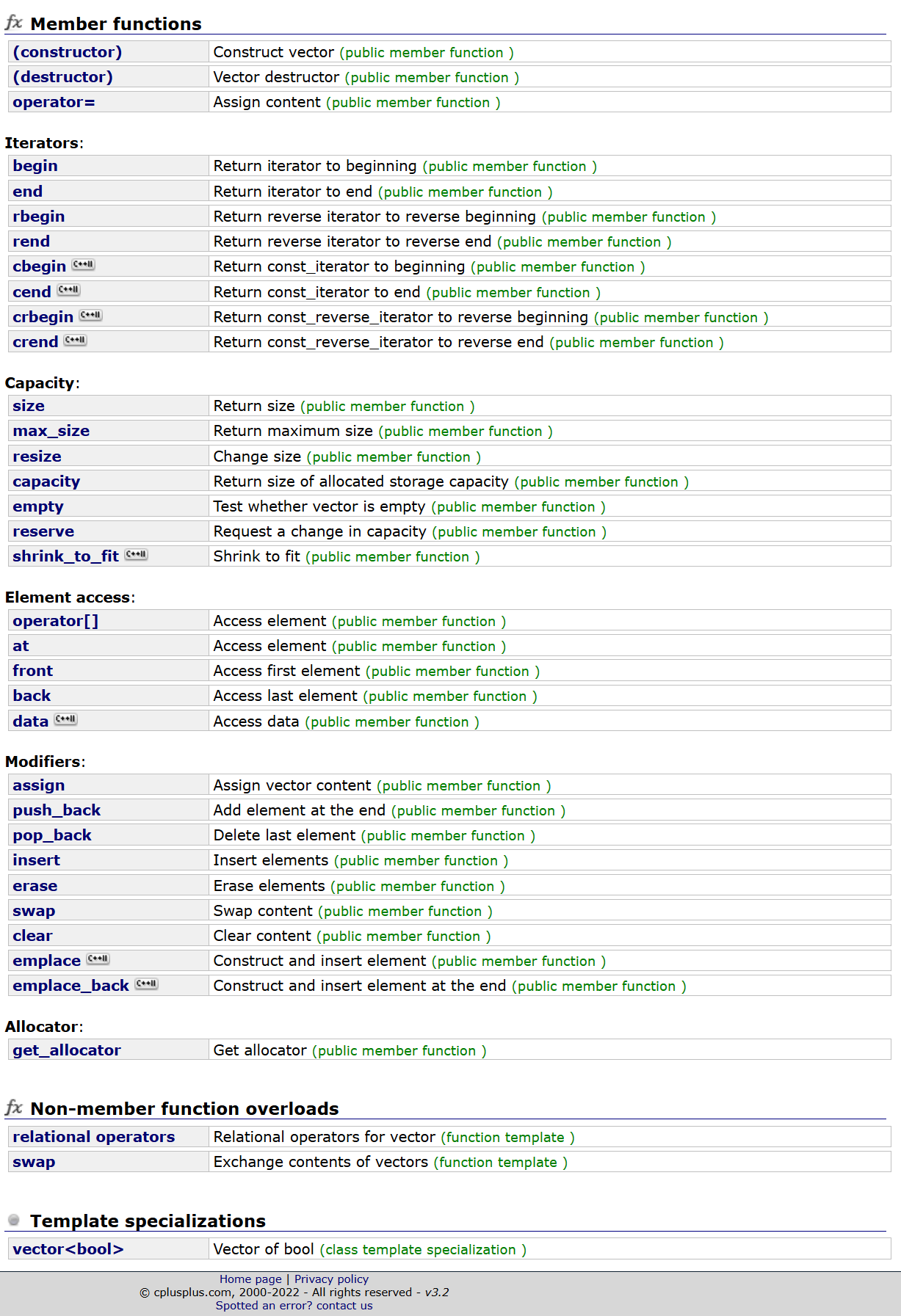
现在我们可以说还没开始学vector呢,大致上浏览就发现了很奇特的现象:
构造析构不多说,既然vector是个类,而且还有内存的申请,那肯定少不了构造析构函数、
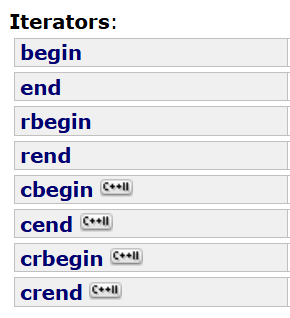
iterator的接口:begin和end,rbegin和rend等等,和string类的完全一样啊。
然后再看与capacity有关的,size、max_size、resize、capacity、empty等等,看起来好像跟string大部分一样啊。
剩下的也不多说了,其实很明显就能看出来vector大部分接口和string是存在高度类似的。
其实这样是STL设计的理念之一,即只要学了一个容器,其它容器基本上全部都掌握了,因为接口在设计上保证高度一致性,这样克服了我们C语言阶段一个问题,一千个人心中有一千个哈姆雷特,就拿扩容来说,有的人可能写个reserve,有的人就写extend,毕竟这些接口的设计完全取决于程序员自己的喜好和认知,这样就会给接手程序的人带来了很大的麻烦。
2.构造函数

就先说一个点:
![]()
这个参数我们一般就直接不管,原因很简单,默认库里面给我们提供了设计好的内存池,用的时候你也不用给,毕竟是缺省值嘛,现阶段直接无视这个参数就行,可以说我们现在才初识STL容器,难道你现在就想自己设计内存池用吗。
所以接下来的情况就简单了,如果什么都不传:

就会创建一个空的vector

传个n和val,最底层的数组就会用n个val初始化

传迭代器以这个迭代器范围的值初始化[first,lasr)。
![]()
拷贝构造,这个根本不用多说。
3.析构函数

其实也不用想个啥,大概率就是把底层申请的动态数组给释放了,然后全部置空。
4.iterator
直接看测试代码吧,iterator依旧是:
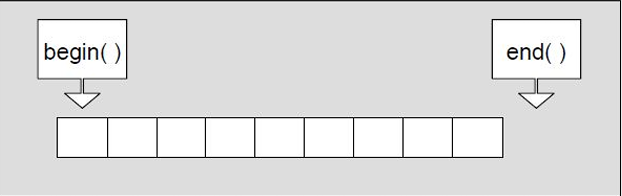
所以其实不用多讲。
int main()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << ' ';}cout << endl;vector<int> v2(10,1);vector<int>::iterator it1 = v2.begin();vector<int>::iterator it2 = v2.end();while (it1 != it2){cout << *it1 << ' ';it1++;}cout << endl;vector<int> v3(v1.begin(),v1.end());for (auto e : v3){cout << e << ' ';}cout << endl;vector<int> v4(v2);for (auto e : v4){cout << e << ' ';}cout << endl;return 0;
}虽然临时调了一下push_back和size两个接口,但是由于接口的设计,其实我们写代码和读代码都没什么压力。
这段测试代码分别把我们常见的构造也展示了一下:
刚开始默认构造,什么玩意都没有,创建了个空的v1,通过push_back使得v1存储下来1 2 3 4,我们采用类似于数组的形式遍历打印。
创建v2的是时候用的是n个val填充,遍历是显式通过迭代器来遍历,也不用多说。
v3用的是v1这个对象的迭代器的始末,也就是纯复制v1的值,采取范围for打印,当然,其实我们也十分清楚,底层范围for会根据提供的可迭代对象调用其对应的迭代器去遍历。
v4调用的是拷贝构造复制的v2的值,至于打印方式还是用范围for,毕竟这玩意写起来最不用费脑子了,内置类型的直接无脑写就行。
5.capacity
①size
这个接口真就不多介绍了,这个接口![]()
返回的是有效元素的个数。
真的非常非常熟悉了。
②max_size
还是说,这个接口是一个无用的接口。

返回这个vector最多能够返回多少个有效元素个数。
其实输出的都是固定的值:

在string类我们已经熟知这个接口就是个无用的接口了,为什么在这里还非得再拉出来说说呢?
我还是想再强调一下一个认知:
我们在C最开始学习指针的时候说过,指针其实就是个地址,什么地址呢,以一个字节为单位的地址。
我们还说过32位系统和64位系统的区别是什么呢,是地址总线的不同,地址总线是专门用来管理地址的线路,如何理解呢?(下面的讲解以32位为例)
电脑根据电信号的有无代表1/0,而32位的地址的物理上就是这样1/0的电信号一共有32个,不同的电信号的排列组合就组成了所有的地址。
所以平常我们算指针变量的大小的是就是依据这32个1/0,相当于32个bit位,如果存储这样的地址就需要4个字节;同理64位指针大小就是8个字节。
假如说我们现在有一个vector<char>,它maxsize也还是这个值1073741823,如果这么算的话,一个char存储需要一个字节,那么这么多个char就需要:

大约一个G的空间来存储,实际上一个程序哪能给你这么多的空间,所以这个空间也只是理论上一个vector<char>可以使用的大小,如果换成更大的类型甚至是自定义类型,直接把内存申请干涸了。
为什么提上面这两点呢,之前我计算32位操作系统的大小的时候经常这么算:
0x11111111~0xffffffff这都是指针嘛,所以内存就应该是一个地址多大*总个数。
我这个时候老是犯迷糊,怎么算呢?
一个地址4个字节大小,多少个地址呢?个。
我这么一算:byte = 1GB,所以内存大小应该是4*
/
,该是16GB的,这个时候我上网一搜:

给我干蒙了,我的电脑不是跟人家一样的嘛,咋地,还给我夹带私货嘛,当然不是,其实我迷瞪过来以后发现道理也很简单:

其实一个地址应该是1字节,一共个,只不过存这个地址需要4个字节(32位下)。
所以再次回顾max_size这个接口多么无能,一共就4个G,你存的char可以说用的内存最少了,就这你就向操作系统要1个G,计算机这个家又不是只有你一个堆区,好事都让你占了,我们其它区还活不活,你干嘛呢想,存的更大你岂不是想上天。
③resize

resize函数是用来修改有效数据个数的。同string
从底层简单想想,底层是个顺序表,如果n比现在的size要小,直接让顺序表的_size--就行,这就是函数介绍说的只保留前n个数据,因为这样最高效;如果n比现在的size要大,且第二个参数val被指定了,多于n的数据就用val尾插补齐。
当然,缩小就不说了,如果扩大肯定要检查需不需要扩容,这个道理不用多说。
④capacity

不必讲解了。
⑤empty
判断vector是否为空,还是从底层,直接看_size是不是0就行。
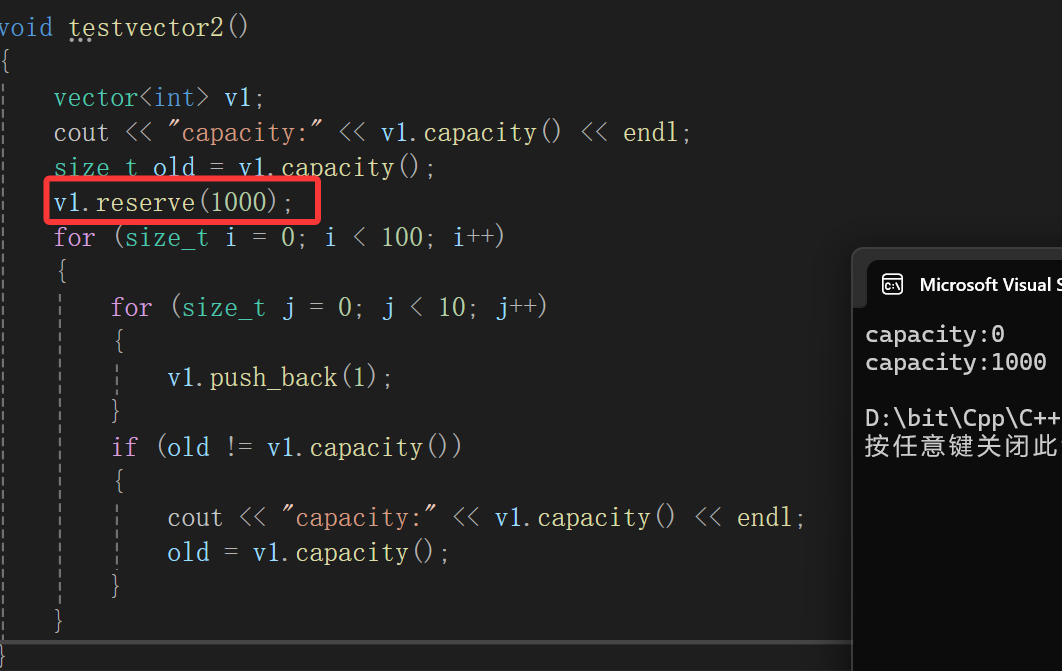
⑥reserve
虽然我们非常熟悉了,提前申请空间,或者用来增容用。

但是毕竟学了一个新类型,不妨展示一下:
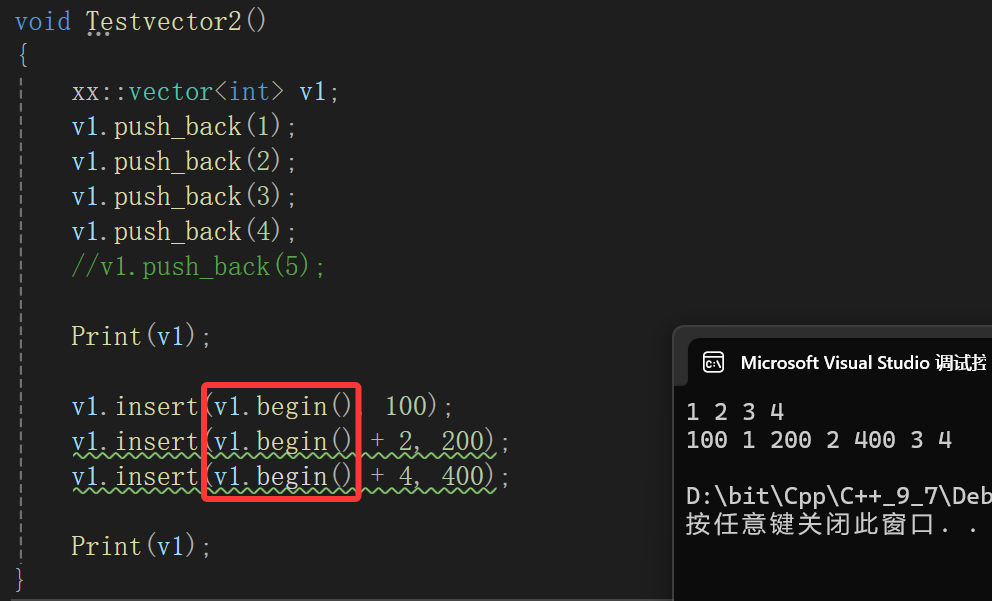
void testvector2()
{vector<int> v1;cout << "capacity:" << v1.capacity() << endl;size_t old = v1.capacity();for (size_t i = 0; i < 100; i++){for (size_t j = 0; j < 10; j++){v1.push_back(1);}if (old != v1.capacity()){cout << "capacity:" << v1.capacity() << endl;old = v1.capacity();}}
}有这样一段测试代码,输出结果是:
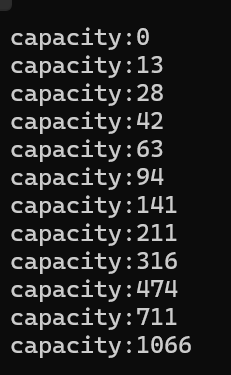
基本上VS还是1.5倍扩容,因为我们每次插入10这点越后面越能体现。
我们有string的经验知道,C++没有realloc只能new一块要求的大小的地址,再拷贝,我们知道这不仅会造成空间的反复申请释放的碎片化,还会浪费很多时间,所以一般这个时候reserve一登场:
⑦shrink_to_fit

一般不推荐用,因为还是涉及到内存的申请和释放,最终缩容到最小能够容下size个数据的大小。
6.访问
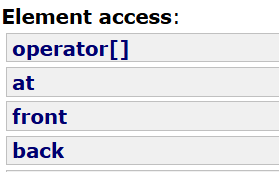
运算符重载依照类似于数组的形式访问;
at函数可以输入pos,最终返回pos位置数据的引用;
front返回vector的第一个数据的引用;
back返回vector最后一个数据的引用。
7.data

据库里的意思,data这个函数返回的是底层管理的数组的第一个元素的地址。
库里的测试代码:
void testvector3()
{std::vector<int> myvector(5);int* p = myvector.data();*p = 10;++p;*p = 20;p[2] = 100;std::cout << "myvector contains:";for (unsigned i = 0; i < myvector.size(); ++i)std::cout << ' ' << myvector[i];std::cout << '\n';
}走读代码就是开辟了5个int大小的vector,将第一个元素放成10,第二个元素方程20,第二个元素往后偏移两个数据也就是第四个元素放成100。最后遍历打印:

8.插入删除操作
①push_back和pop_back
这哥俩不用多说,简简单单的尾插尾删。
②insert和erase

 本来不想多说,但是需要注意的是,在vector的insert和erase中,绝对不能搞pos下标来来选择目标位置的插入,可以看到所有能代表位置的参数全部都是iterator。
本来不想多说,但是需要注意的是,在vector的insert和erase中,绝对不能搞pos下标来来选择目标位置的插入,可以看到所有能代表位置的参数全部都是iterator。
③clear
清空vector,真不用多说,因为很明显就是个无参函数,而且底层大概率就是个_size = 0。
9.swap
库里面的swap直接就能调用,传过去两个vector即可:

10.relational operators

其实逻辑运算符大体上差不多,实现个==,先判断大小相同不相同,相同再判断对应位置的每个字符是否相同。
<就是依次一个一个比,啥时候碰见值小的就返回对应的bool值。
三、vector扩展学习
1.vector与string类对比
可能了解了这么多vector以后,就会有人蠢蠢欲动了,因为vector可以用来存储任意类型的变量,所以char肯定也被包裹在其中,为何不用vector<char>来代替string呢?
其实基本上每个类都有它存在的必要性,比如就从最简单的构造串开始,string类支持c-str初始化,但是如果是vector的话只能是一个一个读取,而且string类最终在字符串末尾会补\0,如果是vector的话,还必须手动+\0,并且很容易想通,vector里的\0也会当成有效数据记入size,那么capacity很明显也会被改变。
而且很容易可以知道,字符串有追加的操作,vector的追加是什么呢?所以+=就更不可能去实现了。
就简单分析分析,目的是不要动歪心思,能用string用string,能用vector用vector,不要驴唇不对马嘴。
2.构造函数扩展
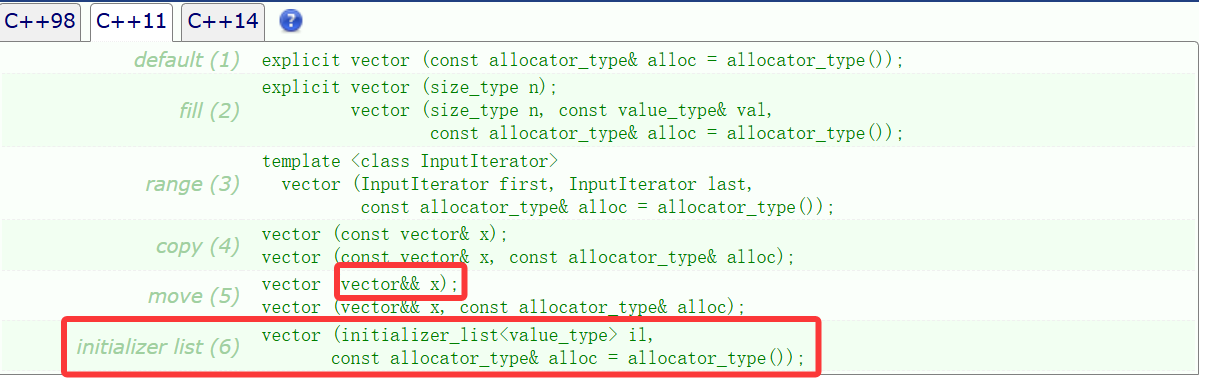
在上面我们学习的是C++98的vector的构造函数,在C++11中新增了两种,不过move那种就先不说,因为这就又涉及到C++11里的右值引用。
重点是最下面的那种构造函数:

第一个参数是干嘛的啊,啥叫initializer list,一看就是个麻烦的类,但其实还好,如果直接翻译的话就是初始化列表,诶,咋弄的跟构造函数内部的初始化列表一个名字呢?
带着疑惑和不解我们跳转到这个类里阅读阅读到底是什么意思:

对于这玩意的了解大概有两点:一个就是理解到底什么是initialieze list类,或者说这个类是用来干什么的。一个就是如果构造函数使用初始化列表作为参数有什么用。
看文字读文章可能是大多数人都不愿意干的事,特别是现在短视频横行的时代,所以我们上来稍微看点文字直接看使用:
一样望过去,库里对这个类的描述就是,这个类的对象是用来存储一列数据的,类似于数组的样式给它初始化即可。
用起来就是:

cout这句不用多在意,我上网查的,这样用可以确定对象或者类型的这种真正类型,可以看到用auto确实方便,直接代表那么长一段单词。
前面我们说过,数组是不能用auto[]来定义的,那是不是意味着{}的数据就不能被auto接受了,现在就看到了,直接用列表来接收就可以。
大致了解一下是啥东西,咋用就行,重点还是看看vectorC++11增加的构造函数里到底干嘛的:

叽里咕噜说一大堆,意思就是可以吧初始化列表当成参数放到构造函数里,这样就支持用初始化列表初始化对象了。
等于说这样呗:
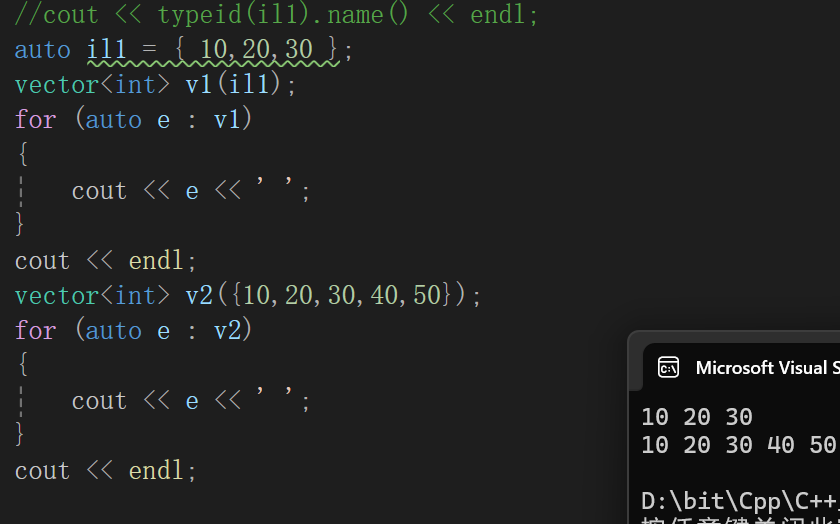
直接参数里传个类似于数组的东西,其实是调初始化列表类型的构造函数。
但是一般我们肯定不太喜欢这样构造,看着奇奇怪怪的,其实我们更喜欢:
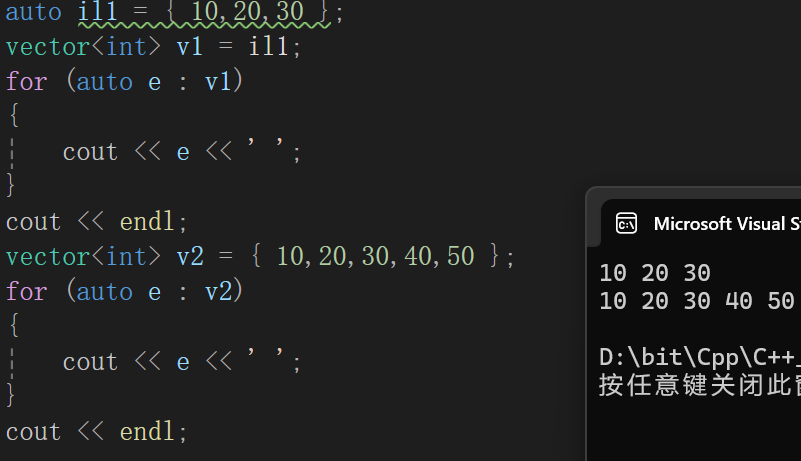
在C++学习记录(2)类和对象-CSDN博客学习的时候我们说过这样的事:

这里其实同样如此,有对应的单参数构造函数
我们知道赋值基本上得两边类型相同或者说可以转化,这里就是有初始化列表为参数的构造函数,所以会隐式调用构造函数来创建一个vector的temp对象,然后调用拷贝构造将这个临时的temp对象传给现在构造的vector对象。
底层是这样的,而我们用起来最直观的感觉就是传一组数来初始化vector,可以说是非常舒服了。
目前肯定是无法完全讲清楚这些玩意的,但是了解以后用,肯定是非常不错的,否则按照C++98的构造函数你想创建这样的一个vector,你必须废了八劲的调push_back,或者只能用n个连续的值初始化,达不到我们的目的。
3.emplace和emplace_back
在上面我们没有展开将emplace和emplace_back这两个玩意。
原因其实和构造函数扩展的那个初始化列表初始化道理一样,因为都是C++11的新增语法,但是非常有用,所以不得不在这里扩展学习,后面会系统学习C++11甚至C++17、C++20的内容,目前仅作使用了解。
原因很简单:


右值引用这个玩意是C++11的东西。
目前阶段就把emplace当成insert,把emplace_back当成push_back使用。
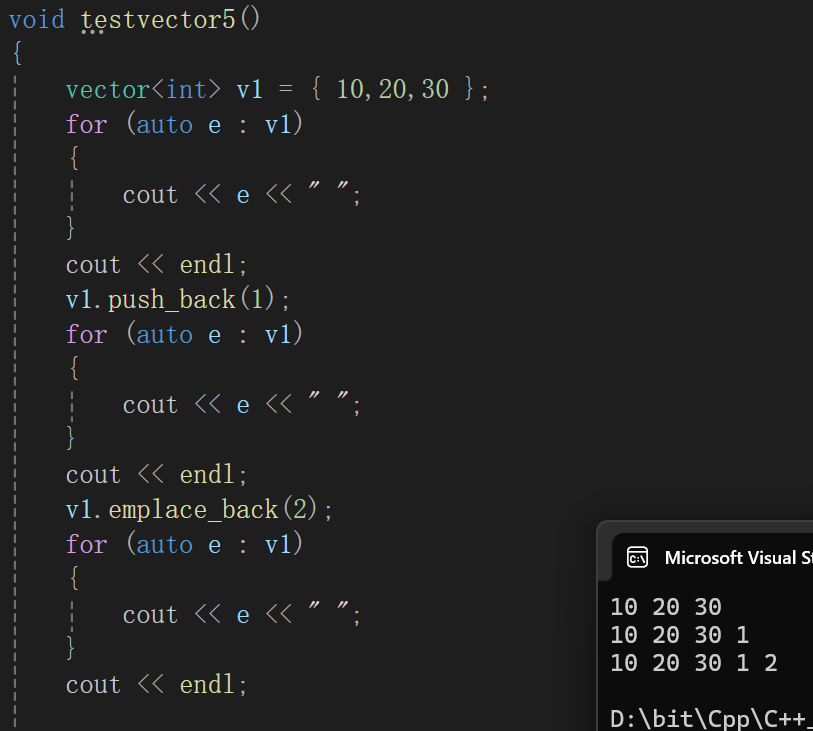
既然一样我用push_back也行,非得用个这干啥,因为差别不在这。
比如有这样的一个类型:
struct A
{A(int a1,int a2):_a1(a1),_a2(a2){}int _a1;int _a2;
};
这几种push_back没毛病吧,刚说emplace_back和push_back当成一样的用:
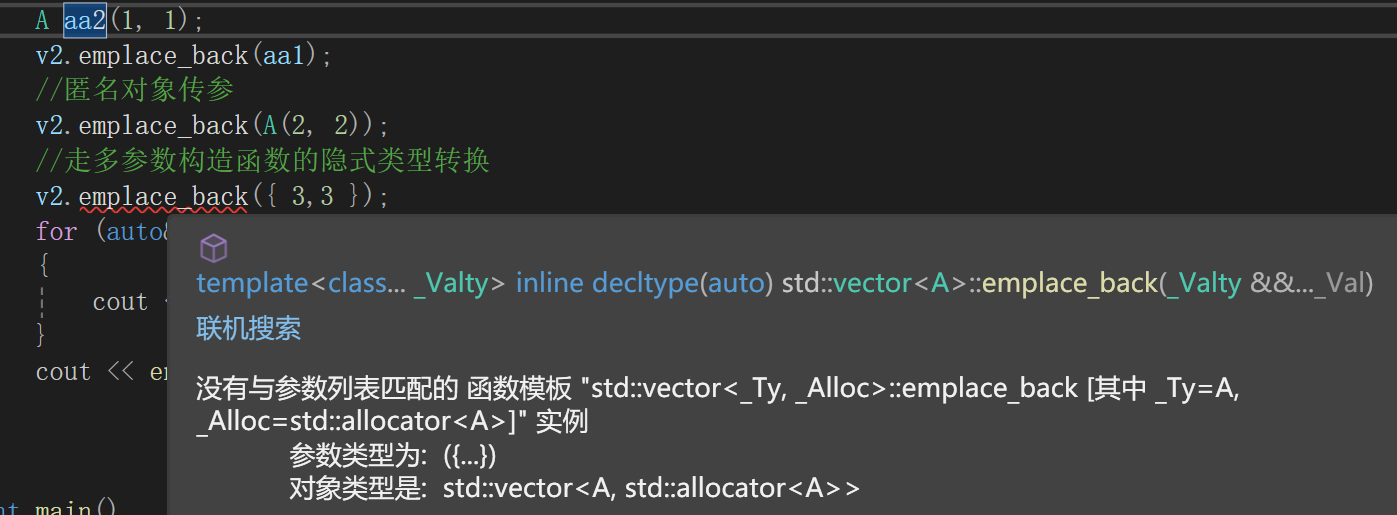
结果最后一种告我说不能用,说是没有你这样的参数。
主要还是emplace_back的参数的问题,其实它给的参数是可变参数,可变指的是参数的的长度可以改变,一般是这么用的:


我们不聊怎么实现的,就说这玩意整的也是让人看起来好像就是直接插入了3,3一样。
不仅如此,如果我们使构造函数的调用显示出来,并补个拷贝构造:
struct A
{A(int a1,int a2):_a1(a1),_a2(a2){cout << "A(int a1,int a2)" << endl;}A(const A& aa):_a1(aa._a1), _a2(aa._a2){cout << "A(const A& aa)" << endl;}int _a1;int _a2;
};调试一行一行看:

创建对象调用构造没毛病。

执行push_back的时候怎么说呢,其实我们库里的push_back传的是引用,只不过push_back实质上拷贝了一份在底层,因为开空间复制其实相当于把拷贝构造代码写了一遍,底层直接调拷贝构造了。

匿名对象走的更多了,走了构造不用说,底层多走了一层拷贝构造才把这个匿名对象又拷贝构造到v2上。
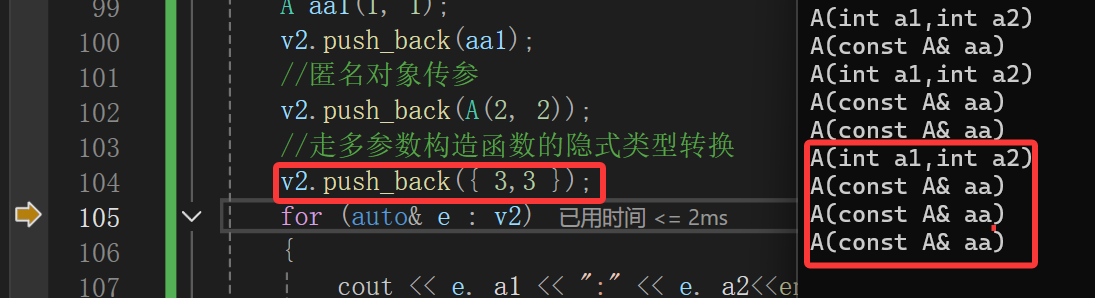
走的更多了,我们不说底层到底咋实现的。
目前代码是这样:
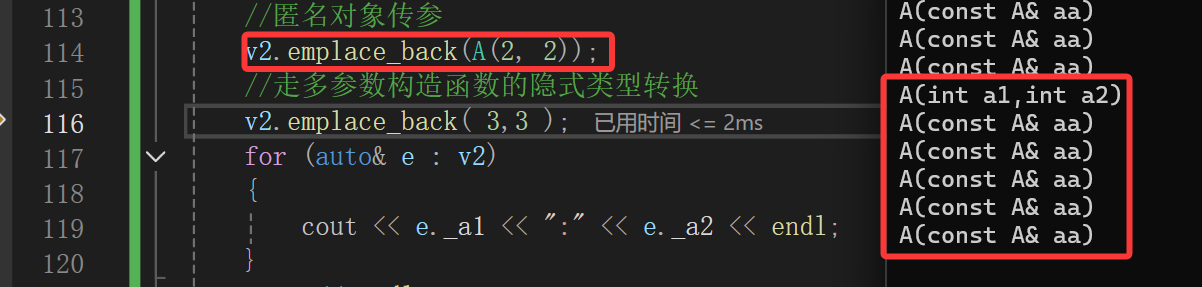
接下来再看看emplace_back的表现:
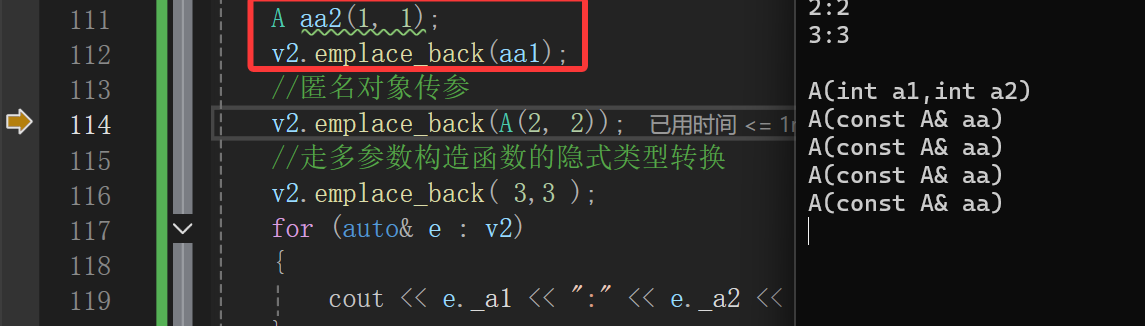
构造和一大堆的拷贝构造。
构造和更多的拷贝构造。
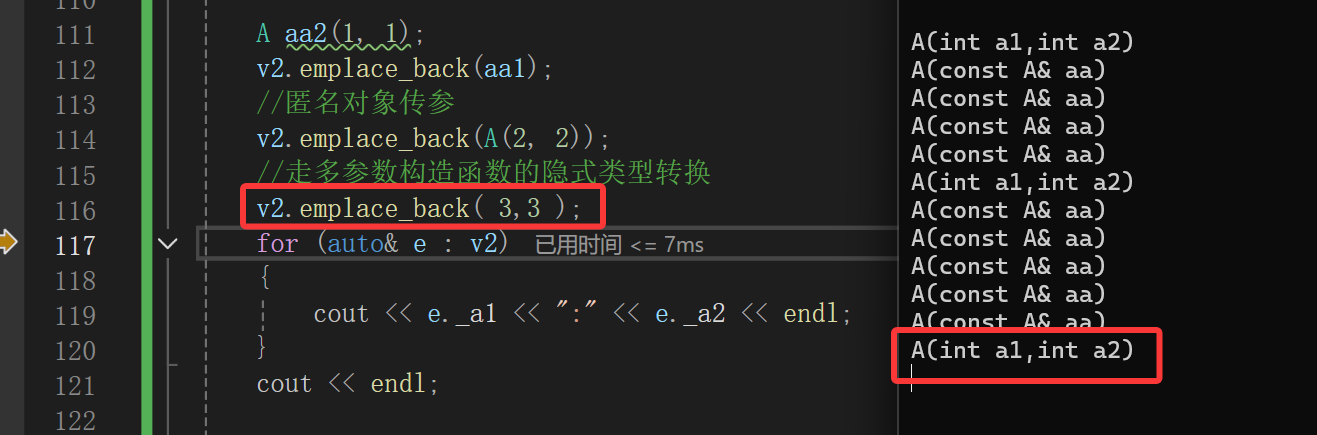
只走构造。
综上,对于自定义类型我们肯定更喜欢直接隐式类型转换去构造,而emplace_back支持多参数的隐式类型转换,并且会优化成直接在底部构造,所以对于自定义类型的话推荐用emplace_back的隐式类型转换,最省事效率最高。
4.C++17结构化绑定
C++17支持一种特定的语法格式:允许你像拆快递一样,将复合类型的多个成员绑定到多个独立的对象上:
如:
int arr[3] = {1, 2, 3};
auto [x, y, z] = arr;
// x=1, y=2, z=3结构化绑定主要适用于以下三种类型的对象:
数组、元组、所有非静态数据成员均为public的结构体或类。
我们这里提出来就是跟emplace和emplace_back那里的struct A的遍历打印提供一种更新的遍历方式:
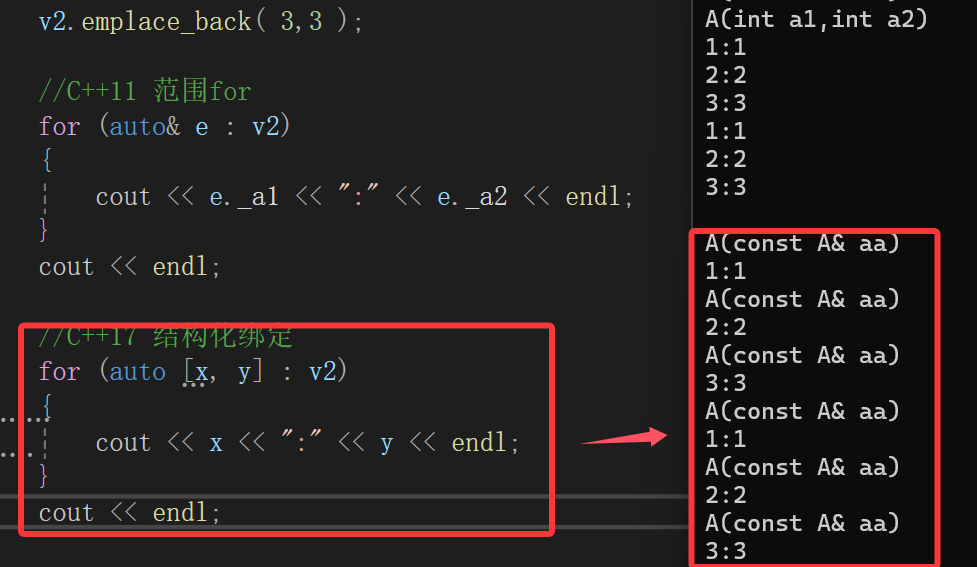
底层也能一眼看出来,相当于范围for的升级版本嘛,还是底层用迭代器遍历,每次遍历拷贝一份赋给auto的变量,但是由于多了个结构化绑定,就会把A类型(public成员变量)拆到x和y里。
由此又说明,引用的重要性,如果直接传就会造成拷贝也就调用拷贝构造,所以还是推荐没事就传引用:

四、实现vector成员属性
如果我们自己写vector很容易写出来:
namespace xx
{template <typename T>class vector{private:T* _arr;size_t _size;size_t _capacity;};}因为我们自己写个测试代码不讲究那么多,直接using namespace std;直接写vector的话会造成冲突,所以写个命名空间包起来。
依据顺序表的经验,很容易就能写出来这三个成员变量,但是:
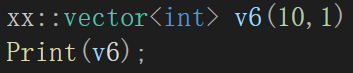
我们阅读了SGI版本大概0几年的版本,里面vector的设计大概是这样的:

第一个头文件大概是算法的,第二个大概是内存池相关的,而最下面的一个应该就是vector的实现。
而所有的vector的实现都在stl_vector这个头文件中:



等等一系列函数。
有的人就会问了,咋把实现文件全扔头文件里了呢,干嘛呢?
这里暂时不多说原因,简单一句结论,那就是模板不能声明和定义相分离,必须一股脑把所有的操作扔到头文件里。
不管是类模板还是函数模板都是如此,而vector既然作为容器,就应该也是类模板,因此关于vector的所有操作实现直接一股脑扔头文件即可。
回到最开始的问题,所以我们成员属性就不再写成

而是模仿SGI版本的vector实现(当然,我们实现大部分操作肯定会稍微简单于)

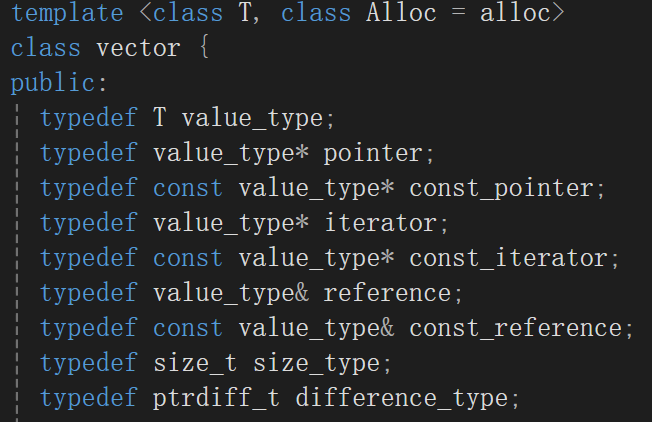
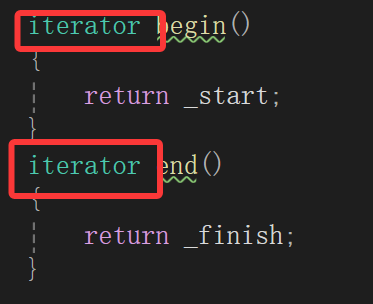
至于iterator其实就是value_type*而value_type又是T,所以简单来说,其实iterator都是T*。
start指的是第一个有效数据的地址;finish指的是最后一个有效数据地址的下一个位置,也就是我们之前一直认为的size位置;end_of_storage则是指向空间的末尾,论相对于start偏移量则就是capacity的位置。
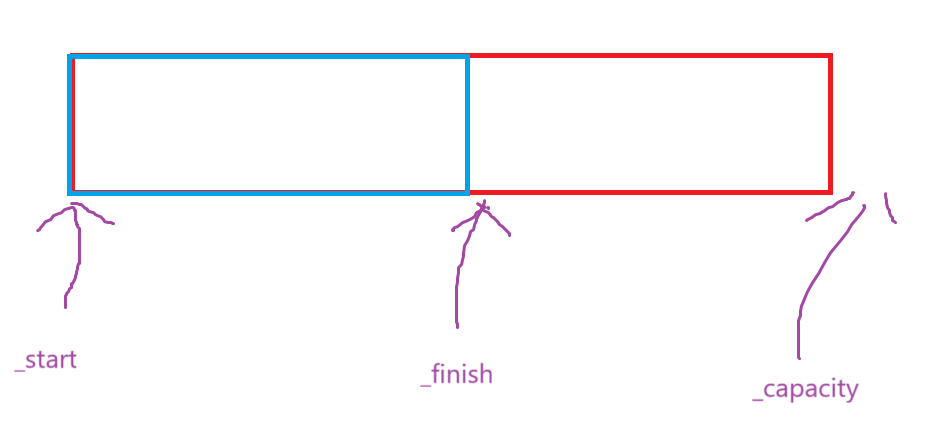
故而准备工作为:
template <typename T>class vector{public:typedef T* iterator;private:iterator _start;iterator _finish;iterator _end_of_storage;};五、vector相关操作的实现
不太想分点,因为基本上环环相扣就写出来了:
1.默认constructor、push_back、reserve、size、capacity、iterator、const_iterator、operator[]、begin、end、pop_back、empty
上来啥道理咱都不说,构造函数总得干出来吧:
//构造函数vector():_start(nullptr),_finish(nullptr),_end_of_storage(nullptr){}就简单写个默认构造函数。
想做出来最简单的,创建完vector你总得让我push_back然后遍历吧,所以先完成push_back:
void push_back(const T& x){//扩容if (_finish == _end_of_storage){reserve(_start == nullptr ? 4 : 2 * capacity());}*_finish = x;_finish++;}但是发现push_back的讲究实在是太多了,想完成push_back得先保证申请的空间大小够用,所以就写一个reserve函数:
void reserve(size_t n){if (n > capacity()){T* temp = new T[n];if (_start)//不为空就得拷贝后释放{memcpy(temp, _start, size());delete[] _start;}_start = temp;_finish = _start + size();_end_of_storage = _start + n;}}可以看到为了实现个reserve函数还得:
size_t size(){return _finish - _start;}size_t capacity(){return _end_of_storage - _start;}push_back这一系列干完,我们vector遍历要不然[]遍历,要不然迭代器(或者说范围for)遍历,为了便利实现[]重载或者实现迭代器接口:
//访问T& operator[] (size_t pos){assert(pos < size());return *(_start + pos);}const T& operator[] (size_t pos)const{assert(pos < size());return *(_start + pos);}iterator begin(){return _start;}iterator end(){return _finish;}const_iterator begin()const{return _start;}const_iterator end()const{return _finish;}真是为了一瓶醋包了一顿饺子,为了写个push_back就补了一大堆的size capacity reserve函数,为了弄个遍历也是呼呼搞了好几个迭代器和运算符重载。
void Testvector1()
{xx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;for (auto e : v1){cout << e << " ";}cout << endl;
}结果我处心积虑写了这么久直接:
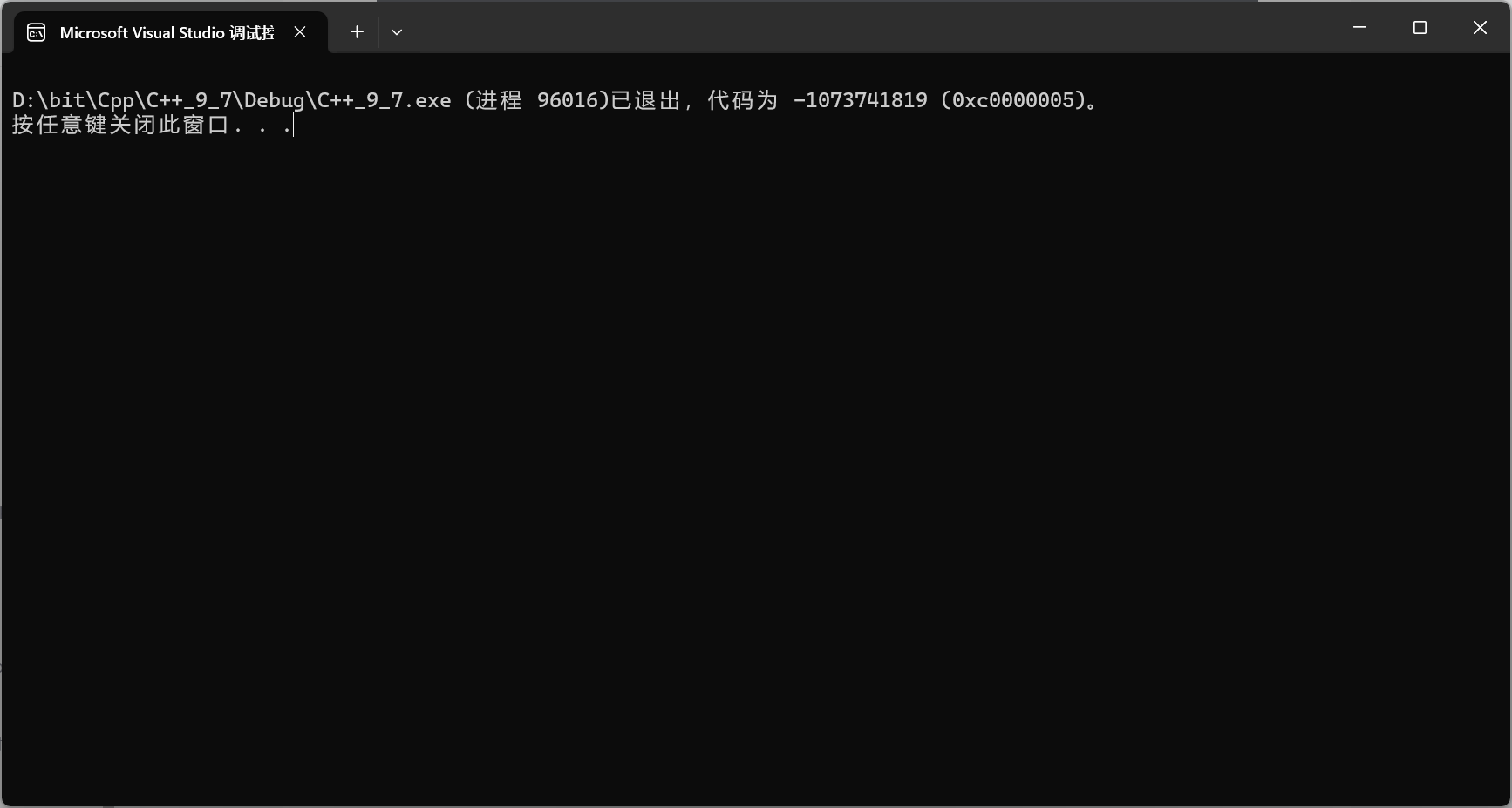
感觉也没地方有毛病,只能说好好调试看看到底哪里出问题了:

构造没有毙。
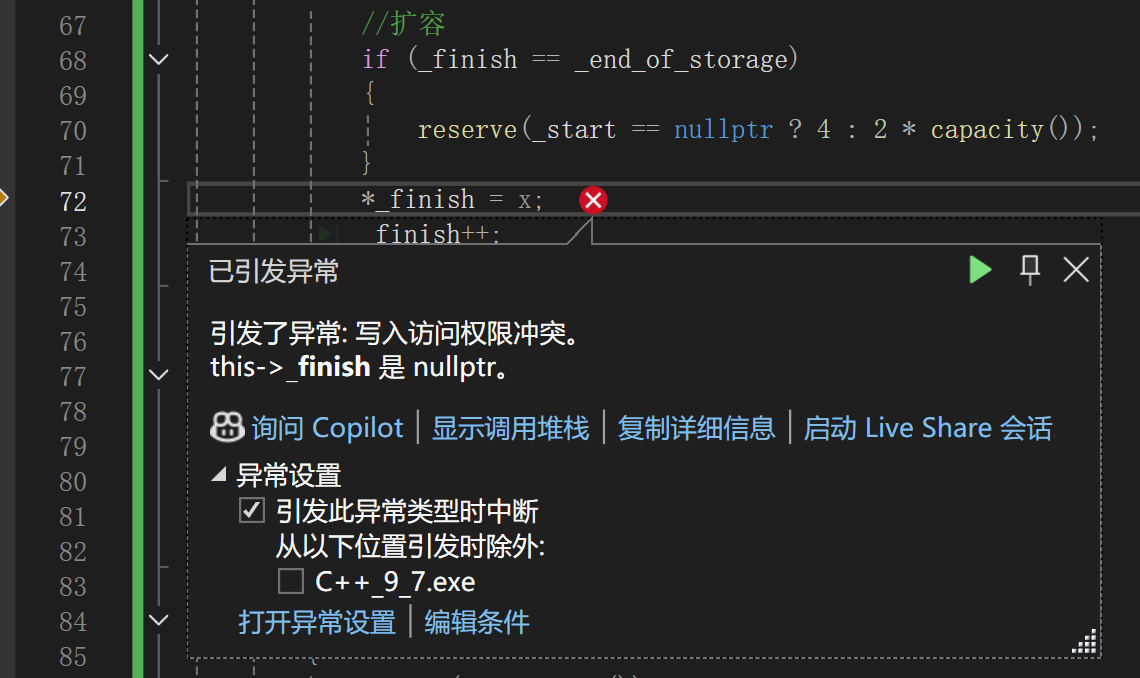
往下push_back了一下就炸了,等于push_back内部有问题了,但是仔细一看他说的是空指针的解引用,啥玩意,等于我开空间开出问题了吗:
这次慢一点调试:
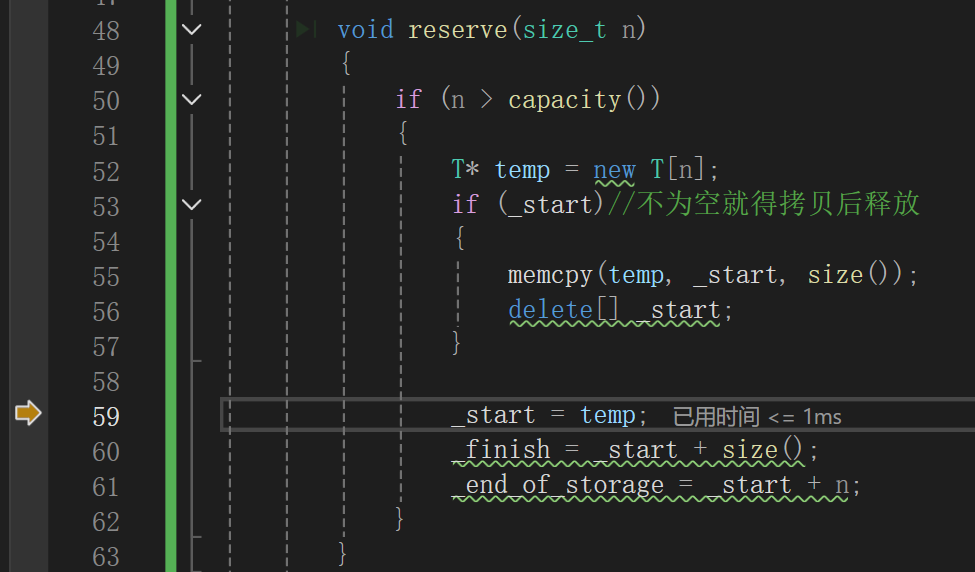
最后确实进去开空间了,而且检查到_start是空指针,也没去拷贝数据,直接开始赋值了,咋就炸了呢?

按下F11后:

赋值成功了啊。
继续:

我们第一次开空间给的是4个大小的,所以size应该是4,而vector存的是int类型的所以是16个字节,那么根据_start的地址应该是fb180:

结果直接炸了,_finish压根没赋上值,_start还没问题就只能是size的问题了,size那么简单的逻辑我是真没想到还能有问题,索性直接跳过了,没进size,只能重新调试一遍:

进去一看,直接破案。
size用的是_finish到_start的偏移量来计算的,但是很明显上句刚把_start赋新值,你_finish还是0x00000000,相当于啥吧,你_finish = _start + _finish - start,_start和_start抵消了,最后剩个自己,自己赋给自己能变才怪嘞。
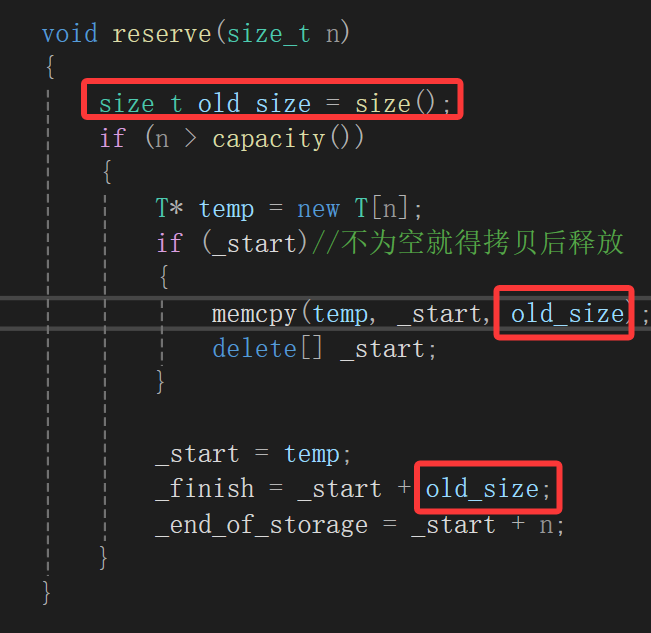
所以在这步算size非常蠢,必须在_start被realloc之前就算:
信心满满去调试:
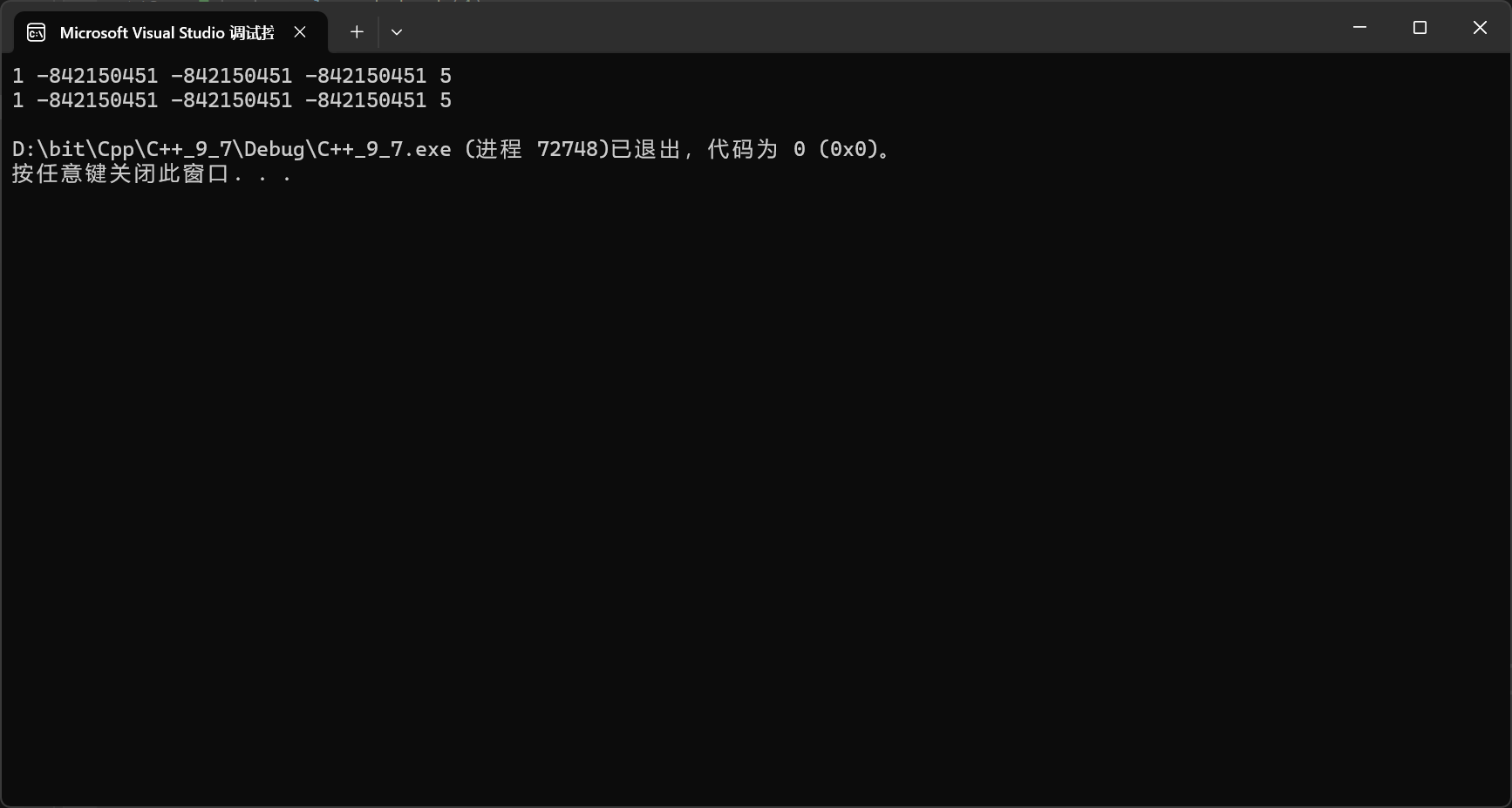
其实错了这么多次了,我大概知道估计又是二次扩容搞得鬼,因为我正常不扩容一直*finish = x,finish++能有什么问题。
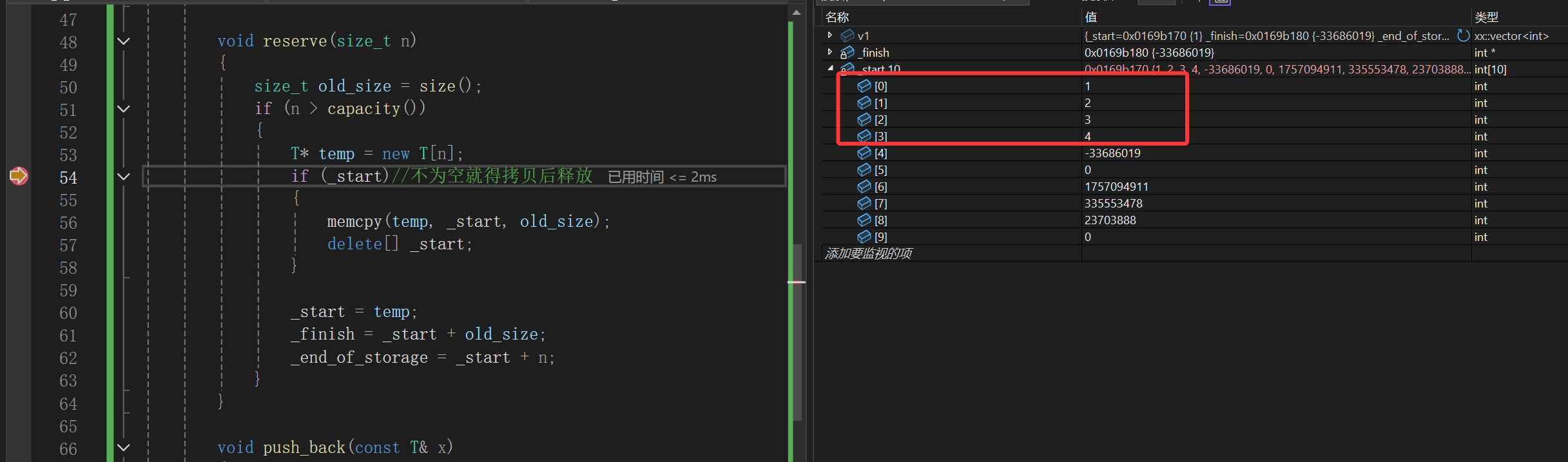
看吧,不出所料根本没有问题,1234都有,继续看:

唉,memcpy最后一个参数传的是拷贝多大空间,我拷贝的是元素个数,中间还差个sizeof呢:

一整终于过了。
void reserve(size_t n){size_t old_size = size();if (n > capacity()){T* temp = new T[n];if (_start)//不为空就得拷贝后释放{memcpy(temp, _start, old_size * sizeof(T));delete[] _start;}_start = temp;_finish = _start + old_size;_end_of_storage = _start + n;}}其实一直在改reserve一个是拷贝的问题,一个是扩容后的指针位置,真是个麻烦事。
当然,push_back已经搞出来了,pop_back也该登场了:
void pop_back()
{assert(_finish > _start);_finish--;
}当然,assert其实可以改成:
bool empty(){return _finish == _start;}void pop_back(){//assert(_finish > _start);assert(!empty());_finish--;}
2.insert
大致思路还是需不需要扩容,怎么插数据。
不过需要注意的是,我们经过看库里面的insert注意到:

传pos可不是传下标,而是传迭代器。
其实insert等于直接用指针确定pos的位置了。
void insert(iterator pos,const T& x){assert(pos >= _start && pos <= _finish);//扩容if (_finish == _end_of_storage){reserve(_start == nullptr ? 4 : 2 * capacity());}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}/*memmove(pos, pos + 1, sizeof(T) * (_finish - pos));*/*pos = x;_finish++;}另外,为了方便随时遍历,直接搞个函数出来:
void Print(xx::vector<int> v)
{for (auto e : v){cout << e << " ";}cout << endl;
}
测试看起来也没啥毛病,是我们想象中的场景。
但是:
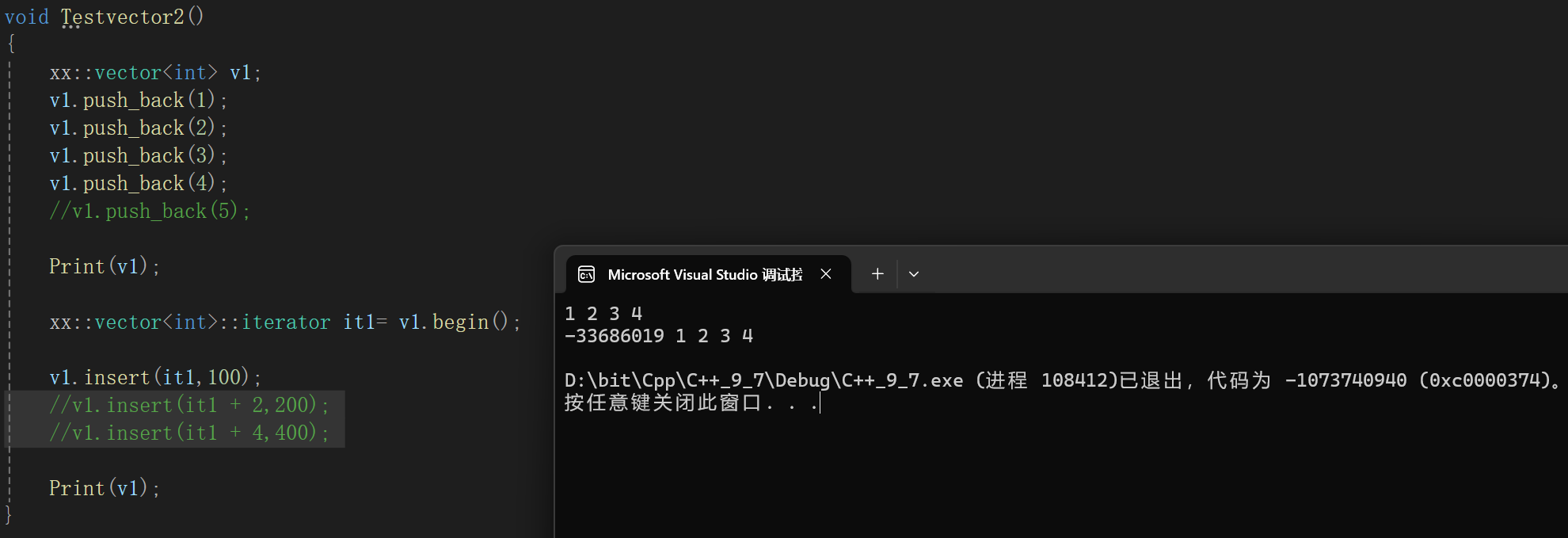
其实这个场景就是扩容的场景,一旦需要扩容,直接炸缸了,而且经过调试可以看到:
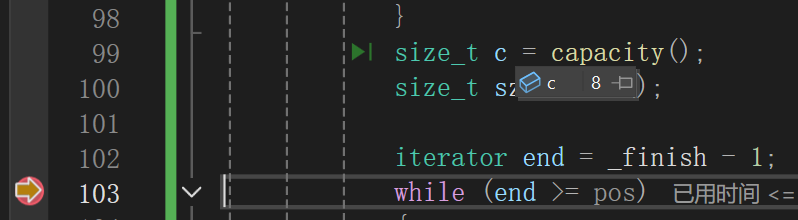
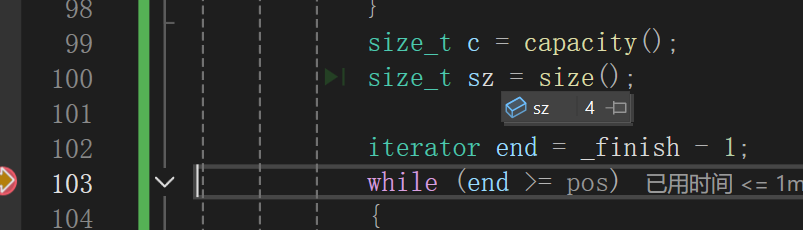
显示出来size和capacity都是扩容成功的,这个时候只能是while循环出问题了:
一看就发现,其实前几次的后移都没问题,直至下一次:
我得发,给我干哪来了???
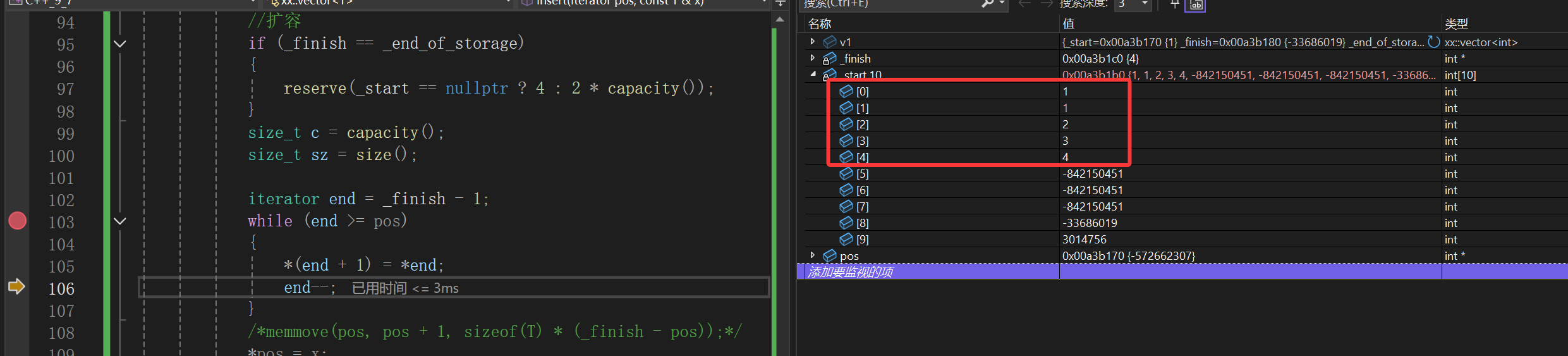
重新调试可以发现这样的现象:
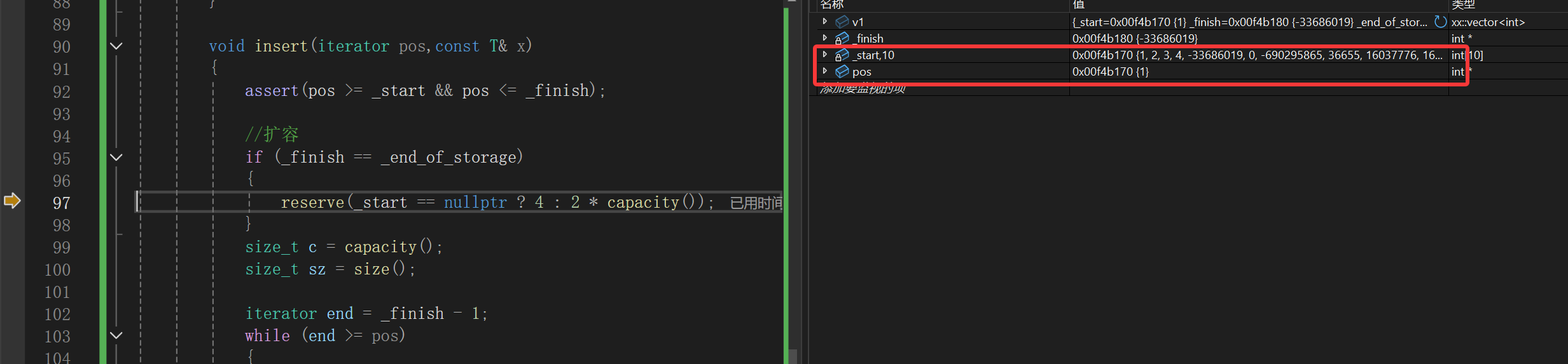
我们传的值其实是想头插,pos和_start相等。
我们这个时候该扩容了,因为初始给4个元素的空间,已经是不够了,扩容的细节是什么:
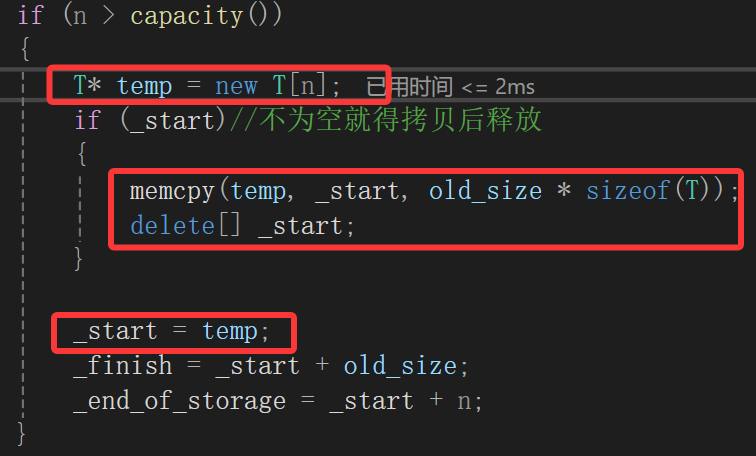
C++没有realloc,这个事我是反复的说,所以只能申请一块新的空间然后把所有数据和指针移走。
出了扩容就能注意到: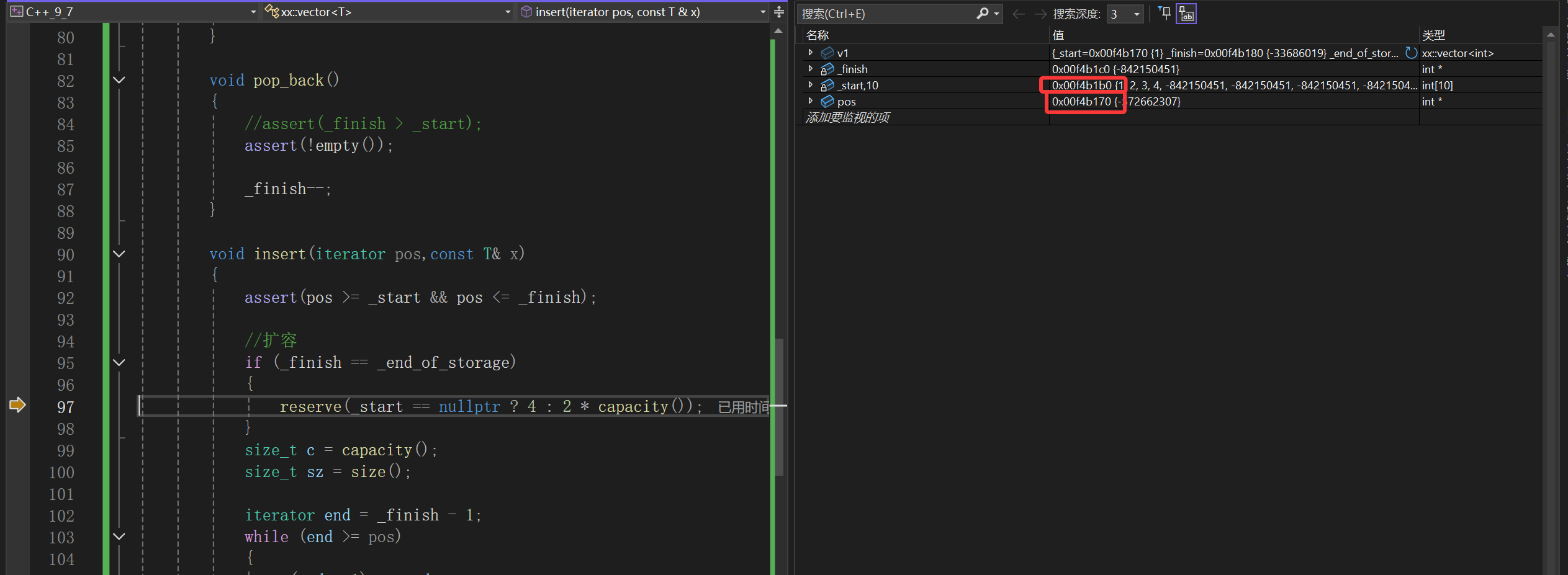
直接把_start _finish _end_of_storage全部更新了。
你end是扩容后现算的,所以也是没毛病的,但是你pos可没更新啊。
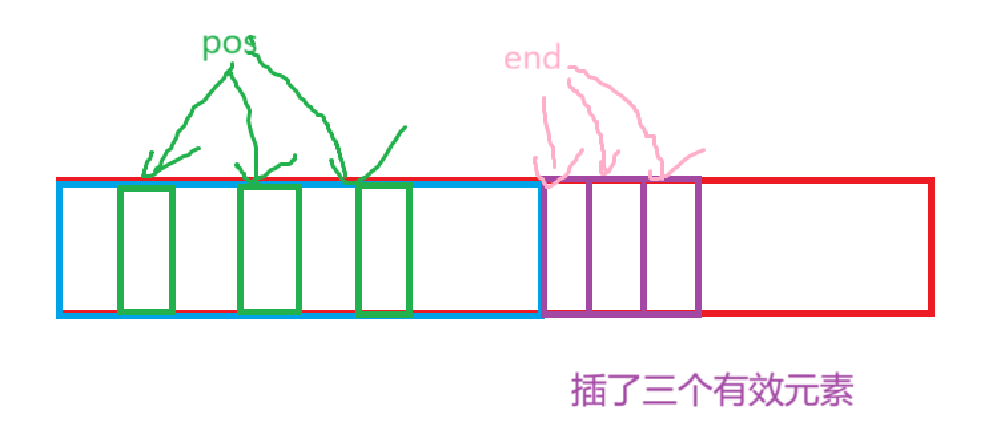
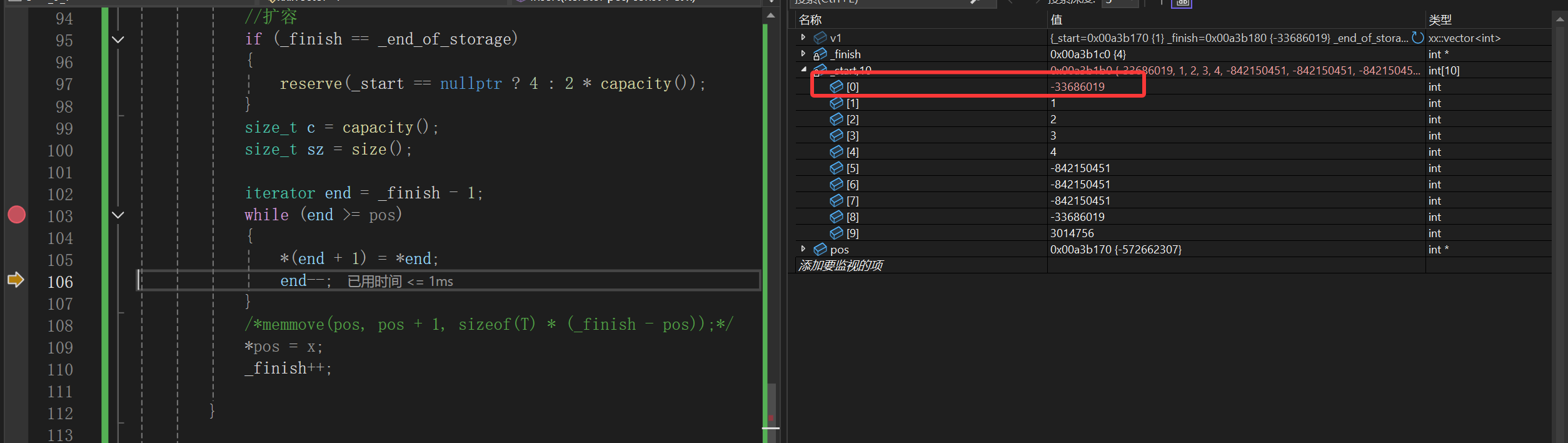
比如说这次调试的结果,_start是1b0,pos是170,更新后的_start明显大于pos很多,那么_end只能更大,这样的话肯定会越界,画图理解就是这样的:

当然,不一定每次调试都是这样的效果,这样就会造成越界访问了,所以就会明明end已经过了pos(我们想象中的),但是仍然继续拷贝,而且*pos赋值也没作用,当然没作用了,你从_start哪里能看到原来的pos。
这个扩容而导致迭代器的错误被称为迭代器失效,怎么理解呢?
现在短视频横行,可能在家刷到哪里有好吃的好玩的,你就想去玩,但是因为工作了家庭了一些事搁置了,所以一年后才圆梦,这个时候你还照着原位置找那个地方,假如那个地方因为房租涨了等不可抗力因素换位置了,地图也没有更新,造成的结果就是你找不到自己想去的地方了。
跟这里是一个道理,你找错地方了,我举的例子算温和了,我们上面代码做的是什么事呢?
没找到想去的地方,直接把原来的场子都砸了(修改数据,而且是越界访问修改)。
越界访问是非常可怕的事情,就举个简单例子,假如这块区域是一个应用程序的组成部分,好,本来的想法是没有钱,你往里充了100块,结果现在因为越界访问,想象中的到账一百元没有实现,因为随机值是负的嘛,所以直接干成负的一大堆了。出这种bug估计早就炸了。
知道迭代器为什么失效以后,肯定就得想办法了,道理也很简单,手机电池最大容量不够了你就会去换电池,轮胎破的不能修了,你也知道去换,同样的道理,迭代器坏了你就换呗,这里的换当然不是随便换,你不能说我一个越野车的轮胎坏了给我上个自行车胎,所以一定要合理:
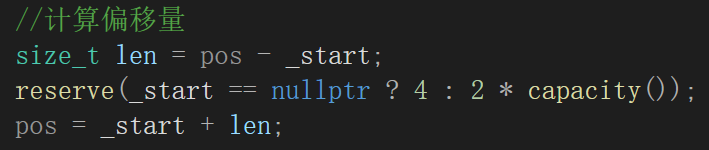
所以修改后的版本就是:
void insert(iterator pos,const T& x){assert(pos >= _start && pos <= _finish);//扩容if (_finish == _end_of_storage){//计算偏移量size_t len = pos - _start;reserve(_start == nullptr ? 4 : 2 * capacity());pos = _start + len;}size_t c = capacity();size_t sz = size();iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}/*memmove(pos, pos + 1, sizeof(T) * (_finish - pos));*/*pos = x;_finish++;}一测试:
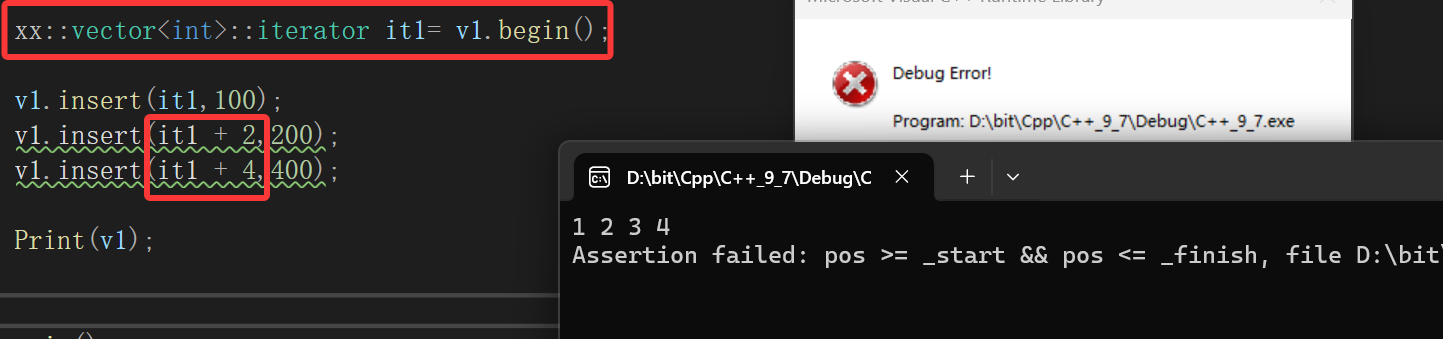
道理很简单,我们it1存的是最开始的有效数据个数只有四个的vector的起始位置,扩容后肯定就不合适了,因为内部更新的pos不会影响外部,所以最好传参:
其实insert内部就那么多东西,重点是这次用的不是下标,是迭代器扩容以后造成的迭代器失效是很可怕的。
这个时候可能又有人说了,,那直接改成传引用算了呗,传引用pos就能一直有效,搞那么麻烦干什么?
好,如果传引用返回:

肯定是存在问题的,原因也很简单:
begin和end都是传值返回,我们早说过了,传值返回肯定是要拷贝出来一份临时的,临时变量具有常性,那么你要用非const&肯定就坏事了,那索性一不做二不休,直接用个const:

结果奇迹的发现:
![]()
你还给常量赋值了。
所以这个场景就是典型的必须传值,传引用就会造成一系列错误。
之前string的insert是这样的:
void string::reserve(size_t n){if (n > _capacity){char* str = new char[n + 1];strcpy(str, _str);delete[]_str;_str = str;_capacity = n;}}string& string::insert(size_t pos, char c){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 :2 *_capacity;reserve(newcapacity);}size_t end = _size;while (end >= pos){_str[end + 1] = _str[end];end--;}_str[pos] = c;_size++;return *this;}重点是reserve是会更新_str![]() ,后续访问pos位置用的是[],其实本质也是算偏移量的,所以之前就没出问题。
,后续访问pos位置用的是[],其实本质也是算偏移量的,所以之前就没出问题。
3.erase
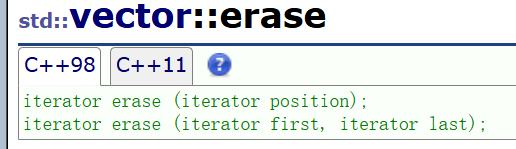
库里面迭代器位置的删除,迭代器区间的删除都有,其实没有必要都实现,实现迭代器位置的最简单粗暴了,道理很简单,直接复用从first到last这么多次erase pos即可。
erase最核心的思路就是pos位置后的所有数据前移。
所以最终代码就是:
void erase(iterator pos){assert(pos >= _start && pos < _finish);iterator end = pos + 1;while (end != _finish){*(end - 1) = *end;end++;}_finish--;}为了测试代码能够展现出随机删除,调用一下算法库里的find算法:

不再截介绍了,简单说就是传一段你想查的迭代器区间(迭代器区间当然是左闭右开的),以及想查找的值,最后返回第一个目标数据位置的下标。
所以测试代码:
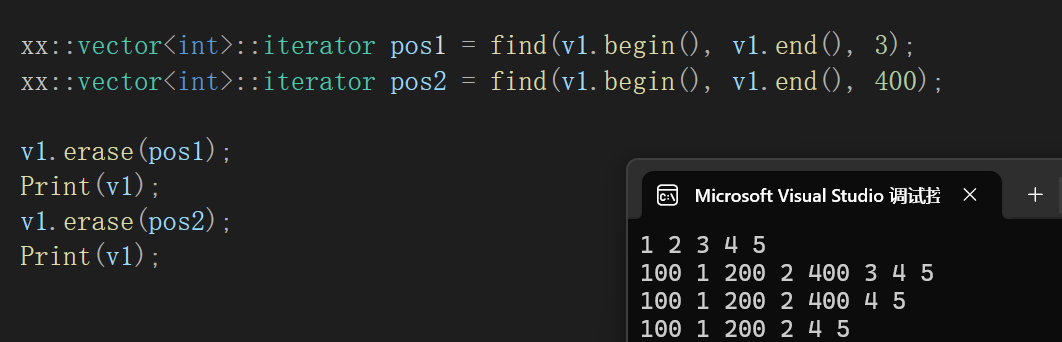
同样道理,erase以后我们的迭代器会失效吗?
比如这样一段代码:
void Testvector3()
{xx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);//xx::vector<int>::iterator pos = v1.begin();auto pos = v1.begin();while (pos != v1.end()){if (*pos % 2 == 0){v1.erase(pos);}pos++;}Print(v1);}看起来平平淡淡的,也就是把v1里所有的偶数删除嘛,很简单的逻辑啊,一测试:
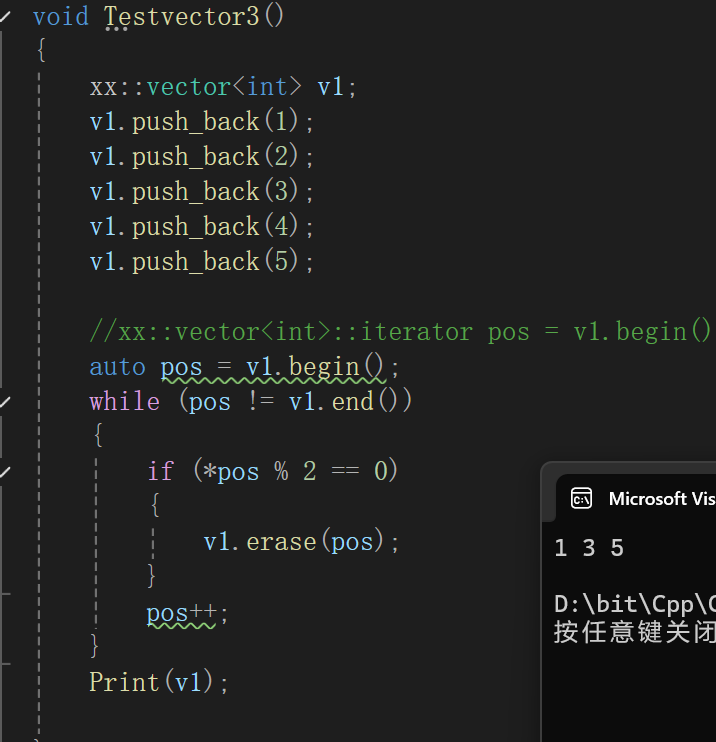
不错不错,圆满完成任务。
但是测试样例一旦变成这样:
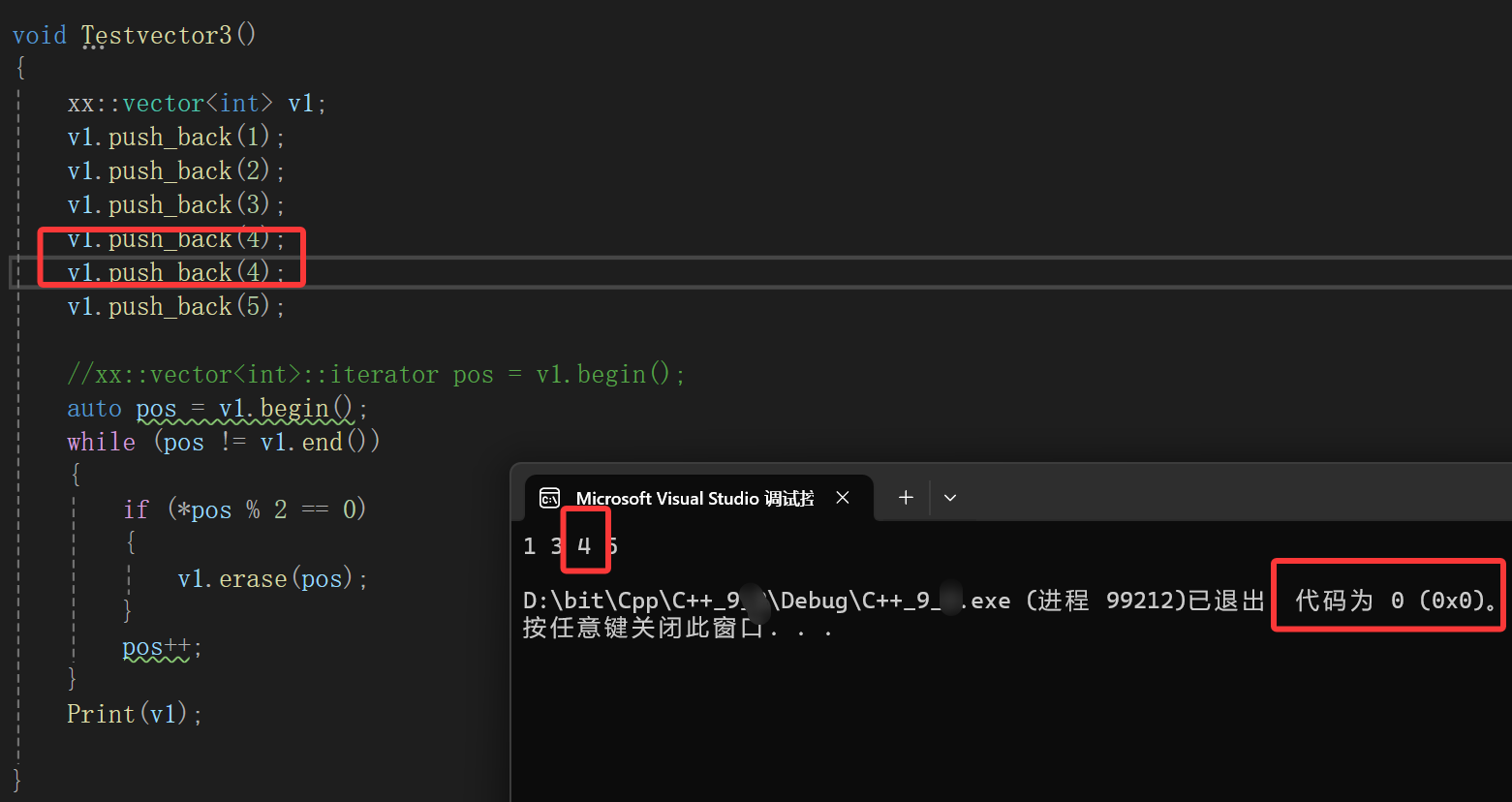
代码正常运行但是答案却是错的,不妨画图看看:

理想情况就是一一遍历而后符合条件的删去。
但是实际上:

我们做的是移动数据来覆盖代替删除,移动完数据确实没毛病,但是我们自己写的时候不知道啊,还在傻傻的移动,其实这个时候直接跳过了3,到4了,也就是说每当碰见偶数的时候因为前移数据已经达到了pos++的效果,此时我们还++就会无效。
我们不用自己实现的vector,改用标准库的试试:
![]()
不过用标准库里的还有一个问题,那就是你Print写的是xx这个命名空间的vector<int>,直接写死了,所以就不能这样调用Print函数来遍历,这个场景很明显就是函数模板的实现,但是注意,如果这么写:
template <typename T>
void Print(xx::vector<T>& v)
{for (auto e : v){cout << e << " ";}cout << endl;
}
一句话,治标不治本,本质是命名空间的同名容器导致无法兼容,你改个内部的类型照样突破不了类域,还是个麻烦事嘞。
所以这次狠一点:
template <typename Container>
void Print(const Container& con)
{for (auto& e : con){cout << e << " ";}cout << endl;
}相当于参数直接就是容器本身,什么意思呢?
就好像原来我们吃月饼不仅要吃五仁的,还要吃水果味的、玫瑰味的。本质可能就是个馅变了,但是这次我们不仅馅要多种多样的,而且油酥皮的、冰皮的都想吃。月饼的内部和外部都变了。
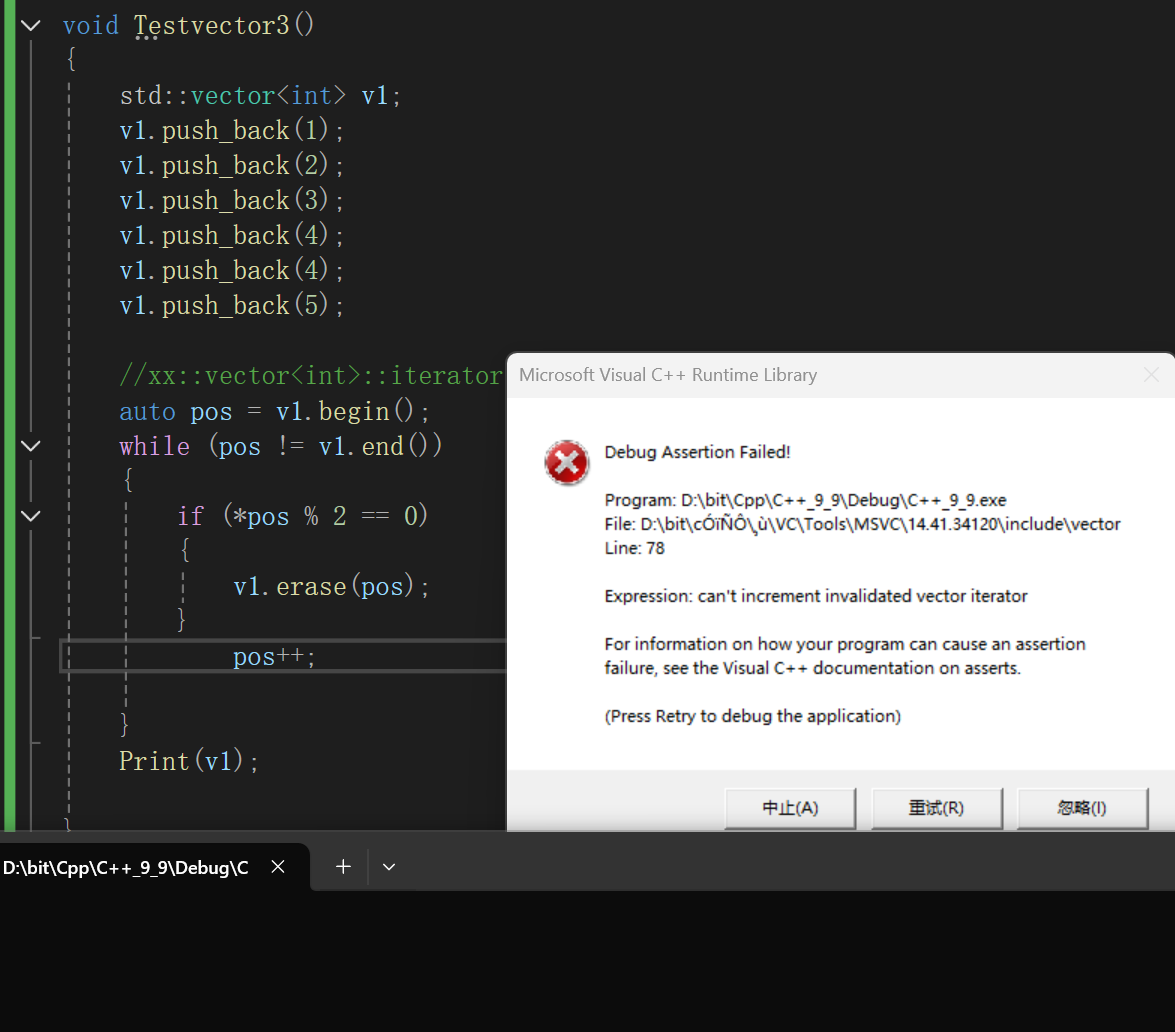
同样的代码用std的vector直接就报错,原因是这里其实也是一种迭代器失效,我们写的逻辑上其实和库里的基本大差不差,库里面比我们多写的好多都是用来诊断的,防止未定义的行为出现。
要想让上面代码成功就得:
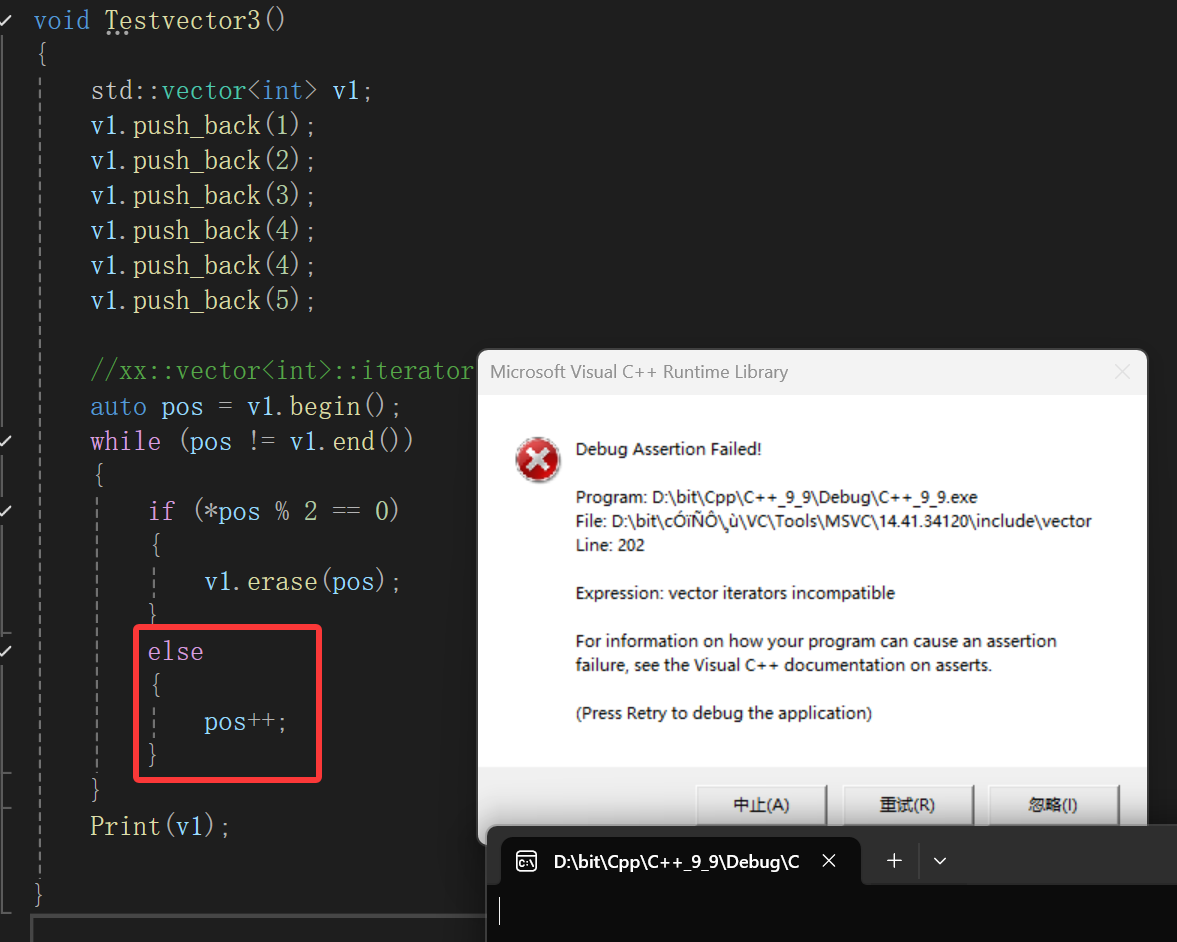
想象中是吧erase的统一前移当成pos++,如果没有erase就继续pos++,但是编译器还是严格的检查了,检测到你继续使用失效的迭代器。
STL库里的erase其实是有返回值的,包括insert:
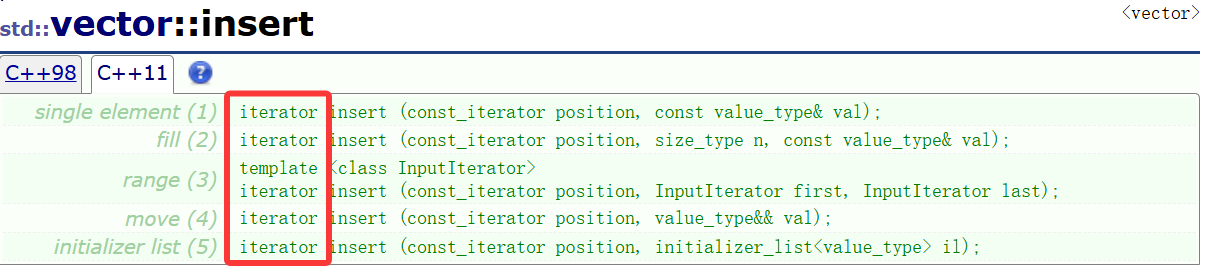



分别看看:
insert返回新插入的第一个元素的迭代器;erase返回被删的这个元素的下一个元素的迭代器。
有什么用呢?
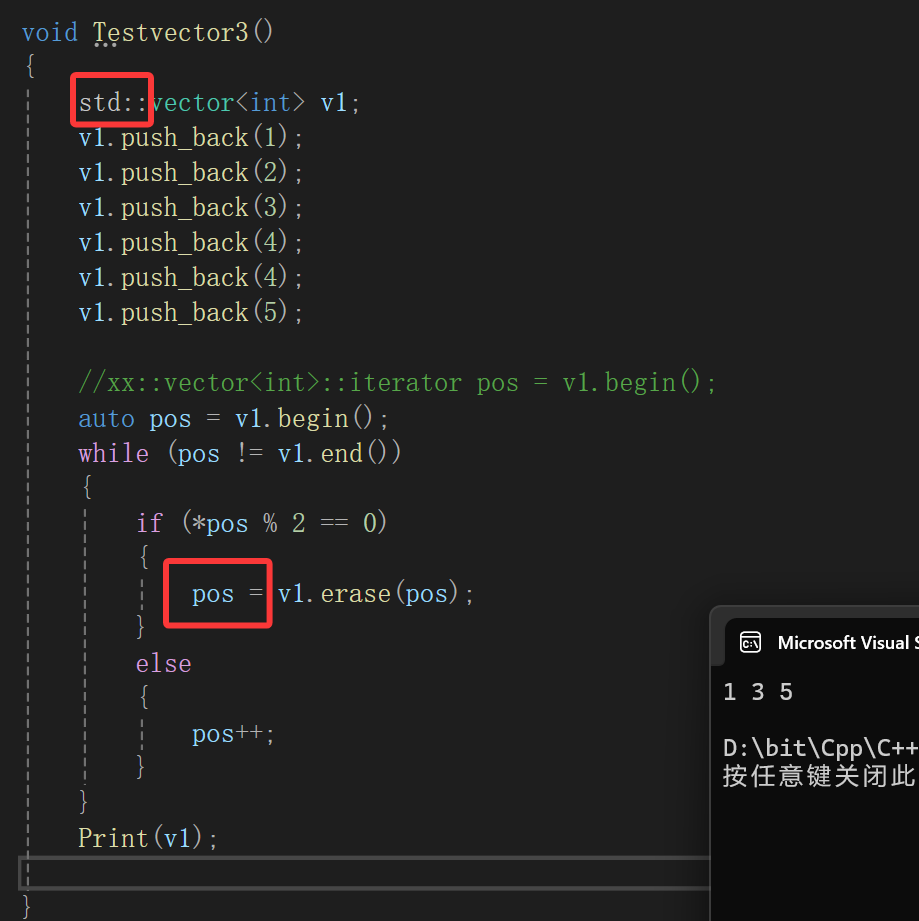
更新迭代器编译器就不会找你的麻烦了,所以简简单单给我们的insert和erase都加上返回值:
iterator insert(iterator pos, const T& x){assert(pos >= _start && pos <= _finish);//扩容if (_finish == _end_of_storage){//计算偏移量size_t len = pos - _start;reserve(_start == nullptr ? 4 : 2 * capacity());pos = _start + len;}size_t c = capacity();size_t sz = size();iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}/*memmove(pos, pos + 1, sizeof(T) * (_finish - pos));*/*pos = x;_finish++;return pos;}iterator erase(iterator pos){assert(pos >= _start && pos < _finish);iterator end = pos + 1;while (end != _finish){*(end - 1) = *end;end++;}_finish--;return pos;}其实还是有点小疑问的:
虽然这段代码没有更新迭代器,但是迭代器指向的位置应该和更新迭代器那段代码的逻辑是一样的啊,为什么你这里就错了呢?
底层检查我们就不深究,其实迭代器失效严格来说是非常经典的,未定义行为,至于不理解,我们用链表举例:
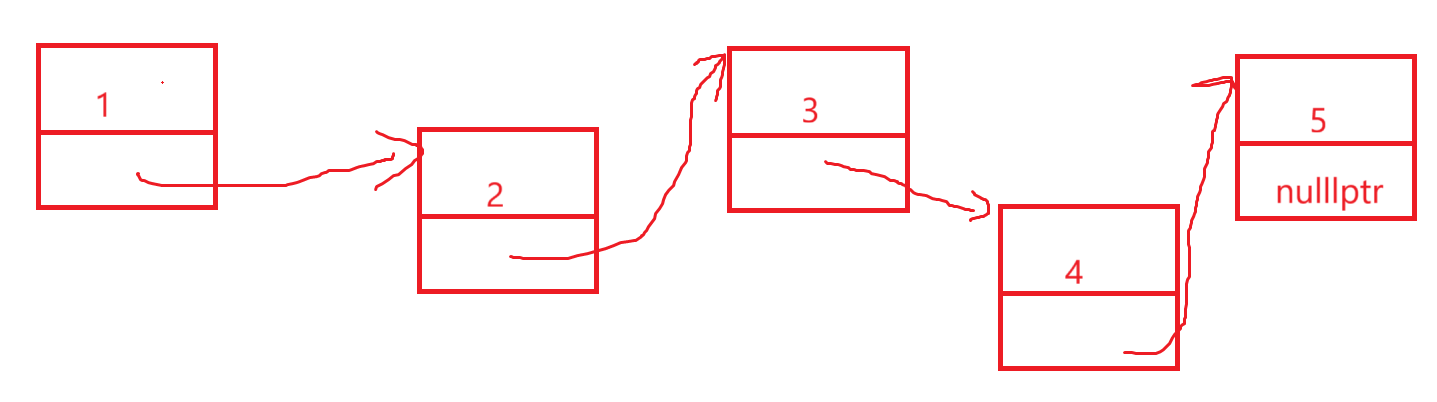
我们这里的erase就是哪个需要删,就从逻辑结构里抹除了就行,也就是:
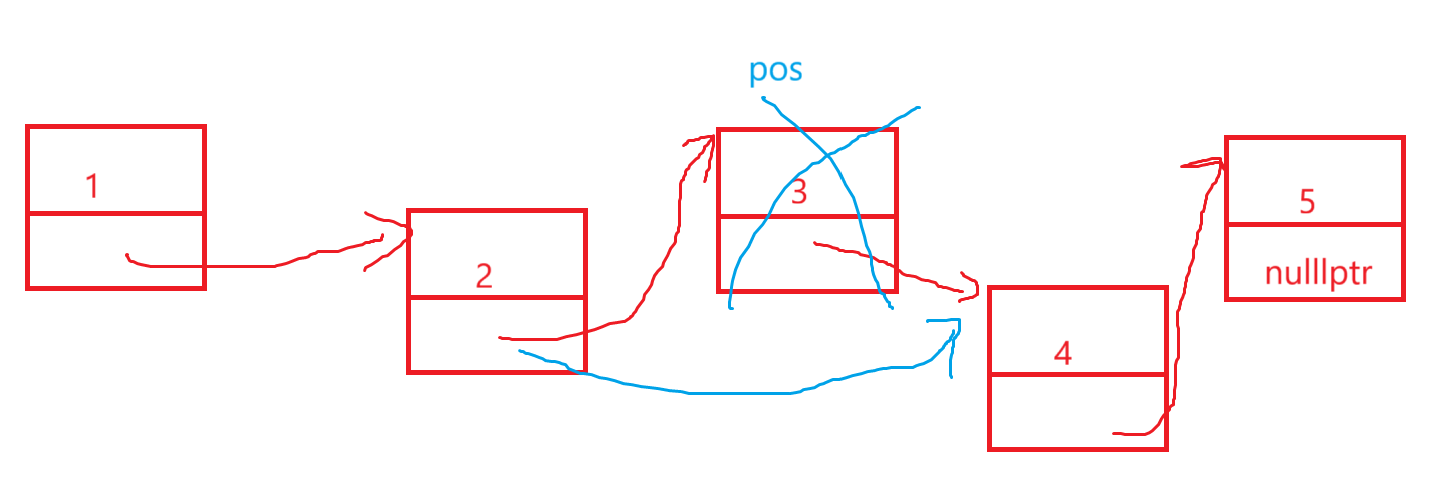
那我问你,同样的道理,只不过vector底层是顺序表,所以pos刚好就是我们要更新的迭代器位置,那么单链表还傻傻等着这种天上掉馅饼的好事那不直接炸了嘛,pos指向的结点直接就被释放了,所以这就是为什么说底层到底怎么检查迭代器更新没更新不是重点,重点是为什么要检查迭代器更新不更新。
4.clear
顺手的事:
void clear(){_finish = _start;}5.resize
改变有效元素个数,如果n < size那么就只保留前n个有效元素,如果n>size那就直接扩容,当然,扩容值不给的话我们就得填缺省值了。
那么好,如果保留前n个有效元素:
void resize(size_t n){if (n < size()){_finish = _start + n;}}真是随便写。
如果需要扩有效元素个数:
else if (n > size()){if (n > capacity()){reserve(n);}while (size() != n){push_back(x);}}
但是缺省值填啥呢?
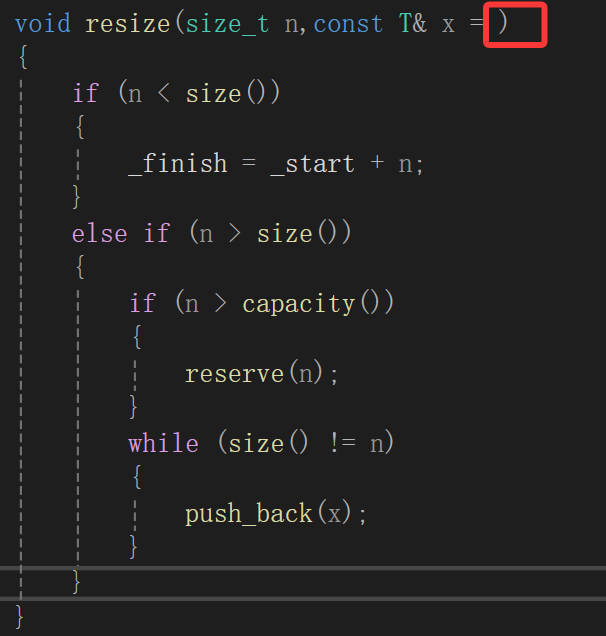
填个0吗,但是万一是其它的自定义类型呢?填nullptr也是一个道理啊。
这里就得补充个知识了,为了这种情况,也就是模板里的函数的默认缺省值问题,C++对内置类型进行了升级:
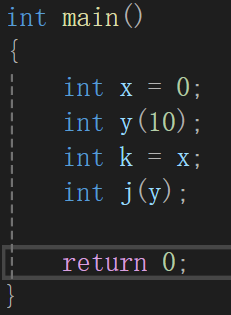
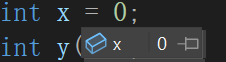
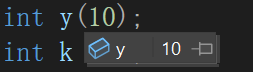
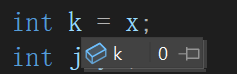
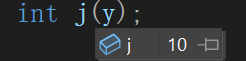
简单看就是让内置类型可以像自定义类型一样初始化,我们原来认为的赋值其实类似于这里的常量0/10,隐式类型转换成int类,再赋值给x j,当然也有拷贝构造。
有了这样的升级,模板就可以做到:

相当于不管vector存储什么类型,如果不传的话就用默认值来resize。
简单测试一下:
六、关于vector的补充
1.析构函数
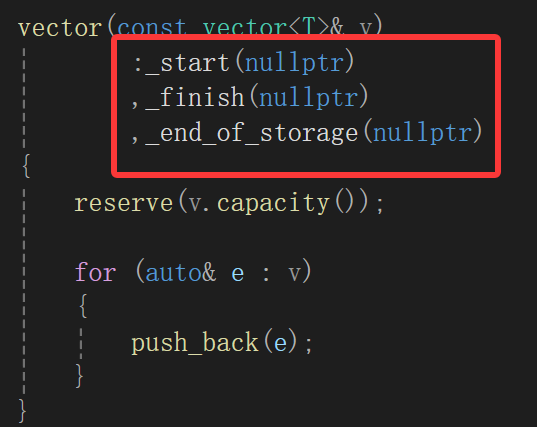
~vector(){if (_start){delete[] _start;_start = _finish = _endofstorage = nullptr;}}2.拷贝构造
vector(const vector<T>& v){reserve(v.capacity());for (auto& e : v){push_back(e);}}简单来说,能够复用代码就复用代码,比如我们string类的现代写法就是复用c-str的构造函数,构造一个深拷贝的temp,swap给我们的*this。
vector我们仿造库里面写的,构造函数也只是给三个成员指针置空,所以干脆直接开空间再遍历尾插就行。
测试倒是没,不过生成解决方案的时候发现:
![]()
一检查:
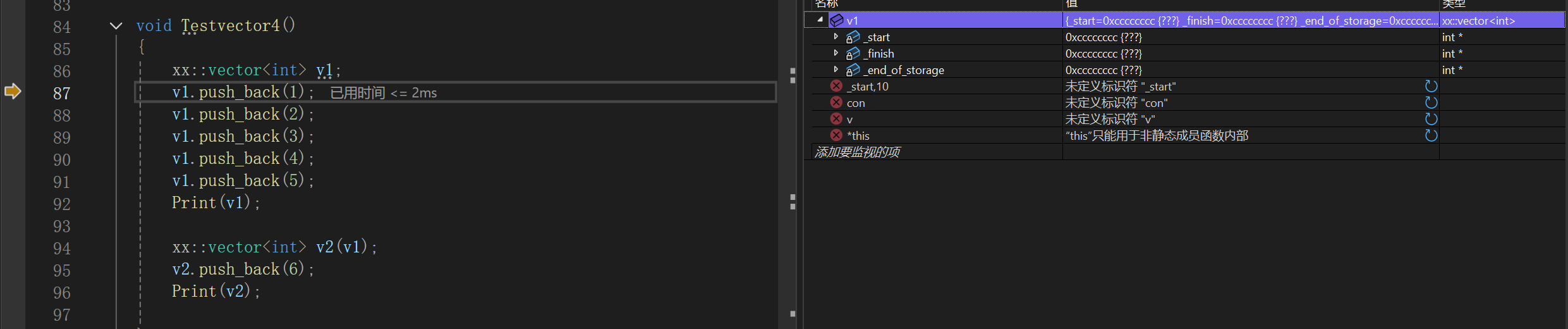
确实存在const的this指针被转为非const的问题,这又印证了我们前面说的,只要是只读的函数,索性都变成const成员函数:
size_t size()const{return _finish - _start;}size_t capacity()const{return _end_of_storage - _start;} 比较尴尬的就是我模拟实现的时候遇到了bug,大致上就是拷贝构造不给三个成员指针显式初始化嘛,因为很明显我们上面提供的拷贝构造函数体没有显式初始化,初始化列表和缺省值也都没走,所以三个指针的值完全取决于编译器,也就有可能是垃圾值,类似于这样:
现在我们只让编译器生成默认的构造函数,其实相当于什么都不做,因为默认生成的就是这样,内置类型就完全依赖于编译器,产生的都是垃圾值:
我就问你全部都是随机值,那么reserve还能成吗?

不为空,但是随机值是一样的啊,所以2 * capacity开了0个空间,那你还不炸了。
拷贝构造本来也是这样的,但是由于我试着写了解决方案:
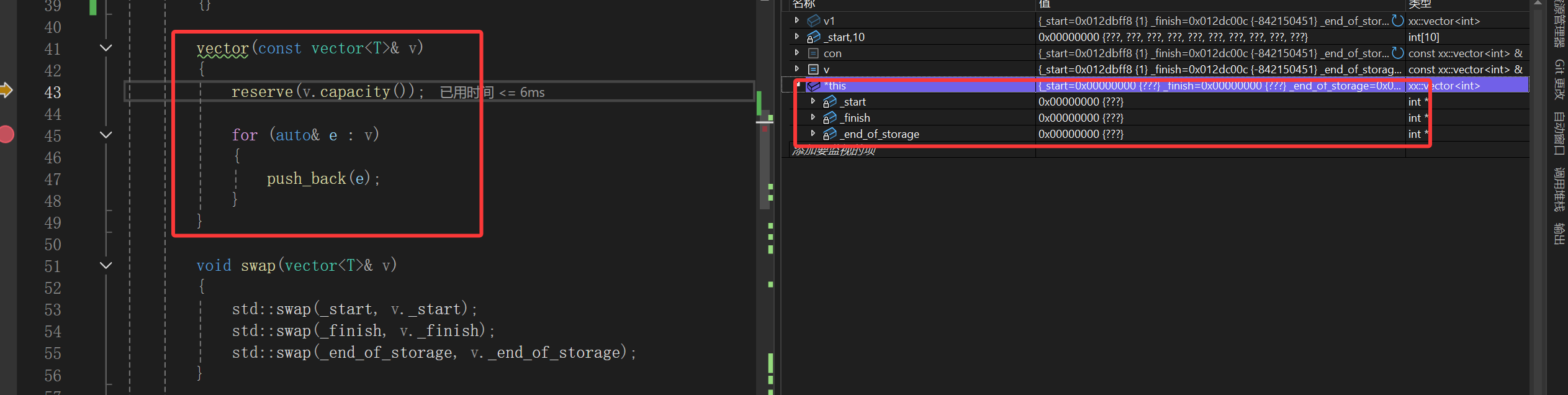
也就是试着在成员变量写缺省值(其实也就是走初始化列表了,只不过初始化列表没有显式给所以隐式走了缺省值走初始化列表):

结果我测试完bug在哪了,就算缺省值我删了,也模拟不出来垃圾值了,后来问了问ai,大概意思就是编译器试过nullptr初始化以后拷贝构造的默认行为都是用nullptr初始化了,如果还想模拟就再重新换个环境写代码,这样就可以了。
重点还是要对成员变量初始化。
当然,显式走初始化列表也行:
3.operator=重载
核心还是复用:
void swap(vector<T>& v){std::swap(_start, v._start);std::swap(_finish, v._finish);std::swap(_end_of_storage, v._end_of_storage);}vector<T>& operator=(const vector<T>& v){vector<T> temp(v);swap(temp);return *this;}其实仔细想想,这里不初始化也没事,拷贝构造出来个temp,temp的成员变量都是有效的
测试:
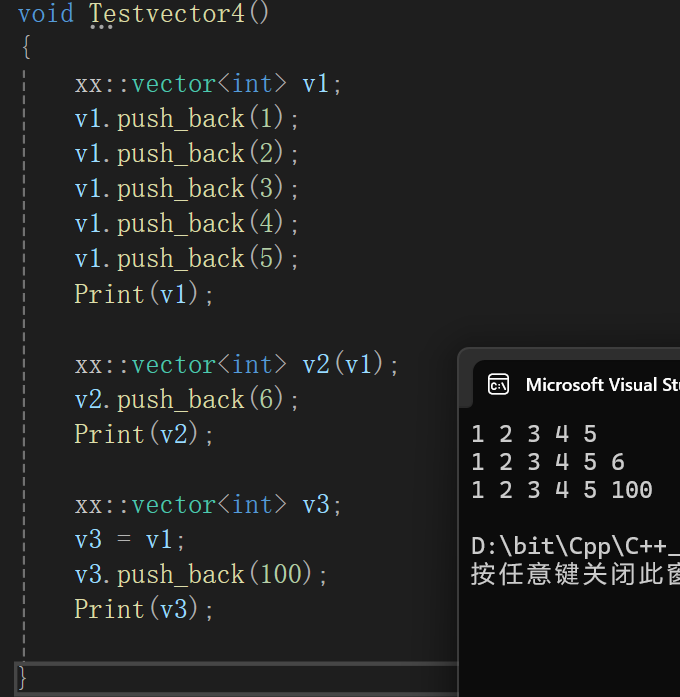
没毛病。
4.初始化列表初始化
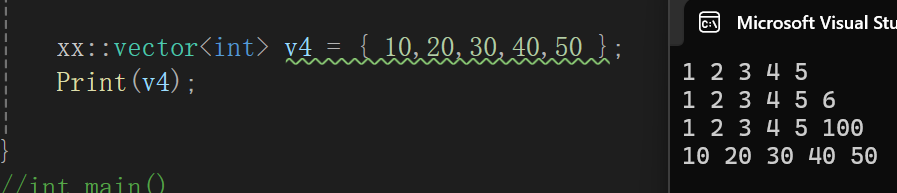
vector(initializer_list<T> il){reserve(il.size());for (auto e : il){push_back(e);}}这个真不用多说,跟拷贝构造一个思路,只不过容器不一样。
5.任意容器迭代器区间初始化
为了能够接受任意容器的迭代器,那模板中的类型其实也就是迭代器类型,这点参考标准库:

至于为什么类型名起成这个样子,等到学list的时候再详细讲解,现在我们也模仿着先写着:
template <class InputIterator>vector(InputIterator first, InputIterator last){size_t size = last - first;reserve(size);while (first != last){push_back(*first);first++;}}
6.任意n个值初始化

其实这玩意老不想写了。
vector(size_t n, const T& x = T()){resize(n, x);}
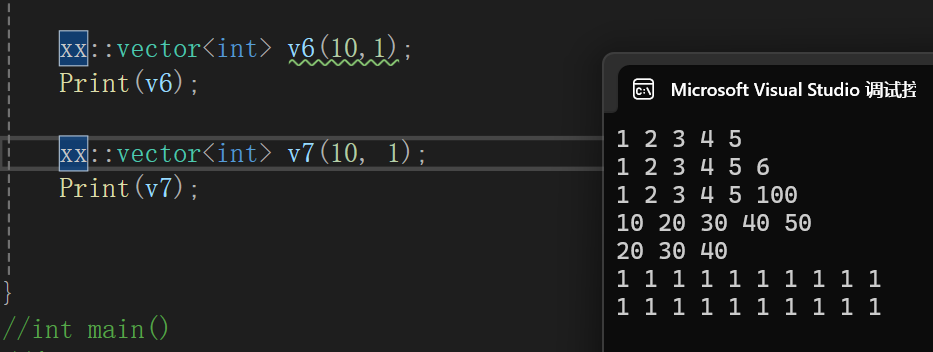
看着老容易了,但是一旦测试:
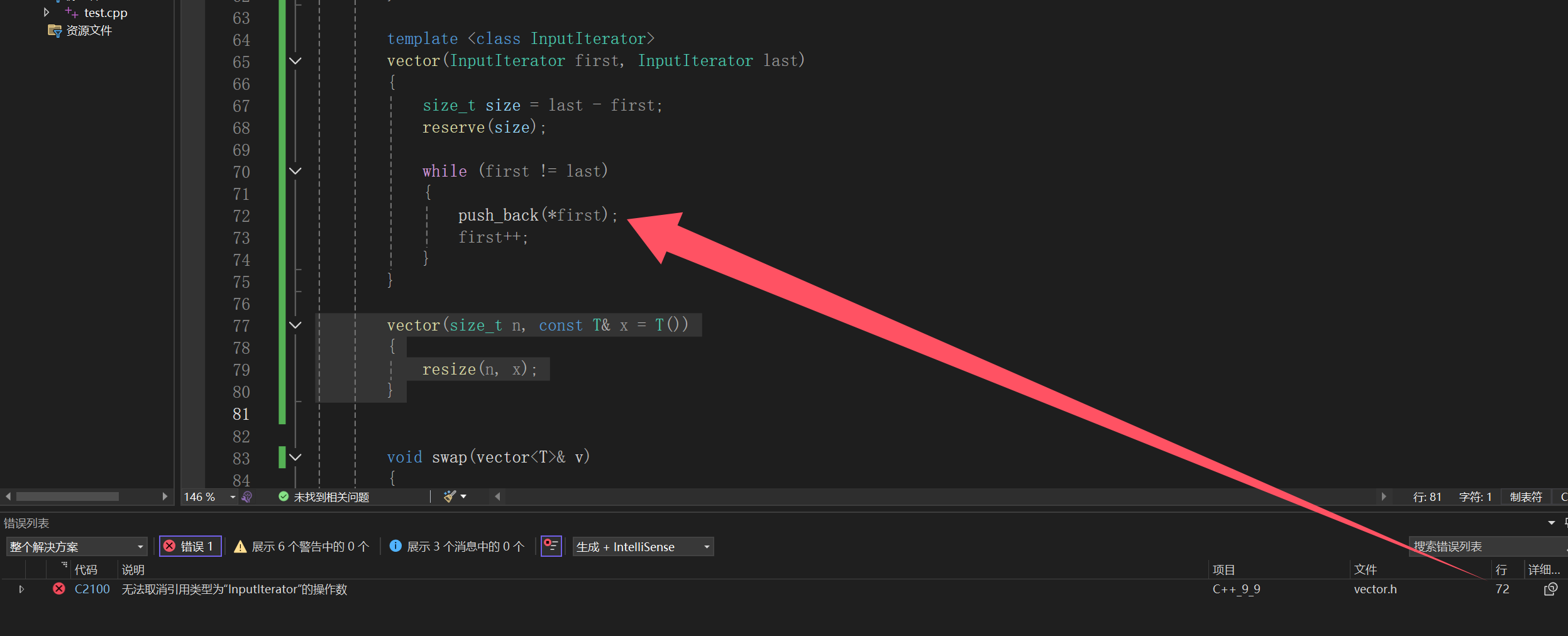
我也不多bb了,简单来说就是,你上面不是个函数模板嘛,甭管你类型叫啥,肯定能传任意类型的吧,我们测试样例就是这样的:
两个int int,如果去匹配我们想要匹配的那个构造,那就是size_t,int类型的形参,如果直接用模板生成,那就是int int,我们前面说过有现成的用现成的,不用模板生成,但是我们另外还说过一个事,那就是如果模板生成的比现成的更匹配,那就用模板生成的。
再来,也不要想什么用int n做形参,如果传的是size_t的n的实参呢,如果传的是long呢,传的是longlong呢,当然,也没啥毛病,你完全可以全部写出来。
主要人家VS包的标准库不是这么玩的:
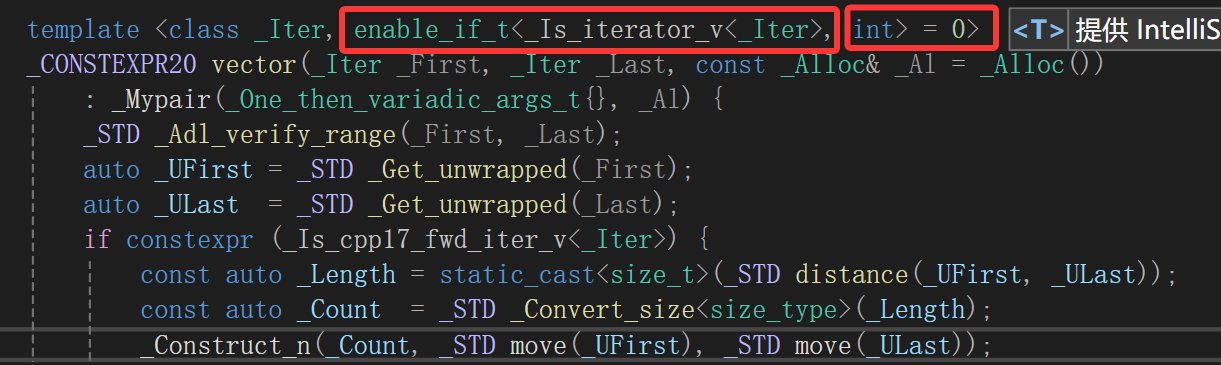
直接弄了个这,如果想要匹配迭代器区间初始化那个,还得走这个判断,所以人家都模板并不会被我们这种情况匹配,不信直接粘到我们自己写的函数里:
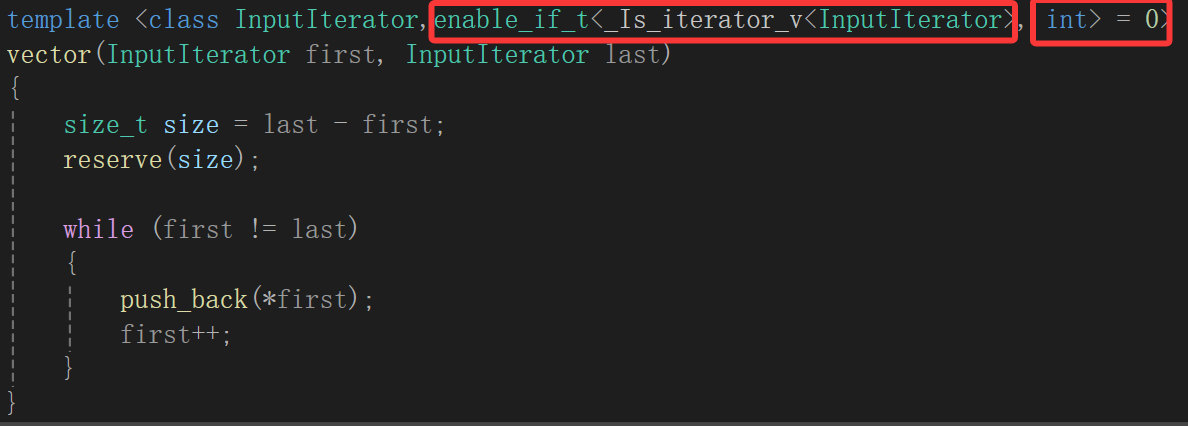
因为试过了,所以根本不想再粘了,知道原理即可。
七、深拷贝的浅拷贝问题
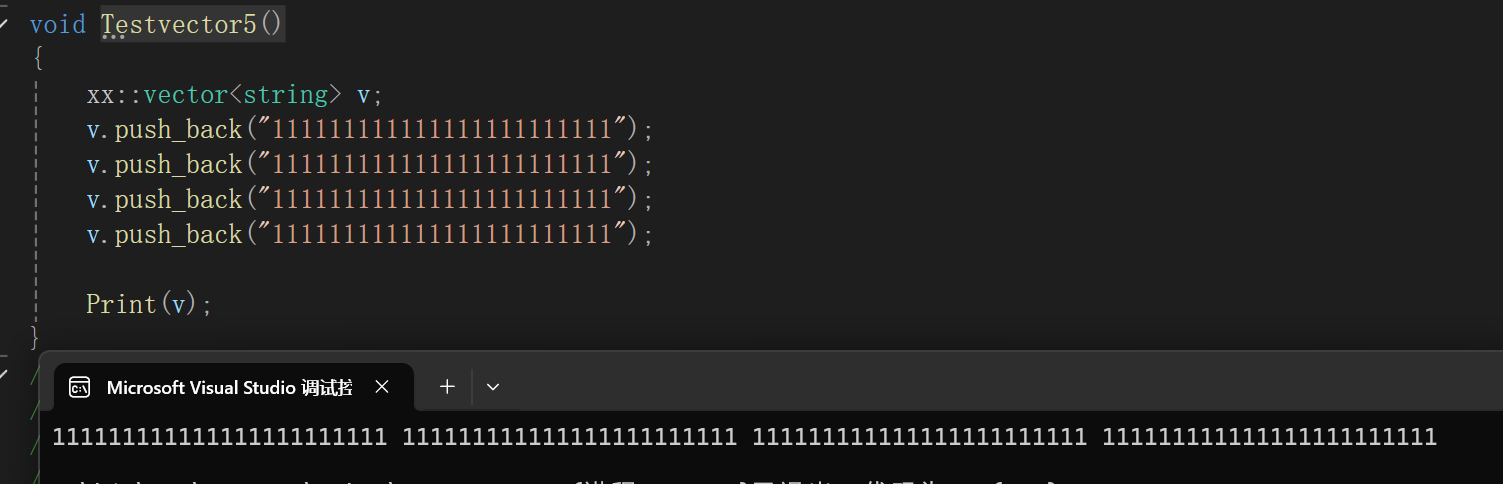
看着好好的,没啥毛病。
但是一旦涉及到扩容:
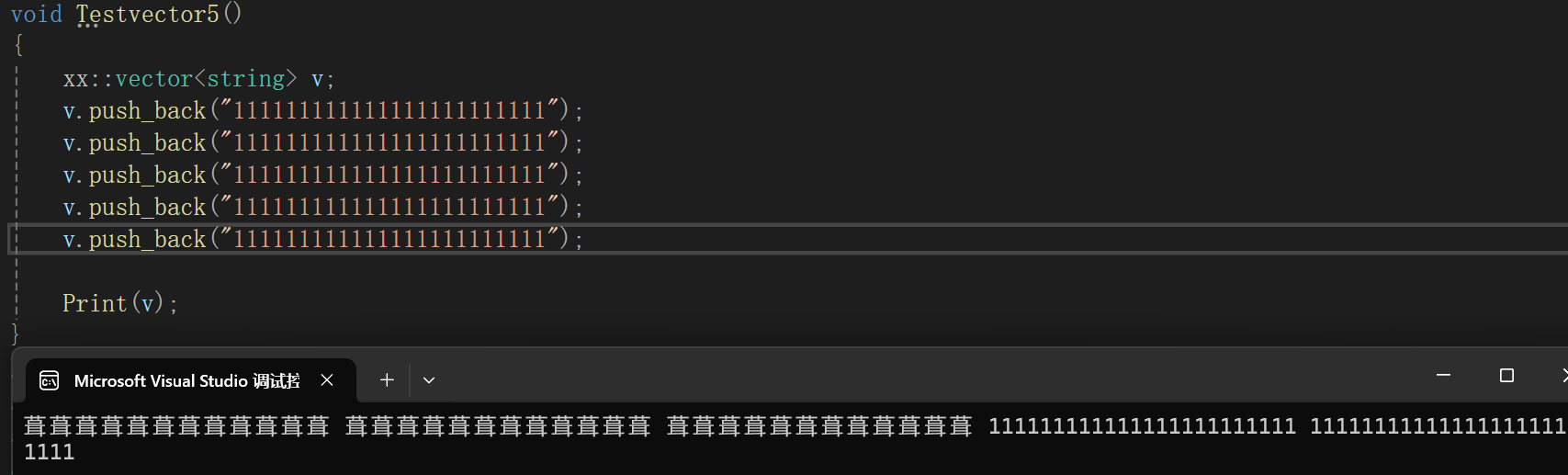
依旧调试:
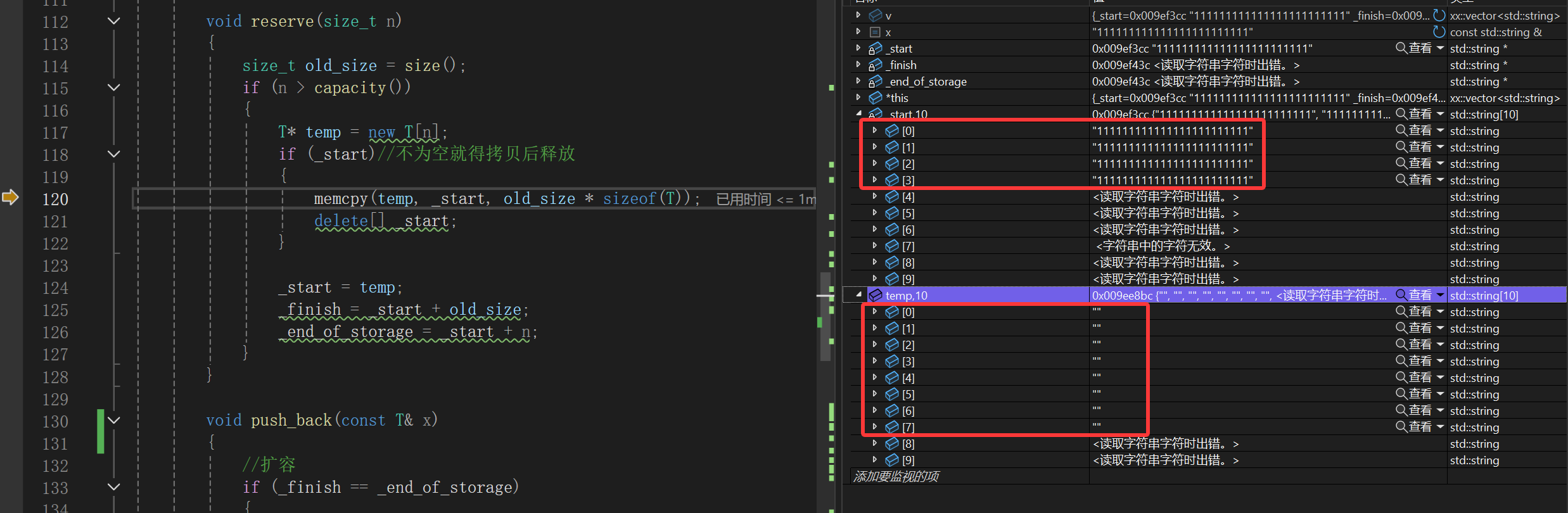
一直到正式reserve前都没啥问题,重点来了:
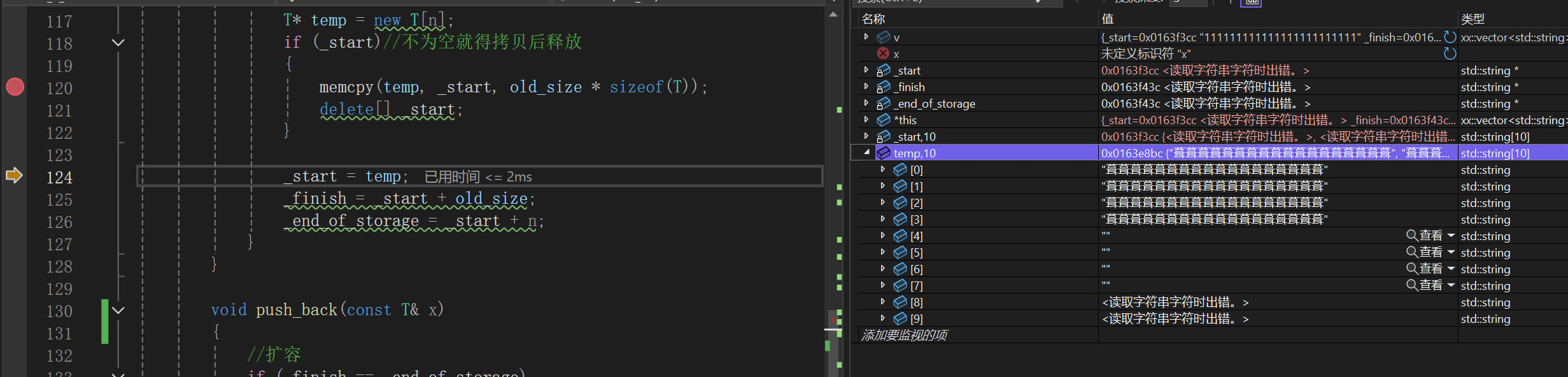
一旦memcpy再delete[]就会直接成随机值,其实我这里已经是第二次调试,第一次调试我啥都没发现,继续调试我继续深究:

memcpy以后:
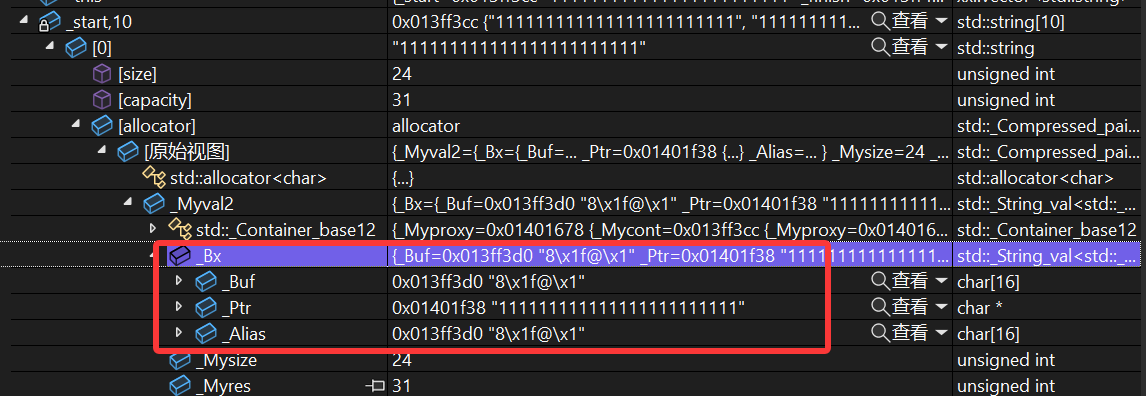
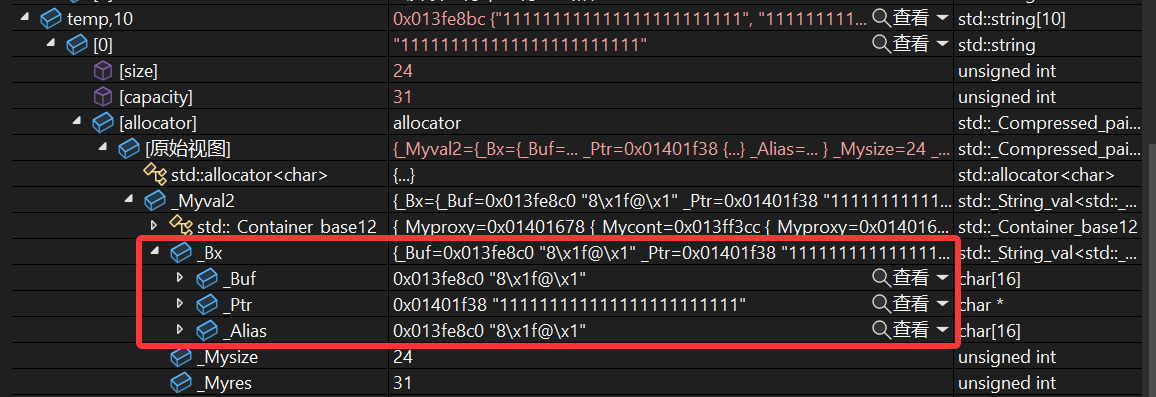
超过15个不存_Buf上了,改存_Ptr上了,结果呢?
两处指针完全一样,这样的话delete[]_start以后相当于把temp底层的string也释放了。
大概意思就是:
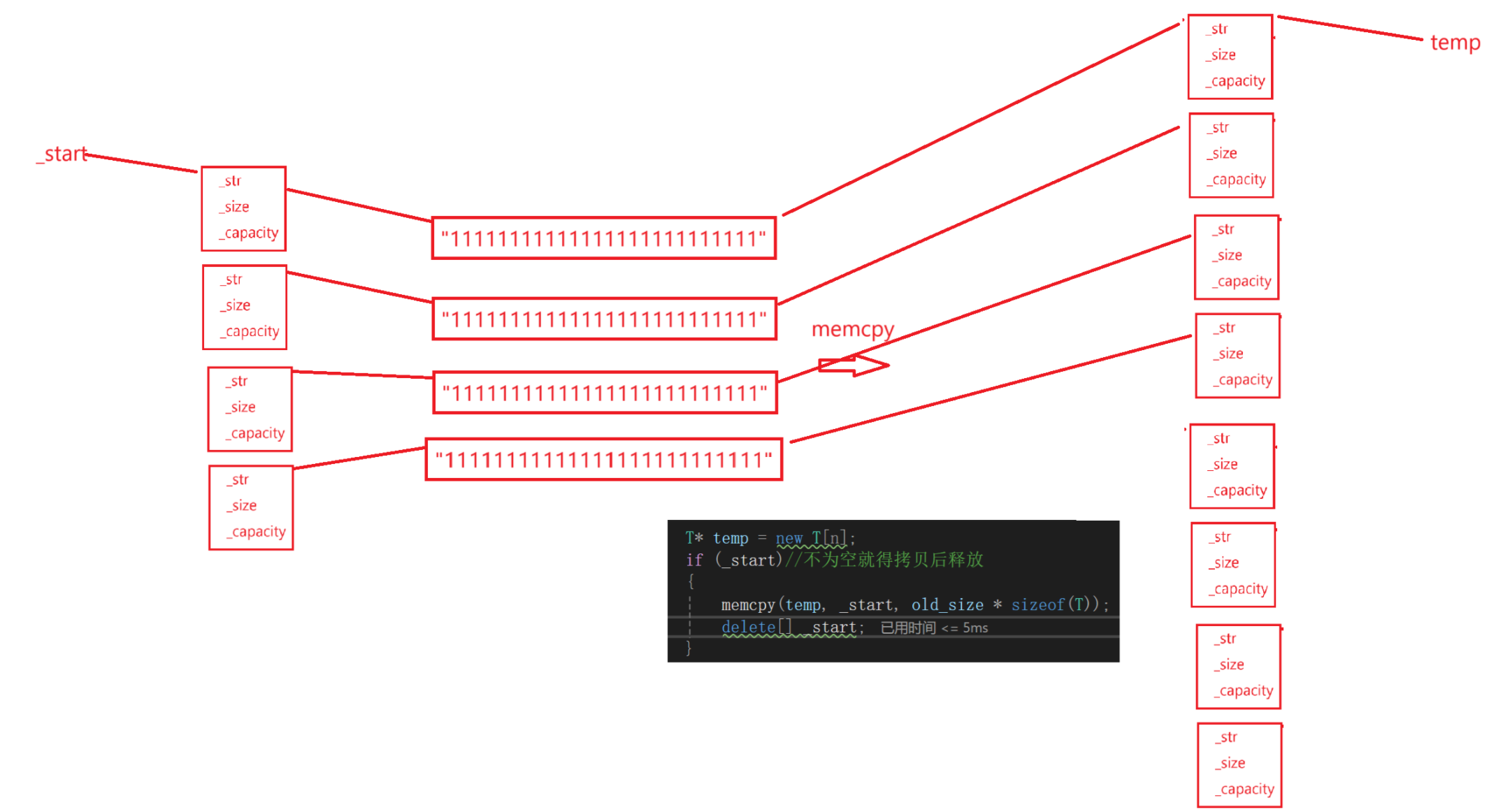
如果delete[] start,对于自定义类型在operator delete中自定义类型调用对应的析构函数,也就是内层的string调用析构函数释放空间,由于temp的深拷贝,temp内层的string也分别一一对应这些string类对象的空间,一一析构
所以升级到vector以后memcpy也不能用了,那可如何是好呢?
void reserve(size_t n){size_t old_size = size();if (n > capacity()){T* temp = new T[n];if (_start)//不为空就得拷贝后释放{//memcpy(temp, _start, old_size * sizeof(T));for (size_t i = 0; i < old_size; i++){temp[i] = _start[i];}delete[] _start;}_start = temp;_finish = _start + old_size;_end_of_storage = _start + n;}}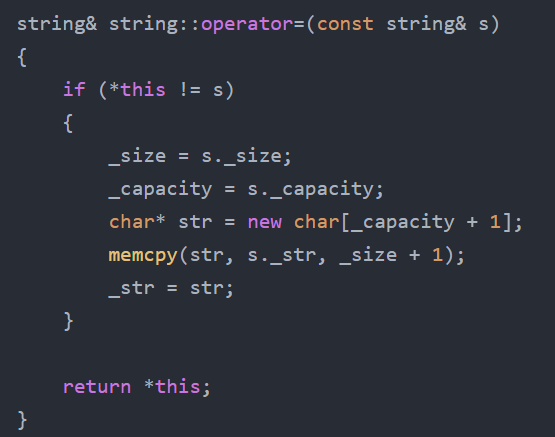
string类的赋值运算符重载我也给你搬过来了,道理是什么呢,外层深拷贝是创建出新的空间用来存string对象,内层深拷贝是为了让每个string对象与原vector(扩容前)对应的string对象指向不同的空间但内容完全相同。