【ComfyUI】Flux Krea 微调完美真实照片生成
今天展示的案例是一个基于 FLUX.1 Krea Dev 微调模型 的 ComfyUI 工作流,它通过融合高精度的 UNet 推理网络、双重文本编码器以及高保真的 VAE 解码器,实现了照片级真实感的图像生成。




整个工作流不仅在细节刻画上具备极高的还原度,还利用正向与反向提示词的对比,实现了对人像风格和瑕疵控制的灵活调节。读者通过该流程能够直观理解从文本提示到最终高保真图像的生成逻辑,并掌握如何利用不同节点进行组合优化,从而发挥出模型的最大潜力。
文章目录
- 工作流介绍
- 核心模型
- Node节点
- 工作流程
- 应用场景
- 开发与应用
工作流介绍
本工作流以 Flux.1 Krea Dev 为核心扩展,结合 HuggingFace 提供的预训练权重,通过 UNet 主体、CLIP 与 T5 双文本编码器以及 VAE 解码器组成了完整的生成链路。流程中首先由双文本编码器将提示词与反向提示词转换为条件向量,随后输入至 UNet 与采样器模块进行潜空间的逐步迭代采样,最终通过 VAE 解码器还原为高清图像。节点间的衔接充分展示了 ComfyUI 模块化的优势,使得每一个环节都具备可替换性和可扩展性。
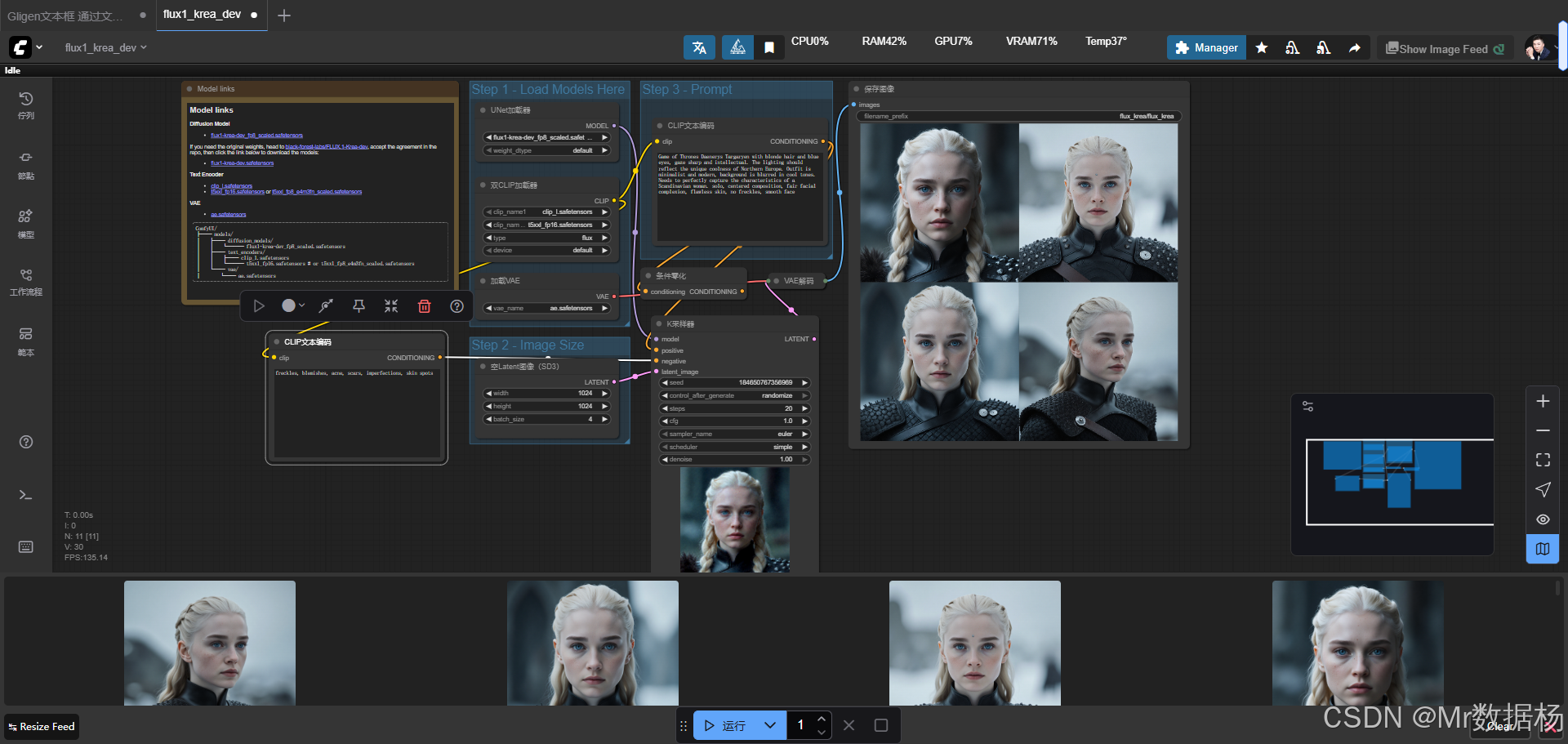
核心模型
该工作流的核心在于对 Flux.1 Krea Dev 模型的加载与应用,它提供了高精度的图像生成能力,同时辅以 CLIP 和 T5 系列的文本编码器实现多模态信息融合,VAE 则负责潜在空间与图像之间的映射解码。综合使用这些模型,形成了一个既保证画质又具备语义理解能力的生成管线。
| 模型名称 | 说明 |
|---|---|
| flux1-krea-dev_fp8_scaled.safetensors | 基于 FLUX.1 微调的扩散模型,负责潜在空间的迭代更新,提升图像真实感 |
| clip_l.safetensors | CLIP 文本编码器,用于将提示词转化为语义向量,保证语义与图像的一致性 |
| t5xxl_fp16.safetensors | 大规模 T5 文本编码器,增强对复杂语义和长提示的理解能力 |
| ae.safetensors | VAE 解码器,将潜空间样本还原为最终高分辨率图像 |
Node节点
该工作流由多个核心节点构成,每个节点承担着不同的功能,从文本输入到潜空间采样,再到图像解码与保存,形成完整的流水线结构。文本提示通过 CLIPTextEncode 节点转换为条件信息,采样器节点执行扩散采样,最后由 VAE 解码得到可视化图像并保存。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载 Flux.1 Krea Dev 扩散模型,核心图像生成组件 |
| DualCLIPLoader | 加载 CLIP 与 T5 文本编码器,支持多语义输入 |
| CLIPTextEncode | 将提示词与反向提示词转换为条件向量,控制生成效果 |
| EmptySD3LatentImage | 创建空潜在空间作为初始输入,定义生成图像尺寸 |
| KSampler | 控制采样过程,包括步数、随机种子与采样器类型 |
| VAELoader | 加载 VAE 模型,负责潜空间与图像的映射 |
| VAEDecode | 将潜在样本解码为高清图像输出 |
| SaveImage | 输出最终生成结果并保存到指定目录 |
工作流程
在这个 ComfyUI 工作流中,整体的生成过程被拆解为若干阶段,每个阶段都承担了特定的职责。通过模型加载、提示词处理、潜空间采样、图像解码以及结果保存的有机衔接,形成了完整的图像生成闭环。模型加载环节确保各类权重文件被正确调取;提示词处理阶段将用户输入的描述语义化为条件向量;采样阶段利用扩散模型对潜在图像进行迭代优化;解码阶段则负责将潜空间中的数据还原成高清图像;最终由保存节点输出结果。这样的流程设计不仅保证了生成的稳定性和灵活性,也为后续替换不同模型或节点提供了可扩展空间。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 调用扩散模型、文本编码器与 VAE 模型,为后续推理提供基础组件 | UNETLoader、DualCLIPLoader、VAELoader |
| 2 | 提示处理 | 将正向与反向提示词转化为条件向量,提供语义控制与负面约束 | CLIPTextEncode |
| 3 | 潜空间初始化 | 创建空的潜空间数据并设定分辨率,作为采样输入 | EmptySD3LatentImage |
| 4 | 扩散采样 | 在潜空间中执行迭代采样,逐步生成符合条件的潜在图像 | KSampler |
| 5 | 图像解码 | 使用 VAE 将潜在图像解码为高清可视化结果 | VAEDecode |
| 6 | 图像保存 | 输出最终生成的图像并保存至指定路径 | SaveImage |
应用场景
该工作流主要适用于高保真肖像生成与艺术风格实验。在人像创作中,正向提示词能够细致地描绘人物特征与光影氛围,而反向提示词则用来抑制瑕疵与不必要的元素,从而得到接近照片质感的高质量图像。在广告与影视视觉设计中,可以通过这一流程快速产出风格统一的人物形象;在AI 艺术创作领域,用户能够尝试不同的提示组合,探索独特的艺术效果。由于工作流采用模块化节点设计,扩展性极强,能够灵活适配到角色再创作、虚拟人生成以及跨文化形象设计等多种应用中。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 高保真肖像生成 | 生成逼真人物照片,避免细节缺陷 | 摄影师、设计师 | 人像特写、面部光影效果 | 呈现接近真实摄影的质感 |
| 广告与影视设计 | 快速产出视觉统一的人物形象 | 影视制作人、广告团队 | 宣传画面、电影角色定妆照 | 节省时间并提升视觉一致性 |
| AI 艺术创作 | 探索独特风格与表现形式 | 数字艺术家 | 实验性艺术图像 | 生成兼具创新与艺术性的作品 |
| 虚拟人生成 | 构建多元化虚拟人物形象 | 游戏开发者、元宇宙设计师 | 虚拟角色、虚拟偶像 | 适配互动场景与虚拟空间 |
| 跨文化创作 | 结合不同文化元素进行形象再创作 | 文化创意工作者 | 跨文化角色设计 | 打造多元化文化风格的视觉内容 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
ComfyUI使用教程、开发指导、资源下载
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用